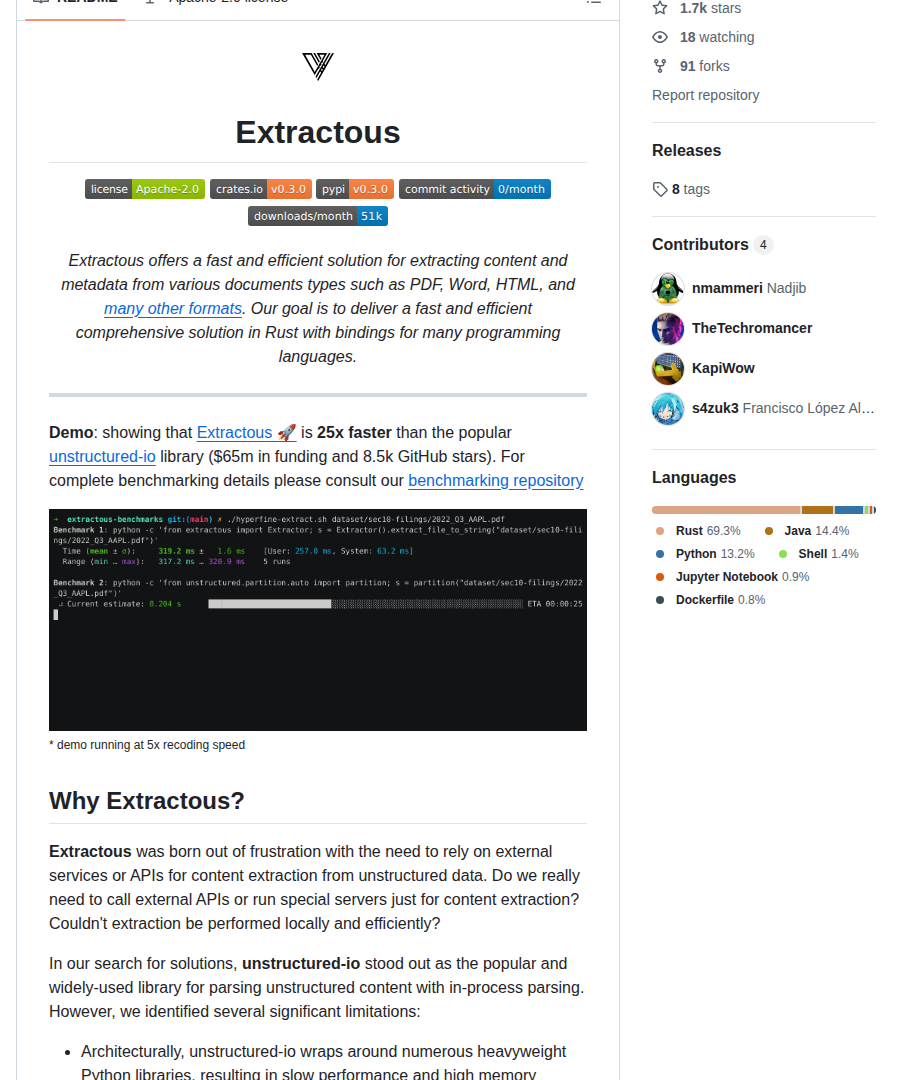
きっかけ
LLMでドキュメント処理を扱う案件が増えてきて、PDFと画像を混在したデータセットが来るたびに、形式ごとに処理ロジックを分けるのが面倒になってた。pypdfでPDF、Pillowで画像、みたいに毎回ライブラリを組み合わせるのは、依存関係の管理も地味に負担。何かまとめて扱えるツールないかなと探してたら、これが目に入った。
使ってみた
GitHubから落としてsetup.pyで入れたら、本当に数分で動いた。ドキュメント見ながら試しに extractous extract --input sample.pdf --output out.txt みたいなコマンド打ったら、そのままテキストが出てくる。「え、これだけ?」って感じ。その後、同じコマンドラインで画像をぶっ込んでみても、自動で形式を判定して処理してくれる。インターフェースがシンプルだから、スクリプト側で分岐させる必要がなくて楽。Pythonからも直接呼び出せるのも地味にポイント高い。
ここが良い
一番良いのは、複数ファイル形式を統一APIで扱える設計。PDF、画像、動画とか、形式の種類を気にせず同じロジックで処理できるから、前処理スクリプトの複雑度がガッと下がる。実案件でも、バッチ処理でPDFと画像を混ぜたデータセットを流してみたら、エラーハンドリング含めてシンプルに収まった。あと、OCRもビルトインされてるのか、画像内のテキストもちゃんと拾ってくれた。その結果、わざわざopenCVやTesseractを別に組む必要なくなって、依存関係がスッキリした。
気になった点
ドキュメントがまだちょっと薄い感じで、細かい挙動をテストで確認しながら進めることになった。あと、大きなファイルを一気に処理すると、メモリ使用量が結構いくみたい。数GBの動画とかは小分けして走らせる工夫がいるかもしれない。
まとめ
マルチフォーマット対応のデータ前処理が必要な人には、試す価値ある。今は依存ライブラリを何個も管理してるなら、このツール使うだけで結構スッキリするはず。自分は今後もプロジェクトで使い続けるつもり。