きっかけ
データセット作成の現場では、ラベリング作業や検証に多くの時間を要する。正確性の維持とスケーラビリティのバランスは、データ処理プロジェクトの重要な課題。HumanSignalが開発したAdalaは、データラベリングを自動化する枠組みとして注目される。
機能概要
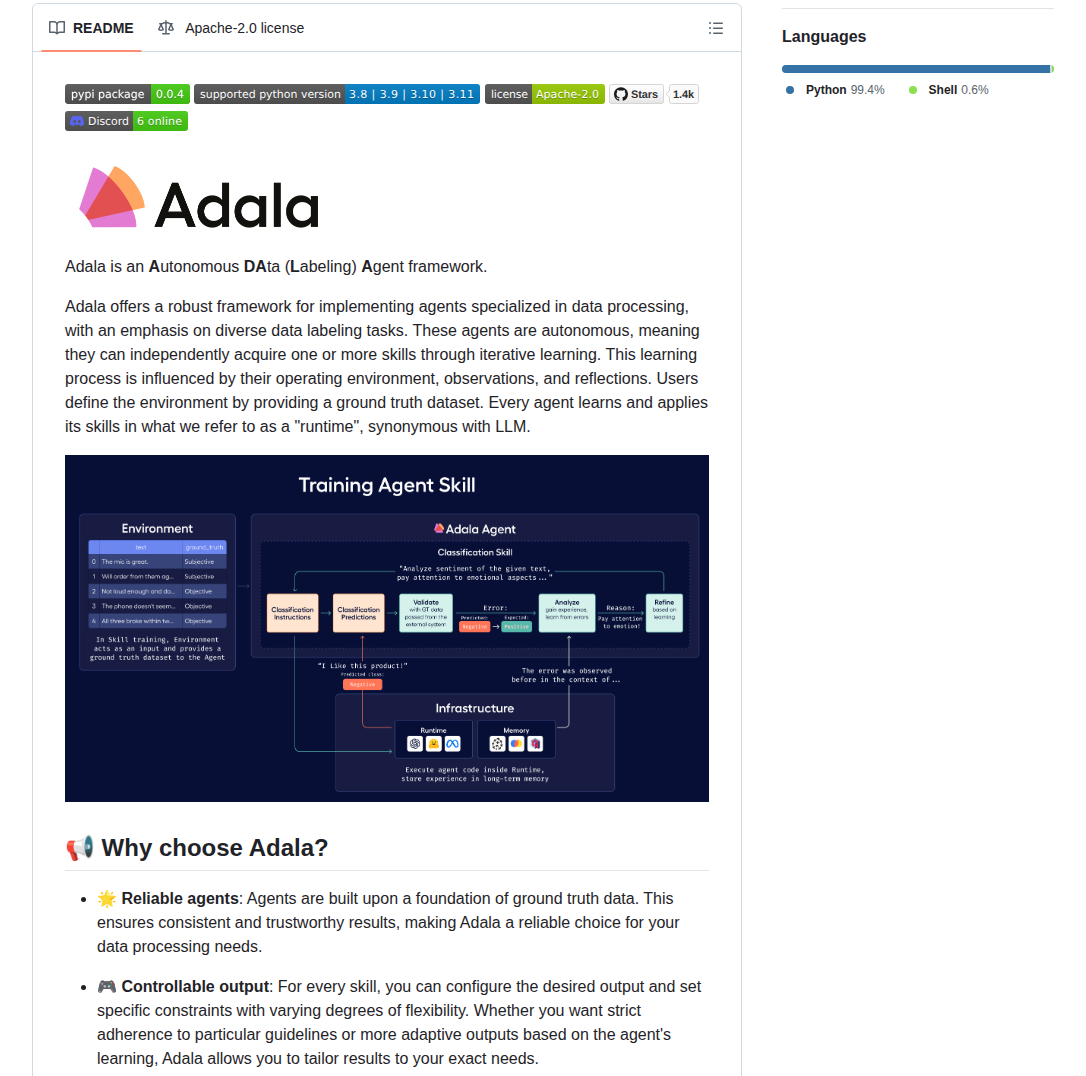
Adalaは自律型データラベリングエージェント框架。PyPI経由で配布されており、Python 3.8~3.11に対応している。エージェントはタスク定義に基づいて動作し、繰り返しの実行を通じた学習メカニズムを備えている。このメカニズムは、観測と反省(observations and reflections)に基づいており、ユーザーが提供する正解データセットを環境として学習を進める設計。
ドキュメントによれば、エージェントの学習は実行環境(runtime)、具体的にはOpenAIやVertexAIなどのLLMプロバイダーを活用して実装される。
設計の特徴
Adalaの設計には以下の特徴がある:
- 正解データに基づく信頼性:エージェントの動作は提供された正解データセットに基づいており、一貫性のある結果を目指している
- 出力の制御性:タスク定義やプロンプトエンジニアリングを通じた細かな制御が可能な構造
- 反復的な改善ループ:エージェントは複数回のタスク実行を通じて、学習プロセスに組み込まれている
実装上の検討事項
Adalaの実装検討にあたっては、以下の点に注意が必要。
LLMの出力に依存する特性上、同じタスク定義でも実行結果にばらつきが生じる可能性がある。本番運用を想定する場合、結果の検証プロセスは必須。また、複雑なタスク要件に対応させるには、プロンプトエンジニアリングの工夫が重要になる。
活用シーン
ラベリングやデータ処理における手作業の比率が高いプロジェクトでは、Adalaの導入を検討する価値がある。エージェントの繰り返し学習という考え方は、今後のAI開発における標準的なアプローチになる可能性がある。