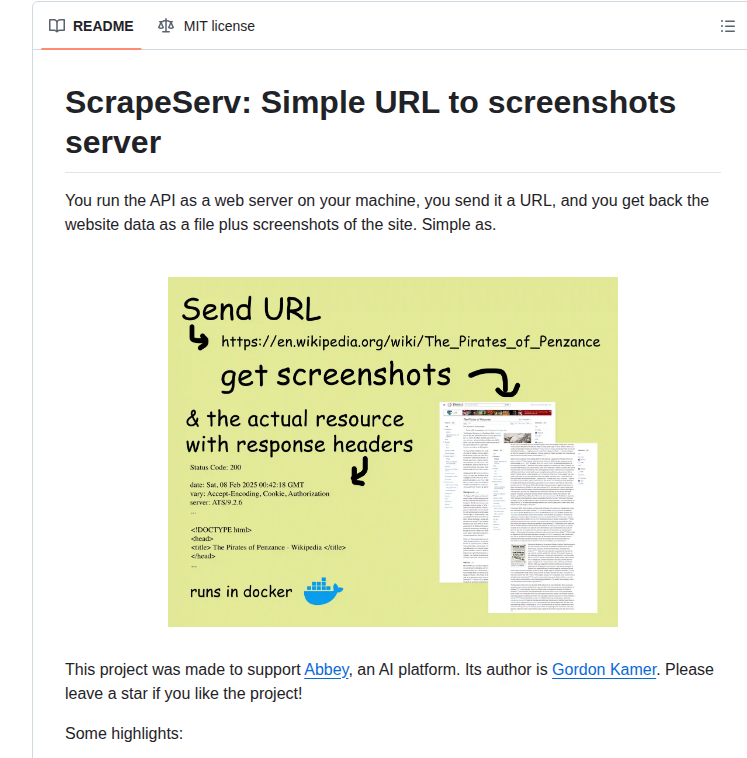
概要
ScrapeServはGoodreasonAIが開発するAI駆動型Webスクレイピングツールで、従来の正規表現やセレクタベースの手法に代わり、LLMの自然言語理解能力を活用して動的かつ複雑なWebページから高精度でデータを抽出します。JavaScriptレンダリング対応サイトやレイアウト変動への耐性が高く、スクレイピング開発の保守コスト削減を目指して設計されました。
主な機能
- LLMベースのコンテンツ抽出:正規表現やCSSセレクタに依存せず、AIが自然言語の指示に基づいてテキスト・画像・テーブルデータを抽出できます。
- マルチモーダル対応:HTMLテキスト、スクリーンショット、PDFドキュメントなど複数の入力形式を処理し、視覚的な情報も含めた抽出が可能です。
- 動的レイアウト適応:Webページの構造が変更されてもAIが柔軟に対応するため、セレクタの更新作業が不要になります。
- バッチ処理とスケーリング:複数URLの並列処理をサポートし、大規模データセット収集時の効率化を実現します。
- スキーマベースの構造化出力:抽出結果をJSON・CSV・データベース形式で標準化でき、ダウンストリーム処理をシンプルにします。
- プロキシ・ユーザーエージェント管理:Bot対策機構やセッション管理に対応し、実運用環境での安定稼働を支援します。
- 実行ログとエラーハンドリング:各スクレイピング実行の詳細トレースログを記録し、失敗時の原因特定を高速化します。
技術スタック
- プログラミング言語:Python 3.10以上(メイン実装)
- フレームワーク・ライブラリ:FastAPI(Web API提供)、Asyncio(非同期処理)、Pydantic(スキーマ検証)
- LLMプロバイダー:OpenAI GPT-4・GPT-4V(Vision)、Anthropic Claude、Azure OpenAI
- ブラウザ自動化:Playwright、Selenium(JavaScriptレンダリング対応)
- データ処理:pandas、BeautifulSoup4(HTML解析の補助)
- キャッシング・キュー:Redis(オプション、高速化用)
- ログ・モニタリング:Python logging、構造化ログ(JSON形式対応)
導入方法
GitHubリポジトリからクローンし、Pythonの仮想環境を構築してインストールします。
git clone https://github.com/goodreasonai/ScrapeServ.git
cd ScrapeServ
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
pip install -r requirements.txt
環境変数を設定し、APIキーを登録します。
export OPENAI_API_KEY="your-api-key"
export SCRAPESERV_CONFIG="config.yaml"
APIサーバーを起動します。
python -m scrapeserv.server --host 0.0.0.0 --port 8000
ブラウザでhttp://localhost:8000/docsにアクセスするとSwagger UIが表示され、REST APIの対話的テストが可能になります。
競合比較
| 項目 | ScrapeServ | Bright Data / Smartproxy | Beautiful Soup + Regex |
|---|---|---|---|
| 技術基盤 | AI/LLM駆動 | プロキシ・ローテーション特化 | 静的HTML解析 |
| マルチモーダル対応 | テキスト・画像・PDF対応 | テキスト中心 | テキストのみ |
| レイアウト変動への耐性 | 高(AIが柔軟対応) | 中(セレクタ更新が必要) | 低(正規表現破損) |
| 学習曲線 | 中程度(自然言語指定) | 低(GUI・複数言語) | 低(シンプル) |
| 料金体系 | トークン従量課金 | データ従量課金 | オープンソース |
ScrapeServの最大の差別化ポイントは、AI/LLMを活用した意味論的データ抽出にあります。Bright Data等のプロキシサービスはBot対策回避に優れているものの、データの「何を」取得すべきかを定義するのは開発者に委ねられる。一方ScrapeServは「商品の価格と在庫状況を抽出してください」といった自然言語指示により、AIが自動的に最適な抽出ロジックを生成・実行するため、メンテナンスコストが大幅に削減されます。複雑な複数ステップのスクレイピングやPDF内の表データ抽出にはScrapeServが、単純なAPI化やプロキシ管理にはBright Dataが、プロトタイプ開発には Beautiful Soupがそれぞれ最適という位置付けです。
こんな人におすすめ
- データエンジニア・分析職:HTMLセレクタのメンテナンス負荷を削減し、複雑なWebデータ収集パイプラインを迅速に構築できます。
- Webスクレイピング初心者:正規表現やXPath習得が不要で、日本語での自然言語指定でデータを抽出できるため学習効率が向上します。
- 動的Webサイト対応が必要な組織:JavaScriptレンダリング後のDOM操作に対応し、Single Page Application(SPA)からの高精度抽出を実現します。
- 大規模データセット収集プロジェクト:バッチ処理と非同期実行により、数千〜数百万レコード規模のスクレイピングを効率的に処理できます。
- 複数言語サイトの統一的抽出:LLMが多言語に対応するため、日本語・英語・中国語など言語ごとに別セレクタを用意する必要がなくなります。