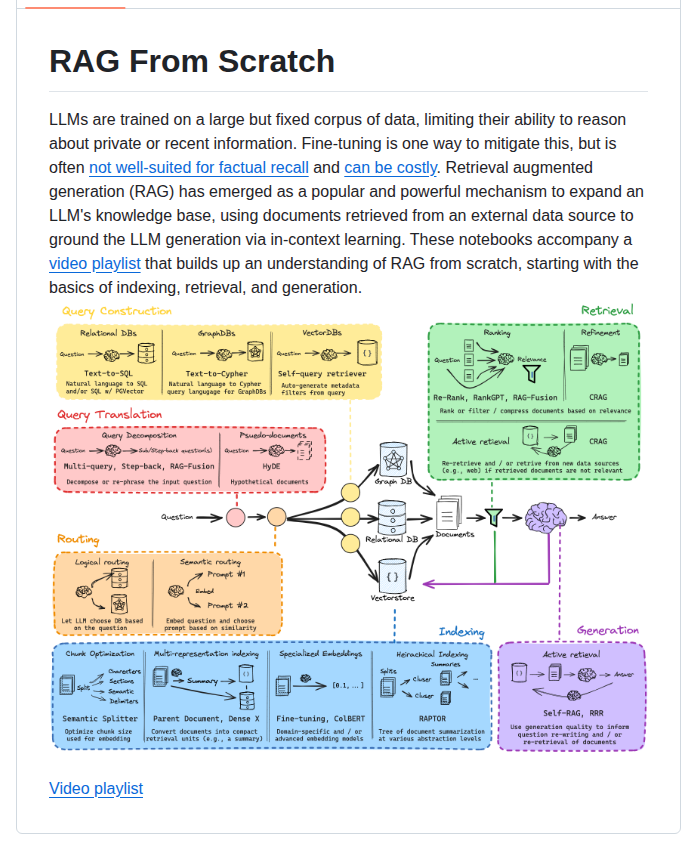
概要
Langchain RAG From Scratchは、LangChainが公式に提供するRAG(Retrieval-Augmented Generation)システムの実装ガイドおよびコード集です。外部知識ベースを活用してLLMの回答精度を向上させるRAGの構築方法を、初級者向けから段階的に解説しています。2024年以降、生成AIの実運用でRAGの需要が急速に高まる中、このリポジトリは単なるサンプルコード以上の価値を持つ——実装パターンのベストプラクティス集として機能しており、データエンジニアやML開発者の事実上の教科書となっています。
主な機能
-
段階的な実装チュートリアル:RAGの基礎的なデータ取得から、複雑なマルチステップ検索まで、ステップバイステップで学べる構成になっており、未経験者でも段階を踏みながら習得できます。
-
複数の検索戦略パターン:キーワード検索、セマンティック検索、ハイブリッド検索、さらには質問の言い換え(Query Rewriting)やステップバイステップの検索など、複数のRAG戦略の実装例を提供します。
-
Langchain統合ガイド:Langchainの各コンポーネント(Retriever、VectorStore、Chain)を組み合わせた実践的な統合方法を、実動作するコード例で示しており、すぐに本番環境へ応用できます。
-
評価・最適化メトリクス:RAGシステムの性能測定方法や改善手法——精度(Precision)、再現率(Recall)、NDCG(正規化割引累積利得)の計算式と実装を含む——を解説しており、本番運用での意思決定に直結します。
-
複数ベクトルDB対応:Pinecone、Weaviate、Chroma、Qdrantなど主要なベクトルデータベースに対する接続パターンを複数用意しており、インフラの構成に応じて柔軟に選択・切り替えられます。
-
プロンプトエンジニアリング実践例:検索結果を効果的にLLMに入力する方法、コンテキストウィンドウの最適化、システムプロンプトの設計パターンなど、エンドツーエンドの実装ノウハウが含まれています。
技術スタック
- メイン言語:Python 3.9以上
- コア依存ライブラリ:LangChain(0.1.0以上)、LangSmith(トレーシング・デバッグ)
- LLMプロバイダー:OpenAI API(GPT-4、GPT-3.5-turbo)、Azure OpenAI、Anthropic Claude
- ベクトルDB:Pinecone、Weaviate、Chroma、Qdrant、Supabase(PostgreSQL)
- ドキュメント処理:LangChain DocumentLoader(PDF、HTML、テキスト)、Unstructured、PyPDF
- 埋め込みモデル:OpenAI Embeddings、HuggingFace Sentence Transformers、Cohere
- 評価ライブラリ:RAGAS(RAG Assessment)、Trulens、DeepEval
導入方法
最小限のセットアップで始める場合:
pip install langchain langchain-openai langchain-community
ベクトル検索を含む本格的なセットアップの場合:
pip install langchain langchain-openai pinecone-client python-dotenv PyPDF2
リポジトリのクローン後、依存パッケージをインストール:
git clone https://github.com/langchain-ai/rag-from-scratch.git
cd rag-from-scratch
pip install -r requirements.txt
環境変数の設定(OpenAI APIキーなど):
cp .env.example .env
# .envファイルを編集してAPIキーを設定
各段階のチュートリアルはJupyterノートブックまたはPythonスクリプトで提供されており、python example_01_basic_rag.pyのように実行できます。
競合比較
| 項目 | Langchain RAG From Scratch | LlamaIndex | Haystack |
|---|---|---|---|
| 学習曲線 | 初級〜中級向け・段階的 | 中級〜上級向け・高機能 | 中級向け・エンタープライズ志向 |
| RAG最適化機能 | Query Rewriting、Hybrid Search | Auto Merging、Self-Refining | Pipeline UI、Evaluation Framework |
| ベクトルDB対応 | 6種以上対応 | 8種以上対応・より詳細なドキュメント | 4〜5種・エンタープライズ優先 |
| コミュニティ規模 | LangChainコミュニティの一部・成長中 | 専門コミュニティ・活発 | 企業サポート重視 |
| 評価機能 | RAGASライブラリと連携 | LlamaIndex Eval統合 | Haystack Evaluation Pipeline |
Langchain RAG From ScratchはLangChainの公式教材として位置づけられ、最新のAPI変更に即座に対応している点で強み。LlamaIndexは高度なRAG最適化手法(Auto Merging、Hierarchical Retrievalなど)の実装が詳しく、より複雑なシステム構築を志向する層に適している。Haymarkはエンタープライズレベルの本番運用パイプライン構築に秀でており、評価・監視の仕組みが充実している。
こんな人におすすめ
-
LangChainを初めて使う開発者:公式提供のシーケンシャルなチュートリアルにより、基礎から応用まで体系的に習得でき、独学での実装ハードルが大幅に低下する。
-
RAGシステムの本番運用に携わるエンジニア:複数の検索戦略やベクトルDB、評価メトリクスの実装例が揃っており、実際のプロダクション環境への導入判断に必要なノウハウをすぐに活用できる。
-
データエンジニア・アナリスト:ドキュメント処理からベクトル化、検索、LLM統合までのパイプライン全体をコード例で理解でき、データ準備の最適化方法を直接習得できる。
-
企業内のLLMプロジェクト責任者:段階的な実装ガイドと複数の選択肢(ベクトルDB、埋め込みモデル)を同時に比較検討できるため、チーム全体での技術スタック決定を効率化できる。
-
研究者・学生:RAGの理論と実装が一体化しており、論文で扱われている手法(Query Rewriting、Self-Refinement)の具体的な実装方法を直接確認でき、学習から論文執筆への接続が容易になる。