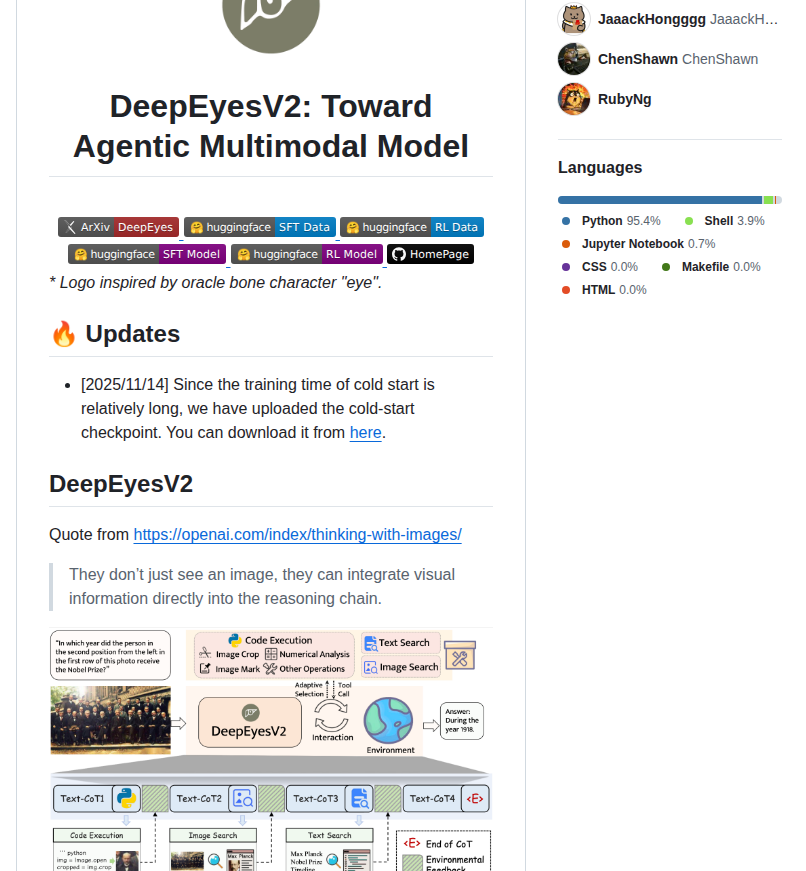
DeepEyesV2について
DeepEyesV2はマルチモーダルエージェントモデルであり、単一の推論ループ内でコード実行とウェブ検索を統合する特徴を持つ。視覚情報を推論チェーンに直接組み込むことで、複雑な推論処理を実現するプロジェクト。
DeepEyesV2の特徴
DeepEyesV2の核となる特徴は、画像などの視覚情報をエージェントの推論プロセスに統合する点にある。単なる画像分類ツールではなく、コード実行とウェブ検索の両機能を同一の推論ループ内で動作させることで、より信頼性の高い複雑な推論を実現する設計となっている。
視覚情報に基づいた多段階の分析タスクや、複雑な判定が必要なシーンでは、AIエージェントが複数の観点から統合的に処理することが可能。従来の単純なパイプライン処理ではなく、推論を伴う動的なタスク処理が特徴。
活用の可能性
マルチモーダルなエージェント機能により、画像入力に基づいた複雑な判定やレポート作成など、知識ワーカーの補助ツールとしての活用が見込まれる。単一の決定木的な処理ではなく、エージェントが複数の推論ステップを自動実行することで、見落としの削減や判定精度の向上につながる可能性がある。
技術的背景
DeepEyesV2の開発では、厳密なデータフィルタリングとクリーニングを通じた学習コーパスの構築が行われている。Hugging Faceにおいてモデルチェックポイント、SFT(Supervised Fine-Tuning)データセット、RL(Reinforcement Learning)データセットが公開されており、研究およびプロダクト利用の両面で活用可能な環境が整備されている。