この記事ではAIエージェントに特化して解説します。AIエージェント全般は AIエージェントフレームワーク完全比較2026|LangGraph/CrewAI/AutoGen他 をご覧ください。
この記事はCode with Claude London 2026 完全ガイドシリーズの一部です。ロンドン版(5/19)でのMemory & Dreamingセッション解説はリンク先をご覧ください。
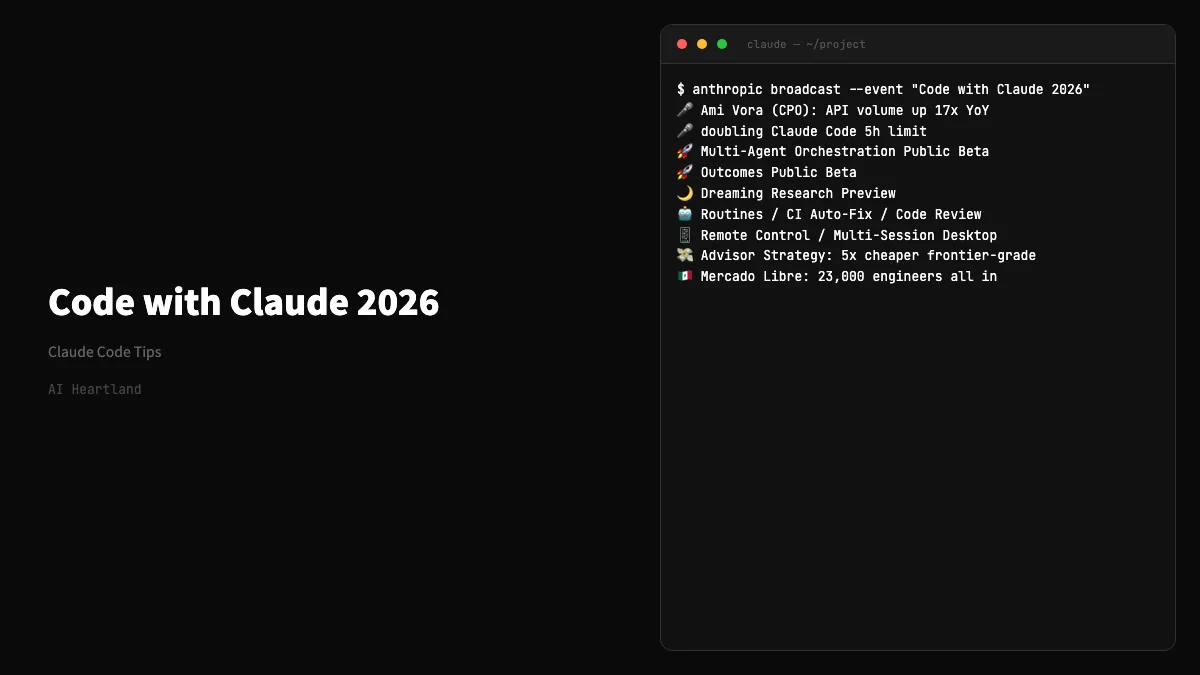
基調講演全体の速報は Code with Claude 2026速報|新モデルなし、全製品一気に強化 を参照。本記事はそのうち Managed Agents の3大機能(Dreaming/Outcomes/Multi-Agent Orchestration)と Memory 昇格を、API仕様まで踏み込んで深掘りする。
何が起きたか — 「夜の間に自己改善するエージェント」が現実に
2026年5月6日、サンフランシスコで開催された Anthropic の開発者カンファレンス Code with Claude 2026 で、Claude Managed Agents(4月にパブリックベータ開始した、Anthropic ホスティング型のエージェントランタイム)に 3つの大型機能 と Memory の正式β昇格が同時発表された。
| 機能 | ステータス | 一言で何か |
|---|---|---|
| Memory | public beta(昇格) | セッション横断のファイルベース記憶 |
| Dreaming | research preview | 過去セッション群を定期走査して Memory を再構成する自己改善パイプライン |
| Outcomes | public beta | ルーブリック評価器を別コンテキストで走らせ、合格まで自己修正 |
| Multi-Agent Orchestration | public beta | リードエージェントから specialist subagent への並列ファンアウト |
特に注目を集めたのは Dreaming。Anthropic公式ブログは次のように説明している。
“Dreaming surfaces patterns that a single agent can’t see on its own, including recurring mistakes, workflows that agents converge on, and preferences shared across a team.”
— 単一のエージェントでは見えないパターン(繰り返すミス、収束するワークフロー、チーム横断の好み)を浮かび上がらせる
人間が寝ている間にエージェントが過去の自分の作業を振り返り、Memory を整理して翌朝に賢くなって戻ってくる。これは LLM 運用の常識(毎セッションが独立で、知識が積み上がらない)を根本から覆す設計だ。
加えて、楽天が本番投入して 97%のファーストパスエラー削減・27%のコスト削減・34%のレイテンシ削減 を達成したという具体的な数字が公開された点も大きい。Memory + Dreaming は単なるリサーチ機能ではなく、実運用で測定可能な ROI を生んでいる。
2026-05-06 Code with Claude SF にて発表(既存製品の総力アップデート)
Memory が public beta に昇格、Dreaming は research preview 開始
楽天で97%エラー削減・27%コスト削減・34%レイテンシ削減という実数値を公開
Dreaming — 「過去を読み直して Memory を再構成する」非同期ジョブ
コンセプト
Memory ストアは、エージェントが作業しながらインクリメンタルに書き込む。これを長く運用すると、重複・矛盾・古くなったエントリ が溜まってくる。Dreaming はこれをまとめて掃除する。
公式ドキュメント(/docs/en/managed-agents/dreams)から引用:
“A dream reads an existing memory store alongside past session transcripts, then produces a new, reorganized memory store: duplicates merged, stale or contradicted entries replaced with the latest value, and new insights surfaced.”
入力ストアは絶対に変更しない(output ストアが新規に作られる)。気に入らなければ捨てればいい、という設計思想だ。
アーキテクチャ図
(既存・読み込み専用)"] S1["Session 1"] S2["Session 2"] S3["…最大100セッション"] end subgraph DREAM["Dream パイプライン
(async, 数分〜数十分)"] READ["1. 全入力を読み込み"] PATTERN["2. パターン抽出
(重複・矛盾・新知見)"] WRITE["3. 新ストアに再構成"] end M0 --> READ S1 --> READ S2 --> READ S3 --> READ READ --> PATTERN PATTERN --> WRITE WRITE --> OUT["Memory Store v1
(新規・人間がレビュー可)"] OUT --> NEXT["次セッションに
memory_store として attach"]
API 仕様
/v1/dreams を叩く。ベータヘッダーが2つ必要:
managed-agents-2026-04-01(Managed Agents 全体)dreaming-2026-04-21(Dreaming 専用)
Python SDK での起動例(公式ドキュメントから):
dream = client.beta.dreams.create(
inputs=[
{"type": "memory_store", "memory_store_id": store_id},
{"type": "sessions", "session_ids": [session_a, session_b]},
],
model="claude-opus-4-7",
instructions="Focus on coding-style preferences; ignore one-off debugging notes.",
)
print(dream.id) # drm_01...
返ってくるレスポンスは status: "pending" で始まり、ポーリングで running → completed を追跡する。
while dream.status in ("pending", "running"):
time.sleep(10)
dream = client.beta.dreams.retrieve(dream.id)
print(f"status={dream.status} input_tokens={dream.usage.input_tokens}")
完了すると outputs[] に新しい memory_store_id が入っている。これを次のセッション作成時に resources として渡せば、整理された Memory で動き出す。
制約と料金
| 項目 | 値 |
|---|---|
| 1 dream あたりの最大セッション数 | 100 |
instructions の文字数 |
最大 4,096 文字 |
| サポートモデル | claude-opus-4-7, claude-sonnet-4-6 |
| 料金 | 選択モデルの標準APIトークン料金(プレミアム課金なし) |
| 実行時間 | 数分〜数十分(入力サイズに比例) |
usage フィールドに input/output/cache_creation/cache_read の各トークン数が記録される。小規模なバッチで品質を確認してから本番ロールアウトすることが公式に推奨されている。
ライフサイクル
status |
意味 |
|---|---|
pending |
作成済み、キュー待ち |
running |
パイプライン実行中(session_id フィールドに内部セッションID。SSEでイベントストリーム可) |
completed |
正常終了。outputs[] に新ストア |
failed |
エラーで停止。途中まで書き込まれた output ストアは残る |
canceled |
キャンセル。output ストアは残る |
よくあるエラー
error.type |
発生条件 |
|---|---|
timeout |
パイプラインが実行時間予算を超過 |
input_memory_store_too_large |
入力ストアがサイズ上限超過 |
input_memory_store_unavailable |
入力ストアが実行中に削除/アーカイブされた |
input_session_unavailable |
入力セッションが実行中に削除/アーカイブされた |
memory_store_org_limit_exceeded |
組織の Memory Store 数上限に到達 |
Simon Willison のデモ観察
Simon Willison のライブブログによれば、デモでは Dreaming が descent-playbook.md というファイルを過去セッションから生成してみせた。具体的には、複数の試行錯誤セッションを読み込ませ、エージェントが「降下手順のベストプラクティス」を1ファイルにまとめ直す、というシナリオだ。
“Claude Managed Agents can inspect previous sessions overnight to self-improve and create new memories.”
「夜間の自己改善」という表現は誇張ではなく、文字通り cron で dreams.create を回せば毎晩 Memory が整理される という運用が成立する。
Outcomes — ルーブリック評価器で「合格まで自己修正」
コンセプト
エージェントの最大の弱点は「いつ完成したか自分で判断できない」こと。Outcomes はこれを解決する。
開発者は rubric(評価基準)を書く。エージェントが出力を生成すると、別のコンテキストウィンドウで動く grader(評価器)がその rubric に照らして採点する。基準を満たすまで、エージェントは自己修正を繰り返す。
公式ブログの表現:
“Set what success looks like so Claude can iterate and get it done.”
評価器を 別コンテキスト で走らせる点が肝で、エージェント自身の推論バイアスから切り離して採点できる。
性能数値(Anthropic 社内テスト)
| ベンチマーク | Outcomes なし → あり |
|---|---|
| 全体タスク成功率 | +最大 10pt |
| docx ドキュメント生成 | +8.4% |
| pptx プレゼン生成 | +10.1% |
公式ブログより:
“Outcomes improved task success by up to 10 points over a standard prompting loop, with the largest gains on the hardest problems.”
「難しい問題ほど効果が大きい」 という挙動は、ルーブリック駆動の自己修正ループが本質的に効いている証拠だ。簡単な問題は1発で通るので余地が小さく、難しい問題は何度も修正される過程で精度が積み上がる。
適合するワークロード
公式ドキュメントは以下のユースケースを推奨している:
- 網羅的カバレッジが必要 — テスト生成、QAレポート、リファクタリング全コード走査
- 細部への注意 — ドキュメント整形、表記統一、フォーマット遵守
- ブランドボイス一致 — マーケティングコピー、社内文書のトーン統一
- ビジュアルデザイン遵守 — スライド、PDF、図表のスタイルガイド準拠
逆に、正解が一意に決まらないクリエイティブな探索タスク(ブレスト、アイデア出し)には rubric が書けないので向かない。
Simon Willison のメンタルモデル
Simon は Outcomes を 「Ralph loop」 パターンになぞらえて解説している。Ralph loop とは、ある目標に対してエージェントが自己評価しながら反復改善する古典的なエージェント設計パターンで、Outcomes はその「評価器を別コンテキストで持つ」工夫を入れた洗練版と捉えるとわかりやすい。
Multi-Agent Orchestration — リードから specialist への並列ファンアウト
コンセプト
1つのエージェントに全部やらせると、コンテキストが肥大化し、判断が遅くなり、専門性も曖昧になる。Multi-Agent Orchestration はこれを 「リードエージェント + 複数 specialist subagent」 の編成で解決する。
公式の説明:
“A lead agent breaks the job into pieces and delegates each one to a specialist with its own model, prompt, and tools, with these specialists working in parallel on a shared filesystem and contributing to the lead agent’s overall context.”
各 specialist は 個別のモデル・プロンプト・ツール を持てる。例えば:
- リード:Opus 4.7(全体設計)
- subagent A:Sonnet 4.6(ログ解析専門、grep/awk ツール)
- subagent B:Haiku 4.5(メトリクス集計、PromQL ツール)
- subagent C:Sonnet 4.6(チケット検索、Linear MCP)
公式デモ(インシデント調査)
公式ブログのユースケース例:
“A lead agent can run an investigation while subagents fan out through deploy history, error logs, metrics, and support tickets.”
インシデント発生時、リードがデプロイ履歴・エラーログ・メトリクス・サポートチケットを 並列に subagent に走らせ、それぞれの結果を集約して原因仮説を立てる。シーケンシャル実行に比べてレイテンシが大幅に短縮される。
「Moon Landing Drone」デモ
Code with Claude のキーノートでは、Multi-Agent Orchestration のショーケースとして「月着陸ドローン」のシミュレーションが披露された。Simon の記録:
“The moon landing drone demo showed multiple specialized agents (Commander, Detector, Navigator) coordinating to accomplish objectives impossible for single instances.”
Commander(指令)・Detector(観測)・Navigator(航法)の3エージェントが協調して、単一エージェントでは到達不能な複雑タスクを成功させた。
Console での可観測性
公式ドキュメント:
“You can trace every step in the Claude Console: which agent did what, in what order, and why, giving you full visibility into how your task was delegated and executed.”
これは運用上きわめて重要。マルチエージェントは「ブラックボックスで何が起きたかわからない」になりがちだが、Anthropic の Console では どの subagent が何を実行したか・どの順序で・なぜ呼ばれたか が可視化される。
Memory — public beta 昇格、楽天が示した実運用 ROI
Memory の基本
Memory は filesystem-based。エージェントが普段使っている bash・コード実行と同じインターフェースで読み書きできる。Markdown ファイルの構造化フォルダだと思えばよい。
公式ドキュメントから:
“Memory files are portable and programmable—Memories are files that can be exported and independently managed via the API, giving developers full control.”
公開された機能
| 機能 | 内容 |
|---|---|
| Cross-session learning | セッション間で知見を保持・共有 |
| Scoped access | 複数エージェント間でストア共有、アクセススコープ設定可 |
| Audit log | どのエージェント・どのセッションが書いた変更か追跡 |
| Version control | 古いバージョンへロールバック、履歴からの編集削除 |
| Concurrent safety | 複数エージェントが同一ストアに同時書き込みしても上書きされない |
楽天の本番事例(Yusuke Kaji 氏のステートメント)
楽天は Memory を本番投入し、以下の結果を公開した:
“Memory in Claude Managed Agents lets us put continuous learning into production at scale. Our agents distill lessons from every session, delivering 97% fewer first-pass errors at 27% lower cost and 34% lower latency.”
— Yusuke Kaji, General Manager, AI for Business at Rakuten
| 指標 | 改善 |
|---|---|
| ファーストパスエラー | −97% |
| コスト | −27% |
| レイテンシ | −34% |
3指標が同時に大幅改善している点が示唆的だ。Memory に過去のミスを書き残すことで、
- 同じミスを繰り返さない(エラー削減)
- 試行錯誤回数が減る(コスト削減)
- 最初から正解に近い手順を取る(レイテンシ削減)
という3重の効果が連動している。
4機能の関係性 — どう組み合わせて使うか
1. Multi-Agent Orchestration でリード+specialist編成を組む
2. 各エージェントは Memory ストアを参照/書き込み
3. Outcomes でルーブリック評価し、合格まで自己修正
4. 1日の終わりに Dreaming をスケジュール起動して Memory を整理
5. 翌日のセッションは整理済みの新ストアから開始
これは「継続学習する組織型エージェント」の最初の本格実装と言える。従来のエージェントが「毎朝記憶喪失で出社する派遣社員」だとすれば、この4機能を組み合わせたエージェント群は「ナレッジを共有し、夜間に振り返り会をする正社員チーム」に近い。
競合との比較
Multi-Agent Orchestration や Memory に類する機能は他社も提供しているが、4機能を統合して提供しているのは Anthropic だけだ。
| 機能 | Claude Managed Agents | OpenAI Assistants | Google Vertex AI Agent Builder |
|---|---|---|---|
| 永続Memory | public beta(filesystem) | あり(Threads) | あり(Vector Store) |
| 自己改善(Dreaming相当) | research preview | なし | なし |
| ルーブリック評価器 | public beta(Outcomes) | なし | 限定(Eval Service) |
| マルチエージェント編成 | public beta(共有FS) | Swarm(実験的) | あり |
| 実行履歴の可視化 | Claude Console | Threads UI | Cloud Logging |
| ホスティング | Anthropic | OpenAI | Google Cloud |
Dreaming に相当する 「メタ認知的に過去セッションを振り返って Memory を再構成する」機能 は、現時点で Anthropic にしかない独自機能だ。
エンジニアへの影響
- 「セッション ≒ コンテキストウィンドウ」だった世界観の終わり:Memory + Dreaming で継続学習が実装レイヤで提供される
- Outcomes で「いつ止めるか問題」が解消:エージェントの暴走防止と早期停止のバランス制御に効く
- マルチエージェントは「やりすぎ」から「現実解」へ:共有FS + Console トレースで運用可能性が大きく上がった
- 楽天事例の数字(−97%, −27%, −34%)が業界基準になる可能性:今後の社内導入RFPで Memory の有無が必須要件化する可能性
- API 設計の細かさが秀逸:dream の input store は変更不可・output は別ストア・失敗時も部分結果保存、という配慮が運用しやすい
- research preview は申請制:Dreaming を試したい場合は request access form からの承認待ちが必要
試してみるには
- Claude API キーを取得(console)
- Managed Agents は API アカウントでデフォルト有効。
managed-agents-2026-04-01ベータヘッダーを必ず付ける - Dreaming / Outcomes / Multi-Agent は research preview で申請制(Request access)
- Memory は public beta、Managed Agents 本体(Sessions/Environments/Agents)と一緒にAPI アカウントで即利用可
最小構成のセッション作成例(Dreaming の output ストアを次のセッションに attach):
session = client.beta.sessions.create(
agent=agent_id,
environment_id=environment_id,
resources=[
{"type": "memory_store", "memory_store_id": output_store_id},
],
)
AIエージェントフレームワーク完全比較2026 で取り上げている LangGraph や CrewAI との大きな違いは、ホスティング・サンドボックス・セッション永続化を Anthropic 側が引き受ける 点だ。OSS フレームワークでこれと同等のものを自前で組むには、Kubernetes・Vault・Postgres・監査ログ基盤を全部整える必要がある。
利用条件・対応プラン(2026年5月時点)
「Pro/Max/Team サブスクで Managed Agents を使えるのか?」「Dreaming は誰でも触れるのか?」は読者から最もよく聞かれる質問だ。Claude.ai のコンシューマプラン(Pro/Max/Team/Enterprise)と Anthropic API(Console)では契約系統が完全に別物であり、Managed Agents は API/Console 側でのみ利用可能な点をまず押さえておく必要がある。
4機能のステータス・対応経路(公式ドキュメントベース)
| 機能 | ステータス | 対応プラン | アクセス方法 | ベータヘッダー |
|---|---|---|---|---|
| Managed Agents 本体(Sessions / Environments / Agents) | Public beta | Anthropic API / Console アカウント | API キーがあれば即利用可、申請不要 | managed-agents-2026-04-01 |
| Memory | Public beta(Managed Agents の一部として) | API / Console | 即利用可 | managed-agents-2026-04-01 |
| Dreaming | Research preview | API / Console | 申請制(Request access フォーム) | managed-agents-2026-04-01 |
| Outcomes | Research preview | API / Console | 申請制(同フォーム) | managed-agents-2026-04-01 |
| Multi-Agent Orchestration | Research preview | API / Console | 申請制(同フォーム) | managed-agents-2026-04-01 |
公式ドキュメント(platform.claude.com/docs/en/managed-agents/overview)の該当箇所を直接引用する。
“Claude Managed Agents is currently in beta. All Managed Agents endpoints require the
managed-agents-2026-04-01beta header.” “Access to Claude Managed Agents (enabled by default for all API accounts).” “Certain features (outcomes and multiagent) are in research preview. Request access to try them.”
つまり整理すると:
- API アカウントを持っていれば即使えるもの — Managed Agents 本体、Memory
- 追加で申請(Request access)が必要なもの — Dreaming、Outcomes、Multi-Agent Orchestration
Claude Pro / Max / Team サブスクでは使えない
ここが日本のユーザーにとって最も重要なポイントだ。Claude.ai の Pro/Max/Team/Enterprise サブスクでは Managed Agents は利用できない。Pro契約をしていても、Managed Agents API を叩くには別途 Anthropic API(Console)のアカウントを開設し、API キーを発行する必要がある。
この設計は Claude Code(コンシューマプラン側で動く)と対照的で、混同しやすい。違いを整理すると:
| プラットフォーム | 契約 | 提供機能 | 課金 |
|---|---|---|---|
| Claude.ai 系(Pro/Max/Team/Enterprise) | コンシューマサブスク | Claude Code、Claude Web、Routines、Skills、Code Review (Team/Ent) | サブスク定額 + extra usage |
| Anthropic API(Console) | API アカウント | Messages API、Managed Agents、Files API、Batch API | トークン従量 + Managed Agents は別途 $0.08/session-hour |
「Pro契約していれば Dreaming も使える」という誤解はよく見るが、両者は完全に別契約系統で、料金体系も別だ。Managed Agents を使うには Console(console.anthropic.com)でアカウントを作り、API キーを発行する必要がある。
Dreaming / Outcomes / Multi-Agent の申請フロー
Research preview の3機能(Dreaming・Outcomes・Multi-Agent Orchestration)は、API アカウントを持っているだけでは使えない。claude.com/form/claude-managed-agents のフォームから access request を出す必要がある。フォームでは以下を聞かれる(2026年5月時点):
- ユースケース(何を作るか・なぜ research preview 機能が必要か)
- 想定セッション数・月間予算
- 連絡先(メール・所属)
承認には数日〜数週間かかると報告されている。申請が通るまでは、Managed Agents 本体 + Memory で先に PoC を組み、Dreaming/Outcomes/Multi-Agent は承認後に組み合わせる、という段階的な開発が現実的だ。
課金体系
Managed Agents は通常の API トークン課金に加え、セッション実行時間のランタイム課金が別途発生する。
- API トークン: 入力・出力ともに通常レート(Claude Sonnet/Opus の token pricing と同じ)
- セッションランタイム: $0.08/session-hour(コンテナ実行コスト)
- Batch API ディスカウントは適用されない(Managed Agents は対話型ワークロード前提)
- Memory ストアの永続化コスト: 別途ストレージ料金(プレビュー期間中は無料の可能性あり、要確認)
例えば1セッション平均30分の Outcomes ワークフローを1日10回回すと、ランタイム課金だけで月 $12(10回 × 30日 × 0.5h × $0.08)。これに API トークンが上乗せされる。Dreaming のように長時間動くジョブは $0.08/h が積み重なるので、夜間バッチで何時間も走らせる設計は要監視だ。
ZDR(Zero Data Retention)との関係
Anthropic の Zero Data Retention 契約を結んでいる組織でも、Managed Agents 本体・Memory は利用可能(公式ドキュメントに ZDR 不可の明記なし)。ただし Claude Code 側の Code Review は ZDR 有効化組織では使えないと明記されているので、ZDRを使う大企業ユーザーは Managed Agents で代替するのが現実的な選択肢になる。
まとめると
- すぐ試したい人 — Console で API キー発行 → Managed Agents(本体 + Memory)を
managed-agents-2026-04-01ベータヘッダー付きで叩く - Dreaming/Outcomes/Multi-Agent を試したい人 — 上記 + Request access フォーム で申請
- Pro/Max/Team サブスクしか持っていない人 — 別途 Console アカウントが必要。Routines(Claude Code側)と混同しないこと
- ZDR を使っている組織 — Code Review は使えないが Managed Agents は使えるので、PR レビュー自動化は Managed Agents 側で組むのが筋
まとめ
1. Code with Claude SF(5/6)で Managed Agents に Dreaming/Outcomes/Multi-Agent Orchestration が追加され、Memory が public beta に昇格
2. 数値根拠:Outcomes で +最大10pt(pptx +10.1% / docx +8.4%)、楽天 Memory 本番運用で −97%エラー / −27%コスト / −34%レイテンシ
3. Dreaming は API レベルで非常に丁寧な設計(input不変・別outputストア・部分結果保存・SSEで可観測)。「夜間に自己改善するエージェント」が現実に運用可能になった
関連記事: AIエージェントフレームワーク完全比較2026|LangGraph/CrewAI/AutoGen他 / Code with Claude 2026速報|新モデルなし、全製品一気に強化 / Claude Managed Agents発表(4月):エージェントの構築からデプロイまでをAnthropicがホスティング
参照ソース
- New in Claude Managed Agents: dreaming, outcomes, and multiagent orchestration(Anthropic公式ブログ)
- Built-in memory for Claude Managed Agents(Anthropic公式ブログ)
- Dreams — Claude API Docs(一次仕様)
- Claude Managed Agents overview — Claude API Docs
- Anthropic will let its managed agents dream(The New Stack)
- New in Claude Managed Agents(SD Times)
- Live blog: Code w/ Claude 2026(Simon Willison)
- Rakuten Q&A — Customer Story
この記事はAI業界の最新動向を速報でお届けする「AI Heartland ニュース」です。