RAG(検索拡張生成)
ベクトルDB・セマンティック検索・RAGフレームワークを用途別に整理。
21件のツール・リソース
RAG(Retrieval-Augmented Generation)は、LLMに外部データの検索結果を組み合わせて回答精度を高める手法。ベクトルDB・チャンク分割・リランキングを適切に設計すれば、社内文書や最新情報に基づく高精度な回答システムを構築できる。ハルシネーション抑制の切り札としても注目されている。
検索精度
ベクトル検索・ハイブリッド検索・リランキング対応
データ規模
数百件からbillion規模までスケーラブル
対応形式
PDF・HTML・Markdown・Office文書など多形式
データ鮮度
リアルタイム更新・定期再インデックス対応
ベクトルDB・インデックス
ベクトル検索エンジン・インデックス管理・スケーリング
ベクトルデータベース比較2026|Qdrant・Milvus・pgvectorをRAG用途で選ぶ完全ガイド
ベクトルデータベースをRAG用途で比較。Qdrant・Milvus・pgvector・Weaviate・Chromaの5本をランキング形式で評価し、性能・ライセンス・運用コストの違いと選び方を2026年最新版で解説。Postgres利用中はpgvector、専用DBならQdrantが基準になる。

LlamaCloud Demo:LLM向けデータインデックスの実装リポジトリ
LlamaIndexが提供するLlamaCloudのデモ実装。451のスター獲得。ドキュメント解析とベクトル検索の統合例を学び、実装に活用。LlamaCloud Demoとは:LlamaIndexエコシステムのRAG実装集 run-llama/llamacloud-demoは、LlamaIndexが提供するLlam…
RAGフレームワーク
RAGパイプライン構築・オーケストレーション・評価
ベクトルデータベース比較2026|Qdrant・Milvus・pgvectorをRAG用途で選ぶ完全ガイド
ベクトルデータベースをRAG用途で比較。Qdrant・Milvus・pgvector・Weaviate・Chromaの5本をランキング形式で評価し、性能・ライセンス・運用コストの違いと選び方を2026年最新版で解説。Postgres利用中はpgvector、専用DBならQdrantが基準になる。
liteparse|LlamaIndex製RustドキュメントパーサがRAG前処理の速度ボトルネックを解く
liteparseはLlamaIndexチームがRustで書き直したローカル実行のドキュメントパーサ。v2.0のグリッド射影でPDFを最大100倍高速に解析し、RAG前処理の速度ボトルネックを解く。markitdown・Docling・PyMuPDFとの違い、Python実装、落とし穴まで一次ソースで整理する。

officeParser入門:Node.jsでdocx・xlsx・pptxをAST解析してRAGパイプラインに組み込む
officeParserはNode.js/ブラウザ対応のドキュメント解析OSSで週23万DL・v6.1.0に進化。docx・xlsx・pptx・PDF・RTFをAST出力し、OCRやメタデータ抽出もサポート。RAGパイプラインへの組み込み方を解説。
LightRAG|知識グラフ×デュアルレベル検索でRAGの精度と網羅性を高める仕組み
LightRAGは知識グラフとデュアルレベル検索を組み合わせたOSS RAGフレームワーク。GitHubスター33k超、EMNLP2025採択。PostgreSQL・Neo4j対応、Web UI・REST API・Docker完備。導入から運用まで解説

Onyx AIとは?企業向けRAGチャットボットの使い方・導入手順・Docker構築ガイド
Onyx AIとは、22,000スター超のOSS企業向けRAGチャットボット。社内ドキュメントをAIが自動検索・回答。Onyx AIの使い方・Docker Composeセットアップ・コネクタ設定・セルフホスティング導入手順を完全解説します。
RAGapp:LLMにドキュメントを読ませるOSSプラットフォーム
PDFやテキストをアップロードして、LLMに質問できるRAGシステム。Python+FastAPIで構築され、Docker対応。自分たちの知識ベースでAIを動かしたい開発チーム向け。

Wax:Apple Silicon最適化のシングルファイルAIメモリレイヤー、サブミリ秒RAG対応
WaxはSwift製のシングルファイルAIエージェント用メモリレイヤー。Apple SiliconのMetal最適化でサブミリ秒のRAGを実現。サーバー不要・API不要・1ファイルで完結するオンデバイス設計。
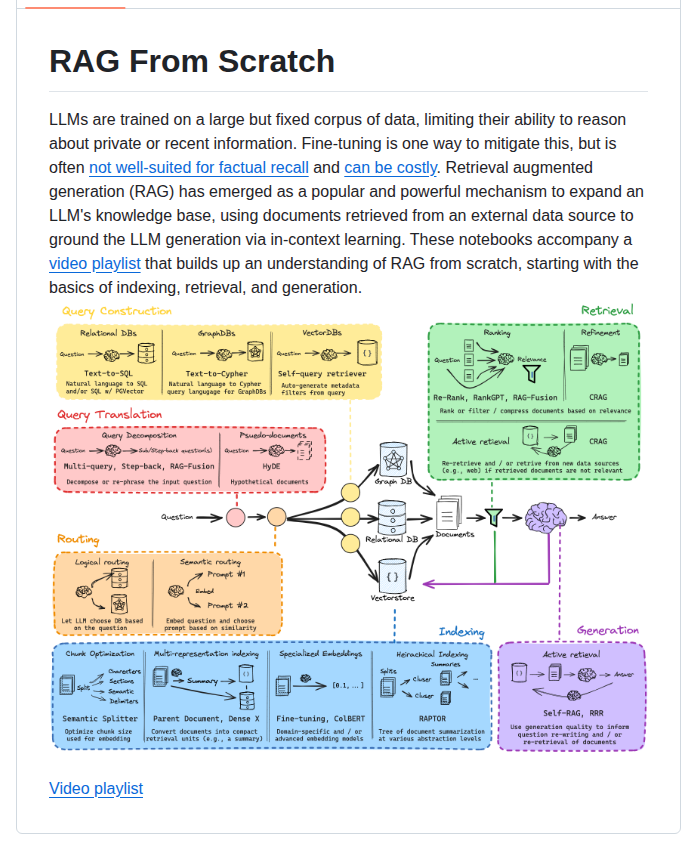
Langchain RAG From Scratch:ゼロからRAGシステムを構築
Langchainの公式教材でRAG(Retrieval-Augmented Generation)の仕組みを基礎から習得。ベクトル検索・プロンプト最適化・チャンク戦略を実装。
RAGFlow|エンタープライズRAGエンジンの導入と使い方 — DeepDoc・ナレッジベース構築
RAGFlowはGitHub7.8万スターのオープンソースRAGエンジン。高精度文書解析・GraphRAG・エージェント・MCP対応をDockerで即デプロイ。エンタープライズRAG構築の決定版。
LangChainの使い方|日本語入門 — LLMエージェント・RAG・チェーン構築をPythonで実践
LangChainはLLMを活用したエージェント開発・RAG構築を簡単にするPythonフレームワーク。プロンプト管理・メモリ機構・外部ツール統合が標準搭載。OpenAI/Claude/Llamaに対応。使い方を日本語で解説。
ドキュメント処理
文書パース・チャンク分割・エンベディング生成
liteparse|LlamaIndex製RustドキュメントパーサがRAG前処理の速度ボトルネックを解く
liteparseはLlamaIndexチームがRustで書き直したローカル実行のドキュメントパーサ。v2.0のグリッド射影でPDFを最大100倍高速に解析し、RAG前処理の速度ボトルネックを解く。markitdown・Docling・PyMuPDFとの違い、Python実装、落とし穴まで一次ソースで整理する。
RAGapp:LLMにドキュメントを読ませるOSSプラットフォーム
PDFやテキストをアップロードして、LLMに質問できるRAGシステム。Python+FastAPIで構築され、Docker対応。自分たちの知識ベースでAIを動かしたい開発チーム向け。
Onyx導入ガイド:企業向け社内ドキュメントAI検索基盤をDocker Composeで構築・運用する
企業向けRAG基盤Onyxの導入手順を完全解説。Docker Composeセットアップ、Slack・Confluenceコネクタ設定、Python API活用、運用チューニングまで網羅。社内ドキュメントAI検索を自前サーバーで構築したいチームは必見
RevPDF──OSSのPDF編集ツールでテキスト修正からページ操作まで完結させる
RevPDFはテキスト編集・ページ操作・注釈追加をローカルで完結させるOSS PDF編集ツール。有料サービス不要でPDF加工の全工程をカバーする方法を解説。PDF編集に毎月課金し続ける必要はあるか Adobe Acrobatの月額プラン、あるいはオンラインPDF編集サービスへのアップロード。どちらもPDFを数文字直…
MinerU|PDFをマークダウンに変換するOSSツール — 表・数式・レイアウトを高精度抽出
MinerUは複雑なPDFをLLM対応のMarkdown/JSONに変換するオープンソースツール。OCR・レイアウト解析・数式認識に対応し、RAGやAIワークフローへのデータ投入に最適。
用途別おすすめ
RAGを初めて試す → LlamaIndexやLangChainのRAGテンプレートから始めるのが最短。ローカルのベクトルDB(Chroma等)と組み合わせれば数十分で動作する。
社内文書検索システムを構築したい → 「ドキュメント処理」セクションで文書パースを、「ベクトルDB・インデックス」で検索基盤を選定。
RAGの精度が出ない → チャンク分割の見直し、リランキングの導入、ハイブリッド検索への移行を「RAGフレームワーク」セクションで検討。
大規模データでRAGを運用したい → マネージドベクトルDB(Pinecone・Qdrant Cloud等)と、増分インデックス更新の仕組みを構築。
すべてのツール
新着順に全21件を表示
ベクトルデータベース比較2026|Qdrant・Milvus・pgvectorをRAG用途で選ぶ完全ガイド
ベクトルデータベースをRAG用途で比較。Qdrant・Milvus・pgvector・Weaviate・Chromaの5本をランキング形式で評価し、性能・ライセンス・運用コストの違いと選び方を2026年最新版で解説。Postgres利用中はpgvector、専用DBならQdrantが基準になる。
supermemory入門|AI時代のMemory APIをmem0・cognee・Lettaと比較で読み解く
supermemoryはアプリにAI記憶層を組み込むMemory API。約25,140★・MIT・TypeScriptで、SaaSとセルフホストの両対応。mem0・cognee・Letta(MemGPT)との違い、API設計、ローカル実行、料金、落とし穴まで一次ソースで整理する。
liteparse|LlamaIndex製RustドキュメントパーサがRAG前処理の速度ボトルネックを解く
liteparseはLlamaIndexチームがRustで書き直したローカル実行のドキュメントパーサ。v2.0のグリッド射影でPDFを最大100倍高速に解析し、RAG前処理の速度ボトルネックを解く。markitdown・Docling・PyMuPDFとの違い、Python実装、落とし穴まで一次ソースで整理する。

Google LangExtract完全ガイド:LLMで非構造テキストから構造化抽出、ソース位置も追跡
Googleの最新OSS「LangExtract」は、LLMで非構造テキストから構造化データを抽出。ソース位置追跡・対話型HTML可視化・Gemini/OpenAI/Ollama対応で、医療・文学・多言語領域に対応。コード例付きで完全解説。
officeParser入門:Node.jsでdocx・xlsx・pptxをAST解析してRAGパイプラインに組み込む
officeParserはNode.js/ブラウザ対応のドキュメント解析OSSで週23万DL・v6.1.0に進化。docx・xlsx・pptx・PDF・RTFをAST出力し、OCRやメタデータ抽出もサポート。RAGパイプラインへの組み込み方を解説。
LightRAG|知識グラフ×デュアルレベル検索でRAGの精度と網羅性を高める仕組み
LightRAGは知識グラフとデュアルレベル検索を組み合わせたOSS RAGフレームワーク。GitHubスター33k超、EMNLP2025採択。PostgreSQL・Neo4j対応、Web UI・REST API・Docker完備。導入から運用まで解説
Dify ファイルアップロードが「キューイング中」で止まる原因3つと解決策【大量ファイルのリセット対応】
Difyのナレッジベースでファイルアップロードが「キューイング中」のまま止まる原因をCelery Worker設定・Embedding APIレート制限・大量ファイル同時処理の3軸で解説。docker-compose設定とKnowledge APIによる解決手順を網羅
Onyx AIとは?企業向けRAGチャットボットの使い方・導入手順・Docker構築ガイド
Onyx AIとは、22,000スター超のOSS企業向けRAGチャットボット。社内ドキュメントをAIが自動検索・回答。Onyx AIの使い方・Docker Composeセットアップ・コネクタ設定・セルフホスティング導入手順を完全解説します。
LlamaCloud Demo:LLM向けデータインデックスの実装リポジトリ
LlamaIndexが提供するLlamaCloudのデモ実装。451のスター獲得。ドキュメント解析とベクトル検索の統合例を学び、実装に活用。LlamaCloud Demoとは:LlamaIndexエコシステムのRAG実装集 run-llama/llamacloud-demoは、LlamaIndexが提供するLlam…
RAGapp:LLMにドキュメントを読ませるOSSプラットフォーム
PDFやテキストをアップロードして、LLMに質問できるRAGシステム。Python+FastAPIで構築され、Docker対応。自分たちの知識ベースでAIを動かしたい開発チーム向け。
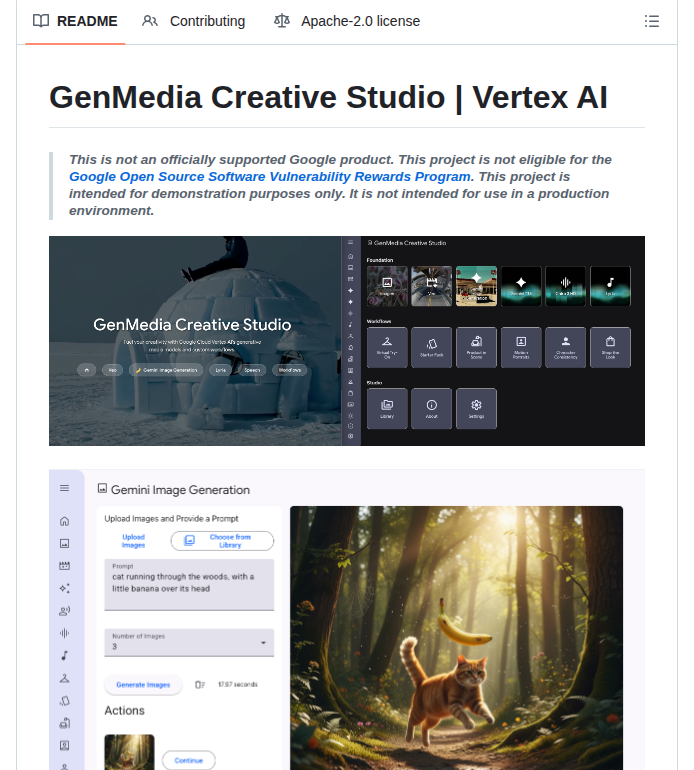
Vertex AI Creative Studio:Googleの生成AIで動画・画像・テキスト制作を一元化
GoogleCloudPlatformが提供するVertex AI Creative Studioは、生成AIを活用した動画・画像・テキスト生成を統合プラットフォーム上で実現。マーケティング資産の制作フローを短縮でき、チーム連携も効率化される。公式リポジトリでサンプルコードも公開中。

Rclone:クラウドストレージ間のファイル同期・転送を一元管理するCLIツール
50以上のクラウドストレージに対応し、S3・Google Drive・OneDriveなど異なるプラットフォーム間でファイルを効率的に同期・転送。複数のストレージ管理を統一インターフェースで実現する
Onyx導入ガイド:企業向け社内ドキュメントAI検索基盤をDocker Composeで構築・運用する
企業向けRAG基盤Onyxの導入手順を完全解説。Docker Composeセットアップ、Slack・Confluenceコネクタ設定、Python API活用、運用チューニングまで網羅。社内ドキュメントAI検索を自前サーバーで構築したいチームは必見
RevPDF──OSSのPDF編集ツールでテキスト修正からページ操作まで完結させる
RevPDFはテキスト編集・ページ操作・注釈追加をローカルで完結させるOSS PDF編集ツール。有料サービス不要でPDF加工の全工程をカバーする方法を解説。PDF編集に毎月課金し続ける必要はあるか Adobe Acrobatの月額プラン、あるいはオンラインPDF編集サービスへのアップロード。どちらもPDFを数文字直…
Wax:Apple Silicon最適化のシングルファイルAIメモリレイヤー、サブミリ秒RAG対応
WaxはSwift製のシングルファイルAIエージェント用メモリレイヤー。Apple SiliconのMetal最適化でサブミリ秒のRAGを実現。サーバー不要・API不要・1ファイルで完結するオンデバイス設計。
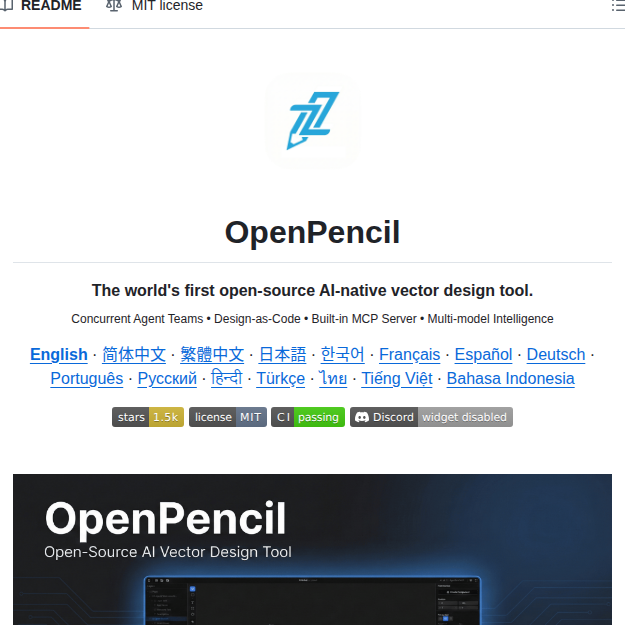
OpenPencil - iPad をワコムペンタブレット化するオープンソースツール
OpenPencilはiPadをMac/Windows対応ペンタブレットに変えるオープンソースツール。8192段階の筆圧感知とUSB/Wi-Fi接続に対応し、高価なワコム製品を買わずにApple Pencilで本格的なデジタル描画環境を構築できます
Langchain RAG From Scratch:ゼロからRAGシステムを構築
Langchainの公式教材でRAG(Retrieval-Augmented Generation)の仕組みを基礎から習得。ベクトル検索・プロンプト最適化・チャンク戦略を実装。
MinerU|PDFをマークダウンに変換するOSSツール — 表・数式・レイアウトを高精度抽出
MinerUは複雑なPDFをLLM対応のMarkdown/JSONに変換するオープンソースツール。OCR・レイアウト解析・数式認識に対応し、RAGやAIワークフローへのデータ投入に最適。
RAGFlow|エンタープライズRAGエンジンの導入と使い方 — DeepDoc・ナレッジベース構築
RAGFlowはGitHub7.8万スターのオープンソースRAGエンジン。高精度文書解析・GraphRAG・エージェント・MCP対応をDockerで即デプロイ。エンタープライズRAG構築の決定版。
LangChainの使い方|日本語入門 — LLMエージェント・RAG・チェーン構築をPythonで実践
LangChainはLLMを活用したエージェント開発・RAG構築を簡単にするPythonフレームワーク。プロンプト管理・メモリ機構・外部ツール統合が標準搭載。OpenAI/Claude/Llamaに対応。使い方を日本語で解説。
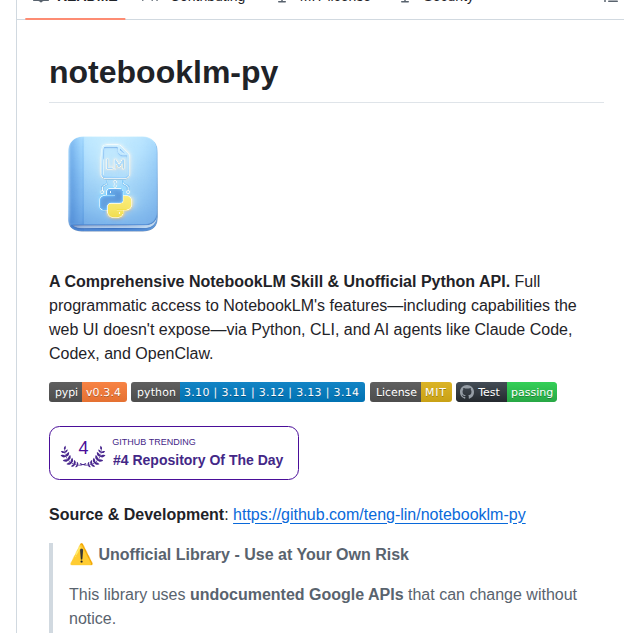
NotebookLMの使い方+Python API自動化|notebooklm-pyで一括処理・音声生成まで
NotebookLMの使い方をPython API自動化の視点で解説。notebooklm-pyでPDF一括取り込み・音声ポッドキャスト生成・クイズJSON出力をコードから自動化。Web UIではできない一括処理とパイプライン構築の実践例。10.4kスター獲得のOSS。
よくある質問
RAG(検索拡張生成)とは?
RAG(Retrieval-Augmented Generation)はLLMに外部データの検索結果を付加して回答を生成する手法。社内文書・最新ニュース・専門データベースなど、LLMの訓練データにない情報を活用できる。ハルシネーション(幻覚)の抑制にも効果的。
ベクトルDBの選び方は?
データ規模・検索速度・運用コストで選ぶ。小規模ならChromaやFAISS(ローカル実行)、中〜大規模ならPinecone・Weaviate・Qdrant(マネージド/セルフホスト)が定番。フィルタリング・メタデータ検索の要件も確認する。
RAGの精度を改善するには?
チャンク分割の最適化、リランキング(Reranker)の導入、ハイブリッド検索(ベクトル+キーワード)の併用が基本。さらにクエリ変換・HyDE・親子チャンク構造などの高度なテクニックで精度を向上できる。
エンタープライズRAGに必要な要素は?
アクセス制御(ドキュメント単位の権限管理)、監査ログ、データ鮮度管理(定期的な再インデックス)、マルチテナント対応が必須。加えてソース引用の正確性とハルシネーション検知の仕組みも重要。
RAGとLLMのfine-tuningの違いは?
RAGは外部データを検索して回答に反映する手法で、データの更新が即座に反映される。fine-tuningはモデル自体を再訓練する手法で、文体やフォーマットの変更に向く。最新情報への対応ならRAG、特定タスクの品質向上ならfine-tuningが適切。両方を組み合わせることも多い。