
「動画を理解させたいだけなのに、要約ツール・編集ツール・字幕ツール・翻訳ツールを別々に使い分けて、出力を手で繋いでいる」——AIで動画を扱おうとすると、すぐにこの“ツールのつぎはぎ”地獄に突き当たります。理解は理解、編集は編集と道具が分かれているせいで、少し凝ったことをしようとすると、人間が手順を設計してパイプラインを組む羽目になるのです。
その断絶を、1つの自律エージェントで埋めにきたのが、香港大学データインテリジェンス研究室(HKUDS)の VideoAgent(HKUDS/VideoAgent) です。掲げるのは「動画の理解・編集・リメイクを、自然言語の指示ひとつで完結させる」こと。本記事では、このオールインワン動画エージェントが何者で、どう動き、既存ツールと何が違うのかを、AI開発者の視点で読み解きます。

本サイトはAI関連OSSの解説に特化しているため、本稿では「このエージェントで結局、何ができる/何の手間が解ける/何の代わりになるのか」という観点で整理します。記述は公式README・arXiv論文の記載に基づき、確定情報と一般的な解釈を区別します。VideoAgentは研究プロジェクト由来のため、実運用に載せる前提というより、まず「動画AIをエージェント化するとは何か」を学ぶ素材として読むと、得るものが多いはずです。
- ・VideoAgentは動画の理解・編集・リメイクを1基盤に統合するマルチモーダル・エージェント(HKUDS製)。
- ・中核は意図分析・自律ツール計画(グラフ)・マルチモーダル理解の3技術。Claudeがグラフ・ルーターを駆動。
- ・ミーム/MV/解説/クロストーク/多言語リメイクまで、自然言語の指示1つで生成できる。
- ・グラフ計画+二段階の自己評価で、ワークフロー構築成功率0.95(論文)。反復ほど品質が上がる。
- ・動作にはGPU 8GB+複数モデルDL+各社APIキーが必要。素材の権利確認は利用者責任。
1. VideoAgentとは — 動画理解・編集・リメイクのオールインワン
VideoAgentは、HKUDSが公開した 「包括的な動画インテリジェンス」 を掲げるエージェント基盤です。キャッチコピーは “An All-in-One Framework for Understanding, Editing, and Generation”——すなわち 理解・編集・生成(リメイク)を1つにまとめる ことを正面から狙っています。
従来、動画まわりのAIツールは「1つの機能に特化」しているのが普通でした。動画を要約するツール、切り抜くツール、字幕を付けるツール、翻訳するツール——それぞれは優秀でも、横断的な作業をしようとすると、人間がそれらを繋ぐ“接着剤”にならざるを得ません。VideoAgentの発想は逆で、ユーザーは「何をしたいか」を自然言語で伝えるだけ、ツールの選択と手順の設計はエージェントが引き受ける、というものです。
ここで読者が探している「①結局何ができる/②何を解決する/③何を代替する」に当てはめると——① 自然言語の指示から、動画の理解・編集・リメイクを自動で実行できる。② ツールを使い分け、手順を組み立てる“人間オーケストレーター”の手間を解消する。③ 個別の動画ツール群(編集・要約・翻訳・リメイク)を、1つのエージェント基盤で代替し得る——という整理になります。
技術的な土台として重要なのは、VideoAgentが 複数のLLMを役割分担で使う 点です。READMEの設定例では、エージェントのグラフ・ルーター(どのツールをどう繋ぐかを決める司令塔)に Claude が必須とされ、動画リミックスやTTSにDeepSeek、編集・要約・QAにGPT、キャプション生成にGeminiを割り当てます。つまりVideoAgentは「単一の万能モデル」に頼るのではなく、各工程に向いたモデルをオーケストレーションする設計思想を採っています。論文では、Claude 3.7をバックボーンにした場合に、GPT-4oやDeepSeek-v3より安定して高い創造的性能を示したと報告されています。
この「モデルの役割分担」は、AIエージェント設計の観点でも示唆的です。動画という重いタスクを、単一モデルに丸投げするのではなく、「計画は推論に強いモデル、生成は各専用モデル、理解はマルチモーダルモデル」と分業させる——これは、コストと品質を両立させる現実的なアーキテクチャです。司令塔(グラフ・ルーター)に推論能力の高いClaudeを据えるのは、ワークフロー構築という“間違えると全体が崩れる”工程を最も賢いモデルに任せる、という合理的な判断といえます。本サイトで扱ってきたエージェント設計の文脈に引き付ければ、VideoAgentは「司令塔モデル+専用ツール群」という、いまどきのエージェント・アーキテクチャを、動画ドメインで具体化した好例です。
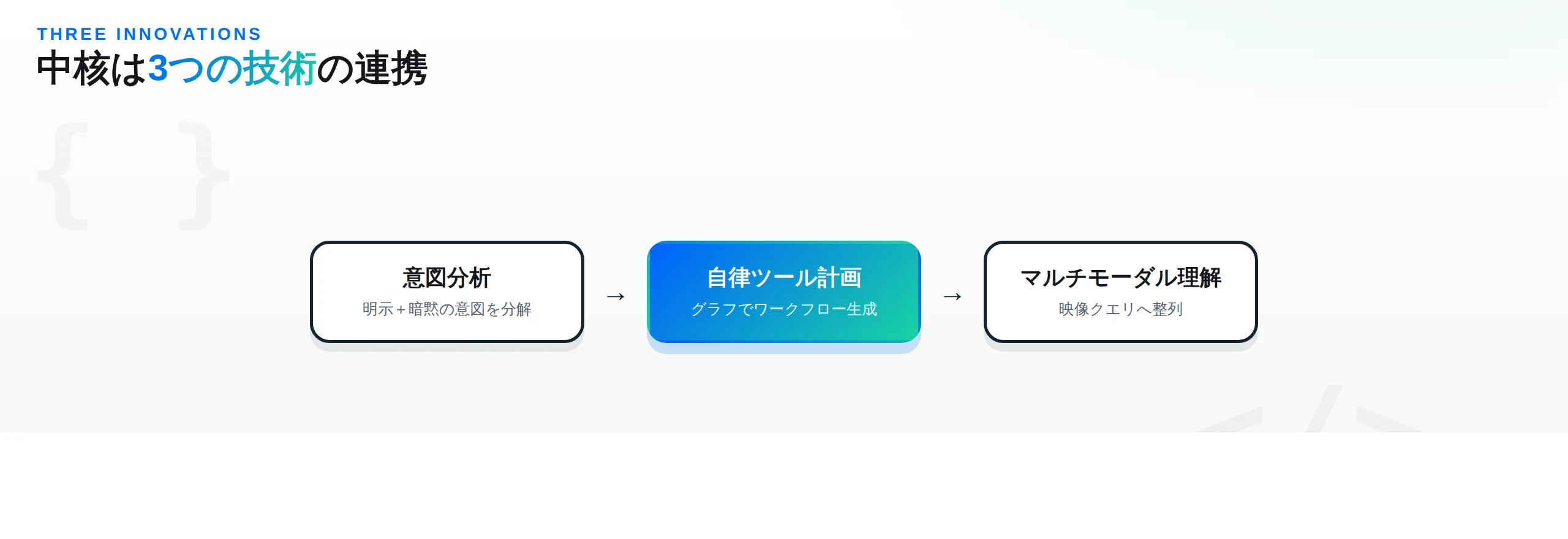
2. 3つの中核技術 — 意図分析・グラフ計画・マルチモーダル理解
VideoAgentの“賢さ”は、3つの中核技術の連携から生まれます。順に見ていきましょう。
① 意図分析(Intent Analysis)。VideoAgentはまず、ユーザーの指示を 明示的な意図と暗黙の意図(サブ意図) に分解します。たとえば「この英語のスタンドアップを中国の漫才っぽくして」という依頼には、「言語を変える」という明示的要求の裏に、「文化的な間(ま)や掛け合いの呼吸を再現する」といった言葉にされない狙いが潜んでいます。意図分析は、こうした表層の指示を超えた要求まで汲み取り、意図とエージェント能力の対応づけ(intent-to-agent mapping) によって、必要な機能だけを的確に起動します。無駄な処理を避け、最適なタスク実行につなげる仕組みです。
② 自律的ツール使用と計画(Autonomous Tool Use & Planning)。ここがVideoAgentの心臓部です。グラフ駆動のフレームワーク が、ユーザーの意図を 実行可能なワークフロー へ自動変換します。ノードがツールの能力を、エッジがワークフローのつながりを表し、複雑な動画タスクに対して最適な実行順序を動的に構築します。さらに 二段階の自己評価(two-step self-evaluation) による適応的フィードバックループで、計画を継続的に精緻化。システムが自己修正しながら、タスク全体を通じて性能を最適化していきます。
この「自律ツール計画」の流れは、図にすると直感的に理解できます。
明示+暗黙の意図に分解"] INTENT --> MAP["意図→エージェント能力の対応づけ"] MAP --> GRAPH["グラフでワークフロー生成
ノード=ツール / エッジ=つながり"] GRAPH --> EXEC["ツールを順に実行"] EXEC --> EVAL{"二段階の自己評価
品質は十分?"} EVAL -->|"不足"| GRAPH EVAL -->|"OK"| OUT["動画を出力"]
③ マルチモーダル理解(Multi-Modal Understanding)。ストーリーボード・エージェント が、生のユーザー入力を 最適化された視覚クエリ に変換します。まず事前にキャプション付けされた素材バンクを分析して「使える素材は何か」を把握し、次にユーザー入力を 視覚的にも意味的にも整列した細粒度のサブクエリ に分解。これにより、ユーザーの意図と最も関連する映像コンテンツを精度よく検索(retrieval)できます。論文の評価では、シャッフルしたキャプションで動画クリップを正しく並べ直すRecallなど複数指標で、正確な映像セグメント検索が示されています。
図のループ構造に注目してください。自己評価で「品質が不足」と判断されれば、ワークフロー生成に戻ってやり直す——この 失敗を許容し、自分で立て直す 仕組みこそが、一発勝負の生成パイプラインとエージェントの決定的な違いです。人間の編集者が「この繋ぎは違うな」と気づいて編集をやり直すのと同じことを、VideoAgentは自己評価フィードバックで実現しています。
3つを通して見ると、VideoAgentは「意図を読む → 計画を立てて自己修正する → 映像を意味で扱う」という、人間の編集者に近い思考プロセスを、エージェントとして実装していることが分かります。
3. 何ができるのか — ミーム・MV・解説・多言語リメイク
抽象論だけでは掴みにくいので、具体的に何を作れるのか を見ましょう。READMEが挙げる用途は、想像以上に幅広いものです。

・映画の切り抜き編集(Movie Edits):長い映像から見せ場を抜き、ビートに同期させて編集する
・ミーム動画(Meme Videos):素材を再構成し、ネットミーム的な再制作を行う
・AI音楽動画(Music Videos):歌声合成・歌声変換(SVC)を使ったMVを生成する
・解説・コメンタリー動画(Commentary):ナレーションを付けた解説動画を組み立てる
・クロストーク/スタンドアップ変換:英語スタンドアップを中国漫才へ、またはその逆へと言語・文化を跨いでリメイク
・動画Q&A・要約(Video QA/Summarization):動画の内容に答える・要約する
これらを支えるのが、用途別に必要となるモデル群です。READMEの対応表では、クロストーク/トークショーにはCosyVoice・Whisper・ImageBind、ミームのTTSにはfish-speech、MV(SVC)にはDiffSinger・seed-vc・Whisper・ImageBind、リズム編集にはWhisper・ImageBind、動画QA・要約にはWhisper、と機能ごとに使うモデルが整理されています。必要な機能のモデルだけ入れればよい 設計なので、たとえば「動画要約だけ試したい」ならWhisperだけで始められます。
ここで強調したいのは、VideoAgentが 「理解」と「生成」を地続きにしている ことです。動画を理解するだけ、生成するだけのツールは多くありますが、VideoAgentは「内容を理解したうえで、その理解に基づいて編集・リメイクする」という一連の流れを、同じエージェント基盤で扱います。たとえば「この動画の面白い部分を理解して、ミーム化して」という依頼は、理解(どこが面白いか)と生成(ミーム化)の両方を必要としますが、VideoAgentならこれを1つの指示として投げられます。これこそが「オールインワン」の実利です。
注目したいのは、これらの用途の多くが 「言語・文化を越える」リメイク を含むことです。英語スタンドアップを中国漫才へ、あるいはその逆へ——という変換は、単なる字幕翻訳ではありません。話者の声質を保ったまま(seed-vcの歌声・声質変換)、間(ま)や掛け合いの呼吸(意図分析が汲む暗黙の意図)まで再構成する必要があります。VideoAgentがこれを射程に入れているのは、動画コンテンツのグローバル展開 という実需に直結します。日本語コンテンツを他言語圏へ、あるいは海外コンテンツを日本向けに作り替える——そうした“ローカライズを越えたリメイク”を自動化する基盤として捉えると、VideoAgentの価値はより鮮明になります。
4. 既存ツールとの違い — 単機能ツールから自律エージェントへ
VideoAgentの立ち位置を、既存ツールとの比較で明確にしておきましょう。READMEには、Director・Funclip・NarratoAI・NotebookLMとの機能比較表が掲載されています。

| 機能 | VideoAgent | Director | Funclip | NotebookLM |
|---|---|---|---|---|
| ビート同期編集 | ✅ | ✅ | ✅ | — |
| ストーリー動画 | ✅ | — | — | — |
| 動画概要(Overview) | ✅ | ✅ | ✅ | ✅ |
| ミーム動画リメイク | ✅ | — | — | — |
| 歌のリミックス | ✅ | — | — | — |
| 多言語アダプテーション | ✅ | — | — | — |
| 動画Q&A | ✅ | ✅ | — | ✅ |
表から読み取れるのは、動画概要やQ&Aといった「理解」系の機能は既存ツールも持つ一方、ミーム化・歌のリミックス・多言語リメイクといった「リメイク(再制作)」系はVideoAgent独自だという点です。つまりVideoAgentの差別化は、単に機能数が多いことではなく、「理解した内容を、創造的に作り替える」領域まで踏み込んでいることにあります。
そしてもう一つの本質的な違いが、「ツール」か「エージェント」かです。Director等は優れた“道具”ですが、何をどう作るかは人間が決めて操作します。VideoAgentは“自律エージェント”として、意図分析からワークフロー構築までを自分で行います。論文では、この自律的なワークフロー構築の 成功率が全構成で0.95 に達し、さらに 反復(reflection)の回数を増やすほど性能が向上 する自己改善能力が報告されています。「使うほど・考えるほど良くなる」のは、固定的なツールにはない、エージェントならではの性質です。
ただし、この自律性は万能ではありません。複雑な指示ほど意図分析の精度が結果を左右し、使うLLMのバックボーン次第で創造性に揺らぎが出ることも論文は示しています。「賢い道具」ではなく「育てる協働者」 として捉えると、VideoAgentの強みと限界の両方が見えてきます。
5. セットアップと使い方 — 必要なモデルとAPIキー
実際に動かす流れを、READMEに沿って確認します。VideoAgentは研究由来のフレームワークらしく、セットアップはやや重め です。

環境要件 は、GPUメモリ8GB、OSはLinux/Windows。まずリポジトリをクローンし、conda環境を作って、ffmpegやpynini等を導入し、依存をpipで入れます。
git clone https://github.com/HKUDS/VideoAgent.git
conda create --name videoagent python=3.10
conda activate videoagent
conda install -y -c conda-forge pynini==2.1.5 ffmpeg
pip install -r requirements.txt
次に モデルのダウンロード。用途に応じて、CosyVoice・fish-speech・seed-vc・DiffSinger・Whisper(large-v3-turbo)・ImageBindなどをHugging Face等から取得します。READMEは「複数モデルが用意されているが、プロジェクトに関係するものだけ落とせばよい」と明記しているので、全部入れる必要はありません。たとえばWhisperはこのように取得します。
cd tools
huggingface-cli download openai/whisper-large-v3-turbo --local-dir whisper-large-v3-turbo
最後に LLMの設定。設定ファイル(config.yml)に各社のAPIキーを記述します。コメントにもある通り、エージェントのグラフ・ルーターを担うClaudeが必須 で、用途別にDeepSeek・GPT・Geminiを割り当てます。
llm:
# Video Remixing/TTS/SVC/Stand-up/CrossTalk
deepseek_api_key: ""
# Agentic Graph Router/TTS/SVC/Stand-up/CrossTalk(Claudeが司令塔)
claude_api_key: ""
# Video Editing/Overview/Summarization/QA/Commentary Video
gpt_api_key: ""
# MLLM for caption and fine-grained video understanding
gemini_api_key: ""
設定が済めば、あとは python main.py を実行し、コンソールに自然言語で要求を入力するだけです。READMEの例では「既存動画の話者の声を保ったまま台詞を差し替えたい」「スタンドアップの台本を、間(ま)や観客の反応つきの本格的な動画にしたい」といった、かなり高水準の依頼がそのまま投げられています。現在のLLM選択は各機能向けに最適化済みで、必要なら llm.py でモデル名を調整できます。
実務的なアドバイスとしては、最初から全機能を狙わず、使いたい1機能(たとえば動画要約やコメンタリー)に絞ってモデルとキーを揃えるのが、つまずきの少ない始め方です。マルチモデル前提のため、各社APIの利用料が積み上がる点も、検証時から意識しておくとよいでしょう。
6. 使いどころと注意点 — 権利・コスト・品質
最後に、VideoAgentをどう使い、何に気をつけるべきかを整理します。

向くケース:動画の理解・要約を自動化したい、ミーム・MV・解説動画を量産したい、コンテンツを多言語にリメイクして展開したい、研究・検証用に動画生成パイプラインを試したい——こうした「理解から生成までを横断する、創造的な動画タスク」は、VideoAgentの自律性が素直に効く領域です。とくに、これまで複数ツールを手で繋いでいたワークフローを、自然言語の指示1つに置き換えられる点は大きな魅力です。
注意すべき点 は3つあります。第一に権利。READMEも、デモの音声・映像はネット上の素材で研究・実証目的に限る旨を明記しており、第三者の著作物を扱うなら、利用者側で権利確認・許諾が必須です。生成・リメイクした動画を公開・商用利用する場合は、ここが最重要のリスク管理になります。第二にコストと資源。GPU 8GB、複数モデルのダウンロード、各社LLMのAPIキーが前提で、相応のリソースと費用がかかります。第三に品質。出力の質は指示の明確さとモデルに依存し、研究由来のフレームワークである以上、生成物は人手で事実確認・品質チェックする運用が欠かせません。
投資対効果の観点でも、向き不向きははっきりしています。1本の動画を丁寧に作り込む“作品志向”の制作では、人間の編集者の細やかな判断にまだ及ばない場面があるでしょう。一方、「同じフォーマットの動画を、多言語で、大量に」 というスケール志向の制作では、VideoAgentのような自律エージェントが圧倒的に効きます。1本あたりの完成度より、量と展開速度が価値になる領域——ショート動画のチャンネル運用、多言語マーケティング動画、解説コンテンツの量産——こそ、VideoAgentの“自律性×横断性”が報われる土俵です。自分の制作が「作品志向」か「スケール志向」かを見極めることが、導入判断の最初の分かれ道になります。
総じてVideoAgentは、「動画AIの“つぎはぎ”を、自律エージェントで束ねる」という方向性を、研究水準で具体化したプロジェクトです。すぐに業務へ丸ごと載せる、というより、動画エージェントの設計思想(意図分析→グラフ計画→自己評価)を学び、自分のユースケースに合う部分から試す——そんな付き合い方が、今のVideoAgentには最も合っています。グラフ駆動のワークフロー構築や二段階自己評価といった仕組みは、動画に限らず、あらゆるマルチステップ・エージェントの設計に応用できる普遍的なパターンでもあります。
VideoAgent(HKUDS)は、動画の理解・編集・リメイクを1つのエージェント基盤に統合し、自然言語の指示から意図分析→グラフによるワークフロー生成→自己評価による精緻化までを自律実行します。Claudeをグラフ・ルーターに据え、GPT・Gemini・DeepSeekを役割分担。ミーム・MV・解説・多言語リメイクまで横断し、論文ではワークフロー構築成功率0.95、反復ほど性能が上がる自己改善を報告します。一方で動作にはGPU 8GB・複数モデル・各社APIキーが必要で、素材の権利確認は利用者の責任。単機能ツールの使い分けに疲れたなら、「意図を読み、計画し、自己修正する」動画エージェントという次の地平を、まず1機能から覗いてみる価値があります。
まとめ
本記事では、HKUDSの VideoAgent を、動画AIを“ツールのつぎはぎ”から“自律エージェント”へ引き上げる試みとして読み解きました。
要点は3つです。第一に、VideoAgentは動画の理解・編集・リメイクを1基盤に統合し、自然言語の指示1つで完結させることを狙うこと。第二に、その賢さは意図分析・グラフによる自律ツール計画・マルチモーダル理解の3技術の連携から生まれ、Claudeを司令塔に複数モデルをオーケストレーションすること。第三に、ミーム・MV・解説・多言語リメイクまで横断し、論文ではワークフロー構築成功率0.95と自己改善能力を示す一方、GPU・複数モデル・APIキー・権利確認という現実的なハードルもあること。
動画を「理解させる」だけでも「生成させる」だけでもなく、その両方を地続きにエージェントへ委ねる——VideoAgentが見せるのは、動画AIの次の設計図です。まずは使いたい1機能から、その思想に触れてみてください。
参照ソース
・HKUDS/VideoAgent(公式リポジトリ) — 本記事が解説した一次情報(README・設定・対応表)
・VideoAgent arXiv 論文(2606.23327) — 評価(成功率0.95・自己改善)の出典
・VideoRAG(関連OSS・HKUDS) — VideoAgentが謝辞で挙げる関連プロジェクト





