Anthropicの応用AIリサーチチームに所属するAlexander Brickenが、2025年の「Code w/ Claude」カンファレンスで21分のセッションを行った。タイトルは「The thinking lever(思考レバー)」。
このセッションが扱うのは「Claudeに何を考えさせるか」ではなく、「Claudeにどれだけ考えさせるか」という問いだ。推論モデルの台頭以来、開発者にとって最重要の設計判断のひとつになったtest-time compute——Inference時のトークン消費——を、どう制御するか。
本記事では動画の全発言と実演データを日本語で体系化し、Adaptive Thinking・5段階Effort Level・モデル選択とのトレードオフを実践的な粒度で解説する。
Claude Code全体のアーキテクチャについては ハーネスエンジニアリング完全解説 を合わせてご覧ください。

01 Test-time computeとは何か——2つのスケーリング軸
AIモデルの性能向上には2つの異なる軸がある。
ひとつはTrain-time compute——モデルの学習に投じる計算量。パラメータ数を増やし、データを増やし、学習ステップを増やすことで、モデルの基礎知識と推論能力が向上する。
もうひとつがTest-time compute(推論時計算量)——ユーザーの質問に答えるとき、つまりInference時に費やすトークン数だ。これが推論モデルの根幹にある概念で、簡単に言えば「考える時間を増やすと賢くなる」という性質だ。
- 大きいモデルで答える = Train-time computeを増やす
- 長く考えてから答える = Test-time computeを増やす
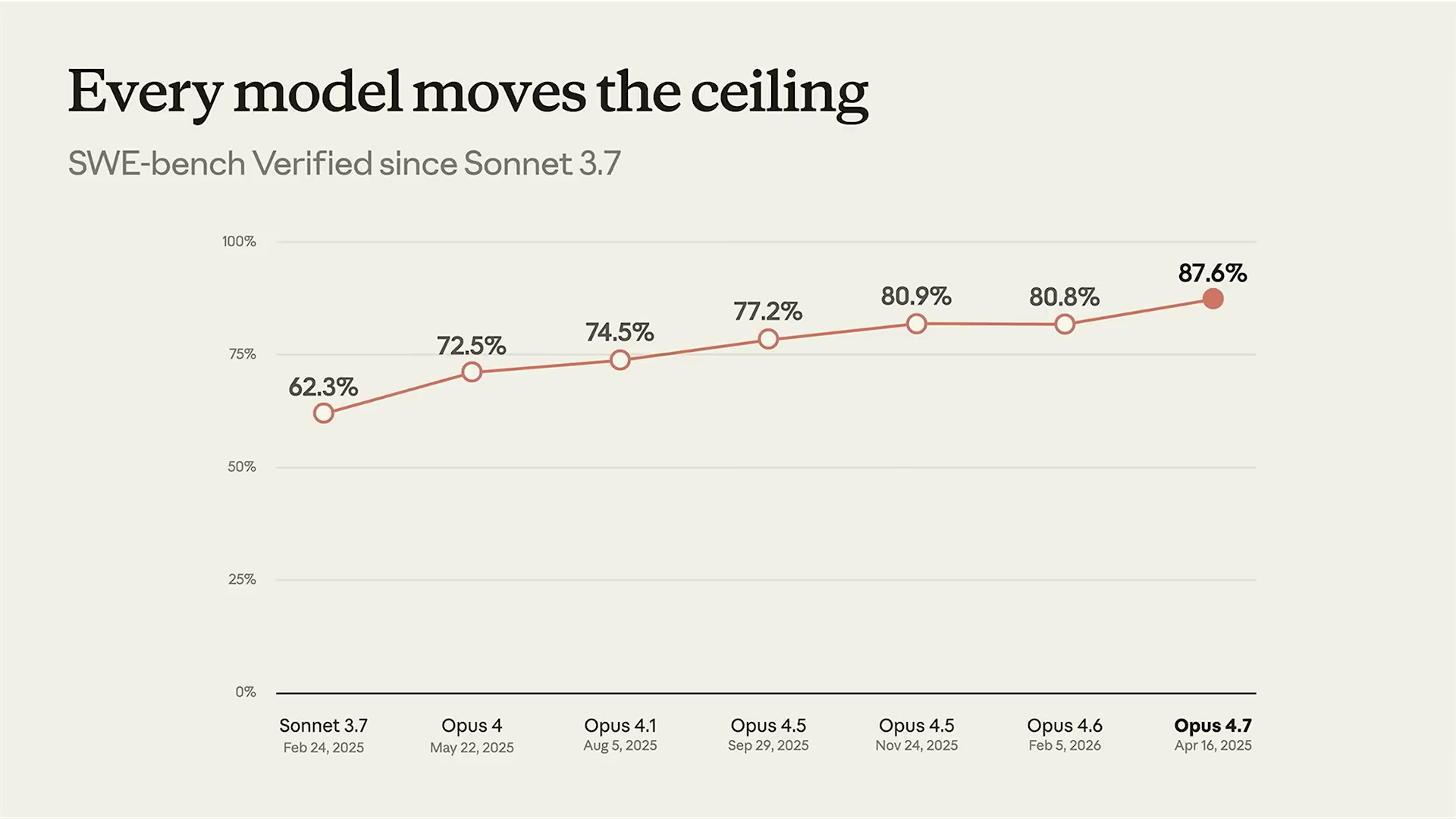
- Anthropicの内部ベンチマーク(エージェントコーディング)では両者の性能上限がほぼ同水準
セッションでBrickenが示したグラフが実態をよく示していた。左図では、Haiku→Sonnet→Opusとモデルサイズが上がるにつれてベンチマークスコアが上昇する。右図(対数軸)では、同じモデルでもトークン消費量が増えるにつれてスコアが上昇する。そしてどちらの軸の最大値も、同じスコア帯に収束する。
この性質は、コーディングに限らない。Brickenは複数のベンチマークで同様の傾向が確認されていると述べた。
- GPQA Diamond(大学院レベルの理科・数学)
- SWE-bench(実際のGitHubバグ修正)
- OSWorld(コンピュータ操作エージェント)
- Humanity’s Last Exam(PhD水準の多分野テスト)
いずれも「より多くのトークンを思考に使うほど精度が上がる」という傾向を示している。つまりeffort levelは単なる速度調整ノブではなく、実質的な知能の調整レバーだ。
02 Test-time computeの3種類——思考・ツール・テキスト
Test-time computeは具体的に何に使われるのか。Brickenは3つのカテゴリに整理した。
- Thinking(思考) — 問題を解く前にClaudeが使うスクラッチパッド。回答候補の検討、矛盾の発見、戦略の立案など
- Tool calling(ツール呼び出し) — 外界とのインターフェース。ウェブ検索、MCP呼び出し、ファイル操作、データベースアクセスなど
- Text(テキスト出力) — ユーザーへの回答。要約、質問、説明文など
このうち、思考(Thinking)こそが「effort level」の主要な調整対象だ。ツール呼び出しとテキスト出力は問題の性質で量が決まるが、思考量はモデルに任せるか開発者が制御するかを選べる。
Test-time computeには直接コストがある——トークン数と処理時間だ。だからこそ「どれだけ考えさせるか」はプロダクト設計の中心的な意思決定になる。
03 実演:トラフィックシミュレーションで見るeffort levelの差
セッションでBrickenが見せたのが、同一プロンプトをLow/High/Max effortで実行した比較だ。プロンプトはシンプルだった。
「一方通行の道路に信号機がある、リアルな交通シミュレーションを作れ」
3つのバージョンを順に見ていく。
Opus 4.7 — Low effort
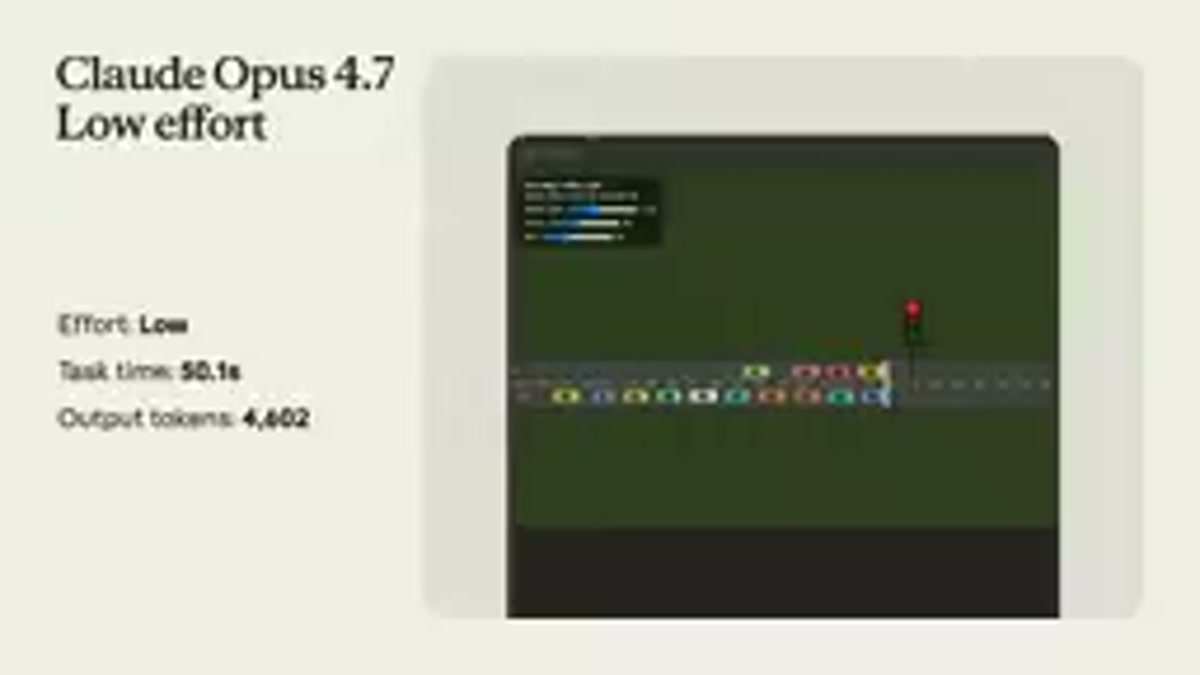
処理時間50.1秒、出力トークン4,602。シンプルながら動くシミュレーションが完成した。一方通行の道路、複数レーンの車、信号で止まるという基本動作は実現している。ただしBrickenが指摘した通り、信号機が道路の真ん中に立っているという非現実な点がある。
Opus 4.7 — High effort
処理時間はLowの約2倍、トークンも約2倍になった。結果として:
- 異なる車種(乗用車だけでなくトラックも)が登場
- 信号機の位置が改善(道路脇に移動、ただし上下が逆)
- ドライバーの知性が向上(周囲の車の動きに反応して加速・減速)
Brickenが特筆したのは「Claudeがプロンプトに書いていない『ドライバーの知性』を自発的に実装した」という点だ。thinking空間が倍になった結果、要件以上の要素を自律的に追加している。
Opus 4.7 — Max effort

処理時間593.1秒、出力トークン52,893——Lowの約11倍のトークンを消費した。生成物は:
- 都市の夜景スカイライン
- 物理的に正確な信号機(道路にオーバーハング)
- 複雑なインタラクションを持つ車の動作
Brickenは「明らかに最高の信号機だ」と笑いながらコメントした。
| Low effort | High effort | Max effort | |
|---|---|---|---|
| 処理時間 | 50.1秒 | ~100秒 | 593.1秒 |
| 出力トークン | 4,602 | ~9,000 | 52,893 |
| 信号機の位置 | 道路中央(誤) | 道路脇・逆さま | 道路上部・正確 |
| 車種 | 単一 | 複数 | 複数+リアル |
| ドライバーAI | 基本 | インタラクション付き | 高度なインタラクション |
重要な観察点は、Lowでも「動くもの」が作れるという点だ。問題の性質(正確な物理シミュレーション)が高知性を要求するから差が出た。単純なCRUD操作や定型フォーマットへの変換では、Lowで十分な場合が多い。
04 Interleaved ThinkingからAdaptive Thinkingへの進化
推論モデルの「考え方」には歴史的な発展がある。
第1世代:バッチ思考
最初の設計はシンプルだった。
- ユーザーの質問を受け取る
- 思考ブロック(scratch pad)で考える
- 一連のツール呼び出しを実行する
- テキストで回答する
問題は、最初にまとめて考えてからすべてのツールを実行するという構造にあった。人間なら「やってみる → 考える → また試す → 考える」を繰り返すのに、これでは「考えてから全部やる」になってしまう。
第2世代:Interleaved Thinking(インタリーブ思考)
各ツール呼び出しの後に思考ブロックを挿入する設計に変わった。テニスのアナロジーでBrickenが説明した通りだ——ボールを打って、コートの端まで戻りながら次の戦略を考える。行動と思考の繰り返しサイクル。
第3世代:Adaptive Thinking(適応的思考)

現在のClaudeが採用しているAdaptive Thinkingは、さらに一歩進んでいる。モデルが自律的に決定する:
- いつ考えるか(thinking block)
- いつツールを呼ぶか(tool call)
- いつ文章を出力するか(text)
- そもそも考えないか
「10 + 10 は?」に答えるとき、人間は考えない。「PhD水準の問題セット」に答えるとき、人間は深く考える。Adaptive Thinkingは同じ判断をClaudeに委ねる。モデルは質問の難易度・提供されたコンテキスト・直前のツール実行結果に基づいて、thinking blockを挿入するかどうかを自律的に決定する。
重要な補足がある。Adaptive ThinkingはClaude内部で「思考ツール」を持つ設計だ。分類器で質問を判定して思考量を変えるのではなく、Claudeが思考ツールを持ち、必要なときに使うというアーキテクチャだ。
Brickenはこのアナロジーを使った。「ウェブ検索ツールを与えたとき、我々はClaudeに『必ず検索しろ』でも『絶対に検索するな』でも言わない。ツールを与えて、いつ使うかはClaudeが判断する。思考も同じだ」。
05 なぜ「Thinking Toggle」は悪い設計なのか
Adaptive Thinkingが登場する前、一般的な認識は「extended thinking = より賢い回答、オフ = 速い回答」だった。これは間違いだとBrickenは明言した。
Thinkingをオフにすることは「考える量を減らす」操作ではない。「考える能力を丸ごと削除する」操作だ。
3つの能力のうち1つを完全に取り除いている:
Thinking(削除)- Tool calling
- Text
この設計の悪さは、ツールのアナロジーで明快になる。「Claudeにウェブ検索ツールを与えつつ、検索の多い回答と少ない回答の両方を求めるとき、我々はツールを外さない。effort levelや具体的な指示で調整する」。
同様に、チームメンバーに「内なる独り言を使うな、考えるな、ただ答えを出せ」とは言わない。制約と期待を伝えて、その人が判断する。Claudeも同じように扱うべきだというのがBrickenの主張だ。
Anthropicが推奨する設計原則は:
- Thinkingは「常に有効」にしておく
- 思考量の制御はeffort levelで行う
- モデルが本当に必要と判断したときだけ思考ブロックを挿入するのに任せる
実際、AnthropicはすべてのベンチマークをAdaptive Thinkingで計測し、Interleaved Thinkingよりパレート効率的(同じトークンでより高いスコア)であることを確認している。
06 5段階Effort Levelの選び方
セッションの核心部分として、Brickenは5段階のeffort levelの実践的な使い分け方を解説した。


グラフが示すように、xHigh→Maxの性能向上は他のステップより小さい(逓減する限界効用)。では具体的にどう使い分けるか。
| Effort Level | 推奨ユースケース | トークン消費 | 処理時間 |
|---|---|---|---|
| Max | 最難関タスク(数学証明、複雑なデバッグ、ロングホライズンエージェント) | 最大(xHighの約2倍以上) | 長い |
| xHigh(Extra High) | デフォルト推奨。Claude Code・Claude.aiの標準設定 | 高い | 中程度 |
| High | 知性が必要なほとんどのタスク。xHighより速く知性と速度のバランスが良い | 中高 | 速め |
| Medium | 知性と速度のバランスが必要な場合 | 中程度 | 速い |
| Low | 分類・要約・データ抽出。レイテンシ敏感なユースケース | 少ない | 最速 |
実践的な意思決定フロー(Bricken推奨):
- Evals(評価セット)がある場合: 実際の難問セットで各effort levelを試し、性能とコストのグラフを引く。逓減が始まる点が最適値
- Evalsがない場合: xHighをデフォルトにする(Claude Code・Claude.aiと同じ設定)
- コスト・レイテンシが問題になってきたら: HighやMediumを試し、性能が許容範囲内かをテスト
- Low: 知性不要タスクに限定する
Brickenはセッション中に繰り返しこの原則を強調した。「Extra highは私たちがClaude Code・Claude.aiで設定したデフォルトです。知性・速度・トークン数の三者間で最もパレート効率的な水準だと考えています。これを出発点にして、必要に応じて調整してください」。
07 Claude Plays Pokémon——Low effortが生む逆説的創造性
Brickenが「私のお気に入りのeval」と紹介したのが「Claude Plays Pokémon」だ。

設定:
- Claude Opus 4.7にゲームボーイのボタン操作ツールを与える
- ゲーム画面のビジョンアクセスを与える
- 目標:エリートフォーを倒す(ポケモン赤の最終目標)
興味深い発見はLow effortでの振る舞いだった。
通常のプレイヤーなら正面突破するところ、Claudeは:
- 虫除けスプレー(Repel) を大量使用して草むらでの野生ポケモン遭遇を回避
- ポーションでHP管理をしてポケモンセンターに戻る回数を最小化
- 逃走コマンドを積極的に使ってバトルの消耗を避ける
- 洞窟ではエスケープロープで素早く脱出
これは「ゲームを迂回する」戦略だ。Brickenが指摘した通り、思考を制約することで、制約のない場合には出てこない創造的なアトラクター状態に落ち着いた。
高思考量があると、モデルは「正解」に向かってまっすぐ思考する。低思考量では、その「正解への強引な突進」が起きないため、問題を別の側面から見る非線形な解法に行き着く可能性がある。これはすべてのユースケースに当てはまるわけではないが、「モデルに通常とは異なるアプローチをとらせたい」場面では意図的なLow effortが有効な実験になりうる。
08 Effort LevelとモデルサイズのトレードオフMatrix

開発者がよく迷う問いがある:「小さいモデルで高思考量」と「大きいモデルで低思考量」、どちらが良いか?
Brickenの実演が明確な答えを示した。同一プロンプトで:
- Opus 4.7 Low effort: 50.1秒、4,602トークン → 動作するシミュレーション
- Haiku 4.5 同等トークン: 24.1秒、4,413トークン → 「あれが車なのかわからない」レベル
思考を増やしても、基礎となるモデルの知識と推論能力の上限は超えられない。Haiku 4.5がどれだけ長く考えても、Opus 4.7 Low effortに勝てないユースケースが多い。
では小さいモデルをいつ使うか。Brickenの整理:
| ユースケース | 推奨モデル | 推奨Effort |
|---|---|---|
| 複雑なコード生成・デバッグ | Opus 4.7 | High〜xHigh |
| 複雑な推論・分析 | Opus 4.7 | High〜xHigh |
| 汎用タスク(知性要求あり) | Sonnet 4.6 / Opus 4.7 | High |
| 分類・タグ付け | Haiku 4.5 | Low〜Medium |
| データ抽出・変換 | Haiku 4.5 | Low |
| 単純な要約 | Haiku 4.5 | Low〜Medium |
| リアルタイム補完 | Haiku 4.5 | Low |
理想は「すべてのモデル×すべてのeffort levelのEvals結果を比較して最適を選ぶ」だが、現実的にはxHigh Opusから始めて、コストが問題になったらモデルを下げるかeffortを下げるかをベンチマークする順序が合理的だ。
09 Anthropic APIでのEffort Level実装
実際のAPIでeffort levelをどう設定するかを見ておこう。
Anthropic Python SDKでのbeta thinking設定(基本形):
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-opus-4-7-20251101",
max_tokens=16000,
thinking={
"type": "enabled",
"budget_tokens": 10000 # thinking用のトークン予算
},
messages=[{
"role": "user",
"content": "一方通行道路の交通シミュレーションを実装してください"
}]
)
effort levelによるbudget_tokens目安:
EFFORT_BUDGET_MAP = {
"low": 1_000, # 簡単なタスク、低レイテンシ優先
"medium": 5_000, # バランス重視
"high": 10_000, # 知性が必要なタスク
"xhigh": 20_000, # Claude Code・Claude.aiのデフォルト相当
"max": 50_000, # 最難関タスク、コスト最大
}
def create_with_effort(prompt: str, effort: str = "xhigh") -> str:
budget = EFFORT_BUDGET_MAP.get(effort, 20_000)
response = client.messages.create(
model="claude-opus-4-7-20251101",
max_tokens=budget + 8000, # thinking + 出力分
thinking={
"type": "enabled",
"budget_tokens": budget
},
messages=[{"role": "user", "content": prompt}]
)
# thinking blockを除いてテキストブロックのみ返す
return next(
block.text for block in response.content
if block.type == "text"
)
task budgetパターン(将来仕様・概念コード):
# Anthropicが開発中の機能(2025年時点)
# 時間・コストベースのbudgetを指定し、モデルが自律的にトークンを配分する
response = client.messages.create(
model="claude-opus-4-7-20251101",
task_budget={
"type": "time_based",
"max_duration_seconds": 3600, # 最大1時間
},
messages=[{
"role": "user",
"content": "このコードベース全体をリファクタリングしてください"
}]
)
task budgetはBrickenが「理想の将来像」として言及した機能で、「Claudeに1日、1週間という長期タスクを任せるとき、時間と予算の制約を自然言語ではなく構造化パラメータで与えたい」という設計思想に基づいている。
10 Metrベンチマーク——人間の労働時間との対比
セッションでBrickenはもうひとつの軸を示した。時間だ。
Metrは「現実の人間の労働タスク」を用いたエージェントベンチマーク。複数世代のモデルと、train-time computeとtest-time computeの組み合わせを評価する。
Claude最新モデル(Mythos):約16時間相当の人間労働を50%精度で達成。
これはモデルサイズ(train-time)とthinking量(test-time)の両方を高めた結果だ。そして「数秒→数分→数時間→数日→数週間」という方向で、人間の労働を置き換えられる範囲が広がっていく。
この観点から見ると、effort levelを「コストとレイテンシのトレードオフ」として捉えるのは部分的にしか正しくない。本質的には「どれだけ長いホライズンのタスクをモデルに任せるか」を決定するレバーでもある。
数時間のタスクをモデルに委ねるなら、maxやxhighは「高すぎるコスト」ではなく「必要なコスト」になりうる。
11 Adaptive Thinkingのライブデモ——ツール呼び出しとthinkingの交錯

セッションでBrickenがライブデモとして見せたのは、「Code w/ Claudeカンファレンスについて教えて」というシンプルな質問に対するAdaptive Thinkingの動作だった。
実際に観察された順序:
- Thinking block: 「これは最新情報を要するトピック。Web検索が必要」と判断
- Tool call: Web検索を実行
- Thinking block: 検索結果を評価し、追加情報が必要と判断
- Tool call: 別のクエリで再検索
- Thinking block: 情報が十分と判断
- Text output: ユーザーへの回答
この自律的な「think → act → think → act」サイクルが、Interleaved Thinking(act後に必ずthink)とは異なるポイントだ。ステップ3で「追加検索不要」と判断すれば、3つ目のToolcallはスキップされる。
判断ポイント} B -->|複雑・情報不足| C[Thinking Block
スクラッチパッド] B -->|シンプル| G[Text Output] C --> D{次のアクション
は何か?} D -->|外部情報が必要| E[Tool Call
検索・MCP・ファイル操作] D -->|十分考えた| G E --> F{結果を評価} F -->|追加思考が必要| C F -->|回答可能| G G --> H[ユーザーへの出力] style B fill:#e8f4fd,stroke:#2196F3 style C fill:#fff3e0,stroke:#FF9800 style E fill:#f3e5f5,stroke:#9C27B0 style G fill:#e8f5e9,stroke:#4CAF50
このグラフが示すように、Adaptive Thinkingは線形のパイプラインではなく状態機械として動く。各ノードでの判断がClaudeに委ねられており、開発者はeffort levelというパラメータで「判断の傾き」だけを調整する。
12 3つの実践原則
Brickenはセッションの締めくくりとして、3つの原則をまとめた。

原則1:Thinkingを有効にして、effort levelとbudgetで調整する
Thinkingは常時有効にする。「有効にするかどうか」ではなく「どれだけ使わせるか」を調整する。budget_tokensパラメータやeffort levelがその調整機構だ。
原則2:Evalsで理想のバランスを見つける
本番環境で起きる最難問に近いテストケースを用意し、複数のeffort levelでスコアと費用を比較する。逓減が始まる点が最適値だ。Evalsがない状態で「最適なeffort level」を決めることはできない。
原則3:迷ったらxhigh
Claude Code・Claude.aiがデフォルトにしている設定は、Anthropicが「知性・速度・コストのパレート効率的な水準」と判断した設定だ。独自のEvals結果がない限り、ここから始めるのが合理的だ。
Brickenが「理想の目標」として語ったのが「task budget」だ。「Claudeに1週間のタスクを任せる。予算はX円、または時間はY時間まで」と指定すると、Claudeが自律的にトークン配分を最適化する。max_tokensという「出力量の制限」ではなく、「タスク全体へのリソース配分」という次元の制御に進化する設計思想だ。
まとめ:思考レバーを引く前に確認すべき4点
「The thinking lever」セッションからの要点を整理すると:
- Thinkingはオフにするな — 能力削除ではなく、effort levelで量を調整する
- 知性が必要なら大きいモデル+低effortが小モデル+高effortより優れる — モデルの天井は超えられない
- xhighをデフォルトに — Evalsで最適化できるまでは、これが安全な出発点
- 低effortは制約が目的の特殊ケース — Pokemon事例のように、意図的な制約が創造性を引き出す場合がある
Test-time computeは「費用対効果を調整するコスト管理の問題」ではなく、「モデルに何時間・何日のタスクを任せるか」という設計の問題でもある。Metrベンチマークが示すように、Claudeが担える「人間の労働時間」は確実に伸びている。そのスケールに合わせてeffort levelをどう設定するかが、今後のエージェント設計の中心的な問いになる。
参照ソース
- The thinking lever — YouTube (Code w/ Claude, 2025) — 本記事のベース動画。Alexander Bricken (Applied AI Research, Anthropic)
- Extended thinking documentation — Anthropic — Anthropic公式のthinking設定リファレンス
- Anthropic Python SDK — GitHub — APIコード実装の参照元