2026年4月30日、Canonical/Ubuntuの中核インフラが大規模なDDoS攻撃を受けて長時間ダウンした。ubuntu.com本体、開発者向けプラットフォームのLaunchpad、Snap Store、シングルサインオン基盤のCanonical SSOまで影響が波及し、世界中のapt update/apt installが失敗、新規CVEに対するセキュリティアップデートの取得が事実上不可能になった。攻撃の主体は313 Team(Islamic Cyber Resistance in Iraq)を名乗る親イラン系ハクティビスト集団で、Ubuntu 26.04 LTS(Resolute Raccoon、4月23日リリース)公開直後の需要ピークを狙った点が今回の特徴だ。Canonicalは5月1日 14:44 CETに全サービス復旧を発表したが、約30時間の停止が世界中のDevOps現場に与えた衝撃は大きい。本記事ではこの事件の経緯、26.04直撃という攻撃の意図、運用者が取るべき暫定回避策、そしてOSS配布インフラを狙う脅迫型ハクティビズムの構造的リスクを解析する。
この記事ではCanonical/Ubuntuに対するDDoS攻撃事件を解析します。OSSサプライチェーン全体のリスク像についてはサプライチェーンセキュリティ2026|攻撃手法・防御ツール・実践チェックリストをご覧ください。
30秒で理解する
- 2026年4月30日にCanonical/Ubuntuインフラが313 TeamのDDoS攻撃で停止、5月1日 14:44 CETに全サービス復旧
- ubuntu.com・archive.ubuntu.com・Launchpad・Snap Store・Canonical SSOが同時に影響を受け、
apt updateが世界規模で失敗 - Ubuntu 26.04 LTS(Resolute Raccoon、4月23日リリース)の公開直後・需要ピーク週を意図的に狙った「26.04直撃」型のハクティビズム
- 攻撃手法はBeamed.SU等のIPストレッサーを利用したL3/L7ハイブリッドDDoSと推定
- 運用側の即応策は国内ミラー切替・apt-cacher-ng・retry/timeout調整の3点セット
事実関係の注意:本記事はUbuntu Discourseの公式更新投稿、TechCrunch・The Register・Tom’s Hardware等の報道、CanonicalステータスページとX上の独立観測に基づく。Canonical自身は本記事執筆時点で攻撃手法・規模の詳細を公表しておらず、ペイロード解析・帰属の技術根拠は攻撃者の自己申告と第三者観測の範囲にとどまる点に留意してほしい。
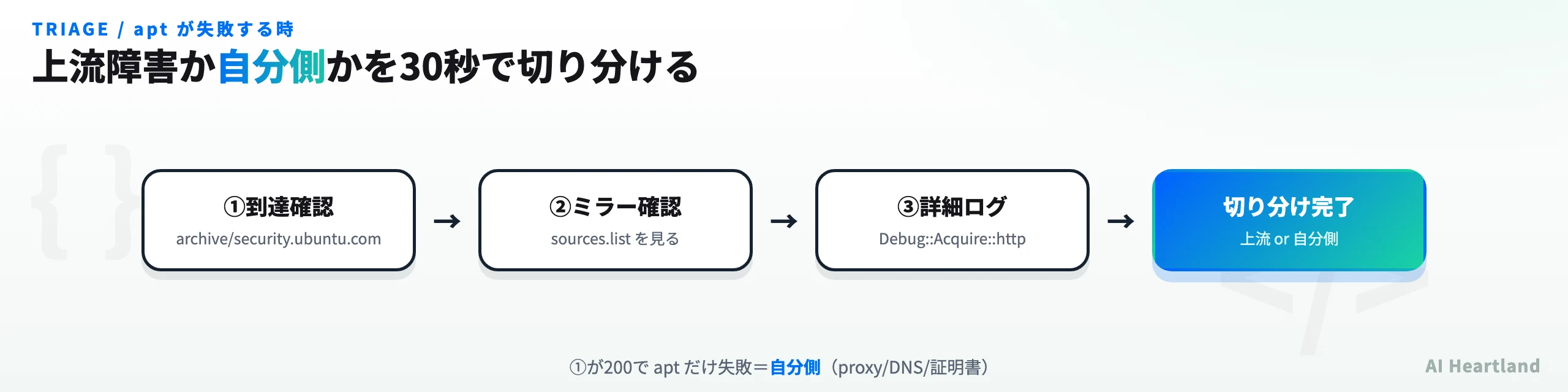
apt が失敗している人向けの切り分け。①が200を返すのに apt だけ失敗するなら、原因は上流ではなく自分側(プロキシ・DNS・ミラー設定・証明書)だこの障害は復旧済み — いま apt が失敗しているなら、まず切り分ける
先に結論を書く。本記事が扱う2026年4月30日のDDoS障害は、約30時間で復旧済みだ(本記事の更新時点=2026年7月31日)。いま apt update が失敗している場合、原因はこの事件そのものではなく、別の障害・ネットワーク・設定である可能性が高い。
「Ubuntuが落ちているのか、自分の環境の問題なのか」は、次の順で30秒あれば切り分けられる。
# 1) 名前解決とHTTP到達性を確認(Canonicalのアーカイブ)
curl -sI https://archive.ubuntu.com/ubuntu/dists/ | head -1
curl -sI https://security.ubuntu.com/ubuntu/dists/ | head -1
# 2) 自分が向いているミラーを確認する(ここが海外だと遅延・失敗が出やすい)
grep -rhE '^deb |^URIs:' /etc/apt/sources.list /etc/apt/sources.list.d/ 2>/dev/null | sort -u
# 3) 詳細ログ付きで再試行し、どこで止まるかを見る
sudo apt-get update -o Debug::Acquire::http=true 2>&1 | tail -30
1が200を返すのに apt update だけ失敗するなら、自分側(プロキシ・DNS・ミラー設定・証明書)を疑う。1から到達できないなら、上流障害の可能性がある——その場合の暫定回避策は本記事後半の「運用者が今すぐ取れる暫定回避策」がそのまま使える。国内ミラーへの切り替えや apt-cacher-ng は、今回のような上流障害の再発時にも同じように効くため、平時に仕込んでおく価値がある。
以降は「2026年4月30日に何が起きたか」の記録と、そこから引き出せる恒久対策だ。いま困っている人は上のコマンドで切り分け → 「運用者が今すぐ取れる暫定回避策」へ、事後の体制づくりを考えている人は「BCPとして考えるOSS依存リスク」へ進むのが早い。
攻撃の経緯:26.04リリース週を直撃した約30時間の停止
Ubuntu Discourseの公式投稿と複数の独立した報道を時系列で整理すると、攻撃は単発の波ではなく断続的に継続し、復旧と再ダウンを繰り返したことがわかる。
ubuntu.com / archive.ubuntu.com
5xxエラー多発"] --> B["同日
Launchpad / Snap Store
Canonical SSO に波及"] B --> C["313 Teamが犯行声明
Telegram / X で投稿
Beamed.SU使用と主張"] C --> D["断続的な復旧と再攻撃
ステータスページが揺れる"] D --> E["世界中で apt update / install 失敗
CI/CD パイプラインが連鎖停止"] E --> F["2026-05-01 14:44 CET
Canonical が全サービス復旧を宣言
(Ubuntu Discourse 更新投稿)"] F --> G["復旧後もミラー同期遅延が残存
5/2 朝までCVE反映が遅れる"]
ステータスページ上では多数のコンポーネントが同時に「Major Outage」となり、canonical.com・portal.canonical.com・maas.io・jaas.ai・assets.ubuntu.com・developer.ubuntu.comまで波及したことが報告された。攻撃者は単一ドメインを狙ったのではなく、Canonical配下のCDN/オリジンを横断的に標的化したと推定される。約30時間に及ぶ累計停止は、商用OSSベンダーのインシデントとしてはCloudflare/Fastly関連事件と並ぶ規模だ。
なぜ26.04リリース週を狙ったのか
今回の攻撃の最大の特徴は、Ubuntu 26.04 LTS(Resolute Raccoon、2026年4月23日リリース)の公開直後を狙って発射された点だ。26.04は偶数年4月の長期サポート(LTS)版にあたり、新カーネルや刷新されたツールチェーンを含む重要リリースで、世界中のISP・データセンターでイメージ取得需要が急増する週だった。攻撃が観測された4月30日は、まさにそのリリース直後の需要ピークのただ中だった。
| 攻撃が直撃した26.04リリース要素 | 影響 |
|---|---|
| ISOミラーリング | 一次ミラーが落ち、二次ミラーへトラフィック殺到 |
| Snap版アプリの更新 | Firefox/Chromium/snapd自身の更新が遅延 |
do-release-upgrade |
25.10からの自動アップグレードが失敗連発 |
| Cloud Image配布(AWS/Azure/GCP) | パブリッククラウド側の26.04 AMI/Imageの一部反映遅延 |
| Launchpad PPA | サードパーティ開発者のビルド/公開が停止 |
リリース直後のミラー同期負荷とDDoSが重なることで、正常なフラッシュトラフィックなのか攻撃トラフィックなのか切り分けが困難になるという二次効果も生じる。これは2024年のFedora 41リリース時に観測された類似インシデントと構造が似ており、ハクティビスト側が「OSSの年中行事カレンダー」を学習している可能性を示唆する。
過剰評価への警鐘:脅威インテリジェンス各社の観測では、313 Teamの主張には誇張・捏造が混在する傾向が指摘されている。今回の事件についても「成功した」と即断するのではなく、Canonical側のオフィシャルなインシデント報告書(ポストモーテム)を待つ姿勢が必要だ。攻撃ベクトルの帰属(attribution)は本来、極めて慎重な作業を要する。
313 Teamとは何者か:脅迫型ハクティビズムの新潮流
313 Teamは「Islamic Cyber Resistance in Iraq」を称する親イラン系ハクティビスト集団で、2023年12月以降に短時間DDoSを連続発射する手口で知られる。これまでの観測では以下の特徴が報告されている。
| 観測項目 | 内容 |
|---|---|
| 主な手口 | L3/L7混在のDDoS(ボリューメトリック+アプリ層) |
| 利用インフラ | Beamed.SU等のIPストレッサー(commercial booter)と推定 |
| 過去の標的 | TruthSocial(Trump系SNS)、Bluesky、各種西側企業ドメイン |
| 特徴 | Telegram/X/Sessionで犯行声明・脅迫を発信 |
| 動機 | 政治的アジェンダが中心、金銭目的は二次的 |
今回の事件で注目すべき点は、金銭ではなく政治的アジェンダを掲げた“象徴的攻撃”である一方、攻撃対象としてOSSの中核を支える企業を選んだ非対称性だ。Canonicalほどの組織でも、配布インフラを止められれば全世界の運用者が即時に困る。OSS配布層の単一障害点が現実の攻撃面として狙われた典型例といえる。
何が止まったか:Launchpad/Snap Store停止の真の意味
今回の攻撃の真に深刻な側面は、止まった対象がOSS配布チェーンのほぼ全層に及んだ点にある。単にaptが失敗するだけではなく、開発者がパッケージを公開するLaunchpad、Snap Store、Canonical SSOまで一斉に止まった。
| 影響を受けたサービス | 運用上の意味 |
|---|---|
ubuntu.com |
ドキュメント・公式情報の参照不可 |
archive.ubuntu.com |
apt update/パッケージ取得失敗 |
security.ubuntu.com |
セキュリティパッチ配信が停止 |
| Launchpad | PPA公開・ビルド・バグトラッカーが停止 |
| Snap Store | snapパッケージ更新の遅延、新規公開の不可 |
| Canonical SSO | login.ubuntu.com/login.canonical.comが応答停止 |
| Ubuntu One | 認証連動サービス全般に影響 |
canonical.com系 |
商用サポート・MAAS/JAASへの影響 |
たとえば本サイトでも先日扱ったLinux Kernel Container Escape脆弱性 CVE-2026-31431(Copy Fail)の解説のような重大CVEが連続している現状で、security.ubuntu.comが落ちる=CVE適用が遅れるという事実は、攻撃の「副次効果」ではなく明確な狙いとみるべきだ。Snap Storeの停止は、Firefoxのゼロデイが出た瞬間に更新が走らないことを意味し、結果としてエンドユーザー側の脆弱性窓を意図的に広げる効果を持つ。
運用者が今すぐ取れる暫定回避策
公式の復旧を待つ間にも、現場のサーバーは脆弱性を抱えたまま動き続ける。Ubuntu運用者が即座に取れる現実的な対策を3段階で整理する。
1. 国内ミラーへの切り替え
/etc/apt/sources.listのarchive.ubuntu.com・security.ubuntu.comを国内ミラーに差し替えることで、Canonical本体が落ちていても更新を継続できる。日本国内の主要ミラーは次のとおり。
| ミラー運営 | エンドポイント | 特徴 |
|---|---|---|
| JAIST | ftp.jaist.ac.jp/pub/Linux/ubuntu |
北陸先端、長年安定 |
| 理研 | ftp.riken.jp/Linux/ubuntu |
関東、HTTPS対応 |
| 山形大学 | ftp.yz.yamagata-u.ac.jp/pub/linux/ubuntu |
大学系では最古参 |
| KDDI研究所 | ftp.kddilabs.jp/Linux/packages/ubuntu |
商用回線で帯域広い |
| Cloudflare Mirror | mirror.ubuntu.cloudflare.com/ubuntu/ |
グローバルCDN |
# JAIST(北陸先端科学技術大学院大学)に切替
sudo sed -i.bak \
-e 's|http://archive.ubuntu.com/ubuntu|http://ftp.jaist.ac.jp/pub/Linux/ubuntu|g' \
-e 's|http://security.ubuntu.com/ubuntu|http://ftp.jaist.ac.jp/pub/Linux/ubuntu|g' \
/etc/apt/sources.list
# 24.04以降のDEB822形式(/etc/apt/sources.list.d/ubuntu.sources)を使う環境
sudo sed -i.bak \
-e 's|archive.ubuntu.com|ftp.jaist.ac.jp/pub/Linux|g' \
-e 's|security.ubuntu.com|ftp.jaist.ac.jp/pub/Linux|g' \
/etc/apt/sources.list.d/ubuntu.sources
sudo apt update
ただしsecurity mirrorはCanonical本体の信頼チェーンに依存しているため、本体が完全停止していると更新タイムスタンプが古くなる場合がある。あくまで「攻撃が部分的で本体側の同期が動いている」前提での回避策だ。
2. apt実行時のリトライ/タイムアウト調整
DDoSが間欠的な場合、apt側の再試行回数を増やすだけで体感の改善ができる。/etc/apt/apt.conf.d/99-retryに以下を追加する。
# /etc/apt/apt.conf.d/99-retry
Acquire::Retries "5";
Acquire::http::Timeout "60";
Acquire::https::Timeout "60";
Acquire::ForceIPv4 "true";
# 並列ダウンロード数を抑え、上流負荷を下げつつ自分の成功率を上げる
Acquire::Queue-Mode "host";
Acquire::http::Pipeline-Depth "0";
ForceIPv4はDDoS時にIPv6側のルーティングが不安定になる現象を回避する保険として有効だ。
3. ローカル/オフラインキャッシュの活用
中規模以上の組織ではapt-cacher-ngやAptlyを社内に立て、ミラーから取得したパッケージをローカルキャッシュ化しておくと、上流ダウンの影響を最小化できる。CIランナーや本番サーバー群が同じパッケージを並列取得する場合、平常時のトラフィック削減にもなる。
# apt-cacher-ng クイックスタート(Docker)
docker run -d --name apt-cacher-ng \
-p 3142:3142 \
-v $(pwd)/apt-cacher-ng-cache:/var/cache/apt-cacher-ng \
--restart unless-stopped \
sameersbn/apt-cacher-ng:latest
# クライアント側設定
echo 'Acquire::HTTP::Proxy "http://apt-cache.local:3142";' \
| sudo tee /etc/apt/apt.conf.d/01proxy
# 主要ミラーをremap_*で複数登録(apt-cacher-ng本体側)
# /etc/apt-cacher-ng/backends_ubuntu に以下を列挙:
# http://ftp.jaist.ac.jp/pub/Linux/ubuntu/
# http://ftp.riken.jp/Linux/ubuntu/
# http://archive.ubuntu.com/ubuntu/
複数のミラーをbackendsに登録しておけば、片方が落ちても自動でフェイルオーバーする。CIランナー専用の小規模Squidキャッシュを置くだけでも、リリース週のフラッシュ需要を吸収できる。
Tip:Snapパッケージはsnapの自動更新が裏で走る仕組みのため、ストア側がDDoSを受けると自動更新が遅延する。クリティカルなSnap(特にsnapd自身、core、firefox、chromium)はバージョン固定運用も検討する価値がある。sudo snap refresh --hold=72h <name>で一時的に更新を止める運用も有効。
Ubuntuリリース体系とAIスタック更新で押さえる前提
今回の影響範囲を正しく見積もるには、Ubuntuのリリース体系と、apt経由で更新されるAIスタック(GPUドライバ・CUDA)の依存関係を理解しておく必要がある。とくにLLM/機械学習を回す環境は、OS本体よりもNVIDIAドライバ・CUDA・cuDNNといったapt配布物への依存が深く、archive停止の影響を受けやすい。
| バージョン | コードネーム | 種別 | サポート期限の目安 |
|---|---|---|---|
| Ubuntu 24.04 | Noble Numbat | LTS | 標準5年(ESMで最大12年) |
| Ubuntu 24.10 | Oracular Oriole | 中間リリース | 9ヶ月 |
| Ubuntu 25.04 | Plucky Puffin | 中間リリース | 9ヶ月 |
| Ubuntu 25.10 | Questing Quokka | 中間リリース | 9ヶ月 |
| Ubuntu 26.04 | Resolute Raccoon | LTS | 標準5年(ESMで最大12年) |
偶数年4月の.04リリース(24.04・26.04)が長期サポート(LTS)版で、本番・サーバー用途の基準になる。.10や奇数年の中間リリースはサポート9ヶ月の短期版で、新機能の先取り用と位置づけられる。今回攻撃を受けた26.04は前述のとおりLTSであり、LTSへのアップグレード需要が世界規模で集中する週を狙われたことが被害を増幅させた。
AIスタック(GPUドライバ/CUDA)はarchive停止の影響を強く受ける
GPUを使うAI/ML環境は、OSパッケージに加えて以下のapt由来コンポーネントに依存する。archive・securityミラーやNVIDIAのaptリポジトリが止まると、これらの更新・再構築が連鎖的に詰まる。
・ubuntu-drivers/nvidia-driver-*:Ubuntu本体archive経由で配布されるNVIDIAドライバ。archive停止時はドライバ更新・新規インストールが失敗
・CUDA Toolkit・cuDNN:NVIDIAの専用aptリポジトリ(developer.download.nvidia.com)から取得。Ubuntu archiveとは別系統だが、依存パッケージ(gcc、build-essential、カーネルヘッダ)はUbuntu archive側にあるため間接的に影響
・コンテナ基盤のnvidia-container-toolkit:GPUコンテナ運用の要。これが更新できないとCUDAイメージのビルド・更新が停止
・do-release-upgradeでの26.04移行:GPUドライバの再ビルド(DKMS)を伴うため、archive混雑期のアップグレードはドライバ不整合のリスクが上がる
# GPU/CUDA環境では、archive停止時に「何が更新待ちか」を即座に把握する
apt list --upgradable 2>/dev/null | grep -Ei 'nvidia|cuda|linux-(image|headers)|dkms'
# DKMS(ドライバ再ビルド)状態の確認。アップグレード前に整合性を見る
dkms status
# NVIDIA aptリポジトリの到達性チェック(停止検知用)
curl -sS -o /dev/null -w '%{http_code}\n' \
https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/
GPU/CUDA環境では、ドライバとカーネルのバージョン整合(ABI)が崩れると起動不能やCUDA認識不可に直結する。archive混雑期にはドライバ・カーネルの更新を意図的に保留(apt-mark hold)し、ミラー同期が落ち着いてから整合性を確認しつつ更新するのが安全だ。AIワークロードを止めないためにも、後述のローカルキャッシュにNVIDIA系パッケージも含めておくと復旧が早い。AIエージェントが自動でこうした更新・運用を回す環境のリスク設計については、ピラー記事AIセキュリティとは?LLM時代の脅威モデル・代表的リスク・OSS対策ツールを体系解説する入門ガイドも参考になる。
攻撃手法の技術的解析:L3/L7ハイブリッドDDoS
公開情報と過去の313 Teamの行動パターンから推測される今回の攻撃の技術的構造を整理する。あくまで状況証拠ベースの推定だが、再発時の検知・対処のヒントになる。
推定される攻撃ベクトル
| 層 | 想定手法 | 影響 |
|---|---|---|
| L3/L4 | UDP reflection(DNS/NTP/memcached) | オリジン回線の帯域飽和 |
| L4 | SYN Flood/ACK Flood | フロントエンドLBの接続テーブル枯渇 |
| L7 | HTTPS GET/POST flood、TLS handshake消費 | アプリケーションサーバーのCPU飽和 |
| L7 | Slowloris/slow read | ワーカー枯渇、特にPython/Ruby系で顕著 |
| L7 | キャッシュバスター付きリクエスト | CDNキャッシュ無効化、オリジン直撃 |
security.ubuntu.comのように静的ファイル中心のオリジンに対しては、ボリューメトリック攻撃でCDN/オリジン間回線を埋めるのが効きやすい。一方で動的処理を含むLaunchpadやCanonical SSOは、L7のTLSハンドシェイク消費がCPU側のボトルネックになる。今回複数のドメインが同時に長時間落ちたのは、両方を組み合わせた「ハイブリッドDDoS」と見るのが妥当だろう。
商用booterの経済性
313 Teamが利用したと主張するBeamed.SUのようなcommercial booter(IPストレッサー)は、月額数十ドル〜数百ドルでGbps級のDDoSを発射可能だ。ハクティビストにとって費用対効果が極めて高く、「金銭目的の犯罪者」と「政治的動機の集団」の境界が曖昧になりつつある。
booter利用料の概算:
- 月額$30: 〜10Gbps、攻撃時間 数分単位
- 月額$200: 〜100Gbps、攻撃時間 長時間
- 月額$500+: 数百Gbps、複数キャンペーン同時実行
数十万円の月額コストで世界規模のOSSインフラに圧力をかけられる構造そのものが、今回の事件の根本にある。サプライチェーン側で見ると、依存関係の自動更新を扱うRenovate・Dependabot防御|サプライチェーン攻撃の最新対策とも問題が地続きで、配布経路と依存性管理の両面で備える必要がある。
過去のOSSサプライチェーン事件との位置づけ
OSSインフラを標的にしたDDoS/脅迫はこれが初めてではない。文脈を整理すると今回の攻撃の位置づけが見える。
| 年 | 事件 | 概要 |
|---|---|---|
| 2014 | sourceforge改ざん | OSSバイナリにマルウェア混入 |
| 2018 | event-stream npm乗っ取り | 依存性経由で暗号通貨ウォレット攻撃 |
| 2021 | log4shell(CVE-2021-44228) | 脆弱性悪用、配布経路は無事 |
| 2024 | XZ Utils backdoor | 信頼ある開発者を装った長期工作 |
| 2026 | 313 TeamによるCanonical DDoS | 配布経路を直接停止する圧力型攻撃 |
過去の主流は「悪意あるコードを混入させる」「特定脆弱性を悪用する」攻撃だったが、今回はインフラそのものを止めて影響力を交渉カードにする点で性質が異なる。npmやPyPI、cargo、Docker Hubなど他のOSSパッケージレジストリも同様の標的になり得る。最近のCI/CD周辺の脆弱性(git push を起点にパイプラインを乗っ取る類のもの)と組み合わさると、影響範囲は配布層と実行層の両方に広がる。
構造的リスク3点
- OSS配布インフラの寡占:DebianやUbuntuのarchiveが落ちるだけで、世界中のサーバーが同時に困る。攻撃インセンティブが大きい
- ハクティビストの商業化:commercial booterサービス(IPストレッサー)の発達で、技術力が低くても大規模DDoSが打てる
- 公式コミュニケーション不足:Canonicalほどの組織でも初動の声明が遅い。混乱拡大と二次被害(フィッシング偽サイト誘導等)を招く
BCP(事業継続計画)として考えるOSS依存リスク
今回の事件を一過性のニュースとして消費するのではなく、自社の事業継続計画(BCP)に「OSS配布インフラの停止」を正式に組み込む契機とすべきだ。具体的なシナリオベースの想定と対応を表にまとめる。
| シナリオ | 発生確率 | 影響度 | 推奨対策 |
|---|---|---|---|
| Ubuntu archive停止(24h以内) | 中 | 中 | 国内ミラーfallback/apt-cacher-ng |
| Ubuntu archive停止(72h以上) | 低 | 高 | オフラインミラー構築/代替OSへの一時切替 |
| Snap Store停止 | 中 | 低 | 重要Snapはdebに置換、--holdで更新固定 |
| Launchpad PPA停止 | 中 | 中 | PPAビルドのGitHub Actions移行+自前配布 |
| Docker Hub停止 | 中 | 高 | プライベートレジストリ常設、harbor等 |
| npm/PyPI停止 | 中 | 高 | バージョンロック+プライベートレジストリ |
「想定外の停止」を「想定内の運用」に組み替える発想転換が、SRE組織にとっての真の学びになる。
監視テンプレート例(Prometheus/Blackbox Exporter)
外部依存サービスの可用性を継続的に監視するためのblackbox-exporter設定例を示す。これがあれば、次回似たような事象が発生したとき早期に気づける。
# prometheus.yml の抜粋
scrape_configs:
- job_name: 'oss-supply-chain-health'
metrics_path: /probe
params:
module: [http_2xx]
static_configs:
- targets:
- https://archive.ubuntu.com/ubuntu/dists/noble/Release
- https://security.ubuntu.com/ubuntu/dists/noble-security/Release
- https://api.snapcraft.io/v2/snaps/info/core
- https://launchpad.net/
- https://login.ubuntu.com/
- https://registry-1.docker.io/v2/
- https://registry.npmjs.org/
- https://pypi.org/simple/
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: blackbox-exporter:9115
応答時間とHTTPステータスをアラート化し、5分以上継続失敗で通知すれば、ニュースで知る前に運用側で気づける。Slack通知に「代替ミラーへの切替コマンド」をリンクとして含めれば、夜間オンコール対応も効率化できる。
復旧後の事後対応チェックリスト
5月1日 14:44 CETに復旧した後も、以下の点検を行うことで「次回」への備えとなる。
sources.list/ubuntu.sourcesに複数のミラーURLを冗長化しているかapt-cacher-ng等のローカルキャッシュを構築済みか- CVE通知をCanonical Security APIだけでなく、CVE.org・OSV・GitHub Advisory Databaseなど複数経路で監視しているか
- CI/CDで
apt失敗時の自動リトライ/代替ミラー切替が機能するか - サプライチェーンインシデントを想定したランブック(手順書)が整備されているか
- 26.04へのアップグレード計画を、ミラー混雑が落ち着くタイミングまで見直したか
- Snap更新の状態(
snap changes)に異常がないか確認したか
OSSは「タダで動くもの」ではなく、コミュニティとインフラ運営者の善意とコストで成り立っている。今回のような攻撃は、その脆さを露呈させる一方で、運用者側にも「依存関係の冗長化」という当事者意識を要求している。Ubuntu 26.04のアップグレードを予定している組織は、ミラー側の同期が落ち着く5月中旬以降を目安に、複数ミラーを併用しながら段階的に切り替えるのが安全だ。
参照ソース
- Update concerning DDoS attack on Canonical and Ubuntu (Ubuntu Discourse) — Canonical/Ubuntu公式の更新投稿(5月1日 14:44 CET全サービス復旧の発表を含む)
- Ubuntu services hit by outages after DDoS attack (TechCrunch) — TechCrunchによる第一報の俯瞰
- Canonical confirms Ubuntu infrastructure under sustained DDoS attack (The Register) — The Registerの技術的詳細とDevOpsインパクトの分析
- Canonical under sustained DDoS attack as Ubuntu 26 releases — Iranian group 313 Team claims responsibility (Tom’s Hardware) — 帰属(attribution)と26.04リリースとの関連分析