会議の文字起こし、コールセンターのリアルタイム字幕、聴覚障害者向けアクセシビリティ——音声認識の用途は爆発的に増えているが、OpenAIのAPIに頼らずセルフホストで「ほぼ遅延なし」のWhisperを動かすのは依然として難しい。標準のWhisperは数十秒のチャンクを一括処理する設計で、リアルタイム用途では文の途中で切れる・文脈を失うといった問題を抱える。WhisperLiveKitはこの壁を、SimulStreaming(AlignAttポリシー)・LocalAgreement・話者識別(Sortformer/Diart)といった研究成果をひとまとめにしたOSSパッケージとして突破する。Apache-2.0、★10.2k、Python製、最新版v0.2.20(2026年3月)。Docker docker run 1発でリアルタイム文字起こし基盤が立ち上がる。本記事ではアーキテクチャから実運用までを徹底解説する。
この記事ではセルフホスト音声認識OSS WhisperLiveKitを解説します。LLMとローカルAI全体の文脈についてはLLMとは?仕組み・主要モデル比較・ローカル実行・量子化を一気にまとめる2026年版をご覧ください。
この記事のポイント
- WhisperLiveKitはSimulStreaming・話者識別・200言語対応を1パッケージにまとめた音声認識OSS(Apache-2.0、★10.2k)
- FastAPI + WebSocket構成、
pip install whisperlivekitまたは Dockerdocker runで即起動 - Apple Silicon(MLX)・CUDA・CPU・OpenAI API・Voxtralなど6種類のバックエンドから選択可能
- OpenAI/Deepgram互換のAPIを提供し、既存システムから差し替えやすい
WhisperLiveKitとは:「実用Whisper」を再構築するOSS
WhisperLiveKitはフランスのエンジニアQuentin Fuxa氏が開発する音声認識OSSだ。OpenAIのWhisperそのものをラップするのではなく、「Whisperでリアルタイムを実現するために必要な周辺技術」を最新研究から取り込み統合している。
標準のWhisperを「そのまま」リアルタイムに使うと次の問題が起きる。
- 30秒チャンクを境に音声が切られ、単語が途中で分断される
- 文脈窓が短く、後半の音声で前半の修正ができない
- 話者の切り替わりが分からない(ノートテイク用途で致命的)
- 多言語混在の音声で言語切替が苦手
WhisperLiveKitはこれらに対し、AlignAtt(注意機構を使った超低遅延出力)、LocalAgreement(連続出力の整合性確保)、Streaming Sortformer/Diart(リアルタイム話者識別)を組み合わせて解決する。SimulStreamingは特に学術論文で実証されたアルゴリズムで、英語で平均1〜2秒以下の遅延を実現する。
設計思想:「研究レベルの最新リアルタイムASR技術を、pip installで誰もが使える形にまとめる」のがWhisperLiveKitの位置づけ。Whisper本体・Faster-Whisper・MLX-Whisper等の高速バックエンドを抽象化し、上位層でストリーミング制御と話者識別を提供する。
名前が紛らわしい:LiveKit とは無関係、表記ゆれにも注意
検索で辿り着く前に整理しておきたい点がある。WhisperLiveKit は livekit/livekit とは無関係のプロジェクトだ。
| 名前 | 実体 | 関係 |
|---|---|---|
| WhisperLiveKit(本記事) | QuentinFuxa/WhisperLiveKit。Whisperを低遅延ストリーミング化するPythonパッケージ |
— |
| LiveKit | livekit/livekit(★20,041)。WebRTCベースのリアルタイム通信基盤 |
別プロダクト。依存関係も無い |
WhisperLiveKit のREADMEにLiveKitへの言及は無く、構成は FastAPI + WebSocket で完結している。「Whisper を LiveKit に組み込む方法」を探して来た場合、本記事の対象は別物なので注意してほしい(もっとも、WebSocketで文字起こし結果を配信する設計なので、LiveKit側のパイプラインに繋ぎ込むこと自体は不可能ではない)。
表記についても、日本語圏では次のゆれが観測される。いずれも同じものを指す。
・WhisperLiveKit(公式表記)
・whisper livekit / whisper live kit(スペース区切り)
・whisperlivekit(PyPIパッケージ名。pip install whisperlivekit)
QuentinFuxa/WhisperLiveKit。組織名が個人アカウント名なので、「whisperlivekit github」で探すと本家より二次情報が上に出ることがある。PyPIパッケージ名は全小文字の whisperlivekit で、こちらは公式配布物である。
SimulStreaming と AlignAtt:なぜ「低遅延」が実現できるのか
WhisperLiveKit の低遅延は独自実装ではなく、公開されている同時通訳研究の成果を実装に落とし込んだものだ。READMEが挙げる論文を辿ると、設計思想がはっきりする。
| 要素 | 出典 | 役割 |
|---|---|---|
| Simul-Whisper / SimulStreaming | arXiv:2406.10052 / arXiv:2506.17077(SOTA 2025) | Whisperを逐次処理へ作り替える中核 |
| AlignAtt policy | arXiv:2305.11408 | いつ出力を確定するかを注意機構のアラインメントで決める方針 |
| AlignAtt4LLM | IWSLT 2026(arXiv:2606.03967) | デコーダのみのLLMでの同時翻訳。attention-gated commits・append-only出力 |
素のWhisperが「数十秒の塊をまとめて処理する」設計であるのに対し、AlignAtt は「モデルの注意がまだ先の音声に向いているなら、その単語は確定させない」という判断基準を与える。これにより、言い直しの少ない出力を保ちながら単語単位で結果を出せる。simulstreaming という語で検索してここへ来た場合、探しているのはこの中核部分である可能性が高い。
つまりWhisperLiveKitの価値は「新しいASRモデルを作ったこと」ではなく、「研究段階のストリーミング手法を、pipで入る形にまとめたこと」にある。モデル自体はWhisper系をそのまま使うため、認識精度の土台はWhisperと同等で、変わるのは出し方だ。
この理解は導入判断にも直結する。「Whisperで精度が足りなかったからWhisperLiveKitに替える」という動機は成立しない——土台のモデルが同じである以上、聞き取り精度そのものは大きく変わらないからだ。逆に「精度は足りているが、録音が終わるまで結果が出ないのが使いづらい」という不満に対しては、まさにこれが解になる。
もう一点、実装が研究由来であることの副作用として、論文側の更新がそのまま機能追加として降りてくるという性質がある。READMEに並ぶ arXiv リンクは飾りではなく、採用している手法の出典であり、AlignAtt4LLM(IWSLT 2026)のように新しい成果が順次取り込まれている。長期運用するなら、リリースノートだけでなくどの手法が入れ替わったかを見ておくと、遅延や確定タイミングの挙動が変わった理由を追いやすい。
アーキテクチャ:FastAPI+WebSocketで構成される配信系
公式が提供しているアーキテクチャ図がこの構成を端的に示している。
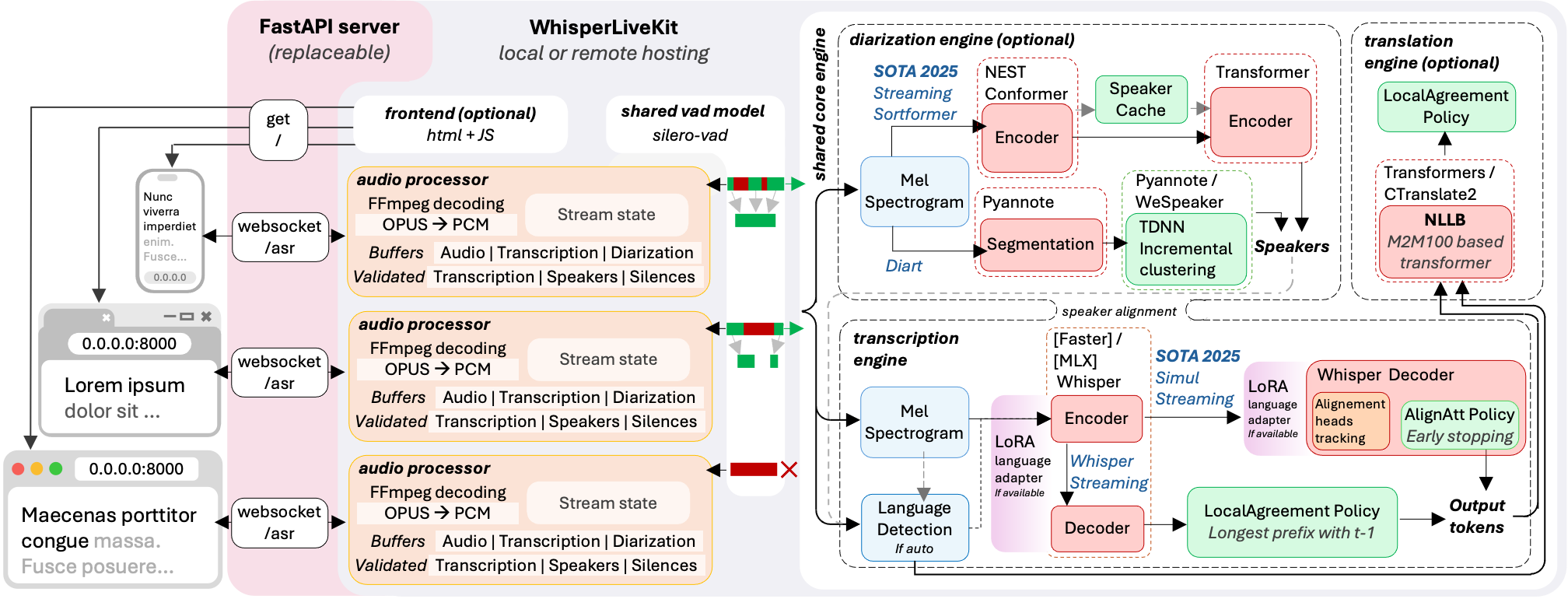
WhisperLiveKitは大きく3層に分かれている。
(ブラウザ / Chrome拡張 / アプリ)"] -->|"WebSocket"| B["FastAPIサーバー
(WhisperLiveKit)"] B --> C["VAD
(音声区間検出)"] C --> D["Streaming Engine
(SimulStreaming / LocalAgreement)"] D --> E{"ASR Backend"} E --> F["MLX-Whisper
(Apple Silicon)"] E --> G["Faster-Whisper
(CUDA最適化)"] E --> H["Vanilla Whisper"] E --> I["OpenAI API"] E --> J["Voxtral Mini
(Mistral 4B)"] D --> K["話者識別
(Sortformer / Diart)"] D --> L["翻訳
(NLLB-200, 200言語)"] K --> M["WebSocket Response
(speaker_id + text)"] L --> M M --> A
入力音声はブラウザのマイクからWebSocket経由でサーバーに届き、VAD(Voice Activity Detection)で発話区間を切り出した後、ASRバックエンドが文字起こしを行う。並行して話者識別モデルが「誰が話しているか」を推定し、結果をマージしてクライアントへ返す。すべてがストリーミング処理で動くため、入力から出力までの遅延が極小化される。
6つのバックエンド:Apple Silicon・CUDA・CPU・API混在対応
WhisperLiveKitの大きな魅力はバックエンドの自由度だ。1つのフロントエンドコードに対し、状況に応じてバックエンドを切り替えられる。
| バックエンド | 用途 | 強み |
|---|---|---|
| MLX-Whisper | Apple Silicon(M1/M2/M3) | Macで最高速、消費電力低 |
| Faster-Whisper | NVIDIA GPU | CUDA最適化、量子化対応 |
| Vanilla Whisper | CPU/GPU汎用 | OpenAI公式実装、最大互換性 |
| OpenAI API | クラウド経由 | 自前GPUなしでも動作 |
| Voxtral Mini | Mistral AI製、4Bパラメータ | 多言語性能、Hugging Face配布 |
| HuggingFace Transformers | カスタムモデル | LoRA/独自Fine-tuning対応 |
開発時はOpenAI APIで素早く検証し、本番ではFaster-Whisper+A10/A100に切り替えるという運用が容易だ。Apple Silicon MacBookで開発・デモする場合はMLX-Whisperで電池の持ちと速度を両立できる。
クイックスタート:3コマンドで動かす
Docker(GPU版)
git clone https://github.com/QuentinFuxa/WhisperLiveKit.git
cd WhisperLiveKit
docker build -t wlk .
docker run --gpus all -p 8000:8000 --name wlk wlk
ブラウザでhttp://localhost:8000にアクセスすればデモUIが表示される。マイクボタンを押せばその場で文字起こしが始まる。
Docker(CPU版)
GPUがない環境ではCPU版が用意されている。
docker build -f Dockerfile.cpu -t wlk --build-arg EXTRAS="cpu" .
docker run -p 8000:8000 --name wlk wlk
pipでインストール
ローカルPython環境にインストールする場合は次のとおり。
# 基本インストール
pip install whisperlivekit
# Apple Silicon用
pip install -e ".[mlx-whisper]"
# CPU PyTorch
pip install -e ".[cpu]"
# CUDA 12.9
pip install -e ".[cu129]"
# 翻訳機能(NLLB-200)追加
pip install -e ".[translation]"
# 話者識別(Sortformer)追加
pip install -e ".[diarization-sortformer]"
サーバー起動はCLIで一発。
# 英語、baseモデル
wlk --model base --language en
# 日本語、large-v3モデル
wlk --model large-v3 --language ja
# 自動言語検出+話者識別+ホスト公開
wlk --model medium --diarization --host 0.0.0.0 --port 8000
CLI機能:文字起こし・モデル管理・ベンチマークが揃う
WhisperLiveKitは単なるサーバーではなく、Ollamaライクな運用CLIを備える。
ファイルからの文字起こし
# 単純な文字起こし
wlk transcribe meeting.wav
# SRT字幕として出力
wlk transcribe --format srt podcast.mp3 -o podcast.srt
# 話者識別付き
wlk transcribe --diarization interview.m4a -o interview.txt
モデル管理
# インストール済みモデル一覧
wlk models
# モデルのダウンロード
wlk pull large-v3
# モデルの削除
wlk rm large-v3
ベンチマーク機能
# 標準ベンチマーク
wlk bench
# 特定バックエンドでベンチマーク
wlk bench --backend faster-whisper --model large-v3
ベンチマーク結果は遅延(latency)と単語誤認識率(WER)の両軸で評価される。プロジェクトのREADMEには英仏のベンチマーク散布図も掲載されており、「どのバックエンド×どのポリシー×どのモデル」が最適かを論理的に選べる。
話者識別(ダイアライゼーション)の実装
会議文字起こしでは「誰が話したか」が決定的に重要だ。WhisperLiveKitは2つのダイアライゼーション手法から選択できる。
| 手法 | 特徴 | ライセンス |
|---|---|---|
| Streaming Sortformer | NVIDIA研究、リアルタイム高精度 | Apache-2.0系 |
| Diart | pyannote.audioベース、軽量 | MIT |
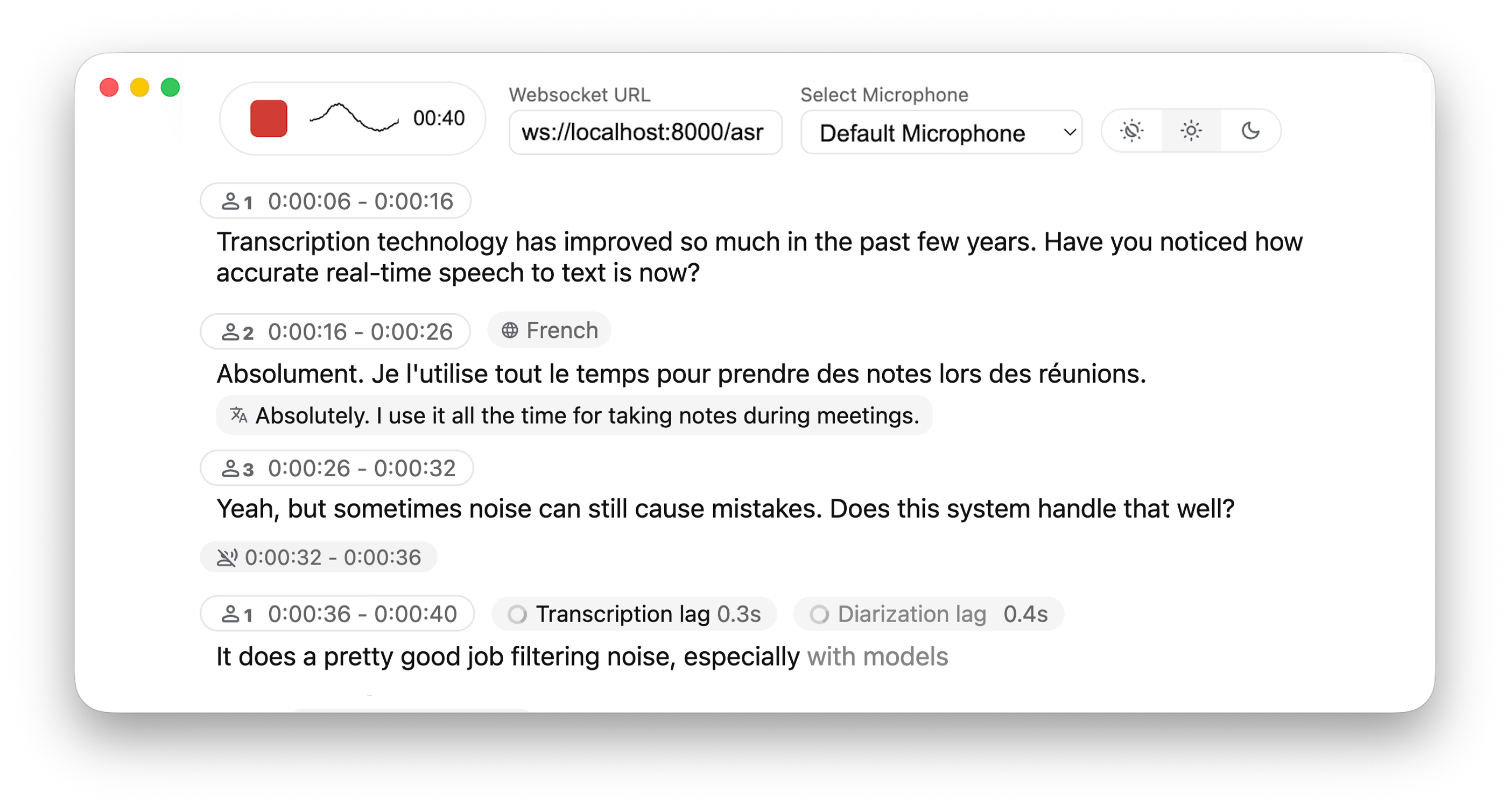
ストリーミング対応している点が重要で、録音終了後に一括処理するのではなく話している最中から「Speaker A」「Speaker B」のラベルが付与される。
# Python APIでの話者識別有効化
from whisperlivekit import AudioProcessor, TranscriptionEngine
engine = TranscriptionEngine(
model_size="medium",
diarization=True, # 話者識別ON
lan="ja"
)
processor = AudioProcessor(transcription_engine=engine)
results = await processor.create_tasks()
async for result in results:
print(f"[{result.speaker}] {result.text}")
これだけで会議録のドラフトが自動生成できる。Notion・Slackへの自動送信を組み合わせれば、議事録ゼロタッチ運用が現実になる。
OpenAI/Deepgram互換APIで既存システムからの移行が容易
WhisperLiveKitの実用面で大きな魅力がAPI互換性だ。
| エンドポイント | 互換 | 用途 |
|---|---|---|
/v1/audio/transcriptions |
OpenAI Whisper API | REST、ファイル単発 |
/v1/audio/translations |
OpenAI同様 | 翻訳付き |
/asr |
Deepgram WebSocket | リアルタイムストリーミング |
| ネイティブWebSocket | 独自 | より柔軟な制御 |
つまりOpenAI APIで動いている既存アプリのエンドポイントを書き換えるだけで、セルフホストWhisperLiveKitに切り替えられる。コストとプライバシーの両面で大きな移行メリットがある。
ベンチマーク:英仏での実測値
公式リポジトリには英語・フランス語のリアルタイムベンチマーク散布図が公開されている。
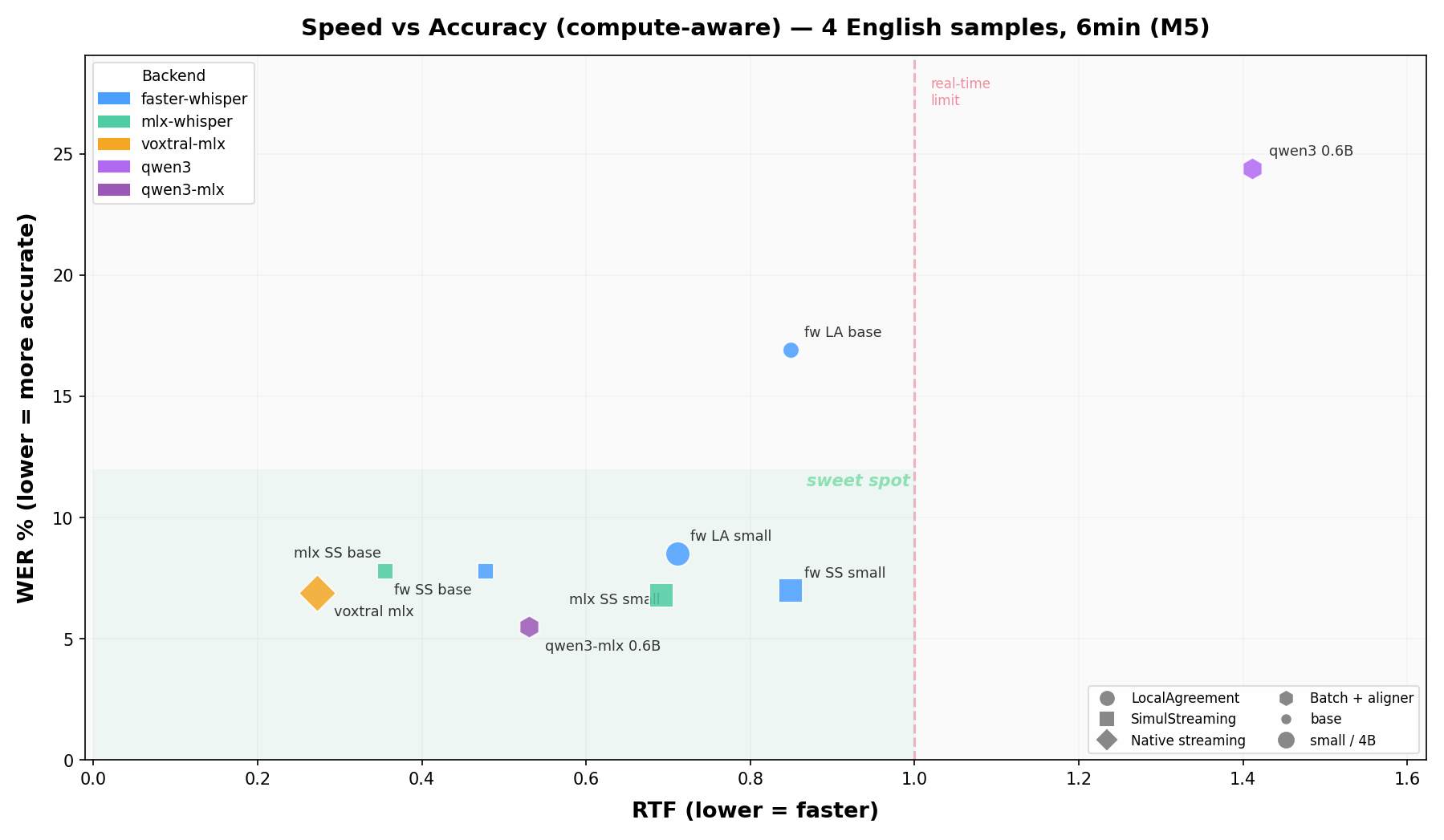
横軸が遅延、縦軸が単語誤認識率(WER)。SimulStreaming(AlignAtt)+ Faster-Whisper(large-v3)の組み合わせが、低遅延と高精度を両立しているのが視覚的に分かる。フランス語版でも同様の傾向が確認できる。
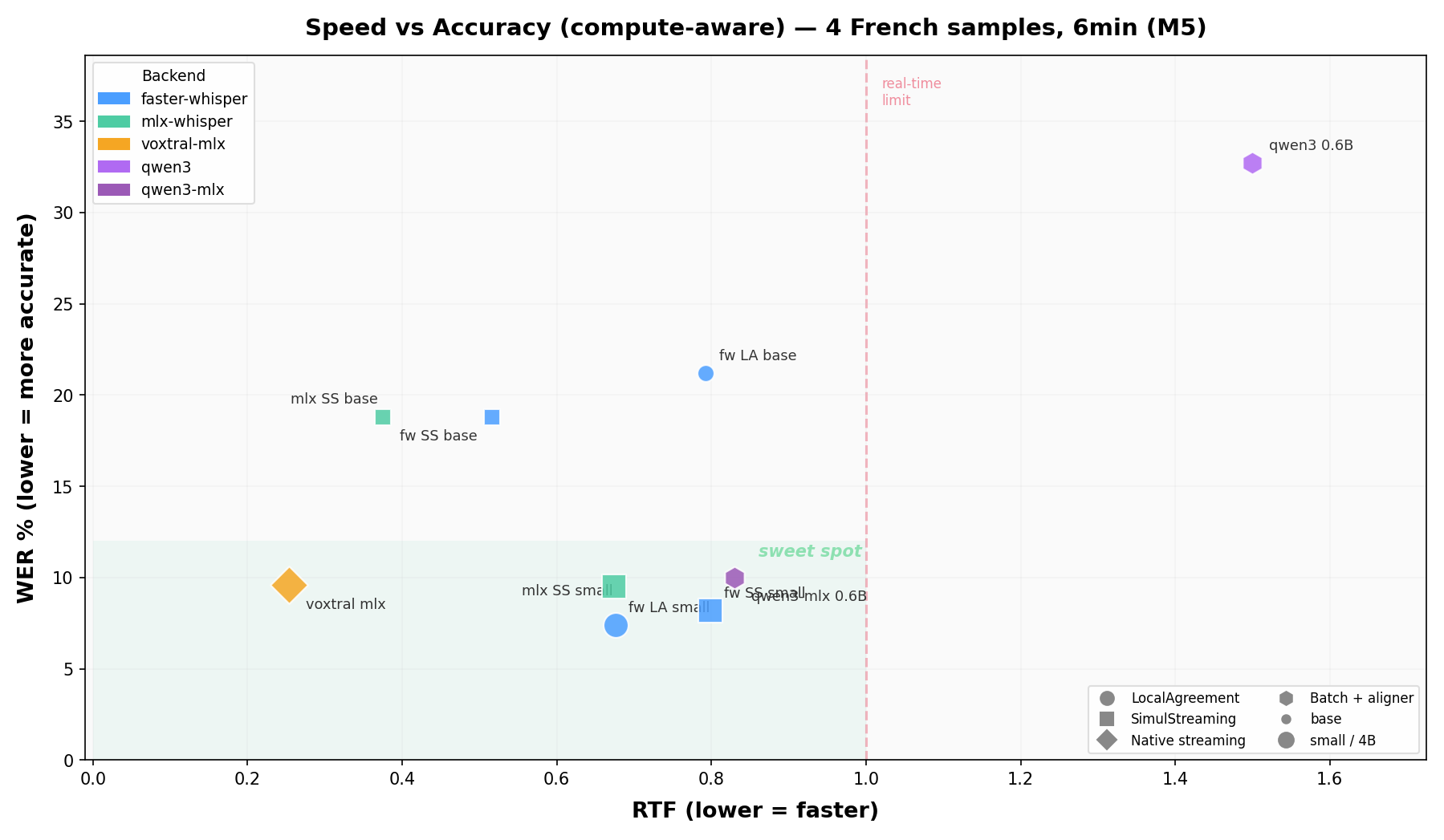
これらは公式が再現可能なスクリプトで生成しており、自分の環境(GPU、モデル、言語)で再実行することで信頼性の高い選定が可能だ。
Chrome拡張:任意のWebページ音声を文字起こし
WhisperLiveKitにはオプションでChrome拡張が付属する。Google Meet・Zoom・YouTube・TikTokなどブラウザで再生されるあらゆる音声を、WhisperLiveKitサーバーに送って文字起こしできる。

利用シナリオ:
- Google Meetの文字起こしを社内サーバーで完結(議事録の外部漏えい防止)
- YouTube動画のライブ字幕を200言語に翻訳
- 海外Webinarをリアルタイムで日本語化
Chrome拡張から見えるサーバーは自分のWhisperLiveKitなので、音声データが第三者に渡らない点が企業利用での大きなアドバンテージだ。
類似ツールとの比較:Whisper.cpp・Vosk・Deepgramと何が違うか
セルフホスト音声認識の領域では複数の選択肢がある。
| ツール | 形態 | 強み | 弱み |
|---|---|---|---|
| WhisperLiveKit | OSS(Apache-2.0) | リアルタイム最適化+話者識別+多バックエンド | Whisper精度に依存 |
| Whisper.cpp | OSS(MIT) | C++実装、低リソース、組み込み向け | リアルタイム制御は別途実装が必要 |
| Vosk | OSS(Apache-2.0) | 軽量、20言語対応、モバイル対応 | 精度はWhisper系に劣る |
| Deepgram | SaaS | 高精度・高速、運用不要 | 月額コスト、データ越境 |
| AssemblyAI | SaaS | 話者識別・要約APIまで統合 | 同上 |
| OpenAI API | SaaS | 公式、簡単 | リアルタイム未対応、レート制限 |
「精度・話者識別・リアルタイム・セルフホスト・多言語」を1つで満たすのはWhisperLiveKitくらいだ。SaaSの便利さを諦められない場合でも、開発・テスト環境用にWhisperLiveKitを置いておくと費用最適化に効く。日本語の音声認識精度比較はInsanely Fast Whisper完全ガイド:OpenAI Whisperを最大23倍高速化するCLIツールの使い方も併せて参照したい。
セルフホストすべきか|OpenAI API と比べる3つの判断軸
「OpenAI の文字起こしAPIに払い続けるか、自前で立てるか」は、精度だけでは決められない。WhisperLiveKit を検討する際に効いてくる軸は3つある。
| 判断軸 | セルフホスト(WhisperLiveKit)が有利 | API利用が有利 |
|---|---|---|
| データの置き場所 | 音声を外部に出せない(会議・医療・法務・社内議事録) | 制約が無い |
| 利用量とコスト構造 | 常時稼働・長時間・多拠点で従量課金が積み上がる | 利用が散発的で、GPU/運用コストのほうが高くつく |
| リアルタイム性の要件 | 発話中に単語単位で出したい(字幕・同時通訳的用途) | 録音後に一括で文字起こしできれば十分 |
3軸のうち2つ以上が「セルフホスト有利」に倒れたときが導入の目安。逆に「たまに録音ファイルを文字起こしする」だけならAPIのほうが総コストは低い。GPUの確保・モデル更新・障害対応という運用コストは、従量課金の請求書には現れないが確実に存在する。
なお同じ「Whisperを速くする」系でも狙いが違う。バッチ処理をとにかく速く終わらせたいなら Insanely Fast Whisper完全ガイド:OpenAI Whisperを最大23倍高速化 の系統が向き、発話しながら出力したいなら本記事のストリーミング系になる。音声を「出す」側(TTS)まで含めて構成するなら RealtimeTTS:テキスト音声変換オープンソースで実現するLLM応答のゼロ遅延音声化手法 と組み合わせると、入力から応答までを自前で閉じられる。
想定ユースケースと注意点
向いているシーン
- 社内会議の自動議事録:データを外部に出せない法務・金融・医療系
- コールセンターのリアルタイム字幕:オペレーター支援、品質モニタリング
- 聴覚障害者向け会議室:ライブ字幕で参加バリアを下げる
- 海外Webinarの同時通訳:NLLB-200で200言語へリアルタイム翻訳
- ポッドキャスト・YouTube動画の字幕生成:CLI batch運用
注意すべきポイント
- GPU推奨:CPU only動作はlarge-v3で実用的でない。会議用途なら最低RTX 3060/4060クラスを推奨
- 日本語精度はlarge-v3以上が現実的:base/smallでは固有名詞・専門用語の誤認識が多い
- 話者識別は「ベター推定」:完全に正確とは限らず、訂正フェーズが必要
- WebSocket帯域:1接続で数十kbps、大規模配信ではロードバランサ必須
Local LLMツールガイド的な観点では、自社GPUで完結する音声処理基盤が組めることが大きな差別化要素になる。
モデルサイズ別の選定ガイド
WhisperLiveKitで選べるWhisperモデルは6サイズ。用途・GPU・要求精度から逆算すると次の選定軸になる。
| モデル | パラメータ | VRAM目安 | 速度 | 想定用途 |
|---|---|---|---|---|
| tiny | 39M | 1GB | 最速 | 検証・低スペックPC |
| base | 74M | 1GB | 高速 | 開発デモ、英語短文 |
| small | 244M | 2GB | 中速 | 多言語・カジュアル用途 |
| medium | 769M | 5GB | 中速 | 会議・実務での標準 |
| large | 1550M | 10GB | 低速 | 高精度要求・公開字幕 |
| large-v3 | 1550M | 10GB | 低速 | 2026年現在のベスト精度 |
「日本語×会議×話者識別×実用」なら large-v3 + Faster-Whisper + Sortformer が現時点のスイートスポット。GPU側はRTX 4070 Ti(12GB)以上を確保すると余裕がある。
運用Tips:本番投入で陥りがちな罠
1. WebSocketのプロキシ設定漏れ
Nginx/Cloudflare等の前段リバースプロキシでWebSocket通信を許可していないと「最初の数秒だけ動いて切れる」現象が起きる。
# Nginx設定例
location /asr {
proxy_pass http://localhost:8000;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_read_timeout 3600s;
proxy_buffering off;
}
proxy_buffering offが抜けるとストリーミングがバッファされ低遅延が損なわれる。
2. GPUのVRAM枯渇
複数の同時セッションを受け付けると、Whisperモデルの推論メモリで簡単にVRAMが枯渇する。FastAPIのWorkerを増やすのではなく1Workerで複数接続を捌く設計が王道だ。Faster-Whisperのint8_float16量子化を使えばVRAM消費を半分以下に抑えられる。
3. 話者識別の初期化遅延
Sortformer/Diartは初回ロードに5〜15秒かかる。uvicornの起動時に事前ロードする--lifespan startupオプションでウォームアップしておくと、初回ユーザー体験が大きく改善する。
まとめ:「OpenAI APIに払い続ける必要があるか」を見直す節目
OpenAI Whisper APIは便利だが、月単位のコストとデータの越境という構造課題は変わらない。WhisperLiveKitはこの構造に対し、「セルフホスト×リアルタイム×話者識別×OpenAI互換」という4つの武器で代替候補を提示する。Apache-2.0で改変も商用利用も自由、★10.2kの実績、Docker一発起動という導入の手軽さを考えれば、まずは検証環境で試してみない理由がない。
最初のステップはdocker run --gpus all -p 8000:8000 wlkだけだ。マイクで30秒喋ってみて、その文字起こし精度と遅延を体感してから、本格採用の判断をすれば遅くない。
参照ソース
- QuentinFuxa/WhisperLiveKit (GitHub) - 本体リポジトリ
- WhisperLiveKit Releases - 最新リリース内容(v0.2.20)
- Whisper Streaming (academic paper) - SimulStreamingアルゴリズムの一次論文
- NVIDIA Sortformer - 採用されている話者識別モデル
- pyannote/diart - Diartの上流リポジトリ
- NLLB-200 (Meta AI) - 採用されている翻訳モデル