ChatGPTに質問を投げると数秒で回答が返ってくる。その裏側で動いているのがLLM(Large Language Model=大規模言語モデル)だ。
2026年4月時点で、LLMのパラメータ数は1兆を超え(Kimi K2.6)、APIの価格は1年前の5分の1に下がり、日本語特化モデルはGPT-4oのベンチマークスコアを上回った。しかし「LLMとは」で検索して出てくる記事のほとんどは、概念の説明で終わっている。
本記事は「LLMとは何か」を解説するだけでなく、Ollamaで実際に動かし、量子化でメモリを70%削減し、用途に応じてAPIとローカル実行を使い分けるところまでカバーする。自分の手で試せる実践型の完全ガイドだ。
- LLMは「次の単語を確率的に予測する」自己回帰モデル。Transformer×MoEで1兆パラメータ時代へ。2026年の主要モデルは性能・価格・ライセンスで比較できる
- 日本語LLMはGPT-4oを超えた(LLM-jp-4:MT-Bench 7.82 / Rakuten AI 3.0:JamC-QA首位)。商用利用ライセンスも確認が必要
- ローカル実行はOllama 1コマンドで7B〜70Bが動く。Q4_K_M量子化で約75%軽量化、API料金は1年で約80%下落しコストの見極めが鍵
LLMとは——「次の単語を予測する」仕組みが世界を変えた
LLMとは「Large Language Model(大規模言語モデル)」の略称で、膨大なテキストデータを学習し、与えられた文脈に対して次に来る単語(トークン)を確率的に予測するAIモデルだ。ChatGPT、Claude、Geminiといったサービスはすべて、基盤にLLMを使っている。
生成AIとの違い
「生成AI」と「LLM」は混同されやすいが、両者の関係は明確だ。
| 概念 | 対象 | 具体例 |
|---|---|---|
| 生成AI(総称) | テキスト・画像・音声・動画など | Midjourney(画像)、Suno(音楽)、Sora(動画) |
| LLM(生成AIの一種) | テキスト(言語)に特化 | GPT-5.4、Claude Opus 4.6、Gemini 3.1 Pro |
つまりLLMは生成AIのサブカテゴリであり、「文章を扱う生成AI」がLLMだと考えればよい。
次トークン予測の原理
LLMの動作原理はシンプルだ。「東京の天気は」という入力に対し、学習データから「明日」「晴れ」「今日」といった候補を確率順にランク付けし、最も確率の高いトークンを1つ選ぶ。これを繰り返して文章全体を生成する。
入力: "東京の天気は"
予測: "明日" (0.23) → "晴れ" (0.18) → "今日" (0.15) → ...
選択: "明日"
次の入力: "東京の天気は明日"
予測: "は" (0.31) → "も" (0.22) → "、" (0.19) → ...
このプロセスを「自己回帰(Autoregressive)生成」と呼ぶ。シンプルな原理だが、学習データが数兆トークンに達し、パラメータ数が数千億を超えると、翻訳・プログラミング・論理的推論まで高精度にこなす能力が「創発(Emergence)」する。これがLLMの核心だ。
(Tokenization)"] B --> C["埋め込み
(Embedding)"] C --> D["Transformerブロック
×N層"] D --> E["次トークン
確率分布"] E --> F["サンプリング
(top-p / temperature)"] F --> G["出力トークン"] G -->|"自己回帰ループ"| C
LLMの学習プロセス
LLMの構築は2段階で行われる。
事前学習(Pre-training)では、インターネット上のテキスト・書籍・コードなど数兆トークンを使い、「次の単語を予測する」タスクを繰り返す。この段階で言語の文法、知識、推論能力の基盤が形成される。
微調整(Fine-tuning)では、人間のフィードバックを使って出力を調整する。RLHF(Reinforcement Learning from Human Feedback)が代表的な手法で、「有害な回答を避ける」「指示に正確に従う」といった振る舞いを学習する。ChatGPTやClaudeが単なるテキスト補完ではなく「アシスタント」として機能するのは、この微調整のおかげだ。
LLMのアーキテクチャを図解——TransformerからMoEへの進化
LLMの中核技術は2017年のGoogle論文「Attention Is All You Need」で提案されたTransformerアーキテクチャだ。そして2024年以降、計算効率を劇的に高めるMoE(Mixture-of-Experts)が主流になりつつある。
Self-Attention:文脈を読む仕組み
Transformerの最大の革新はSelf-Attention(自己注意)機構だ。入力テキストの各トークンが、他のすべてのトークンとの関連度を計算し、文脈に応じて重要な情報に「注意」を向ける。
たとえば「彼女は銀行の川岸で釣りをしていた」という文で、「銀行」の意味を「金融機関」ではなく「川の岸」と解釈できるのは、Self-Attentionが「川岸」「釣り」との関連度を高く計算するからだ。
Query(Q) × Key(K)^T / √d_k → Attention Weights(注意重み)
Attention Weights × Value(V) → Context-aware Representation(文脈考慮済みの表現)
この計算を複数の「ヘッド」で並列実行するのがMulti-Head Attentionであり、各ヘッドが構文的関係・意味的文脈・位置情報など異なる観点を担当する。
MoE:2026年の主流アーキテクチャ
2026年のフロンティアモデルの多くはMoE(Mixture-of-Experts)を採用している。全パラメータのうち推論時にアクティブ化するのは一部(5〜15%)だけで、「ルーター(Gate Network)」が入力に応じて最適なExpertを動的に選択する。
(Router)"] B -->|"選択"| C["Expert 1
(数学推論)"] B -->|"選択"| D["Expert 2
(コード生成)"] B -.->|"非活性"| E["Expert 3
(言語理解)"] B -.->|"非活性"| F["...
Expert 128+"] C --> G["上位K個の出力を
重み付き合算"] D --> G G --> H["次のTransformerブロックへ"] style C fill:#10b981,color:#fff style D fill:#10b981,color:#fff style E fill:#94a3b8 style F fill:#94a3b8
| アーキテクチャ | 特徴 | 代表モデル | 推論コスト |
|---|---|---|---|
| Dense(密) | 全パラメータを毎回使用 | GPT-5.4、Gemini 3.1 Pro | 高い |
| MoE(疎) | 一部のExpertのみ活性化 | Llama 4 Maverick、DeepSeek V3、Kimi K2.6 | 低い(同性能比) |
| ハイブリッド | Transformer + SSM(Mamba) | Jamba | 長文で効率的 |
なぜMoEが主流になったのか:たとえばKimi K2.6は総パラメータ1兆個だが、推論時にアクティブなのは320億個(約3%)だ。つまり「知識量は1兆パラメータ級だが、計算コストは320億パラメータ級」という効率を実現している。同様に、Llama 4 Maverickは400B / 17Bアクティブ、DeepSeek V3は671B / 37Bアクティブで動作する。MoEの登場で、「パラメータ数=計算コスト」という図式は過去のものになった。
2026年の主要LLMモデル比較——性能・価格・ライセンス一覧
2026年4月時点で、LLMは「クローズドモデル(API提供のみ)」と「オープンウェイト(重み公開)」に大別される。以下に主要モデルを網羅する。
クローズドモデル
| モデル | 開発元 | コンテキスト長 | API入力 / 出力($/1Mトークン) | 強み |
|---|---|---|---|---|
| Claude Opus 4.6 | Anthropic | 1M | $5.00 / $25.00 | SWE-bench 80.8%、コーディング最強 |
| Claude Sonnet 4.6 | Anthropic | 200K | $3.00 / $15.00 | コスパ×性能のバランス |
| GPT-5.4 | OpenAI | 1M | $2.50 / $15.00 | マルチモーダル統合 |
| Gemini 3.1 Pro | 1M | $1.25 / $10.00 | GPQA Diamond 94.3%、科学推論 | |
| Gemini 2.5 Flash | 1M | $0.30 / $2.50 | 低コスト×高品質 |
オープンウェイトモデル
| モデル | 開発元 | 総パラメータ / アクティブ | ライセンス | 特徴 |
|---|---|---|---|---|
| Llama 4 Maverick | Meta | 400B / 17B (MoE) | Llama License | 128 Expert、ネイティブマルチモーダル |
| Llama 4 Scout | Meta | 109B / 17B (MoE) | Llama License | 10Mコンテキスト、単一H100で動作(Int4) |
| DeepSeek V3.1 | DeepSeek | 671B / 37B (MoE) | MIT | Thinking/Non-thinkingモード切替 |
| Qwen 3-235B-A22B | Alibaba | 235B / 22B (MoE) | Apache 2.0 | 119言語対応、36兆トークン学習 |
| Kimi K2.6 | Moonshot AI | 1T / 32B (MoE) | Modified MIT | SWE-Bench ProでGPT-5.4超え |
| Mistral Large 3 | Mistral AI | 675B / 41B (MoE) | Apache 2.0 | 40+言語、256Kコンテキスト |
ベンチマーク比較(2026年4月時点)
従来の主要ベンチマーク(MMLU、HumanEval、GSM8K)はフロンティアモデルが90%超で飽和し、差別化指標として機能しなくなった。現在はより難度の高いベンチマークが使われている。
| ベンチマーク | 測定対象 | トップモデル | スコア |
|---|---|---|---|
| GPQA Diamond | 専門レベル科学推論 | Gemini 3.1 Pro | 94.3% |
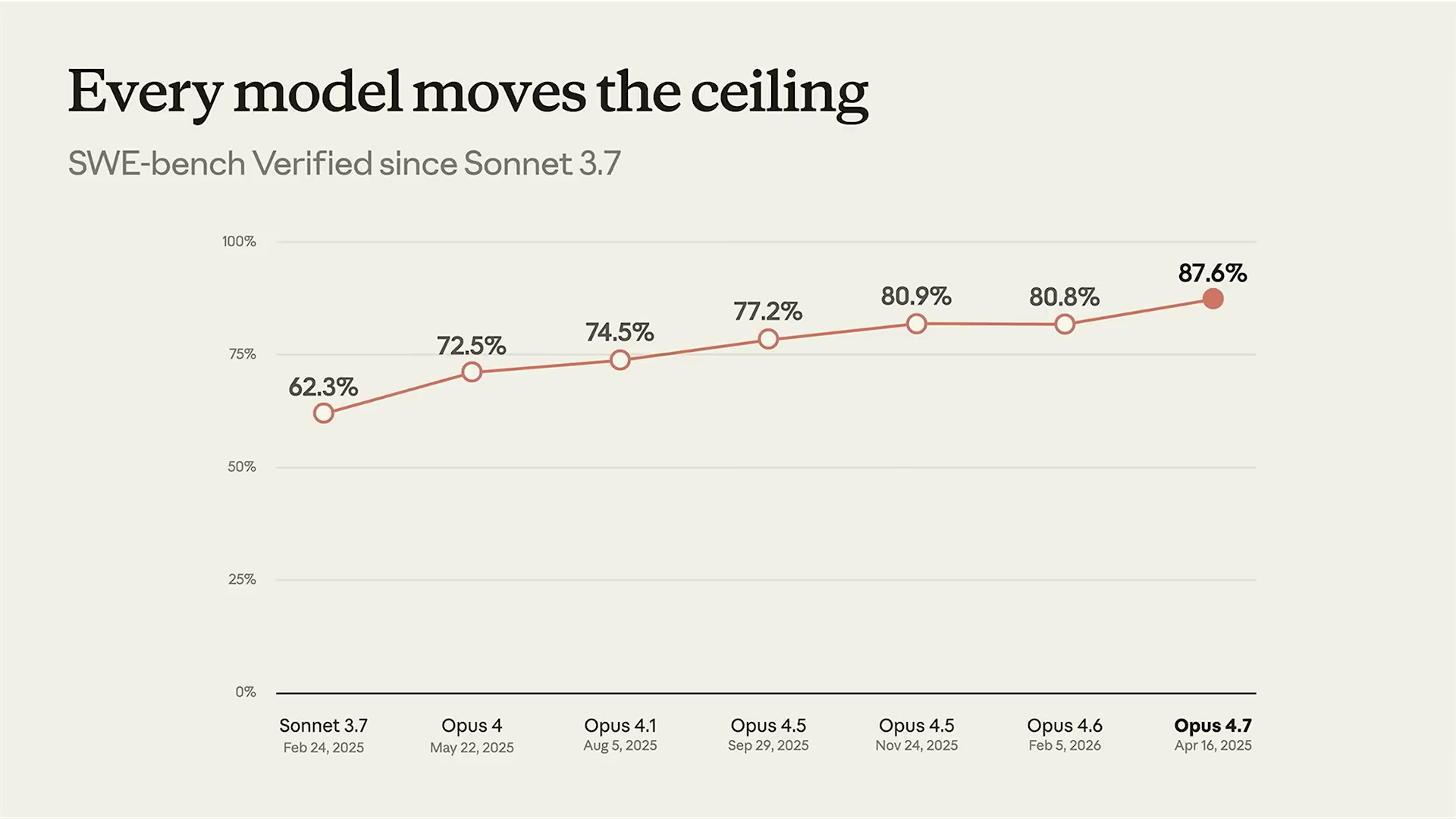
| SWE-bench Verified | ソフトウェアエンジニアリング | Claude Opus 4.6 | 80.8% |
| Chatbot Arena Elo | 総合ユーザー評価 | Claude Opus 4.6 Thinking | 1504 |
| MMLU(飽和) | 学術知識 | 複数モデルが90%超 | — |
| AIME 2025 | 数学的推論 | 複数モデルが80%超 | — |
2026年のLLM選定で重要なのは「最強の万能モデル」を探すことではなく、用途に応じて使い分けることだ。コーディングならClaude、科学推論ならGemini、コスト優先ならDeepSeek——という判断基準が実務では有効だ。
日本語LLMの実力——GPT-4oを超えた国産モデルの全貌
2026年、日本語LLMは大きな転換点を迎えた。国産モデルが日本語ベンチマークでGPT-4oを上回る結果を示し始めている。これは経済産業省のGENIACプロジェクトや国立情報学研究所(NII)の長年の研究が実を結んだ成果だ。
LLM-jp-4(国立情報学研究所)
国立情報学研究所(NII)が2026年4月3日にオープンソース公開したLLM-jp-4は、8.6Bパラメータの密モデルと、32B総パラメータ / 3BアクティブのMoEモデルの2種類を提供する。
| 指標 | LLM-jp-4 32B-A3B | GPT-4o |
|---|---|---|
| 日本語MT-Bench | 7.82 | 7.29 |
| 英語MT-Bench | 7.86 | — |
| 学習データ | 12兆トークン | 非公開 |
| ライセンス | オープン | クローズド |
学習データにはインターネット公開データに加え、政府・国会文書と合成データが含まれる。前世代のLLM-jp-3.1と比較して学習データ量は6倍に拡大された。NII は2026年度中に332B総パラメータ / 31BアクティブのMoEモデルのリリースを予定している。
Rakuten AI 3.0(楽天)
楽天が2026年3月にリリースしたRakuten AI 3.0は、671B総パラメータ / 37BアクティブのMoE構成で、Apache 2.0ライセンスの完全オープンソースとして公開されている。経済産業省のGENIACプロジェクトの成果物だ。
| 指標 | Rakuten AI 3.0 | GPT-4o |
|---|---|---|
| JamC-QA | 76.9 | 74.7 |
| MMLU-ProX(日本語) | 71.7 | 64.9 |
| ライセンス | Apache 2.0 | クローズド |
楽天はこのモデルを自社エコシステム全体に展開し、90%のコスト削減を目標としている。
その他の注目国産モデル
| モデル | 開発元 | 特徴 |
|---|---|---|
| tsuzumi 2 | NTT | デジタル庁「ガバメントAI」に採用(2026年3月)。行政文書処理に特化 |
| PLaMo 2.2 Prime 31B | Preferred Networks | GPT-5.1相当(JFBench)。150+自治体で展開中 |
日本政府のAI投資
日本政府は2025年12月にAI・半導体分野へ5年間で1兆円を投資する計画を発表した。GENIACプロジェクトを通じて日本企業30社以上が主要LLMバリアントを開発しており、国産モデルのエコシステムは急速に拡大している。
LLMを自分のPCで動かす——Ollama・vLLM・llama.cpp実践ガイド
ここからが本記事の独自パートだ。LLMは「APIを叩く」だけでなく、自分のPCやサーバーでローカル実行できる。データをクラウドに送らないプライバシー保護、API料金ゼロのコスト削減、ネットワーク不要のオフライン利用——ローカル実行のメリットは大きい。
2026年時点でローカルLLM実行の三大ツールはOllama、vLLM、llama.cppだ。それぞれ設計思想が異なるため、用途に応じた選択が重要になる。
Ollamaで5分で始める
OllamaはローカルLLM実行の定番ツールで、ワンコマンドでモデルのダウンロードから推論まで完結する。200以上のモデルがライブラリに登録されており、ollama run モデル名 だけですぐに対話を始められる。
# インストール(macOS / Linux)
curl -fsSL https://ollama.com/install.sh | sh
# モデルをダウンロードして即実行
ollama run llama3.2
# → プロンプトが表示され、対話が始まる
# 日本語に強いQwen3を試す
ollama run qwen3:8b
# OpenAI互換APIとしても使える(他のツールとの連携に便利)
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3:8b",
"messages": [{"role": "user", "content": "LLMとは何か、3行で説明して"}]
}'
![]()
vLLMで本番サーバーを立てる
vLLMは高スループットLLM推論エンジンで、本番環境での大量リクエスト処理に最適化されている。コア技術のPagedAttentionにより、OSの仮想メモリと同じ発想でKVキャッシュを管理し、HuggingFace Transformers比で最大24倍のスループットを実現する。128並列リクエスト時にはOllamaの3.23倍の性能を発揮する。vLLMの詳細な使い方と導入手順も合わせて参照してほしい。
# インストール
pip install vllm
# OpenAI互換APIサーバーとして起動(GPU 2枚でテンソル並列)
vllm serve meta-llama/Llama-4-Scout-17B-16E-Instruct \
--tensor-parallel-size 2 \
--max-model-len 32768
# Python SDKから利用(OpenAIライブラリがそのまま使える)
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy")
response = client.chat.completions.create(
model="meta-llama/Llama-4-Scout-17B-16E-Instruct",
messages=[{"role": "user", "content": "Pythonでフィボナッチ数列を実装して"}]
)
print(response.choices[0].message.content)
llama.cppでエッジ推論
llama.cppはC/C++のみで実装されたLLM推論ランタイムだ。外部依存がなく、ラップトップからRaspberry Piまであらゆるデバイスで動作する。GGUFフォーマットの量子化モデルを直接実行でき、複数デバイスを繋いで分散推論を実現するDistributed Llamaのバックエンドとしても利用されている。
# ビルド(依存ライブラリ不要)
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
cmake -B build && cmake --build build --config Release
# GGUF形式のモデルを直接実行
./build/bin/llama-cli \
-m models/qwen3-8b-q4_k_m.gguf \
-p "日本の首都は" \
-n 128
ツール選定フローチャート
動かしたい"] --> B{"用途は?"} B -->|"個人利用・開発
プロトタイピング"| C["Ollama"] B -->|"本番サーバー
高並列リクエスト"| D["vLLM"] B -->|"エッジデバイス
組み込み・IoT"| E["llama.cpp"] C --> F["ollama run qwen3:8b"] D --> G["vllm serve model-name"] E --> H["./llama-cli -m model.gguf"] style C fill:#10b981,color:#fff style D fill:#6366f1,color:#fff style E fill:#f59e0b,color:#fff
| 項目 | Ollama | vLLM | llama.cpp |
|---|---|---|---|
| セットアップ | 1コマンド | pip install | 要ビルド |
| 単一リクエスト速度 | ○ | ○ | ○ |
| 高並列処理 | △ | ◎(24倍) | △ |
| メモリ管理 | 静的 | 動的(PagedAttention) | 手動 |
| エッジ対応 | △ | × | ◎ |
| OpenAI互換API | ○ | ◎ | ○ |
| 推奨用途 | 開発・学習 | 本番デプロイ | エッジ・IoT |
LLM量子化で70%軽量化——GGUF・GPTQ・AWQの選び方
ローカルでLLMを動かすとき、最大のボトルネックはメモリだ。たとえばQwen3の8Bモデルは、FP16(16ビット浮動小数点)で約16GBのメモリを要求する。一般的なノートPCでは厳しい。
ここで登場するのが量子化(Quantization)だ。モデルの重みパラメータの精度(ビット数)を下げることで、ファイルサイズとメモリ使用量を50〜80%削減しつつ、実用的な品質を維持する技術だ。
GGUFの量子化レベル一覧
ローカル実行で最も広く使われるのがGGUF形式だ。以下がビット数ごとの比較表になる。
| 量子化レベル | ビット数 | FP16比サイズ | 品質 | 推奨シーン |
|---|---|---|---|---|
| Q8_0 | 8-bit | 約50%削減 | ほぼ無損失 | VRAMに余裕がある場合 |
| Q6_K | 6-bit | 約62%削減 | ほぼ無損失 | 高品質かつメモリ節約 |
| Q5_K_M | 5-bit | 約69%削減 | 95-99%保持 | 品質とサイズのスイートスポット |
| Q4_K_M | 4-bit | 約75%削減 | 主流の選択肢 | ほとんどのタスクで許容 |
| Q3_K_S | 3-bit | 約81%削減 | 顕著な品質低下 | 極限のメモリ制約時 |
迷ったらQ4_K_MまたはQ5_K_Mを選べば間違いない。Q4_K_Mは「とにかくメモリを節約したい」場合、Q5_K_Mは「品質を少しでも高く保ちたい」場合の選択肢だ。
# Ollamaで量子化モデルを指定して実行
ollama run llama3.2:8b-q4_K_M # 4bit量子化版(約4.5GB)
ollama run llama3.2:8b-q5_K_M # 5bit量子化版(約5.5GB)——品質重視ならこちら
# HuggingFaceからGGUFを直接ダウンロードしてllama.cppで実行
wget https://huggingface.co/bartowski/Qwen3-8B-GGUF/resolve/main/Qwen3-8B-Q4_K_M.gguf
./build/bin/llama-cli -m Qwen3-8B-Q4_K_M.gguf -p "量子コンピュータとは" -n 256
GGUF・GPTQ・AWQ——3大量子化手法の使い分け
| 手法 | 特徴 | 最適環境 | 品質保持率 |
|---|---|---|---|
| GGUF | CPU/GPU両対応。ファイル単体で動作 | Ollama / llama.cpp | ~92% |
| GPTQ | GPU特化の4bit量子化。Marlinカーネルで高速化 | vLLM(CUDAサーバー) | ~90% |
| AWQ | 重要な重みを高精度で保持し品質維持 | GPU推論、創造的タスク | ~95% |
使い分けの指針はシンプルだ。
- ローカルPC(CPU/GPU混在) → GGUF(Q4_K_MまたはQ5_K_M)
- CUDAサーバーで最大スループット → GPTQ(Marlinカーネル対応)
- 品質を最優先するGPU推論 → AWQ
さらに極端な軽量化:Microsoftが開発したBitNetは1ビット(実質1.58ビット)の超低精度量子化を実現し、メモリ使用量を90%削減する。CPUだけで100Bパラメータモデルが動作する技術だが、現時点では対応モデルが限定的だ。量子化技術の最先端として注目されている。
LLMの実用ユースケースとコスト比較——API vs ローカル実行
3大ユースケース
LLMの実用場面は大きく3つに分かれる。
1. コーディングアシスタント
Claude Code、Cursor、GitHub Copilotが三大ツール。Claude Codeはターミナルからエージェント型でPR作成まで自律的に行い、SWE-benchスコアが最も高い。日常的なコード補完ではCursorの補完受入率72%が強力だ。開発者の26%以上がCopilotとClaudeを併用しているというデータもある。
2. RAG(検索拡張生成)
社内文書や法律文書など、LLMの学習データに含まれない情報を検索エンジンやベクトルDBから取得し、回答に組み込む技術だ。LLMの「ハルシネーション(幻覚)」を抑制する実用的な手法として、エンタープライズ導入が急速に進んでいる。
3. AIエージェント
LLMが自律的にツールを呼び出し、多段階のタスクを遂行する仕組みだ。2025年が「エージェント元年」と呼ばれ、2026年には企業でのAI導入率が33%から67%に倍増した。MCP(Model Context Protocol)による外部ツール連携が標準になりつつある。
API vs ローカル実行:月額コスト比較
月に100万トークン(約75万文字、書籍約2冊分)を処理する場合の月額コスト比較を示す。
| 方式 | モデル | 月額コスト(概算) | メリット | デメリット |
|---|---|---|---|---|
| API | Claude Opus 4.6 | 約$30 | 最高性能、メンテ不要 | データ外部送信 |
| API | DeepSeek V3.2 | 約$0.70 | 圧倒的低コスト | レイテンシ変動 |
| API | Gemini 2.5 Flash | 約$2.80 | 高コスパ | — |
| ローカル | Ollama + Qwen3-8B | 電気代のみ(〜$5) | プライバシー確保 | GPU推奨(8GB VRAM〜) |
| ローカル | vLLM + Llama 4 Scout | サーバー費(〜$100/月) | 高スループット | 運用コスト |
2025年から2026年でAPI料金は約80%下落した。とくにDeepSeek V3.2は入力$0.28/100万トークンで、2023年のGPT-4($30/100万トークン)の100分の1以下だ。一方、プライバシー要件が厳しい業務や月間1,000万トークン超の大量処理ではローカル実行のコストメリットが大きくなる。
選定の判断基準まとめ
- API推奨:最高性能が必要 / 処理量が少ない(月100万トークン以下) / 運用コストを最小化したい
- ローカル推奨:データを外部に出せない / 月間処理量が多い(1,000万トークン超) / オフライン要件がある
- ハイブリッド推奨:通常タスクはローカルのOllama、高難度タスクだけClaude API——という使い分けが2026年のベストプラクティスだ
関連記事
同じクラスタの入門ピラーと実践衛星をまとめて読むと、点が線につながります。
・Ollama入門2026|Mac/Windows/Linuxでローカル大規模言語モデルを動かす完全ガイド
・Ollamaとllama.cppの違い2026|ローカルLLMはどちらで動かすべきか徹底比較
・Ollama API完全ガイド2026|REST・OpenAI互換・Python/JSでローカルLLMを叩く
参照ソース
- Attention Is All You Need — Transformer原論文(Google, 2017)
- vLLM: Easy, Fast, and Cheap LLM Serving(GitHub)
- Ollama — ローカルLLM実行ツール公式サイト
- llama.cpp — C/C++製LLM推論ランタイム(GitHub)
- Llama 4 Model Card(Meta AI)
- DeepSeek-V3 Technical Report(arXiv)
- Qwen3 — Alibaba Cloud(GitHub)
- NII LLM-jp-4 プレスリリース(2026年4月)
- Rakuten AI 3.0 プレスリリース(2026年3月)
- LMSYS Chatbot Arena Leaderboard