AI論文を読みたいが、どこから手をつければいいかわからない。Transformers、RLHF、Chain of Thought、DeepSeek R1――用語は知っていても、それぞれの論文がどう繋がるのか見えていない。そんなエンジニアに向けて、GitHub Star 5900超のリポジトリ「AI Crash Course」が体系的な学習ロードマップを提供している。
本記事では、AI Crash Courseの構造・収録論文・学習ルート・他リソースとの違いを整理し、2週間でAI研究の最前線にキャッチアップするための実務的な読み方を示す。特にLLMアプリやエージェントを開発するエンジニアが、内部で何が起きているかを理解するために役立つ設計になっている。
この記事ではAIエージェントに特化して解説します。AIエージェント全般は AIエージェントフレームワーク比較2026年版 をご覧ください。
AI Crash Courseとは:GitHub Star 5900超のAI論文ロードマップ
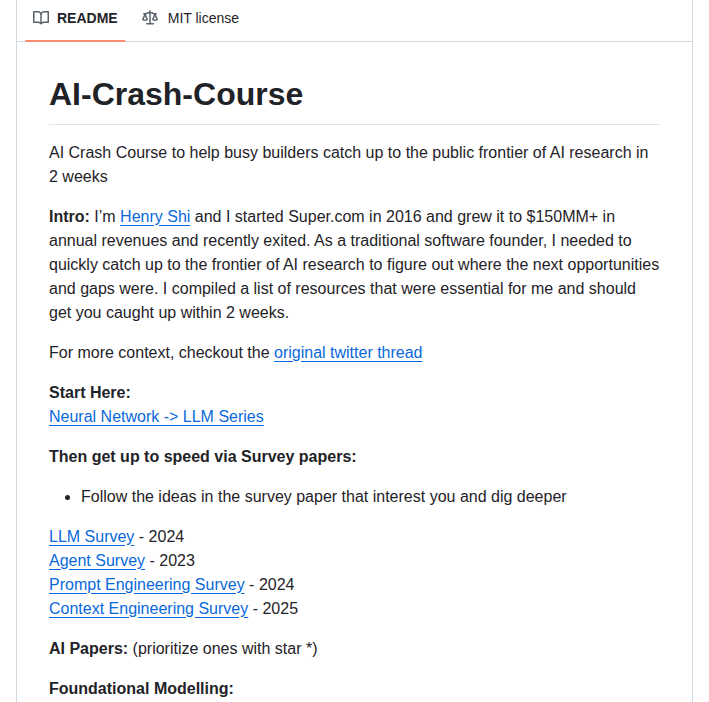
AI Crash Courseは、AI研究の重要論文とリソースを体系的にまとめたGitHubリポジトリだ。作者のHenry Shi氏はSuper.comの創業者で、同社を年間売上1.5億ドル以上に成長させた後にexitした人物。READMEによると「伝統的なソフトウェア創業者として、AI研究の最前線に素早くキャッチアップする必要があった」ことがきっかけで、自身の学習に不可欠だったリソースを整理した。
個人学習ノートがそのまま公開リポジトリになったという経緯があり、「自分がもう一度ゼロから学ぶならこの順序で読む」という視点で構成されている。単なるAwesomeリストではなく、著者の優先順位と文脈が反映されている点が他の論文リストとの違いだ。
リポジトリの構成はシンプルだ。READMEに全コンテンツが集約されており、各セクションが学習の段階に対応している。
AI-Crash-Course/
├── README.md # 全論文・リソースへのリンク集
├── Start Here # 3Blue1Brown Neural Network → LLM Series
├── Survey Papers # LLM Survey, Agent Survey, Prompt Engineering Survey
├── AI Papers # Foundational / Planning / Applications / Benchmarks
├── Videos/Lectures # Karpathy, Yannic Kilcher, Stanford等
└── Helpful Websites # Prompting Guide, Full Stack DL等
2026年3月時点で、GitHub Star数は5981、Fork数は862。AI論文の学習リソースとして高い支持を得ている。スター数の伸びは公開直後のXでのバイラルがきっかけで、その後もHacker NewsやReddit r/MachineLearningなどで断続的に言及されている。
「論文を全部読む」のではなく、「自分のプロダクトに関係する論文だけ優先順位をつけて読む」という発想で使うのが効率的だ。READMEの星印と学習順序を地図として使い、気になった論文からarXivリンクに飛ぶだけで、AI研究の全体像を見失わずに深掘りできる。
AI Crash CourseはSuper.com創業者Henry Shi氏が自身のAIキャッチアップ用に整理した論文ロードマップ。GitHub Star 5900超、Fork 862で、READMEに全論文・動画・サイトが集約されている。個人学習ノートがベースなので、単なるリストではなく「読む順序」と「優先度」が明示されている。
学習ロードマップ:4つのフェーズで最前線まで到達する
AI Crash Courseの最大の特徴は、論文が「読む順番」で整理されている点だ。闇雲に論文を読むのではなく、4段階のフェーズを踏むことで理解が積み上がる構成になっている。
基礎固め"] --> B["Phase 1
サーベイ論文"] B --> C["Phase 2
コア論文"] C --> D["Phase 3
応用・最前線"] A1["3Blue1Brown
Neural Network → LLM Series"] --> A B1["LLM Survey 2024
Agent Survey 2023
Prompt Engineering Survey 2024
Context Engineering Survey 2025"] --> B C1["Transformers 2017
GPT-3 2020
RLHF 2022
CoT 2022
DeepSeek R1 2025"] --> C D1["SWE-Agent / OpenHands
Benchmarks
Recursive Language Models 2026"] --> D style A fill:#e1f5fe style B fill:#f3e5f5 style C fill:#fff3e0 style D fill:#e8f5e9
READMEでは星印(*)が付いた論文が優先推奨されている。以下が推奨論文のリストだ。
★ 優先推奨論文(星印付き)
─────────────────────────────
Foundational:
- Transformers* (2017) — Self-attention機構の原論文
- GPT-3* (2020) — スケーリング則の実証
- RLHF* (2022) — InstructGPT → ChatGPTの基盤
Planning/Reasoning:
- MuZero* (2019) — ルール知識なしでのRL
- CoT (Chain of Thought)* (2022) — 推論の連鎖
- ARC-Prize* (2024) — ARC-AGI問題の最新手法
- DeepSeek R1* (2025) — 純粋RLでo1級推論モデル構築
Applications:
- Llama 3* (2024) — Metaのモデル構築詳細
星印が付いた論文は、「これを読まずにAIを語るのは難しい」と著者が判断した幹の論文だ。逆に言えば星印以外は「興味のある領域だけ選んで読めばよい」というスタンスで、全部読もうとして挫折するリスクを下げる設計になっている。
Phase 0の3Blue1Brownは動画ベースで、ニューラルネットワークからTransformerまでを視覚的に解説する。論文を読む前にこのシリーズを1周しておくと、Attention機構やBack Propagationの式が出てきても直感で追えるようになる。Phase 1のサーベイ論文は50〜100ページと分量はあるが、個別論文の文脈を一気に把握できるため、投資対効果が高い。
学習は「基礎の視覚化 → サーベイで全体像 → 星印論文で幹を押さえる → 応用で最前線」の4フェーズ構成。星印論文はTransformers・GPT-3・RLHF・CoT・DeepSeek R1など、AI研究の骨格をなすもの。全論文を読む必要はなく、自分の関心領域と星印を優先する。
収録論文の全体構成:基盤からエージェントまで4領域をカバー
AI Crash Courseは大きく4つの領域に分かれている。それぞれの領域がカバーする範囲と代表的な論文を整理した。
| 領域 | 論文数 | 時系列 | 代表的な論文 | 学べること |
|---|---|---|---|---|
| Foundational Modelling | 8本 | 2017-2024 | Transformers, GPT-3, LoRA, RLHF, DPO, MoE | LLMの基盤技術、学習手法 |
| Planning/Reasoning | 7本+ | 2017-2026 | AlphaZero, CoT/ToT/GoT, ReACT, DeepSeek R1 | 推論・計画能力の発展 |
| Applications | 6本 | 2023-2024 | Toolformer, GPT-4, Llama 3, OpenHands | 実用モデルとエージェント |
| Benchmarks | 3本 | 2022-2024 | BIG-Bench, SWE-Bench, Chatbot Arena | モデル評価手法 |
これに加えて、サーベイ論文4本、ビデオ/講義10本以上、参考サイト6件が含まれる。合計で30本以上の論文と20以上の補助リソースを網羅している。
Foundational Modellingセクションでは、2017年のTransformersから始まり、スケーリング則(GPT-3)、ファインチューニング(LoRA)、アラインメント(RLHF→DPO)、効率化(MoE)と進む。LLMがどう大きくなり、どう賢くなり、どう安くなったかの流れが一本の線で追える。
Planning/Reasoningセクションは、OpenHandsやForgeCodeのようなAIコーディングエージェントがなぜ動くのかを理解するための基盤だ。ReACTパターンは推論と行動を交互に生成する手法で、現在のエージェントフレームワークの多くがこのアーキテクチャに基づいている。さらに2026年のRecursive Language Modelsでは、シンプルなREPL+基本ツールだけでモデルが自律的な戦略を学習する研究が紹介されている。
# ReACTパターンの基本フロー(論文より)
Thought: ユーザーの質問に答えるために、まず検索が必要だ
Action: Search["DeepSeek R1 training method"]
Observation: DeepSeek R1は純粋なRLで学習され、SFTやReward Modelを使わない
Thought: この情報で回答を構成できる
Action: Finish["DeepSeek R1は純粋な強化学習で..."]
Applicationsセクションでは、ToolformerやOpenHandsといった実世界のアプリケーションに踏み込む。Toolformerはモデルが自律的にAPIを呼び出す学習手法で、現在のFunction Callingの源流にあたる論文だ。OpenHandsはAIコーディングエージェントの代表例で、SWE-Benchのスコアをどのように押し上げたかが詳細に報告されている。
Benchmarksセクションは見落とされがちだが重要度が高い。BIG-Benchはモデルの能力を多角的に測定する大規模ベンチマーク、SWE-Benchは実世界のGitHub Issue解決能力を測る指標、Chatbot ArenaはEloレーティングによるモデル比較だ。ベンチマークの設計思想を知ると、リリース時の派手なスコアに振り回されず、自分のユースケースに合うモデルを選べるようになる。
収録論文は基盤モデリング・推論計画・応用・ベンチマークの4領域で合計30本以上。Foundationalで「どう作るか」、Planning/Reasoningで「どう考えさせるか」、Applicationsで「どう使うか」、Benchmarksで「どう評価するか」を学ぶ構造。エージェント開発者はPlanning/ReasoningとApplicationsを中心に読むと実務に直結する。
エージェント開発者がAI Crash Courseを読むべき理由
LangChainのようなフレームワークを使う開発者は、APIの使い方は知っていても、その背後にある理論を把握していないケースが多い。AI Crash Courseはこのギャップを埋める。
具体的に、エージェント開発の各レイヤーがどの論文に対応するかを整理した。
| エージェント開発の要素 | 関連する論文 | なぜ読むべきか |
|---|---|---|
| プロンプト設計 | CoT, Prompt Engineering Survey | なぜ「step by step」が効くのか理解する |
| ツール呼び出し | Toolformer, ReACT | エージェントがツールを選択する仕組み |
| モデル選定 | SWE-Bench, Chatbot Arena | ベンチマーク結果の正しい読み方 |
| コスト最適化 | MoE, LoRA, DPO | 推論コストを下げる技術的背景 |
| 推論能力 | DeepSeek R1, ARC-Prize | o1級の推論がどう実現されているか |
たとえば、CoT(Chain of Thought)の論文を読めば、プロンプトに「Let’s think step by step」を入れるだけでなぜ精度が上がるのかが分かる。MoE(Mixture of Experts)の論文は、GPT-4やDeepSeek V3がどのようにコスト効率を実現しているかの仕組みを教えてくれる。
SWE-BenchやChatbot Arenaの論文は、OpenHandsのようなAIコーディングエージェントの性能を正しく評価するための判断軸を提供する。ベンチマークスコアの「読み方」を知ることで、ツール選定の精度が上がる。
APIドキュメントだけ読んでいても、なぜそのAPIがその形をしているかは分からない。RLHFの論文を読めば「system promptがなぜ効くのか」、MoEの論文を読めば「Claude Sonnet 4.5とOpus 4.6の価格差がなぜあるのか」、DeepSeek R1の論文を読めば「reasoning modelの思考トークンに課金される理由」まで繋がる。論文の知識はプロダクト選定・コスト試算・プロンプト設計すべてに波及する。
たとえば社内でRAGシステムを構築する場合、Context Engineering Survey(2025)を読むことで「コンテキストウィンドウに何を詰めるか」の判断軸が手に入る。単に「LangChainでretrieverを呼ぶ」だけのコードが、「なぜこの順序でドキュメントをrerankするのか」という設計判断を伴う実装に変わる。
エージェント開発の各要素(プロンプト・ツール呼び出し・モデル選定・コスト最適化・推論能力)は、それぞれ対応する論文がある。APIラッパーの使い方ではなく、背後の論文を押さえることで、プロダクト選定とプロンプト設計の精度が上がる。ベンチマーク論文の読み方を知ると、モデル選定で騙されなくなる。
学習の進め方:READMEが示す推奨ルート
READMEでは以下の順序で学習を進めることが推奨されている。
Step 1: 基礎の視覚的理解
3Blue1Brownの「Neural Network → LLMシリーズ」を最初に視聴する。数学的な基盤をビジュアルで把握することが目的だ。
# 推奨学習リソース(READMEより)
1. 3Blue1Brown — Neural Network → LLM Series(基礎数学・概念)
2. Andrej Karpathy — Zero to Hero Series(実装レベル)
3. Sebastian Raschka — Build a Large Language Model (from Scratch)
4. Stanford — Building LLMs 講義
5. Yannic Kilcher — 論文解説チャンネル
Step 2: サーベイ論文で全体像を掴む
LLM Survey(2024)、Agent Survey(2023)、Prompt Engineering Survey(2024)、Context Engineering Survey(2025)の4本から、興味のある領域を選ぶ。サーベイ論文は個別論文の文脈と関係性を教えてくれるため、最初に読む価値が高い。
Step 3: 星印論文を優先的に深掘り
星印(*)が付いたTransformers、GPT-3、RLHF、MuZero、DeepSeek R1、Llama 3などを集中的に読む。これらがAI研究の「幹」にあたる論文だ。
Step 4: 応用論文で最前線へ
SWE-Agent/OpenHands、Recursive Language Models(2026)など、実用レベルの研究に進む。ここまで来れば、ForgeCodeのようなAIコーディングツールやLangChainベースのエージェントが内部で何をしているか、技術的に把握できる状態になる。
2週間スケジュールのイメージとしては、1週目にPhase 0+1+星印論文の半分、2週目に星印の残り+応用論文、という配分が現実的だ。1日2〜3時間の学習を確保できるなら十分達成可能なペースだが、論文1本に何時間もかけるのではなく、「Abstract+Introduction+Conclusion+図表」を先に読んで全体像を掴んでから、必要な章だけ深堀りする戦略が効く。
# 2週間スケジュールの例
Week 1:
Day 1-2: 3Blue1Brown動画シリーズ視聴
Day 3: LLM Survey 2024を流し読み
Day 4-5: Transformers + GPT-3 論文
Day 6-7: RLHF + CoT 論文
Week 2:
Day 8-9: DeepSeek R1 + MuZero
Day 10-11: Toolformer + ReACT + Llama 3
Day 12-13: SWE-Bench + OpenHands
Day 14: 振り返り + 未読論文のメモ化
論文を1本読み終わるごとに、自分の言葉で「3行要約」をメモしておくと理解度が定着する。Notionやscrapboxに貯めておけば、後でプロダクト設計時に「この判断はどの論文に根拠があったか」を即座に引ける。
推奨ルートは「3Blue1Brown動画 → サーベイ論文 → 星印論文 → 応用論文」の4ステップ。論文は全文を読むのではなく、Abstract+Introduction+Conclusion+図表から入り、必要な章だけ深堀りする。2週間で完走するには1日2〜3時間の学習時間と、3行要約のメモ化が鍵。
類似リソースとの比較:AI Crash Courseの位置づけ
AI論文の学習リソースは複数存在する。AI Crash Courseがどの位置にあるかを整理した。
| リソース | 論文数 | 対象者 | 構造化 | 更新頻度 | 特徴 |
|---|---|---|---|---|---|
| AI Crash Course | 30本+ | 中級〜 | 学習順序あり | 不定期 | 2週間で最前線到達を目標 |
| a16z AI Canon | 100本+ | 初級〜 | カテゴリ分類 | 低頻度 | 網羅的だが優先順位なし |
| 2025 AI Engineer Reading List | 50本+ | 中級〜 | 分野別 | 年次 | エンジニア向け、実務寄り |
| Awesome Deep Learning | 200本+ | 全レベル | Awesome List形式 | コミュニティ | 量は多いが構造が平坦 |
AI Crash Courseの差別化ポイントは「学習順序が明示されている」ことと「優先度が星印で示されている」ことだ。他のリソースは「何を読むか」は教えてくれるが、「どの順番で読むか」は自分で判断する必要がある。
逆に言えば、論文を網羅的に把握したい研究者にはa16z AI CanonやAwesome Deep Learningの方が適している。AI Crash Courseはあくまで「エンジニアが最短距離で実務レベルの理解に到達する」ことを最優先にしているため、漏れがないとは限らない。使い分けの基本は「最短で全体像 → AI Crash Course」「網羅性 → a16z Canon」「実務寄り → 2025 AI Engineer Reading List」と覚えておくと良い。
AI Crash Courseは「学習順序」と「星印による優先度」が明示されている点で他リソースと差別化される。網羅性ではa16z CanonやAwesome Deep Learningが勝るが、最短ルートで最前線に到達したいエンジニアにはAI Crash Courseが最適。用途に応じて使い分けるのが現実解。
注意点と活用のコツ
AI Crash Courseを最大限に活用するために、いくつかの注意点がある。
リンク集であり教材ではない。 コーディング演習やハンズオンは含まれていない。実装スキルを身につけるには、Andrej KarpathyのZero to Heroシリーズや、Sebastian Raschkaの『Build a Large Language Model (from Scratch)』など、READMEに記載された実装リソースと組み合わせる必要がある。
AI分野の進歩は速い。 2026年以降の論文は随時追加される可能性があるが、最新の状況を常に反映しているとは限らない。特にエージェント領域は進化が速く、OpenHandsのようなツールは頻繁にアップデートされている。
英語論文が前提。 収録論文はすべて英語で書かれている。論文を読む英語力に不安がある場合は、まずYannic Kilcherの動画解説やサーベイ論文から入ると、個別論文の理解がスムーズになる。
補助リソースが充実している。 論文だけでなく、以下のWebサイトもREADMEで紹介されている。
# README記載の補助サイト
- History of Deep Learning — 深層学習のタイムラインと主要ブレイクスルー
- Full Stack Deep Learning — AIプロダクト構築のコース
- Prompting Guide — プロンプト技術の網羅的リスト
- a16z AI Canon — より広範な論文リスト(やや古い)
- 2025 AI Engineer Reading List — エンジニア向け長めの論文リスト
- State of Generative Models — 生成モデルの現状まとめ
これらの補助サイトは、論文では抽象度が高すぎて掴みにくい「AIプロダクトを実際に作るときの判断軸」を補ってくれる。Full Stack Deep Learningはモデル選定・データパイプライン・デプロイ・モニタリングまで一気通貫のコースで、論文の知識を実装に落とし込むフェーズで活きる。
AI Crash Courseは論文リンク集であり、実装スキルは別途獲得が必要。英語論文が前提で、進化の速いエージェント領域は随時最新情報で補う必要がある。Full Stack Deep LearningやPrompting Guideといった補助サイトを組み合わせると、論文の知識を実装に接続できる。
📌 まとめ
AI Crash Courseは、AI研究の膨大な情報を「2週間」という実行可能な時間軸に圧縮するための地図として設計されている。Henry Shi氏が自身の学習ノートとして整理したものだからこそ、「エンジニア視点で何を優先すべきか」が明確だ。
本記事で押さえたポイントを再確認する。
- 構造:README一本に学習順序と星印による優先度が集約されている
- 4フェーズ:基礎の視覚化 → サーベイ → 星印論文 → 応用論文の流れで進む
- 4領域:Foundational、Planning/Reasoning、Applications、Benchmarksをカバー
- エージェント開発との接続:プロンプト・ツール呼び出し・ベンチマーク評価がすべて論文で裏付けられる
- 他リソースとの違い:網羅性より最短ルートを優先、星印で迷いをなくす設計
論文を1本ずつ読む前に、まずはREADME全体に目を通し、自分のプロダクトに関係する領域だけをピックアップして星印論文から始めよう。2週間後には、LangChainやOpenHandsのようなツールが内部で何をしているかが「論文レベルで」理解できている状態になる。そこまで到達すれば、API連携のトラブルシューティングもモデル選定の意思決定も、一段深い解像度で判断できるようになる。