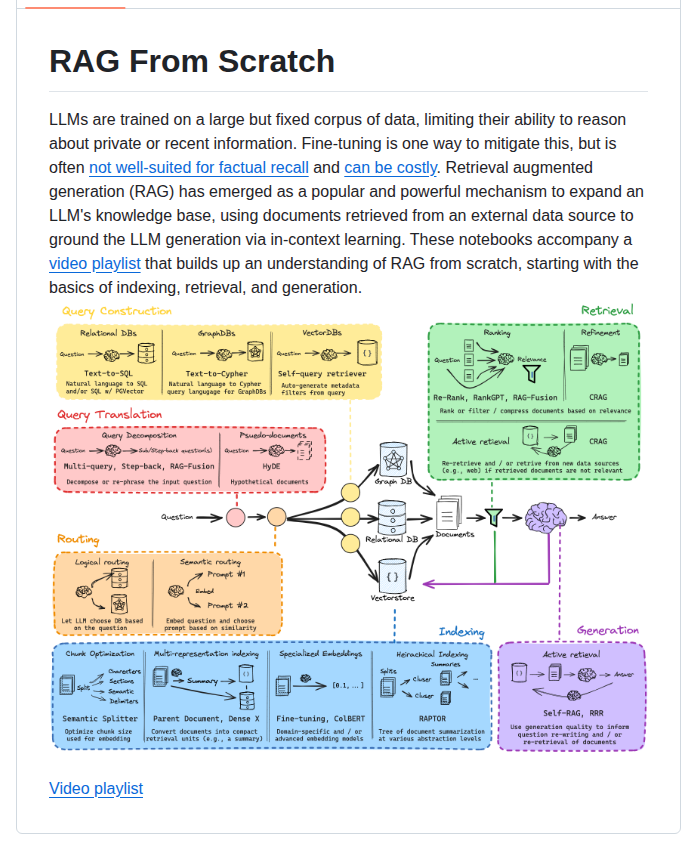
この記事ではRAGに特化して解説します。RAG全般は RAGとは?仕組み・構築・ベクトルDB選定まで【2026年完全ガイド】 をご覧ください。
LangChainとは:エージェントエンジニアリングプラットフォーム
LangChainはLLMを活用したアプリケーション・エージェントの開発を大幅に簡素化するPythonフレームワークだ。 GitHub 133,000スター超(2026年4月時点)という圧倒的なOSSコミュニティを持ち、LLMアプリ開発のデファクトスタンダードとして広く採用されている。
2024年以降、公式は「The agent engineering platform(エージェントエンジニアリングプラットフォーム)」を掲げている。単なるLLM呼び出しラッパーを超え、エージェントが自律的にツールを選択・実行し、複数ステップの推論を行う本格的なシステムを構築するためのインフラへと進化している。
LangChainが解決する問題は明確だ:異なるLLMプロバイダーへの統一インターフェース、ドキュメントの取り込みとベクトル化、会話履歴の管理、外部ツールとの連携──これらをゼロから実装すると膨大なボイラープレートコードが必要になる。LangChainはこれらのコンポーネントを標準化されたAPIとして提供し、開発者がアプリケーションのコアロジックに集中できるようにする。
LangChainエコシステムは主に4つのコンポーネントで構成される:
- LangChain Core:モデル・エンベッディング・ベクトルストア等の抽象インターフェース(OSS)
- LangGraph:ステートフルな複雑エージェントのオーケストレーション(OSS)
- LangSmith:エージェントの評価・観測・デバッグ(有料SaaS)
- Deep Agents:サブエージェントとファイルシステムを使う高度なエージェント(OSS)
新しいプロジェクトを始める際、高レベルのチェーンAPIで十分なシンプルなRAGや単純なLLM呼び出しにはLangChainのみで対応できます。複雑なエージェント(条件分岐・ループ・並列実行・ステート管理)が必要な場合はLangGraphを組み合わせることで、より制御可能な実装になります。
LangChainの技術アーキテクチャ
LangChainの設計思想は「コンポーザブルなコンポーネント」にある。LLMプロバイダー、エンベッディングモデル、ベクトルストア、ドキュメントローダー、テキストスプリッター──これらが共通インターフェースを実装しており、自由に組み替えられる。
PDF・CSV・Web・DB等"] B["Text Splitters
チャンキング"] A --> B end subgraph "エンベッディング層" C["Embedding Models
OpenAI・HuggingFace等"] B --> C end subgraph "ストレージ層" D["Vector Stores
Chroma・Pinecone・Weaviate等"] C --> D end subgraph "検索・生成層" E["Retrievers
MMR・類似度・キーワード"] F["LLM/Chat Models
OpenAI・Claude・Gemini・Ollama"] G["Prompt Templates
System/Human/AI"] D --> E E --> H["RAG Chain
RetrievalQA"] G --> H F --> H end subgraph "エージェント層" I["Tools
検索・計算・API呼び出し等"] J["Memory
会話履歴・要約"] K["Agent
ReAct・Tool Calling等"] H --> K I --> K J --> K end K --> L["最終回答"]
LangChain Expression Language (LCEL)
LangChain v0.1以降、LCEL(LangChain Expression Language) が推奨の実装スタイルになっている。パイプ演算子(|)でコンポーネントをつなぐ宣言的なAPIだ:
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
# LCELチェーン:プロンプト | LLM | パーサー
chain = (
ChatPromptTemplate.from_template("以下の文章を要約してください:\n{text}")
| ChatOpenAI(model="gpt-4o")
| StrOutputParser()
)
# 実行
result = chain.invoke({"text": "LangChainは..."})
LCEL の利点はストリーミング・非同期・バッチ処理がすべて同じAPIで対応できることだ。
インストール・セットアップ
基本インストール
# LangChain Core
pip install langchain
# または uv(高速)
uv add langchain
LLMプロバイダーごとのパッケージ
# OpenAI(GPT-4o・o4等)
pip install langchain-openai
# Anthropic(Claude Sonnet・Opus等)
pip install langchain-anthropic
# Google Gemini
pip install langchain-google-generativeai
# Ollama(ローカルLLM)
pip install langchain-ollama
# ベクトルDB(Chroma)
pip install langchain-chroma
# ドキュメント処理(PDF等)
pip install langchain-community
環境変数の設定
# OpenAI
export OPENAI_API_KEY="sk-..."
# Anthropic
export ANTHROPIC_API_KEY="sk-ant-..."
# Google
export GOOGLE_API_KEY="AIza..."
# LangSmith(観測・デバッグ。オプション)
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY="ls__..."
export LANGCHAIN_PROJECT="my-project"
.env ファイルで管理する場合は python-dotenv を使う:
from dotenv import load_dotenv
load_dotenv() # .envファイルの変数を読み込む
モデルの初期化
from langchain.chat_models import init_chat_model
# 統一インターフェースでモデル初期化
model = init_chat_model("openai:gpt-4o") # OpenAI
model = init_chat_model("anthropic:claude-sonnet-4-5") # Anthropic
model = init_chat_model("google_genai:gemini-2.0-flash") # Google
# シンプルな呼び出し
result = model.invoke("LangChainとは何ですか?")
print(result.content)
複数LLMプロバイダーを試す開発段階ではAPIコストが積み上がりやすいです。LangSmithのトレーシングでトークン使用量をモニタリングするか、開発初期はOllama(ローカルLLM)を使ってコストを抑えることを推奨します。
RAGパイプラインの実装
LangChainのRAG実装は、ドキュメントロード → チャンキング → エンベッディング → ベクトルストア格納 → リトリーバー → LLM生成、という一連のパイプラインを構成する。
ステップ1:ドキュメントのロード
from langchain_community.document_loaders import (
PyPDFLoader, # PDF
WebBaseLoader, # Webページ
TextLoader, # テキストファイル
DirectoryLoader, # ディレクトリ
UnstructuredMarkdownLoader, # Markdown
)
# PDFのロード
loader = PyPDFLoader("./technical_manual.pdf")
docs = loader.load()
print(f"ページ数: {len(docs)}")
# ディレクトリ内の全PDFをロード
dir_loader = DirectoryLoader(
"./company_docs",
glob="**/*.pdf",
loader_cls=PyPDFLoader,
)
all_docs = dir_loader.load()
ステップ2:テキストの分割
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 日本語テキスト対応の分割設定
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # チャンクの最大文字数
chunk_overlap=200, # 前後のチャンクとの重複文字数
length_function=len, # 文字数カウント関数
separators=["\n\n", "\n", "。", "、", " ", ""],
)
chunks = text_splitter.split_documents(docs)
print(f"チャンク数: {len(chunks)}")
ステップ3:エンベッディングとベクトルストアへの格納
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
# エンベッディングモデルの初期化
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# ベクトルストアの作成・永続化
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db",
)
# 既存ストアのロード
vectorstore = Chroma(
persist_directory="./chroma_db",
embedding_function=embeddings,
)
ステップ4:RAGチェーンの構築
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# リトリーバーの作成
retriever = vectorstore.as_retriever(
search_type="mmr", # MMR(最大辺境関連性)でリランキング
search_kwargs={"k": 5}, # 上位5件を取得
)
# RAGプロンプトテンプレート
prompt = ChatPromptTemplate.from_template("""
以下のコンテキストに基づいて質問に答えてください。
コンテキストに情報がない場合は「情報がありません」と答えてください。
コンテキスト:
{context}
質問: {question}
""")
# LLMの初期化
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# LCELでRAGチェーンを構築
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# クエリの実行
answer = rag_chain.invoke("APIの認証方法を教えてください")
print(answer)
ストリーミングレスポンス
# ストリーミングでの回答生成
for chunk in rag_chain.stream("会社の休暇ポリシーを教えてください"):
print(chunk, end="", flush=True)
print()
エージェント機能の実装
LangChainのエージェントは、LLMが与えられたツールの中から適切なものを選択して実行し、その結果を使って次の行動を決定する仕組みだ。
ツール定義
from langchain_core.tools import tool
from langchain_community.tools import DuckDuckGoSearchRun
# カスタムツールの定義
@tool
def get_weather(city: str) -> str:
"""指定した都市の天気を取得する"""
# 実際の実装では気象APIを呼び出す
return f"{city}の天気:晴れ、気温 22°C"
@tool
def calculate(expression: str) -> str:
"""数学的な計算を実行する"""
try:
result = eval(expression)
return str(result)
except Exception as e:
return f"計算エラー: {e}"
# 組み込みツール
search_tool = DuckDuckGoSearchRun()
# ツールリスト
tools = [get_weather, calculate, search_tool]
ReActエージェントの構築
from langchain.agents import create_react_agent, AgentExecutor
from langchain_core.prompts import PromptTemplate
# LLMにツールをバインド
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# ツール呼び出し型エージェント(推奨)
from langchain.agents import create_tool_calling_agent
prompt = ChatPromptTemplate.from_messages([
("system", "あなたは役立つAIアシスタントです。必要に応じてツールを使ってください。"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
])
agent = create_tool_calling_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# エージェントの実行
result = agent_executor.invoke({
"input": "東京の天気を調べて、明日の服装のアドバイスをください"
})
print(result["output"])
会話履歴付きエージェント
from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
# セッションごとの会話履歴
store = {}
def get_session_history(session_id: str) -> InMemoryChatMessageHistory:
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
# 会話履歴付きエージェント
agent_with_history = RunnableWithMessageHistory(
agent_executor,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
)
# 会話セッションの開始
config = {"configurable": {"session_id": "user-123"}}
result1 = agent_with_history.invoke(
{"input": "私の名前は田中です"}, config=config
)
result2 = agent_with_history.invoke(
{"input": "私の名前は何ですか?"}, config=config
)
print(result2["output"]) # → "田中さんです"
LangGraphによる高度なエージェント構築
複雑なエージェント(条件分岐・ループ・複数エージェントの協調)にはLangGraphを使う:
from langgraph.graph import StateGraph, END
from langgraph.prebuilt import ToolNode
from typing import TypedDict, Annotated
import operator
# エージェントの状態定義
class AgentState(TypedDict):
messages: Annotated[list, operator.add]
# グラフの構築
workflow = StateGraph(AgentState)
# ノード(エージェントとツール実行)の追加
workflow.add_node("agent", agent_node)
workflow.add_node("tools", ToolNode(tools))
# エントリーポイント設定
workflow.set_entry_point("agent")
# 条件付きエッジ(ツールを呼ぶか終了するかの判断)
def should_continue(state):
last_message = state["messages"][-1]
if last_message.tool_calls:
return "tools"
return END
workflow.add_conditional_edges("agent", should_continue)
workflow.add_edge("tools", "agent")
# コンパイルと実行
app = workflow.compile()
result = app.invoke({
"messages": [("human", "東京の天気を調べて最適な旅行プランを提案してください")]
})
実践的なユースケース5選
1. 社内ドキュメントQ&Aシステム
# 社内規程・マニュアルのRAGシステム
from langchain_community.document_loaders import DirectoryLoader, PyPDFLoader
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
# PDFをまとめてインデックス化
loader = DirectoryLoader("./company_docs", glob="**/*.pdf", loader_cls=PyPDFLoader)
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=800, chunk_overlap=100)
chunks = splitter.split_documents(docs)
vectorstore = Chroma.from_documents(
chunks,
OpenAIEmbeddings(),
persist_directory="./hr_docs_db"
)
# シンプルなQ&Aインターフェース
retriever = vectorstore.as_retriever(search_kwargs={"k": 4})
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| ChatPromptTemplate.from_template("コンテキスト:{context}\n質問:{question}")
| ChatOpenAI(model="gpt-4o")
| StrOutputParser()
)
print(rag_chain.invoke("育児休業は何日取得できますか?"))
2. マルチモーダル文書解析
from langchain_anthropic import ChatAnthropic
from langchain_core.messages import HumanMessage
import base64
# PDF画像ページをClaudeで解析
def analyze_image_with_claude(image_path: str, question: str) -> str:
with open(image_path, "rb") as f:
image_data = base64.b64encode(f.read()).decode()
model = ChatAnthropic(model="claude-sonnet-4-5")
message = model.invoke([
HumanMessage(content=[
{"type": "image", "source": {"type": "base64", "media_type": "image/png", "data": image_data}},
{"type": "text", "text": question}
])
])
return message.content
result = analyze_image_with_claude("./chart.png", "このグラフのトレンドを説明してください")
3. Webスクレイピング + RAG
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 複数のWebページをインデックス化
urls = [
"https://docs.langchain.com/",
"https://api.python.langchain.com/",
]
loader = WebBaseLoader(urls)
docs = loader.load()
# ドキュメントの前処理と格納
splitter = RecursiveCharacterTextSplitter(chunk_size=1500, chunk_overlap=150)
chunks = splitter.split_documents(docs)
vectorstore = Chroma.from_documents(chunks, OpenAIEmbeddings())
4. 構造化データ抽出
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
# 抽出したいデータ構造を定義
class ProductInfo(BaseModel):
name: str = Field(description="製品名")
price: float = Field(description="価格(円)")
features: list[str] = Field(description="主要機能のリスト")
release_date: str = Field(description="発売日(YYYY-MM-DD形式)")
# LLMで構造化抽出
llm = ChatOpenAI(model="gpt-4o")
structured_llm = llm.with_structured_output(ProductInfo)
result = structured_llm.invoke(
"新製品XYZ-2026は2026年4月1日に発売。価格は49,800円。AI搭載、防水、"
"バッテリー48時間持続が特徴。"
)
print(result.name) # → "XYZ-2026"
print(result.price) # → 49800.0
5. マルチエージェントシステム
# 複数の専門エージェントを協調させる
from langchain_core.tools import tool
# 各専門エージェントをツールとして定義
@tool
def research_agent(query: str) -> str:
"""最新情報を調査する専門エージェント"""
# DuckDuckGo検索 + 要約
search = DuckDuckGoSearchRun()
results = search.run(query)
return llm.invoke(f"以下を日本語で要約: {results}").content
@tool
def writing_agent(topic: str, research: str) -> str:
"""調査結果をもとに文章を作成する専門エージェント"""
prompt = f"以下の調査結果をもとに、{topic}についての記事を書いてください:\n{research}"
return llm.invoke(prompt).content
# オーケストレーターエージェント
orchestrator_tools = [research_agent, writing_agent]
orchestrator = create_tool_calling_agent(llm, orchestrator_tools, prompt)
result = AgentExecutor(agent=orchestrator, tools=orchestrator_tools).invoke({
"input": "LangChain v0.3の新機能について調査して記事を書いてください"
})
LangChainと競合フレームワークの比較
LangChainは最も広範なエコシステムを持つが、用途によっては他フレームワークが優れる場面もある。
| フレームワーク | 学習コスト | エコシステム | エージェント | RAG | ローカルLLM | 特徴 |
|---|---|---|---|---|---|---|
| LangChain | 中 | 最大 | ✅ | ✅ | ✅ | 汎用・最多インテグレーション |
| LlamaIndex | 低〜中 | 大 | ✅ | ✅ | ✅ | RAG特化・高精度検索 |
| AutoGen | 中 | 中 | ✅✅ | ✅ | ✅ | マルチエージェント協調 |
| CrewAI | 低 | 中 | ✅✅ | ✅ | ✅ | 役割分担型マルチエージェント |
| Haystack | 中 | 中 | ✅ | ✅✅ | ✅ | 企業向けRAGパイプライン |
| Dify | 低(GUI) | 中 | ✅ | ✅ | ✅ | ノーコード/ローコード |
| LangGraph | 高 | LangChain依存 | ✅✅✅ | ✅ | ✅ | 複雑なステートフルエージェント |
フレームワーク選択の指針
| ユースケース | 推奨フレームワーク |
|---|---|
| シンプルなRAG Q&A | LangChain または LlamaIndex |
| 複雑な条件分岐エージェント | LangGraph |
| マルチエージェント協調 | AutoGen または CrewAI |
| ノーコードでRAG構築 | Dify |
| 企業向け本番RAG | Haystack または RAGFlow |
| iOS/macOSのオンデバイスRAG | Wax |
LangSmithによる観測・デバッグ
LangSmithはLangChainプロジェクト向けの観測・評価プラットフォームだ。トレーシングを有効にするだけで、チェーンの各ステップの入出力・レイテンシ・トークン使用量が可視化される:
import os
# LangSmithのトレーシングを有効化
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "ls__your-key"
os.environ["LANGCHAIN_PROJECT"] = "my-rag-project"
# 以降のLangChain呼び出しは自動的にトレース記録される
result = rag_chain.invoke("質問テキスト")
# → LangSmith UIで各ステップの詳細を確認できる
# 評価の実装
from langsmith import Client
from langchain.smith import RunEvalConfig, run_on_dataset
# テストデータセットの作成
client = Client()
dataset = client.create_dataset("qa-evaluation-set")
client.create_examples(
inputs=[{"question": "育児休業は何日ですか?"}],
outputs=[{"answer": "最大1年間取得可能です"}],
dataset_id=dataset.id,
)
# RAGチェーンの自動評価実行
eval_config = RunEvalConfig(
evaluators=["qa"], # 質問-回答の正確性評価
prediction_key="output",
)
run_on_dataset(
dataset_name="qa-evaluation-set",
llm_or_chain_factory=lambda: rag_chain,
evaluation=eval_config,
)
LangSmithは月3,000トレースまで無料です。開発・プロトタイプ段階では十分です。本番環境での大量トレースには有料プランが必要ですが、まずは無料枠でRAGの精度改善サイクルを回すことから始めましょう。
よくある質問
Q:LangChainの学習に最適なリソースは?
A:公式のLangChain Academyが最も体系的です。LangChain Core・LangGraph・LangSmithを段階的に学べる無料コースが用意されています。また公式ドキュメント(docs.langchain.com)のConceptual Guideも参考になります。
Q:OpenAIの関数呼び出し(Function Calling)とLangChainのツールの違いは?
A:OpenAIの関数呼び出しはOpenAI APIに固有の機能ですが、LangChainのツールAPIは複数LLMプロバイダーに対して同じコードで動作する抽象化レイヤーです。Claude・Gemini・GPT-4oのいずれでも同じツール定義が使えます。
Q:LangChainのRAGとllama-index-coreのRAGはどちらが優れていますか?
A:どちらも優れており、用途次第です。LangChainはインテグレーション数とエージェント機能で優位。LlamaIndexはRAG特化の高度なリトリーバー(クエリデコンポジション・リランキング・知識グラフ統合)で優位です。RAGの精度追求が最優先ならLlamaIndex、エージェント機能と幅広いインテグレーションが必要ならLangChainが向いています。
Q:ローカルLLM(Ollama)でLangChainを使うには?
A:langchain-ollama パッケージをインストールし、from langchain_ollama import ChatOllama でモデルを初期化します。Ollamaがローカルで動作していれば、OpenAIと同じインターフェースで使えます。
Q:LangChainはRAGだけでなく何に使えますか?
A:LLMを活用するほぼすべてのアプリケーションに使えます。チャットボット、文書分類・要約・翻訳、コード生成・デバッグ、構造化データ抽出、マルチエージェントシステム、顧客サポート自動化、コンテンツ生成パイプライン等です。
関連記事: RAGとは?仕組み・構築・ベクトルDB選定まで【2026年完全ガイド】
まとめ
LangChainは「エージェントエンジニアリングプラットフォーム」として、LLMアプリ開発のデファクトスタンダードとしての地位を確立している。GitHub 133,000スター超・160以上のデータコネクター・主要LLM全社対応という層の厚さは他に並ぶものがない。
シンプルなRAG構築からマルチエージェントシステムまで、LangChainのコンポーザブルなアーキテクチャは開発者が必要なコンポーネントだけを取り出して使えるよう設計されている。複雑なエージェントワークフローが必要になった際にLangGraphへ自然に移行できる点も、長期的な開発基盤として評価できる。
RAGシステムの実装を始める際は本記事のコードサンプルをベースに、MinerUでPDFを前処理してチャンキングの品質を高め、RAGFlowやDifyでビジュアルなワークフロー管理を組み合わせるアーキテクチャが、2026年時点でのベストプラクティスとなっている。
LangChainは単独のツールというよりも、LLMアプリ開発のエコシステム全体を構成するOSS基盤だ。その豊富なインテグレーションと活発なコミュニティを活用することで、LLMアプリケーションの開発・本番化・継続改善のサイクルを大幅に加速できる。