この記事ではAIエージェントに特化して解説します。AIエージェント全般は AIエージェントフレームワーク比較2026年版 をご覧ください。
AutoResearchClawとは何か——1コマンドで論文を生成する研究エージェント
研究論文を1本仕上げるまでには、文献調査・仮説設計・実験実行・結果分析・執筆・査読対応と膨大な工程が積み重なる。AutoResearchClaw はこれらすべてを23段階のパイプラインに分解し、研究アイデアをテキストで渡すだけでNeurIPS/ICML/ICLR形式のLaTeX論文まで自動で書き上げるOSSだ。
実行は1コマンドで完結する。
pip install -e . && researchclaw setup && researchclaw init
researchclaw run --topic "Your research idea here" --auto-approve
OpenAlex・Semantic Scholar・arXivから実在する論文だけを取得し、ハルシネーション(捏造引用)は4層の検証システムで排除する。2,699件のテストがすべてパスし、MIT Licenseで公開されている点も研究用途には重要だ。自律性の設計思想は OpenHands のようなAIコーディングエージェントと近いが、対象領域が「研究プロセスそのもの」である点が大きく異なる。
「AI-generated papers are drafts, not finished work — human review is essential.」(公式README より)
公式READMEが強調するとおり、生成された論文はあくまで「ドラフト」であり、学会投稿前の人間のレビューは必須という位置づけだ。AutoResearchClawは研究者を置き換える道具ではなく、文献整理やベースライン実験など「面倒で再現性の高い工程」を肩代わりし、研究者の時間を本質的な考察に集中させる基盤として設計されている。
研究プロセス全体を23段階に分解し1コマンドで実行
OpenAlex/Semantic Scholar/arXivから実在論文のみ取得、4層で引用検証
生成物は「ドラフト」であり人間レビュー必須という思想で設計
23段階パイプラインの全体像——8フェーズで論文完成まで到達
AutoResearchClawの核は、研究プロセスを8フェーズ・23段階に体系化したパイプライン設計にある。各段階は独立したステージとして定義され、失敗時のリトライや部分再実行もステージ単位で行える。
Scoping
Stage 1-2"] --> B["Phase B
Literature
Stage 3-6"] B --> C["Phase C
Synthesis
Stage 7-8"] C --> D["Phase D
Design
Stage 9-11"] D --> E["Phase E
Execution
Stage 12-13"] E --> F["Phase F
Analysis
Stage 14-15"] F --> G["Phase G
Writing
Stage 16-19"] G --> H["Phase H
Finalize
Stage 20-23"] F -->|REFINE| E F -->|PIVOT| C
各フェーズで起きていることを表にまとめると次のようになる。
| フェーズ | 段階 | 処理内容 |
|---|---|---|
| A: Scoping | 1-2 | トピック初期化、問題分解ツリー生成 |
| B: Literature | 3-6 | OpenAlex/Semantic Scholar/arXiv取得、スクリーニング、知識抽出 |
| C: Synthesis | 7-8 | 知見クラスタリング、研究ギャップ特定、Multi-Agent Debateで仮説生成 |
| D: Design | 9-11 | 実験計画、GPU/MPS/CPU自動検出、コード生成、リソース見積もり |
| E: Execution | 12-13 | サンドボックス実験、NaN/Inf検出、自己修復ループ |
| F: Analysis | 14-15 | 結果分析、PROCEED/REFINE/PIVOTの自律判断 |
| G: Writing | 16-19 | アウトライン → セクション別執筆(5,000-6,500語) → 査読 → 修正 |
| H: Finalization | 20-23 | 品質ゲート、知識アーカイブ、LaTeX出力、引用整合性検証 |
ゲート段階と自律判断ロジック
23段階の中には特に重要な「ゲート」が3箇所存在する。Stage 5(文献スクリーニング)、Stage 9(実験設計)、Stage 20(品質ゲート)だ。--auto-approve を外して実行すると、これら3箇所で人間の承認を必要とする設計になっている。
Stage 15の Analysis & Decision が最もエージェント的な挙動を示す段階だ。実験結果を分析し、次のアクションとして以下の3択から自律的に選ぶ。
- PROCEED: 仮説どおりの結果が得られたので、論文執筆フェーズへ進む
- REFINE: 仮説は有望だがパラメータ調整が必要。Phase Eへ戻り再実行
- PIVOT: 根本から仮説を見直す必要あり。Phase Cへ戻り新仮説を生成
この判断ロジックが「失敗した実験をそのまま論文化する」ことを防ぎ、生成される研究の質を底上げしている。
長大な自動化パイプラインは「どこで止めて、どこで人間が介入するか」の設計が成否を分ける。AutoResearchClawはゲート3箇所・フェーズ境界8箇所・全段階という粒度を選べるため、ユースケースに合わせて介入コストと自動化恩恵のバランスを調整できる。
8フェーズ・23段階に研究プロセスを体系化
ゲートは Stage 5 / 9 / 20 の3箇所、フェーズ境界は8箇所
Stage 15で PROCEED / REFINE / PIVOT を自律判断し品質を担保
インストールと初期設定——Quick Startの実行手順
実際に動かすための手順を見ていく。Python 3.11以上が前提で、LaTeXコンパイルを行う場合は latexmk を含むLaTeX環境も必要になる。
# 1. クローンとインストール
git clone https://github.com/aiming-lab/AutoResearchClaw.git
cd AutoResearchClaw
python3 -m venv .venv && source .venv/bin/activate
pip install -e .
# 2. セットアップ(OpenCode Beast Mode、Docker/LaTeX確認)
researchclaw setup
# 3. 設定ファイル生成(対話式でLLMプロバイダー選択)
researchclaw init
# 4. 実行
export OPENAI_API_KEY="sk-..."
researchclaw run --config config.arc.yaml \
--topic "Your research idea" \
--auto-approve
最小構成の設定ファイル
researchclaw init で生成される config.arc.yaml の最小構成は次のとおり。
# config.arc.yaml
project:
name: "my-research"
research:
topic: "Your research topic here"
llm:
base_url: "https://api.openai.com/v1"
api_key_env: "OPENAI_API_KEY"
primary_model: "gpt-4o"
fallback_models: ["gpt-4o-mini"]
experiment:
mode: "sandbox"
sandbox:
python_path: ".venv/bin/python"
ポイントは fallback_models を指定できる点だ。primaryモデルがレート制限や一時障害で失敗した場合、自動的にfallbackへ切り替わり、23段階パイプラインの途中停止を防ぐ。長時間実行ではこのフェイルオーバーが実効成功率を大きく左右する。
成果物の保存先
実行結果は artifacts/rc-YYYYMMDD-HHMMSS-<hash>/deliverables/ 配下に格納される。典型的な成果物は以下のとおりだ。
| ファイル | 内容 |
|---|---|
paper.tex |
NeurIPS/ICML/ICLR対応のLaTeX本文 |
references.bib |
BibTeX形式の引用リスト |
figures/*.pdf |
matplotlib/tikzで生成したチャート |
experiments/*.py |
実際に実行された実験コード |
review.md |
内部査読エージェントによる改善提案 |
そのままOverleafにZipアップロードできる構造になっているため、ドラフトをチームで共同編集する流れに自然に乗せられる。
Python 3.11 + LaTeX環境 + LLM APIキーで動く
fallback_models で長時間実行の途中停止を防ぐ成果物は Overleaf にそのまま上げられる LaTeX/BibTeX 一式
Co-Pilotモード——人間とAIが協調する6つの介入レベル
v0.4.0で導入された Human-in-the-Loop(HITL)システムは、完全自律から1ステップずつの確認まで6段階の介入モードを提供する。自律性を最大化する Browser Use のようなエージェントとは対照的に、AutoResearchClawは「研究の質を担保するためには人間の判断を要所に組み込む」設計思想を貫いている。
6つの介入モード
| モード | コマンド | 動作 |
|---|---|---|
| Full Auto | --auto-approve |
人間の介入なし(従来動作) |
| Gate Only | --mode gate-only |
3つのゲート段階で承認待ち |
| Checkpoint | --mode checkpoint |
フェーズ境界(8箇所)で一時停止 |
| Co-Pilot | --mode co-pilot |
仮説生成・実験設計・論文執筆で深い協調 |
| Step-by-Step | --mode step-by-step |
全段階で一時停止(学習用) |
| Custom | --mode custom |
段階ごとにポリシーを定義 |
Co-Pilotモードでは特に重要な3つの協調機能が有効になる。
- Idea Workshop(Stage 7-8): 仮説生成の場で、AIが出した候補に対して研究者がフィードバックし、共同でブレストする
- Baseline Navigator(Stage 9): 実験ベースラインの選定をレビューし、ドメイン知識を注入する
- Paper Co-Writer(Stage 16-19): セクション別に共同執筆。AIのドラフトを段落単位で修正・指示できる
別ターミナルからの接続フロー
Co-Pilotモードで実行中のパイプラインには、別ターミナルから attach コマンドで接続できる。長時間実行中でも、いつでも状態を確認して介入できる。
# Co-Pilotモードで実行開始
researchclaw run --topic "Quantum noise as neural network regularization" \
--mode co-pilot
# 別ターミナルから接続
researchclaw attach artifacts/rc-2026-xxx
# 現在の状態を確認
researchclaw status artifacts/rc-2026-xxx
# 承認・却下・ガイダンス注入
researchclaw approve artifacts/rc-2026-xxx --message "LGTM"
researchclaw reject artifacts/rc-2026-xxx --reason "Missing key baseline"
researchclaw guide artifacts/rc-2026-xxx --stage 9 \
--message "Use ResNet-50 as primary baseline"
SmartPause機能が信頼度スコアを監視し、AIの判断に不確実性が高い箇所では自動的に人間に質問を投げる。これにより「確信のある箇所は一気通貫、怪しい箇所だけ相談」という効率的な分担が成立する。
初見では
--mode checkpoint を推奨。フェーズ境界で自動停止するため、23段階が何をやっているか肌感覚で掴める。慣れたら --mode co-pilot で仮説・実験・執筆だけ深く関与し、他は任せるのが最も生産的だ。
6モードで完全自律〜全段階承認までスライダー式に調整可能
Co-Pilotモードは Idea Workshop / Baseline Navigator / Paper Co-Writer で深く協調
別ターミナルから
attach で接続、approve / reject / guide で介入
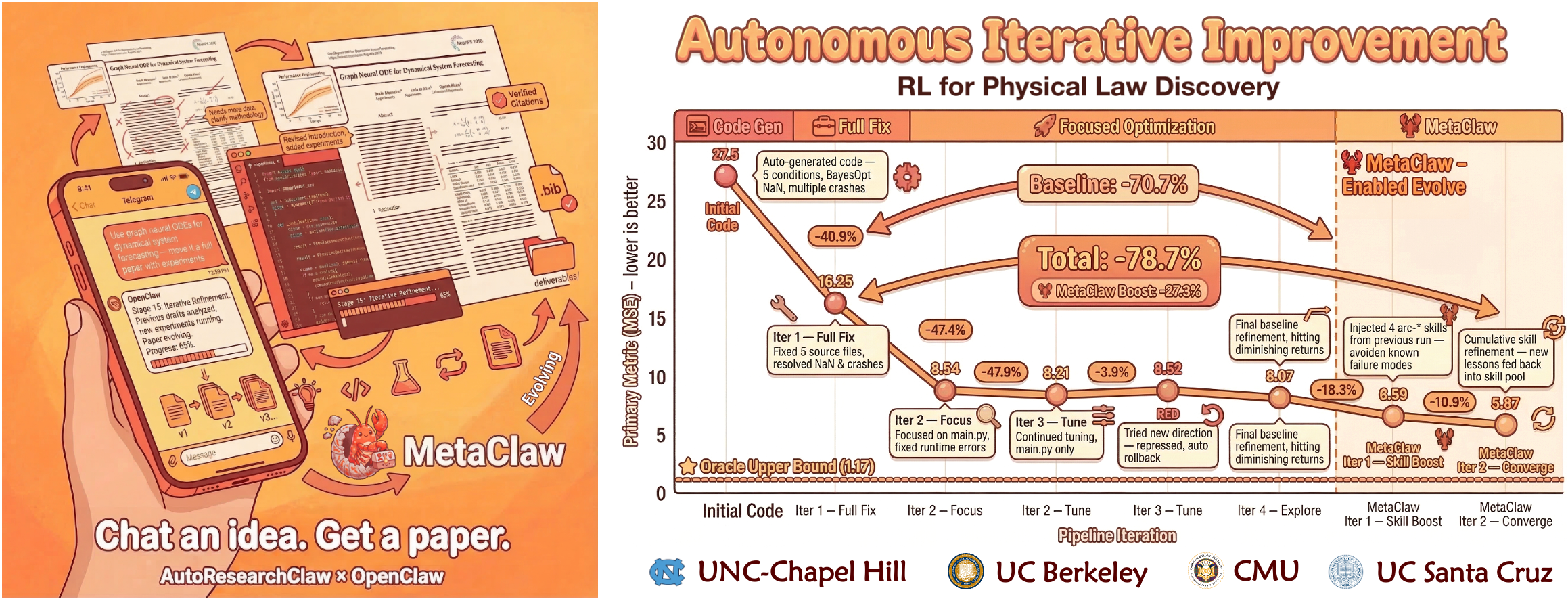
MetaClawで自己進化——実行ごとに賢くなる研究パイプライン
AutoResearchClawの思想で最も先進的なのが、MetaClaw と連携して「失敗から学習し次回は同じミスを繰り返さない」自己進化機能を備えている点だ。LangChain がRAGパイプラインの構成要素を抽象化するように、MetaClawは研究パイプラインの「学習層」を抽象化するレイヤーと理解できる。
Lesson → Skill 変換の仕組み
Lesson化"] B --> C["MetaClaw
Lesson → Skill 変換"] C --> D["~/.metaclaw/skills/
にSkillファイル保存"] D --> E["Run N+1
build_overlay() で
23段階の LLM プロンプトに注入"] E --> F["既知の落とし穴を回避
品質向上・リトライ削減"] F --> A
各Runで発生した失敗や警告は「Lesson」として記録され、MetaClawがそれをLLMが解釈できる「Skill」(短いプロンプト断片)に変換する。次回以降のRunでは、23段階すべてのLLM呼び出しにこのSkillが自動で注入され、過去の失敗を踏まえた推論が走る。
公式ベンチマーク結果
公式リポジトリが公開しているA/Bテスト(同一トピック・同一LLM・同一設定)は次のとおり。
| 指標 | ベースライン | MetaClaw有効 | 改善率 |
|---|---|---|---|
| ステージリトライ率 | 10.5% | 7.9% | -24.8% |
| Refineサイクル数 | 2.0 | 1.2 | -40.0% |
| パイプライン完走率 | 18/19 | 19/19 | +5.3% |
| 総合ロバストネス | 0.714 | 0.845 | +18.3% |
Refineサイクルが4割削減され、総合ロバストネスが18%向上する効果は、長時間実行するほど累積的に効いてくる。
有効化は数行の設定で済む
MetaClawはデフォルトOFFだが、有効化は設定ファイルに数行追加するだけだ。
# config.arc.yaml
metaclaw_bridge:
enabled: true
proxy_url: "http://localhost:30000"
skills_dir: "~/.metaclaw/skills"
lesson_to_skill:
enabled: true
min_severity: "warning"
max_skills_per_run: 3
min_severity で何を学習対象にするか、max_skills_per_run でプロンプト膨張を防ぐ上限を制御できる。既存環境への影響がないため、まず試してみる価値は高い。
MetaClawが失敗ログを Skill に変換し、次回Runに自動注入
Refineサイクル -40% / ロバストネス +18% を公式ベンチマークで報告
設定数行で有効化、デフォルトOFFなので既存環境を壊さない
他ツール比較とACP連携——AutoResearchClawの立ち位置
ここで他のAI研究支援ツールと機能を比較し、AutoResearchClawの独自性を整理しておく。
| 機能 | AutoResearchClaw | 一般的なLLM論文支援 | 手動ワークフロー |
|---|---|---|---|
| 文献検索 | OpenAlex/Semantic Scholar/arXiv自動取得 | ユーザーが論文URLを提供 | Google Scholar手動検索 |
| 引用検証 | 4層自動検証(arXiv/CrossRef/DataCite/LLM) | なし | 手動確認 |
| 実験実行 | サンドボックスで自動実行・自己修復 | コード生成のみ | 手動実行 |
| 論文執筆 | NeurIPS/ICML/ICLR テンプレート対応 | フリーフォーマット | 手動執筆 |
| 自己学習 | MetaClaw統合で実行ごとに改善 | なし | なし |
| Human-in-the-Loop | 6段階の介入モード | なし | 全て人間 |
| マルチエージェント | 仮説生成・査読で構造化ディベート | 単一LLM | なし |
ForgeCode のようなAIコーディングツールがソフトウェア開発を自動化するのと同様に、AutoResearchClawは研究プロセスに特化したエージェント設計を選んでいる。「コード生成だけでなく、仮説・実験・執筆・査読まで縦に統合した」点が最大の差別化ポイントだ。
ACP(Agent Client Protocol)対応
さらにAutoResearchClawはACP(Agent Client Protocol)に対応しており、Claude Code・Codex CLI・Copilot CLI・Gemini CLI・OpenCode・Kimi CLI など主要AIコーディングエージェントをバックエンドとして利用できる。ACPモードを使えばAPIキー管理をエージェント側に任せられるため、組織のシークレット管理ポリシーとも衝突しにくい。
# config.arc.yaml — ACP設定例
llm:
provider: "acp"
acp:
agent: "claude" # claude / codex / copilot / gemini / opencode / kimi
cwd: "."
OpenClaw経由のチャット起動
OpenClawとの連携を使うと、GitHubリポジトリURLを共有するだけでクローン・インストール・設定・実行・結果返却まで全自動で処理される。Discord・Telegram・Slack・WeChat 経由でも研究を開始できるため、研究室のSlackに「このアイデアで論文書いて」と投げるだけで数時間後にドラフトが戻ってくる、という使い方も現実的になっている。
Phase B/G(文献スクリーニング・論文執筆)はコンテキスト長と執筆品質が効くため高性能モデル、Phase E(実験コード生成)はコードベンチが高いモデル、それ以外は安価なモデル、と段階別に使い分けると費用対効果が最適化される。
primary_model と fallback_models の2段構えを活用しよう。
「仮説〜実験〜執筆〜査読まで縦統合」が他ツールに対する最大の差別化点
ACP対応で主要AIコーディングエージェントをそのままバックエンドに使える
OpenClaw連携でチャットツールから研究を起動可能
想定ユースケースと注意点——研究倫理・再現性を守るための設計
AutoResearchClawは強力だが、研究倫理と再現性の観点では使い方を選ぶ必要がある。想定される典型ユースケースと、やってはいけない使い方を整理しておく。
向いているユースケース
- 文献レビューの初稿作成: 数百件の論文を数時間でクラスタリングし、ギャップを可視化
- ベースライン実験の自動整備: 既知の手法をサンドボックスで再現し、新手法の比較相手を揃える
- アイデア壁打ち・仮説量産: Multi-Agent Debateで仮説候補を複数出させ、人間が取捨選択
- 授業・ゼミの教材生成: Step-by-Stepモードで学生に23段階を見せながら研究プロセスを教える
避けるべき使い方
- そのまま投稿: 生成された論文は必ず人間がレビューし、実験を自分で再現してから投稿する
- 他者の未公開データを勝手に食わせる: APIに送られたデータは外部LLMに渡る前提で扱う
- 査読論文として匿名性が重要な場面で使う: LLM経由で原稿が漏れるリスクを考慮する
「AIに書かせたドラフトをそのまま投稿する」行為は、ほとんどの学会で明示的に禁止または開示義務の対象になっている点にも注意が必要だ。
4層引用検証の中身
ハルシネーション対策として実装されている4層検証は、研究利用の信頼性を担保する要だ。
| レイヤー | 検証対象 | 使用データソース |
|---|---|---|
| L1: 存在確認 | 論文タイトル・著者・発行年の実在 | arXiv API |
| L2: DOI照合 | DOIが正しく登録されているか | CrossRef |
| L3: データセット照合 | データセット引用の実在性 | DataCite |
| L4: 意味一致 | 引用文脈と論文内容が一致するか | LLM照合 |
この4層をすべてパスしなかった引用は自動で除去または差し替え候補に降格される。捏造引用が混入すること自体は完全には防げないが、一次ソースとの照合ログが残る点で手動調査よりは再現性が高い。
向いているのは「初稿・壁打ち・ベースライン整備・教材生成」
投稿前レビュー必須、未公開データや匿名査読原稿の投入は避ける
4層引用検証(arXiv / CrossRef / DataCite / LLM)でハルシネーションを抑制
📌 まとめ
AutoResearchClawは、研究プロセス全体を23段階のパイプラインに落とし込み、1コマンドでLaTeX論文ドラフトまで到達する意欲的なOSSだ。ポイントを再掲する。
- 8フェーズ・23段階のパイプラインで文献調査から論文執筆までを一気通貫で自動化
- 6段階のHuman-in-the-Loopモードで「任せる範囲」をユースケースに合わせて調整できる
- MetaClaw連携により Refineサイクル -40% / ロバストネス +18% という自己進化を実現
- ACP対応で Claude Code・Codex CLI など主要エージェントをバックエンドに選べる
- 4層引用検証・2,699件テストパス・MIT Licenseという研究利用に耐える基盤
一方で、生成物は「ドラフト」であり、学会投稿前の人間レビューが必須という制約は忘れてはならない。AutoResearchClawは研究者を代替するツールではなく、文献整理・ベースライン構築・初稿生成といった再現性の高い雑務を肩代わりし、研究者の時間を本質的な考察・議論・実証に振り向けるための基盤として位置づけるのが最も健全な使い方だ。
研究エージェントに興味があれば、OpenHands でソフトウェアエンジニアリング系タスクの自律化を、Browser Use でブラウザ経由の情報収集自動化を、LangChain でRAGレイヤー構築を、ForgeCode でコード生成パイプラインの最適化を、それぞれ横断的に学ぶと研究自動化の全体像が見えてくる。