この記事ではAIエージェントに特化して解説します。AIエージェント全般は AIエージェントフレームワーク比較2026年版 をご覧ください。
DeepEyesV2とは――「画像で考える」エージェント型マルチモーダルAI
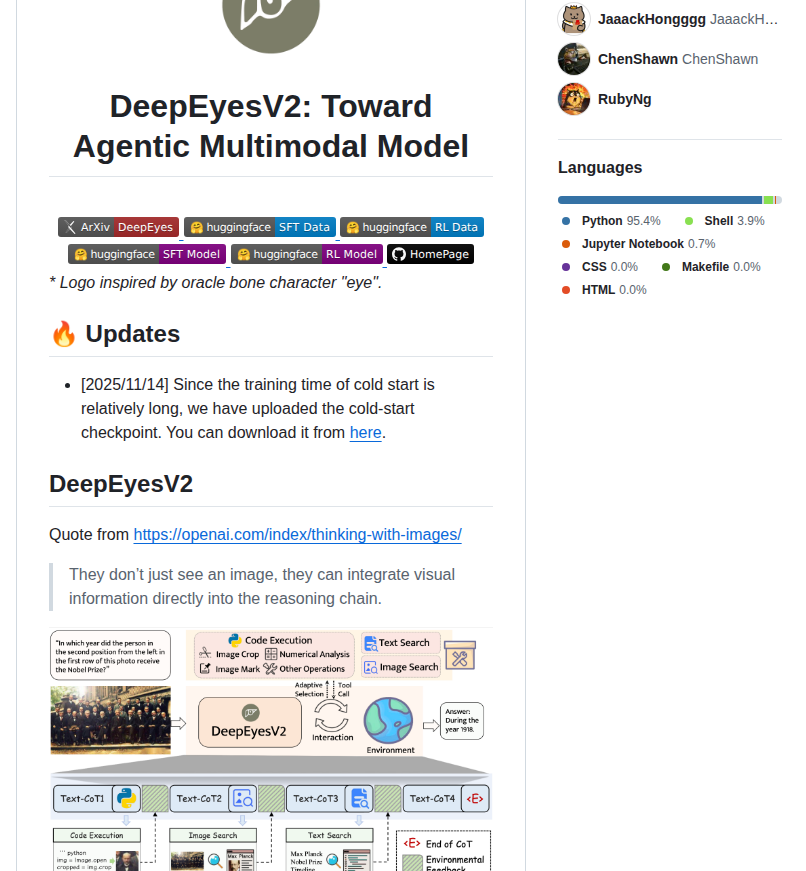
DeepEyesV2は、Visual-AgentチームがGitHubで公開しているエージェント型マルチモーダルモデルだ。Qwen2.5-VLをベースに、コード実行・ウェブ検索・視覚推論という3つの能力を単一の推論ループ内で統合している。OpenAIが提唱した「Thinking with Images(画像で考える)」というコンセプトを、オープンソースで具現化したプロジェクトである。
They don’t just see an image, they can integrate visual information directly into the reasoning chain. ――OpenAI “Thinking with Images”
従来のマルチモーダルモデルは、画像を「見る」ことはできても、その情報を推論チェーンに直接組み込むのは難しかった。DeepEyesV2はこの課題を解決し、画像入力をもとにコードを書いて実行し、必要に応じてウェブ検索で外部知識を取得し、その結果をさらに推論に活用する一連の流れを自律的に行う。単なる画像キャプショナーではなく、「画像を見て考え、道具を使い、答えを導く」自律エージェントだ。
公開されているのは7Bと32Bの2サイズで、いずれもApache 2.0ライセンス。モデルチェックポイントだけでなく、学習に使ったSFTデータセット、RLデータセット、画像検索キャッシュまでHugging Faceで配布されており、学習プロセスの再現や独自データでのファインチューニングが可能だ。
AIエージェントの自律的タスク処理に興味がある方は、コーディングエージェントのOpenHandsも合わせて参照すると、エージェント型AIの全体像が見えてくるだろう。
DeepEyesV2はQwen2.5-VLベースの7B/32Bエージェント型マルチモーダルモデル
コード実行・ウェブ検索・視覚推論を単一の推論ループで統合
モデル・データセット・検索キャッシュが全てApache 2.0で公開
アーキテクチャ全体像――3つのコア機能を1つのループに統合
DeepEyesV2のアーキテクチャは、3つのコア機能を単一の推論ループ内で統合している点が最大の特徴だ。モデルは画像とテキストを入力として受け取り、タスクの性質に応じてコード実行・ウェブ検索・視覚推論を動的に選択し、それぞれの結果を次の推論ステップに活用していく。
推論ループ"] B --> C["コード実行
Jupyter Sandbox"] B --> D["ウェブ検索
Online Search API"] B --> E["視覚推論
画像理解・分析"] C --> F["実行結果を
推論チェーンに統合"] D --> F E --> F F --> B B --> G["最終回答の生成"] style B fill:#4a90d9,color:#fff style F fill:#50c878,color:#fff
1. コード実行サンドボックス
DeepEyesV2はOpenAI o3と同様にJupyterスタイルのコード実行機能を持つ。モデルが生成したPythonコードをサンドボックス内で実行し、その結果(数値、グラフ、テーブルなど)を推論の次のステップに活用する。安全性を担保するためにDocker仮想化が推奨されており、公式から専用のDockerイメージ(chenshawn6915/multimodal-ipython-sandbox)が公開されている。
たとえば、画像中のグラフからデータを読み取り、Pythonで統計処理を実行し、その結果に基づいて最終的な判断を下すといった複合的なタスクが、単一の推論ループ内で完結する。
2. オンラインウェブ検索
LangChainのようなRAGパイプラインではなく、オンライン検索を直接推論ループに統合している点が特徴的だ。テキスト検索と画像検索の両方に対応し、モデルが推論中に外部知識を能動的に取得できる。画像検索にはMMSearch-R1のキャッシュを利用し、テキスト検索は独自のオンライン検索サービスに接続する。検索APIのカスタマイズも可能で、reinforcement_learning/verl/workers/agent/envs/deepeyesv2/search_utils.pyを編集することで独自の検索エンジンに差し替えられる。
3. 視覚情報の推論チェーン統合
画像を単にキャプション化するのではなく、視覚情報を推論チェーンの各ステップに直接組み込む。これにより、画像中の細部に基づいた複雑な判断や数学的推論が可能になる。公式論文で引用されているOpenAIの「Thinking with Images」のコンセプトを体現しており、画像を「見て、考えて、道具を使って、答えを出す」という人間に近い推論プロセスを実現している。
3つのコア機能(コード実行・ウェブ検索・視覚推論)を単一ループで統合
Jupyterサンドボックス内蔵でo3と同等のコード実行能力を持つ
検索は外部RAGではなくエージェント内蔵の能動的アクション
学習パイプライン――Cold StartからRLまでの二段階構成
DeepEyesV2の学習は、Cold Start(SFT)と強化学習(RL)の二段階で構成されている。厳密なデータフィルタリングとクリーニングを経て構築された学習コーパスが、両段階で相互補完的に活用される。この二段階アプローチにより、まずSFTでツール利用の基本パターンを習得させ、次にRLでタスクに応じた適応的なツール組み合わせを獲得させる段階的な能力構築が実現されている。
| 学習段階 | 手法 | ベースモデル | データセット | 目的 |
|---|---|---|---|---|
| Cold Start | SFT(教師ありファインチューニング) | Qwen2.5-VL-7B/32B-Instruct | DeepEyesV2_SFT | ツール利用の基本パターンを学習 |
| 強化学習 | RL(LLM-as-a-Judge) | SFTモデル | DeepEyesV2_RL | 複雑なツール組み合わせを獲得 |
Cold Startの実行
Cold StartにはLLaMA-Factoryを使用する。以下のコマンドで実行できる。
# LLaMA-Factoryを先にインストールしておく
# ベースモデル: Qwen-2.5-VL-7B-Instruct(32Bも対応)
cd DeepEyesV2
bash ./cold_start/run_cold_start.sh
強化学習の環境構築
強化学習にはDeepEyesの同一コードベースとVeRLを使用する。
cd reinforcement_learning
# VeRL公式インストール手順に従う
pip install -e .
# DeepEyes追加依存パッケージのインストール
bash scripts/install_deepeyes.sh
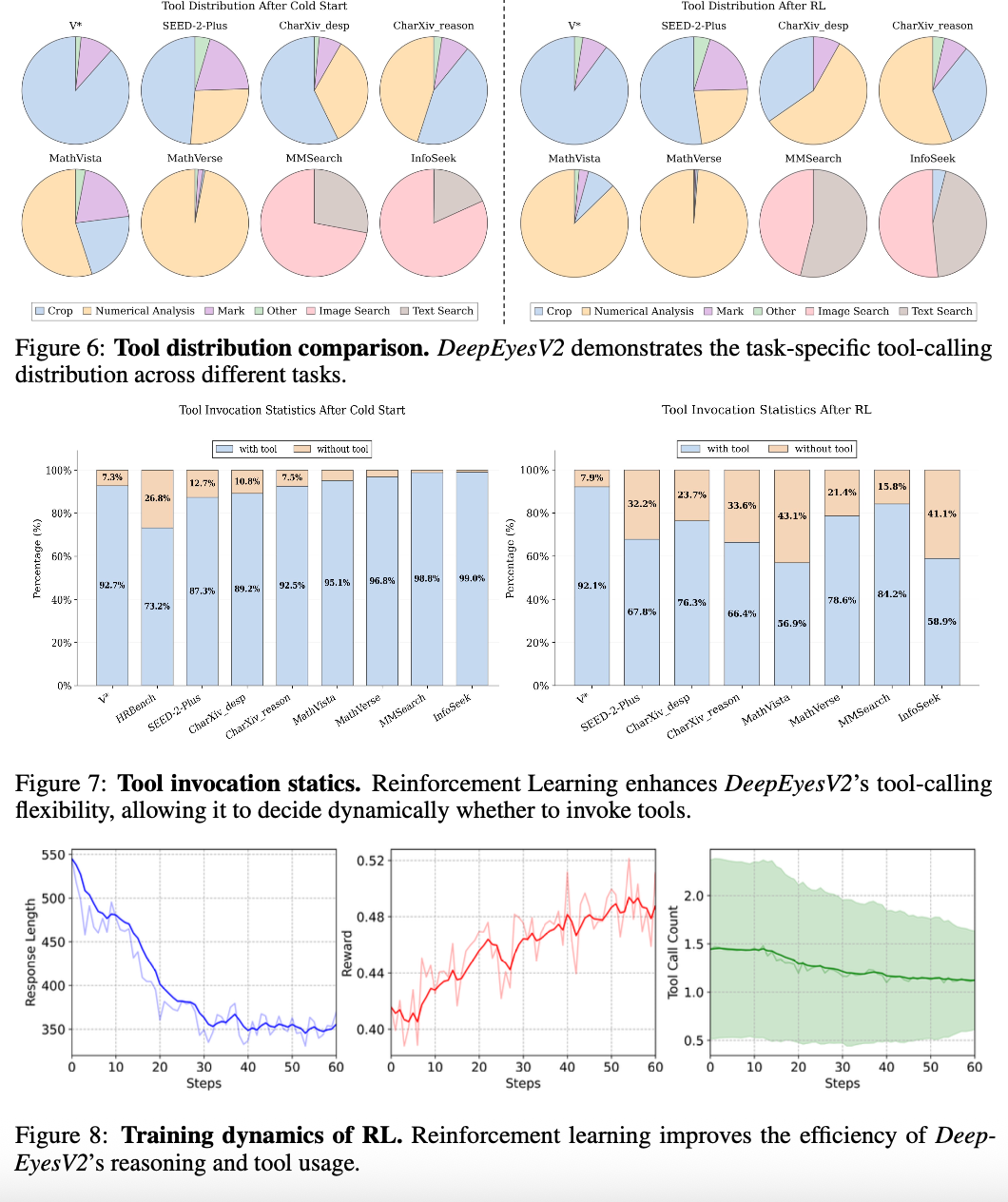
公式READMEによると、強化学習の興味深い発見として、RLによりモデルがより複雑なツール組み合わせと、コンテキストに応じた適応的なツール呼び出しを獲得することが確認されている。たとえば、数学の問題ではコード実行の頻度が高まり、知識が必要な問題ではウェブ検索が多用されるなど、タスクの性質に応じてツール利用パターンが動的に変化する。
SFTデータセットとRLデータセットは同じ公開コーパスから派生しているため、独自データで拡張する場合は
image + instruction + tool_traceのフォーマットを守ることが重要だ。タスク種別(math / search / vqa)を明示的にタグ付けすると、RL段階で報酬設計がしやすくなる。
Cold Start(SFT)でツール利用の基本を習得→RLで適応的な組み合わせを獲得
SFTはLLaMA-Factory、RLはVeRLベースのDeepEyesコードで実行
RLによりタスクの性質に応じたツール使い分けが自然に出現
コードサンドボックスとJudgeサーバーの構築
DeepEyesV2を実際に動かすには、コード実行用のサンドボックスとLLM-as-a-Judge用のサーバーを構築する必要がある。この2つのサービスは学習と推論の両方で利用される基盤コンポーネントだ。
コードサンドボックスのデプロイ
コードサンドボックスはDockerイメージとして提供されている。RL学習時に大量の高解像度画像を単一ノードに送信すると帯域が飽和するため、複数のコードサーバーを各GPUノードにローカルデプロイすることが推奨されている。
# Dockerイメージを取得
docker pull chenshawn6915/multimodal-ipython-sandbox
# 各GPUノード上でローカル起動(例: ポート8000)
docker run -d --name ipython-sandbox \
-p 8000:8000 \
--shm-size=16g \
chenshawn6915/multimodal-ipython-sandbox
# デプロイ手順の詳細:
# https://github.com/ChenShawn/MultiModal-Jupyter-Sandbox
Judgeサーバーの起動
評価にはQwen-2.5-72B-Instructを使用したLLM-as-a-Judge方式を採用している。vLLMでサービングする。
# Qwen-2.5-72B-Instructモデルのダウンロード
huggingface-cli download --resume-download \
Qwen/Qwen2.5-72B-Instruct \
--local-dir /path/to/your/local/filedir \
--local-dir-use-symlinks False
# vLLMサービングの起動(A100/H100 x 8想定)
vllm serve /path/to/your/local/filedir \
--port 18901 \
--gpu-memory-utilization 0.8 \
--max-model-len 32768 \
--tensor-parallel-size 8 \
--served-model-name "judge" \
--trust-remote-code \
--disable-log-requests
サンドボックスもJudgeサーバーも、学習ジョブからは単なるHTTPエンドポイントとして見える。ネットワーク帯域とGPUメモリの両方を意識した配置設計が、大規模分散RLの成否を分ける。
コード実行はDocker隔離サンドボックスで複数ノードに分散配置が必須
LLM-as-a-JudgeにはQwen-2.5-72B-InstructをvLLMでサービング
両サービスは学習・推論の共通インフラとして常時稼働させる
強化学習の実行――32GPU以上の大規模分散学習
RL学習の実行には大規模な計算リソースが必要だ。公式の推奨スペックは以下の通りである。
| モデルサイズ | 最低GPU数 | 構成 | CPU RAM(ノードあたり) |
|---|---|---|---|
| 7B | 32 GPU | 4ノード × 8 GPU | 1200GB以上 |
| 32B | 64 GPU | 8ノード × 8 GPU | 1200GB以上 |
高解像度画像の処理が大量のメモリを消費するため、CPU RAMの要件が極めて高いことに注意が必要だ。一般的なクラウドGPUインスタンスでは1200GBのRAM要件を満たせない場合が多く、ベアメタルサーバーや専用HPCクラスタでの実行が前提となる。
cd reinforcement_learning
# wandbでトレーニングの可視化を有効化
wandb login
# Judgeサーバーのエンドポイントを環境変数で指定
export LLM_AS_A_JUDGE_BASE="http://your.vllm.machine.ip:18901/v1"
# サンドボックスのエンドポイント一覧(ノード毎)
export SANDBOX_URLS="http://node1:8000,http://node2:8000,http://node3:8000,http://node4:8000"
# 7Bモデルの学習開始
bash examples/deepeyesv2/run_qwen2_5_vl-7b_final_allin.sh
学習の可視化にはwandbとRL Logging Boardの両方が利用可能だ。パラメータ調整時にForgeCodeのようなAIコーディングツールで学習スクリプトを書き換えながら回すと、実験サイクルを短縮できる。
よくあるエラーと対処
| エラー現象 | 原因 | 対処 |
|---|---|---|
OOM on CPU |
画像バッチサイズが大きすぎる | max_pixelsを下げる・train_batch_size_per_gpu削減 |
sandbox timeout |
単一ノードに負荷集中 | サンドボックスをノード毎にデプロイしSANDBOX_URLSをラウンドロビン化 |
judge rate limit |
Judgeサーバーのリクエスト詰まり | tensor-parallel-sizeを増やすか、複数インスタンスで負荷分散 |
rollout collapse |
報酬設計が偏っている | tool-useボーナスを再調整、evalセットで定期チェック |
フルスケール学習が難しい場合は、公式が公開しているSFTチェックポイントから少量データでLoRAファインチューニングする形でも、タスク特化モデルを構築できる。まずは推論だけ試したい場合はRL最終モデル
honglyhly/DeepEyesV2_7B_1031をそのまま読み込むのが最速だ。
7Bで32GPU・32Bで64GPU+ノード毎1200GB RAMが公式推奨
Judgeサーバーとサンドボックスのエンドポイントを環境変数で明示指定
フルスケールが難しい場合はSFT済みチェックポイント+LoRAで代替可能
ベンチマーク結果と従来モデルとの比較
公式リポジトリでは、リアルワールド理解、数学推論、検索集約型ベンチマークにおける広範な実験結果が報告されている。DeepEyesV2は7Bという比較的小さなパラメータ数ながら、ツール利用の統合によって高い性能を発揮している。
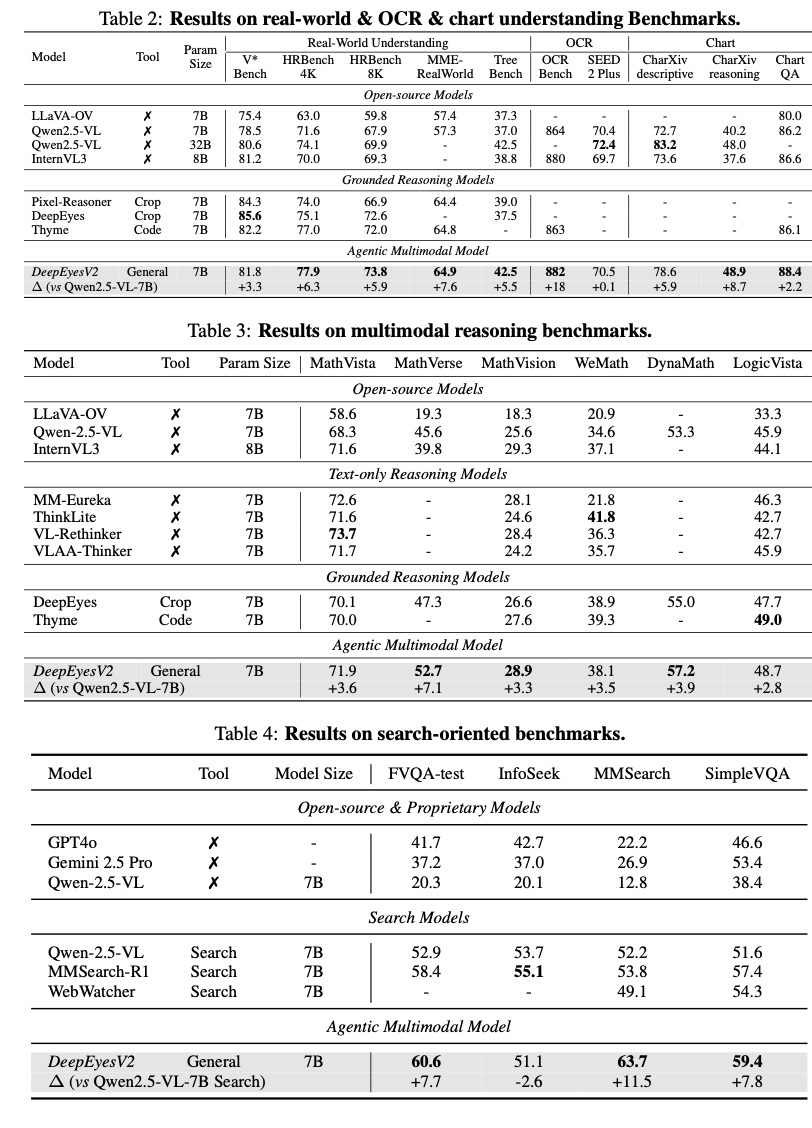
DeepEyesV2の特筆すべき点は、強化学習によるツール利用パターンの動的な適応である。タスクの種類に応じて、コード実行の頻度、検索の利用回数、視覚推論の深さが自動的に調整される。
従来マルチモーダルモデルとの機能比較
| 特徴 | 従来のマルチモーダルモデル | DeepEyesV2 |
|---|---|---|
| 画像理解 | キャプション生成・分類中心 | 推論チェーンに直接統合 |
| コード実行 | 非対応または外部連携 | Jupyterサンドボックス内蔵 |
| ウェブ検索 | 非対応 | オンライン検索を推論中に実行 |
| ツール利用 | 固定パイプライン | RLにより適応的に組み合わせ |
| 学習データ | 汎用データセット | 厳密フィルタリング済みSFT+RL |
| モデルサイズ | 多様 | 7B/32B(Qwen2.5-VLベース) |
| ライセンス | 多様 | Apache 2.0 |
他のエージェント型AIとの棲み分け
| エージェント | 主戦場 | 強み | 相性の良いタスク |
|---|---|---|---|
| DeepEyesV2 | マルチモーダル推論 | 画像+コード+検索の統合 | グラフ読み取り、画像ベースの事実確認、数学図形問題 |
| Browser Use | ブラウザ操作 | DOM理解・UI自動化 | スクレイピング、フォーム入力、Webワークフロー |
| OpenHands | コーディング | 長時間のコード生成・修正 | リポジトリ改修、PR作成、バグ修正 |
| LangChain | RAGパイプライン | 構築済みナレッジの検索 | 社内ドキュメントQA、FAQ応答 |
DeepEyesV2はブラウザ操作ではなくマルチモーダル推論とツール統合に焦点を当てており、他のエージェントとは棲み分けが明確だ。Browser Useが「ウェブページを操作する」エージェントであるのに対し、DeepEyesV2は「画像を見て考え、コードを書き、検索で知識を補い、答えを導く」エージェントである。
7Bながらツール統合で高性能を実現、タスクに応じてツール利用が動的に変化
Browser Useはブラウザ操作、DeepEyesV2はマルチモーダル推論で棲み分け
Apache 2.0ライセンスで商用利用可能、再現実験もデータ公開で可能
利用可能なモデルとデータセット
Hugging Faceで以下のリソースが公開されている。すべてApache 2.0ライセンスで、研究・商用利用の両方に対応している。モデルチェックポイントだけでなく、学習データセットと検索キャッシュも公開されているため、学習プロセスの再現や独自データでのファインチューニングが可能だ。
| リソース | リンク | 用途 |
|---|---|---|
| SFTモデル(7B) | honglyhly/DeepEyesV2_7B_SFT_1031 | Cold Startチェックポイント |
| RLモデル(7B) | honglyhly/DeepEyesV2_7B_1031 | 最終モデル |
| SFTデータセット | honglyhly/DeepEyesV2_SFT | Cold Start学習用 |
| RLデータセット | honglyhly/DeepEyesV2_RL | 強化学習用 |
| 検索キャッシュ | honglyhly/DeepEyesV2_Search_Cache | 画像検索キャッシュ |
とりあえず推論だけ試したい場合
Hugging Face Transformersから直接ロードできる。Qwen2.5-VLの推論コードがそのまま動く。
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from PIL import Image
model_id = "honglyhly/DeepEyesV2_7B_1031"
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
)
processor = AutoProcessor.from_pretrained(model_id)
image = Image.open("chart.png")
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image},
{"type": "text", "text": "このグラフから売上のトレンドを分析して。"},
],
}
]
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt",
).to(model.device)
out = model.generate(**inputs, max_new_tokens=512)
print(processor.decode(out[0], skip_special_tokens=True))
ただし、この方法ではコード実行とウェブ検索のエージェントループは動かない。フル機能を使うには公式リポジトリのサンドボックスと検索サービスを立ち上げて、エージェントランタイム経由で推論する必要がある。
モデル・データセット・検索キャッシュがすべてHugging Faceで公開
Qwen2.5-VL互換コードで単純な画像QAだけならすぐ試せる
フル機能(コード実行+検索)はランタイム構築が必要
スキル&エージェントとの比較――いつDeepEyesV2を選ぶか
Claude CodeのSkillsやMCP、ブラウザ操作エージェント、RAGフレームワークなど、エージェント系のオープンソースは百花繚乱だ。DeepEyesV2を選ぶべき状況はどこか、整理しておく。
| 状況 | 推奨される選択肢 | 理由 |
|---|---|---|
| 画像ベースの数理・分析問題 | DeepEyesV2 | コード実行+視覚推論の統合が唯一の近道 |
| 社内ドキュメントQA | LangChain+ベクターDB | RAGが最短経路、マルチモーダル不要なら過剰 |
| ブラウザ自動化 | Browser Use | DOM理解はDeepEyesV2の守備範囲外 |
| 大規模コード改修 | OpenHands | 長時間コード生成+Git操作に特化 |
| 自分のワークフローを教える | Claude Skills | SKILL.mdで軽量に拡張可能 |
「画像を見て、数値を計算し、背景知識を検索し、総合的な判断を返す」——このサイクルが必要な場合に限り、DeepEyesV2は他を圧倒する。逆にテキストのみのタスクや、純粋なコード生成タスクでは、よりスコープを絞った専用エージェントの方が速く・安く解ける。
よくあるユースケース
- 科学論文の図表解析: チャートを読み取り、数値を抽出、Pythonで再計算して仮説を検証
- E-commerce商品画像のファクトチェック: 画像内の表記をウェブ検索と突き合わせて整合性確認
- 教育分野の図形問題: 幾何図を理解してPythonで数値計算、解答ステップを生成
- 医療画像の解析補助: 定量指標を計算し、関連論文をウェブ検索して参考情報を添える
Browser Useでスクリーンショットを取得→DeepEyesV2で画像解析、というようにパイプライン化すると、「Webページのビジュアルまで含めた自動理解」が可能になる。MCP経由で複数エージェントを連携させる構成は、今後のエージェント設計の主流になる見込みだ。
「画像+コード+検索」が同時に必要なタスクでDeepEyesV2が最適
テキストのみ・コードのみのタスクは専用エージェントの方が効率的
他エージェントとパイプライン化すればマルチモーダル自動化が実現
📌 まとめ
DeepEyesV2は、従来のマルチモーダルモデルが抱えていた「画像理解とツール利用の分離」を、単一の推論ループで統合することで解決した。
ポイントを改めて整理すると次の通りだ。
- アーキテクチャ: Qwen2.5-VLベース、コード実行・ウェブ検索・視覚推論を1ループに統合
- 学習: Cold Start(SFT)→ RL(LLM-as-a-Judge)の二段階、VeRL+LLaMA-Factoryで実装
- インフラ: Dockerサンドボックス+vLLM Judgeサーバーが必須、ノード毎ローカル配置が推奨
- スケール: 7Bで32GPU/32Bで64GPU、CPU RAMは1200GB以上
- 公開リソース: モデル・データセット・検索キャッシュ全てApache 2.0
- 差別化: Browser Useやコーディングエージェントと棲み分け、「画像で考える」領域に特化
「画像を見て、コードを書いて、検索して、答える」——このサイクルをオープンソースで実現したDeepEyesV2は、マルチモーダルAIエージェントの次の標準になる可能性を秘めている。
まずはhonglyhly/DeepEyesV2_7B_1031をHugging Faceからダウンロードして、手元の画像で簡単な推論を試すところから始めてみてほしい。フル機能が必要になったときに、公式リポジトリのサンドボックスと検索サービスを立ち上げる——この段階的なアプローチが、実運用までの最短経路だ。