2026年5月、Anthropic主催の「Code with Claude」イベントでOmniのCTO・Chris Merrickが登壇し、自社のアジェンティック分析プラットフォーム「Blobby」の設計判断を全公開した。99%のコードをClaude Codeで書き、月間1033億トークンを消費する本番システムがどのように進化してきたか。18ヶ月の試行錯誤と5回の「手術(Blobotomy)」の記録を一次ソースから読み解く。
- OmniがClaudeを中心に据えたアジェンティック分析ハーネスの全体設計
- セマンティック層がClaudeのコンテキスト問題をどう解決するか
- Blobbyエージェントの18ヶ月進化史とBlobotomy(手術)の内容
- HaikuからSonnetへの移行と使用量爆発のメカニズム
- 45ツール・エバリュエーション体制まで含む現在のシステム設計
AIエージェントの設計パターン全般についてはAIエージェントフレームワーク比較2026年版を参照されたい。本記事ではOmniが採用した実装判断を深掘りする。
Omniとは何か、そしてなぜClaudeを選んだか
Omni(omni.co)は2022年にサンフォランシスコで創業されたAIアナリティクスプラットフォームだ。「ビジネスに関するfast・trustworthy・answerをすべての人に届ける」というミッションのもと、約30名のエンジニアと200名の全社員がPerplexity、Mercury、dbt Labs、BambooHR、Synthesiaなど多数の企業顧客にサービスを提供している。
Chris Merrick自身は「CTOとして成長する会社で、いつかコードを書くのをやめなければならないと思っていたが、Claudeのおかげで今もエンジニアリングができている」と語る。プラットフォームコードの99%をClaude Codeで書き、Claude Codeへの全面移行以降、コミット数のスロープが目に見えて改善した。
重要なのは、Omniがただの「Claude活用企業」ではなく、ClaudeをコアエンジンとするB2B向けAIアナリティクス基盤として製品を設計しているという点だ。この立場が、ハーネスの設計判断に独自の深みをもたらしている。
ClaudeがOmniのアナリティクスハーネスのコアである理由
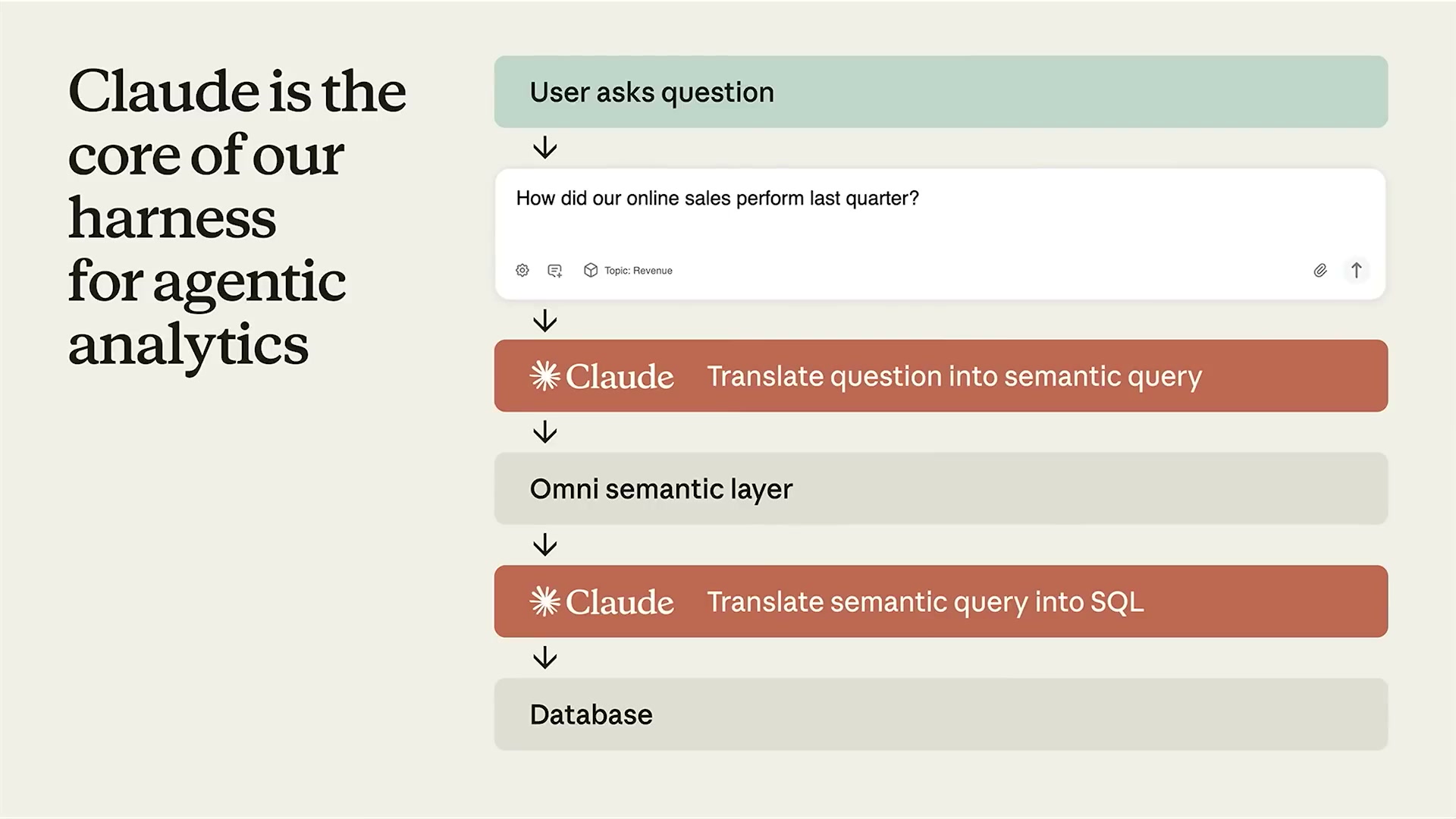
Omniのシステム設計はシンプルなフローで説明できる。ユーザーが「先四半期のオンライン売上はどうだったか?」と質問する。Claudeがその質問をセマンティッククエリに変換する。Omniのセマンティック層がそのクエリをSQLに変換する。結果がデータウェアハウスから返ってくる。
このフローの中で「Claude」が2か所に登場する。最初の自然言語理解と、最終的なSQL生成だ。単なるインターフェース以上に、Claudeがビジネスロジックの理解と技術的変換の両方を担っている。
コンテキストがなければClaudeは答えられない

このスライドが示す問題は根深い。「先四半期のオンライン売上はどうだったか?」という質問には:
- “our”(自社全体か担当リージョンか)
- “online”(モバイルアプリ・店舗受取注文を含むか)
- “sales”(返品・キャンセル・割引を含むか)
- “last quarter”(暦年四半期か財務四半期か)
という4つの解釈の余地がある。Chris自身がOmni社内でこの問題に直面していた。プロダクト・エンジニアリング部門では「last quarter」は暦年四半期を指し、セールスチームでは会計四半期を指す。これをすべてセマンティック層に定義として組み込まなければ、Claudeは間違った答えを返し続ける。
Omniのセマンティック層:Claudeを誘導する4つの機能

Omniのセマンティック層は4つの役割を果たす:
1. Curation(キュレーション) 実際の企業データウェアハウスには数万〜数十万のデータセットがある。同じ「revenue」テーブルが100個存在することもある。どれを使うべきか。セマンティック層がClaudeに「このテーブルを使え、他は無視しろ」と伝える。
2. Context(コンテキスト) メタデータ経由でClaudeをビジネス文脈に追いつかせる。フィールド定義・用語・典型的なクエリパターンを記述することで、Claudeが業務データを正しく解釈できるようになる。
3. Permissions(パーミッション) ユーザーが見るべきデータにしかアクセスできないことを保証する。役員データをアナリストに見せない、地域データを他地域の担当者に見せないといった制御だ。
4. Feedback Loop(フィードバックループ) ビジネスデータは常に変化する。フィードバックループが次の質問への回答を前回の学習に活かし、定義を継続的に改善する。
Chris Merrickは「Claude Codeを使っている人は、CLAUDE.mdファイルを知っているだろう。コードに対してコンテキストを定義するように、セマンティック層はデータに対してコンテキストを定義する。コードに近い場所にコンテキストを書くほど良い結果が出るように、データフィールドの定義に直接コンテキストを書くことが重要だ」と語る。
AIエージェント「Blobby」の誕生
Omniのエージェントの名前はBlobbyだ。丸くてピンク色のキャラクターで、「成熟したプロフェッショナルなデータアナリスト」として設計されている。
Blobbyの構築は18ヶ月前に始まった。初期バージョンは単純なQ&Aシステムだったが、段階的な改良と5回の「Blobotomy(手術)」を経て、現在の洗練されたアジェンティックシステムへと進化した。
デモでBlobbyが行うこと:
- 「先会計四半期のomniリポジトリのPRを週次で見せて」という質問を受け取る
- GitHubプルリクエストに対応するトピックを特定する
github__issue_merged.merged_atフィールドとgithub__repository.nameフィールドを確認する- リポジトリ名の候補値をルックアップして「omni」を特定する
- クエリを生成してデータウェアハウスに実行する
- 結果を可視化してサマリーを提供する
Phase 1:展開メタデータで精度を底上げする

初期のBlobbyは単純なラベルと説明しか持っていなかった。最初の改良として、Omniは以下の「展開メタデータ」を追加した:
# セマンティック層のメタデータ定義例
first_name:
label: "First Name"
description: "first name in salesforce"
opportunity_topic:
ai_context: |
description: "use this Topic to answer questions about sales, revenue, etc."
iarr_by_quarter:
sample_queries:
query:
fields: ["close_date_quarter", "iARR"]
base_view: "opportunity"
region:
all_values: ["EMEA", "NAM", "APAC"]
ai_contextは「LLMがこのフィールドをどう使うべきか」を明示的に記述するフィールドだ。通常のdescriptionとは別に、AIに特化したガイダンスを提供する。
sample_queriesは典型的なユースケースを具体的なクエリとして示すことで、Claudeが「このフィールドを使うとはこういうことだ」を理解できるようにする。
all_valuesが特に効果的だった。regionフィールドの値が「EMEA」「NAM」「APAC」だとわかれば、Claudeは「これらは世界の地域の略語だ」と推測し、「United States」と入力されたときに「NAM」でフィルタリングすべきだと判断できる。タイポへの対応(ファジーマッチング)にも機能する。
Phase 2:アジェンティックループの導入とタスク管理

メタデータ改善だけでは不十分だった。Blobbyはまだ「エージェント」ではなく、単なる洗練されたQ&Aシステムに過ぎなかった。次のフェーズは自社でアジェンティックハーネスをゼロから構築することだった。
このアジェンティックループで最も効果的だったのはエラー回復機能だ。
早期に行った最大のクオリティ改善の一つが:
- Blobbyにエラーからどうリカバリするかを教えること
- 実行予算(何回再試行してよいか)を与えること
- エラーメッセージを「何が起きているか・どう修正するか」を説明する高品質なものにすること
この3点だけで、難しいEvalのスコアが劇的に改善した。
# アジェンティックループの概念的な実装
class BlobbyAgent:
def execute(self, question: str, max_iterations: int = 50) -> str:
tasks = self.plan_tasks(question)
for task in tasks:
attempts = 0
while attempts < MAX_RETRY:
try:
result = self.execute_task(task)
self.checkpoint(result) # outer loop: durable execution
break
except QueryError as e:
# 高品質なエラーメッセージで自己修正を促す
error_context = self.build_error_context(e)
task = self.revise_task(task, error_context)
attempts += 1
return self.synthesize_results()
モデル切り替え:HaikuからSonnetへ、使用量爆発の転換点
初期のアジェンティックフェーズではHaikuモデルを使っていた。Haikuはシンプルなタスクには優れているが、複雑なアジェンティック会話には設計されていない。Sonnetへ切り替えた理由は2つだ:
1. 会話が長くなった アジェンティックループでは、エージェントが複数のステップをたどり、ツールを呼び出し、エラーから回復する。これは単純なQ&Aより遥かに多くのコンテキストを必要とし、トークン消費量が増える。これは意図的な設計判断だった。
2. これがブロッカー解消につながった Sonnet移行後、顧客から「このシステムが以前は答えられなかった質問に答えてくれた」「2分で解決した」というフィードバックが続々と届くようになった。使用量はここから急騰し始める。
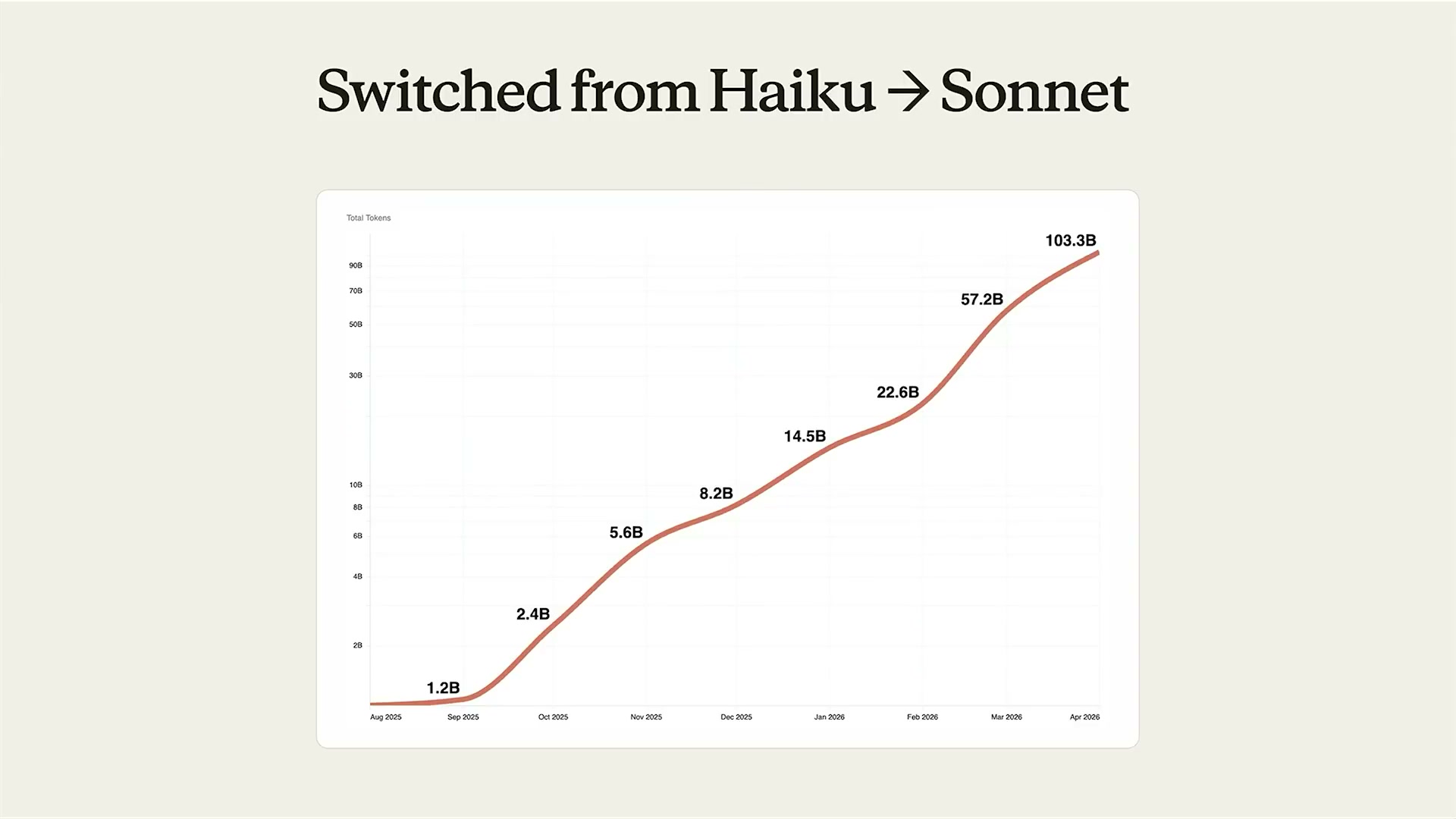
グラフが示すように、月次消費量の成長率は指数的だ:
- 2025年8月:1.2B
- 2025年10月:2.4B(2倍)
- 2025年11月:5.6B(2.3倍)
- 2026年1月:14.5B(5.8倍)
- 2026年4月:103.3B(86倍)
これはプロダクトへの信頼が積み重なり、顧客の使い方が変化したことを示している。
Blobotomy 1:スプリットブレインの解消

Omniの最初のアジェンティック設計は「少し賢すぎた」。アーキテクチャはこうだった:
- アウターエージェント:タスクリストの作成、利用可能なデータの把握、計画立案を担当
- クエリ生成サブエージェント:実際のクエリ生成のみを担当
この分離は合理的に見えた。クエリ生成サブエージェントを他のコンテキストでも使い回せるからだ。しかし実際のトレースを見ると問題が明らかになった。
スプリットブレインの問題:アウターエージェントは「どんなデータが利用可能か」を知っていたが、「1つのクエリで何が取得できるか」は知らなかった。そこでアウターエージェントが「GitHubプルリクエストとサポートデータを組み合わせてサマリーしてくれ」とサブエージェントに依頼すると、サブエージェントが「それは1つのクエリでは答えられない」と返してくる。この往復が無限ループの原因になっていた。
エンジニアのJoelが「脳の統合」と呼んだ解決策は:クエリ生成ツールをアウターエージェントのハーネスに直接統合することだった。
# 統合前:サブエージェント呼び出し
outer_agent.plan("GitHubとサポートデータを分析して")
# → sub_agent.generate_query() が「1クエリでは無理」と返す
# → 往復エラーが発生
# 統合後:ツールとして直接利用
class OuterAgentHarness:
tools = [
QueryGenerationTool(), # 直接ハーネスに組み込む
DashboardTool(),
VisualizationTool(),
ValidationTool(),
ModelingTool(),
]
この変更で「見かけ上ランダムに見えた予測不能な動作」の多くが解消した。
Blobotomy 2:SQL生成の刷新

Omniには以前から独自のJSONクエリ形式があった。Claudeにはこの独自形式を学習させてクエリを生成させていたが、問題があった:
- 独自形式なのでClaudeには事前知識がなく、プロンプトで都度教える必要がある
- 複雑なクエリは独自形式では表現しにくい
- 複数のクエリを連鎖させなければ答えられないケースが頻発する
転換点:実はOmni創業当初にSQLパーサーを内部実装していたが、「全てのSQL変形に対応できない」という理由で使用を断念していた。しかし「ClaudeはSQLが得意だ。AnthropicはClaudeのSQL能力に投資し続けている。これに賭けよう」という判断でパーサーを復活させた。
エンジニアのStephenが古いパーサーを改良し、クエリ生成インターフェースをSQLに切り替えた:
-- Claudeが生成するSQL(CTEを使った複雑なクエリの例)
WITH weekly_prs AS (
SELECT
DATE_TRUNC('week', merged_at) AS week_start,
COUNT(DISTINCT pull_request_id) AS pr_count
FROM github_pull_requests
WHERE
repository_name = 'omni'
AND base_ref = 'main'
AND merged_at IS NOT NULL
AND merged_at >= DATE_TRUNC('quarter', CURRENT_DATE - INTERVAL '3 months')
AND merged_at < DATE_TRUNC('quarter', CURRENT_DATE)
GROUP BY DATE_TRUNC('week', merged_at)
)
SELECT
week_start,
pr_count,
SUM(pr_count) OVER (ORDER BY week_start) AS cumulative_prs
FROM weekly_prs
ORDER BY week_start;
Chris Merrickが注目したのは、ClaudeがCTE(Common Table Expression:共通テーブル式)を好む点だ。Omniのパーサーがこの構文を得意としていたため、SQLベースの生成への移行は非常に効果的だった。
結果として:
- 独自形式を教えるプロンプトが不要になった
- 3〜4回試行が必要だったクエリが1回で生成できるようになった
- システム全体の効率が大幅に向上した
現在のシステムアーキテクチャ
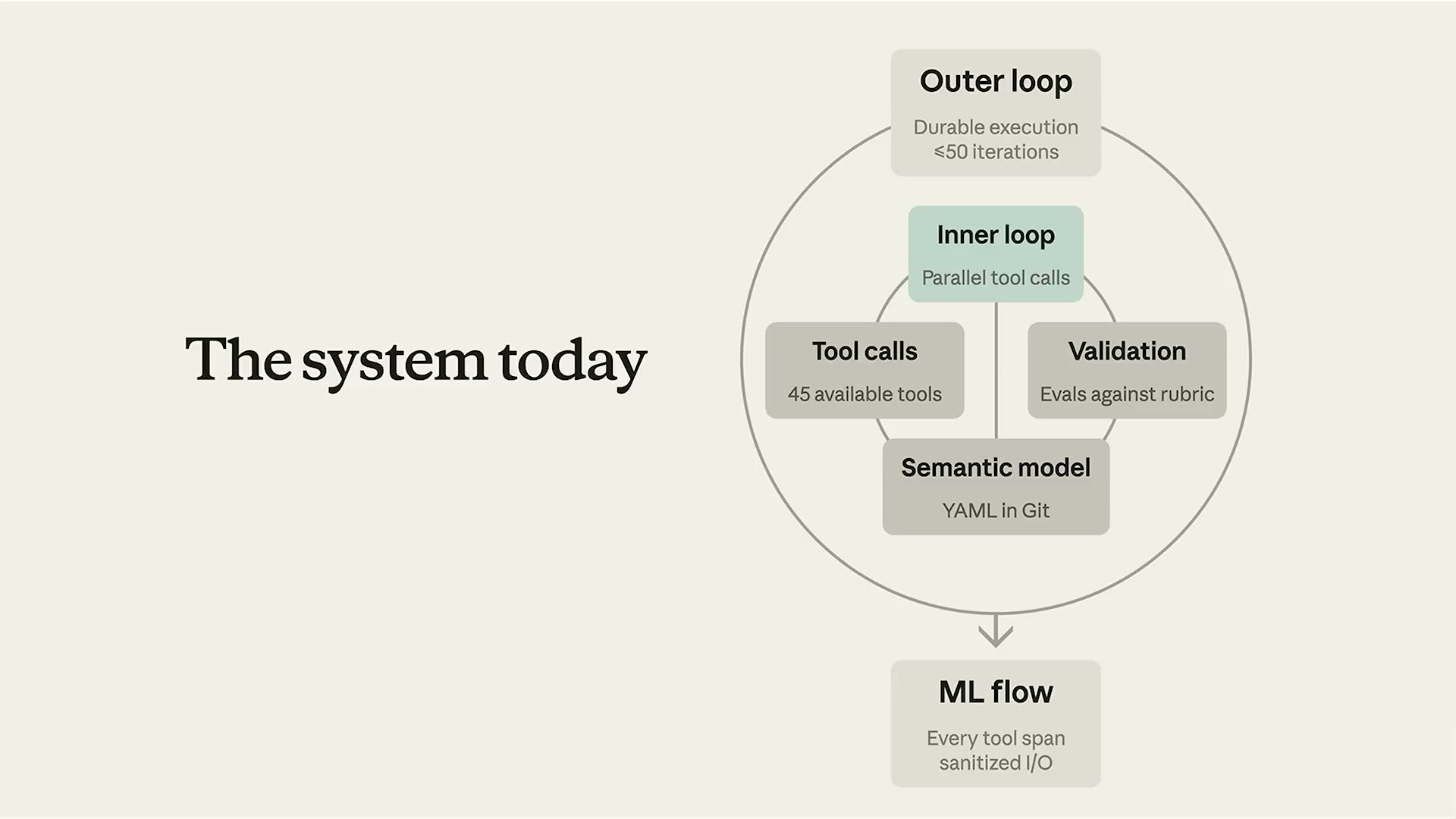
現在のシステムは2層ループ構造を持つ:
耐久実行 最大50イテレーション"] --> CP["チェックポイント
障害回復"] OL --> IL IL["インナーループ
並列ツール呼び出し"] --> TC["ツール群
45ツール利用可能"] IL --> V["バリデーション
評価ルーブリック"] IL --> SM["セマンティックモデル
YAML in Git"] TC --> DB["データウェアハウス"] SM --> DB DB --> IL IL --> R["レスポンス生成
可視化 + サマリー"] R --> OL OL --> ANS["最終回答"] style OL fill:#5b9bd5,color:#fff style IL fill:#70ad47,color:#fff style SM fill:#ffc000,color:#000
アウターループ:最大50イテレーションで耐久実行を保証する。チェックポイントを使って実行状態を保存し、障害時にはそこから再開できる。
インナーループ:並列ツール呼び出しをサポートする。45の利用可能なツールがあり、クエリ生成・ダッシュボード作成・可視化・バリデーション・データモデリングなどをカバーする。
セマンティックモデル:YAMLをGitで管理する。これによりデータチームが通常の開発フローでセマンティックモデルをメンテナンスできる。
MLフロー:全ツールスパンのI/Oをサニタイズして観測可能性を担保する。これが後述するEvalシステムの基盤になる。
エバリュエーション:「うまく動いている」をどう知るか
Omni CEOの「このシステムはいい。でもこの質問を間違えた。直してくれ」という要求がEvalシステム構築の動機になった。LLMの予測不能性を「仕方ない」と諦めることを拒否したCEOの執念が、プロダクトの品質を根本的に引き上げた。
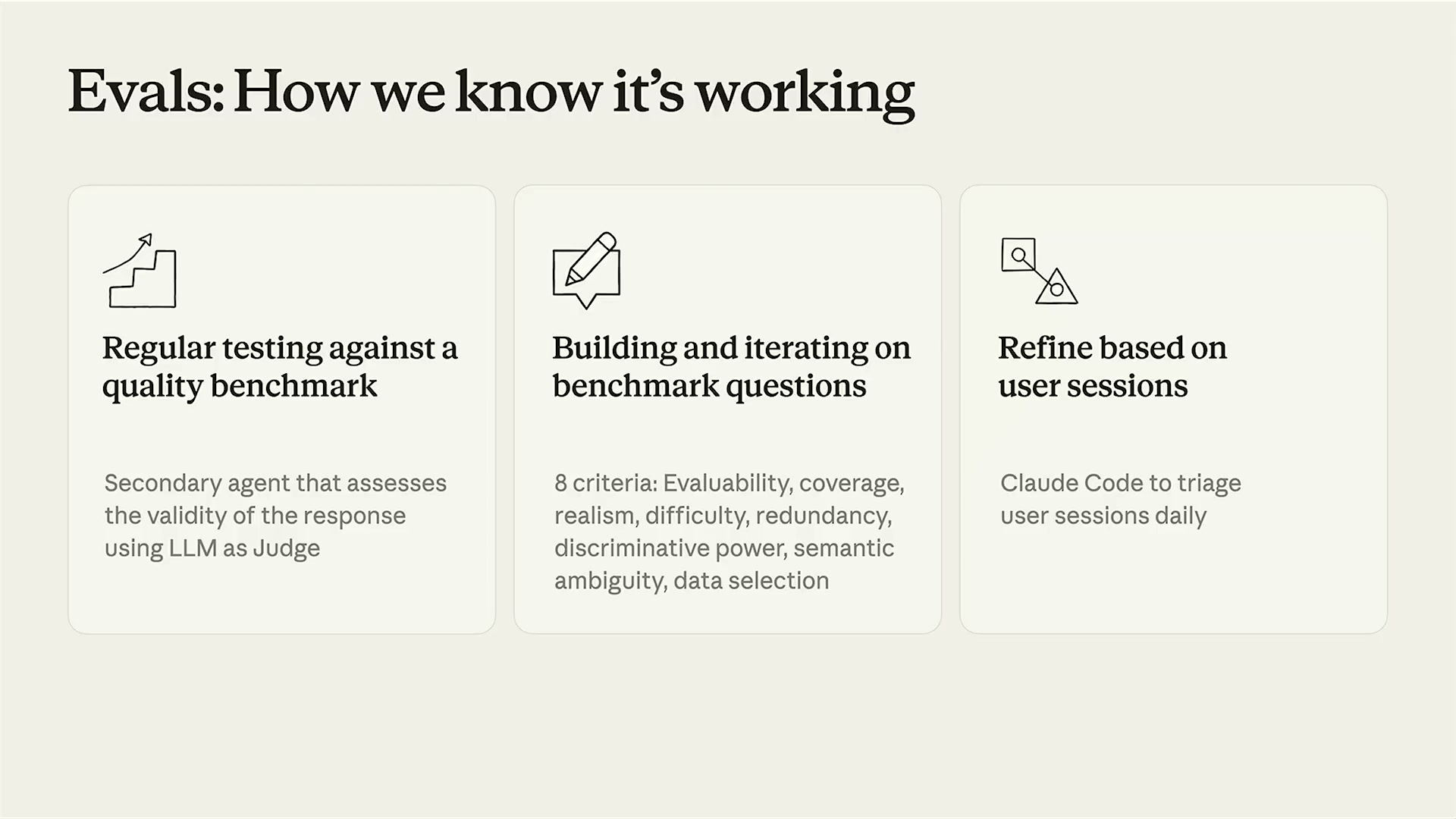
Omniのエバリュエーション体制は3つの柱で構成される:
1. クオリティベンチマークへの定期テスト セカンダリエージェントが「LLM as Judge」パターンでレスポンスの妥当性を評価する。応答が正しいか、ビジネスコンテキストに沿っているかを自動判定する。
2. ベンチマーク質問の構築と反復 良い評価質問には8つの基準がある:評価可能性・カバレッジ・リアリズム・難易度・冗長性のなさ・識別力・セマンティックの曖昧さ・データ選択。これらを満たす質問セットを継続的に充実させる。
3. ユーザーセッションを基にした改善 Claude Codeを使って実際のユーザーセッションを日次でトリアージする。失敗セッションのトレースを読んで根本原因を分析し、次のリリースに反映する。
Chris Merrickは「Evalが好きな理由は人と違う。Judgeに捕捉するのは効率化だが、私が本当に好きなのはObservabilityの部分だ。生のトレースデータを見て『これはなぜ失敗したのか』を自分で見ていける。ブルートフォース的なアプローチかもしれないが、これが一番直接的に問題の根本原因に到達できる」と語る。
Claude Codeを使うことで見えてくる「良いハーネス」の姿
このトークで最も示唆に富む部分は、「どうOmniのハーネスを設計したか」という技術的な話ではなく、「なぜエンジニアがユーザー視点でハーネスを設計できたか」という話だ。
エンジニア全員がClaude Codeを日常的に使っているため、彼らは「良いエージェントハーネスがどう見えるべきか」を身をもって理解している。「Blobbyのセマンティックモデルの探索方法を改善しよう」という議論になったとき、「Claude Codeはどうやってコードベースを探索しているか?セマンティックモデルとコードベースはそんなに違わない。同じアプローチを取り込もう」という発想が自然に出てくる。
この視点はハーネスエンジニアリング完全解説でも論じられている。実装者がユーザーでもある環境が、最良のハーネス設計につながる。
Blobbyの進化と設計判断の比較
| フェーズ | モデル | 主要変更 | 主な学び |
|---|---|---|---|
| Phase 0 | Haiku | 単一Q&A | セマンティック層の基本 |
| Phase 1 | Haiku | ai_context/sample_queries/all_values追加 | コンテキスト精度でクオリティが変わる |
| Phase 2 | Haiku→Sonnet | アジェンティックループ導入・タスク管理 | エラー回復機能が最大のクオリティ改善 |
| Blobotomy 1 | Sonnet | サブエージェント統合(スプリットブレイン解消) | エージェント間で知識を分割してはいけない |
| Blobotomy 2 | Sonnet | JSON形式→SQL生成 | Claude の既存知識を活かす形式を選ぶ |
| 現在 | Sonnet | 45ツール・外部Eval・Claude Codeトリアージ | 観測可能性がプロダクトの信頼の基盤 |
OmniのBlobbyが示す設計原則5つ
18ヶ月の進化から抽出できる設計原則をまとめる。
原則1:コンテキストはデータ定義の近くに置く グローバルなプロンプトよりも、フィールド定義のすぐ隣にai_contextを書く方が精度が上がる。CLAUDE.mdとセマンティック層は同じ原則で動いている。
原則2:エラーメッセージに投資する Claudeが自己修正できるのは、エラーメッセージが「何が起きているか」「どう修正するか」を明確に示している場合だけだ。高品質なエラーメッセージへの投資はEvalスコアに直接効いた。
原則3:サブエージェント間で知識を分割しない アウターエージェントが「何のデータがあるか」を知り、インナーエージェントが「1クエリで何が取れるか」を知るという分割は、スプリットブレインを生む。情報と実行能力は同じレイヤーに持たせる。
原則4:モデルが既に知っている形式に合わせる 独自のJSONクエリ形式よりも、ClaudeがトレーニングデータとしてすでにSQL構文を知っている形式を活かす。新しい形式を教えるコストは見えにくいが確実に存在する。
原則5:トレースの観測可能性が改善の鍵 問題が起きたときにトレースデータを読んで根本原因を特定できることが、「予測不能なLLM」という諦めを「直せる問題」に変える。Evalはスコアよりも観測可能性のために使う。
これらの原則は12-Factor Agents完全解説が提唱するプロダクション投入原則とも深く呼応している。実装の形式は異なるが、「エージェントが信頼できる動作をするための設計思想」という観点では同じ方向を向いている。
また、Hermes Agent v0.14.0のFoundation Releaseで見られるKanbanマルチエージェント設計との比較も興味深い。Omniが分析ドメインに特化した「深い垂直統合」を追求したのに対し、Hermesは「水平展開可能な汎用フレームワーク」を目指している。
まとめ:分析ドメインでClaude専用ハーネスを構築するとはどういうことか
OmniのBlobbyは、「汎用AIチャットボット」ではなく「ドメイン特化型アジェンティックシステム」としての設計が際立つ。
セマンティック層によるコンテキスト注入、タスク計画と実行を一体化したアジェンティックループ、SQL生成へのモデル知識活用、そしてトレース観測可能性を中核に置いたEvalシステム。これらは互いに補強し合って、「月次103Bトークンを処理する本番システム」の信頼性を支えている。
Merrick CTO自身が「Claude Codeユーザーとして日常的に良いハーネスの価値を体験しているからこそ、Blobbyに良いハーネスを設計できる」と語ったことが、このトークの最も重要なメッセージかもしれない。ツールを作る側がツールのユーザーであることの強さ、それがOmniの設計品質の根拠になっている。
参照ソース
- Code with Claude — Omni: Building the best agentic analytics harness(YouTube) — Chris Merrick(Omni CTO)による一次講演、2026年5月
- Omni公式サイト — Omniのプロダクト・デモページ