AIエージェントを本番運用したとき、最初に壁になるのはコンテキスト管理だ。記憶はコードの中に散在し、リソースはベクトルDBに、スキルはまた別の場所に——断片化した状態でエージェントを動かすと、トークンコストが跳ね上がり、検索精度は安定せず、問題が起きても検索の過程が見えない。
OpenVikingはこの三重苦に対して、ファイルシステムというシンプルなメタファーで回答するByteDance/Volcengineのオープンソースプロジェクトだ。2026年1月5日に公開されてから約4ヶ月でGitHubスター22,800超・フォーク1,663を記録し、AGPLv3ライセンスで公開されている。
OpenVikingが解こうとしている問題
AIエージェント開発で繰り返し直面する課題は、「コンテキストの断片化」「トークンコストの膨張」「検索のブラックボックス化」の3つに集約できる。
コンテキストの断片化とは、記憶・リソース・スキルという3種類のコンテキストが別々のシステムに分散している状態を指す。長時間タスクでは実行のたびに新しいコンテキストが生まれるが、単純な切り詰めや圧縮では情報の欠落が起きる。
トークンコストの膨張は、すべての関連情報を一度にプロンプトに詰め込む設計から生まれる。プロジェクト全体のドキュメントをRAGで取得して毎回渡すと、関係のある情報もない情報もまとめて送られ、コストが跳ね上がる。
検索のブラックボックス化は従来型RAGの根本的な問題だ。フラットなベクトル空間への類似度検索は、なぜその文書が選ばれたかを説明しにくい。デバッグが困難で、検索ロジックの改善も手探りになる。
OpenVikingはこれらを「ファイルシステムパラダイム」「3段階コンテキストロード」「ディレクトリ再帰検索」「可視化された検索トレジェクトリ」「自動セッション管理」という5つのアプローチで解決しようとしている。
ファイルシステムパラダイム——viking://プロトコルの仮想FS
OpenVikingの最も特徴的な設計は、すべてのコンテキストを仮想ファイルシステムとして扱う点だ。記憶・リソース・スキルをすべてviking://プロトコルのURIにマッピングし、lsやfindのような標準的なファイル操作コマンドでエージェントがコンテキストを操作できる。
viking://
├── resources/ # プロジェクトドキュメント、リポジトリ、Webページ等
│ ├── my_project/
│ │ ├── docs/
│ │ │ ├── api/
│ │ │ └── tutorials/
│ │ └── src/
│ └── ...
├── user/ # ユーザーの好み、習慣等
│ └── memories/
│ ├── preferences/
│ │ ├── writing_style
│ │ └── coding_habits
│ └── ...
└── agent/ # スキル、インストラクション、タスク記憶等
├── skills/
│ ├── search_code
│ ├── analyze_data
│ └── ...
├── memories/
└── instructions/
この設計が解決するのは断片化問題だ。記憶・リソース・スキルという異なる種類のコンテキストが、同一の仮想ファイルシステム上に統一されて存在する。エージェントは「ベクトルDBのAPIを呼ぶ」「メモリストアを検索する」という複数のインターフェースを覚える必要がなく、ファイルシステム操作という単一のパラダイムでコンテキスト全体にアクセスできる。
ファイルシステムは階層構造・名前空間・永続性という性質を持ち、人間が数十年かけて発達させてきた情報整理の手法だ。エージェントにとっても「ディレクトリをたどる」「ファイルを探す」という操作は直感的で、検索の意図が明確になる。フラットなベクトル空間への類似度検索と異なり、なぜその情報にたどり着いたかのトレジェクトリが残る。
実際のCLI操作例を見ると、このパラダイムの直感性がよくわかる。
# OpenVikingサーバーを起動
openviking-server
# ステータス確認
ov status
# GitHubリポジトリをリソースとして追加
ov add-resource https://github.com/volcengine/OpenViking
# ディレクトリ一覧
ov ls viking://resources/
# ツリー表示(深さ2まで)
ov tree viking://resources/volcengine -L 2
# セマンティック検索
ov find "what is openviking"
# パターン検索(特定ディレクトリ内)
ov grep "openviking" --uri viking://resources/volcengine/OpenViking/docs/zh
L0/L1/L2の3段階コンテキストロード——トークン削減の核心
OpenVikingがトークンコストを劇的に削減できる理由は、コンテキストを3段階の抽象レベルに分けて管理し、必要な情報だけを段階的にロードする設計にある。
コンテキストを追加するとき、OpenVikingはバックグラウンドで3つの表現を自動生成する。
| レイヤー | ファイル | トークン上限 | 用途 |
|---|---|---|---|
| L0(Abstract) | .abstract.md |
約100トークン | ベクトル検索・高速フィルタリング |
| L1(Overview) | .overview.md |
約2,000トークン | リランク・コンテンツナビゲーション |
| L2(Detail) | オリジナルファイル | 無制限 | オンデマンドの詳細読み込み |
viking://resources/my_project/
├── .abstract # L0: 「API認証ガイド、OAuth 2.0・JWT・APIキーを網羅」(〜100トークン)
├── .overview # L1: 章構成・キーポイント・L2へのナビゲーション(〜2kトークン)
├── docs/
│ ├── .abstract # 各ディレクトリにも対応するL0/L1が存在
│ ├── .overview
│ ├── api/
│ │ ├── .abstract
│ │ ├── .overview
│ │ ├── auth.md # L2: フルコンテンツ(オンデマンド)
│ │ └── endpoints.md
│ └── ...
└── src/
└── ...
エージェントが情報を探すとき、まずL0の100トークンのサマリーで関連性を判定し、有望なディレクトリのみL1の2,000トークンで詳細を確認し、最後に必要なファイルだけL2でフル取得する。
# Python APIでの段階的ロード例
client = OpenVikingClient()
# L0: 高速な関連性チェック(100トークン)
abstract = client.abstract("viking://resources/docs/auth")
print(abstract)
# → "API authentication guide covering OAuth 2.0, JWT tokens, and API keys"
# L1: 構造理解(2,000トークン)
overview = client.overview("viking://resources/docs/auth")
print(overview)
# → 章構成、キーポイント、L2へのアクセス方法を含む詳細サマリー
# L2: 必要なときだけフルコンテンツを取得
content = client.read("viking://resources/docs/auth/oauth.md")
従来のRAGがすべての関連チャンクを一度にプロンプトに詰め込んでいたのに対し、このアプローチはエージェントが「まず概要を把握し、必要な詳細だけを取得する」という人間の情報収集行動に近い。
後述するベンチマーク結果では、このL0/L1/L2設計が入力トークンコストの83〜96%削減という数字を生んでいる。
ディレクトリ再帰検索——従来RAGとの根本的な違い
(複数の検索条件を生成)"] B --> C["L0ベクトル検索
(高スコアディレクトリを特定)"] C --> D["L1セカンダリ検索
(ディレクトリ内で絞り込み)"] D --> E{"サブディレクトリ
存在?"} E -- "Yes" --> F["再帰的ドリルダウン
(同じ手順を繰り返す)"] F --> D E -- "No" --> G["候補セットに追加"] G --> H["結果集約・ランキング"] H --> I["最終コンテキスト返却"] style A fill:#2d3748,color:#e2e8f0 style I fill:#2d3748,color:#e2e8f0 style B fill:#1a3a5c,color:#e2e8f0 style C fill:#1a3a5c,color:#e2e8f0 style D fill:#1a3a5c,color:#e2e8f0 style F fill:#1a3a5c,color:#e2e8f0 style G fill:#1a3a5c,color:#e2e8f0 style H fill:#1a3a5c,color:#e2e8f0 style E fill:#2d5016,color:#e2e8f0
従来のRAGが「フラットなベクトル空間でTop-K検索」というシンプルな手法に依存しているのに対し、OpenVikingのディレクトリ再帰検索は5段階のプロセスで動作する。
- インテント分析: クエリから複数の検索条件を生成する
- 初期ポジショニング: ベクトル検索でスコアの高いディレクトリを特定する
- 精緻化探索: そのディレクトリ内でセカンダリ検索を行い、高スコア結果を候補セットに追加
- 再帰ドリルダウン: サブディレクトリが存在する場合は、同じ手順をレイヤーごとに繰り返す
- 結果集約: 最も関連性の高いコンテキストを集めて返す
この「まず高スコアディレクトリを絞り込み、その中で内容を精緻化探索する」という戦略は、意味的に最適なフラグメントを見つけるだけでなく、その情報が存在するコンテキスト全体(ディレクトリ構造)を理解することで、検索の全体性と精度を向上させる。
可視化された検索トレジェクトリ
従来のRAG最大の問題のひとつが、「なぜこの情報が取得されたのか」がわからないことだった。OpenVikingはすべてのコンテキストがviking://のURIを持つ階層的な仮想ファイルシステムで管理されるため、検索の過程——どのディレクトリを閲覧し、どのファイルを特定したか——が完全に記録される。
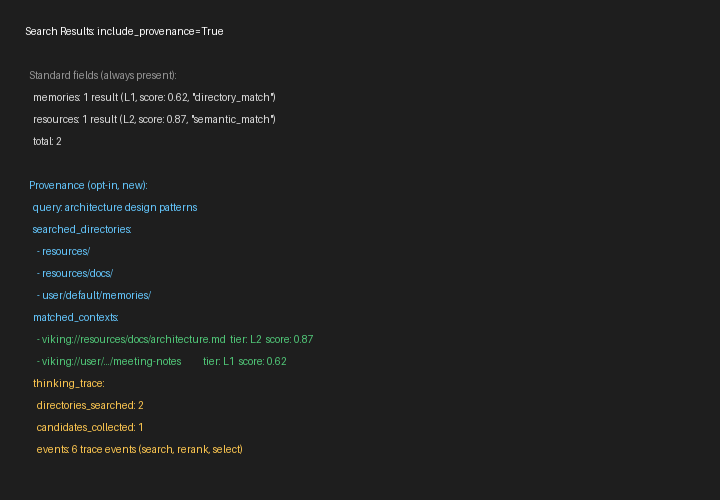
このトレジェクトリの可視性は、実際の開発で2つの効果をもたらす。1つは問題の根本原因特定が容易になること。2つ目は、どのディレクトリ構造が検索精度に影響しているかを分析して、コンテキスト整理のロジックを改善できることだ。
自動セッション管理——使うほど賢くなる仕組み
OpenVikingには、セッション終了後に自動的にメモリを抽出・更新する「自動セッション管理」機能が組み込まれている。これによりエージェントは使えば使うほど文脈を蓄積していく。
セッション終了時、システムは会話履歴を非同期で分析し、以下の2種類のメモリを自動更新する。
- ユーザーメモリ更新 (
viking://user/memories/): ユーザーの好みや習慣に関するメモリを更新し、エージェントの応答をユーザーのニーズに合わせる - エージェント経験蓄積 (
viking://agent/memories/): タスク実行経験から操作のコツやツール活用の知見を抽出し、後続タスクの効率的な意思決定を支援する
インストールと基本設定
インストール
# Pythonパッケージとして
pip install openviking --upgrade --force-reinstall
# macOS(pipx推奨)
brew install pipx
pipx ensurepath
pipx install openviking
# Rust CLI(オプション)
curl -fsSL https://raw.githubusercontent.com/volcengine/OpenViking/main/crates/ov_cli/install.sh | bash
設定ファイルの作成
~/.openviking/ov.confを作成する。最低限必要なのは埋め込みモデルとVLMモデルの設定だ。
Volcengine(Doubao)を使う場合:
{
"storage": {
"workspace": "/home/your-name/openviking_workspace"
},
"log": {
"level": "INFO",
"output": "stdout"
},
"embedding": {
"dense": {
"api_base": "https://ark.cn-beijing.volces.com/api/v3",
"api_key": "your-volcengine-api-key",
"provider": "volcengine",
"dimension": 1024,
"model": "doubao-embedding-vision-251215"
},
"max_concurrent": 10
},
"vlm": {
"api_base": "https://ark.cn-beijing.volces.com/api/v3",
"api_key": "your-volcengine-api-key",
"provider": "volcengine",
"model": "doubao-seed-2-0-pro-260215",
"max_concurrent": 100
}
}
OpenAIを使う場合:
{
"storage": {
"workspace": "/home/your-name/openviking_workspace"
},
"embedding": {
"dense": {
"api_base": "https://api.openai.com/v1",
"api_key": "your-openai-api-key",
"provider": "openai",
"dimension": 3072,
"model": "text-embedding-3-large"
},
"max_concurrent": 10
},
"vlm": {
"api_base": "https://api.openai.com/v1",
"api_key": "your-openai-api-key",
"provider": "openai",
"model": "gpt-4-vision-preview",
"max_concurrent": 100
}
}
ローカルモデル(Ollama)を使う場合: 対話形式のウィザードが自動でOllama検出・推奨モデルのプル・設定ファイル生成まで行う。
openviking-server init
# → 対話型ウィザードでOllamaを選択
openviking-server doctor
# → セットアップの検証
環境変数の設定
export OPENVIKING_CONFIG_FILE=~/.openviking/ov.conf
# CLIクライアント用設定
# ~/.openviking/ovcli.conf に以下を記述
# {"url": "http://localhost:1933", "timeout": 60.0, "output": "table"}
export OPENVIKING_CLI_CONFIG_FILE=~/.openviking/ovcli.conf
サーバー起動と初回動作確認
# 設定検証
openviking-server doctor
# サーバー起動
openviking-server
# バックグラウンド起動
nohup openviking-server > /data/log/openviking.log 2>&1 &
起動後、別ターミナルでCLIを使って動作確認する。
# ステータス確認
ov status
# GitHubリポジトリをリソース追加(--wait で処理完了まで待機)
ov add-resource https://github.com/volcengine/OpenViking --wait
# 一覧表示
ov ls viking://resources/
# ツリー表示(2階層まで)
ov tree viking://resources/volcengine -L 2
# セマンティック検索
ov find "what is openviking"
# パターン検索(特定ディレクトリ内)
ov grep "filesystem paradigm" --uri viking://resources/volcengine/OpenViking
Claude Code メモリプラグイン——セッションを超えた記憶
OpenVikingが特に力を入れているのがAIコーディングツールとの統合だ。examples/claude-code-memory-pluginには、Claude CodeのMCPサーバーとフックを組み合わせた本格的なメモリプラグインが含まれている。
プラグインのアーキテクチャは以下のようになっている。
┌──────────────────────────────────────────────────────────┐
│ Claude Code │
└────────┬─────────────────────────────┬───────────────────┘
│ │
UserPromptSubmit Stop
(コマンドフック) (コマンドフック)
│ │
┌──────▼──────────┐ ┌──────────▼─────────┐
│ auto-recall │ │ auto-capture │
│ │ │ │
│ 1. クエリ解析 │ │ 1. トランスクリプト │
│ 2. OV検索 │ │ 読み込み │
│ 3. ランキング │ │ 2. セッション抽出 │
│ 4. コンテンツ読込│ │ 3. メモリ保存 │
│ │ │ │
│ → systemMessage │ │ → 自動保存(完了) │
└──────┬──────────┘ └──────────┬─────────┘
└─────────────┬───────────────┘
┌─────▼──────┐
│ OpenViking │
│ Server │
└─────────────┘
┌──────────────────────────────────────┐
│ MCP Server(明示的操作用) │
│ • memory_recall(手動検索) │
│ • memory_store(手動保存) │
│ • memory_forget(削除) │
│ • memory_health(ヘルスチェック) │
└──────────────────────────────────────┘
自動リコール(UserPromptSubmit): ユーザーがメッセージを送るたびに、auto-recall.mjsがOpenVikingの/api/v1/search/findを呼び出し、viking://user/memoriesとviking://agent/memoriesを検索する。クエリアウェアなスコアリング(リーフブースト・好みブースト・時間ブースト・語彙オーバーラップ)でランキングし、上位の記憶を<relevant-memories>としてsystemMessageに注入する。Claude Codeはこのコンテキストを透過的に受け取る。
自動キャプチャ(Stop): Claude Codeがレスポンスを完了するたびに、auto-capture.mjsがトランスクリプトを解析し、最近のユーザーターンを抽出してOpenVikingのテンポラリセッションに追加、メモリとして抽出・保存する。Claude Codeのツール呼び出しは一切不要で完全に透過的に動作する。
インストール手順は以下の通り。
# 1. OpenVikingをインストール
pip install openviking
# 2. OpenVikingサーバーを起動
openviking-server
# 3. Claude Codeプラグインをインストール
# (openviking-pluginsマーケットプレイス経由が推奨)
# https://github.com/Castor6/openviking-plugins
このプラグインにより、Claude Codeは「セッションをまたいだ記憶」を持つ。プロジェクトの技術的な決定事項、コーディング上の好み、過去のデバッグ経験などがOpenViking上に蓄積され、次のセッションで自動的に参照される。
OpenCode・その他エージェントへの統合
OpenVikingは複数のAIコーディングツールへのプラグイン例を提供している。
# VikingBot(OpenViking上に構築されたエージェントフレームワーク)
pip install "openviking[bot]"
# Botを有効にしてサーバー起動
openviking-server --with-bot
# 別ターミナルでインタラクティブチャット
ov chat
公式リポジトリには以下のプラグイン例が含まれている。
| 統合先 | パス | 概要 |
|---|---|---|
| OpenClaw | examples/openclaw-plugin/ |
コンテキストエンジンプラグイン |
| OpenCode | examples/opencode-memory-plugin/ |
メモリツールとセッション同期 |
| Claude Code | examples/claude-code-memory-plugin/ |
MCP+フックによる透過的統合 |
| Codex | examples/codex-memory-plugin/ |
Codex向け統合例 |
ベンチマーク:OpenClawとの比較で見る実力
OpenVikingのパフォーマンスは、LoCoMo10データセット(長期対話1,540ケース)を使ったOpenClawとの比較ベンチマークで測定されている。使用モデルはseed-2.0-code、OpenVikingバージョンは0.1.18。
| 実験グループ | タスク完了率 | 入力トークン数(合計) |
|---|---|---|
| OpenClaw(memory-core有効) | 35.65% | 24,611,530 |
| OpenClaw + LanceDB(memory-core無効) | 44.55% | 51,574,530 |
| OpenClaw + OpenViking(memory-core無効) | 52.08% | 4,264,396 |
| OpenClaw + OpenViking(memory-core有効) | 51.23% | 2,099,622 |
memory-core無効の場合:
- 元のOpenClawより49%のタスク完了率改善、入力トークンコスト83%削減
- LanceDBより17%の改善、トークンコスト92%削減
memory-core有効の場合:
- 元のOpenClawより43%の改善、トークンコスト91%削減
- LanceDBより15%の改善、トークンコスト96%削減
タスク完了率が上がりながらトークンコストが大幅に下がるという結果は、L0/L1/L2の段階的ロードとディレクトリ再帰検索の組み合わせが単なるコスト削減にとどまらず、検索精度向上にも寄与していることを示している。
他のコンテキスト管理ツールとの比較
アプローチ"] --> B["フラットRAG
(LanceDB等)"] A --> C["ナレッジグラフ型
(cognee等)"] A --> D["ファイルシステム型
(OpenViking)"] B --> B1["○ シンプル
コスト高
グローバル把握困難"] C --> C1["○ 関係性保持
セットアップ複雑
リアルタイム更新が重い"] D --> D1["○ 構造的整理
○ 段階的ロードでコスト削減
○ 検索トレジェクトリ可視化"]
| 比較軸 | 従来型RAG(フラット) | cognee(ナレッジグラフ) | OpenViking(ファイルシステム) |
|---|---|---|---|
| コンテキスト構造 | フラット | グラフ | 階層ディレクトリ |
| トークン効率 | 低(全チャンクを一括投入) | 中 | 高(L0/L1/L2段階ロード) |
| 検索可視性 | 低(ブラックボックス) | 中 | 高(トレジェクトリ記録) |
| セットアップ複雑度 | 低 | 高 | 中 |
| 記憶の自動進化 | なし | 手動 | 自動(セッション終了時) |
| Claude Code統合 | プラグイン次第 | MCP経由 | 公式プラグイン提供 |
| ライセンス | ツール依存 | Apache 2.0 | AGPL-3.0 |
cogneeのナレッジグラフ型AI記憶管理と比較すると、OpenVikingはグラフの関係性抽出よりも「ファイルシステムという直感的な階層構造」と「段階的なコンテキストロード」を優先している。どちらのアプローチが適切かは用途による——複雑な関係性の把握が重要なユースケースにはcogneeが向き、コスト効率と検索の透明性を重視するならOpenVikingが選択肢になる。
より幅広いRAGの基礎を理解したい場合はRAGとは?仕組み・構築・ベクトルDB選定までを、他のエージェントフレームワークと比較したい場合はAIエージェントフレームワーク比較2026が参考になる。
対応プロバイダーとエコシステム
Volcengine(Doubao)、OpenAI、OpenAI Codex(OAuth)、Kimi(サブスクリプション)、GLM(Z.AI Coding Plan)
埋め込みモデルのサポートはさらに広く、Volcengine・OpenAI・Jina・Voyage・MiniMax・VikingDB・Gemini(pip install "google-genai>=1.0.0"が必要)に対応している。
Gemini埋め込みを使う設定例:
pip install "google-genai>=1.0.0"
{
"storage": {
"workspace": "/home/your-name/openviking_workspace"
},
"embedding": {
"dense": {
"provider": "gemini",
"api_key": "your-google-api-key",
"model": "gemini-embedding-2-preview",
"dimension": 3072
},
"max_concurrent": 10
},
"vlm": {
"api_base": "https://api.openai.com/v1",
"api_key": "your-openai-api-key",
"provider": "openai",
"model": "gpt-4o",
"max_concurrent": 100
}
}
Dockerとクラウドデプロイ
本番環境向けには、Docker Composeを使ったデプロイが推奨されている。
# リポジトリをクローン
git clone https://github.com/volcengine/OpenViking.git
cd OpenViking
# Dockerイメージでサーバー起動(VikingBot同梱)
docker-compose up -d
VikingBotはDockerイメージにデフォルトで含まれており、サーバー起動時に自動的に有効化される。無効にする場合は--without-botフラグまたは環境変数-e OPENVIKING_WITH_BOT=0を使う。
VolcengineのECS(Elastic Compute Service)とveLinuxを使ったクラウドデプロイの詳細手順はリポジトリ内のdocs/en/getting-started/03-quickstart-server.mdに記載されている。
Kubernetesデプロイにはexamples/k8s-helm/にHelmチャートが用意されている。またexamples/grafana/にはGrafanaダッシュボード設定が含まれており、コンテキストの使用状況やAPIのレイテンシをモニタリングできる。
OpenClawとの関係——なぜ「OpenViking」という名前なのか
OpenVikingはVolcengineの内部プロジェクト「Viking」に由来する。Volcengine(Volcano Engine)はByteDanceのクラウドサービス部門で、TikTokやDouyinなどのプロダクトを支える技術基盤を提供している。
OpenVikingは特にOpenClawとの連携を前提に設計されている。OpenClawはGitHub 35万stars超を誇る自律型AIアシスタントOSSで、OpenVikingはそのコンテキスト管理の弱点を補完するプラグインとして機能する。ベンチマーク結果でOpenClaw単体と比較されているのもそのためだ。
2026年1月5日のオープンソース公開から約4ヶ月でスター22,000超を獲得したスピードは、AIエージェントのコンテキスト管理という問題がいかに多くの開発者が直面しているかを示している。
まとめ:OpenVikingが開くコンテキストエンジニアリングの新地平
OpenVikingが提示するのは「コンテキストもファイルのように扱う」という、シンプルだが強力なパラダイムシフトだ。
従来のRAGがベクトルDBへのフラットな格納と類似度検索に依存していたのに対し、OpenVikingは仮想ファイルシステムによる構造的整理、L0/L1/L2の段階的ロード、ディレクトリ再帰検索、トレジェクトリの可視化という4つの仕組みを組み合わせて、コスト削減と検索精度向上を同時に実現している。
ベンチマークでの最大96%のトークンコスト削減と49%のタスク完了率向上という数字は、このアプローチの有効性を具体的に示している。
AGPL-3.0ライセンスであるため商用利用には注意が必要だが、個人開発・研究・OSS プロジェクトでの利用には適している。Claude Code・OpenCode・OpenClaw向けのプラグイン例が公式提供されており、既存のAIコーディングワークフローへの統合から始めるのが最もハードルが低い。
コンテキスト管理の問題に悩んでいるエージェント開発者にとって、OpenVikingはまず試してみる価値のあるアプローチだ。