この記事ではAIエージェントに特化して解説します。AIエージェント全般は AIエージェントフレームワーク比較2026年版 をご覧ください。
スキルが増えすぎて管理できない——組織の共通課題
AIエージェントの導入が進むにつれ、プロンプト・ワークフロー定義・ツール設定・SKILL.mdといった「スキル資産」が組織内に急速に蓄積している。どのチームがどんなスキルを持っているか把握できない、同じスキルを別のチームが重複開発している、安全性が検証されていないスキルが本番で使われている——こうした運用課題に正面から取り組むOSSが Agent Skill Harbor だ。
Agent Skill Harborは、AIエージェントのスキルをリポジトリ横断で収集・共有・監査・公開できるオープンソースのプラットフォームである。最大の特徴は サーバーレス・DB不要・Gitネイティブ な設計で、スキルデータをYAML/JSONとしてGitに保存する点だ。既存のGitインフラをそのまま活かせるため、導入障壁が極めて低い。
OpenHandsのようなAIコーディングエージェントやBrowser Useのようなブラウザ自動化エージェントが急速に普及するなか、これらのエージェントが使うスキルを組織的に管理する基盤の需要は確実に高まっている。Harborはそのニーズに「既存のGit + 静的サイト」という最小構成で応える。
動画やブログではなく、公式リポジトリのREADMEと実装をもとに、本記事ではHarborのアーキテクチャ・セットアップ・プラグイン拡張・従来手法との比較までを体系的に解説する。
組織内のAIスキルが散在・重複・未監査のまま運用されるのは典型的な失敗パターン
Agent Skill HarborはサーバーレスかつDB不要なGitネイティブ設計のOSS基盤
既存Git + 静的サイトという最小構成で企業レベルのスキル管理を実現できる
Agent Skill Harborの5つのコア機能
Agent Skill Harborが提供する主要機能は大きく5つに整理できる。単なる「スキルリスト表示」ではなく、 ガバナンス・由来追跡・自動監査・通知までを一気通貫で扱う 点が差別化要素だ。
| 機能 | 説明 | 対応プラグイン |
|---|---|---|
| スキルカタログ化 | リポジトリ全体でAIエージェントスキルを収集・公開 | - |
| ガバナンス | スキルを推奨/非推奨/禁止として分類・管理 | governance.yaml |
| 由来追跡(Provenance) | コピー・インストールされたスキルを起源まで追跡 | - |
| スキル分析・安全性監査 | スキルを自動収集・監査し安全性をチェック | builtin.audit-skill-scanner |
| Slack通知 | 収集完了後の通知を自動送信 | builtin.notify-slack |
特にガバナンス機能は、組織でAIエージェントを安全に運用するうえで中核となる。config/governance.yaml でスキルを「推奨(recommended)」「非推奨(discouraged)」「禁止(prohibited)」に分類でき、チーム全体の品質基準を維持できる。
「スキルは自由に作れるべきだが、本番で動くスキルは統制が必要」——この矛盾に既存ツールは応えられなかった。Harborは Gitの自由さと組織のガバナンスを両立させる 現実解を提示している。
由来追跡(Provenance)は地味だが強力だ。誰かが別リポジトリのスキルをコピーして使ったときに、その「起源」を自動で追跡できるため、セキュリティインシデント時の影響範囲調査が容易になる。Harborは単なる可視化ツールではなく、「組織のAIスキル台帳」として機能する。
Harborは5つのコア機能(カタログ化・ガバナンス・由来追跡・安全性監査・Slack通知)を一体提供
ガバナンスファイルで「推奨/非推奨/禁止」の3段階分類を適用できる
Provenance追跡で、インシデント時の影響範囲特定が自動化できる
クイックスタート:npxで5分セットアップ
Agent Skill Harborのセットアップは npx コマンド1つで始められる。READMEに沿って最小構成を立ち上げる手順は以下のとおりだ。
npx agent-skill-harbor init my-skill-harbor
cd my-skill-harbor
pnpm install
pnpm install --dir collector
# .envにGH_ORGを設定してからスキル収集を実行
gh auth login && GH_TOKEN=$(gh auth token) pnpm collect
pnpm dev
pnpm install でWebカタログUI用のパッケージ、pnpm install --dir collector でスキル収集ランタイムが入る。pnpm collect を実行すると、.env に指定した組織のリポジトリからスキルが自動収集され、data/ ディレクトリにYAML/JSONとして保存される仕組みだ。
npx の段階で必要なのはNode.jsとpnpm、そしてGitHubのPersonal Access Tokenだけ。DockerもDBもKubernetesもいらない。
CLIは harbor コマンドとしても利用可能で、プロジェクト作成やプラグインの追加はこちらで行う。
# 新規プロジェクトの作成
harbor init my-catalog
# プラグインのセットアップ
harbor setup builtin.audit-skill-scanner
harbor setup builtin.audit-promptfoo-security
harbor setup example-user-defined-plugin
日常的な運用は、ルートの package.json に登録されたnpmスクリプトを叩くだけで完結する。
| コマンド | 用途 |
|---|---|
pnpm collect |
組織のリポジトリからスキルを収集 |
pnpm post-collect |
プラグインによる後処理(監査・通知等) |
pnpm dev |
ローカル開発サーバー起動 |
pnpm build |
静的サイトをビルド |
pnpm preview |
ビルド済みサイトをプレビュー |
GH_ORG には対象とするGitHub組織名(例: your-company)を指定する。トークンはローカルでは
gh auth token、CIでは secrets.GITHUB_TOKEN やPATを使うのが安全。個人利用なら
GH_USER を指定して自分のリポジトリ群だけを収集できる。
セットアップは
npx agent-skill-harbor init の1コマンドから始まる`pnpm collect` で組織リポジトリからスキルを自動収集し、`data/` に保存する
運用はpackage.jsonのnpmスクリプトに集約され、学習コストが低い
アーキテクチャ:DB不要のGitネイティブ設計
Agent Skill Harborが他のスキル管理ツールと一線を画すのは、 データベースを一切使わず、すべてGitで完結する点 だ。スキルデータはすべてYAML/JSONとしてGitに保存され、カタログUIは静的Webアプリとしてプリレンダリングされる。
スキル収集エンジン"] B --> C["data/skills.yaml
スキルインデックス"] B --> D["data/skills/
キャッシュ済みスキルファイル"] B --> E["data/collects.yaml
収集履歴"] E --> F["Post-Collect Plugins"] F --> G["builtin.audit-skill-scanner
安全性監査"] F --> H["builtin.notify-slack
Slack通知"] F --> I["builtin.detect-drift
ドリフト検出"] C --> J["静的Web UI
カード/リスト/統計/グラフ表示"] D --> J J -->|"GitHub Pages
Cloudflare Pages"| K["チームに公開"]
プロジェクトのディレクトリ構造は明確に役割分離されている。
my-skill-harbor/
├── .github/workflows/ # GitHub Actionsワークフロー
├── config/
│ ├── harbor.yaml # アプリケーション設定
│ └── governance.yaml # ガバナンス設定
├── collector/ # スキル収集バッチ処理
│ ├── package.json
│ └── plugins/ # プラグインごとのマニフェストとコード
├── data/
│ ├── collects.yaml # 収集履歴
│ ├── skills.yaml # 収集されたスキルのインデックス
│ └── skills/ # キャッシュされたスキルファイル
├── .env # 環境変数(GH_TOKEN等)
└── package.json # Web UIのマニフェスト
この設計により、GitHub Actionsでスキル収集→データをGitにコミットバック→GitHub PagesまたはCloudflare Pagesで公開、という 完全にサーバーレスなパイプライン が実現する。MCPサーバーの扱い方についてはMCPサーバーの構築ガイドでも整理しているとおり、Gitベースのインフラはバージョン管理と監査ログを自動的に提供するため、エンタープライズ環境での信頼性が高い。
組織導入の基本ステップ
実際に組織で運用する場合の導入手順はシンプルだ。
npx agent-skill-harbor initで新規プロジェクトを作成- 組織のプライベートリポジトリにプッシュ
GH_TOKENをGitHub Actionsシークレットとして設定- GitHub PagesまたはCloudflare Pagesを有効化
- 生成された
CollectSkillsワークフローを実行
生成される CollectSkills ワークフローは、Harborの再利用可能なワークフロー(wf-v0)を呼び出す薄いcallerとして作られており、内部では以下のステップが実行される。
- collectステップ:
collector/のコア依存関係のみをインストールし、スキル収集を実行 - post_collectステップ: 収集成果物を復元し、有効化されたオプショナルプラグインのマニフェストのみをインストール
- 最終ステップ:
data/ディレクトリをリポジトリにコミットバック
GitHub Actionsの収集処理とオプショナルなpost-collect依存関係が構造的に分離されているため、CIの安定性が高く、プラグインを追加してもコアの収集処理を壊さずに済む。
全データがYAML/JSONでGitに保存され、UIは静的サイトとしてプリレンダリングされる
GitHub Actions + GitHub Pages/Cloudflare Pagesで完全サーバーレスのパイプラインが成立
collectとpost_collectが構造的に分離され、CIの安定性とプラグイン拡張性を両立
Post-Collectプラグインでスキル監査を自動化
Agent Skill Harborの強力な拡張ポイントが、 Post-Collectプラグインシステム だ。スキル収集後に自動実行される処理を config/harbor.yaml で有効化するだけで、監査・通知・ドリフト検出が自動化される。
| プラグイン | 機能 |
|---|---|
builtin.detect-drift |
スキルの変更(ドリフト)を検出 |
builtin.notify-slack |
Slack経由で収集結果を通知 |
builtin.audit-promptfoo-security |
promptfooによるセキュリティ監査 |
builtin.audit-skill-scanner |
スキルの安全性スキャン |
プラグインのランタイムファイルは harbor setup コマンドでスキャフォールドできる。
# 安全性スキャナーをセットアップ
harbor setup builtin.audit-skill-scanner
# promptfooセキュリティ監査をセットアップ
harbor setup builtin.audit-promptfoo-security
# カスタムプラグインの作成
harbor setup example-user-defined-plugin
生成されたファイルは collector/plugins/<plugin-id>/ 以下に配置される。カスタムプラグインを独自に作成することも可能で、組織固有の監査ルールやレポート生成を自動化できる。たとえば「社外秘キーワードを含むスキルを警告する」「特定のツール呼び出しを含むスキルをSlackに通知する」といった独自ロジックを組み込める。
プラグインはHarborの「拡張口」であり、 コア側に手を入れずに組織固有の運用ルールを追加できる。OSSをforkせずに運用に差分を載せられるのは、長期メンテナンス観点で極めて重要だ。
ForgeCodeのようなAIコーディングツールが生成するスキルが増えるなか、コミットされた全スキルを自動でスキャンし、安全性を継続的に監査する仕組みは運用上ほぼ必須と言える。人力レビューでは到底スケールしない領域を、Harborのプラグインが吸収する形だ。
4つの標準プラグイン(ドリフト検出・Slack通知・promptfoo・安全性スキャナー)を即利用可能
`harbor setup` コマンドでプラグインをスキャフォールドし、collector/plugins配下で管理
カスタムプラグインで組織固有の監査ルールを追加、OSSコアをforkせず運用差分を吸収できる
カタログUIの4つのビューとスキル可視化
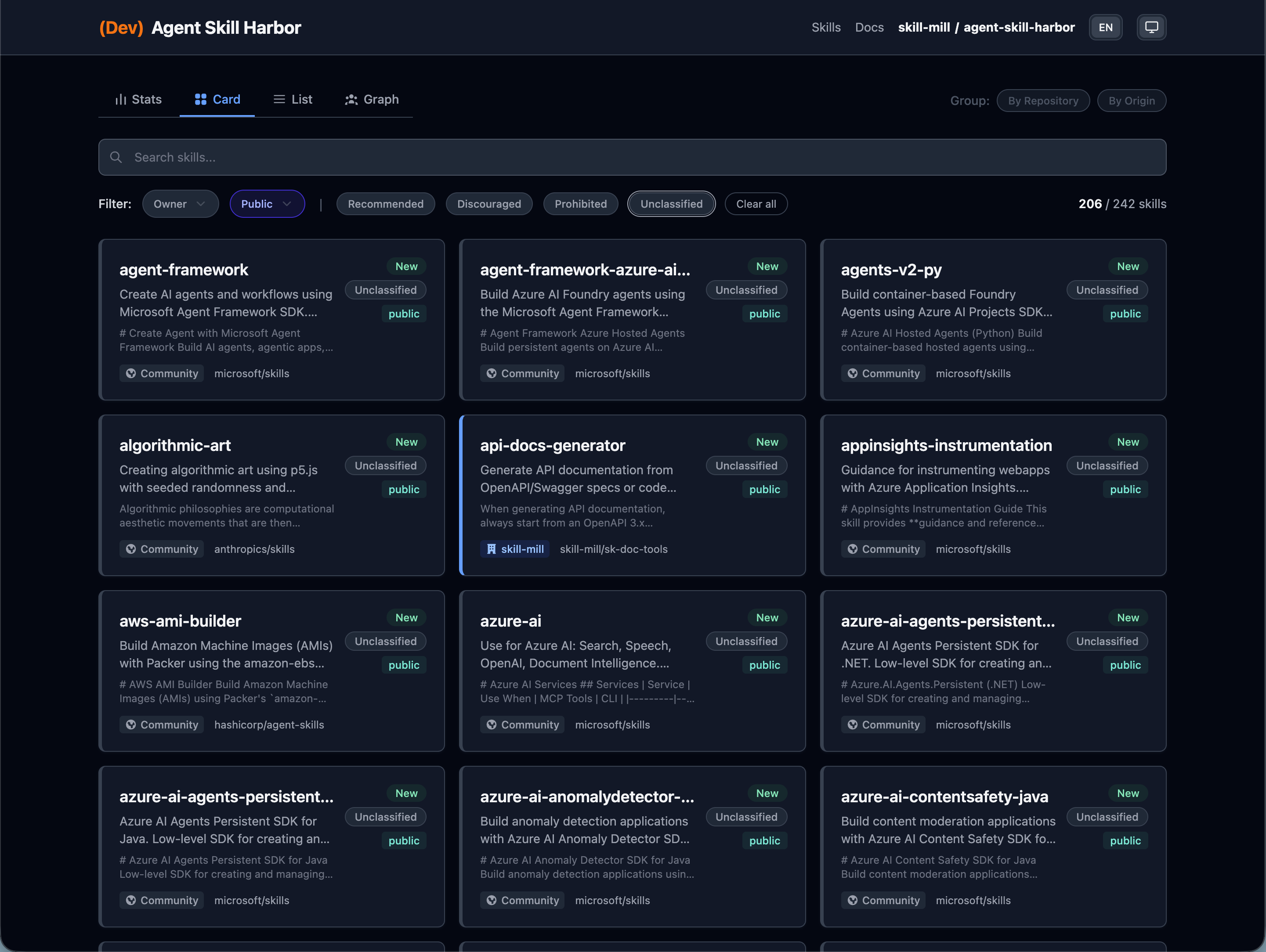
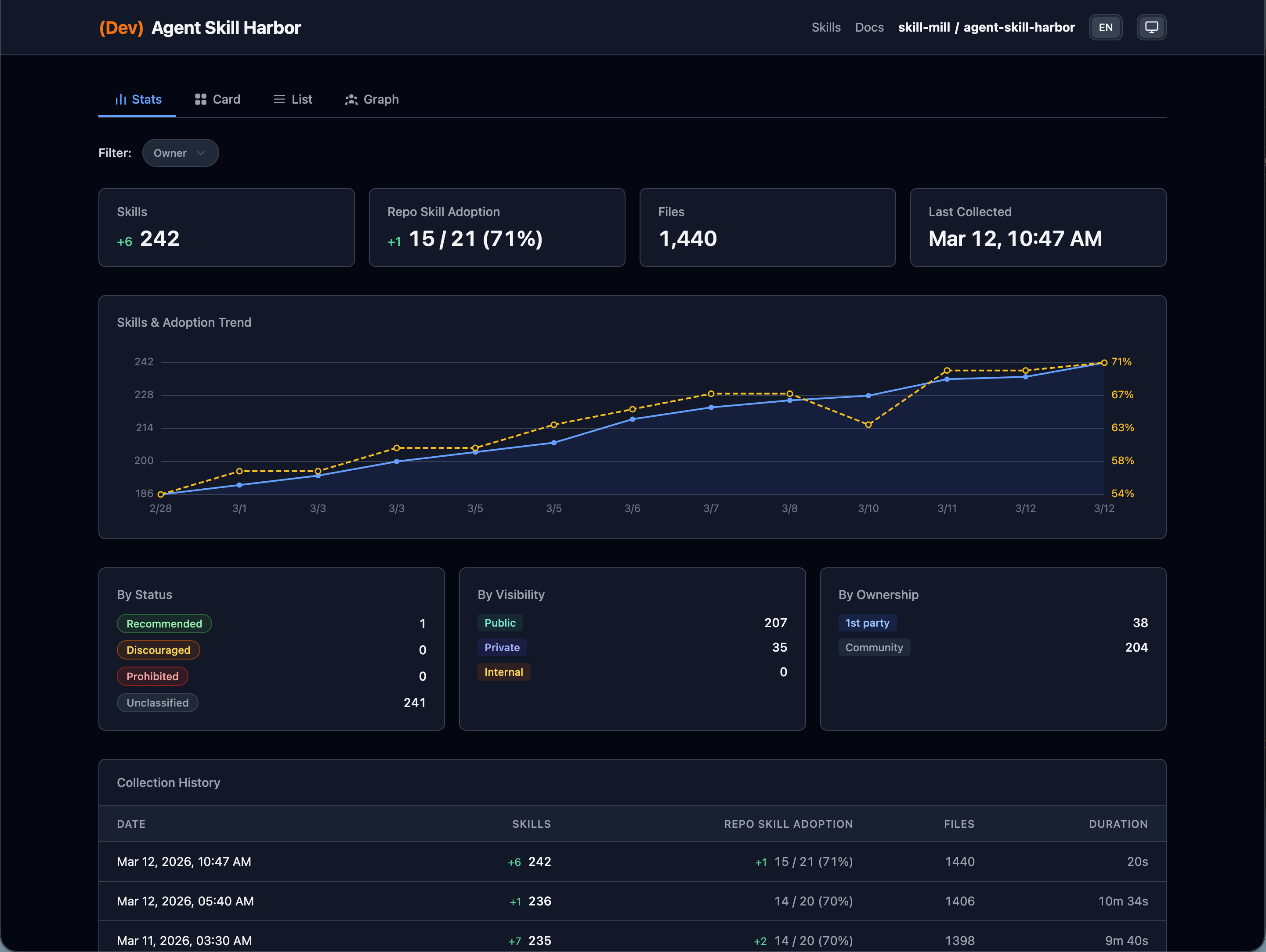
Agent Skill Harborのカタログ UIは、スキル情報を4つのビューで可視化する。単純なリストではなく、 規模・関係性・品質分布を同時に把握できる ことが大規模運用での差になる。
| ビュー | 用途 | 特徴 |
|---|---|---|
| カード表示 | 個別スキルの概要把握 | スキル名・説明・タグをカード形式で表示 |
| リスト表示 | 大量スキルの一覧管理 | ソート・フィルタリング対応 |
| 統計表示 | スキル分布の分析 | リポジトリ別・カテゴリ別の集計 |
| グラフ表示 | スキル間の関係性把握 | 由来追跡の依存関係を可視化 |
静的Webアプリとしてプリレンダリングされるため、サーバーサイドの実行環境が不要でホスティングコストを抑えられる。LangChainでRAGパイプラインを構築している組織なら、LLMが参照するスキルの品質管理や、社内ドキュメントの由来追跡にHarborを組み合わせる使い方が考えられる。
設定は config/harbor.yaml で集約管理される。最小限の例は以下のような構成だ。
# config/harbor.yaml
name: my-skill-harbor
description: "社内AIエージェントのスキルカタログ"
collect:
sources:
- org: your-company
include:
- "**/.claude/skills/**"
- "**/SKILL.md"
post_collect:
plugins:
- builtin.audit-skill-scanner
- builtin.notify-slack
- builtin.detect-drift
スキル収集対象のパスパターンや、監査・通知プラグインの有効化をすべてこのYAML1枚で制御できる。設定の差分はGitに残るため、「いつ誰がガバナンスを変更したか」を完全に追跡可能だ。
4ビュー(カード/リスト/統計/グラフ)でスキルの規模・分布・関係性を同時に把握
静的Webアプリ出力なのでホスティングコストが極小
`config/harbor.yaml` が運用の単一ソースになり、変更履歴はGitで完全追跡可能
従来のスキル管理手法との比較
Agent Skill Harborの位置づけを明確にするため、よくある従来型のスキル管理手法と比較する。
| 比較項目 | Agent Skill Harbor | スプレッドシート管理 | 社内Wiki | 専用SaaS |
|---|---|---|---|---|
| データベース | 不要(Git) | 不要 | 必要 | 必要 |
| バージョン管理 | Git自動追跡 | 手動 | 履歴機能依存 | 製品依存 |
| 由来追跡 | 自動(Provenance) | なし | なし | 製品依存 |
| ガバナンス | 推奨/非推奨/禁止 | なし | 手動タグ付け | 製品依存 |
| 安全性監査 | プラグインで自動化 | なし | なし | 製品依存 |
| セットアップ | npx 1コマンド | 即時 | 環境構築必要 | 契約・設定 |
| コスト | 無料(OSS) | 無料 | サービス依存 | 月額課金 |
| CI/CD連携 | GitHub Actions標準 | なし | 手動 | API依存 |
スプレッドシートや社内Wikiでの管理は初期コストこそ低いが、スキルが数十〜数百件になった瞬間にスケールしない。とくに 「誰がいつ、どのスキルを、どの基準で承認したか」 を追跡できない点は、監査対応で致命的になる。
Harborが選ばれる典型シナリオ
- 複数リポジトリ・複数チームで
.claude/skills/が散らばっている - スキルの安全性レビューを手動で回していて追いつかない
- どのスキルが誰のコピーから派生したかを追跡したい
- SaaSを入れるほどの予算や審査プロセスは通したくない
こうした状況にぴたりとはまるのがHarborだ。Gitという既存インフラの上にガバナンスと自動監査を乗せることで、運用コストを最小限に抑えながら企業レベルのスキル管理を実現できる。
「Excelで管理台帳を作り続けるか、SaaSに月額を払うか」の二択しかなかった領域に、 OSS・Gitネイティブという第三の選択肢 を持ち込んだのがAgent Skill Harborの最大の価値だ。
スプレッドシート・Wiki・SaaSはそれぞれスケール性・追跡性・コストに課題がある
HarborはGitの上にガバナンスと監査を載せ、OSSで無料という第三の選択肢を提供
典型ユースケースは「複数リポジトリ × 複数チーム × 手動レビューが限界」の組織
実践ユースケース:Harborで何ができるか
最後に、Agent Skill Harborが実際にどのような現場課題を解くのかを3パターンに整理する。
ユースケース1:AIコーディング基盤の内製ガバナンス
社内で Claude Code や他のAIエージェントの導入を進める企業では、部署ごとに独自の .claude/skills/ ができあがり、互換性のないスキルが乱立する問題が起きやすい。Harborを導入すれば、全社のSKILL.mdを自動収集し、governance.yaml で「推奨」「禁止」の線を引けるようになる。
ユースケース2:OSSコミュニティ向けスキルカタログ
OSSプロジェクトがAIエージェント向けスキルを公開するとき、Harborを公開カタログとして使えば、コントリビューターはPRを送るだけで自動的にスキルが監査され、カタログに載る。GitHub Pagesで公開される静的サイトはそのままドキュメント代わりになる。
ユースケース3:個人の横断スキル管理
個人開発者でも、自分の複数リポジトリにまたがる .claude/skills/ や SKILL.md をHarborで収集し、自分専用のカタログをホスティングする使い方ができる。ForgeCodeやLangChain関連のスキルを自作している場合、「どこに何を作ったか」を1箇所で俯瞰できる価値は大きい。
# 個人利用向けのシンプルなharbor.yaml例
name: my-personal-skills
collect:
sources:
- user: your-github-username
include:
- "**/.claude/skills/**"
post_collect:
plugins:
- builtin.detect-drift
導入前チェックリスト
- 対象とするGitHub組織・ユーザーを決める
- 収集対象のパスパターン(
.claude/skills/かSKILL.mdか)を整理する - 最初は
detect-driftとnotify-slackだけ有効化し、小さく始める - 運用が安定してから
audit-skill-scannerやカスタムプラグインを追加する
Harborは「企業内製ガバナンス」「OSSコミュニティカタログ」「個人横断管理」の3層でフィットする
`config/harbor.yaml` の収集ソースを切り替えるだけで、組織規模に合わせて運用を縮小・拡大できる
最小構成で始めて、運用が回り始めてから監査プラグインを追加するのが現実的
📌 まとめ
Agent Skill Harborが解こうとしている課題はシンプルだ——組織内に散らばるAIエージェントのスキルを、追加インフラを入れずにGitだけで一元管理したい。その答えとして、HarborはYAML/JSONをGitに保存し、静的サイトでUIを出し、GitHub Actionsで収集と監査を回す、という極めて合理的な構成を選んだ。
本記事で押さえたポイントを整理すると:
- 課題: スキル資産の散在・重複・未監査・由来不明が組織運用での共通問題
- 設計: サーバーレス・DB不要・Gitネイティブ、全データがYAML/JSONで追跡可能
- 機能: カタログ化・ガバナンス・由来追跡・安全性監査・Slack通知の5本柱
- セットアップ:
npx agent-skill-harbor initの1コマンドから始められる - 拡張: Post-Collectプラグインで監査・通知・ドリフト検出を自由に組み合わせ
- 差別化: スプレッドシート・Wiki・SaaSの弱点(スケール性・追跡性・コスト)を同時に解消
「DBもSaaSも追加せず、既存のGitだけで企業レベルのスキル管理を回せる」——これがHarborが提示した現実解だ。社内でAIエージェントのスキルが増え始めたチームは、まず最小構成でHarborを立ち上げ、detect-drift と notify-slack だけを有効にするところから始めてみてほしい。運用に乗った段階で監査プラグインやカスタム拡張を追加していけば、手間をかけずにガバナンス基盤が育っていく。
OpenHands・Browser Use・ForgeCode・LangChain・MCPサーバー——今後エージェント関連のスキル資産は加速度的に増える。その「保管庫」をどう設計するかは、AI活用の本気度を示す重要な一手になる。