「フレームワークを使ってAIエージェントを作ったら、試作では8割うまくいくのに、本番の顧客に出せる品質にどうしても届かない」——この壁にぶつかった人は多いはずです。12-Factor Agents は、まさにこの「80%の壁」を越えるための設計原則集です。HumanLayerの創業者Dex(@dexhorthy)が、100人以上のSaaS開発者やYC企業の創業者に取材し、「本番の顧客の手に渡せるほど良いLLMアプリを作るには、どんな原則を使えばいいのか?」という問いに答えた、GitHubで約23,700スター(2026年6月時点)を集める一次資料です。
この記事を読むと、①この原則集で何が分かるのか(フレームワークに頼らずエージェントを本番品質まで引き上げる12の実装パターン)、②どんな失敗を防げるのか(「プロンプトとツールを渡してゴールまでループさせる」式の魔法のエージェントが本番で崩れる理由と回避策)、③何の代わりになる考え方なのか(巨大フレームワークへの全面移行に代わる、既存プロダクトへ少しずつ組み込めるモジュラーな設計指針)が分かります。なお、AIエージェント全体のフレームワーク選定で迷っている方は、まずAIエージェントフレームワーク徹底比較2026も合わせて読むと位置づけが掴みやすくなります。

本記事では12のファクターを丸暗記させるのではなく、「プロンプトとコンテキストの主権」「状態と制御フロー」「中断・再開と人間協調」「小さく壊れにくい設計」 という4つのテーマに再編成して解説します。これは元リポジトリにはない当サイト独自のグルーピングで、12個バラバラのチェックリストとして読むより、自分のプロダクトのどこに穴があるかを診断しやすくする狙いがあります。たとえば「エージェントが時々おかしな挙動をする」という症状は入力の主権(ファクター1〜4)の問題であることが多く、「途中で止められない・再開できない」という症状は状態と制御フロー(ファクター5・8・12)の問題、「危ない操作を勝手に実行してしまう」は人間協調(ファクター7)の不在、というように、テーマ単位で原因を切り分けられるようにしてあります。各ファクターの英語名と一次ソースのリンクも併記するので、より深く知りたい原則はリポジトリの該当ページへ直接たどれます。
12-Factor Agentsとは何か:エージェントの正体は「ツールを回すループ」
まず大前提として、12-Factor Agentsが何に対する処方箋なのかを押さえます。リポジトリの出発点はシンプルで、「世に出ている『AIエージェント』のほとんどは、実はそれほどエージェント的ではない。良いものは大部分が普通のソフトウェアで、ちょうどいい所にLLMのステップが差し込まれているだけだ」 という観察です。つまり、LLMにゴールとツールを渡して「終わるまでループ」させるパターン(Anthropicの言う自律エージェント型)は、理想ほどうまくいかない、というのが12-Factor Agentsの問題提起です。

リポジトリはエージェントの実体を、次のようなループに分解しています。①LLMがワークフローの次のステップを決め、構造化JSON(ツール呼び出し)を出力する → ②決定論的なコードがそのツール呼び出しを実行する → ③結果をコンテキストウィンドウに追記する → ④「done」と判定されるまで繰り返す。コードで書くと驚くほど短く、本質はこれだけです。
initial_event = {"message": "..."}
context = [initial_event]
while True:
next_step = await llm.determine_next_step(context)
context.append(next_step)
if next_step.intent == "done":
return next_step.final_answer
result = await execute_step(next_step)
context.append(result)
ここで重要なのは、この素朴なループのままだと本番品質に届かないという点です。リポジトリが描く典型的な失敗の道のりはこうです。「エージェントを作ると決める → フレームワークを掴んで一気に作る → 70〜80%の品質に到達する → 80%では顧客向け機能には不十分だと気づく → 80%を超えるにはフレームワークのプロンプトやフローを逆解析する必要があると分かる → 結局ゼロから作り直す」。12-Factor Agentsは、この遠回りを避けるため、エージェント作りの小さくモジュラーな概念だけを取り出し、既存プロダクトに組み込めるようにしたものです。AIの専門家でなくても、腕のあるソフトウェアエンジニアなら適用できる粒度に落としてあるのが特徴です。
リポジトリは、ソフトウェアの歴史を「有向グラフ(DG)と、その非循環版であるDAG」という補助線で語ります。そもそもソフトウェアは有向グラフであり、だからこそ昔はプログラムをフローチャートで表現していた、と。20年ほど前からはAirflowやPrefect、近年のDagster・Inngest・Windmillといった「DAGオーケストレーター」が普及し、可観測性・モジュール性・リトライ・管理機能を備えながら同じグラフのパターンを踏襲してきました。そこにエージェントが登場し、「DAGを捨てられる」という期待が生まれます。各ステップとエッジケースをエンジニアが1つずつコーディングする代わりに、エージェントにゴールと遷移の集合だけを渡し、LLMにリアルタイムで経路を決めさせる——書くソフトウェアは減り、エラーから回復でき、LLMが新しい解法を見つけることもある、という夢です。しかし12-Factor Agentsの率直な結論は、「やってみると、これは思ったほどうまくいかない」。だからこそ、グラフを全部捨てるのではなく、決定論的なコードの骨格を保ちつつ、ちょうどいい所にLLMを差し込む——その「ちょうどいい所」を12個に言語化したのが本リポジトリなのです。
プロンプトとコンテキストの主権:ファクター1〜4
最初のテーマは「入力の主権を握る」ことです。LLMは入力(コンテキスト)を出力に変換するだけのステートレスな関数なので、最良の出力を得るには最良の入力を渡すしかない——これが12-Factor Agentsの中核思想です。ファクター1〜4は、その入力を構成する「自然言語の解釈・プロンプト・コンテキストウィンドウ・ツール」を、フレームワークの内部に隠さず自分の手で握れ、と説きます。

・ファクター1:自然言語をツール呼び出しへ(Natural Language to Tool Calls) — 「2月のAI Tinkerers meetupのスポンサーとしてTerriに750ドルの支払いリンクを作って」といった自然言語を、create_payment_link のような構造化されたAPIコール(JSON)に翻訳する。これがエージェントの最も基本的なパターンで、ここから先は決定論的なコードが引き取れる。
・ファクター2:プロンプトを所有せよ(Own your prompts) — プロンプトをフレームワークの抽象に丸投げせず、自分でコードとして管理する。プロンプトは「関数」であり、品質を上げるには中身を完全に掌握し、あらゆる書き方を試せる自由が要る。
・ファクター3:コンテキストウィンドウを所有せよ(Own your context window) — LLMへの入力は必ずしも標準のメッセージ配列形式である必要はない。「これまでに何が起きたか、次の一手は何か」を最も効率よく伝える独自フォーマットを設計してよい。プロンプト・RAGで取得した文書・過去のツール呼び出しと結果・関連する別履歴(メモリ)・出力スキーマ——これらすべての設計がコンテキストエンジニアリングであり、12-Factor Agentsが最も重視する技術。
・ファクター4:ツールは構造化出力にすぎない(Tools are just structured outputs) — 「ツール」という言葉に過剰な意味を持たせない。ツールとはLLMが出す構造化されたJSON出力であり、それを受けて決定論コードが副作用を起こすだけ。LLMとコードの境界を明確にできる
この4つに共通するメッセージは、「LLMへの入力を、ライブラリ任せのブラックボックスにせず、自分で組み立てられる状態にしておけ」 ということです。80%の壁を超える微調整は、ほぼすべてこの入力側で行われるため、入力の主権を失った瞬間に品質改善の手段を失います。
とくにファクター3のコンテキストウィンドウの主権は、実装上のインパクトが大きい原則です。多くのLLMクライアントは role: user / role: assistant が並ぶ標準のメッセージ配列形式を前提にしますが、リポジトリは「その形式に縛られる必要はない」と言い切ります。たとえばツール呼び出しと結果の履歴を、トークン効率の良い独自のXMLライクなフォーマットや、要点だけを残した要約形式で渡しても構いません。エージェントへの入力は突き詰めれば「これまでに何が起きたか、次の一手は何か」の一言に集約されるため、その「これまで」をどう圧縮し・整形し・優先順位づけして詰め込むかが、そのまま出力品質に直結します。逆に言えば、フレームワークがメッセージ整形を内部で固定してしまうと、トークン上限に当たったときの圧縮戦略も、ノイズの除去も、自分では手を入れられなくなります。なお、リポジトリはモデルの temperature などのパラメータ調整やファインチューニングには踏み込まず、「今日のモデルから最大限を引き出す」ことに集中している点も、実務家にとって再現性が高い理由のひとつです。
状態と制御フローを自分の手に:ファクター5・8・12
次のテーマは、エージェントの「状態管理」と「制御フロー」です。多くのフレームワークは、エージェントの実行状態(今どのステップか、待機中か、リトライ回数は何回か)と業務状態(これまでのメッセージ・ツール呼び出しと結果の履歴)を別々に管理しようとします。12-Factor Agentsは、この分離が不要な複雑さを生むなら、いっそ統一してしまえと主張します。
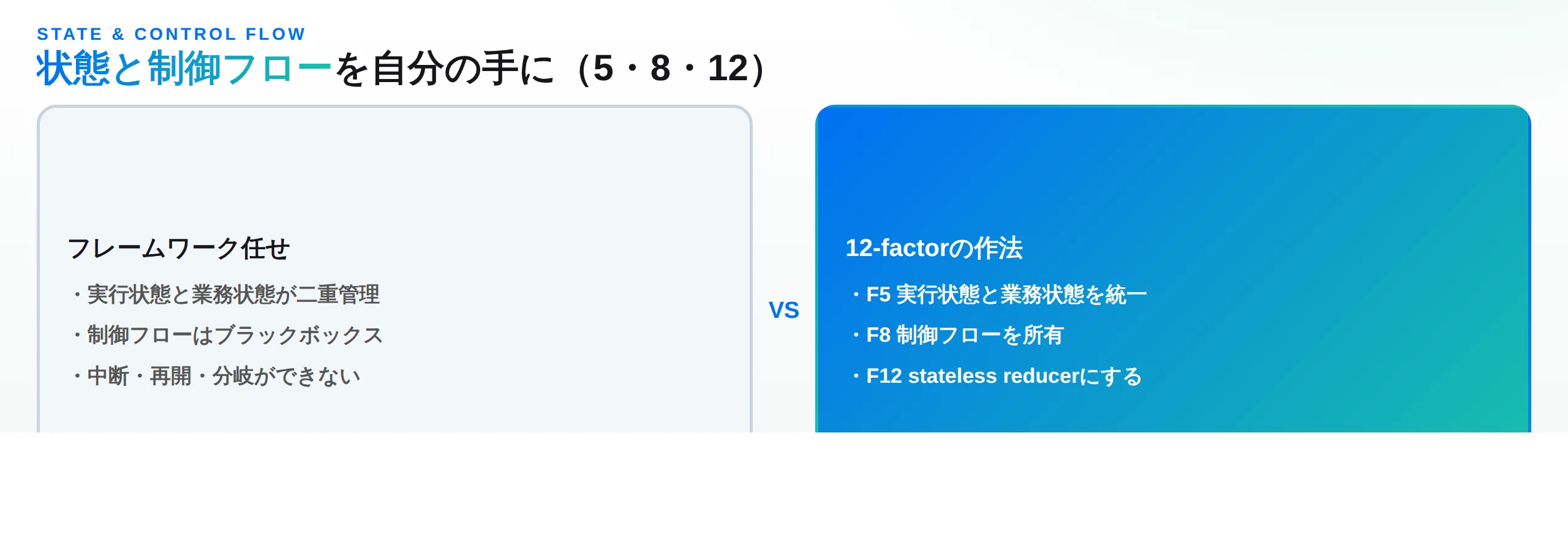
・ファクター5:実行状態と業務状態を統一せよ(Unify execution state and business state) — 実行状態の大半は「これまでに何が起きたか」のメタデータにすぎない。コンテキストウィンドウからすべての実行状態を推論できるよう設計すれば、状態の単一の真実が生まれる。利点は、シリアライズが容易・履歴が一箇所で可視化されデバッグしやすい・任意の地点から再開やフォークができる、など。
・ファクター8:制御フローを所有せよ(Own your control flow) — ループの中身を自分で書けば、特定のツール呼び出しでループを抜けて人間の応答を待つ、長時間ジョブを待つ、といった独自の制御構造を組める。ツール結果の要約・キャッシュ、LLM-as-judgeによる出力検証、コンテキストの圧縮、ロギング・トレース、レート制限、durableな「イベント待ち」など、本番に必要な工夫はすべてここに差し込める。
・ファクター12:エージェントをステートレスなreducerにせよ(Make your agent a stateless reducer) — エージェントを「現在の状態(履歴)+新しいイベント → 次の状態」を返す純粋な畳み込み関数(foldl)として捉える。状態を外に持つことで、テスト・再現・スケールが容易になる
この3ファクターは、関数型プログラミングのreducer(畳み込み)の発想をエージェントに持ち込んだものと読むと腑に落ちます。状態を「履歴という1本のデータ」に集約し、エージェント本体は副作用を持たない変換器にする——この形にしておくと、中断・再開・分岐・リプレイがすべて「履歴をいじるだけ」で実現でき、本番運用で必須になる回復性が手に入ります。下図は、ファクター8の制御フローが「人間の承認待ち」「ツール実行して継続」「明確化の依頼」へ分岐していく様子です。
プロンプト化"] --> B["LLMが
次の一手を決定"] B --> C{"intentは
何か"} C -->|request_clarification| D["ループを抜けて
人間の応答を待つ"] C -->|deploy_backend| E["高リスク:
人間の承認を待つ"] C -->|fetch_git_tags| F["ツール実行→
結果を履歴に追記"] C -->|done| G["最終回答を返す"] F --> B D -->|再開| B E -->|承認| B
中断・再開と人間との協調:ファクター6・7・11
3つ目のテーマは、エージェントを「閉じたループ」から「外の世界とつながるシステム」へ開く設計です。本番のエージェントは、いつでも止まり、いつでも再開し、危険な操作の前には人間に確認を取る必要があります。ファクター6・7・11は、その入口(トリガー)と出口(人間への連絡)と、その間の一時停止・再開を扱います。
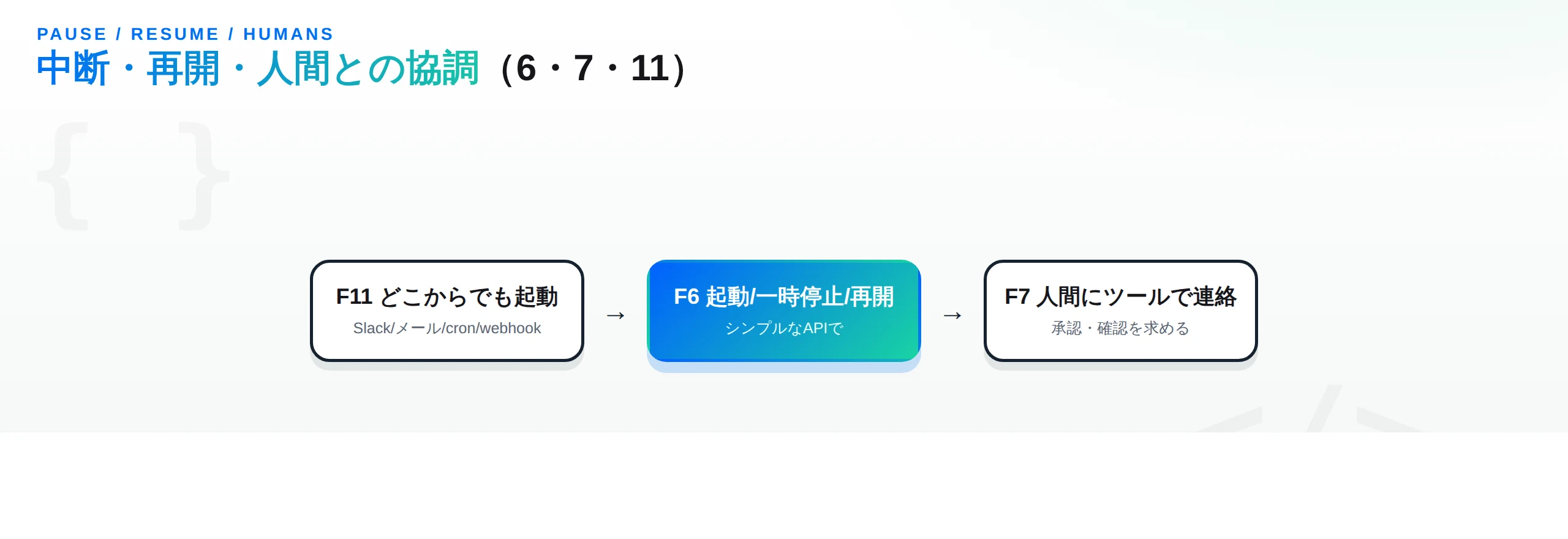
・ファクター6:シンプルなAPIで起動・一時停止・再開(Launch/Pause/Resume with simple APIs) — エージェントは外部システムから簡単に起動でき、長時間の処理の途中で一時停止し、後から再開できるべき。ファクター5・12で状態を履歴に統一していれば、これは「履歴をロードして続きを回す」だけで実現できる。
・ファクター7:人間への連絡もツール呼び出しで(Contact humans with tool calls) — 「人間に確認を求める」「明確化を依頼する」といった人間との対話も、特別な機構ではなく1つのツール呼び出しとして表現する。LLMが request_clarification や承認待ちのツールを出したらループを抜け、人間の応答を待ってから再開する。承認フローやhuman-in-the-loopが自然に組み込める。
・ファクター11:どこからでもトリガー、ユーザーのいる場所で出会え(Trigger from anywhere, meet users where they are) — エージェントの起動口をAPI呼び出しに限定しない。Slack、メール、Discord、SMS、cron、Webhookなど、ユーザーが既にいる場所からトリガーできるようにし、同じチャネルで結果を返す
この3つを合わせると、エージェントは「人間と長時間ジョブを巻き込みながら、止まったり再開したりできる非同期ワークフロー」になります。とくにファクター7は12-Factor Agentsの提唱元であるHumanLayerの中核思想で、「人間への確認」をフローの外の特別扱いではなく、エージェントが選べる普通の選択肢の1つに格下げする点が肝です。高リスクな操作(本番デプロイ、送金など)の前に人間の承認を挟めるかどうかが、本番投入の可否を分けます。
実務でこの設計が効くのは、エージェントが必ずしも数秒で完結しないからです。承認待ちが数時間、外部の長時間ジョブが数十分かかることは珍しくありません。プロセスを起動しっぱなしで待たせるのは現実的でないため、ファクター6の「シンプルなAPIで止めて再開する」が必要になります。ファクター5・12で状態を履歴に統一しておけば、エージェントは「いったん終了し、人間の応答やイベントが来たら履歴をロードして続きを回す」だけで再開できます。さらにファクター11でSlackやメール、Webhookから起動できるようにしておけば、ユーザーはわざわざ専用UIを開かなくても、普段使っているチャネルの中でエージェントに仕事を投げ、結果を受け取れます。「どこから来て、どう止まり、誰に確認し、どこへ返すか」という入口・出口・人間の3点を設計することが、このテーマの本質です。
小さく・壊れにくく作る:ファクター9・10
最後のテーマは、エージェントの「サイズ」と「エラー耐性」です。LLMはコンテキストが長くなるほど迷子になり、フォーカスを失います。だからこそ、1つのエージェントに何でもやらせる巨大モノリスではなく、1つのことを上手くやる小さなエージェントを組み合わせる——これがファクター10の主張です。そしてファクター9は、エラーすらコンテキストの一部として上手く扱う技術です。
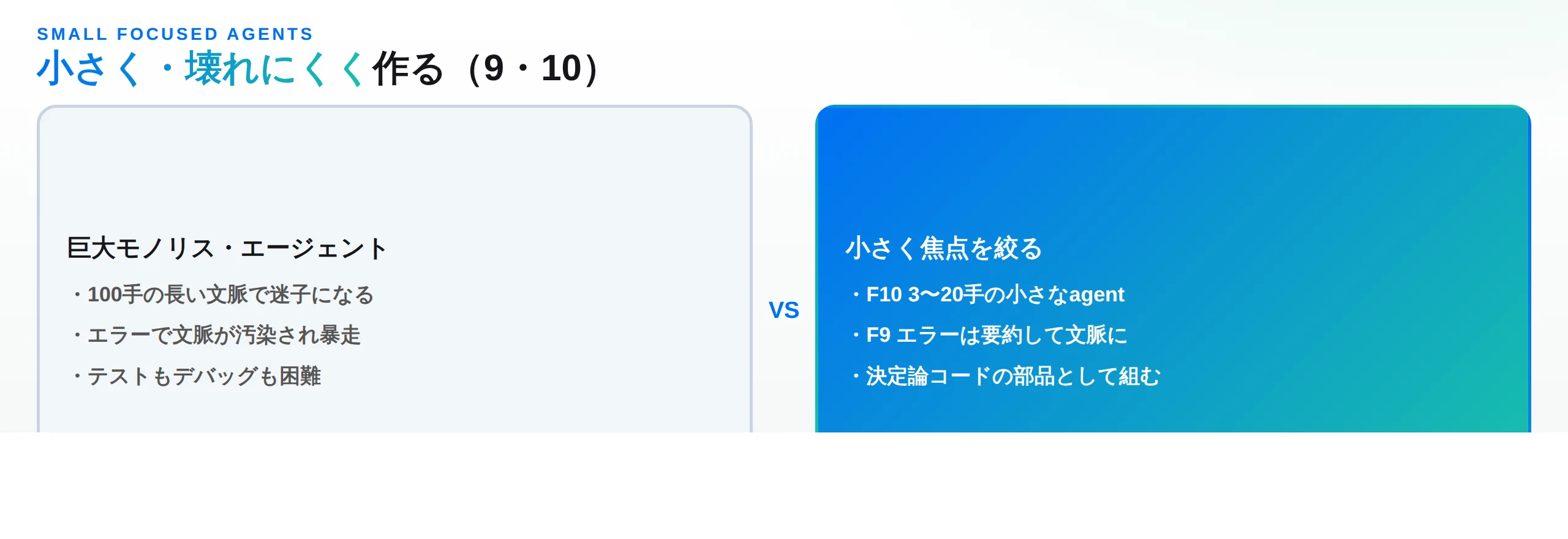
・ファクター9:エラーを要約してコンテキストに畳み込め(Compact Errors into Context Window) — ツール呼び出しが失敗したとき、生のスタックトレースをそのまま延々と文脈に積むのではなく、要約してコンテキストに戻す。これによりLLMは「何が失敗したか」を理解して自己修正でき、かつ文脈が失敗ログで溢れて暴走するのを防げる。エラーハンドリングを制御フロー(ファクター8)の一部として設計する。
・ファクター10:小さく焦点を絞ったエージェント(Small, Focused Agents) — 1つのエージェントの担当を3〜10、多くても20ステップ程度に抑える。タスクが大きく複雑なほどステップ数が増え、コンテキストが膨らみ、LLMは迷子になりやすい。担当範囲を絞ればコンテキストが小さく保たれ、責務が明確になり、信頼性・テスト容易性・デバッグ性がすべて上がる。エージェントは「大部分が決定論的なシステムの中の、1つの部品」にすぎない
ファクター10には「LLMが賢くなれば不要になるのでは?」という当然の疑問への答えも書かれています。リポジトリの結論は「それでも必要(tl;dr yes)」。モデルが賢くなれば扱えるステップ数は増えるかもしれないが、小さく絞る設計は「今日、確実に結果を出す」ためのものであり、モデルの進化に合わせて担当範囲を慎重に広げていく土台になる、という考え方です。リポジトリはNotebookLMを作ったチームの言葉「AI構築で最も魔法のような瞬間は、決まってモデルの能力の限界ギリギリに立っているときに生まれる」を引きながら、その境界を見極めて一貫して当て続けられれば、そこに技術的な堀(moat)が築ける、と述べています。担当を絞るのは品質を諦めることではなく、品質を保てる範囲を見定めたうえで、確実に成果を出せる線を引く工学的な判断なのです。
さらに、リポジトリは正式な12に加えてファクター13:必要なコンテキストを先読みせよ(Pre-fetch all the context you might need) を「番外(Honorable Mention)」として挙げています。LLMにツールで取りに行かせなくても確実に必要と分かっているデータは、先に取得して渡しておけ、という実用的な助言です。たとえば「最初に必ずユーザー情報を引く」と分かっているなら、LLMにわざわざ「ユーザー情報を取得する」というツール呼び出しを1往復させるより、最初から履歴に載せてしまうほうが、ステップ数も減り、ループが迷う余地も減ります。ファクター9のエラー要約と合わせて、「LLMに余計な判断をさせず、決定論で済むことは決定論で済ませる」という姿勢が、この最後のテーマには一貫して流れています。
12-Factor AppとAIエージェント設計原則の違い
12-Factor Agentsという名前は、2011年にHerokuのエンジニアが提唱した12 Factor Appへのオマージュです(リポジトリ自身が「12 Factor Appsの精神に則って」と明記しています)。両者は「移植性と信頼性のある作法を12個に体系化する」構造は同じですが、対象とする世界が決定的に違います。

12 Factor Appが対象にするのは、設定・依存関係・プロセス・ポートバインディングといった「決定論的なWebサービス」をクラウドで安定運用するための作法です。一方12-Factor Agentsが扱うのは、確率的に振る舞うLLMを組み込んだソフトウェアを、いかに信頼でき・保守でき・スケールできるものにするかという、まったく新しい難所です。下の表に両者と、AIエージェントでありがちなアンチパターンとの対比を整理します。
| 観点 | 12-Factor App (2011) | 12-Factor Agents (2025) | ありがちなアンチパターン |
|---|---|---|---|
| 対象 | 決定論的なWeb/SaaS | 確率的なLLMアプリ | 「魔法のループ」型エージェント |
| 核心テーマ | 設定・依存・プロセスの分離 | コンテキスト・制御フロー・状態・人間協調 | プロンプトとツールを渡して放置 |
| 状態 | ステートレスなプロセス | 履歴に統一・stateless reducer | 実行状態と業務状態の二重管理 |
| 制御フロー | プロセスモデルに従う | 自分で所有・カスタム制御 | フレームワーク内部に隠蔽 |
| 失敗時 | プロセス再起動で復旧 | エラーを要約して自己修正 | スタックトレースで文脈が汚染 |
| 人間の関与 | 想定外(自動運用が前提) | ツール呼び出しとして組込 | 承認や確認の機構がない |
ここで誤解してはいけないのは、12-Factor Agentsは「フレームワークを使うな」と言っているわけではない点です。リポジトリは「フレームワークは素晴らしいものを可能にしてきたし、これは批判ではない」と明記しています。主張はむしろ、「フレームワークへの全面移行(グリーンフィールドな書き直し)に飛びつく前に、エージェント作りの小さなモジュラー概念だけを取り出し、既存プロダクトに組み込むのが最速だ」 ということ。つまり12-Factor Agentsは、特定のライブラリの代わりではなく、ライブラリを使うにせよ自作するにせよ通底する「設計の物差し」を提供しているのです。
なお、リポジトリはあえて2つのトピックには深入りしないと断っています。1つはMCP(Model Context Protocol)で、「どこに当てはまるかは見ればわかるだろう」とだけ触れています。MCPはツールの接続規約なので、ファクター4(ツールは構造化出力)の文脈に自然に収まる、という含意です。もう1つは特定の実装言語への依存で、著者は主にTypeScriptで書いているものの、原則はPythonでも他のどの言語でも同様に成り立つとしています。この「言語にもプロトコルにも依存しない」性質こそが、設計原則としての寿命を長くしています。実際、リポジトリは公開後も貢献者によって継続的に更新され、npx/uvx で雛形を作る create-12-factor-agent のような周辺ツールの議論も進んでいます。読者としての向き合い方は明快で、12個すべてを一度に満たそうとするのではなく、自分のプロダクトで最も痛い1〜2点から順に当てていくのが、リポジトリ自身が推奨する「最速で高品質に届く」道筋です。
まとめ
12-Factor Agentsは、「本番の顧客に出せる品質のLLMアプリを作るには、どんな原則を使えばいいのか」という問いへの、現場発の回答です。改めて12のファクター(+番外の13)を本記事のテーマ別グルーピングで振り返ります。
| テーマ | 含まれるファクター | 一言でいうと |
|---|---|---|
| 入力の主権 | F1 自然言語→ツール呼出 / F2 プロンプト所有 / F3 文脈窓所有 / F4 ツールは構造化出力 | LLMへの入力を自分で握れ |
| 状態と制御フロー | F5 状態統一 / F8 制御フロー所有 / F12 stateless reducer | 状態を履歴に集約し、ループを自分で書け |
| 中断・再開・人間協調 | F6 起動/一時停止/再開 / F7 人間にツールで連絡 / F11 どこからでも起動 | 外の世界と人間に開け |
| 小さく壊れにくく | F9 エラー要約 / F10 小さく焦点を絞る | 担当を絞り、失敗を文脈に畳み込め |
| 番外 | F13 コンテキスト先読み | 確実に要るデータは先に取れ |
要点は3つです。①この原則集で何が分かるか——フレームワークに依存せず、エージェントを試作の80%から本番品質へ引き上げる具体的な実装パターンが分かります。②どんな失敗を防げるか——「プロンプトとツールを渡してゴールまで自律ループ」式のエージェントが、状態の二重管理・制御フローのブラックボックス化・エラーによる文脈汚染で崩れるのを防げます。③何の代わりになる考え方か——巨大フレームワークへの全面移行に代わる、既存プロダクトへ少しずつ組み込めるモジュラーな設計指針です。ライセンスは、コードがApache 2.0、文章と画像がCC BY-SA 4.0で、出典を明記すれば翻案・再配布が可能です(GitHub上の表記が正式)。
まずは自分のエージェントを、ファクター3(文脈の主権)とファクター7(人間への連絡)の2点で診断してみるのがおすすめです。この2つが押さえられていないエージェントは、ほぼ確実に本番で壁にぶつかります。
よくある質問(FAQ)
Q1. 12-Factor Agentsはフレームワークやライブラリですか?
いいえ。インストールして使うコードではなく、設計原則(プリンシプル)をまとめたドキュメント集です。リポジトリの実体は大部分がMarkdownで、content/ 配下に各ファクターの解説が置かれています。LangGraphやCrewAIなどのフレームワークを使う場合でも、自作する場合でも適用できる「物差し」として読むものです。
Q2. 既存のフレームワークを捨てる必要がありますか? ありません。リポジトリ自身が「これはフレームワーク批判ではない」と明言しています。むしろ提案は逆で、全面的な書き直しに飛びつくより、エージェント作りの小さなモジュラー概念(コンテキスト管理や人間への確認など)を既存プロダクトに少しずつ組み込むのが、最速で高品質に到達する道だとしています。
Q3. なぜ「魔法のループ」型のエージェントではダメなのですか? LLMにゴールとツールを渡して終わるまでループさせる方式は、試作では70〜80%の品質に届きますが、本番の顧客向け機能には不十分なことが多いからです。残り20%を詰めようとすると、フレームワーク内部のプロンプトやフローを逆解析する羽目になり、結局作り直しになる——この遠回りを避けるのが12-Factor Agentsの狙いです。
Q4. コンテキストエンジニアリングとは何ですか? LLMへの入力(プロンプト・取得文書・過去の履歴・メモリ・出力スキーマなど)を最良の形に設計する技術全般を指します。12-Factor Agentsはこれを最重要視しており、「文脈エンジニアリングを探しているなら、まずファクター3を読め」とREADMEで案内しているほどです。LLMはステートレスな関数なので、出力の質は入力の質でほぼ決まります。
Q5. ファクター13があるのに、なぜ「12」ファクターなのですか? ファクター13「コンテキストの先読み(Pre-fetch)」は、正式な12には含まれない「番外(Honorable Mention/その他の助言)」として付録扱いされているためです。名前は元ネタの12 Factor Appに揃えてあります。実用上は13も有用な助言として読んで構いません。
Q6. 誰が作ったもので、どこまで信頼できますか? HumanLayer創業者のDex(@dexhorthy)が中心となり、SF MLOpsコミュニティなど多数の貢献者のフィードバックを受けて作られた一次資料です。著者が100人以上のSaaS創業者に取材し、数十社の現場で得た知見をまとめたものである点、GitHubで2万スター超を集めコミュニティで継続的に議論・改善されている点が信頼性の根拠になります。ただし設計原則であり、絶対的な正解ではなく「今日のモデルで最大限の成果を出すための指針」として書かれています。
参照ソース
・humanlayer/12-factor-agents(GitHub公式リポジトリ) — 本記事の一次ソース。12ファクターの全文と各ファクターの content/ 解説、ライセンス表記(コードApache 2.0/文章・画像CC BY-SA 4.0)はここを参照。
・12 Factor App(公式サイト) — 12-Factor Agentsの元ネタ。決定論的なWebアプリ向けの12原則で、両者の対比を理解する基礎になる。
・Building Effective Agents(Anthropic Engineering) — 12-Factor Agentsが参照する「自律エージェント型ループ」の出典。エージェント設計の前提を押さえるのに有用。