AIエージェントには「デモでは動くのに、本番で壊れる」という呪いがある。壊れる原因の多くは、モデルの賢さ不足ではなく、その周囲をどう組み立てたか——設計パターンの選び方にある。
2025年末、Googleのエンジニア Antonio Gulli が424ページの実践書『Agentic Design Patterns(エージェント設計パターン)』を公開した。本書はAIエージェントを構築するときに繰り返し現れる課題を、21の再利用可能な「型」として体系化している。本記事はこのPDFをもとに、コードを一切使わず図解だけで、21の設計パターンの全体像を地図化する。
AIエージェントの実装手段そのものを比較したい方は AIエージェントフレームワーク比較2026:LangGraph・CrewAI・AutoGen徹底解説 をご覧ください。
この記事でわかること
・エージェント設計パターンという考え方と、なぜ単一プロンプトでは足りないのか
・AIエージェントの能力レベル(Level 0〜3)と、各段階で必要になる型
・21の設計パターンを「基盤・記憶と学習・堅牢性と安全・協調と探索」の4系統で俯瞰する地図
・各パターンを「いつ使うか」で引けるチートシートと、導入時の落とし穴
30秒でわかるエージェント設計パターン
・設計パターンは設計判断の共通言語:複雑なタスクを巨大な1プロンプトに詰めると壊れる。分割・分岐・検証・記憶といった「型」を組み合わせるのがエージェント設計の本質
・21パターンは4系統に整理できる:実行の流れを作る基盤系、連続性を与える記憶と学習系、本番で壊れないための堅牢性と安全系、複数体を束ねる協調と探索系
・能力はLevel 0〜3の階段:ツールなしの推論コアから、ツール接続、複数ステップの戦略家、専門エージェントの協調へと自律性が上がる
・学習順序は基盤7つから:プロンプトチェーン・ルーティング・並列化・リフレクション・ツール利用・プランニング・マルチエージェントで骨格が見える
・パターンは足し算で増やす:最小構成で動かし、信頼性が足りない箇所にだけ堅牢性・安全のパターンを継ぎ足すのが過剰設計を避ける近道。実際のエージェントは7つ前後の型が連携して動いている
エージェント設計パターンとは何か
AIエージェントとは、環境を知覚し、目的達成のために行動するシステムだ。標準的なLLMに「計画する・ツールを使う・環境とやり取りする」能力を足した進化形と言える。本書はこれを「仕事をしながら学ぶ賢いアシスタント」と表現する。著者のAntonio GulliはGoogleでAIに携わるエンジニアで、本書では各章を1つの設計パターンに割り当て、課題(What)・解法(Why)・使いどころ(Rule of thumb)という共通の型で整理している。
ここ2年で、AIのパラダイムは単純な自動化から自律的なシステムへと劇的に移った。最初は基本的なプロンプトとトリガーでLLMにデータを処理させていた。次にRAG(検索拡張生成)が事実に基づく裏付けで信頼性を高めた。続いてツールを使う個別のAIエージェントが登場し、いまは専門エージェントのチームが協調するAgentic AIの時代に入っている。
設計パターンが必要になるのは、この複雑さを「行き当たりばったり」で組むと破綻するからだ。ソフトウェア工学のデザインパターンと同じく、繰り返し現れる課題に対して検証済みの解法を名前付きで共有することで、設計の議論と再利用が一気に楽になる。
エージェントの普及スピードは速い。本書が引くデータでは、大手IT企業の多くがすでにエージェントを業務で使い始めており、その一部はここ1年で導入を開始したばかりだという。市場規模も2024年末時点で52億ドルと評価され、エージェント関連スタートアップは20億ドル超を調達した。2034年には2000億ドル近くまで拡大すると見込まれている。つまり、エージェント設計の良し悪しが事業の成否を左右する局面が、現実のものになりつつある。
だからこそ「とりあえず動いた」で止めず、再現可能な設計原則を持つことが重要になる。本書の21パターンは、その原則を21枚のカードに整理したカタログだと考えるとわかりやすい。
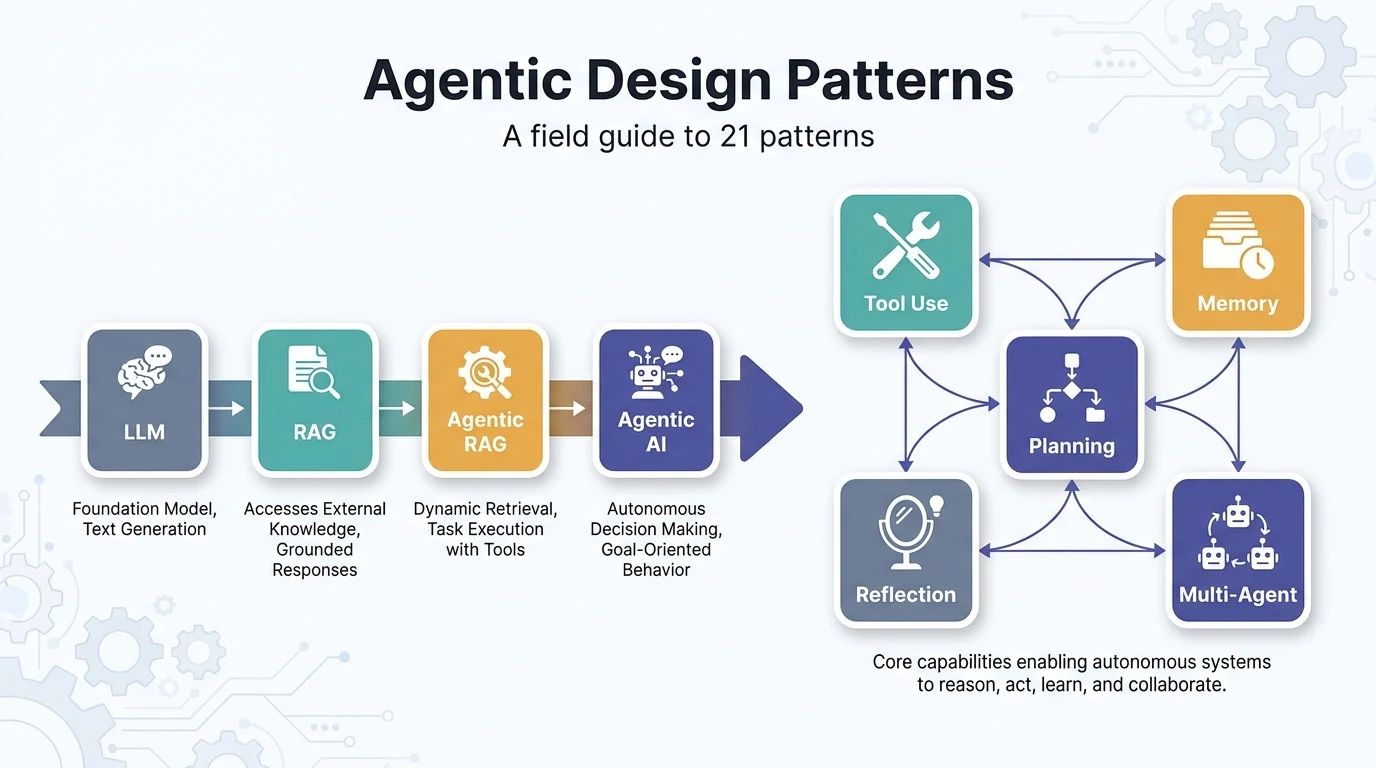
設計パターンの定義:エージェント構築で繰り返し現れる「課題と解法」を、再利用可能な名前付きの型にしたもの。実装フレームワークが何であれ通用する、設計判断のための共通言語だ。
AIエージェントの能力レベル — Level 0から3の階層
すべてのエージェントが同じ複雑さを持つわけではない。本書は能力を4段階で整理する。下の段ほど単純で、上の段ほど自律的になり、必要な設計パターンも増えていく。
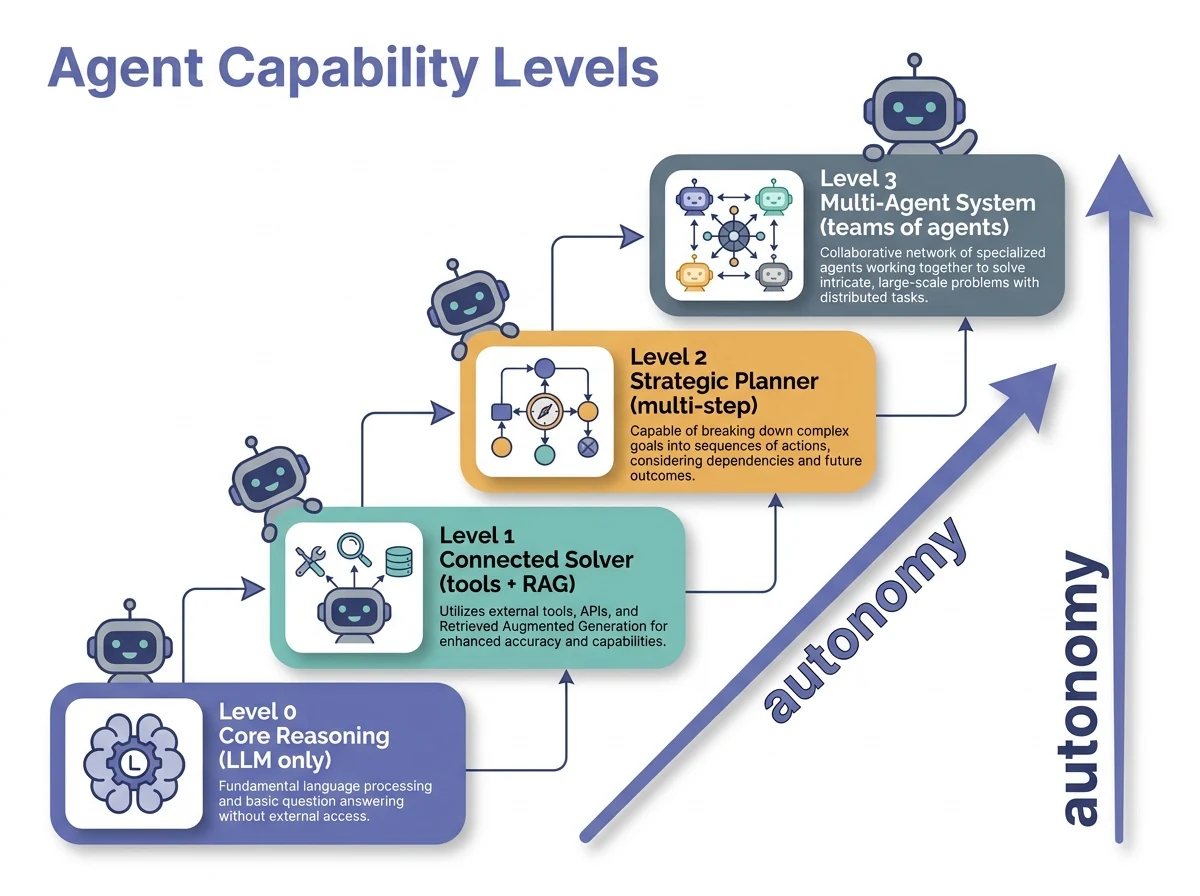
・Level 0:推論コア——ツールも記憶も環境連携もなく、学習済み知識だけで答えるLLM単体。確立した概念の説明には強いが、最新の出来事は知らない
・Level 1:つながった問題解決者——検索やRAGで外部ツールに接続し、学習済み知識の外へ出る。複数ステップで情報を集めて統合できる
・Level 2:戦略的な問題解決者——単一ツールを超え、複雑な多段タスクを計画する。各ステップで最も関連の高い情報だけを選び取る「コンテキストエンジニアリング」が核になる
・Level 3:協調するシステム——専門エージェントのチームが連携して大きな目標に挑む。本書が最も重視する領域
| レベル | 呼び名 | できること | 必要な主なパターン |
|---|---|---|---|
| Level 0 | 推論コア | 学習済み知識で回答 | (パターン不要) |
| Level 1 | 問題解決者 | ツール・RAGで情報収集 | ツール利用 / 知識検索(RAG) |
| Level 2 | 戦略家 | 多段タスクを計画・実行 | プランニング / リフレクション / 記憶 |
| Level 3 | 協調システム | 専門エージェントが協働 | マルチエージェント / A2A / 評価 |
エージェントが動く5ステップのループ
レベルが上がっても、エージェントの基本動作はシンプルなループに収まる。本書はこれを「目的を受け取り、状況を読み、考え、行動し、学ぶ」の5ステップとして示す。設計パターンの多くは、このループのどこかを強化する道具立てだと考えるとわかりやすい。
例: 予定を整理して"] --> B["2 状況を読む
メール・カレンダー収集"] B --> C["3 考える
最適な手順を計画"] C --> D["4 行動する
招待送信・予定登録"] D --> E["5 学んで改善する
結果を観察し適応"] E -. 次のタスクへ .-> A
たとえば「予定を整理して」という目的を受け取ると、エージェントはメールやカレンダーを読んで状況を把握し、最適な手順を考え、招待状の送信や予定の更新を実行し、会議が再調整されればその経験から学んで次に活かす。プランニング・記憶・リフレクションといったパターンは、それぞれ「考える」「読む」「学ぶ」を担当する部品だ。
21の設計パターンを4つの系統で俯瞰する
本書の21パターンは、役割で大きく4つの系統に分けられる。いきなり個別の名前を覚えるより、まずこの地図を頭に入れると迷子になりにくい。系統は「1回の実行を組み立てる→連続性を与える→壊れないようにする→複数体で高度化する」という、エージェントを育てる順序にも対応している。下の象限図のとおり、左上から時計回りに難度と自律性が上がっていくと捉えるとよい。
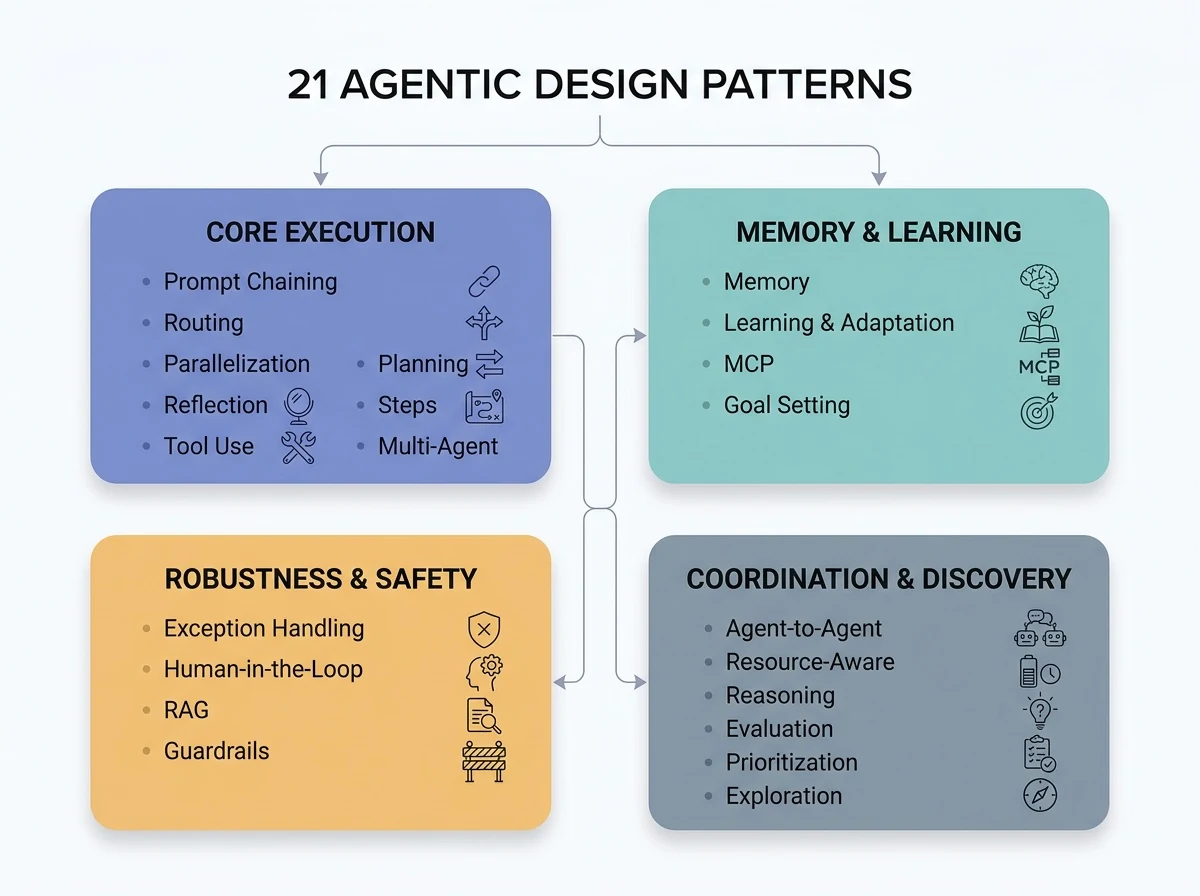
・基盤系(実行の流れを組み立てる):プロンプトチェーン、ルーティング、並列化、リフレクション、ツール利用、プランニング、マルチエージェント
・記憶と学習系(連続性を与える):記憶管理、学習と適応、MCP、目標設定とモニタリング
・堅牢性と安全系(本番で壊れないために):例外処理と回復、ヒューマン・イン・ザ・ループ、知識検索(RAG)、ガードレール
・協調と探索系(高度な連携と推論):エージェント間通信(A2A)、リソース最適化、推論技法、評価とモニタリング、優先順位付け、探索と発見
基盤系パターン — 実行の流れを組み立てる7つ
ここからは系統ごとに中身を見ていく。基盤系の7パターンを押さえれば、ほぼすべてのエージェントの骨格が読めるようになる。
プロンプトチェーンは、複雑な問題を小さなサブタスクの連鎖に分割する型だ。1つのプロンプトの出力を次の入力に渡し、段階的に最終解へ近づける。分割統治によってデバッグしやすくなり、ステップ間に外部ツールを挟む余地も生まれる。多段の推論を要するエージェントの土台になる。たとえば長文資料を「要約→要点抽出→指定トーンへ書き換え」と段階処理すれば、一発で全部やらせるより各ステップを検証・調整しやすい。各段の出力が次段の入力になるため、文脈が引き継がれて精度が積み上がる。
ルーティングは、入力の意図を解析して最適な処理経路へ動的に振り分ける型だ。あらかじめ決めた一本道ではなく、文脈に応じて専門ツールやサブエージェントを選ぶ。振り分けの判断は、LLMへの問い合わせ・あらかじめ定めたルール・埋め込みによる意味的類似度など複数の方法で実装できる。カスタマーサポートで「営業」「技術」「アカウント」の問い合わせを仕分けるような、入力の種類が多岐にわたるアプリケーションに不可欠だ。
意図を解析"} R -->|営業の質問| S["営業エージェント"] R -->|技術サポート| T["技術エージェント"] R -->|アカウント| A["アカウント管理"]
並列化は、互いに依存しない処理を同時に走らせる型だ。複数APIの呼び出しや複数チャンクの処理を逐次でやると合計時間がボトルネックになる。独立した部分を並行実行すれば、総実行時間を大きく削れる。たとえば1つの文章を「事実確認」「文体チェック」「法務観点レビュー」と複数の観点で同時に評価し、最後に結果を統合するような構成に向く。LangChainやGoogle ADKといったフレームワークは、この並行実行を定義・管理する仕組みを標準で備えている。
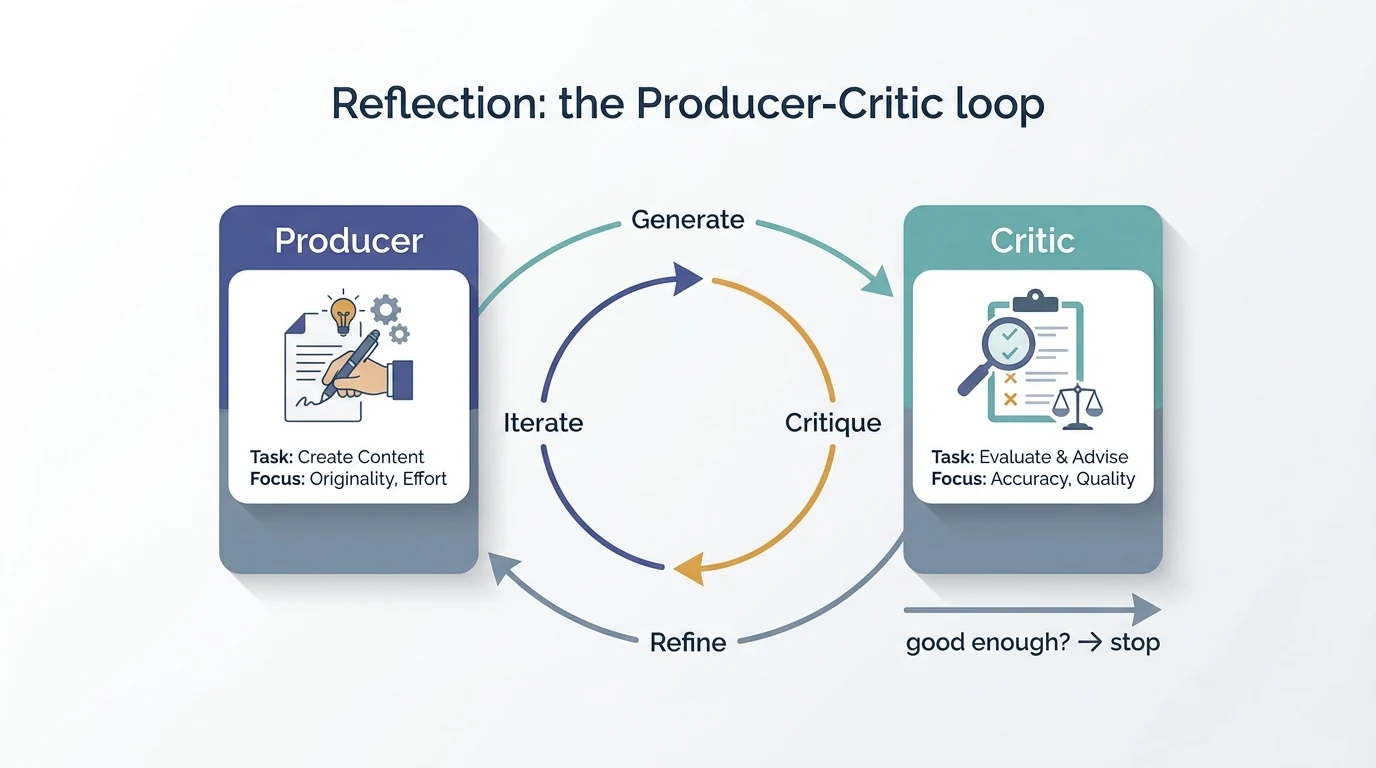
リフレクションは、エージェントが自分の出力を評価して改善する自己修正の型だ。単純な連鎖が出力を次へ渡すだけなのに対し、リフレクションはフィードバックループを持ち込む。実装では生成役(Producer)と批評役(Critic)を分けるモデルが効果的で、別々の役割を与えた方がより堅牢で偏りのない結果になりやすい。
ツール利用(関数呼び出し)は、LLMを外部世界とつなぐ型だ。LLMは本質的に外界から切り離されており、学習時点の静的な知識しか持たない。そこで利用可能な関数をモデルに説明しておき、必要に応じてモデルが「どの関数をどの引数で呼ぶか」をJSONなどの構造化データで指定する。オーケストレーション層がその呼び出しを実行して結果を返し、モデルはそれを最終回答に織り込む。
天気や株価の取得、計算、コード実行、メール送信、スマートデバイスの制御など、内部知識の外にある「行動」を可能にする。
プランニングは、高レベルの目標を実行可能な小ステップの並びに分解する型だ。依存関係を論理的な順序で扱い、調査レポート生成や新入社員オンボーディング、競合分析のような多段プロセスを自動化する。LLMは膨大な学習データから妥当な計画を立てるのが得意で、必要に応じて途中で計画を組み替えることもできる。反応的なエージェントを、目標へ能動的に進む戦略的実行者へ変えるのがこの型の核心だ。
マルチエージェント協調は、複雑な問題を専門エージェントに分担させる型だ。単一の万能エージェントは、多面的なタスクに必要な専門スキルやツールをすべて備えられず、そこがボトルネックになる。そこで問題を小さなサブ問題に割り、それぞれに専用の道具を持つ専門エージェントを割り当てる。逐次の引き継ぎ、並行ワークストリーム、階層的な委譲といった相互作用モデルで連携させると、個々の合計を超える相乗効果が生まれる。
複雑な調査・ソフトウェア開発・創作のように、多様な専門性や段階的なワークフローが要る場面で力を発揮する。
学習のコツ:この7つは「分割(チェーン)→分岐(ルーティング)→同時実行(並列化)→自己改善(リフレクション)→外部接続(ツール)→計画(プランニング)→分担(マルチエージェント)」という流れで眺めると、互いの役割が立体的に見える。
記憶と学習のパターン — エージェントに連続性を与える
基盤系が「1回の実行」を組み立てるのに対し、この系統は時間をまたいだ連続性を与える。
記憶管理は、短期と長期を分けた二層構造でエージェントに記憶を持たせる型だ。短期記憶はLLMの文脈ウィンドウ内で会話の流れを保ち、長期記憶はベクトルストアなどの外部データベースで意味的に検索して過去の知識を呼び戻す。これがないとエージェントは毎回まっさらな状態に戻ってしまう。Google ADKでは会話スレッドを表すSessionと一時データを持つState、長期知識にアクセスするMemoryServiceといった部品でこれを管理する。
ユーザーの好みを覚える、多段タスクの進捗を追う、過去の成功・失敗から学ぶ——いずれも記憶があって初めて成立する。
学習と適応は、新しいデータや経験から振る舞いを自律的に洗練する型だ。強化学習から自己改変まで手法は幅広く、自分のコードを書き換える自己改善型コーディングエージェント(SICA)や、LLMと進化的アルゴリズムを組み合わせて未知の解法を発見するGoogleのAlphaEvolveのような例がある。
事前にプログラムした論理だけでは対応できない、動的で不確実な環境で真価を発揮する。継続的に学ぶことで、エージェントは新しいタスクを習得し、手作業の再プログラミングなしに状況の変化へ適応していく。
自己改変エージェントの具体例は ouroboros解説|自分のコードを書き換える自己改変AIエージェントの仕組みと安全境界 で詳しく扱っています。
MCP(Model Context Protocol)は、LLMと外部システムをつなぐ標準インターフェースの型だ。標準的な通信手段がないと、ツールやデータソースとの統合が毎回個別の作り込みになり、再利用できずスケールしない。MCPはクライアント・サーバーモデルで、サーバーがツール・データ・プロンプトを公開し、クライアントが動的に発見して使えるようにする。
統合をその都度作り込む手間を省き、相互運用可能で再利用できるコンポーネントのエコシステムを育てる。一方、固定的で少数の関数しか使わない単純な用途なら、直接のツール呼び出しで十分なこともある。
目標設定とモニタリングは、明確で測定可能な目標を埋め込み、進捗を継続的に追跡する型だ。目的がないエージェントは単純な反応的タスクしかこなせず、自分の行動が成功に向かっているかも判断できない。そこで具体的な目標を定義し、環境の状態と進捗を目標に照らして監視する仕組みを置く。目標から外れたときに軌道修正できるフィードバックループを作ることで、反応的なエージェントを、人手の介入なしに高レベルの目標を達成できる目標志向の自律システムへ変える。
堅牢性と安全のパターン — 本番で壊れないために
「デモは動くのに本番で壊れる」を防ぐのが、この系統の役割だ。
例外処理と回復は、ツール障害・ネットワーク不調・不正データといった予期せぬ失敗を予測・管理・回復する型だ。実世界で動くエージェントは必ず想定外に出くわす。ツール出力やAPI応答の監視による事前検知、ログ記録・一時的失敗のリトライ・代替手段へのフォールバックといった事後対応、そしてより深刻な事態には安定状態への復帰・計画を見直す自己修正・人間へのエスカレーションまでを体系化する。
これがあるかないかで、エージェントが「壊れやすい試作品」のままか「頼れる本番システム」になるかが分かれる。
ヒューマン・イン・ザ・ループ(HITL)は、重要な判断に人間の監督を組み込む型だ。AIの効率と人間の判断力を組み合わせ、医療・金融・法務のように誤りの代償が大きい領域で信頼性を担保する。すべてを自動化するのではなく、取り返しのつかない操作や曖昧な判断だけを人間に委ね、それ以外はエージェントに任せる。この「どこに人間を挟むか」の設計が、自律性と安全性のバランスを決める。
知識検索(RAG)は、外部データベースから関連情報を取得して回答を事実で裏付ける型だ。ツール利用の一形態だが、「行動」より「知識の補強」に特化している。クエリをベクトルに変換し、意味的に近い文書を検索して、その内容を文脈としてモデルに渡すことで、学習済み知識の鮮度や正確さの限界を外部の一次情報で補う。事実に基づく回答が求められる社内ナレッジ検索や調査タスクで、ハルシネーション(もっともらしい誤り)を抑える定番の手段になっている。
RAGの仕組みを基礎から押さえたい場合は RAG完全ガイド2026:仕組み・実装・ベクトル検索の全体像 が参考になります。
ガードレール(安全パターン)は、エージェントが有害・偏向・不正確な出力を出さないよう多層で防御する型だ。自律性が上がるほど振る舞いは予測しづらくなり、ジェイルブレイクのような攻撃で安全策を回避される恐れもある。そこで入力の検証で悪意あるコンテンツを遮断し、出力のフィルタリングで望ましくない応答を捕まえる。
さらにプロンプトによる行動制約、ツール利用の制限、重要判断での人間監督を組み合わせる。狙いは利便性を削ることではなく、信頼できる予測可能な振る舞いへ導くことだ。チャットボットや金融・医療・法務など、出力が現実に影響する領域では必須になる。
本番運用の最低ライン
・失敗を前提に設計する(例外処理と回復)
・取り返しのつかない操作には人間の承認を挟む(HITL)
・回答は外部の一次情報で裏付ける(RAG)
・入力と出力の両端で危険を遮る(ガードレール)
協調と探索のパターン — 複数エージェントと高度推論
最後は、複数のエージェントや高度な推論を束ねる先端系統だ。
エージェント間通信(A2A)は、異なるフレームワークで作られたエージェント同士を連携させるHTTPベースの標準だ。共通のプロトコルがないと、別々の技術で作られたエージェントの統合は高コストで時間がかかる。A2Aは各エージェントの能力・スキル・通信エンドポイントを記述する「Agent Card」で発見と相互作用を促し、同期・非同期の両方の通信を支える。
Google ADK・LangGraph・CrewAIなど異なる基盤をまたいで、タスクの委譲や情報共有をシームレスに行えるようにし、モジュール式でスケール可能なエージェントの生態系を育てる。
リソース最適化は、計算・時間・コストの消費を賢く配分する型だ。LLMの呼び出しは高価で遅くなりがちで、すべてのタスクに最高性能のモデルを使うのは非効率になる。そこでルーターエージェントが要求の複雑さを分類し、単純な問いには安価で速いモデル、複雑な推論には強力なモデルを割り当てる。批評役のエージェントが応答品質を評価し、振り分けの精度を継続的に高めることもできる。厳しい予算や低遅延が求められる場面、エッジデバイスのような制約下で特に重要になる。
推論技法は、エージェントの「思考」を明示的にする型の総称だ。思考連鎖(CoT)は問題を段階的に分解して考えさせ、思考木(ToT)は複数の解決経路を枝分かれさせて探索する。自己修正は回答を反復的に洗練して精度を高め、ReActは推論と行動を交互に組み合わせて、ツールで情報を集めながら計画を更新する。答えだけでなく「なぜそう考えたか」という過程を見せたいタスクや、一発回答では解けない複雑な問題に向く。
評価とモニタリングは、確率的で非決定的なエージェントの性能を継続的に測る型だ。出力が毎回同じになるとは限らないため、従来のソフトウェアテストだけでは品質を担保できない。正確さ・遅延・トークン消費などの指標を定め、エージェントの推論過程をたどる軌跡(trajectory)分析や、別のLLMに採点させるLLM-as-a-Judgeによる定性評価を組み合わせる。
フィードバックループとレポートを整えることで、A/Bテストやデータドリフト・性能劣化の検知が可能になり、本番投入後も目標との整合を保てる。
優先順位付けは、緊急度・重要度・依存関係・リソースコストを基準にタスクを順位付けする型だ。複雑な環境では取りうる行動が多すぎ、目標も衝突しがちで、リソースは有限になる。明確な基準で各行動を評価し、最も重要で時宜にかなった一手から着手させることで、選択肢の多さに埋もれて動けなくなる状況を避ける。状況の変化に応じて優先度を組み替えられるため、エージェントの振る舞いがより賢く堅牢になる。
探索と発見は、未知の領域を能動的に切り拓く型だ。多くのエージェントは事前に与えた知識の枠内で動くが、それでは「未知の未知」には届かない。このパターンは仮説生成・批判的レビュー・有望概念の発展を別々のエージェントに担わせ、科学的方法を模した協調で新しい知識そのものを生む。解空間がまだ定義されていない科学研究・市場分析・創作のように、最適化を超えて新規性が求められる領域に向く。人手のかかる探索を自動化し、発見のペースを加速する役割を持つ。
ケースで見る — パターンは単体でなく組み合わせて効く
設計パターンは一つずつ使うものではない。実際のエージェントは複数の型を重ねて初めて機能する。「ある製品の競合調査レポートを自動生成する」エージェントを例に、どう組み合わさるかを追ってみよう。
まずプランニングが「競合の特定→各社の情報収集→比較分析→レポート執筆」という手順に目標を分解する。情報収集の段ではツール利用とRAGが外部検索とデータベースから一次情報を集め、複数社を同時に当たるところで並列化が効く。集めた断片は記憶管理が文脈として保持し、ステップをまたいで参照できるようにする。
執筆した下書きはリフレクションが批評・改善し、事実の裏付けが弱い箇所をRAGで補強する。仕上げではガードレールが不適切な表現や誤情報を遮り、最終承認をヒューマン・イン・ザ・ループが担う。全体の進捗は目標設定とモニタリングが追い、外れたら軌道修正する。
- プランニング:目標を実行可能な手順へ分解する
- ツール利用 / RAG / 並列化:外部から一次情報を効率的に集める
- 記憶管理:集めた文脈をステップ間で保持する
- リフレクション:下書きを批評し、品質を引き上げる
- ガードレール / HITL:安全性を担保し、人間が最終承認する
- 目標設定とモニタリング:全体の進捗を追い、逸脱を補正する
このように、1本のエージェントの裏側では7つ前後のパターンが連携している。逆に言えば、どれか一つが欠けると「デモは動くが本番で壊れる」典型的な穴になる。設計パターンを地図として持っておく価値はここにある。
どの設計パターンをいつ使うか
21も並ぶと迷うが、判断軸は「いま困っていること」で引ける。代表的な対応関係をチートシートにまとめた。
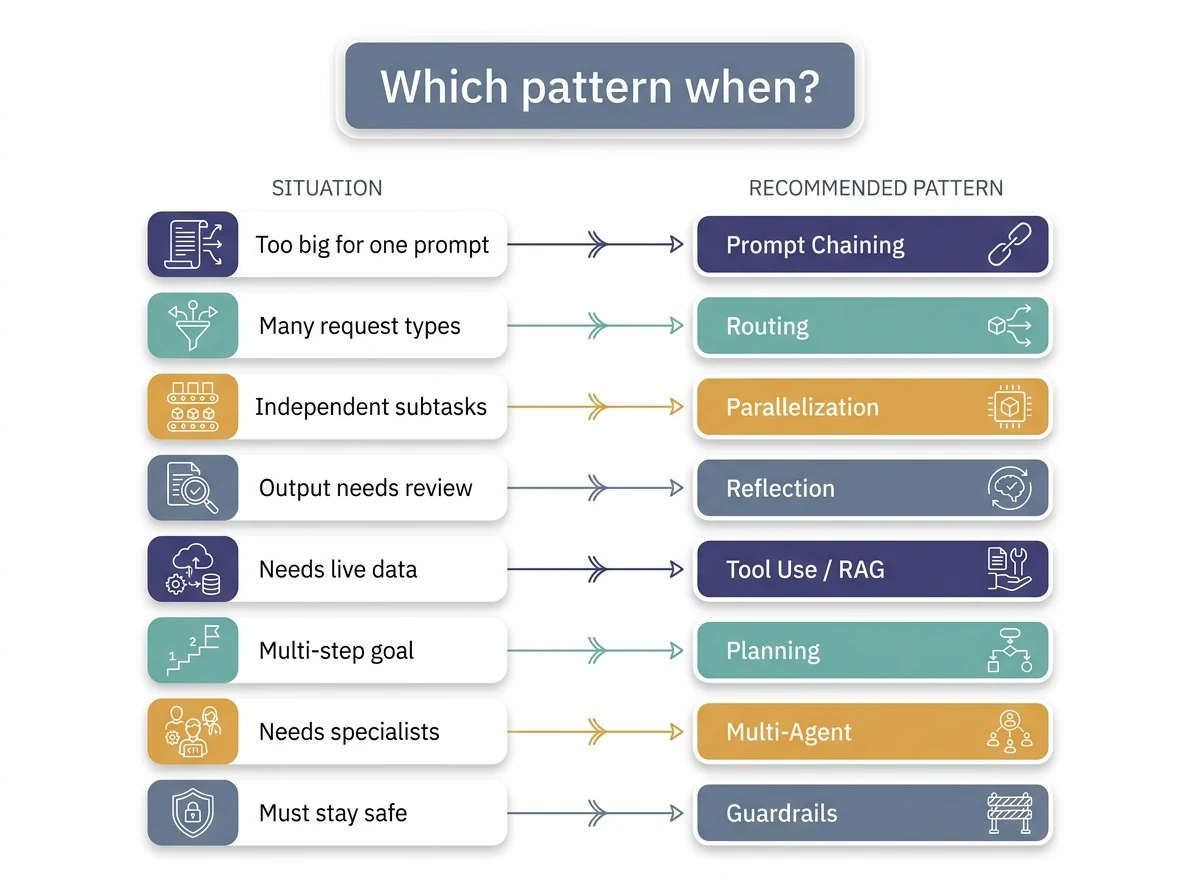
| 困っていること | 当てるパターン |
|---|---|
| 1プロンプトには複雑すぎる | プロンプトチェーン |
| 入力の種類がバラバラ | ルーティング |
| 独立した処理が並んでいる | 並列化 |
| 出力の品質チェックが要る | リフレクション |
| 最新データ・外部行動が要る | ツール利用 / RAG |
| 多段の目標を達成したい | プランニング |
| 専門スキルの分担が要る | マルチエージェント |
| 過去の文脈を覚えたい | 記憶管理 |
| 安全に運用したい | ガードレール / HITL |
選び方の原則:パターンは足し算で増やす。最小構成で動かしてから、信頼性が足りない箇所にだけ堅牢性・安全のパターンを継ぎ足すのが、過剰設計を避ける近道だ。
導入でつまずきやすい落とし穴
設計パターンは万能薬ではない。本書の記述から読み取れる、ありがちな失敗を挙げる。
・最初から全部盛りにする:21パターンを一度に積むと複雑さで自滅する。困りごと起点で必要な型だけを足す
・単一プロンプトに固執する:多段タスクを1プロンプトで押し切ると、指示の見落としや文脈ドリフトが起きる。分割を恐れない
・評価を後回しにする:確率的なエージェントは従来のテストでは守れない。評価とモニタリングを最初から組み込む
・安全層を忘れる:本番では必ず予期せぬ入力が来る。例外処理・ガードレール・HITLを「あとで」にしない
・マルチエージェントを神格化する:分担が要らない問題に複数エージェントを使うと、通信オーバーヘッドだけが増える
・標準化を後回しにする:ツール統合を毎回作り込むと再利用できない。MCPやA2Aのような標準を早めに採り入れると、後の拡張が楽になる
エージェントのコストとコンテキストを抑える具体策は AIエージェントのトークン最適化|コスト削減とコンテキスト管理の5アプローチ2026 にまとめています。
関連概念との違いを整理する
「設計パターン」「フレームワーク」「モデル」は混同されがちだが、役割の層が違う。下表で位置づけを整理する。
| 概念 | 何を指すか | 例 |
|---|---|---|
| モデル | 推論の中核となるLLM本体 | Gemini / Claude / GPT |
| 設計パターン | 課題に対する再利用可能な解法の型 | ルーティング / リフレクション |
| フレームワーク | パターンを実装する道具立て | LangGraph / CrewAI / Google ADK |
| エージェント | 上記を組み合わせて目的を達成するシステム | 調査エージェント / コーディングエージェント |
設計パターンはモデルにもフレームワークにも依存しない。だからこそ、実装を乗り換えても知識が無駄にならない「設計の共通言語」として機能する。
まとめ — パターンは設計判断の地図になる
AIエージェントの良し悪しを決めるのは、単体のモデル性能よりも「どの型を、どこに、どの順で当てるか」という設計判断だ。本書が示す21パターンは、その判断を共通言語にしてくれる地図と言える。
まずは基盤系の7つで骨格を理解し、本番に近づくにつれて記憶・安全・評価のパターンを足していく。困りごとを言語化してから対応する型を引く——この習慣が、壊れにくいエージェントへの最短ルートになる。
21のパターンはどれも「単一プロンプトでは足りない」という同じ出発点から生まれている。複雑さを分割し、外部とつなぎ、自己を検証し、安全に運用する——その積み重ねが、デモ止まりのエージェントと本番で働くエージェントを分ける。本記事の地図を手元に置き、自分のユースケースに必要な型から一枚ずつ引いてみてほしい。
参照ソース
・出典PDF: Antonio Gulli『Agentic Design Patterns: A Hands-On Guide to Building Intelligent Systems』(Google、共有Google Drive版)
・書籍プレプリント: Agentic Design Patterns(Amazon)
・Cloudera(2025年4月): 96% of enterprises are increasing their use of AI agents
・Market.us: Global Agentic AI Market Size, Trends and Forecast 2025–2034