
ローカルLLMを自分のPCで動かす——クラウドにデータを送らず手元でAIを完結させるこの要求が、2026年に入って一気に現実的になった。検索ボリュームは「ローカルLLM」だけで月1.48万件、前年比+96%と倍増している。
背景にあるのは3つの変化だ。オープンウェイトモデルの高性能化(12Bクラスで実用品質)、量子化技術の成熟(Q4_K_MでVRAMを約7割削減)、そしてランタイムの成熟(Ollama・vLLMがOpenAI互換APIを標準装備)。本記事では、2026年6月時点の最新オープンウェイトモデル、ランタイムの選び方、量子化とVRAM別の早見表、そしてAPI課金とのコスト試算までを一気通貫で整理する。
ローカルLLMに特化して解説する本記事の前提知識として、LLM全般の仕組みは LLMとは?仕組みからローカル実行まで徹底解説【2026年完全ガイド】 をご覧ください。
- ローカルLLMのランタイムは用途で選ぶ。CLI/API連携はOllama、本番の高スループットはvLLM、GUI派はLM Studio、RAG込みはAnythingLLM
- VRAM別の上限が明確:8GBで7B、16GBで12〜14B、24GBで32B、48GB以上で70B(いずれもQ4_K_M)。16GB機ならGemma 4 12Bが本命
- コストの分岐点は月間リクエスト量。少量ならクラウドAPI、機密性・大量処理・オフラインが絡むならローカル運用が有利になる
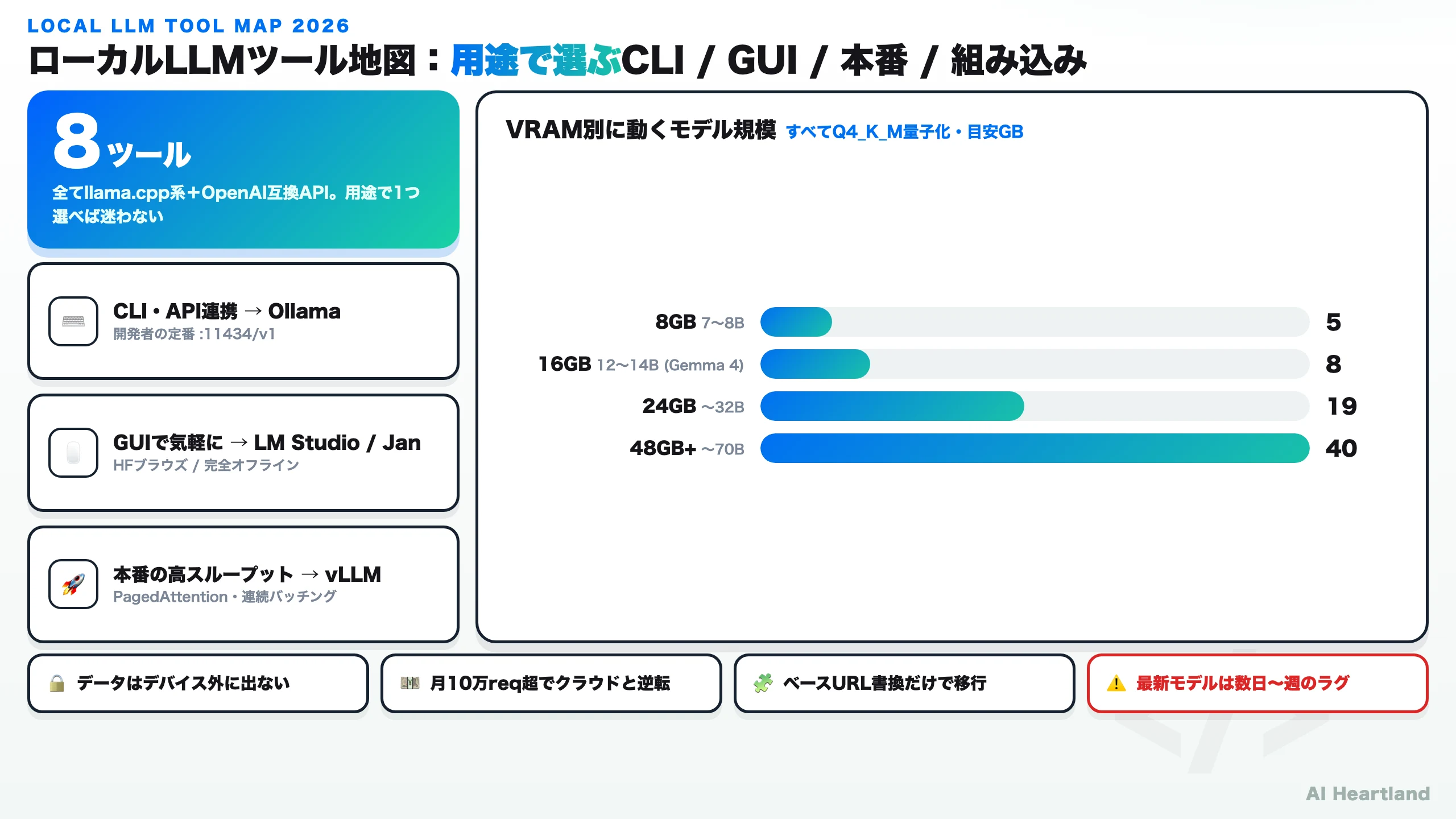
この1枚で、本記事の結論はほぼ言い切れる。ローカルLLMは「どのツールが一番か」ではなく「あなたの用途はCLI連携か・GUIか・本番運用か・組み込みか」で1つに決まり、動かせるモデルの上限は搭載メモリでほぼ機械的に決まる。以下では、この地図の各ブロックを一次ソース(各OSSの公式リポジトリ・公式サイト)で裏取りしながら、①ローカルLLMは結局何ができるのか、②何を解決するのか、③クラウドAPIの何を代替できるのか、の3点に答えていく。
ローカルLLMとは——「デバイスで完結するAI」の本質
ローカルLLMとは、クラウドサーバーへの通信を一切行わず、自分のデバイス(PC・サーバー・スマートフォン)上でLLMの推論処理を完結させる技術・実装の総称だ。
ChatGPTやClaude APIは、質問を入力するとネットワーク越しにOpenAIやAnthropicのサーバーでモデルが動き、回答が返ってくる。ローカルLLMでは、この処理をすべて手元のハードウェアで行う。
| 比較項目 | クラウドLLM | ローカルLLM |
|---|---|---|
| データの扱い | サービス事業者のサーバーへ送信 | デバイス外へ出ない |
| 通信要件 | インターネット必須 | オフラインで動作可能 |
| 処理速度 | サーバー能力に依存(通常高速) | ハードウェアに依存 |
| コスト | 従量課金(使うほど増加) | 電気代+初期ハード代 |
| モデル品質 | GPT-5・Claude Opusなど最上位 | 7B〜70Bクラス(実用品質) |
| セットアップ | APIキー取得のみ | ランタイムのインストールが必要 |
「データがデバイスを出ない」という特性は、単なるプライバシーの話ではない。医療・法律・財務・人事などの機密性の高い業務でも、LLMを活用するための現実的な選択肢になることを意味する。
「ローカルAI」「オンデバイスAI」との違い
ローカルLLMに近い概念として「ローカルAI」「エッジAI」「オンデバイスAI」がある。整理しておこう。
ローカルAIはテキスト生成だけでなく画像生成・音声認識まで含む広い言い方で、エッジAIは工場ラインや車載カメラなど組み込み系も含む。オンデバイスAIはスマートフォン・タブレット向けの表現として使われることが多い。
ローカルLLMはこれらのうち、特に「PC・ワークステーション・サーバー上で動かす汎用的なLLM」を指す用語として定着している。
(GPT・Claude等)"] A --> C["ローカルAI
(広義)"] C --> D["オンデバイスAI
(スマートフォン)"] C --> E["ローカルLLM
(PC・サーバー)"] E --> F["Ollama
vLLM
LM Studio等"] style E fill:#f59e0b,color:#fff style F fill:#10b981,color:#fff
2026年6月時点の最新オープンウェイトモデル
ローカルLLMの実用度を決めるのは、結局「どのモデルを動かせるか」だ。2026年に入ってオープンウェイト(重みが公開され、ローカル実行できる)モデルが急速に充実した。直近の注目株を整理する。
| モデル | 総パラメータ | アクティブ | 文脈長 | ライセンス | ローカル実行 |
|---|---|---|---|---|---|
| Gemma 4 12B | 11.95B | 11.95B | 256K | Apache 2.0 | ◎ 完全オープン |
| Kimi K2.6 | 1T(MoE) | 32B | 256K | 修正MIT | ○ 量子化版で可 |
| gpt-oss:20b | 20B(MoE) | — | 128K | 商用可OSS | ◎ 16GB機で可 |
| gpt-oss:120b | 120B(MoE) | — | 128K | 商用可OSS | △ 96GB+必要 |
| MiniMax M3 | 非公開(前世代229B級) | 非公開 | 1M | 商用条件付き | △ 重み公開待ち |
| MAI-Thinking-1 | 約1T(MoE) | 35B | 256K | 商用(API) | × クラウド限定 |
Gemma 4 12B——16GB機の本命(Apache 2.0)
2026年6月3日に登場したGemma 4 12B(エンコーダレス・マルチモーダルモデル)は、ローカルLLMの最有力候補だ。Apache 2.0で完全にオープンで、商用利用も自由。MMLU Proで77.2%(前世代Gemma 3 27Bの67.6%を大幅に上回る)、GPQA Diamondで78.8%という、サイズに対して破格のベンチマークを叩き出す。
VRAM要件はQ4_K_Mで約7GB、Q8_0で約12.7GB、BF16フル精度でも約23.8GB。16GBのMacBook AirやVRAM 8GBのGPUでも余裕で動く。画像・音声をエンコーダなしで線形射影で扱うマルチモーダル設計のため、ローカルで画像理解まで完結できる点も大きい。
Kimi K2.6——量子化版でローカルに降りてきた1兆パラメータ
Moonshot AIのKimi K2.6(1兆パラメータ・300エージェント並列)は、SWE-Bench Proで58.6%とGPT-5.4(57.7%)を上回るコーディング性能を持つ。総パラメータ1Tの巨大MoEだが、アクティブは32Bに抑えられている。
BF16フル精度では約2TBのメモリが必要で個人環境では非現実的だが、コミュニティが提供するGGUF量子化版(ubergarm・unsloth等)なら、ハイエンドのワークステーションやMac M4 Max 128GB級で動かす道が開けている。修正MITライセンスで、月間アクティブユーザー1億未満・月商2,000万ドル未満なら商用利用も可能だ。
gpt-oss:20b / 120b——Ollamaで即動くOpenAI系OSS
Ollama 0.24でOpenAI Codex CLIをローカルLLMで動かすで詳しく扱ったgpt-oss系は、ollama pull一発で導入できる手軽さが魅力だ。20bは量子化で約13GB(16GB RAM推奨)、128K文脈に対応する。120bは約65GBで96GB以上の大容量メモリ機が前提となる。
MiniMax M3・MAI-Thinking-1——「文脈紹介」のフロンティア勢
MiniMax M3(SWE-Bench Pro 59.0%・MSAアーキ・1M文脈)は、SWE-Bench Pro 59.0%・1M文脈を掲げるオープンウェイト志向のモデルだ。記事公開時点では重みが未公開(10日以内に公開予定とされる)で、公開後はvLLM/SGLangのMSAアーキ対応が前提となる。ローカル候補としては「これから」の位置づけだ。
一方Microsoft MAI-Thinking-1とMAIファミリー7モデルは、AIME 2025で97.0%という推論性能を持つが、重みは配布されずAzure・Foundry経由のAPIのみ。ローカルでは動かせないが、「自前で持つAI」を目指すMicrosoftの戦略として文脈を押さえておく価値がある。
オープンウェイトは学習済みの重みファイルが配布され、ローカルで推論できることを指す。学習データやコードまで含めて公開する「フルオープンソース」とは別概念だ。Gemma 4はApache 2.0で重み公開、Kimi K2.6は修正MIT、gpt-ossは商用可のOSSライセンスと、条件はモデルごとに異なるため利用前に必ず確認したい。
2026年にローカルLLMが実用フェーズへ移行した理由
理由1:12Bクラスで「実用品質」に到達
2025年から2026年にかけて、7B〜14Bパラメータのモデルが急速に進化した。前述のGemma 4 12Bは、わずか12Bで前世代27Bモデルを上回るベンチマークを示す。16GBメモリの一般的なノートPCで、日本語を含む多言語のコーディング・要約・翻訳をこなすモデルが動作する状況は、2023年時点では考えにくかった。
理由2:量子化技術の成熟でVRAM制約が緩和
量子化(Quantization)は、モデルの重みパラメータの精度を16bit→8bit→4bitなどに下げて、ファイルサイズとメモリ使用量を削減する技術だ。Q4_K_M量子化を使うと、7BモデルのVRAMは約4.7GBで済む(BF16フル精度は約14GB)。2026年には品質も向上し、Q4_K_Mで多くのタスクにおいてフル精度との差がほぼわからないレベルに達している。
理由3:ランタイムの成熟でOpenAI互換APIが標準に
OllamaもvLLMもLM Studioも、いずれもOpenAI互換APIを標準で提供するようになった。これは既存のOpenAI向けコードのベースURLを書き換えるだけでローカルに切り替えられることを意味する。LangChain・LlamaIndex・Continueといった主要フレームワークもネイティブ対応し、移行コストが劇的に下がった。
主要ローカルLLMランタイム比較——選択の判断軸
ローカルLLMのランタイムは「どのレイヤーを担うか」で性格が分かれる。一言でいうと、llama.cppという推論エンジンの上に何を乗せるかで差別化されている。
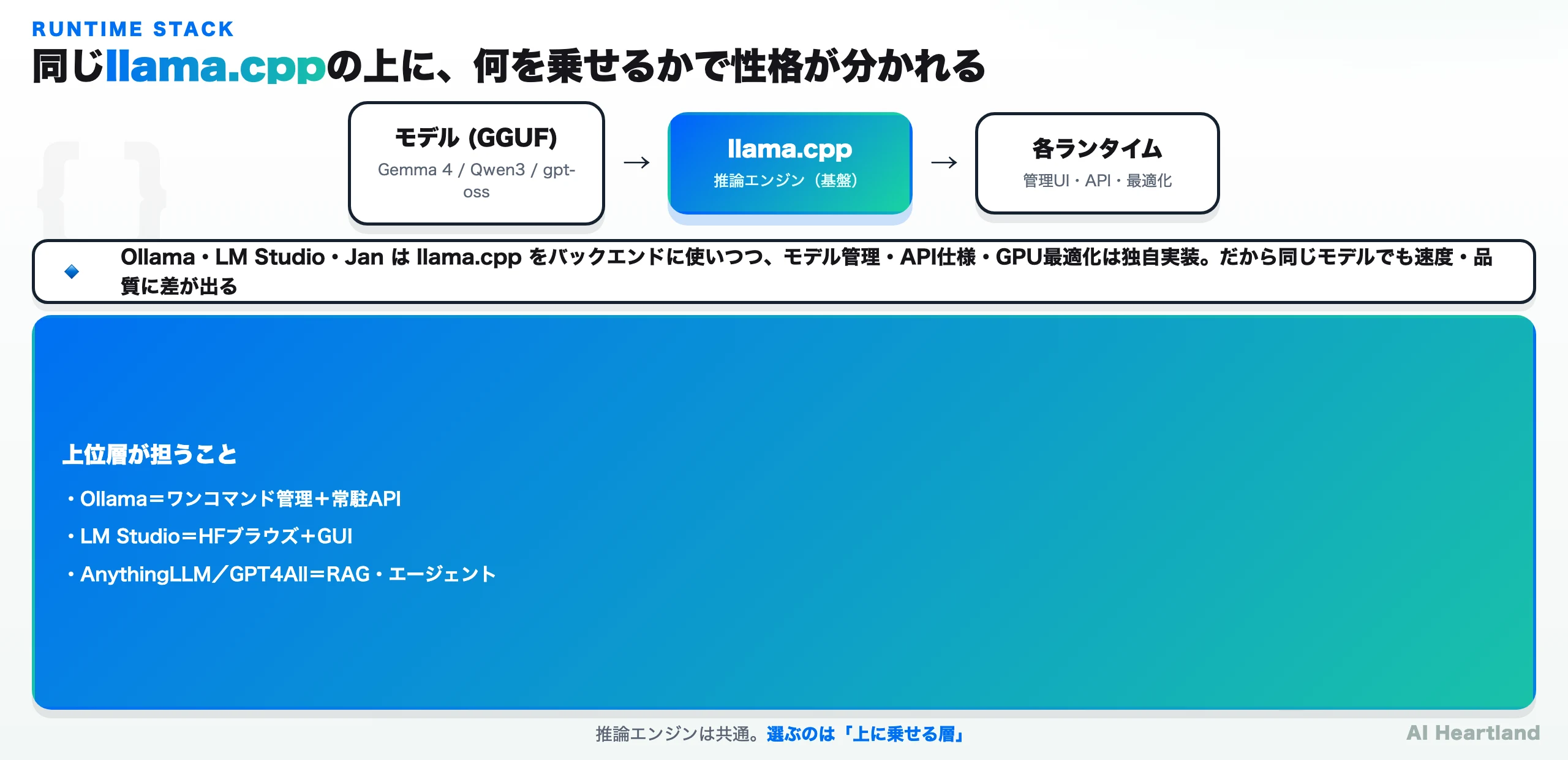
この構造を押さえると「どれができて何を解決するのか」が一目で分かる。共通の推論エンジンが「動かす」を担い、上位のランタイムが「使いやすくする/連携する/守る」を担う。だから選定は機能比較ではなく、自分がどの上位層を必要とするかの一択に落ちる。
| ツール | 対象ユーザー | UI | エンドポイント | 特徴 |
|---|---|---|---|---|
| Ollama | 開発者 | CLI | :11434/v1 |
API連携・モデル管理が容易。常駐サービス向き |
| vLLM | 本番運用 | API | OpenAI互換 | PagedAttentionで高スループット |
| LM Studio | 一般ユーザー | GUI | :1234/v1 |
HFブラウザ付き、直感操作 |
| Jan | プライバシー重視 | GUI | OpenAI互換 | 完全オフライン設計 |
| AnythingLLM | RAG活用者 | GUI | (上記を利用) | RAG・マルチエージェント・社内文書 |
| GPT4All | 文書活用者 | GUI | OpenAI互換 | LocalDocs(RAG)内蔵 |
| llama.cpp | 上級者・組み込み | CLI | サーバー内蔵 | 最軽量・高カスタマイズ性 |
| Lemonade | AMD/Qualcomm環境 | GUI+API | OpenAI互換 | NPU+GPUハイブリッド・マルチモーダル |
Ollama——開発者のデファクトスタンダード
Ollamaは、Dockerライクなモデル管理とOpenAI互換APIの完成度で開発者の定番になっている。ollama pull gemma4:12bの1コマンドでモデルを取得し、すぐにhttp://localhost:11434/v1でOpenAI互換APIが立ち上がる。LangChain・LlamaIndex・AnythingLLM・Continueはすべてネイティブサポートしており、既存のAIアプリをそのままローカル向けに切り替えられる。
弱みはGUI不在で、モデル管理がコマンドライン前提な点。常駐サービス(systemd・Docker・リモートサーバー)として運用するなら最右翼だ。
# Ollamaの基本操作
ollama pull gemma4:12b # モデルをダウンロード
ollama run gemma4:12b # 対話モードで起動
ollama serve # APIサーバーとして起動(localhost:11434)
vLLM——本番の高スループット推論サーバー
vLLM(高速推論サーバー)は、公式が「state-of-the-art(最先端)のサービングスループット」を掲げる本番向け推論サーバーだ。中核はKVキャッシュ(Attentionのkey/value)を効率管理するPagedAttentionで、これに連続バッチング(continuous batching)・チャンク化プリフィル・プレフィックスキャッシュを重ねて、複数ユーザーの同時リクエストを高い占有率でさばく。Ollama系が「1人が快適に使う」設計なのに対し、vLLMは「多数の同時アクセスを高スループットで裁く」設計で、GPU複数枚のワークステーションや社内サーバーでのプロダクション運用の本命になる。NVIDIA・AMDのGPUに加え、Google TPU・Intel Gaudi・Apple Siliconなど幅広いハードウェアに対応する。
LM Studio——GUIで始めたいユーザーの第一選択
LM StudioはHugging Faceのモデルカタログを直接ブラウズし、量子化レベルを選んでワンクリックでダウンロード・実行できるデスクトップアプリだ。内蔵チャットUIとOpenAI互換のローカルAPIサーバー(http://localhost:1234/v1)を兼ね備える。アプリを開いている間だけ動く設計で、ラップトップでローカルLLMを気軽に試したいユーザーに最適だ。
Jan——プライバシーを絶対条件とするユーザー向け
JanはElectronベースのデスクトップアプリで、完全オフライン動作を保証する設計思想が特徴だ。モデルの読み込みから推論まで、ネットワーク接続が一切不要。起動時のアナリティクス送信もデフォルトでオフにする。医療・法律・政府機関など、データ漏洩に厳しい要件がある環境での採用実績が多い。
AnythingLLM——RAGとエージェントのオーケストレーション層
AnythingLLMは推論エンジンではなく、その上位のオーケストレーション層だ。モデル実行自体はOllamaやLM Studioに委譲し、RAG・マルチステップエージェント・ネイティブツール呼び出し・マルチユーザーワークスペースに注力する。社内文書を外部に出さずにナレッジ基盤を作りたい場合の中核になる。
GPT4All——ゼロ設定のローカルRAG
GPT4Allは「LocalDocs」機能が差別化要因だ。PDFやWord文書をフォルダにドロップするだけで、ローカル埋め込みモデルが自動でインデックスを作成し、会話中に関連箇所を検索・引用する。設定ゼロでローカルRAGが完成する点は他にない強みで、非エンジニアが社内文書をもとに質問応答したい場合に向く。
llama.cpp——すべての基盤となるエンジン
上記の多くのツールはllama.cppをバックエンドに使う。直接使うメリットは、余計なレイヤーがなく最軽量で、CPU/GPUの細かいパラメータ(スレッド数・GPUレイヤー数)を完全に制御できる点だ。組み込みや本番の最適化チューニングが必要な場面で有力になる。分散推論(複数台で1モデルを動かす)に特化したDistributed Llamaも、メモリ合算で大型モデルを動かす選択肢だ。
各ツールはllama.cppをバックエンドに使いながらも、モデル管理・API仕様・GPU最適化のコードはそれぞれ独自に実装している。そのため同じモデルでもツールによって速度や品質に差が出る。llama.cppの最新リリースを取り込む開発サイクルも各ツールで異なる点に注意したい。
量子化とVRAM——Q4_K_M / Q6_K / Q8_0 / BF16の最新目安
ローカルLLMで最初につまずくのが「自分のマシンでどのサイズが動くか」だ。鍵は量子化レベルとモデルパラメータ数の掛け算で決まる。おおまかな目安は次のとおりだ。
・Q4_K_M:パラメータ数 × 約0.6GB。品質と容量のバランスが最も良く、ローカルの標準
・Q6_K:パラメータ数 × 約0.8GB。Q4で品質劣化が気になる場合の中間解
・Q8_0:パラメータ数 × 約1.1GB。フル精度にほぼ並ぶ品質、容量は約半分
・BF16:パラメータ数 × 約2GB。フル精度。学習・検証用途や品質最優先時に
これを主要サイズに当てはめると、必要メモリの早見表は以下になる(推論時のKVキャッシュ・文脈長で数GBの上乗せが発生する点に注意)。
| モデル規模 | Q4_K_M | Q6_K | Q8_0 | BF16 |
|---|---|---|---|---|
| 7B | 約4.7GB | 約6GB | 約7.5GB | 約14GB |
| 12〜13B | 約7.9GB | 約11GB | 約13GB | 約24GB |
| 32B | 約19GB | 約27GB | 約35GB | 約64GB |
| 70B | 約40GB | 約55GB | 約78GB | 約140GB |
たとえばGemma 4 12BはQ4_K_Mで約7GB、Q8_0で約12.7GB、BF16で約23.8GBとこの目安にきれいに乗る。Q4_K_Mから始め、品質に不満があればQ6_K・Q8_0へ上げるのが定石だ。
日常のチャット・要約・コード補完:Q4_K_Mで十分(劣化はほぼ体感できない)
精密なコーディング・長文の論理推論:Q6_KまたはQ8_0で安全マージンを
ファインチューニング・品質ベンチ:BF16フル精度を使う
迷ったらQ4_K_M。容量に余裕があるならQ8_0が品質と容量の堅実な落としどころ
VRAM別おすすめ早見表(4GB / 8GB / 16GB / 24GB / 48GB)
手持ちのGPU VRAM、またはMacのユニファイドメモリ容量から逆算して、現実的に動くモデルを示す。すべてQ4_K_M前提だ。
| 搭載メモリ | 動かせる規模 | おすすめモデル例 | 想定用途 |
|---|---|---|---|
| 4GB | 1〜3B | Llama 3.2 1B/3B、Qwen3 1.7B | 軽量な補完・分類・組み込み |
| 8GB | 7〜8B | Llama系8B、Qwen3 8B、Mistral 7B | 日常チャット・要約・翻訳 |
| 16GB | 12〜14B | Gemma 4 12B、Qwen3 14B | 本格的なテキスト生成・コーディング |
| 24GB | 〜32B | gpt-oss:20b、Qwen3 32B、Gemma 4 BF16 | 高品質生成・RAG・エージェント |
| 48GB以上 | 〜70B | 70Bクラス、Kimi K2.6量子化版 | 研究・最高品質・複数モデル同時 |
16GBで動くモデル7選
最も需要が大きい「16GB機(MacBook Air・VRAM 16GBのGPU)で動くモデル」を具体的に挙げる。いずれもQ4_K_Mで余裕を持って動作する。
・Gemma 4 12B(Q4で約7GB):マルチモーダル対応、Apache 2.0で最有力
・Qwen3 14B(Q4で約9GB):日本語・コーディングが強い
・Llama系 8B(Q4で約5GB):エコシステムが豊富で安定
・Mistral 7B系(Q4で約4.5GB):RAG用途に定評
・gpt-oss:20b(量子化で約13GB):16GBでぎりぎり、128K文脈
・Phi系 14B(Q4で約9GB):推論タスクのコスパが高い
・Swallow / LLM-jp(7〜13B):日本語特化、国産モデル
VRAM 16GBはローカルLLMの「快適に使える」最初のラインだ。12B級が余裕で動き、文脈長を伸ばしてもKVキャッシュに耐えられる。
Mac Apple Silicon と Windows + NVIDIA——ハードウェア別の勘所
Mac(Apple Silicon)——ユニファイドメモリが効く
Apple Siliconはユニファイドメモリ採用で、CPUとGPUがメモリを共有する。つまり搭載メモリ容量がそのままモデルサイズの上限になる。M4 Maxはメモリ帯域546GB/sを誇り、128GB構成なら70BモデルをQ4_K_Mで20〜28トークン/秒で動かせる。
Apple純正のMLXフレームワークはユニファイドメモリをネイティブに使い、同じMacでllama.cpp/Ollamaより10〜25%高速な推論を出す。16GBのMacBook AirならGemma 4 12B(Q4)が快適に動き、64GB以上のMac StudioならQ8_0や30B級まで視野に入る。LM StudioとOllamaはMLXバックエンドにも対応しつつある。
Windows + NVIDIA RTX 40/50シリーズ——CUDAエコシステムの王道
NVIDIA GPUはCUDA対応ツールが圧倒的に多く、ローカルLLMの王道だ。VRAM容量がモデルサイズの直接的な制約になる。
・RTX 4060 Ti / 5060(16GB):12〜14B(Q4)が快適。入門の鉄板
・RTX 4080 / 5070 Ti(16GB):同上+高速。文脈長を伸ばす余裕
・RTX 4090 / 5090(24〜32GB):32Bクラスまで。本格運用の主力
・複数枚構成(48GB以上):70Bクラス、vLLMでのマルチユーザー本番
AMD Radeon(RX 7900 XTX等)はROCm/HIP対応ツール(Ollama・Lemonade・vLLM)を選べば同等の性能を発揮するが、CUDA前提のツールでは動かないことがあるため、対応状況の確認が必要だ。
GPU・CPU・NPU推論の違い——どのプロセッサで動かすか
ローカルLLMを動かす際の根本的な問いが「どのプロセッサで動かすか」だ。3者の特性を理解すれば、ハードウェア選択と設定の最適解が見えてくる。

GPU推論——速度最優先の選択肢
GPUは数千コアの並列演算と高帯域メモリを持ち、LLMの行列演算に最適だ。VRAM容量がモデルサイズの直接的な制約になる。コーディング・RAG・本番APIなど速度が効く用途では第一選択になる。
CPU推論——GPUなし環境での現実解
CPUのみの場合、推論速度はGPUの10〜20分の1になるが「動かない」わけではない。llama.cppはAVX2/AVX-512命令を活用して最適化されており、Core i7/i9やRyzen 7/9なら7Bモデルを1〜3トークン/秒で生成できる。さらにBitNet(1ビット量子化)は重みを1ビットまで削減してCPU推論を大幅に高速化し、CPU推論の限界を押し広げている。
NPU推論——AI PCの省電力フロンティア
NPU(Neural Processing Unit)は行列演算に特化した専用チップで、推論時のエネルギー効率がGPUより35〜60%優れる。AMD Ryzen AI 300/400シリーズ、Qualcomm Snapdragon X、Intel Core Ultraが代表格だ。対応モデル・フォーマット(ONNX等)が限定的でOS依存があるという制約はあるが、長時間稼働するエージェントや常時接続型のアシスタントでバッテリー寿命が問われる場面では明確なアドバンテージを持つ。
| 比較項目 | GPU | CPU | NPU |
|---|---|---|---|
| 推論速度 | ◎ 最速 | △ 低速 | ○ 中〜高速(モデル依存) |
| 消費電力 | × 大きい | ○ 中程度 | ◎ 最小 |
| 対応モデル | ◎ 全形式 | ○ GGUF等 | △ ONNX等限定 |
| 初期コスト | × GPU代 | ○ 追加投資なし | ○ AI PCに内蔵 |
| 汎用性 | ○ 高い | ◎ 最高 | △ 特定用途向け |
| 主な用途 | 開発・本番 | 軽量タスク | 常時起動・モバイル |
Lemonade——AMD/Qualcommが本気で作ったローカルAIサーバー
NPU活用を一歩進めたいAMD環境のユーザーには、Lemonadeが有力だ。コミュニティが開発しAMDエンジニアが最適化を担うオープンソースのローカルAIサーバーで、公式は「クラウドAPIと同じことを100%無料・プライベートに」と掲げる。Ryzen AIに載るXDNA2 NPUを活用し、Ryzen AI 300/400シリーズ(Strix Point・Strix Halo)でNPU+GPUのハイブリッド推論を行う。
ハイブリッドモードでは、入力トークンを並列処理するプリフィルをNPUが、1トークンずつ生成するデコードをGPUが担当し、それぞれの強みを活かす。CPU単独より3〜5倍の応答速度向上と電力削減が報告されている。
(Ryzen AI) participant G as GPU/iGPU
(Radeon) U->>L: プロンプト送信 L->>N: プリフィル処理
(入力トークンの並列計算) Note over N: NPUの並列演算で
高スループット処理 N->>L: KVキャッシュ生成完了 L->>G: デコード処理
(次トークン逐次生成) Note over G: GPUのメモリ帯域で
トークン生成を高速化 G->>L: トークン生成 L->>U: 応答ストリーミング
Lemonadeはテキスト生成(GGUF・ONNX・独自のFLM)に加え、画像生成(Stable Diffusion)・音声認識(Whisper)・音声合成(TTS)をワンインストールで提供する。連携面が強力で、http://localhost:13305/v1 を叩けばOpenAI・Anthropic・Ollama互換APIとして既存アプリからそのまま利用できる。NPU推論はWindows/Linuxの両方に対応するが、一部の推論エンジンにはプラットフォーム制約があるため、NPUを本格活用する場合は対応状況の確認が必要だ。
ローカルLLM × エージェント——自前のAIエージェントを動かす
2026年のローカルLLM活用で最も伸びている領域が、ローカルモデルでAIエージェントを動かす使い方だ。エージェントはツール呼び出しを何度も繰り返すため、API課金が積み上がりやすい。ここをローカルに置き換えると、レート制限もトークン課金も気にせず試行錯誤できる。
実際、Ollama 0.24でOpenAI Codex CLIをローカルで動かす構成は、コーディングエージェントをローカルLLMで完結させる代表例だ。gpt-oss:20bをOllamaで立て、Codex CLIから叩くことで、APIキー不要・オフラインのコーディング支援が成立する。
エージェント用途でローカルモデルを選ぶときの勘所は3つある。
・ツール呼び出し(function calling)対応:Gemma 4・Qwen3・gpt-oss系は構造化出力に対応
・十分な文脈長:エージェントの履歴が膨らむため128K以上が望ましい
・安定したJSON出力:ツール引数を壊さない再現性が必須(Q4でも実用上は問題ない)
大規模なマルチエージェントの協調についてはKimi K2.6の300エージェント並列の事例が参考になる。ローカルで小さく試し、スケールが必要になったらクラウドAPIに逃がす——という段階設計が現実的だ。
コスト試算:API課金 vs ローカル運用
「結局どちらが安いのか」は、月間のトークン消費量で決まる。具体的に試算してみよう。
前提として、1リクエストあたり入力500トークン・出力500トークン、Claude Sonnet級のクラウドAPI(入力$3/M・出力$15/M=1リクエスト約$0.009)と、安価なオープンモデルAPI(Kimi K2.6の$0.60/M入力・$2.50/M出力=1リクエスト約$0.0016)、そしてローカル運用(電気代のみ)を比べる。
| 月間リクエスト | クラウドAPI(高品質) | 安価モデルAPI | ローカル運用 |
|---|---|---|---|
| 1万回 | 約$90(約1.4万円) | 約$16(約2,400円) | 電気代+初期ハード |
| 10万回 | 約$900(約13万円) | 約$160(約2.4万円) | 電気代+初期ハード |
| 100万回 | 約$9,000(約135万円) | 約$1,600(約24万円) | 電気代+初期ハード |
ローカル運用の初期コストは、VRAM 16GBのGPU(RTX 4060 Ti 16GB等)で約7〜8万円、Mac M4 Max 128GBで約60万円。電気代は350Wを24時間×30日フル稼働しても月数千円程度だ。
ここから読み取れる分岐点はシンプルだ。月10万リクエストを超え、かつ高品質モデルを使い続けるなら、半年〜1年でローカルハードの初期投資を回収できる。逆に月数千リクエスト程度なら、ハードの減価償却を考えるとクラウドAPIの方が安い。
ローカル運用は電気代以外に、モデル更新の手間・障害対応・スループットの上限(同時リクエスト数)という運用コストが乗る。逆にクラウドAPIは、機密データの社外送信リスクという「金額に出ないコスト」を抱える。純粋な金額比較だけで判断しないことが重要だ。
用途別おすすめ構成——目的から逆算するツール選択
典型的な4つのユースケースから、最適な構成を提示する。
パターン1:開発者がAPIサーバーとして使う
ツール:Ollama(メイン)+ LM Studio(モデル評価用)/モデル:Gemma 4 12B(日常)、gpt-oss:20b(コーディング)/連携:LangChain・LiteLLM・Continue。OLLAMA_HOST=0.0.0.0で他マシンからもAPIアクセス可能にでき、OpenAI API呼び出しと同一コードのままローカルに切り替えられる。
パターン2:本番で複数ユーザーにサービスする
ツール:vLLM(最優先)/モデル:Gemma 4 12B〜32Bクラス/環境:NVIDIA/AMD GPU複数枚。PagedAttentionと連続バッチングで、同時アクセスを高スループットでさばける。社内チャットボットやプロダクションAPIの土台に向く。
パターン3:社内文書・PDFを大量に使いたい
ツール:GPT4All(小規模・非エンジニア向け)またはAnythingLLM + Ollama(大規模)/モデル:Mistral 7B(RAGに強い)またはQwen3 14B(日本語強化)/注意:日本語文書はチャンクサイズの最適化が必要(500〜800トークン推奨)。機密文書を外部送信せずにRAGを組める点が最大の価値だ。
パターン4:プライバシー最優先でセンシティブ情報を扱う
ツール:Jan(デスクトップ)+ llama.cpp(バックエンド)/ネットワーク:完全オフライン(ファイアウォールでアウトバウンド遮断)/モデル:あらかじめダウンロードした量子化モデルを隔離環境に持ち込む。医療・法律・HRなどコンプライアンス要件が厳しい組織での採用実績がある。
提供する?"} B -->|Yes| C["vLLM
(高スループット)"] B -->|No| D{"エンジニアか?"} D -->|Yes| E{"他のアプリと連携が必要?"} E -->|Yes| F["Ollama
(API連携)"] E -->|No| G["llama.cpp
(最軽量)"] D -->|No| H{"文書検索RAGが必要?"} H -->|Yes| I["GPT4All / AnythingLLM
(RAG)"] H -->|No| J{"プライバシーを最重視?"} J -->|Yes| K["Jan
(完全オフライン)"] J -->|No| L["LM Studio
(GUI・初心者向け)"] style C fill:#22c55e,color:#fff style F fill:#6366f1,color:#fff style I fill:#10b981,color:#fff style K fill:#8b5cf6,color:#fff style L fill:#ec4899,color:#fff
クラウドAPIとの使い分け判断フロー
ローカルLLMが「常に正解」ではない。判断軸を整理する。
ローカルLLMが有利なのは、機密データを扱う業務(社外送信が許可されないデータ)、高頻度・大量呼び出し(月10万リクエスト超でコストが逆転)、オフライン環境が必要な用途(工場・船上・地下施設)、レイテンシの完全制御(ネットワーク遅延ゼロ)の4ケースだ。
クラウドAPIが有利なのは、最高品質が必要(Claude Opus・GPT-5などフロンティアモデル)、セットアップゼロで即起動(PoC段階)、GPUなし環境でのマルチモーダル、最新モデルへの即時アクセスの4ケース。新モデルのリリース当日に使えるクラウドAPIに対し、ローカルは量子化・最適化のラグ(数日〜数週間)が出る。
| 判断基準 | ローカルLLM | クラウドAPI |
|---|---|---|
| データの機密性 | ◎ 外部漏洩ゼロ | × サービス規約に依存 |
| 出力品質 | ○ 中〜高(モデル依存) | ◎ フロンティアモデル利用可 |
| ランニングコスト | ◎ 電気代のみ | × 従量課金 |
| セットアップ工数 | △ 初期設定が必要 | ◎ APIキーのみ |
| オフライン対応 | ◎ 完全対応 | × 不可 |
| 最新モデル即時利用 | △ 数日〜週のラグ | ◎ リリース即日 |
| スケールアウト | △ ハードウェア増強が必要 | ◎ API呼び出し増加のみ |
ハイブリッド運用が現実解
2026年のベストプラクティスは「ローカル vs クラウド」の二択ではなく、タスクの性質に応じた使い分けだ。
・機密文書の要約・分類:ローカルLLM(プライバシー確保)
・最終成果物の品質向上:クラウドAPI(最高品質)
・大量の前処理・フィルタリング:ローカルLLM(コスト削減)
・ユーザー向け対話インターフェース:クラウドAPI(低レイテンシ・高品質)
LiteLLMのようなゲートウェイを挟めば、同一コードからローカルとクラウドを切り替えられる。まずローカルで小さく検証し、品質や規模が必要な部分だけクラウドへ逃がす設計が、2026年の合理解だ。
よくある質問
Q. ローカルLLMで日本語はどこまで使えますか?
2026年時点で日本語は実用レベルに達している。Gemma 4 12B、Qwen3、Llama系は日本語で高品質な応答を返す。特にQwen3系は日本語の言い回しと漢字変換の精度が高く、国産モデル(Swallow・LLM-jp等)と比べても遜色ない。ただし俳句・敬語の細かいニュアンス・方言など日本語特有の表現では、Claude OpusやGPT-5などのクラウドAPIが依然優位だ。
Q. Ollamaをサーバーに立ててチーム全員で使えますか?
可能だ。OLLAMA_HOST=0.0.0.0 ollama serveで全インターフェースにバインドすれば社内ネットワークで共有できる。ただし認証機能が標準装備されていないため、本番運用ではNginxリバースプロキシ+Basic認証の追加が推奨される。複数ユーザーの同時利用が前提なら、最初からvLLMを選ぶ方がスループットで有利だ。
Q. ローカルLLMのセキュリティリスクはありますか?
モデルファイル自体がマルウェアになりうるリスクに注意が必要だ。Hugging Faceのセーフテンサー形式(.safetensors)は実行コードを含まない安全なフォーマットだが、古いPickleベースの.ptファイルは任意コード実行のリスクがある。GGUFは構造的に安全だが、出所不明のモデルのダウンロードは避けるべきだ。
Q. ローカルLLMはファインチューニングも可能ですか?
推論はローカルで問題ないが、ファインチューニング(学習)はGPUのVRAM要件が大幅に増える。7Bモデルのフルファインチューニングには80GB以上が必要で、コンシューマー向けGPUでは不可能だ。QLoRAなど効率的な手法を使えば20〜24GB程度まで圧縮できる。多くのケースでは、ファインチューニングはクラウドGPUで行い、完成したモデルをローカルで動かす分業が現実的だ。
関連記事
同じクラスタの入門ピラーと実践衛星をまとめて読むと、点が線につながります。
・Ollama入門2026|Mac/Windows/Linuxでローカル大規模言語モデルを動かす完全ガイド
・Ollamaとllama.cppの違い2026|ローカルLLMはどちらで動かすべきか徹底比較
・Ollama API完全ガイド2026|REST・OpenAI互換・Python/JSでローカルLLMを叩く
参照ソース
- GitHub - ollama/ollama — Ollama公式リポジトリ(OpenAI互換API)
- GitHub - vllm-project/vllm — vLLM公式リポジトリ(PagedAttention)
- GitHub - lemonade-sdk/lemonade — Lemonade公式リポジトリ(AMD NPU対応)
- GitHub - ml-explore/mlx — Apple純正MLXフレームワーク
- Ollama vs vLLM vs LM Studio: Best Way to Run LLMs Locally in 2026 — ランタイム比較
- Best Mac for Local AI 2026: Apple Silicon Buying Guide — Apple Silicon別のVRAM/性能検証
- Mac M4 Max Local LLM 70B Benchmark — M4 Max 70B Q4_K_M実測
- Ollama vs LM Studio vs vLLM vs llama.cpp vs MLX 2026 — 量子化別VRAM目安





