この記事ではLLMに特化して解説します。LLM全般は LLMとは?仕組みからローカル実行まで徹底解説【2026年完全ガイド】 をご覧ください。
概要
Microsoft Lidaはテーブル形式のデータセットに対し、自然言語による指示で自動的にビジュアライゼーションとグラフを生成するツール。大規模言語モデル(LLM)を活用してユーザーの意図を解釈し、適切なグラフタイプの選択からレンダリングまでを一貫処理。データ分析プロセスの初期段階で、非技術者も技術者も同じ速度でデータを探索できる環境を実現する。
Lidaは「LIDA: A Tool for Automatic Generation of Grammar-Agnostic Visualizations and Infographics using Large Language Models」という論文に基づいて設計されており、特定のビジュアライゼーションライブラリに依存しないGrammar Agnosticな設計が技術的な特徴。matplotlib、seaborn、altairなど複数のバックエンドを切り替えられる。
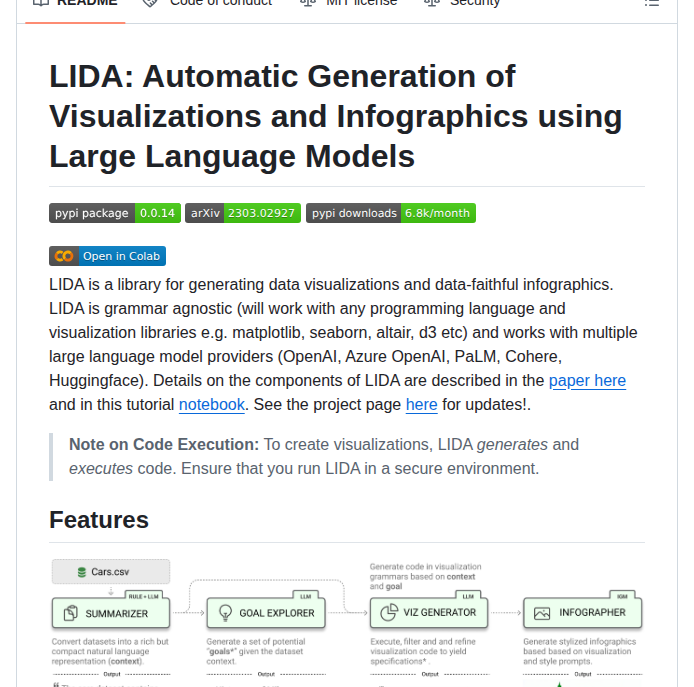
LIDAの処理フロー
CSV / JSON / Excel"] --> B["SUMMARIZER
データ構造を要約・メタ情報抽出"] B --> C["GOAL EXPLORER
分析目標の候補を自動生成"] C --> D["VISGEN
ビジュアライゼーションコード生成"] D --> E["コード実行
matplotlib / seaborn / altair / d3"] E --> F["グラフ出力
インタラクティブ探索"] F -->|"追加質問・修正指示"| C D --> G["INFOGRAPHER
インフォグラフィック生成(ベータ)"]
Lidaのパイプラインは4つのコンポーネントで構成される。SUMMARIZERがデータの統計的特性を要約し、GOAL EXPLORERが分析目標を自動提案、VISGENがグラフコードを生成・実行する。ユーザーは自然言語でフィードバックを返し、ループ的にグラフを改善できる。
主な機能
- 自然言語ベースのグラフ生成:「前年比の増減を示すグラフ」といった日本語指示から最適なビジュアライゼーション自動構築
- ビジュアライゼーション推奨機能:データに基づいた複数の視点からのグラフ提案により、ユーザーが最適なものを選択
- インタラクティブな探索ループ:生成されたグラフに対して追加質問でさらに掘り下げ、対話形式でインサイトを抽出
- 複数フォーマット対応:CSV・JSON・Excel等様々なデータソースに対応
- LLMプロバイダーの選択肢:OpenAI・Azure OpenAI・ローカルLLMなど複数のバックエンドに対応
- プログラマティックAPI:Pythonライブラリとして他のデータパイプラインに組込可能
- ビジュアライゼーション編集・説明機能:生成後のグラフをさらに調整・解釈する機能を備える
- インフォグラフィック生成:複合的なビジュアルコンテンツの生成に対応(ベータ版)
技術スタック
| 項目 | 詳細 |
|---|---|
| 言語 | Python |
| ビジュアライゼーション | matplotlib、seaborn、altair、d3(Grammar agnostic設計) |
| LLM統合 | OpenAI、Azure OpenAI、PaLM、Cohere、Huggingface |
| データ処理 | Pandas、NumPy |
| UI | オプションのウェブアプリケーション搭載 |
導入方法
pipコマンドでインストール:
pip install lida
OpenAI APIキーを環境変数に設定:
export OPENAI_API_KEY="your-api-key"
Pythonスクリプトの基本的な使用例:
from lida import Manager, llm
lida = Manager(text_gen=llm("openai"))
lida_summary = lida.summarize("data.csv")
charts = lida.visualize(summary=lida_summary, query="売上の推移を表示")
Azure OpenAIを使う場合はエンドポイント情報を別途設定する。またはコード内で明示的にキーを指定することも可能。
競合との違い
Tableau/Power BI:これらは高度なビジネスインテリジェンスツールで、複雑なダッシュボード構築が可能だが、セットアップと学習曲線が急。Lidaはデータソースを指定して日本語で質問するだけで即座に試験的グラフを生成でき、BI導入前の探索段階に適した軽量性が特徴。
| 比較軸 | Lida | Tableau/Power BI | ChatGPT + 手作業 |
|---|---|---|---|
| セットアップ | pip install のみ | 専用アプリ導入必須 | アカウントのみ |
| 技術要件 | 低(自然言語で操作) | 中〜高 | 中(コード記述が必要) |
| 反復速度 | 高(対話ループ) | 中 | 低 |
| 本番ダッシュボード | 不向き | 得意 | 不向き |
| LLMバックエンド | 選択可能 | 不可 | 固定(ChatGPT) |
ChatGPT/Claude+手作業グラフ化:LLMにデータの説明を与えて人間が可視化コードを書く方法もあるが、実装に技術知識が必須で反復が遅い。Lidaはコード生成と実行を完全自動化しており、対話速度が段違い。
Vega-Lite仕様書手作業:宣言的ビジュアライゼーション言語として優れているが、JSON記法習得が必要。Lidaは自然言語で意図を伝えるだけでVega-Lite相当の結果を得られる。
こんな人におすすめ
データサイエンティストが新しいデータセットを受け取った際、まず「どんな傾向があるか」を素早く掴むフェーズでLidaが力を発揮する。複数の視点からグラフを自動生成し、手動でコードを書く前の仮説出しが数分で完了する。 【非エンジニアによるセルフサービス分析】
マーケターや営業担当がExcelデータを自分でグラフ化したい場面。Pythonの知識がなくても「月別の売上を棒グラフで見せて」という日本語指示だけで操作できる。 【定期レポート生成の自動化】
Lidaをパイプラインに組み込み、データ更新のたびに自動でグラフを再生成・出力する仕組みを構築できる。ステークホルダー向けの週次レポート作成コストを大幅に削減。 【LLMバックエンドの実験・比較】
同じデータ・同じ質問に対して、OpenAI・Azure OpenAI・ローカルLLMで生成結果を比較したい場合にも対応。LLMプロバイダーを切り替えるコードは数行で済む。
LangChainとの組み合わせ
LangChainを活用したRAGパイプラインでは、文書検索→要約→回答生成の流れを自動化できるが、Lidaはこの流れを「データ分析・可視化」の領域に特化させたツールと位置づけられる。LangChainでデータを取得・整形し、Lidaで可視化するという組み合わせも技術的に成立する。
RAGFlowとのデータ基盤連携
RAGFlowは文書データのRAG処理に強みを持ち、非構造化データを扱う。一方LidaはCSV/JSONなどの構造化テーブルデータに特化している。両ツールを組み合わせることで、文書から抽出した数値データをLidaで可視化するパイプラインを構築できる。
今後の拡張性
LidaはアーキテクチャとしてLLMプロバイダーを容易に交換できるため、新しい言語モデルの出現に対応しやすい。ローカルLLM統合も進行中で、プライベートデータの処理要件がある企業での導入も視野に入る。インフォグラフィック生成機能はベータ段階だが、複合的なビジュアルレポートの自動生成へと発展が期待される。
関連記事: LLMとは?仕組みからローカル実行まで徹底解説【2026年完全ガイド】