非構造テキストから構造化データを取り出すタスクは、RAGやエージェント基盤にとって地味だが重要な前処理だ。Googleが公開したLangExtractは、LLMを使ってこの「テキスト→スキーマ化されたエンティティ」変換を、ソース位置の追跡付き・対話型HTMLビジュアライザ付きで行うPythonライブラリで、執筆時点で36,100スターを獲得している。Apache-2.0ライセンス、Python 99.6%、Gemini/OpenAI/Ollama/Vertex AIに対応——医療文書・文学テキスト・日本語NERまで同じAPIで扱える。
この記事ではGoogle LangExtractの構造化抽出機能を解説します。RAGアーキテクチャ全体の設計指針はRAGとは?2026完全ガイドをご覧ください。
この記事のポイント
- LLM出力をソース位置と紐づけ、ハルシネーションを構造的に検出できる「source grounding」がコア機能。
- 数行のfew-shot例だけでドメイン適応でき、
gemini-2.5-flash/gpt-4o/gemma2:2bを切り替えるだけで動く。 - 抽出結果は自動で対話型HTMLにレンダリングされ、人間レビューと検証ループに直結する。
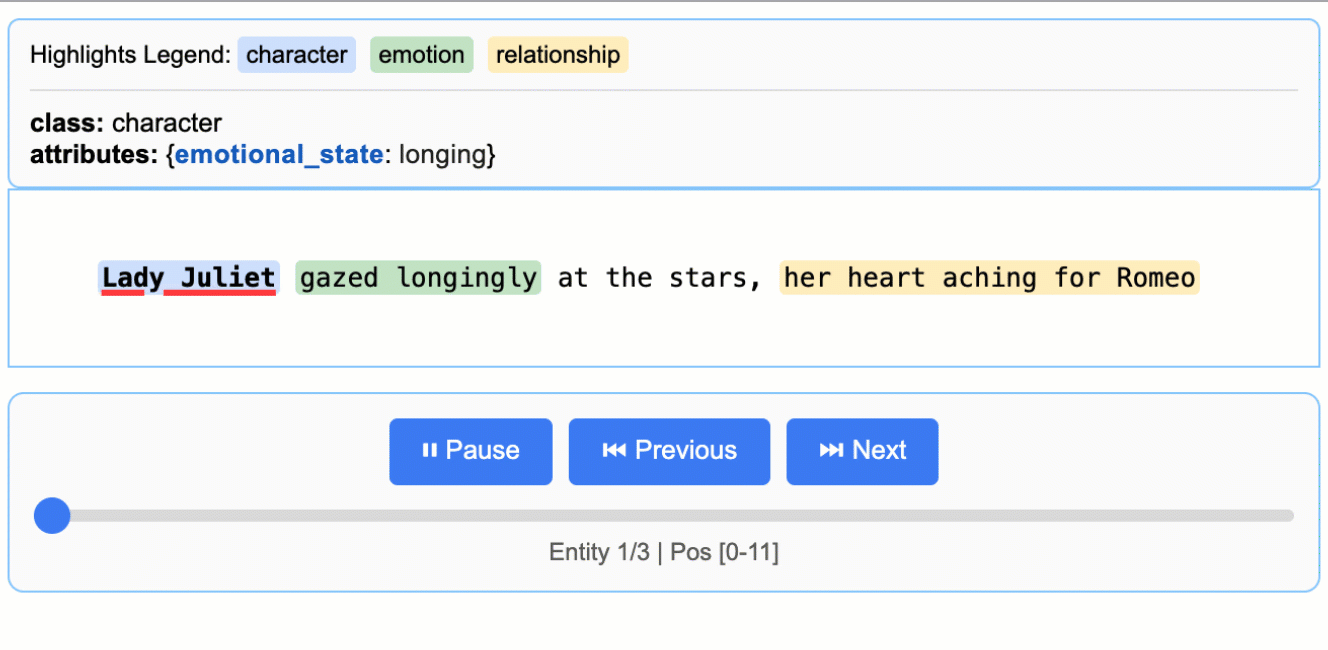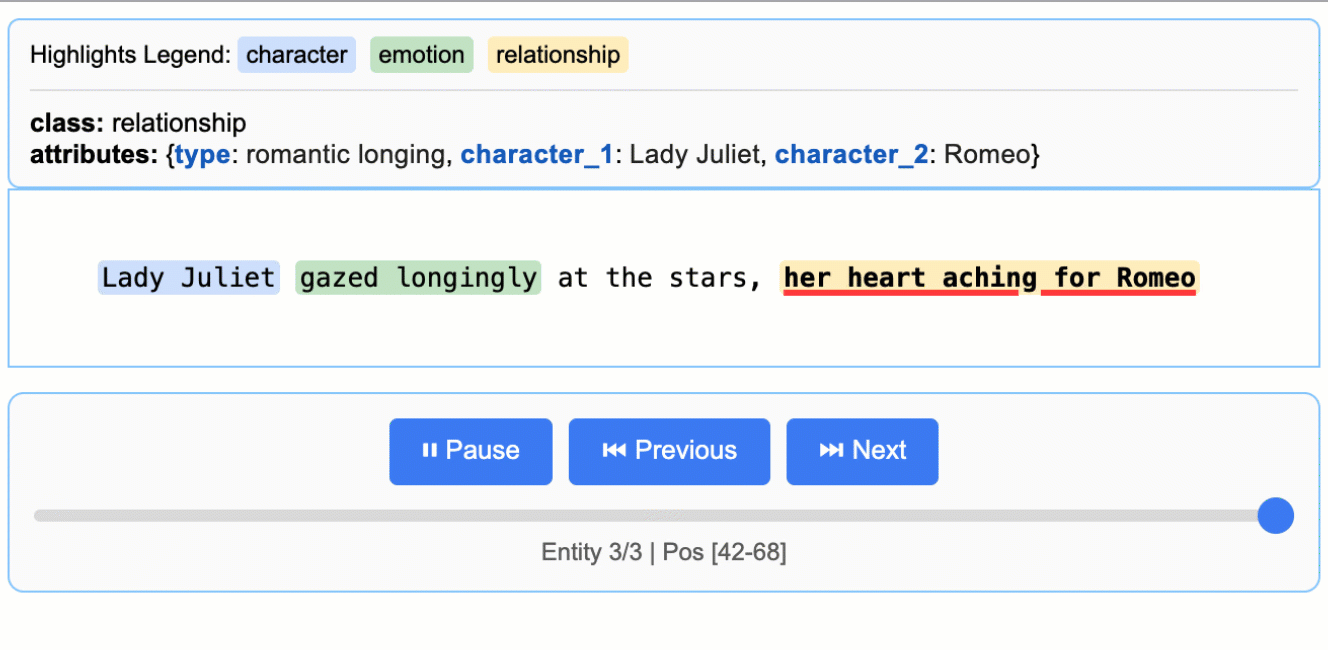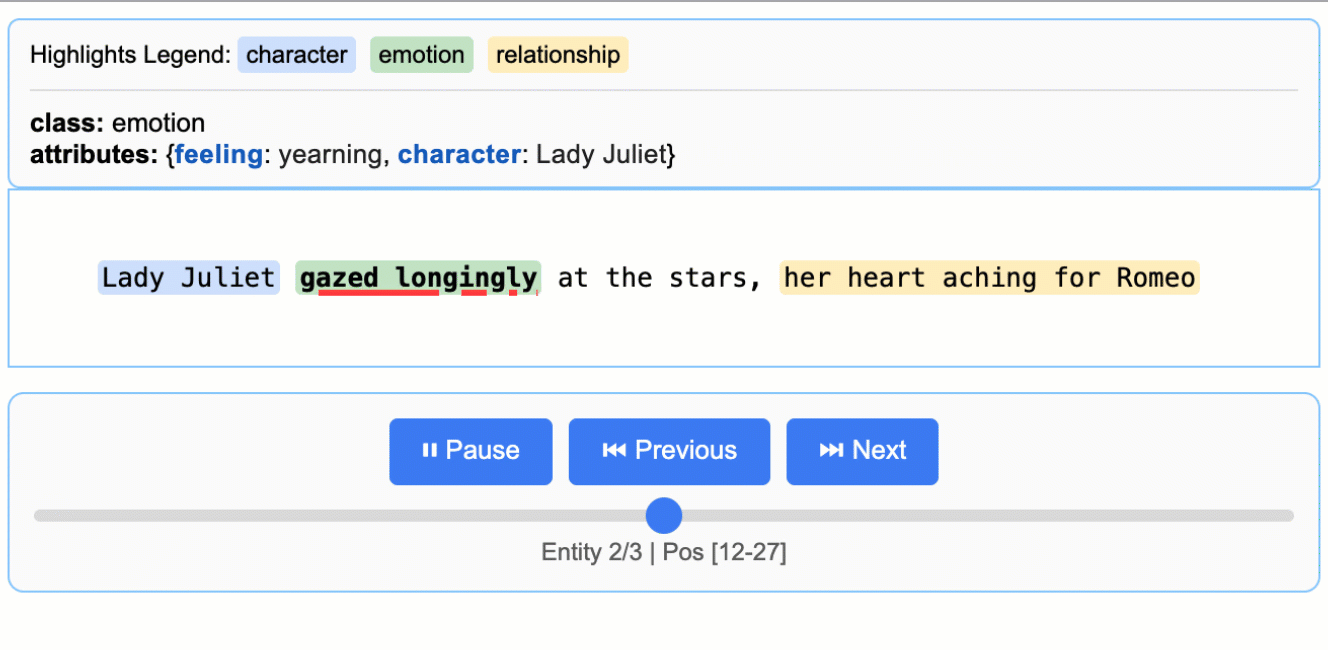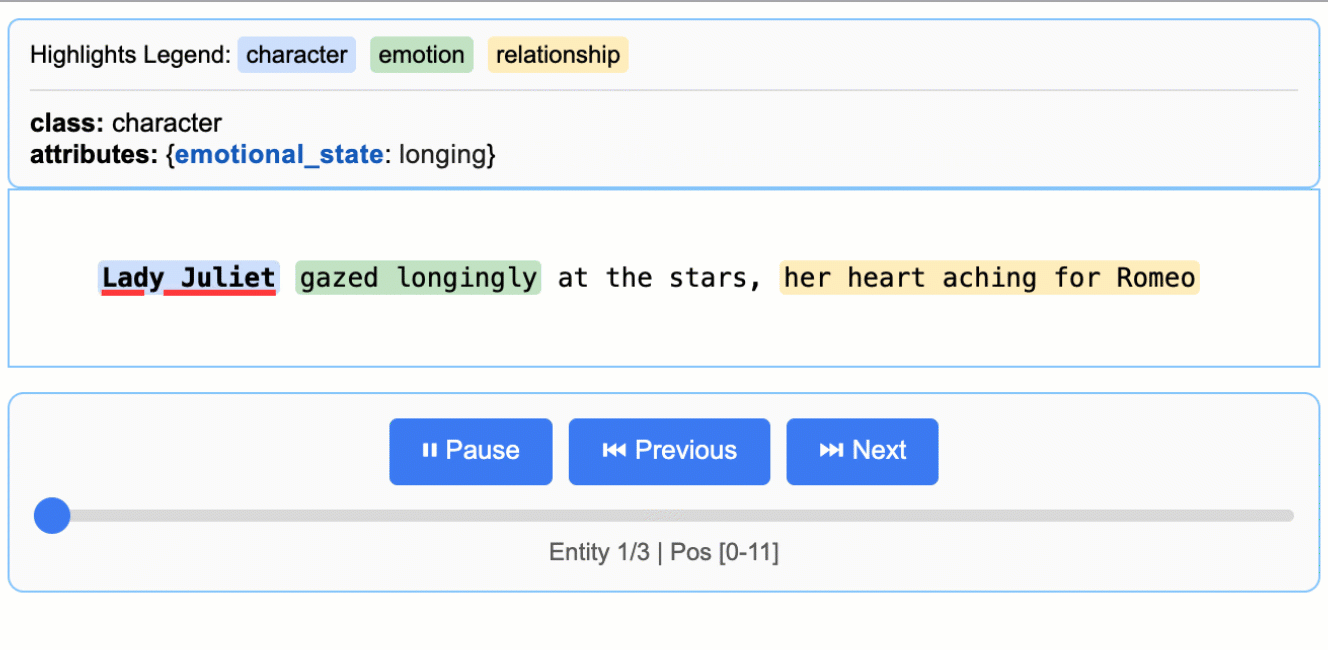 Source: google/langextract — Romeo & Julietテキストから抽出した登場人物・感情・関係性が、原文ハイライト付きで表示される。
Source: google/langextract — Romeo & Julietテキストから抽出した登場人物・感情・関係性が、原文ハイライト付きで表示される。
LangExtractとは:LLMで非構造テキストを構造化する仕組み
LangExtractは「lx.extract(text, prompt, examples, model_id) というシンプルなAPIで、テキスト全体をLLMに食わせて構造化結果+元文字位置を返す」ライブラリだ。Google Researchが社内の医療NLP用途(後述するRadExtractデモ)で使っていたパイプラインを切り出してOSS化した経緯を持つ。
通常のLLM抽出は「JSONを返してください」とプロンプトで頼むだけで、結果がテキスト中のどこに、本当にあったかを後から検証する手段がない。LangExtractはこの「グラウンディング」を一級概念として扱い、抽出された各エンティティに char_interval を付与する。
import langextract as lx
result = lx.extract(
text_or_documents=input_text,
prompt_description="Extract characters and emotions...",
examples=[lx.data.ExampleData(...)],
model_id="gemini-2.5-flash",
)
# 各 extraction には char_interval が付き、原文上の位置が分かる
for ext in result.extractions:
print(ext.extraction_class, ext.extraction_text, ext.char_interval)
char_interval = None だった場合、それは「LLMが勝手に作った/原文に無い」抽出としてフラグできる。RAGや業務オートメーションにLLMを組み込むときに最も嫌われる「もっともらしいハルシネーション」を、機械的に弾く線が引ける。
ライブラリ全体のアーキテクチャは下図のようになる。
Gemini/OpenAI/Ollama"] D --> E[抽出+char_interval付与] E --> G[(JSONL)] G --> H[lx.visualize] H --> I[対話型HTML]
「分割して並列で叩く → 結果を統合 → 原文位置に逆引き → HTML化」までを一本のパイプラインに畳み込んでいるのが、自前で書くと地味に重い部分を肩代わりしている価値だ。
5つのコア機能:ソースグラウンディング、可視化、長文処理など
公式が掲げる主要機能は以下の通り。
| 機能 | 中身 | 何が嬉しいか |
|---|---|---|
| Precise Source Grounding | 抽出ごとに原文の文字位置 (char_interval) を付与 |
ハルシネーションの構造的検出、レビュー効率向上 |
| Reliable Structured Outputs | few-shot例とスキーマでLLM出力を制御(Geminiはcontrolled generation) | スキーマ崩壊を抑止、JSON Parse失敗の削減 |
| Long Document Processing | 自動チャンキングと並列処理(max_workers、extraction_passes) |
数十万文字の小説・カルテも単一呼び出しで扱える |
| Interactive Visualization | 抽出結果を対話型HTMLとして自動生成 | 非エンジニアもブラウザだけで結果検証ができる |
| Flexible LLM Support | Gemini / OpenAI / Ollama / Vertex AI / カスタムプラグイン | クラウド〜ローカルまで同じコードで回せる |
「ドメイン非依存(domain-agnostic)」を掲げているのもポイントで、ファインチューニング不要で医療カルテ、法務文書、文学テキスト、ニュース記事に同じAPIを当てられる。違いはfew-shotサンプルの差分だけ、というのが運用上のコストを大きく下げる。
LLMの選び方を別記事で押さえたいなら、LLMとは?2026完全ガイドが下地になる。LangExtractはあくまで「ラッパー」なので、LLM側の特性が分かっていると効果的にチューニングできる。
インストールから初回実行まで(Romeo & Juliet例)
セットアップは1行で済む。
pip install langextract
# ソースから(開発ツール込み)
git clone https://github.com/google/langextract.git
cd langextract
pip install -e ".[dev]"
# Docker
docker build -t langextract .
docker run --rm -e LANGEXTRACT_API_KEY="$KEY" langextract python script.py
APIキーは環境変数で渡す。
export LANGEXTRACT_API_KEY="your-api-key"
公式READMEのファーストサンプルが「Romeo & Julietから登場人物・感情・関係性を抽出する」例で、これを写経すれば挙動を肌で掴める。
import langextract as lx
import textwrap
prompt = textwrap.dedent("""\
Extract characters, emotions, and relationships in order of appearance.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context.""")
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks?",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO",
attributes={"emotional_state": "wonder"},
),
],
)
]
input_text = "Lady Juliet gazed longingly at the stars, her heart aching"
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
)
# 結果保存
lx.io.save_annotated_documents([result],
output_name="extraction_results.jsonl", output_dir=".")
# 対話型HTMLにレンダリング
html_content = lx.visualize("extraction_results.jsonl")
with open("visualization.html", "w") as f:
f.write(html_content.data if hasattr(html_content, "data") else html_content)
visualize()の出力は単一のHTMLファイルで、CDN参照なしで動く設計になっている(社内ネットワーク・閉域環境にも持ち込みやすい)。記事冒頭のGIFがまさにこの出力で、登場人物の出現順アニメーションと、原文ハイライトが連動する。
長文では同じAPIで extraction_passes と max_workers を増やすだけで挙動が変わる。
result = lx.extract(
text_or_documents="https://www.gutenberg.org/files/1513/1513-0.txt",
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
extraction_passes=3, # 多パスで再現率を上げる
max_workers=20, # 並列ワーカー数
max_char_buffer=1000, # チャンクサイズ(小さいほど精度↑、コール数↑)
)
147,843文字あるRomeo & Juliet全文(Project Gutenberg)でも、上記設定で1呼び出しに見える形で完走できる。同様に大規模ドキュメントの構造化を扱う系統だと、PDF→構造化に特化したMinerU(PDF・複雑レイアウト解析OSS)が補完的に使える。
医療領域での活用:医薬品抽出のNERとリレーション
LangExtractが社内発祥した経緯を反映して、READMEには医療NER(名前付きエンティティ認識)の例が手厚い。たとえばカルテ風テキストから「医薬品名・用量・経路・頻度・期間」を抽出するベースラインは次の通り。
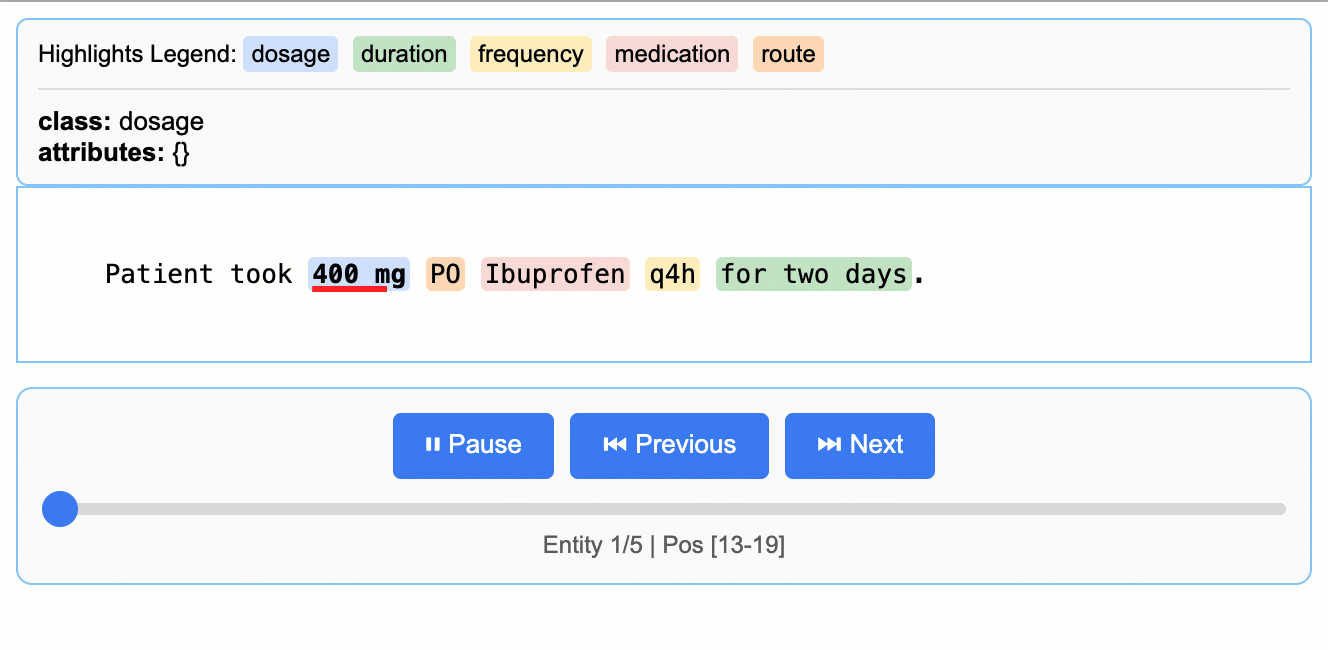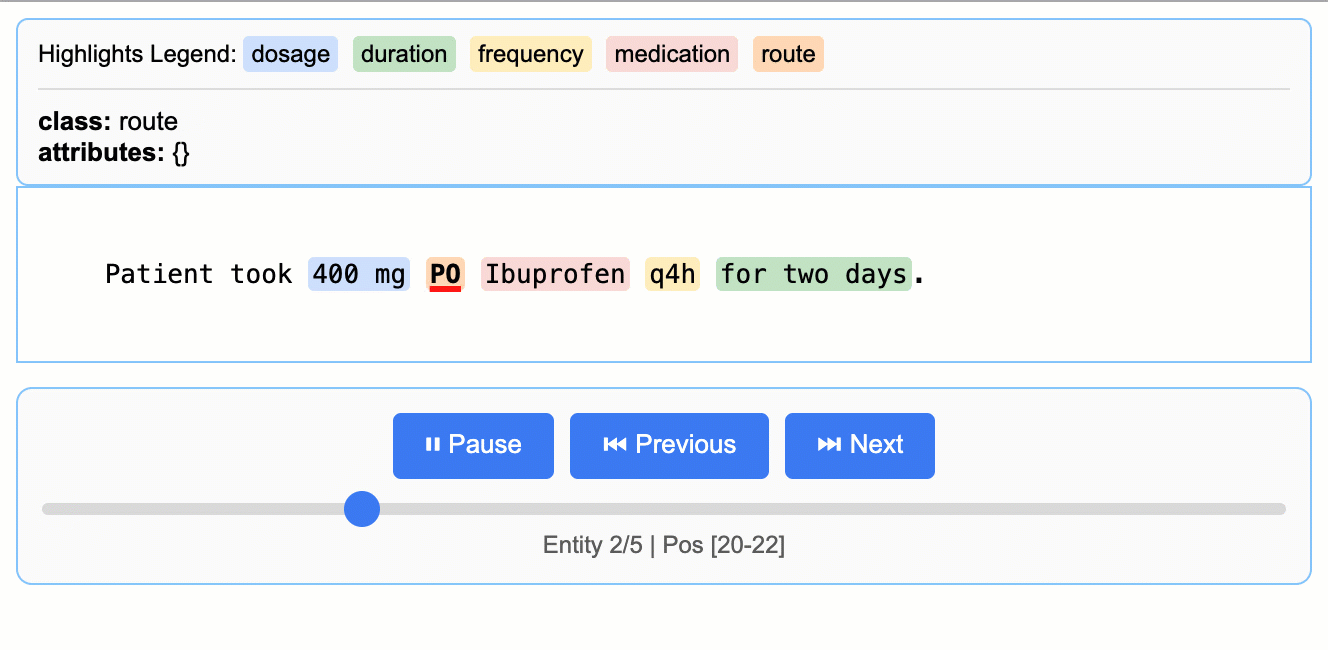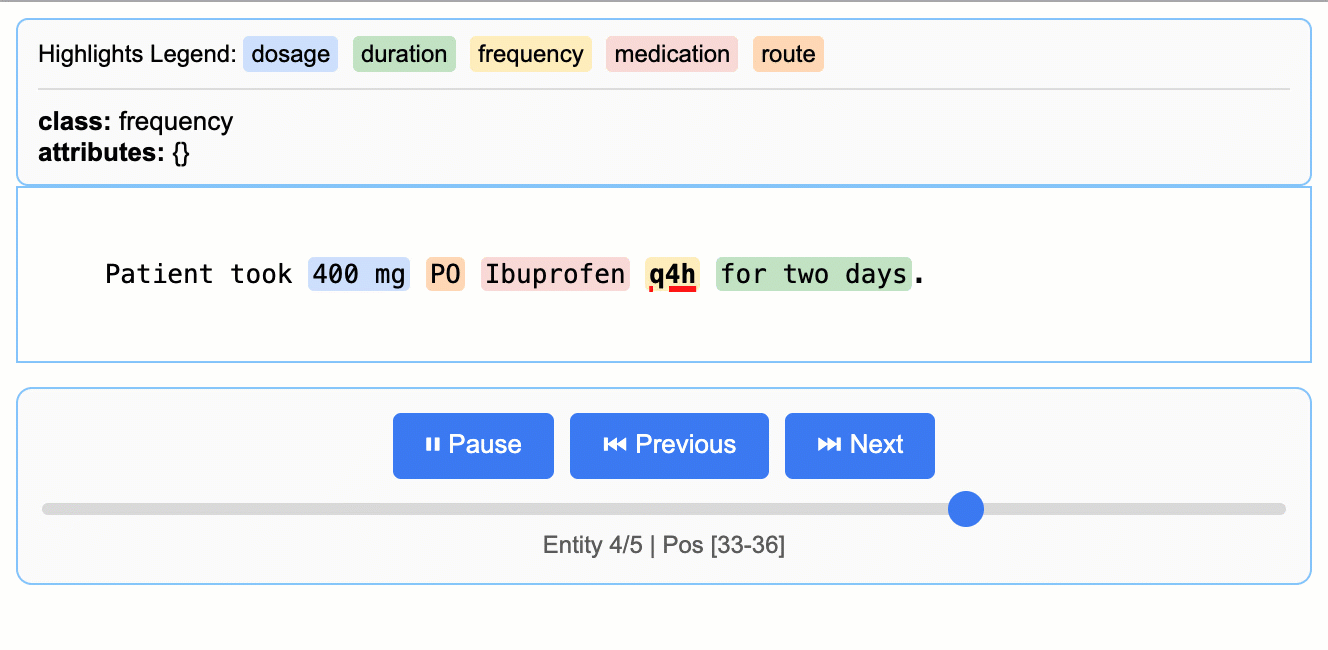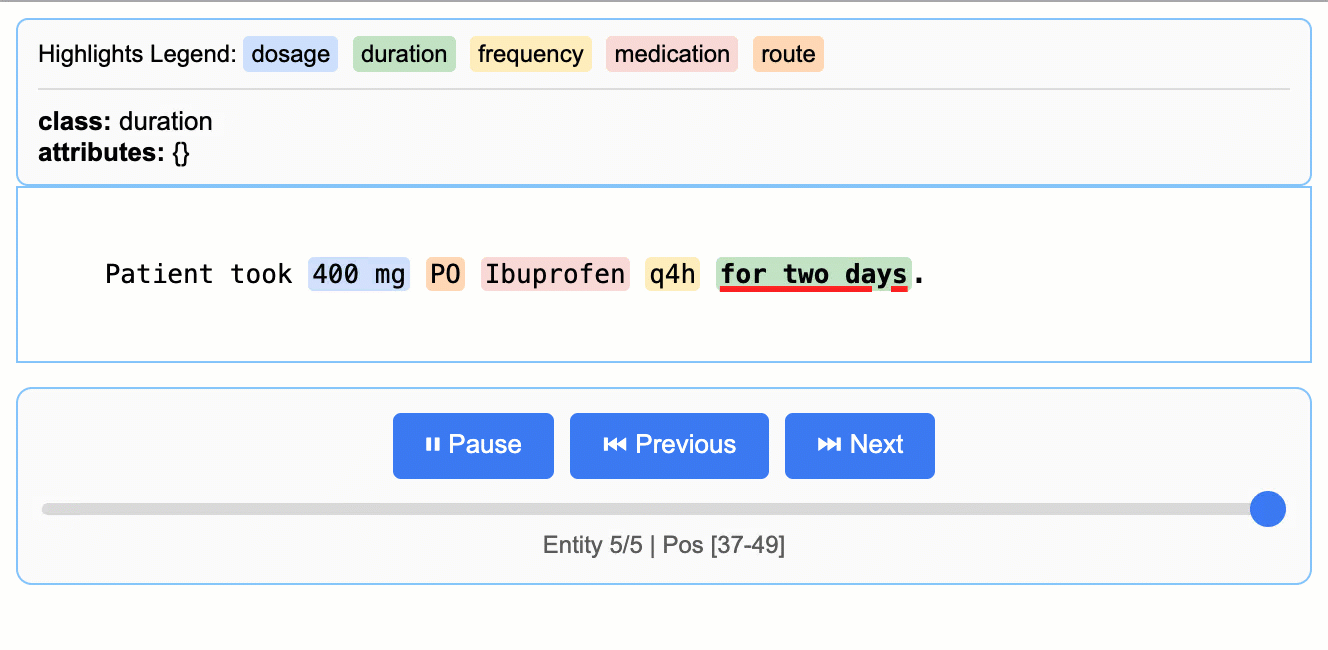 Source: google/langextract — 医療テキストからの薬剤エンティティ抽出デモ。
Source: google/langextract — 医療テキストからの薬剤エンティティ抽出デモ。
import langextract as lx
input_text = "Patient took 400 mg PO Ibuprofen q4h for two days."
prompt_description = (
"Extract medication information including medication name, dosage, "
"route, frequency, and duration in the order they appear in the text."
)
examples = [
lx.data.ExampleData(
text="Patient was given 250 mg IV Cefazolin TID for one week.",
extractions=[
lx.data.Extraction(extraction_class="dosage", extraction_text="250 mg"),
lx.data.Extraction(extraction_class="route", extraction_text="IV"),
lx.data.Extraction(extraction_class="medication", extraction_text="Cefazolin"),
lx.data.Extraction(extraction_class="frequency", extraction_text="TID"),
lx.data.Extraction(extraction_class="duration", extraction_text="for one week"),
],
)
]
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt_description,
examples=examples,
model_id="gemini-2.5-pro",
)
これだけで「400 mg / PO / Ibuprofen / q4h / for two days」が個別エンティティとして取れる。ここまでなら他のNERツールでもできるが、LangExtractの強みはリレーション(同じ薬剤に紐づく属性のグルーピング)を、属性で表現できる点にある。
input_text = """
The patient was prescribed Lisinopril and Metformin last month.
He takes the Lisinopril 10mg daily for hypertension, but often misses
his Metformin 500mg dose which should be taken twice daily for diabetes.
"""
prompt_description = """
Extract medications with their details, using attributes to group related information:
1. Extract entities in the order they appear in the text
2. Each entity must have a 'medication_group' attribute linking it to its medication
3. All details about a medication should share the same medication_group value
"""
examples = [
lx.data.ExampleData(
text="Patient takes Aspirin 100mg daily for heart health and Simvastatin 20mg at bedtime.",
extractions=[
lx.data.Extraction(extraction_class="medication", extraction_text="Aspirin",
attributes={"medication_group": "Aspirin"}),
lx.data.Extraction(extraction_class="dosage", extraction_text="100mg",
attributes={"medication_group": "Aspirin"}),
lx.data.Extraction(extraction_class="frequency", extraction_text="daily",
attributes={"medication_group": "Aspirin"}),
lx.data.Extraction(extraction_class="condition", extraction_text="heart health",
attributes={"medication_group": "Aspirin"}),
lx.data.Extraction(extraction_class="medication", extraction_text="Simvastatin",
attributes={"medication_group": "Simvastatin"}),
lx.data.Extraction(extraction_class="dosage", extraction_text="20mg",
attributes={"medication_group": "Simvastatin"}),
lx.data.Extraction(extraction_class="frequency", extraction_text="at bedtime",
attributes={"medication_group": "Simvastatin"}),
],
)
]
medication_group という共通キーを介して「Lisinopril 10mg daily / hypertension」と「Metformin 500mg twice daily / diabetes」をそれぞれ束ねられる。スキーマを変えずに「実体 + 属性で関係を表現する」のが思想で、ナレッジグラフのトリプルに繋ぎやすい設計になっている。
なお、READMEは医療例についても「臨床利用ではなく研究・開発用途」「Apache 2.0 + Health AI Developer Foundations Termsの併用」と明記している。プロダクション投入時は責任範囲を必ず確認してほしい。GoogleはRadExtract(放射線レポート構造化)デモを Hugging Face Spaces で公開しており、CT/MRIレポートのフリーテキストを所見・診断へ自動分割する応用が公開実装としてある。
日本語テキストへの対応:UnicodeTokenizerとサンプル
「英語前提のNERツールが日本語で破綻する」問題はGoogle側でも認識されており、LangExtractはUnicodeTokenizerを明示的にサポートする。READMEのdocs/examples/japanese_extraction.mdにある通り、東京・田中・Googleなど分かち書きされない言語でも、文字単位アライメントで char_interval が崩れない。
import langextract as lx
from langextract.core import tokenizer
input_text = "東京出身の田中さんはGoogleで働いています。"
prompt_description = "Extract named entities including Person, Location, and Organization."
examples = [
lx.data.ExampleData(
text="大阪の山田さんはソニーに入社しました。",
extractions=[
lx.data.Extraction(extraction_class="Location", extraction_text="大阪"),
lx.data.Extraction(extraction_class="Person", extraction_text="山田"),
lx.data.Extraction(extraction_class="Organization", extraction_text="ソニー"),
],
)
]
unicode_tokenizer = tokenizer.UnicodeTokenizer()
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt_description,
examples=examples,
model_id="gemini-2.5-flash",
tokenizer=unicode_tokenizer,
)
これだけで「東京(Location)/田中(Person)/Google(Organization)」が抽出され、それぞれ原文の文字オフセットと結びつく。日本語の固有表現抽出で手書きのMeCab前処理を一旦やめる選択肢として現実的だ。一方、専門領域(金融・法務・医療)ではfew-shotの作り込みが品質を決める。少数例+ドメインプロンプトの試行錯誤に時間を使うべき、と理解しておけば良い。
ナレッジ構築の文脈でこの抽出結果を活かすなら、エンティティ+関係性をグラフ化するLightRAG(GraphRAGの軽量実装)などとの組み合わせが自然だ。「LangExtractで構造化 → LightRAGで関係グラフ化 → RAGで検索」というパイプラインが描ける。
プロバイダー比較:Gemini / OpenAI / Ollama / Vertex AI
model_idを切り替えるだけで裏側のLLMが入れ替わるので、PoCと本番運用で別プロバイダーを使う運用も容易だ。
| プロバイダ | model_id例 | 特徴 | コスト感 |
|---|---|---|---|
| Gemini | gemini-2.5-flash / gemini-2.5-pro |
controlled generationでスキーマ強制、推奨デフォルト | クラウド従量課金、Flashは安価 |
| OpenAI | gpt-4o |
GPT系の高い言語理解、pip install langextract[openai]で有効化 |
標準的なOpenAI料金 |
| Ollama | gemma2:2b ほか |
ローカル推論、API送信不要、機密データ向き | サーバ電気代のみ |
| Vertex AI | gemini-2.5-pro (vertexai=True) |
サービスアカウント/バッチ処理対応、エンタープライズ | バッチで実質コスト削減 |
| カスタム | プラグイン経由 | 社内LLM・自前推論基盤に接続可 | ケースバイケース |
Ollamaを使ったローカル実行はオフラインPoCに便利だ。
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemma2:2b",
model_url="http://localhost:11434",
)
事前に ollama pull gemma2:2b && ollama serve を立ち上げておくだけ。機密データを外部APIに送らずに動かせる意味は大きく、企業のPoCで社外送信NGに引っかかるケースで重宝する。
OpenAI経由なら、
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gpt-4o", # 自動でOpenAIプロバイダーが選ばれる
)
と1行変えるだけ。Vertex AIのバッチ機能は language_model_params={"vertexai": True, "batch": {"enabled": True}} で有効化でき、夜間まとめてコストを下げる定番運用に乗せやすい。
RAG/エージェント時代における位置づけ
LLMアプリの構成要素は急速に成熟していて、LangExtractは「ETLレイヤー」の標準候補に近づいている。具体的には次のようなレイヤー分担になる。
| レイヤー | 役割 | 代表的な選択肢 |
|---|---|---|
| ドキュメント解析 | PDFやHTMLからプレーンテキスト化 | MinerU、unstructured、officeparser |
| 構造化抽出(本記事) | 非構造テキスト→エンティティ+関係 | LangExtract、spaCy + LLM、独自プロンプト |
| インデキシング | ベクトル/全文/グラフ化 | LangChain、LlamaIndex、Trieve |
| 検索/生成 | RAG・エージェントオーケストレーション | LangChain、LangGraph、Dify |
「ドキュメント解析」と「インデキシング」の間にあった、ふんわりしたプロンプト+JSON.parse頼みの領域に、ソース位置追跡という規律を持ち込んだのがLangExtractの貢献だ。同じ「ドキュメント→構造化」の流れだと、HTML/Officeファイルをパースするofficeparser(Node.js製ドキュメントパーサ)が前段の選択肢として相性が良い。
エージェント側から見ると、ツール呼び出しのfunction_callingに渡す入力スキーマと、LangExtractが返すエンティティ構造はそのまま噛み合う。スキーマを一度定義すれば、抽出 → ツール呼び出し → 実行 → 検証、というループに落とし込みやすい。
開発フローのおすすめは次の3段階だ。
- 設計: 抽出したいエンティティと属性をJSON Schema風に紙で描く。
extraction_classとattributesにどう写せるか考える。 - few-shot: 3〜5例の
ExampleDataを作る。質より代表性を重視(境界ケース・否定例も入れる)。 - 検証:
lx.visualizeのHTMLを開き、char_interval = Noneの抽出を抜き出してハルシネーションをカウント。許容率に達するまで例を追加する。
「LLMを呼ぶアプリ」を作る前にこのライブラリで手抜きせず構造化を済ませる、という判断は、長期的なメンテコストを大きく下げる。
まとめ:LLM抽出を「説明可能な前処理」に格上げする一手
LangExtractは派手な新規概念を持ち込んだわけではない。「LLMで構造化抽出する」というありふれた作業に対して、ソース位置の追跡・対話型HTML・ドメイン非依存・ローカル/クラウド両対応という運用品質を一気に積んできたライブラリだ。
- 既にLLMで抽出を試している → ハルシネーション検証フローが手薄なら導入価値が高い
- これからRAG/エージェントを組む → 前処理レイヤーをLangExtractで標準化しておくと、後工程の自由度が増す
- 医療・法務・教育など説明責任が重い領域 → 原文位置の自動マッピングは、人間レビューの効率を桁で変える
36k starsという実績は、Google発という看板だけでは説明できない。地味だが効くツールが、コミュニティに受け入れられた結果と読むのが妥当だ。