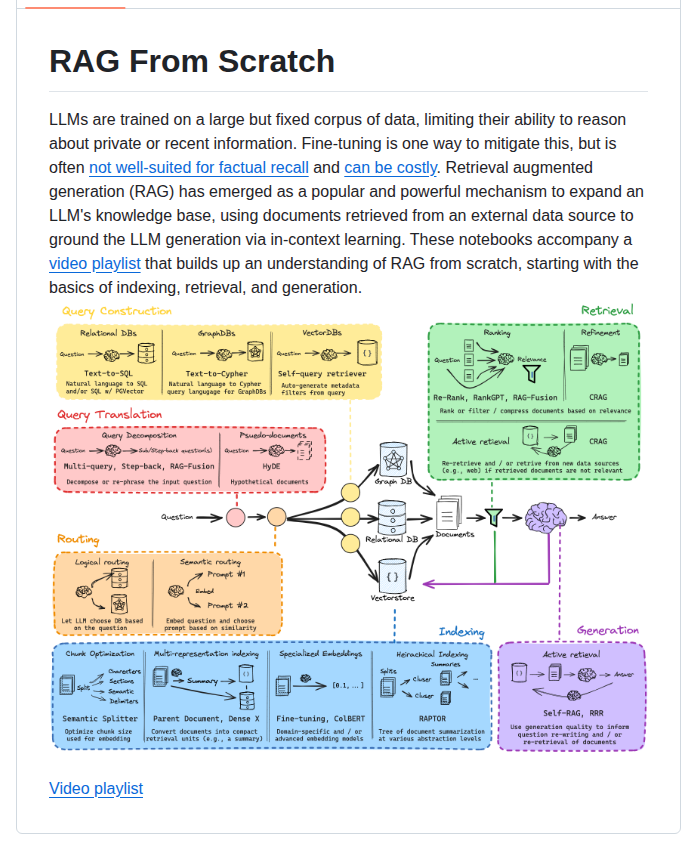
この記事ではRAGに特化して解説します。RAG全般は RAGとは?仕組み・構築・ベクトルDB選定まで【2026年完全ガイド】 をご覧ください。
LlamaCloud Demoとは:LlamaIndexエコシステムのRAG実装集
run-llama/llamacloud-demoは、LlamaIndexが提供するLlamaCloudを活用したRAGアプリケーションのクックブック集だ。GitHub 452スターを獲得しており、LlamaCloudとLlamaIndexを組み合わせてデータパイプラインを管理する実装例がJupyterノートブック形式で収録されている。
重要な前提として、このリポジトリは公式に非推奨(deprecated)となっており、積極的なメンテナンスは終了している。最新のLlamaCloud実装例は llama-cloud-services リポジトリに移行されている。それでも、LlamaIndexエコシステムのRAGパイプラインを理解するための学習リソースとして、このデモリポジトリは多くの実装パターンを提示している。
この記事では、llamacloud-demoの実装パターンを通じてLlamaCloudとLlamaIndexの連携方法を解説し、現在推奨される llama-cloud-services への移行パスも示す。
run-llama/llamacloud-demoは非推奨です。本番環境での新規実装にはllama-cloud-servicesを使用してください。このリポジトリはLlamaCloudのアーキテクチャを学ぶ参考資料として価値があります。
LlamaCloudのアーキテクチャ:データパイプライン管理の仕組み
LlamaCloudは、RAGシステムのデータ管理をマネージドサービスとして提供するプラットフォームだ。通常のRAG構築では、ドキュメントの取り込み・チャンキング・エンベッディング・インデックス化・更新検知という一連のパイプラインを自前で実装・運用する必要がある。LlamaCloudはこれをインフラとして提供し、開発者はインデックスへのクエリに集中できる。
S3・Google Drive・Web・PDF"] --> B["LlamaCloud
データパイプライン"] B --> C["自動チャンキング"] C --> D["エンベッディングモデル
(OpenAI・Custom)"] D --> E["LlamaCloud Index
(管理インデックス)"] F["ユーザークエリ"] --> G["LlamaIndex Python SDK
LlamaCloudIndex"] G --> E E --> H["類似検索
Top-K Retrieval"] H --> I["LLM生成
回答"] I --> J["エンドユーザー"]
主要コンポーネント
LlamaCloud(バックエンド)
- データソース接続(S3、Google Drive、Confluence、Web等)
- 自動チャンキングと前処理
- エンベッディング生成と管理
- インデックスの自動更新・同期
LlamaIndex Python SDK(フロントエンド)
LlamaCloudIndexクラスによるインデックス操作- クエリエンジンの構築
- LLMとの統合(OpenAI、Anthropic、Ollama等)
- レスポンスのストリーミング
LlamaIndexはself-hostedのOSSライブラリで、ベクトルDBや変換処理をすべて自前管理します。LlamaCloudはLlamaIndex社が提供するマネージドサービスで、インデックスの管理をクラウドに委託できます。llamacloud-demoはこの連携パターンを示すものです。
セットアップ手順:Jupyter環境の構築とAPI設定
1. 環境構築
Pythonの仮想環境を作り、依存パッケージをインストールする:
# 仮想環境の作成
python3 -m venv .venv
source .venv/bin/activate
# 依存パッケージのインストール
pip install -r requirements.txt
# Jupyter Labの起動
jupyter lab
requirements.txt には llama-index、llama-cloud、openai などの主要パッケージが含まれている。
2. LlamaCloudアカウントとAPIキーの設定
import os
# LlamaCloud API キー(環境変数推奨)
os.environ["PLATFORM_API_KEY"] = "your-llamacloud-api-key"
# OpenAI APIキー(エンベッディングとLLM用)
os.environ["OPENAI_API_KEY"] = "your-openai-api-key"
本番環境では直接ハードコードせず、.env ファイルと python-dotenv を使って管理する:
from dotenv import load_dotenv
load_dotenv() # .envファイルから環境変数を読み込む
3. LlamaCloudIndex の初期化
LlamaCloudで作成したインデックスに接続する:
from llama_index.indices.managed.llama_cloud import LlamaCloudIndex
# LlamaCloudで作成したインデックスに接続
index = LlamaCloudIndex(
name="my-index", # LlamaCloudで作成したインデックス名
project_name="my-project", # LlamaCloudのプロジェクト名
api_key=os.environ.get("PLATFORM_API_KEY"),
)
# クエリエンジンの作成
query_engine = index.as_query_engine()
4. クエリの実行
# シンプルなRAGクエリ
response = query_engine.query("製品のサポートポリシーはどうなっていますか?")
print(str(response))
# ソースノードの確認
for node in response.source_nodes:
print(f"スコア: {node.score:.3f}")
print(f"テキスト: {node.node.text[:200]}...")
print("---")
パッケージのトラブルシューティング
仮想環境でパッケージの競合が発生した場合の対処:
# 仮想環境を完全にリセット
rm -rf .venv
# 再構築
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
クックブック構成と主要な実装パターン
llamacloud-demoの examples/ ディレクトリには複数のJupyterノートブックが収録されており、それぞれ異なるユースケースを扱っている。
getting_started.ipynb
最初に試すべきノートブック。LlamaCloudへの接続からシンプルなQ&Aパイプラインまでを一通りカバーしている。
# getting_startedの基本パターン
from llama_index.core import VectorStoreIndex
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.indices.managed.llama_cloud import LlamaCloudIndex
# 既存インデックスへの接続
index = LlamaCloudIndex.from_index(
index_id="your-index-id",
project_name="your-project-name",
)
# リトリーバーの設定
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=5, # 上位5件を取得
)
# クエリエンジンのカスタマイズ
query_engine = RetrieverQueryEngine(retriever=retriever)
response = query_engine.query("このドキュメントの要点を教えてください")
print(response)
データパイプラインの更新検知パターン
LlamaCloudの特徴は、データソースの変更を自動検知してインデックスを更新する点だ:
# パイプラインのステータス確認(llama-cloud-services での最新パターン)
from llama_cloud import LlamaCloud
client = LlamaCloud(token=os.environ["PLATFORM_API_KEY"])
# パイプラインの一覧取得
pipelines = client.pipelines.list_pipelines(project_name="my-project")
for pipeline in pipelines:
print(f"Pipeline: {pipeline.name}, Status: {pipeline.status}")
ストリーミングレスポンスの実装
# ストリーミングでの回答生成
streaming_response = query_engine.query(
"この契約書の主要な条項を説明してください",
streaming=True
)
# トークンをリアルタイムに出力
for token in streaming_response.response_gen:
print(token, end="", flush=True)
print() # 改行
LlamaCloudと他のRAGソリューションの比較
LlamaCloudはマネージドサービスとして、self-hostedなRAGソリューションとは異なるトレードオフを提供する。
| 項目 | LlamaCloud | LlamaIndex (OSS) | LangChain + VectorDB | RAGFlow |
|---|---|---|---|---|
| データパイプライン | フルマネージド | 自前構築 | 自前構築 | セルフホスト |
| 初期設定コスト | 低い | 中程度 | 中〜高 | 中程度 |
| 月額費用 | 有料(従量制) | 無料(インフラ別) | 無料(インフラ別) | 無料 |
| カスタマイズ性 | 中程度 | 高い | 高い | 高い |
| データ主権 | クラウド依存 | 完全コントロール | 完全コントロール | セルフホスト |
| 更新・同期管理 | 自動 | 自前実装 | 自前実装 | 自動(一部) |
| ドキュメント品質 | 高い | 高い | 高い | 中程度 |
| マルチモーダル対応 | 対応中 | 対応 | 対応 | 対応 |
LlamaCloudが適しているケース
- 素早くRAGプロトタイプを構築したい
- データパイプラインのインフラ管理コストを削減したい
- LlamaIndexのエコシステムに投資済み
- ドキュメントの更新頻度が高い(自動同期が効く)
self-hostedが適しているケース
llamacloud-demoからllama-cloud-servicesへの移行は、主にimportパスの変更です。
LlamaCloudIndexの基本的な使い方は同じですが、クライアントSDKがllama-cloudパッケージに統合されています。pip install llama-cloudで最新版を取得してください。実践的ユースケース
1. 社内ドキュメントのQ&Aシステム
企業の規程集・マニュアル・技術文書をLlamaCloudにインデックスし、従業員が自然言語で質問できるシステムを構築できる。データソースとしてConfluence・Google Drive・SharePointとの接続が可能。
# マルチドキュメントRAGの構築例
from llama_index.indices.managed.llama_cloud import LlamaCloudIndex
from llama_index.llms.openai import OpenAI
# インデックス取得
index = LlamaCloudIndex(
name="company-docs-index",
project_name="internal-qa",
)
# LLMを指定したクエリエンジン
llm = OpenAI(model="gpt-4o", temperature=0)
query_engine = index.as_query_engine(llm=llm)
# 社内規程の質問
response = query_engine.query("育児休業の申請手続きを教えてください")
print(response)
2. 製品ドキュメントのチャットボット
API仕様書・ユーザーガイド・FAQ等をインデックス化し、チャット形式でサポートを提供するボットを構築できる:
from llama_index.core.memory import ChatMemoryBuffer
# 会話履歴付きチャットエンジン
memory = ChatMemoryBuffer.from_defaults(token_limit=3900)
chat_engine = index.as_chat_engine(
chat_mode="condense_plus_context",
memory=memory,
verbose=True,
)
# 会話形式のやり取り
response = chat_engine.chat("APIの認証方法を教えて")
print(response)
response = chat_engine.chat("それをPythonで実装するとどうなる?")
print(response)
3. 研究論文のサマリーと比較
複数の研究論文をLlamaCloudにアップロードし、比較分析や横断的な質問に答えるシステムを構築できる。
4. カスタムリトリーバーの実装
LlamaIndexのリトリーバーAPIを活用して、検索精度を細かく制御できる:
from llama_index.core.retrievers import (
VectorIndexRetriever,
KeywordTableSimpleRetriever,
)
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.retrievers import RouterRetriever
# ハイブリッドリトリーバー(ベクトル + キーワード)
vector_retriever = VectorIndexRetriever(
index=index,
similarity_top_k=3,
)
# 取得ノードのリランキング
from llama_index.core.postprocessor import SimilarityPostprocessor
postprocessor = SimilarityPostprocessor(similarity_cutoff=0.7)
query_engine = RetrieverQueryEngine(
retriever=vector_retriever,
node_postprocessors=[postprocessor],
)
LlamaIndexエコシステムの全体像
LlamaCloudはLlamaIndexエコシステムの一部であり、フルスタックのRAGフレームワークとして機能する。
(OSS Python SDK)"] B["LlamaCloud
(マネージドデータパイプライン)"] C["LlamaHub
(データローダー・インテグレーション)"] D["LlamaParse
(高精度PDFパーサー)"] end A --> E["アプリケーション"] B --> A C --> A D --> B F["ベクトルDB
(Chroma・Pinecone等)"] --> A G["LLMプロバイダー
(OpenAI・Anthropic等)"] --> A
| コンポーネント | 役割 | 料金 |
|---|---|---|
| LlamaIndex Core | RAGのオーケストレーション | 無料OSS |
| LlamaCloud | データパイプライン管理 | 有料マネージドサービス |
| LlamaParse | 高精度PDF・ドキュメントパーサー | 有料(一部無料枠) |
| LlamaHub | 160以上のデータコネクター | 無料OSS |
LlamaParse との連携
LlamaCloudに組み込まれた高精度パーサーである LlamaParse を単体で使うことも可能だ:
from llama_parse import LlamaParse
parser = LlamaParse(
api_key=os.environ["LLAMA_CLOUD_API_KEY"],
result_type="markdown", # "markdown" または "text"
num_workers=4,
)
# PDFをMarkdownに変換
documents = parser.load_data("./technical_report.pdf")
print(documents[0].text[:500])
PDFパーサーとしての高精度さが必要な場面では、MinerUと比較検討するとよい。MinerUはOSSで自己ホスト可能、LlamaParseはマネージドサービスというトレードオフがある。
よくある質問
Q:llamacloud-demoのノートブックはそのまま動きますか?
A:リポジトリ自体は非推奨ですが、コードは参考として動作確認可能なものが多いです。ただし llama-index のバージョン変更により一部APIが変わっています。最新の llama-index-core に合わせてimportパスの修正が必要な場合があります。
Q:LlamaCloudの無料枠はありますか?
A:LlamaCloudには無料トライアルが用意されています。詳細は cloud.llamaindex.ai の料金ページで確認してください。LlamaParse は月1000ページまで無料枠があります。
Q:LlamaCloud以外のベクトルDBと組み合わせられますか?
A:LlamaIndex CoreはPinecone、Weaviate、Chroma、Qdrant等、多数のベクトルDBとのインテグレーションを持っています。LlamaCloudはその中の一つのバックエンドオプションです。
Q:日本語ドキュメントのRAGに対応していますか?
A:LlamaIndexは日本語対応エンベッディングモデル(OpenAI text-embedding-3-small等)と組み合わせることで日本語RAGを構築できます。テキストスプリッターも日本語に対応したものを選ぶ必要があります。
LlamaIndexを学ぶ順序としては、(1) LlamaIndex Core の基本RAG → (2) カスタムリトリーバーとポストプロセッサー → (3) エージェント機能 → (4) LlamaCloudでの本番化という流れが効率的です。llamacloud-demoは(4)の実装パターンを示す参考資料として活用できます。
関連記事: RAGとは?仕組み・構築・ベクトルDB選定まで【2026年完全ガイド】
まとめ
run-llama/llamacloud-demoは現在非推奨だが、LlamaCloudとLlamaIndexの連携パターンを理解するための貴重な学習リソースだ。データパイプラインのマネージドサービスとして、S3やGoogle Driveからのドキュメント取り込み・チャンキング・インデックス化を自動化できるLlamaCloudの仕組みをこのクックブック集から学べる。
実際の本番実装には llama-cloud-services リポジトリを参照し、最新のAPIとクライアントSDKを使うこと。RAGパイプラインの実装を自前管理したい場合はLangChainやRAGFlowとの組み合わせも検討に値する。