アプリが本番で不調になったとき、ログはここ、メトリクスはあちら、トレースはまた別のツール——と 監視ツールを行ったり来たり して、原因にたどり着く頃には障害が広がっていた。しかもDatadogやSplunkの請求書は、データ量が増えるほど青天井に膨らんでいく。オブザーバビリティ(可観測性)は、現代のシステム運用に不可欠でありながら、コストと複雑さ という二重の負担を抱えがちな領域です。
その両方に正面から挑むのが、OpenObserve(openobserve/openobserve) です。GitHubで19,000以上のスターを集める、Rust製のオープンソース・オブザーバビリティ基盤。掲げるのは「ログ・メトリクス・トレース・RUMを1つに統合し、Elasticsearch比140倍の低コストで運用する」こと。本記事では、このDatadog代替がどう安さと統合を実現し、AI時代の運用基盤としてどう使えるのかを整理します。

なお本サイトはAI関連OSSの解説に特化していますが、オブザーバビリティはLLMアプリの運用にも直結する領域であり、OpenObserve自身もLLMオブザーバビリティを謳っています。本稿では「この基盤で結局、何ができる/何の負担が解ける/何の代わりになるのか」という視点で、公式READMEの記載に基づき確定情報と解釈を区別して解説します(140倍等の数値は公式の主張で、検証が前提)。AIアプリを本番で動かすほど、「呼び出しが遅い・コストが読めない・どこで失敗したか分からない」という運用課題が表面化します。その受け皿としてのオブザーバビリティ基盤、という角度でも読んでみてください。
- ・OpenObserveはログ・メトリクス・トレース・RUMを1基盤に統合するRust製OSSオブザーバビリティ。
- ・Parquet列指向+S3ネイティブで、Elasticsearch比140倍の低ストレージコストを謳う。
- ・単一バイナリで2分起動、クラスタ構築不要。SQL+PromQLで扱え独自クエリ言語が不要。
- ・OpenTelemetryネイティブで、LLMオブザーバビリティを含むトレース集約に対応。
- ・Datadog/Splunk/ES/Grafanaスタックの代替。ただしデータはイミュータブル、一部機能とSSOは商用エンタープライズ版、OSSはAGPL-3.0。
1. OpenObserveとは — Datadog代替の統合オブザーバビリティ
OpenObserve(O2)は、ログ・メトリクス・トレース・分析・RUM(リアルユーザーモニタリング)のために作られた クラウドネイティブなオブザーバビリティツール です。READMEは明確に、Datadog・Splunk・Elasticsearchの、複雑さやコストを伴わない代替 として位置づけています。「フル機能のオブザーバビリティを、複雑さもコストもなしに必要とするチーム向け」というわけです。
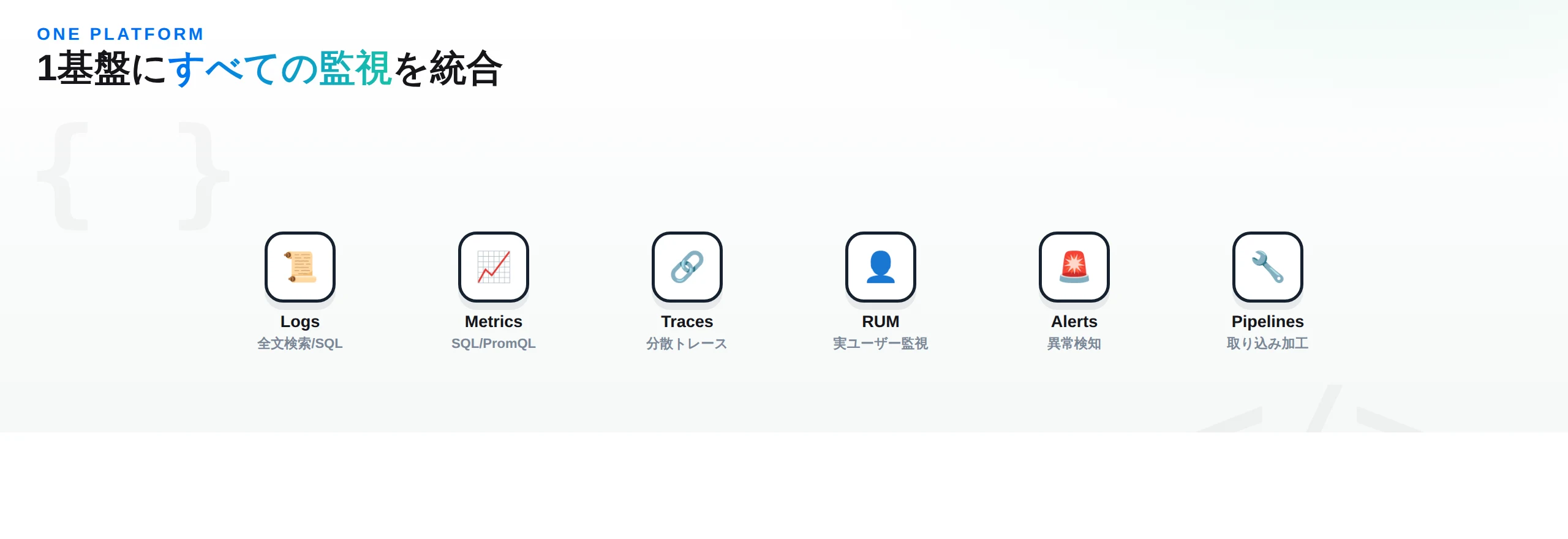
ここで読者が探している「①結局何ができる/②何を解決する/③何を代替する」に当てはめると——① ログ・メトリクス・トレース・RUMを1つの基盤で収集・検索・可視化・アラートできる。② 監視ツールの分断(ログとメトリクスとトレースが別ツール)と、SaaS課金の高騰という二重の負担を解消する。③ Datadog・Splunk・Elasticsearch、あるいはGrafana+Loki+Prometheus+Tempoという複数ツールの寄せ集めを代替できる——という整理になります。
READMEが挙げる「OpenObserveが選ばれる理由」は明快です。140倍低いストレージコスト(Parquet列指向+S3ネイティブ)、単一バイナリのデプロイ(2分未満で起動、複雑なクラスタ設定不要)、OpenTelemetryネイティブ(標準準拠でベンダーロックインなし)、統合プラットフォーム(ログ・メトリクス・トレース・RUM・ダッシュボード・アラートが1ツールに)、高性能(Elasticsearchより良いクエリ性能を1/4のハードで)、SQL+PromQL(独自クエリ言語が不要)、Rust製(メモリ安全・高性能・単一バイナリ)。
とくに本番運用の観点で重要なのは、「単一バイナリ」 という設計です。Elasticsearchやその周辺ツールは、シャード・レプリカ・ヒープサイズといった複雑な設定とクラスタ運用が前提になりがちですが、OpenObserveは1つのバイナリを起動するだけで動きます。READMEのFAQでも「学習曲線は急ではない。シャードやレプリカ、ヒープサイズを理解する必要はなく、ただインストールして使うだけ」と強調されています。運用の複雑さこそがオブザーバビリティ導入の隠れたコストである、という現場の実感を突いた設計思想です。
2. なぜ140倍安いのか — Parquet+S3アーキテクチャ
OpenObserveの代名詞である 「140倍低いストレージコスト」 は、どこから来るのか。ここがこのツールの技術的な核心です。

カギは2つの設計判断にあります。第一に、Parquet(列指向)ストレージ。従来のログ基盤(Elasticsearch等)は、検索のために大きなインデックスを持ち、ストレージを大量に消費します。OpenObserveは、データを列指向のParquetフォーマットで保持します。列指向は 圧縮効率が高く、集計・分析クエリに強い という性質があり、ログやトレースのような大量データを効率よく扱えます。第二に、S3ネイティブ設計。そのParquetデータを、高価なローカルディスクに置くのではなく、安価なオブジェクトストレージ(S3等)にネイティブに格納 し、インテリジェントなキャッシュで高速化します。「ストレージは安いS3、速度はキャッシュで」という割り切りが、コストを劇的に下げる源泉です。
この「安さ」と「速さ」を両立させる仕組みを、データの流れで見ると分かりやすくなります。
OTLP(ログ/メトリクス/トレース)"] --> PARQ["Parquet列指向に変換
高圧縮・分析向き"] PARQ --> S3["S3にネイティブ格納
安価なオブジェクトストレージ"] S3 --> IDX["パーティション+索引+
スマートキャッシュ"] IDX --> Q{"クエリ
SQL / PromQL"} Q --> RES["結果
探索空間を最大99%削減"]
さらにOpenObserveは、パーティショニング・インデックス・スマートキャッシュ によって、多くのクエリで 探索空間を最大99%削減 します。S3は遅いという常識を、賢いキャッシュとインデックスで覆し、結果として Elasticsearch比1/4のハードウェアで、より高速な検索・分析 を実現するとしています。加えて ステートレス・アーキテクチャ により、ノードを素早く再起動でき、S3の 11ナイン(99.999999999%)の耐久性 がデータ保全を担保します。低RPO/RTOの災害復旧も、この設計の副産物です。
注意したいのは、140倍という数字は 公式の主張 であり、実際の削減率はワークロード(データ量・クエリパターン・保持期間)によって変わる点です。とはいえ、Parquet+S3という設計自体は、近年のデータ基盤で広く採られている合理的なアプローチであり、「安さの理屈」が明確である点は信頼に足ります。導入時は、自社の代表的なワークロードでコストを実測して比較するのが堅実です。
3. 何を統合するのか — Logs / Metrics / Traces / RUM
OpenObserveの第二の価値は、「1つのプラットフォームで全部」 という統合性です。バラバラだった監視を、1基盤に束ねます。
READMEが挙げる主要機能を見ていきましょう。
・ログ管理:全文検索・SQLクエリ・強力なフィルタを備えた集中ログ管理。Parquet列指向で140倍低コスト。クイックフィルタとクエリビルダで全ログを即座に検索でき、ログからダッシュボードを作りアラートも設定できる
・分散トレース:OpenTelemetry由来。マイクロサービスの問題切り分けに不可欠で、フレームグラフやガントチャートでユーザーリクエストをサービス横断で追跡し、ボトルネックを特定する
・メトリクスとダッシュボード:インフラやアプリのメトリクスを取り込み、19以上の組み込みチャート(200以上の可視化バリエーション)でダッシュボード化。SQLまたはPromQLで照会し、複数クエリを数式で組み合わせられる
・フロントエンドモニタリング(RUM):パフォーマンス追跡・エラーログ・セッションリプレイで、実ユーザーの体験を把握する
・アラート:任意のテレメトリ信号(ログ・メトリクス・トレース)に閾値を設定し通知。アラート履歴や異常検知も
・パイプライン:取り込み時にデータを加工(エンリッチ・秘匿・削減・正規化)。ログからメトリクスへの変換などをストリーム処理で行い、外部ツールが不要
この統合性が効くのは、「障害調査でツールを行き来しなくて済む」 からです。あるサービスのレイテンシ悪化に気づいたら(メトリクス)、その時間帯のトレースを見てボトルネックを特定し(トレース)、該当サービスのログで詳細を確認する(ログ)——という一連の調査を、同じプラットフォーム上で、同じSQLで 行えます。READMEがGrafanaスタック(Grafana+Loki+Prometheus+Tempo)との比較で強調するのも、まさにこの点です。複数ツールを継ぎ接ぎする代わりに、1つに統合することで、運用の認知負荷とツール間連携の手間を減らせます。さらにLokiが苦手とする高カーディナリティ(ラベルの組み合わせが膨大なケース)にもフル対応する、としています。
統合のもう一つの恩恵が パイプライン機能 です。取り込み時にデータをエンリッチ(情報付加)・秘匿(PII除去)・削減・正規化でき、ログからメトリクスへの変換といったストリーム処理も外部ツールなしで行えます。従来であれば、Fluentd・Logstash・Vectorといった別ツールを前段に挟んでいた処理が、OpenObserve内で完結します。「取り込みの整形」と「保存・検索・可視化」が同じ基盤に乗ることで、データの流れ全体を1つの製品で見通せるようになる——これは運用設計をシンプルに保つうえで、地味ながら大きな価値です。テレメトリの“前処理から分析まで”を一気通貫にできる点で、OpenObserveは単なる「保存・検索エンジン」を超えた統合プラットフォームを志向しています。
4. 他ツールとの比較 — Datadog / Elasticsearch / Splunk
OpenObserveの立ち位置を、主要な競合との比較で明確にしましょう。READMEには、各ツールとの比較表が丁寧に掲載されています。
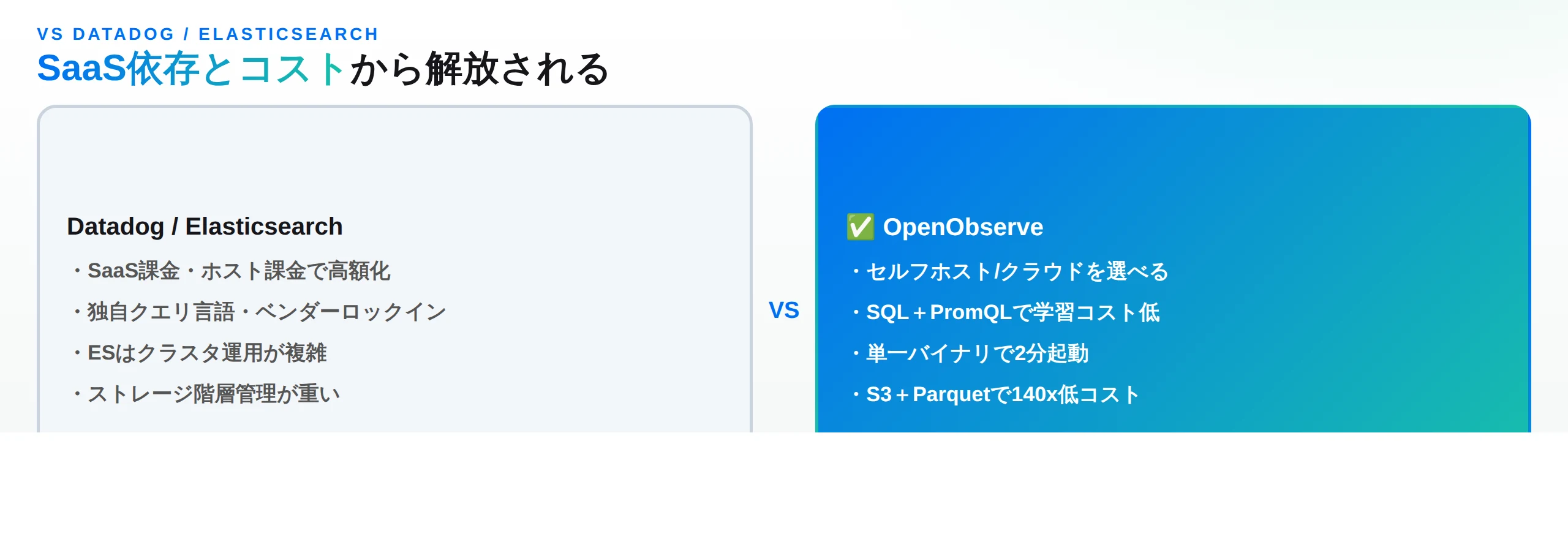
主要な観点を一覧に整理すると、次のようになります。
| 観点 | OpenObserve | Datadog | Elasticsearch |
|---|---|---|---|
| デプロイ | セルフホスト/クラウド | SaaSのみ | 複雑なクラスタ管理 |
| オープンソース | Yes(AGPL-3.0) | No | 一部 |
| クエリ言語 | SQL+PromQL | 独自 | Lucene/KQL |
| ストレージコスト | 基準(140x低い) | ホスト課金+GB課金 | 高い(階層管理) |
| ベンダーロックイン | なし | 高い | 中 |
| ハード要件 | 1/4(ES比) | — | 高メモリ/CPU |
表から見えるのは、OpenObserveの差別化が 「コスト」と「ロックインからの自由」 に集約されることです。Datadogに対しては、SaaS課金・ホスト課金の高騰と独自クエリ言語・ベンダーロックインからの解放。Elasticsearchに対しては、140倍低いストレージコストと単一バイナリの簡便さ、SQLの分かりやすさ、1/4のハードウェア。Splunkに対しては、オープンソースで予測可能な低コスト。そしてGrafanaスタックに対しては、複数ツールを束ねる代わりの単一プラットフォーム化と高カーディナリティ対応です。
ライセンスは押さえておくべき重要事項です。オープンソース版はAGPL-3.0 で、READMEは「OpenObserveへの改善がオープンソースとしてコミュニティに還元されることを保証するため」とこのライセンスを選んだ理由を説明しています。商用利用も無料で可能ですが、AGPLの性質(ネットワーク経由の利用にもソース開示義務が及び得る)は理解しておく必要があります。一方、SSO・高度なRBAC・センシティブデータ秘匿(SDR)・フェデレーテッドサーチ・監査ログ といったエンタープライズ機能は、AGPLではない商用ライセンスの Enterprise版 で提供されます。READMEは「オープンソース版は機能完備で本番対応」と明言しており、まずはOSS版で十分に評価できます。
5. セットアップと使い方 — Docker と Cloud
実際に始める方法を確認します。OpenObserveは、その看板である「2分起動」を、複数の経路で提供します。

経路①:OpenObserve Cloud(最速)。インフラを管理したくないなら、クラウド版が最も手軽です。数分で始められ、1日あたり最大50GBの取り込みまで無料(登録が必要)の無料枠が用意されています。まず触ってみるならこれが簡単です。
経路②:Docker(セルフホスト)。自分で動かすなら、Dockerが手軽です。ルートユーザーのメールとパスワードを環境変数で渡し、5080番ポートで起動します。
docker run -d \
--name openobserve \
-v $PWD/data:/data \
-p 5080:5080 \
-e ZO_ROOT_USER_EMAIL="[email protected]" \
-e ZO_ROOT_USER_PASSWORD="Complexpass#123" \
public.ecr.aws/zinclabs/openobserve:latest
起動後、ブラウザで http://localhost:5080 を開けば、Web UIからログ検索・トレース・ダッシュボード・アラートを操作できます。クラスタ構築は不要で、データを取り込み始めればすぐに使えます。テレメトリは OpenTelemetry(OTLP) で送るのが基本で、既存のOpenTelemetry SDKやコレクタからそのまま流し込めます。
経路③:高可用性(HA)モード。ミッションクリティカルな用途には、クラスタリングによるHAモードがあります。ステートレス・アーキテクチャとS3バックのストレージにより、最大のアップタイムと性能を確保しつつ、ペタバイト規模にスケールできます。READMEによれば、最大級のデプロイでは 1日あたり2PB超 を取り込み、単一バイナリでもテラバイト規模にスケールする(これはオブザーバビリティ業界で独自、とされる)実績があります。小さく始めて大きく育てられる——これがOpenObserveの運用面での強みです。
操作の体感としては、「SQLが分かれば使える」 のが大きい。ログもトレースもSQLで、メトリクスはSQLまたはPromQLで照会できるため、独自クエリ言語の学習が要りません。READMEのFAQも「ほとんどのユーザーは数週間ではなく数時間で生産的になれる」としています。ドラッグ&ドロップのダッシュボードビルダーや活発なSlackコミュニティも、立ち上がりを後押しします。
6. AI時代の使いどころ — LLMオブザーバビリティ
最後に、本サイトの読者に最も関わる 「AIアプリの運用基盤としてのOpenObserve」 を見ておきましょう。

OpenObserveのリポジトリ説明文には、明確に 「LLMオブザーバビリティ」 が含まれています。AIアプリ、とりわけLLMを組み込んだシステムの運用では、従来とは異なる監視課題が生まれます。LLM呼び出しのレイテンシ(生成は遅くなりがち)、トークン消費とコスト(リクエストごとに費用が変動)、エラーやリフューザル(モデルが拒否・失敗するケース)、プロンプトとレスポンスの追跡——これらを可視化しないと、AIアプリの品質もコストも制御できません。
OpenObserveは OpenTelemetryネイティブ なので、LLM呼び出しのトレースをOTLPで送れば、他のテレメトリ(APIのログ、インフラのメトリクス)と同じ基盤で一元的に分析 できます。たとえば「特定のエンドポイントでLLMレイテンシが悪化している→そのトレースを追うと特定モデルの呼び出しが遅い→該当時間帯のトークン消費が急増していた」といった調査を、1つのプラットフォーム上で完結できます。AIアプリのコストとレイテンシは運用の生命線であり、それを安価に・統合的に可視化できる受け皿として、OpenObserveは有力な選択肢です。
注意点 も押さえておきましょう。第一に、データはイミュータブル(取り込み後は変更・個別削除できず、保持期間単位での破棄のみ)です。READMEはこれを「ログやコンプライアンス用途ではむしろ機能(データ完全性・監査証跡の担保)」と説明していますが、設計上の前提として理解が必要です。第二に、エンタープライズ機能(SSO・高度なRBAC・SDR等)は商用版であること。第三に、OSS版はAGPL-3.0 であり、ライセンスの性質を踏まえた利用判断が要ること。これらを理解したうえでなら、OpenObserveは「AI時代の監視を、安く・統合的に・ロックインなしで」始めるための、極めて実用的な基盤になります。
OpenObserveは、ログ・メトリクス・トレース・RUMを1つに統合する、Rust製・OpenTelemetryネイティブのOSSオブザーバビリティ基盤です。Parquet列指向+S3ネイティブにより、Elasticsearch比140倍の低ストレージコスト(公式主張)と、単一バイナリで2分起動という簡便さを両立。SQL+PromQLで扱え、Datadog/Splunk/ES/Grafanaスタックの代替になります。OpenTelemetryネイティブゆえLLMオブザーバビリティを含むトレース集約にも対応し、AIアプリのコスト/レイテンシ可視化の受け皿にもなります。一方、データはイミュータブル、SSO等は商用エンタープライズ版、OSSはAGPL-3.0という前提は要確認。監視ツールの行き来とSaaS課金の高騰に疲れたなら、まずDockerかCloud無料枠で、その「安さ×統合×ロックインなし」を確かめてみてください。
まとめ
本記事では、オープンソースのオブザーバビリティ基盤 OpenObserve を、監視の分断とコスト高騰を解く道具として読み解きました。
要点は3つです。第一に、OpenObserveはログ・メトリクス・トレース・RUMを1基盤に統合し、Datadog/Splunk/ESの複雑さとコストの代替を狙うこと。第二に、Parquet列指向+S3ネイティブという設計で、Elasticsearch比140倍の低ストレージコストと単一バイナリの簡便さを両立し、SQL+PromQLで独自クエリ言語を不要にすること。第三に、OpenTelemetryネイティブゆえにLLMオブザーバビリティを含むトレース集約に対応し、AIアプリ運用の土台にもなる一方、データのイミュータブル性・エンタープライズ機能の商用化・AGPLライセンスという前提は理解が必要なこと。
監視を「複数ツールの寄せ集め」から「1つの安価な統合基盤」へ——OpenObserveが示すのは、オブザーバビリティのコストと複雑さに対する、現実的な回答です。AIアプリの運用も視野に入れるなら、まずは無料で、その実力を試してみる価値があります。とりわけLLMを組み込んだサービスを運用しているなら、レイテンシ・トークン・コストの可視化を、既存の監視と同じ基盤で・安価に始められる点は、検討に値する強みです。OpenTelemetryで送るだけ、という導入の軽さも、最初の一歩を後押ししてくれます。
参照ソース
・openobserve/openobserve(公式リポジトリ) — 本記事が解説した一次情報(README・機能・比較表)
・OpenObserve Documentation(公式ドキュメント) — セットアップ・運用の詳細
・OpenObserve Architecture(公式・アーキテクチャ解説) — Parquet+S3設計・140倍低コストの根拠