Statewrightは、コーディングエージェントに状態機械ガードレールを追加するRust製OSSだ。planning→implementing→testing→completedという「フェーズ」を定義し、各フェーズで呼べるツールをMCPとフックでプロトコル層から制限する。
Claude Code全般の設定・運用については AIエージェントフレームワーク比較2026:LangChain・CrewAI・AutoGen徹底解説 をご覧ください。
“Agents are suggestions, states are laws” — なぜ状態機械なのか
AIエージェントがプロダクション環境でフラつく理由は、モデルの性能ではなく「ツール空間が広すぎる」こと――これがStatewrightの出発点だ。
Claude Codeに40以上のツールを与えて「このバグを直して」と指示すると、何が起きるか。モデルは同じファイルを5回読み直し、レビューフェーズでEditを呼び、テストが通る前にデプロイしようとする。こうした「問題の広がり方」はプロンプトをいくら工夫しても抑制しにくい。なぜならLLMは確率的な次トークン予測であり、今自分が「どのフェーズ」にいるかを会話コンテキストだけで正確に把握し続けることには根本的な限界があるからだ。
Statewrightの解法は「モデルを大きくするのではなく、問題を小さくする」だ。公式READMEにはこう書かれている。
State machines constrain the tool and solution spaces so the model reasons in a focused context at each step. A planning state gets read-only tools. When the agent transitions to implementation, edit tools unlock with limited shell access.(公式READMEより)
許可されていないツールを呼び出すと、エージェントは「今利用可能なツールと遷移方法」を示したエラーメッセージを受け取る。ランダムな失敗ではなく、正しいパスへの誘導だ。さらにDAG(有向非巡回グラフ)と異なり、状態機械はループとリトライを本来サポートする。エージェントのワークは「テストが落ちたら実装に戻る」という反復構造を当然含むため、これは根本的な設計上の優位性になる。
SWE-benchで2/10→10/10 — 研究結果の読み方
公式READMEに記載された実験結果を正確に理解するには、前提を押さえる必要がある。
Statewrightが提示するのはSWE-benchの全2,294インスタンスではなく、内部で選定した5タスクのサブセットだ。同じタスクを同じハードウェアで、ガードレールあり・なしで比較した。
モデル別結果
| モデル | サイズ | 26行バグ修正 | SWE-bench 5タスク |
|---|---|---|---|
| gemma3 | 3.3GB | FAIL | FAIL |
| gemma4:e2b | 7.2GB | PASS* | FAIL |
| gpt-oss:20b | 13.8GB | PASS | PASS (5/5) |
| gemma4:31b | 19.9GB | PASS | PASS (5/5) |
| llama3.3 | 42.5GB | PASS | PASS (2/2)† |
(*specialized edit_line tool adaptationあり) (†5タスク中2タスクのみで検証)
重要な発見は「13GBが閾値」という点だ。それ以下のモデルはバグを正しく特定できるが、「外科的編集」をシリアライズできない。ファイル全体の書き直しを試みて失敗する。これはStatewrightの問題ではなく、モデル自体の制約だ。
13GB以上のモデルでStatewrightが示した構造的な効果は2つある。「同じファイルを繰り返し読むループ死の阻止」と「ツール空間を絞り込むことによるモデルの推論改善」だ。planning状態ではRead/Grep/Globのみ、implementing状態ではEdit/Writeのみ――各フェーズで見えるツールが5個以下になることで、モデルが「今すべきこと」に集中できる。
Rustエンジンの設計とガードレール
StatewrightのコアはRustで書かれた決定論的エンジンだ。状態機械定義(states・transitions・guards・tool restrictions)を評価するが、そのロジック自体にLLMは一切使われていない。
statewright_start"] --> B["planning状態
Read / Grep / Glob のみ"] B --> C{"READY遷移
statewright_transition"} C -->|"READY"| D["implementing状態
Read / Edit / Write
max_edit_lines: 20"] D --> E{"DONE遷移
statewright_transition"} E -->|"DONE"| F["testing状態
Read / Bash
pytest / cargo test のみ"] F --> G{"テスト結果"} G -->|"PASS + tests_passed guard"| H["completed状態
Final"] G -->|"FAIL_TEST"| D H --> I["ワークフロー完了
46秒"] B -->|"ツール外呼出し"| B2["拒否メッセージ
利用可ツール案内"] B2 --> B
エンジンの上に乗るのがプラグイン層だ。ワークフローをアクティブにすると、フックがツール制限を状態ごとに強制する。モデルには30ツールではなく5ツールが見える。現在のフェーズに対する明確な指示と、条件が満たされたときの遷移ルールが与えられる。
Claude Codeのハーネス設計(5層モデル・queryLoop)については、ハーネスエンジニアリング完全解説をご覧ください
ガードレール9種類の詳細
Statewrightが提供するガードレールは9カテゴリに分類される。「単なるallow-list」ではなく、実際のプロダクション利用を想定した設計だ。
| ガードレール | 動作 |
|---|---|
| per-state tool enforcement | allowed_toolsに含まれないツールはエージェントから見えない・呼べない |
| Bash discernment | Bash許可時でも echo > file / rm -rf / sed -i / python・node等のインタープリタをブロック |
| Edit guards | max_edit_linesを超えるdiff・状態ごとのファイル編集数上限を適用 |
| Command allow-lists | prefix一致コマンドのみ実行(例: pytest / cargo test / npm test) |
| Conditional transitions | コンテキストデータへのプログラム的ガード(test_result eq pass / coverage gt 80) |
| Approval gates | requires_approvalで人間レビューのために一時停止 |
| Interrupts | 特定globパターンのファイルを編集したとき自動でバリデーション状態に遷移し、完了後に元の状態へ戻る |
| Fork/join | ブランチを直列・並列実行し、すべて(またはいずれか)が完了したときにjoin |
| Environment scoping | blocked_envで本番DB URLを隠蔽、env_overridesでテスト用値に差し替え |
Bash discernmentが重要なのは「Bashを許可する=何でもできる」という思い込みを壊すからだ。testing状態でBashを許可していても、python -c "import shutil; shutil.rmtree('/prod')" のようなスクリプト実行はブロックされる。allowed_commandsで許可したprefixのみが通過する。
Cursorはハードではなくアドバイザリ強制だ。MCP + rulesでルールをコンテキストに注入するが、Cursorのアーキテクチャ上、ツール呼び出しをMCPだけで阻止できない。モデルがルールを無視する可能性が残る。確実な強制にはClaude Code・Codex・Pi・opcodeを使う。
ワークフロー定義とインストール
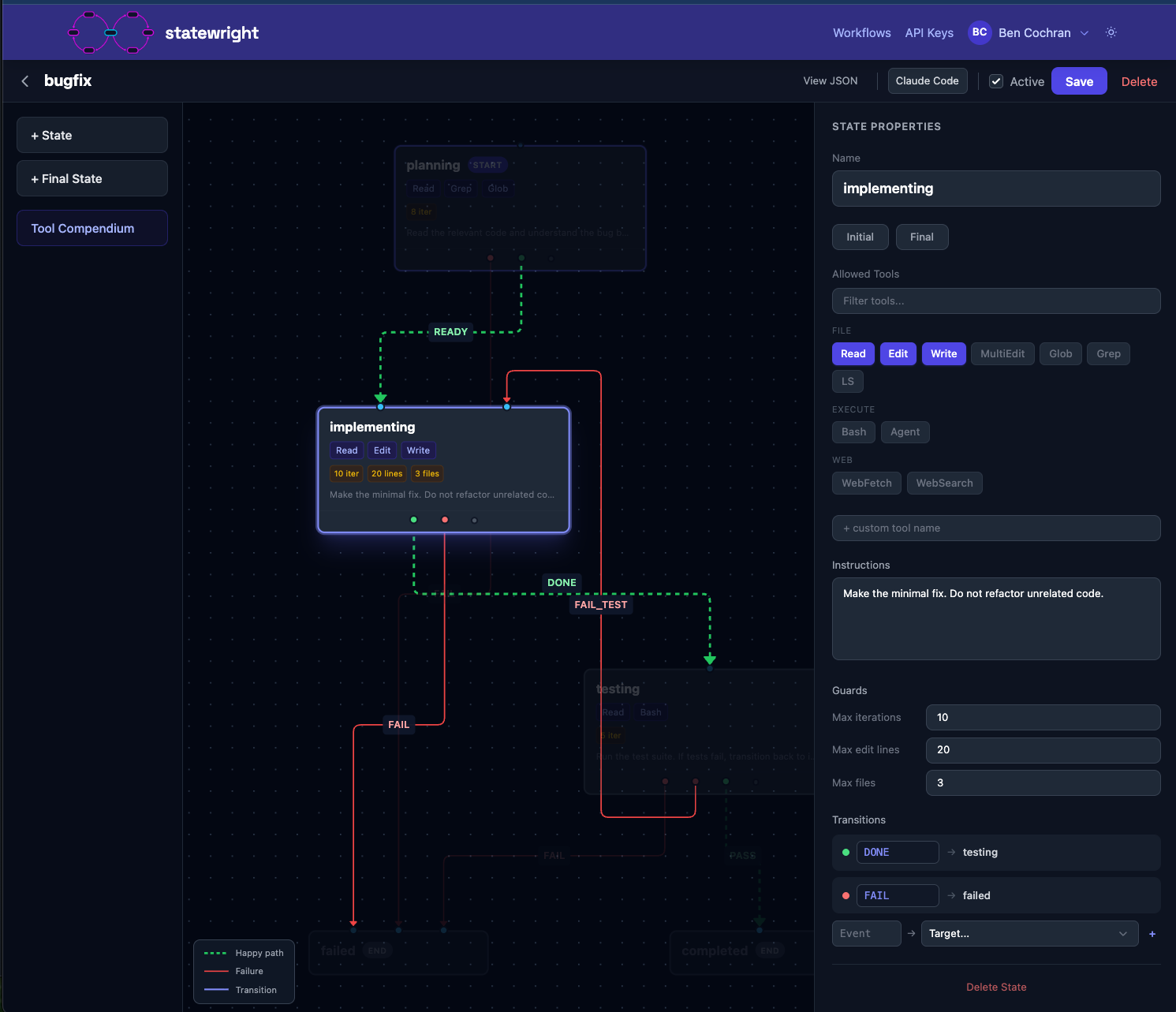
StatewrightのワークフローはJSONファイルで定義する。エージェント自身が statewright_create_workflow ツールで生成することも、ビジュアルエディタで編集することもできる。
JSONスキーマ — 基本バグ修正ワークフロー
{
"id": "bugfix",
"initial": "planning",
"states": {
"planning": {
"allowed_tools": ["Read", "Grep", "Glob"],
"max_iterations": 8,
"on": { "READY": "implementing" }
},
"implementing": {
"allowed_tools": ["Read", "Edit", "Write"],
"max_edit_lines": 20,
"max_files_per_state": 3,
"on": { "DONE": "testing" }
},
"testing": {
"allowed_tools": ["Read", "Bash"],
"allowed_commands": ["pytest", "cargo test", "npm test"],
"on": {
"PASS": { "target": "completed", "guard": "tests_passed" },
"FAIL_TEST": "implementing"
}
},
"completed": { "type": "final" }
},
"guards": {
"tests_passed": {
"field": "test_result",
"op": "eq",
"value": "pass"
}
}
}
各フィールドの意味
- id: ワークフロー識別子。
/statewright start bugfixで参照する - initial: 起動時の初期状態
- states[].allowed_tools: このフェーズでエージェントが見えるツール名の配列
- states[].max_iterations: 1フェーズに留まれる最大ツール呼び出し回数
- states[].max_edit_lines: Editツールで変更できる最大行数
- states[].max_files_per_state: 1フェーズで編集できるファイル数上限
- states[].allowed_commands: Bashを許可する際のコマンドprefix allow-list
- on: イベント名→遷移先状態のマッピング(guardを付けると条件遷移)
- guards: フィールド・演算子・値のトリプルで遷移条件を定義
statewright_create_workflow ツールに自然言語で要件を伝えると、公式JSONスキーマに従ったワークフローが生成される。生成されたJSONは statewright.ai のビジュアルエディタで調整できる。過度に制限的なワークフローでエージェントが詰まった場合は statewright_deactivate で解除できる。
Claude Codeへのインストールと起動
# Claude Code へのインストール
/plugin marketplace add statewright/statewright
/plugin install statewright
# ブラウザが開く → statewright.ai でサインアップ → キー生成 → 貼り付け → 完了
# ワークフロー起動(自然言語)
# start the bugfix workflow — fix the failing tests in calc.py
# スラッシュコマンドでも起動可能
/statewright start bugfix
対応エージェントとEnforcement
Statewrightはハード強制(プロトコル層でツール呼び出しを阻止)とアドバイザリ強制(コンテキストにルールを注入するがモデルが無視できる)を区別して提供する。
| エージェント | 統合方式 | 強制種別 |
|---|---|---|
| Claude Code | Hooks + MCP | Hard(ハード強制) |
| Codex | Hooks + MCP | Hard |
| Oh My Codex | Hooks + MCP | Hard |
| Pi | TypeScript extension | Hard* |
| opencode | TypeScript plugin | Hard(alpha) |
| Cursor | MCP + rules | Advisory(アドバイザリ) |
(Piはローカルモデル向けにツール名正規化・ツール呼出しリカバリを含む)
Claude CodeへのHard強制がStatewrightの中核的ユースケースだ。ClaudeはMCPサーバーとフックの両方をサポートするため、ツール呼び出しをプロセス間通信レベルで評価・拒否できる。モデルに「このツールは今使えない」と伝えるだけでなく、実際に呼び出しを阻止する。
Pi(旧Pythagora)はローカルモデル利用が多く、ツール名がモデルごとに異なる問題をツール名正規化で吸収している。OllamaやLM Studioで動かすローカルモデルがStatewrightの恩恵を受けるには、まず13GB閾値をクリアする必要があるが、それをクリアしたモデルには状態機械の構造的制約が有効に働く。
ハーネスエンジニアリング・12-Factor Agentsとの補完関係
ハーネスエンジニアリングとの接続点
ハーネスエンジニアリング(Claude Codeの5層モデルとqueryLoop設計) の文脈でStatewrightを見ると、その位置づけが明確になる。
ハーネスエンジニアリングは「エージェントのインフラ層」の設計論だ。ループ管理・コンテキスト予算・ツール定義をハーネスが担うことで、モデルは「何を言うか」に集中できる。Statewrightはその設計思想をさらに進め、「ループ内で何を呼べるか」をフェーズ単位で動的に変える。
ハーネスエンジニアリングがqueryLoop()という「時間軸」でコンテキストを管理するとすれば、Statewrightは「状態軸」でツール空間を管理する。両者は競合せず、補完する。
ハーネス設計で頻出する失敗パターンが「同じファイルを繰り返し読み続けてコンテキストを使い切る」read-loop死だ。planning状態のmax_iterationsを8に設定するだけで、このスパイラルを構造的に阻止できる。
12-Factor Agentsとの補完関係
12-Factor Agents(humanlayer/12-factor-agents) はLLMエージェントを本番投入するための12原則を定義している。StatewrightはそのFactor 3「コンテキストウィンドウを所有する」とFactor 8「制御フローを所有する」をランタイムレベルで実装するツールとして位置づけられる。
12-Factor AgentsのFactor 8は「制御フローはLLMではなくコードが所有せよ」と主張する。Statewrightの状態機械はまさにこの原則の具体実装だ。どのフェーズで何のツールを使えるか、いつ次のフェーズに遷移するかはRustエンジン(コード)が決定する。LLMは各フェーズ内でのツール選択を担うが、フェーズ遷移そのものはguardとイベントで決定論的に制御される。
Factor 3「コンテキストウィンドウを所有する」との対応はより間接的だ。allowed_toolsを絞ることで、モデルが見るツール説明文の量が減る。30ツールのsystem promptと5ツールのsystem promptでは、有効なコンテキスト長が大きく異なる。これはコンテキスト予算の節約であり、longer contextが必要な実装ステップのためにトークンを温存する効果がある。
| 12-Factor原則 | Statewright実装 |
|---|---|
| Factor 3: コンテキストを所有する | allowed_toolsを絞ることで各フェーズのtool descriptionを削減 |
| Factor 5: 実行状態とビジネス状態を統一 | ワークフロー状態(planning/implementing/testing)がエージェント実行状態と一致 |
| Factor 8: 制御フローを所有する | 遷移ルール・guardをRustエンジンが評価(LLMが決定しない) |
| Factor 9: コンパクトなエラーで自己修正 | ガードレール違反時に「今使えるツールと遷移方法」を含むエラーを返す |
Statewrightが解くのは「エージェントにポリシーを伝える」問題ではなく「ポリシーを物理的に強制する」問題だ。プロンプトでいくら「testing状態になるまでEditを使うな」と指示しても、確率的な次トークン予測はそれを保証しない。Rustエンジンはプロンプトではなくコードで保証する。
セルフホスト・料金・他ツールとの比較
セルフホスティングとライセンス
Statewrightのセルフホスト構成はPocketBase(データベース)・MCPゲートウェイ・ワークフローエディタの3コンポーネントだ。
docker composeで起動
cd self-hosted && docker compose up --build
# PocketBase / MCPゲートウェイ / ワークフローエディタが起動
# BYO Ollama でローカルモデルと統合可能
ライセンス構造
| コンポーネント | ライセンス | 注意 |
|---|---|---|
| crates/engine(Rustエンジン) | Apache 2.0 | 組み込み利用・依存関係なし |
| crates/agent(エージェント層) | Apache 2.0 | 同上 |
| MCPゲートウェイ | FSL-1.1-ALv2 | 2029年にApache 2.0へ転換 |
FSL(Functional Source License)は個人・シングルチームのセルフホストを許可する。SaaS再販・競合製品への組み込みは制限されるが、自社エージェントインフラへの統合は問題ない。エンジンとエージェント層はApache 2.0なので、状態機械のコア部分を自前スタックに組み込む用途に制限はない。
料金プランと選び方
マネージドクラウド(statewright.ai)は4プランを提供する。「Prices won’t go up」とREADMEに明記されている。
| プラン | ワークフロー数 | 月間遷移回数 | 実行履歴 | 価格 |
|---|---|---|---|---|
| Free | 3 | 200 | 72時間 | $0 |
| Pro | 10 | 2,500 | 7日 | $29/月 |
| Team | 30 | 10,000 | 90日 | $99/月 |
| Enterprise | 無制限 | 無制限 | 仕様による | 要問合せ |
Freeは個人が3つのワークフローを試すのに十分だ。月200遷移はbugfixワークフロー(planning→implementing→testingが3遷移)換算で約66回の完全サイクルに相当する。本番チームで日次利用するならTeamが現実的だ。
セルフホストを選ぶ判断基準は「カスタムワークフロー数の多さ」と「実行履歴の保存要件」だ。エンジンとエージェント層はApache 2.0なので、コアをフォークして独自拡張することも可能だ。
個人開発者・OSS貢献:Free(3ワークフローで主要パターンをカバー)
スタートアップ(5人以下):Pro($29は開発者1人のツール費としてCPがある)
エンジニアリングチーム:Team(90日の実行履歴でワークフロー改善が可能)
大規模・コンプライアンス要件あり:Enterprise or セルフホスト
他のエージェントオーケストレーターとの比較
Statewrightは単体のエージェントオーケストレーターではなく、既存エージェントに状態機械ガードレールを追加するレイヤーとして設計されている。同カテゴリの製品と比較する前に、この設計上の差異を理解する必要がある。
複数エージェントの並列実行を扱うOrcaとの違いについては、こちらの記事を参照
| 比較軸 | Statewright | 従来のオーケストレーター | プロンプトエンジニアリング |
|---|---|---|---|
| 強制方式 | Rustエンジン(ハード) | フレームワーク(ソフト) | プロンプト(最弱) |
| 適用対象 | 既存エージェントへのレイヤー追加 | エージェント自体の構築 | 単一モデル呼び出し |
| ループ対応 | ネイティブ(状態機械はループを本来持つ) | DAGは原則非循環 | モデル依存 |
| 決定論性 | Rustエンジンで保証 | フレームワーク実装依存 | なし |
| モデル依存性 | 低(13GB以上ならモデル非依存) | 高(フレームワークがモデルを規定) | 高 |
| 導入コスト | プラグイン1行 + JSON定義 | フレームワーク移行 | プロンプト編集のみ |
最大の差別化は「導入コスト」と「強制の確実性」のトレードオフを解消している点だ。プロンプトエンジニアリングは導入コストが最低だが強制が最弱。フレームワーク移行は強制が強いが導入コストが高い。StatewrightはJSON定義1つとプラグイン追加でHard強制を提供する。
Statewrightが示す設計の方向性
Statewrightの発表とSWE-bench結果が示すのは、AIエージェントの性能向上に「より大きなモデル」以外のパスが確立されつつあるという事実だ。
13GBモデルが2/10→10/10に改善したということは、このサイズのモデルはすでにタスクを理解する能力を持っているが、実行を正しく構造化できていなかったことを意味する。状態機械が提供するのは、その「構造化」だ。
ハーネスエンジニアリングが「エージェントを支えるインフラ設計」を議論し、12-Factor Agentsが「本番品質に至る12の設計原則」を提示するのに対して、Statewrightは「それらの原則をランタイムで強制するツール」として位置づけられる。3者は設計レイヤーが異なり、組み合わせることで相乗効果が生まれる。
公式GitHubではstatewright_create_workflowツールを使ってエージェント自身がワークフローを生成するというメタ的な使い方も文書化されている。エージェントが自分の制約を定義するという逆説的な構造が、Statewrightの設計哲学の象徴でもある。