Anthropicが2026年5月に開催した「Code with Claude」カンファレンスのブレイクアウトセッションで、API知識チームのRaviが発表した内容が話題になっている。テーマは Claude Managed Agentsに新たに搭載されたMemoryとDreaming — AIエージェントがタスクをまたいで学習し、組織規模で知識を蓄積・改善し続けるための2層記憶アーキテクチャだ。
Rocketinは本番エージェントの初回エラーを 97%削減、Wise Docsはクロスセッションメモリで書類検証パイプラインの問題を解消、Harveyは法律ベンチマークの完了率を 6倍 に向上させた — これらが実測値として示された。
本記事では21分のセッション全体(字幕ベース)を徹底分析し、Memoryの設計思想・Dreamingの仕組み・APIの使い方までを解説する。
AIエージェントフレームワーク全体の比較は AIエージェントフレームワーク徹底比較2026:LangChain・AutoGen・CrewAI・Semantic Kernelの選び方 をご覧ください。
なぜ今「エージェントの記憶」が重要なのか

2024年のMCP(Model Context Protocol)リリースからはじまり、Agent SDK、Skillsと続いてきたAnthropicのエージェントプラットフォーム整備は、2025年にClaude Managed Agentsという形でひとつの到達点を迎えた。
Meterが2025年に発表した研究によれば、「エージェントが完了できるタスクの長さは7ヶ月ごとに倍増している」。コーディング補助から始まったエージェントは、今や何時間もかかるタスクをこなせるようになった。
しかし課題が残る。長時間タスクでのコンテキスト管理だ。
タスクをまたいだ学習がない場合、エージェントA・エージェントBはそれぞれ同じミスを独自に学習する。組織として共通の「経験」を蓄積できない。しかもエージェントが複雑なマルチエージェント構成に進化するほど、この「記憶のサイロ化」は深刻になる。
Memoryが解こうとしているのはこの問題だ。シンプルに言えば:
- 共通戦略と過去ミスから学習する
- アクセス可能なツール・コードベース・ファイルを学習する
- エージェント間で学習を転移する
メモリの進化:CLAUDE.mdからファイルシステムへ
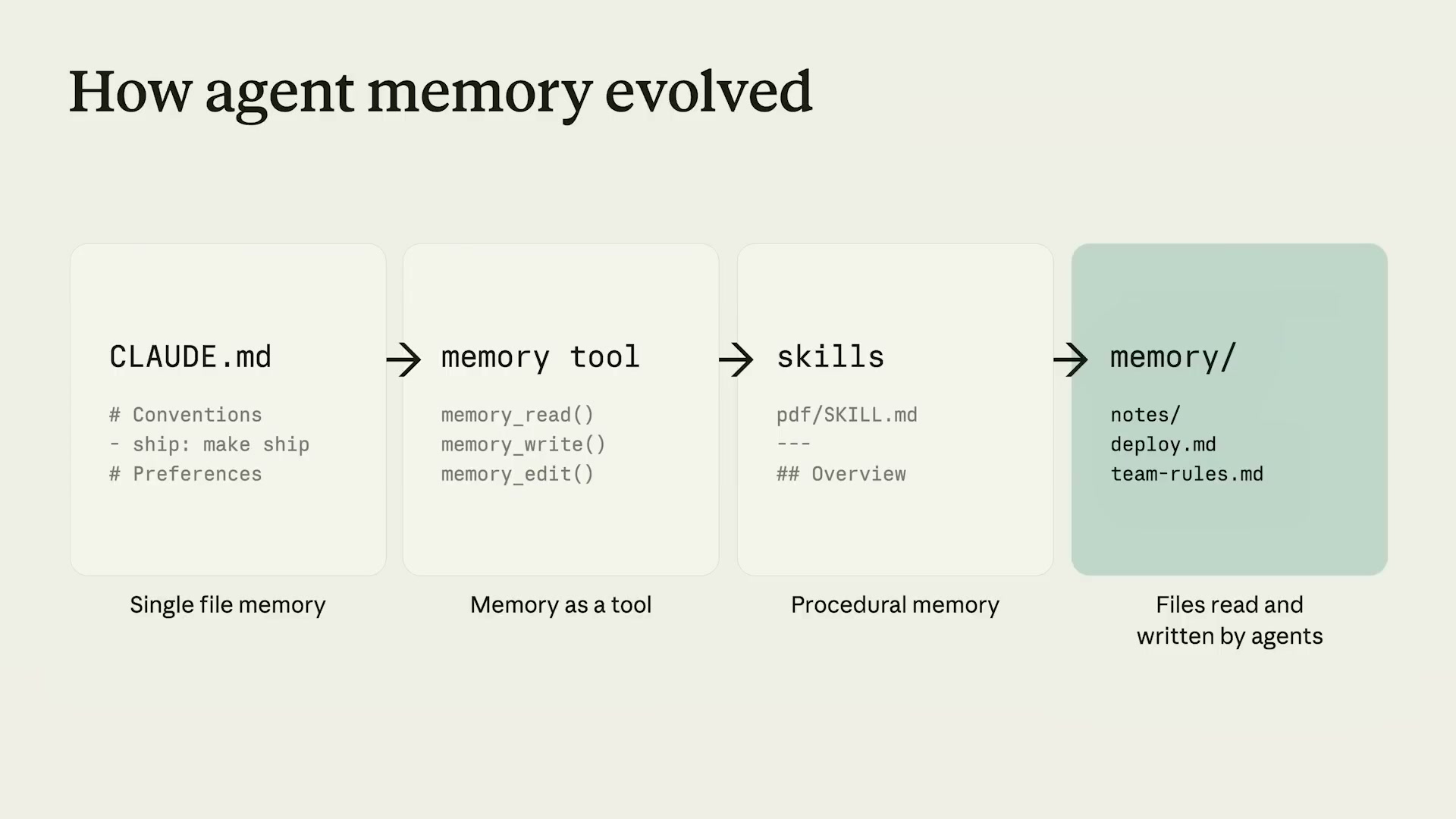
Anthropicのメモリアプローチは段階的に進化してきた。スライドが示す4段階の進化を整理する。
| 段階 | アプローチ | 特徴 |
|---|---|---|
| 1. Single file memory | CLAUDE.md | 規約・Preferences・コマンドを1ファイルに集約 |
| 2. Memory as a tool | memory_read/write/edit() | ツール呼び出しベースの読み書き |
| 3. Procedural memory | SKILL.md形式 | タスク固有の手順をスキルとして抽象化 |
| 4. Files read/written by agents | memory/ ディレクトリ | エージェントがファイルとして自由に読み書き |
重要な洞察は「モデルの能力が向上するにつれ、ハーネスがモデルの邪魔をしないようにすべきだ」という設計哲学だ。Skillsが高い柔軟性と汎用性を実現したように、Memoryもエージェントがすでに持っている能力(ファイル操作・Bash・glob)をそのまま活かす設計にした。
メモリアーキテクチャの3コンポーネント
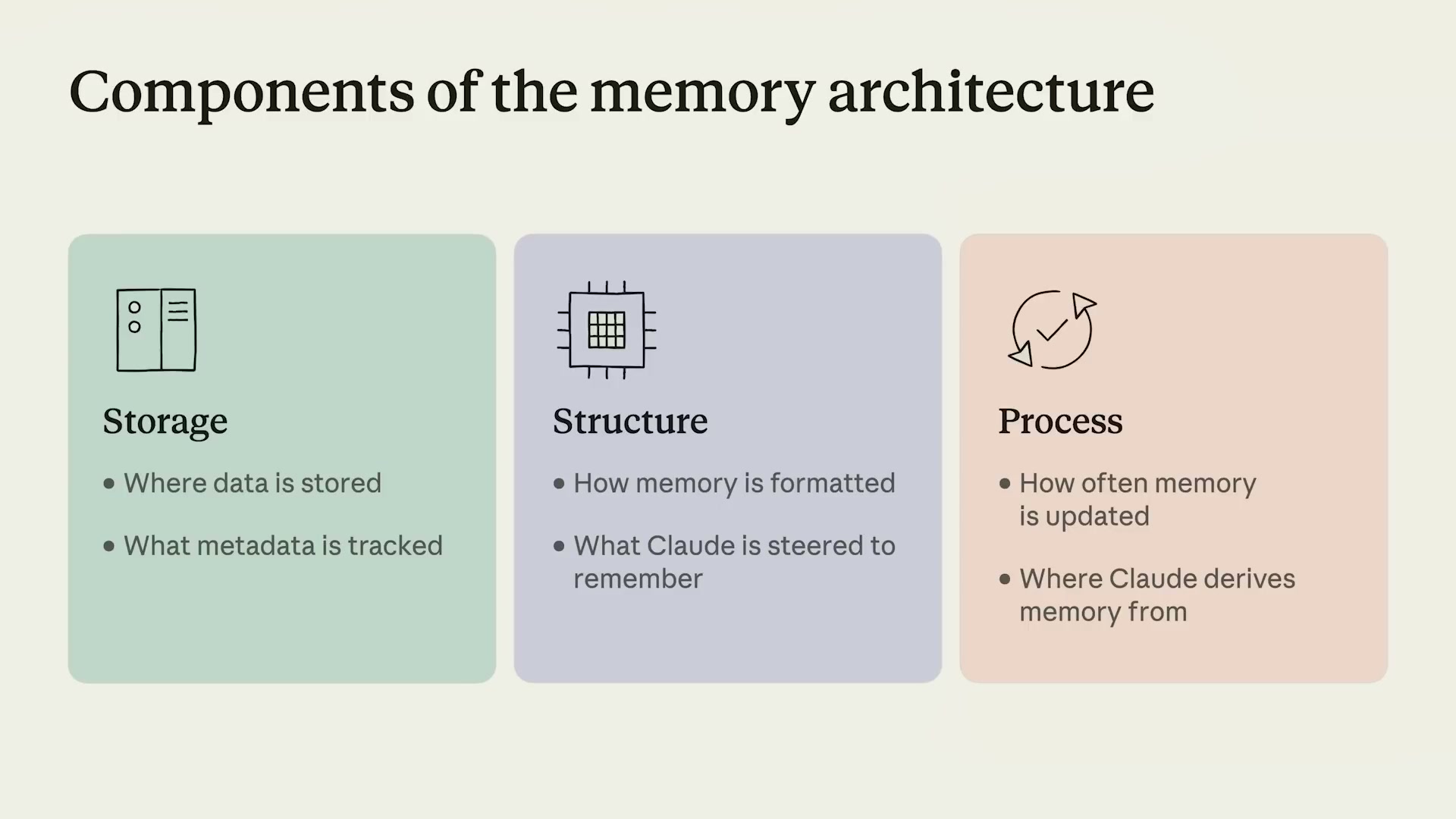
Memoryは3つの独立したコンポーネントで構成される。
Storage(保存層)
どこにデータを保存するか・何のメタデータを追跡するかを扱う。
Claude Managed AgentsのMemoryストアはAnthropicが管理するストレージに保存される。開発者はスタンドアロンAPIでどこからでもメモリを管理できる(エクスポート・リダクションなどのエンタープライズ向け操作も含む)。
Structure(構造層)
どのようにメモリをフォーマットするか・Claudeに何を記憶するよう誘導するかを扱う。
ファイルシステムとして表現されたメモリは、Claude自身がディレクトリ構造とファイル命名を判断する。どのコンテキストが将来の自分にとって最も重要かを選択し、どう構造化・表現するかも判断する — これはOpus 4.7が特に優れているタスクだ。
Process(処理層)
どのくらいの頻度でメモリを更新するか・どこからメモリを導出するかを扱う。
作業しながらメモを取るような「in-band更新」と、セッション外でバッチ処理する「out-of-band更新(Dreaming)」の2パターンが存在する。
ファイルシステムネイティブ設計 — Opus 4.7との親和性

Memoryをファイルシステムとして実装した理由は、現行モデルの強みを最大化するためだ。
Claudeは仮想環境・ファイルシステムのナビゲーションが得意だ。BashやGlobを使ったファイルの読み取り・更新・整理も得意だ。そしてOpus 4.7はファイルシステムベースのメモリ操作で最先端のモデルとして位置づけられ、将来の自分にとって何が重要かを判断する能力が格段に向上している。
設計原則は2つ:
- Filesystem-native(ファイルシステムネイティブ): 柔軟でエージェントに自然
- Steerable(誘導可能): プロンプトでメモリ動作をカスタマイズ
org-conventions/ のような読み取り専用のorganization-wide memoryから、team-memory/ のような読み書き可能なタスク固有メモリまで、用途に応じてスコープを使い分けられる。
マルチエージェント対応:スコープと楽観的同時実行制御

単一エージェント内でのメモリはシンプルだが、複数エージェントが同一環境で同時に動作するとなると新たな課題が生まれる。
スコープ設計(Read/Write Scopes)
1セッションに複数のメモリストアを異なるスコープでアタッチできる。
import anthropic
client = anthropic.Anthropic()
# セッション作成時にメモリストアをアタッチ
session = client.beta.managed_agents.sessions.create(
agent_id="sre-agent",
memory_stores=[
{
"id": "org-knowledge-store-id",
"scope": "read_only" # 組織全体のルールブック
},
{
"id": "team-sre-store-id",
"scope": "read_write" # チーム固有の作業メモリ
}
]
)
read-onlyストアには組織ポリシー・SLO・オンコールマッピングなど変更頻度が低く全エージェントが参照すべき情報を格納する。read-writeストアにはインシデントログ・調査メモ・「修正が進行中」フラグなど動的に更新される情報を格納する。
楽観的同時実行制御(Optimistic Concurrency Control)
複数エージェントが同じファイルを同時に更新しようとすると書き込み競合が発生する。Memoryはこれを楽観的同時実行制御で解決する。各書き込みには content_sha256 のpreconditionが付与され、他のエージェントが先に更新した場合は書き込みが拒否される。エージェントは最新版を読み直してからマージして再書き込みする。
この設計により、スウォームのように大量のエージェントが同一メモリに書き込んでも整合性が保たれる。
エンタープライズ制御:バージョン管理・帰属・ポータビリティ
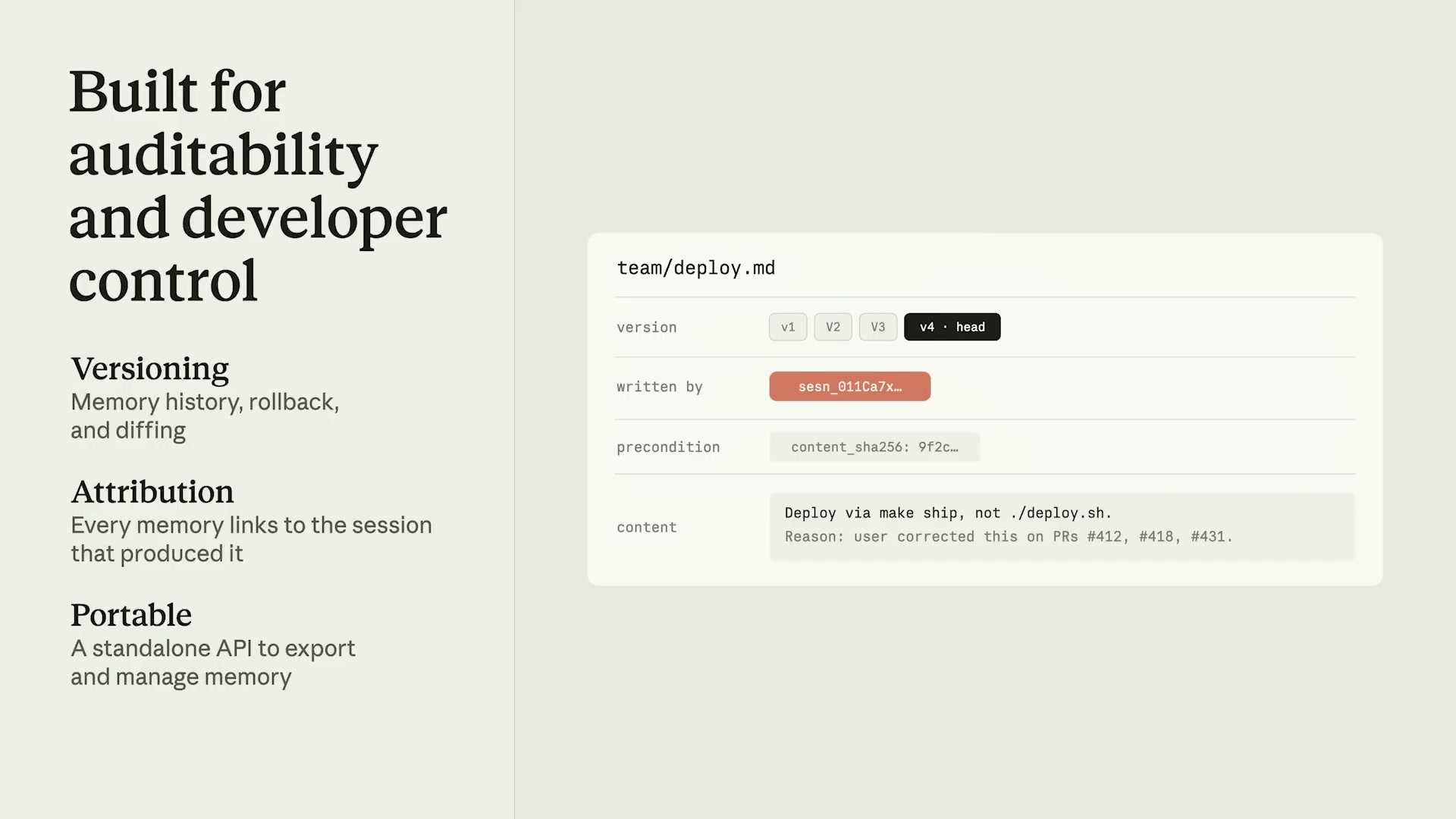
本番エージェントシステムでは「誰がいつ何を書いたか」の追跡が不可欠だ。Memoryは3つの軸でこれに対応する。
Versioning(バージョン管理)
メモリファイルはバージョン履歴付きで管理される。v1・v2・v3と変更が記録され、開発者はバージョン間のdiffを確認したり、ロールバックしたりできる。
Attribution(帰属追跡)
各メモリファイルには written by: sesn_011Ca7x... のようにどのセッションが書き込んだかが記録される。本番エージェントシステムでは「このルールはいつどのエージェントが学習したのか」を追跡できることが信頼性の基盤になる。
Portable API(スタンドアロンAPI)
メモリはAPIとして独立している。エージェント実行とは別に、どの環境からでもメモリの読み書き・エクスポート・リダクションが可能だ。
# メモリストアの作成
memory_store = client.beta.memory_stores.create(
name="team-sre-memory",
description="SREチーム固有の作業メモリ。ライブトリアージノート・既知の問題・インシデントタイムラインを格納。"
)
# メモリへの書き込み
client.beta.memory_stores.files.create(
store_id=memory_store.id,
content="dispatch-svc p99レイテンシスパイクの根本原因:retry_backoff_ms設定のデフォルト値が高すぎる。PR #4128で200→50に変更予定。",
path="known-issues/dispatch-latency.md"
)
# バージョン履歴の確認
history = client.beta.memory_stores.files.versions(
store_id=memory_store.id,
path="known-issues/dispatch-latency.md"
)
Dreaming:Out-of-bandによるグローバル記憶最適化
エージェントが作業しながらメモを取るin-band更新だけでは、いくつかの限界が見えてきた。
- エージェントが同じミスを独立して何度も学習する(重複学習)
- 学習が局所的に最適化されるが、グローバルには最適でない
- 複数のストア間でduplicationやfragmentationが発生する
これを解決するために開発されたのがDreamingだ。

Harveyのケースは象徴的だ。Claude Managed Agentsを使ってlong-form法律書類の起草・文書作成を自動化するHarveyは、Dreamingを有効にすることで法律ベンチマークの完了率を 約6倍に引き上げた(Niko Grupen、Harvey Head of Applied Research)。
Dreamingの仕組み

Dreamingは以下のサイクルで動作する。
セッション1] -->|トランスクリプト| D[Dreaming
バッチ処理] B[エージェントB
セッション2] -->|トランスクリプト| D C[エージェントC
セッション3] -->|トランスクリプト| D D -->|検証・整理・拡充| E[最適化された
メモリスナップショット] E -->|次回セッション| A E -->|次回セッション| B E -->|次回セッション| C D -->|サブエージェント並列解析| D
- 入力: 複数エージェントの日次セッショントランスクリプト
- 現在のメモリ状態の検査: 既存メモリの内容を把握
- 最適化提案: 非効率・ミス・改善が必要な箇所を特定
- 出力: 新しいインサイトと整理された構造を持つ検証済みメモリスナップショット
重要な点は、エージェントはこのスナップショットを採用するかどうかを選択できることだ。
# Dreamingの実行
dream = client.beta.dreams.create(
memory_store_ids=["team-sre-store-id"],
session_ids=[
"sess_01", "sess_02", "sess_03", "sess_04", "sess_05"
],
trigger="manual" # ad_hoc / nightly / hourly / session_end
)
# Dreamingセッションの状態確認
dream_status = client.beta.dreams.retrieve(dream.id)
print(f"Status: {dream_status.status}")
print(f"Sessions analyzed: {dream_status.sessions_analyzed}")
# 提案された差分の確認と採用
if dream_status.status == "completed":
client.beta.dreams.apply(dream.id)
Dreamingは管理エージェント自体がClaude Managed Agentsとして動作し、複数のサブエージェントがトランスクリプトを並列で解析する。Claude Consoleの「Dreams」タブからサブエージェントの進捗をリアルタイムで確認できる。
Out-of-band設計のメリット

Dreamingがエージェントループから切り離されていることには3つの明確なメリットがある。
1. マルチエージェント対応 単一エージェントの視点では見えないパターンを、クロスセッション・クロスエージェントのトランスクリプトを俯瞰して検出できる。
2. 目標の明確な分離 エージェントは「タスクを完了する」という目標に集中できる。メモリ品質の改善をタスク目標とトレードオフする必要がない。
3. ゼロレイテンシ Dreamingはエージェントのホットパスから完全に切り離されているため、エージェントの応答速度に影響を与えない。
デモ:SREオンコールシステムへの適用
Raviが示したデモは、実際のユースケースとしてSREオンコールシステムを選んだ。
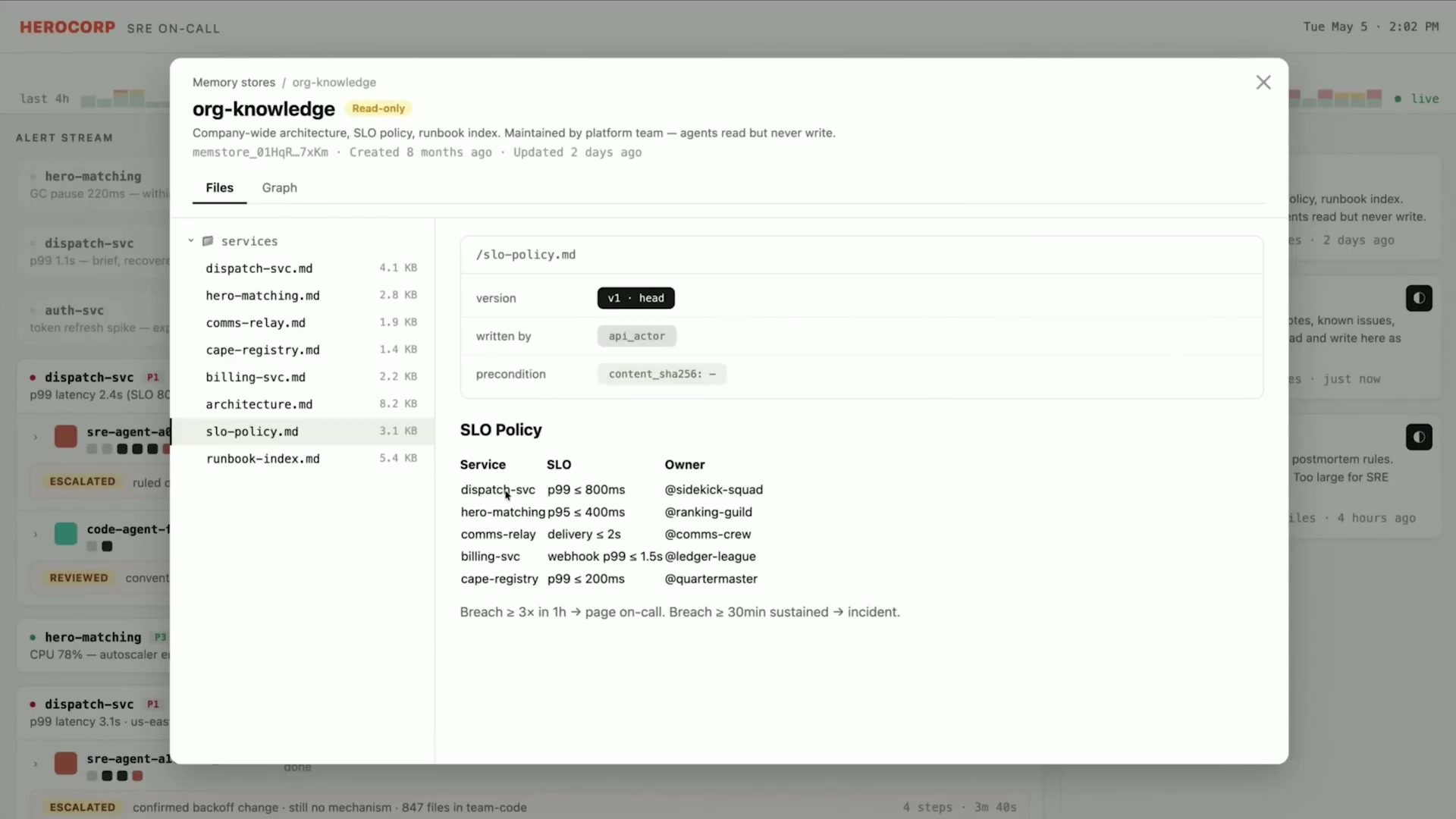
システムはアラートとページを受信し、一部に対してエージェントを起動してトリアージと修正を自動化する。メモリストアは2種類:
- org-knowledge(read-only): SLOポリシー・ランブックインデックス・オンコールマッピング。更新頻度は低いが全エージェントが参照する。
- team-sre(read-write): ライブトリアージノート・既知の問題・インシデントタイムライン。エージェントがリアルタイムに読み書きする。
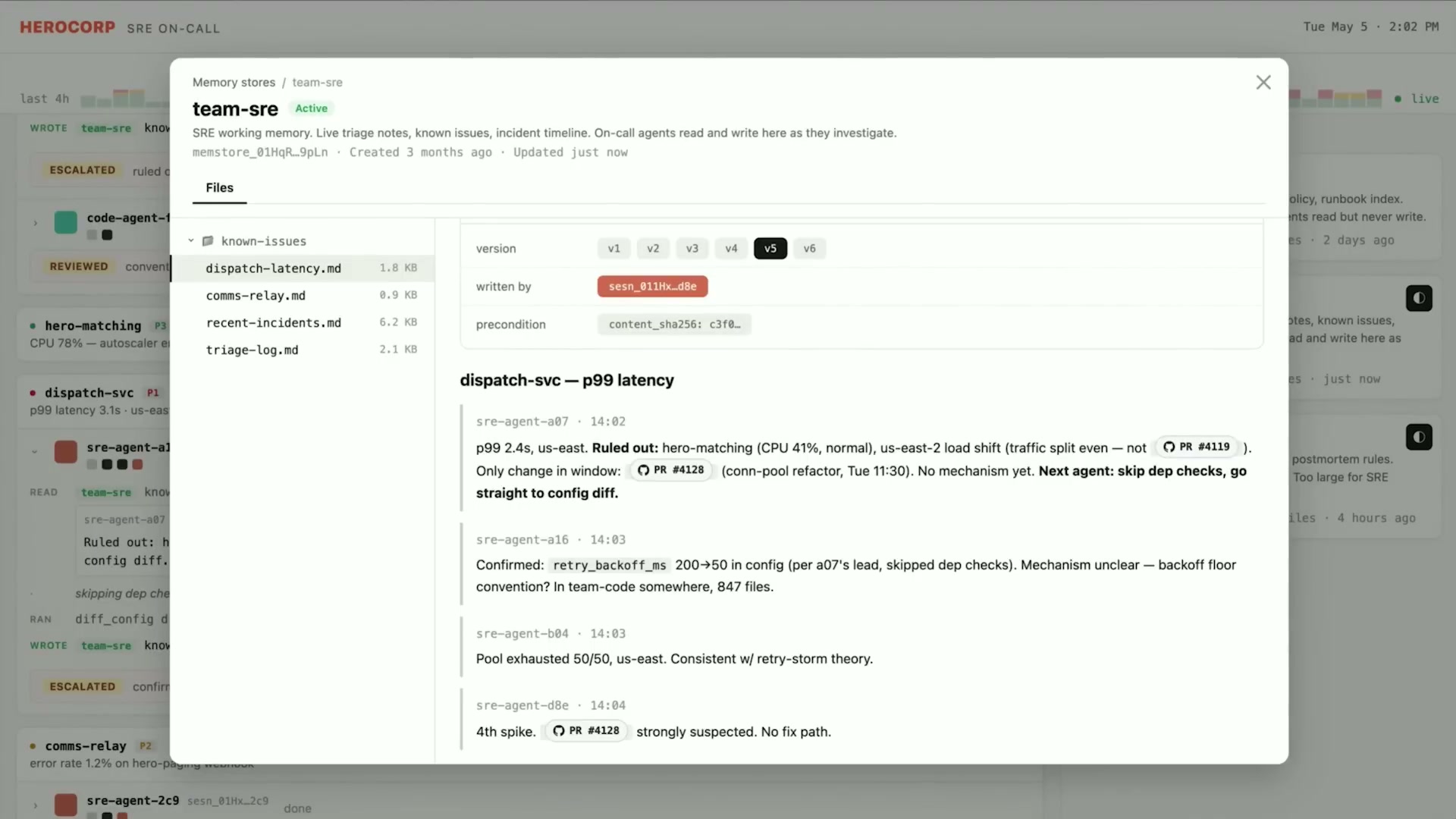
このシナリオが示す価値は明快だ。エージェントAが dispatch-svc のレイテンシスパイクを調査してPR修正中とメモリに書き込む。その後、同じ問題で別のアラートが来た場合、エージェントBは共有メモリを参照して「修正進行中」を確認し、重複調査を回避して適切なアクションを取れる。
「かつてSREをやっていた私にとって、これは本当にクールなパターンだ。全エージェントにわたって調整できる」とRaviは語った。
Claude ConsoleからのDreaming実行
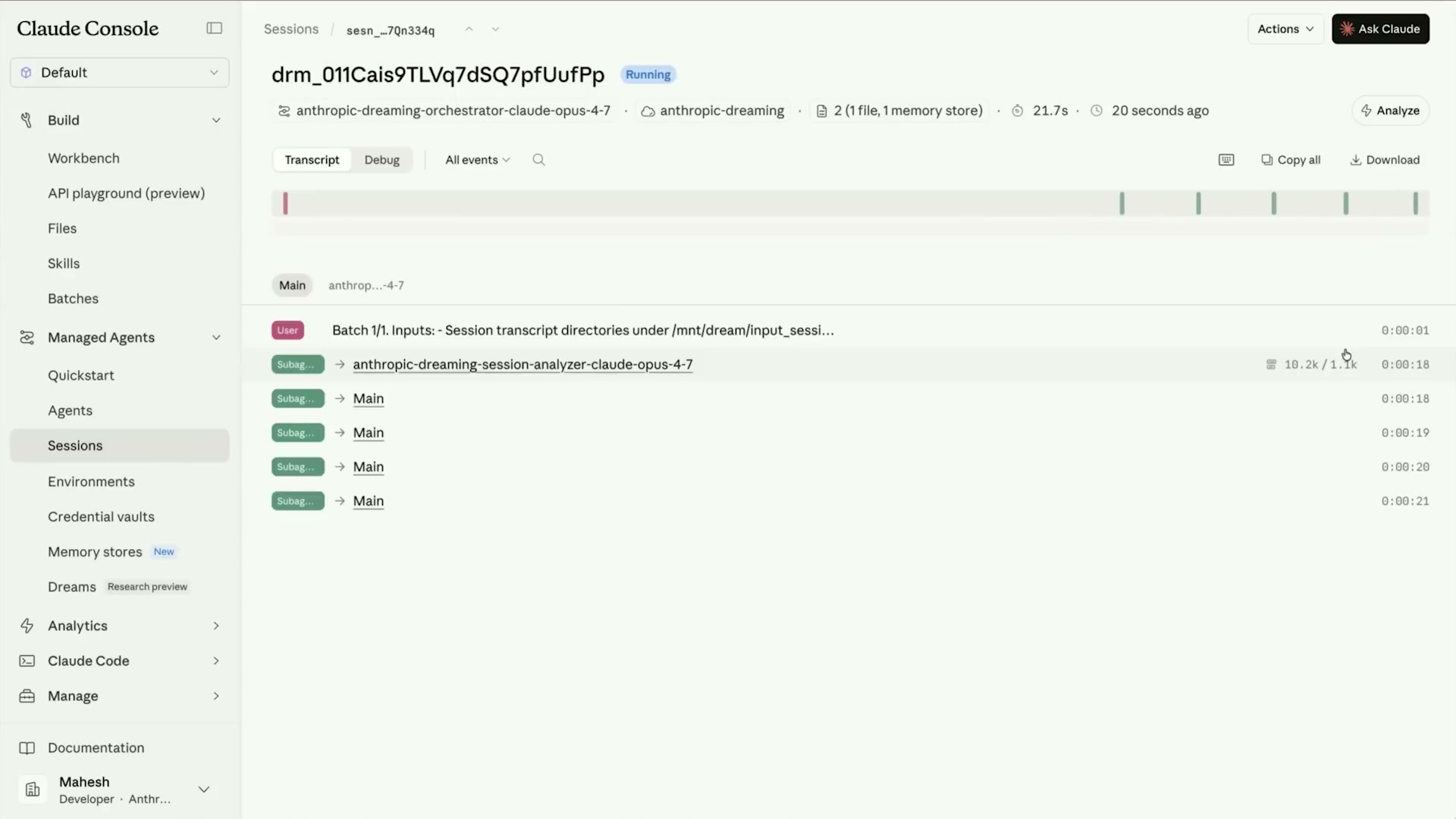
Claude Console(Anthropicのウェブコンソール)では「Dreams」タブからGUI操作でDreamingを実行できる。
実行フローは以下の通り:
- メモリストアを選択:
team-sreなど対象ストアを指定 - 解析期間を選択: 直近7日間のセッションを選択(例では5セッション)
- Dreamingを開始: 複数のサブエージェントが並列でトランスクリプトを解析
- 差分を確認: 完了後にメモリの変更差分を確認
- 採用または拒否: 変更を受け入れるかどうかを判断
デモで示されたDreamingの発見は具体的だった — 複数のエージェントが「CPUスパイクの60秒後に特定のアラートが発生するパターン」を繰り返し観察していた。Dreamingがこれをretry動作の問題として解釈し、次のエージェントが同じパターンに出会った際により適切にトリアージできるよう記憶を更新した。
Memory + Dreamingの組み合わせ効果
RaviはMemory単体とDreamingの組み合わせを「フロアを上げる」仕組みとして説明した。
これはLLMにおけるtest-time compute(推論時に追加トークンを使うことで平均的により良いアウトプットを得る手法)と本質的に同じだ。DreamingはトークンをセッションExternalで消費して高品質な記憶を生成し、その恩恵が後続の全エージェントに波及する。
従来のメモリアプローチとの比較
| 項目 | CLAUDE.md | 専用メモリツール | Claude Managed Agents Memory |
|---|---|---|---|
| 構造の柔軟性 | 低(単一ファイル) | 中(ツール依存) | 高(自由なファイルシステム) |
| マルチエージェント共有 | 不可 | 実装依存 | ネイティブ対応 |
| 楽観的同時実行制御 | なし | なし | あり |
| バージョン管理 | なし | なし | v1/v2/v3… |
| 帰属追跡 | なし | なし | セッションID付き |
| グローバル最適化 | なし | なし | Dreaming |
| エンタープライズAPI | なし | なし | スタンドアロンAPI |
| エージェントレイテンシへの影響 | なし | あり(ツール呼び出し) | Dreamingはゼロ |
Claude Managed AgentsのMemoryが既存アプローチと決定的に異なるのは「Dreaming」という out-of-band 最適化層の存在だ。個別エージェントの局所的な学習を、組織全体の知識へと昇華させる仕組みを持つ点で、先行する記憶ツール実装と一線を画す。
実用上の注意点
何を記憶させるべきか
ファイルシステムとして実装されているため「何でも書ける」が、記憶の質が重要だ。Raviが示したように、Claudeはopus 4.7が「将来の自分にとって重要な情報を選別し、どう構造化するか」を自律的に判断する。プロンプトで「このタスクから得た学習・判断理由・回避した落とし穴を記録せよ」と指示するとよい。
Dreamingの実行タイミング
夜間バッチが最も一般的だが、「セッション終了イベントトリガー」は高頻度のエージェント運用で特に有効だ。一方、hourlyを設定するとDreamingコストが増大するため、セッション量に応じて調整する。
read-onlyストアの更新管理
組織全体の知識(SLOポリシー・ルールブック)はread-onlyで全エージェントが参照するが、その更新はAPIやConsoleから手動で行う。更新頻度が高い情報はread-onlyに入れると更新コストが高くなるため適切に分類する。
メモリシステムとしての位置づけ
Anthropicが最も強調したのは「Memory + Dreamingは将来の組織スケールメモリへの橋渡し」という点だ。
現在:
- Memoryがタスク間でエージェントに学習させる
- Dreamingが記憶を検証・整理・拡充する
将来ビジョン:
- 数日単位の長期エージェントが、継続的に世界理解を構築・改善する
- 組織全体の知識がメモリに蓄積され、全エージェントが共有する
agentmemoryなど独立したOSS実装との比較で言えば、agentmemory — Claude CodeにBM25+ベクトル+グラフ融合記憶を追加するMCPサーバー のようなツールがMCPレイヤーで記憶を追加するのに対し、Claude Managed AgentsのMemoryはプラットフォームレベルで記憶を管理し、エンタープライズ制御(帰属・バージョン・API)とDreamingによる自動最適化を標準で提供する。
より広いエージェントアーキテクチャの文脈では、12-Factor Agentsの12原則 — エンタープライズ向け信頼できるLLMアプリ設計ガイド が示す「ステートをエージェント外で管理する」原則と、今回のMemory設計思想は一致している。