フロンティアモデルの進化は、ベンチマーク数値の更新にとどまらない。開発者がエージェントをどう設計するか、スキャフォールディングをどう書くか、コンテキストをどう渡すかを根本から変える。
AnthropicのCode w/ Claudeイベントで公開された「The capability curve」(2026年5月)は、Sonnet 3.7からOpus 4.7に至る約14ヶ月の変化を、実測データとスライドで体系化したものだ。SWE-bench Verifiedで62.3%から87.6%への到達がどういう構造変化を意味するのか、そして開発者が今すぐ変えるべきことは何かを一次資料から解説する。
Claude Codeを使った開発ワークフロー全体については Claude Code完全ガイド2026:インストールから本番運用まで を合わせてご覧ください。
ケイパビリティカーブ——毎モデルが天井を引き上げる
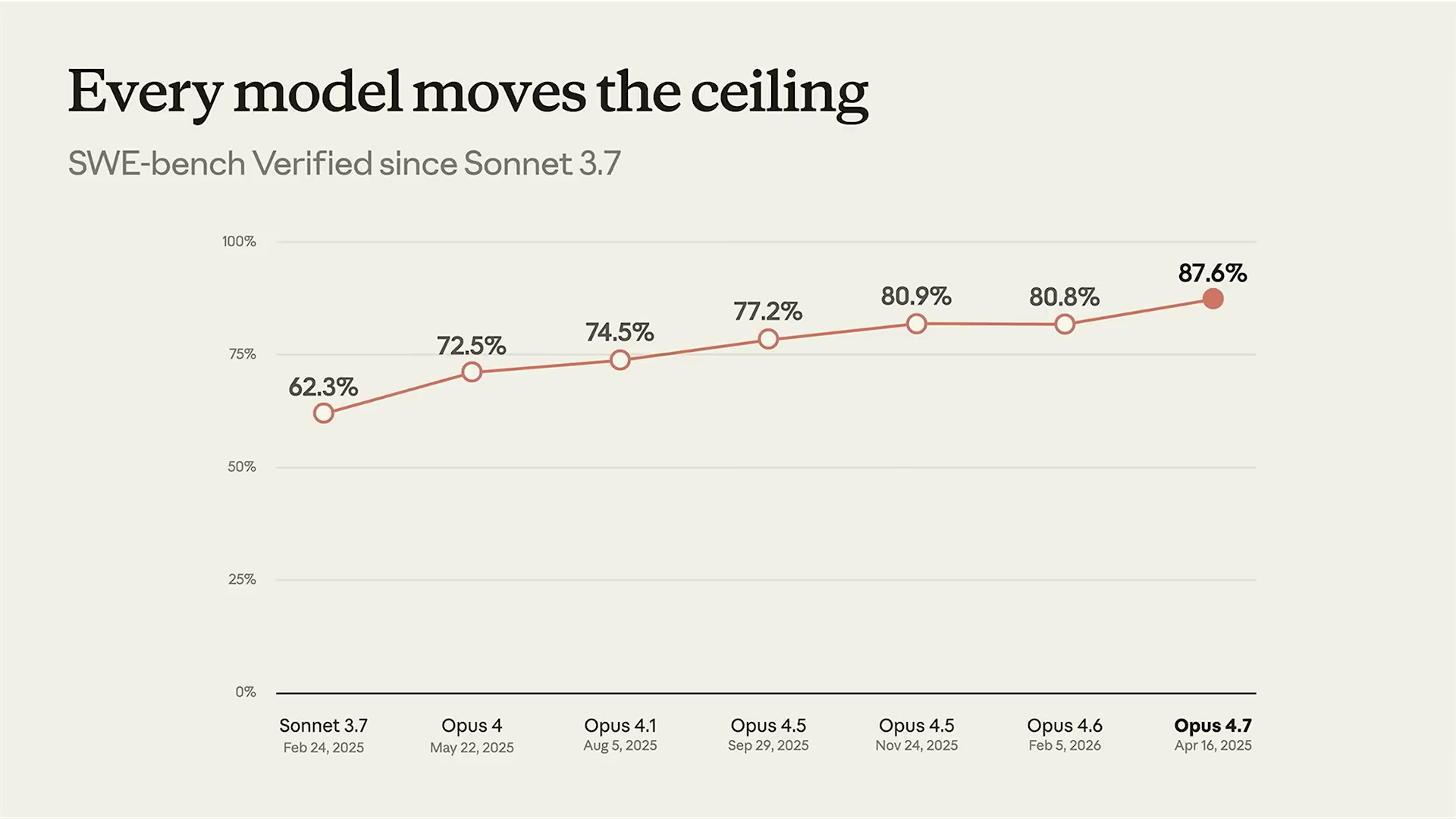
Anthropicのスライドタイトルは「Every model moves the ceiling(毎モデルが天井を引き上げる)」だ。SWE-bench Verified——実際のGitHubイシューに対してパッチを当てる能力を測るベンチマーク——のスコア推移を見ると、この主張は数値で裏付けられている。
| モデル | リリース日 | SWE-bench Verified |
|---|---|---|
| Claude Sonnet 3.7 | 2025年2月24日 | 62.3% |
| Claude Opus 4 | 2025年5月22日 | 72.5% |
| Claude Opus 4.1 | 2025年8月5日 | 74.5% |
| Claude Opus 4.5 | 2025年9月29日 | 77.2% |
| Claude Opus 4.5(更新) | 2025年11月24日 | 80.9% |
| Claude Opus 4.6 | 2026年2月5日 | 80.8% |
| Claude Opus 4.7 | 2026年4月16日 | 87.6% |
14ヶ月で25.3ポイントの向上。単純な平均では月次1.8ポイントに相当するが、実際の向上は均等ではなく、モデルの構造的変化を伴うリリースで大きく跳ねている。Opus 4.7の+6.8ポイントはその典型だ。
この数値が意味するのは、現在のClaudeは実際のソフトウェアエンジニアリングタスクのほぼ9割を正しく解決できるということだ。ただし、残りの12.4%は依然として失敗する。ベンチマークスコアはモデルの平均的な能力を示すが、特定のタスク・コードベース・要件ではまだ誤りが起きる。
実際のオープンソースプロジェクトから収集されたGitHubイシューを使い、AIがパッチを作成してテストを通過できるかを評価するベンチマーク。ソフトウェアエンジニアリング能力の実務的な指標として広く参照されている。Verifiedバージョンは人間の開発者が確認した高品質なイシューのみを使用する。
Sonnet 4 → Opus 4.7:デモ統計が示す進化
Code w/ Claudeイベントでは、同じアプリケーション(Next.js + Anthropic APIを使ったクローンアプリ)を各モデルで構築した際の統計が示された。
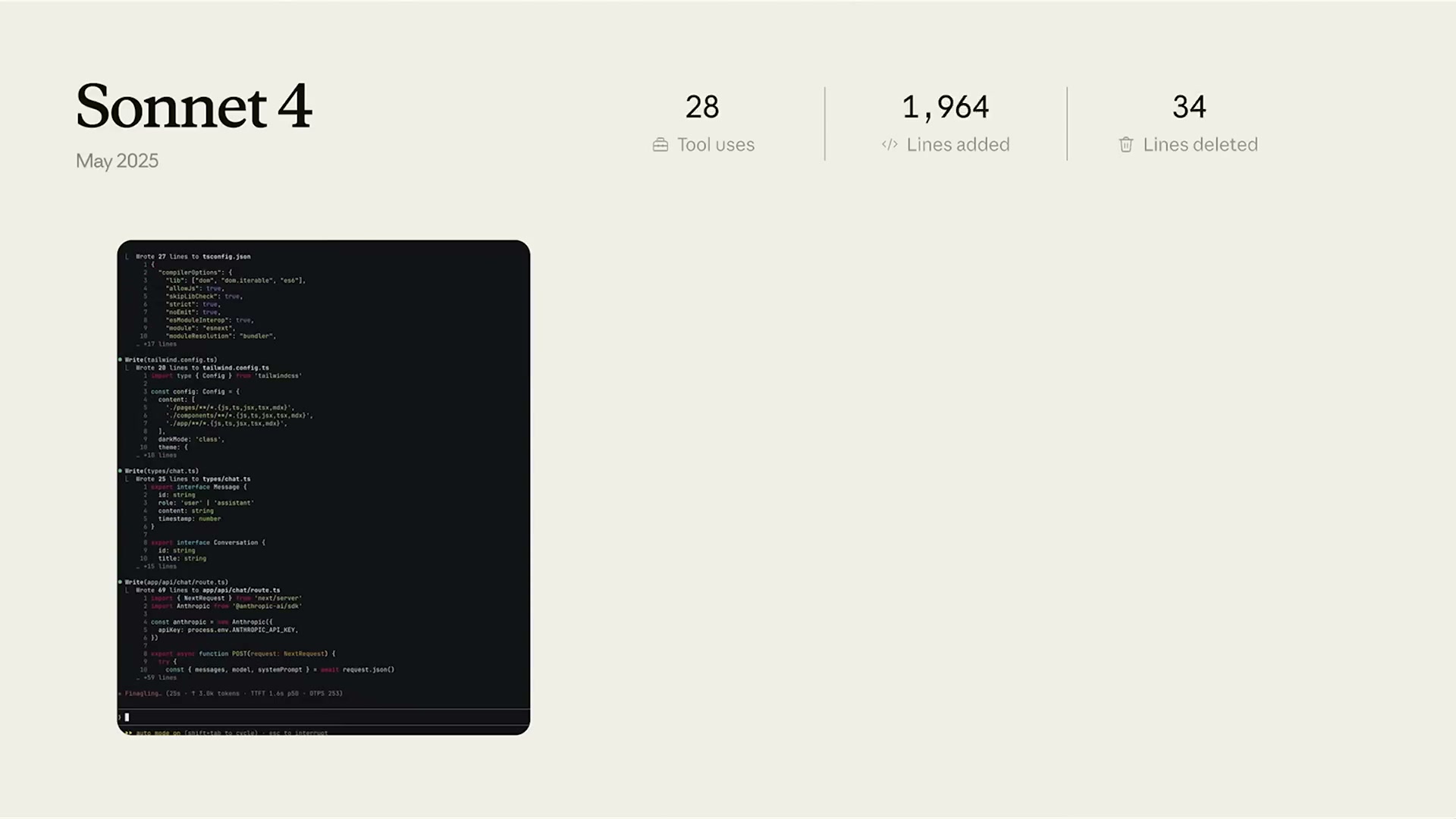
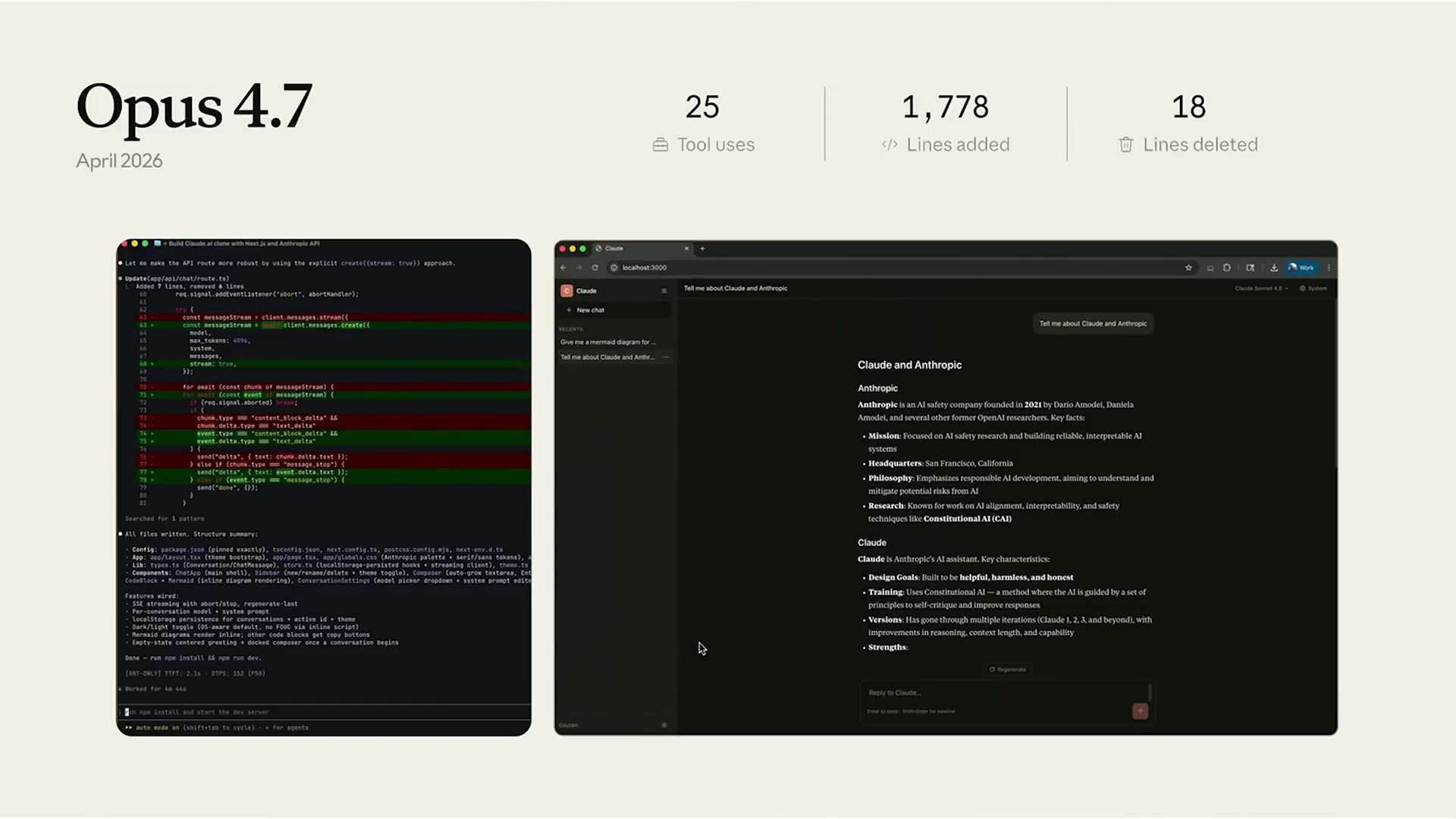
数値の変化はわずかに見えるが、質的な違いは大きい。
Sonnet 4(2025年5月):
- ツール使用回数: 28回
- 追加行数: 1,964行
- 削除行数: 34行
Opus 4.7(2026年4月):
- ツール使用回数: 25回(-10.7%)
- 追加行数: 1,778行(-9.5%)
- 削除行数: 18行(-47.1%)
ツール使用回数と追加行数の減少は、モデルが無駄なコードを書かなくなったことを意味する。Shopifyのエンジニアが「意味のないラッパー関数やフォールバックのスキャフォールディングを削ぎ落とす」と表現したのはまさにこれだ。削除行数が47%減ったのは、最初から正しいコードを書けるようになったことを示している。
3つの構造的改善:計画・回復・持続
Anthropicがイベントで強調したのは3つの構造変化だ。それぞれ「Before(以前)→ Now(現在)→ What this means for you(開発者への意味)」の形式で示された。
計画してから行動する

Now: アクション前にすべてを読み込む。計画の途中で自分のミスを検出する
What this means for you: Claudeに考える時間を与えること
以前のモデルを使った開発者は、プロンプトの中で「まず計画を立ててから実装してください」「ステップバイステップで考えてください」といった指示を入れていた。それはモデルの弱点を回避するためのワークアラウンドだった。
現在のモデルはこれを内部で自然に行う。アクションを取る前にファイル構造を読み込み、依存関係を把握し、実装前に潜在的な問題を特定する。スキャフォールディングで強制する必要がない。
エラーからの回復と自己修正

Now: エラーを読み、アプローチを変える。以前は終了していた失敗を越えて実行を継続する
What this means for you: 無駄なトークンを減らして、より良いタスクパフォーマンスを得る
エージェントが停滞する最も一般的なパターンは「同じ失敗の繰り返し」だった。ツールが失敗すると同じ呼び出しを再試行し、同じエラーで止まる。このループを検出して中断する再試行制限ロジックを書くのが開発者の仕事だった。
現在のモデルはエラーメッセージを実際に読んで、なぜ失敗したかを理解し、別のアプローチを試みる。これによって、以前はエージェントを終了させていた種類の失敗を越えて実行が続く。開発者が書いていた再試行ロジックの多くが不要になっている。
長時間ランにわたる持続的な注意力

Now: 1Mトークンにわたるランで一貫性を保つ
What this means for you: コンテキストウィンドウを管理するためにチャンキングするのをやめる。ファイルだけでなくコードベース全体を渡す
長いコンテキストウィンドウを持つモデルが登場しても、実際に長い入力で一貫したパフォーマンスを維持できるかは別の問題だった。以前は100K〜200Kトークンの範囲でもコンテキスト後半になると初期指示の重要な詳細を「忘れる」挙動が見られた。
開発者はこれを回避するために、コードベースを小さなチャンクに分割してモデルに渡し、重要な指示を何度も繰り返すプロンプトを書いていた。Opus 4.7では1Mトークン全体で一貫性が保たれる。コードベース全体を渡してよい。
ロングホライズンエージェントの設計思想

イベントで示されたロングホライズンエージェントの図は、エージェント設計の根本思想を可視化している。
Validate against goal| C1{OK?} V2 -->|Checkpoint
Validate against goal| C2{OK?} V3 -->|Checkpoint
Confirm and hand off| C3{Done?} C1 -->|Yes| P2 C1 -->|No| P1 C2 -->|Yes| P3 C2 -->|No| P2
Plan → Execute → Verify → Adjust の4ステップサイクルが繰り返され、各サイクルの終わりにCheckpointが入る。最初のCheckpointは「目標に対する検証」、最後のCheckpointは「確認とハンドオフ」だ。
スライドの下に書かれたテキストがこの設計の本質を一文で示している。
The agent runs unsupervised, but never unchecked. Every cycle ends in self-verification. (エージェントは監督なしで動くが、チェックされないことはない。すべてのサイクルが自己検証で終わる)
「監督なし(unsupervised)」と「チェックなし(unchecked)」は別物だ。エージェントが完全に自律して実行するのは、各サイクルで目標に対して検証することが前提になっているからだ。開発者がすべき設計上の仕事は、Claudeが自分のアウトプットを検査してイテレーションできる環境を作ることだ。
企業評価——Vercel・Shopify・Windsurfの声

AnthropicはCode w/ Claudeイベントで3つの主要パートナーからの評価を示した。
Joe Haddad(Vercel、Distinguished Software Engineer):
“It’s phenomenal on one-shot coding tasks, it even does proofs on systems code before starting work, which is new behavior we haven’t seen from earlier Claude models.”
「ワンショットコーディングタスクで驚異的。作業を始める前にシステムコードの証明を行う。これは以前のClaudeモデルでは見られなかった新しい動作だ。」
Ben Lafferty(Shopify、Senior Staff Engineer):
“Claude Opus 4.7 feels like a real step up in intelligence. Code quality is noticeably improved, it’s cutting out the meaningless wrapper functions and fallback scaffolding that used to pile up, and fixes its own code as it goes.”
「Claude Opus 4.7はインテリジェンスの真のステップアップを感じる。コード品質が明らかに向上し、積み重なっていた無意味なラッパー関数やフォールバックスキャフォールディングを削ぎ落とし、進行しながら自分のコードを修正する。」
Jeff Wang(Windsurf、CEO):
“Claude Opus 4.7 extends the limit of what models can do to investigate and get tasks done. Anthropic has clearly optimized for sustained reasoning over long runs, and it shows with market-leading performance.”
「Claude Opus 4.7はモデルが調査してタスクを完了できる限界を拡張する。Anthropicは長時間ランにわたる持続的な推論のために明らかに最適化しており、それは業界トップのパフォーマンスとして現れている。」
開発者への実践ガイド:スキャフォールディングを削ぎ落とせ
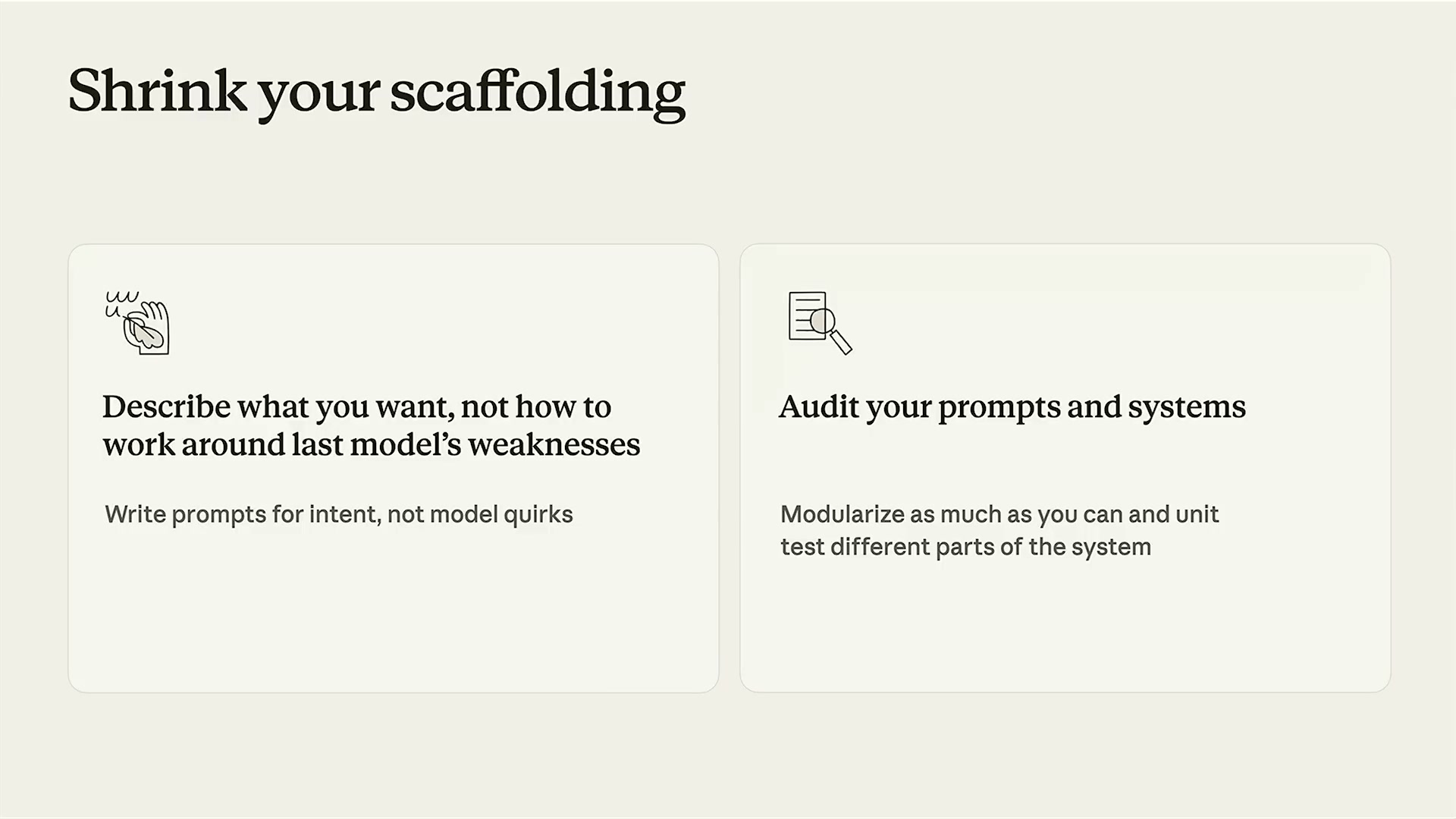
AnthropicはCapability Curveの話を「では開発者は何を変えるべきか」という実践ガイドで締めた。
1. スキャフォールディングを縮小する
スライドには2つの指針が示された。
「達成したいことを記述せよ。以前のモデルの弱点を回避する方法ではなく。」
過去のプロンプトを開くと、「ステップバイステップで考えてください」「エラーが起きたら別の方法を試してください」「ファイルを読んでから変更してください」といった指示が並んでいることが多い。これらはモデルの弱点を補うためのワークアラウンドだ。現在のモデルはこれらの動作を内部で自然に行う。以前のモデルのクセに対応した指示が、新モデルでは余計なノイズになる。
「プロンプトとシステムを監査し、できる限りモジュール化して、システムの各部分をユニットテストせよ。」
スキャフォールディングを削減するには、まず現在のプロンプトとシステムの全体を見直す必要がある。「なぜこのコードが存在するのか」を問い、「モデルの旧バージョンの弱点を回避するため」という答えが返ってきたら、削除またはリファクタリングの候補だ。

2. モデルに働く余地を与える
3つの指針が示された。
「Claudeが考えるタイミングを選ばせる。アダプティブシンキングを使い、コストを制御するために努力量を調整する。」
Extended Thinking(拡張思考)をすべてのリクエストで有効にする必要はない。適応的に使い、コストと品質のトレードオフをClaudeに判断させる。
「制御された方法でエージェントにより多くのアクセスを許可する。Claude Codeのオートモード: Claudeをより多くのツールと権限で実行させる。」
エージェントの権限を過度に制限すると、タスクを完了できなかったり、余計な確認を頻繁に求めたりする。信頼できる範囲でアクセスを与え、問題が起きたときはログを見てから制限を調整する。
「エージェントループを閉じる。ClaudeがアウトプットをInspectしてイテレーションできるようにシステムを設計する。」
Claudeが生成したコードを実行し、テスト結果をフィードバックとして返し、Claudeが修正するループを設計する。Claudeが自分のアウトプットを見られない環境では、エラー回復機能も自己検証機能も発揮できない。
Claude APIでAdaptive Thinkingを実装する
AnthropicのSDKを使ったコード例で、各指針をどう実装するかを示す。
Extended Thinkingの活用
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-opus-4-7-20260416",
max_tokens=16000,
thinking={
"type": "enabled",
"budget_tokens": 10000 # 複雑なタスクには多く割り当てる
},
messages=[{
"role": "user",
"content": "このPythonコードベース全体のアーキテクチャを分析して、"
"パフォーマンスのボトルネックを特定してください。"
}]
)
# thinking blockとtext blockを分けて処理
for block in response.content:
if block.type == "thinking":
print(f"[思考プロセス]: {block.thinking[:200]}...")
elif block.type == "text":
print(f"[回答]: {block.text}")
コストを制御したい場合は budget_tokens を下げる。単純なタスクには小さな値を、複雑な設計レビューには大きな値を設定することで、モデルが思考に使うリソースを調整できる。
自己検証エージェントループ
import anthropic
import subprocess
client = anthropic.Anthropic()
def run_agent_with_verification(task: str, max_cycles: int = 5):
"""Plan→Execute→Verify→Adjustサイクルを実装したエージェントループ"""
messages = [{"role": "user", "content": task}]
for cycle in range(max_cycles):
# Executeフェーズ
response = client.messages.create(
model="claude-opus-4-7-20260416",
max_tokens=8096,
tools=[
{
"name": "run_code",
"description": "Pythonコードを実行してstdoutとstderrを返す",
"input_schema": {
"type": "object",
"properties": {
"code": {"type": "string"}
},
"required": ["code"]
}
}
],
messages=messages
)
# Verifyフェーズ: テスト実行結果をフィードバック
if response.stop_reason == "tool_use":
tool_results = []
for block in response.content:
if block.type == "tool_use" and block.name == "run_code":
result = subprocess.run(
["python", "-c", block.input["code"]],
capture_output=True, text=True, timeout=30
)
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": result.stdout + result.stderr
})
# Adjustフェーズ: 結果をモデルに返してイテレーション
messages.append({"role": "assistant", "content": response.content})
messages.append({"role": "user", "content": tool_results})
else:
return response.content[0].text
return "最大サイクル数に到達しました"
コードベース全体を渡す
import anthropic
from pathlib import Path
client = anthropic.Anthropic()
def analyze_codebase(directory: str) -> str:
"""コードベース全体をコンテキストに入れて分析"""
code_content = []
for path in Path(directory).rglob("*.py"):
if ".git" in str(path) or "__pycache__" in str(path):
continue
try:
content = path.read_text(encoding="utf-8")
code_content.append(f"# File: {path}\n\n{content}\n\n---\n")
except Exception:
continue
full_context = "\n".join(code_content)
# Opus 4.7は1Mトークンで一貫性を保つ
# ファイルを分割する必要はない
response = client.messages.create(
model="claude-opus-4-7-20260416",
max_tokens=4096,
messages=[{
"role": "user",
"content": f"以下のコードベース全体を分析してください:\n\n{full_context}\n\n"
"リファクタリングの優先順位と、アーキテクチャ上の問題点を教えてください。"
}]
)
return response.content[0].text
以前であれば、コードベースを小さなチャンクに分けて複数回に分けて渡すか、重要なファイルだけを選択して渡す必要があった。現在は全体を一度に渡せる。
Before/Nowで見る開発者の仕事の変化
| 以前の仕事 | 現在の意味 |
|---|---|
| 「まず計画を立ててください」とプロンプトに書く | 不要。モデルが内部で行う |
| 再試行ロジック・エラーハンドリングのスキャフォールディング | 大幅に削減可能 |
| コードベースをチャンクに分割して渡す | 不要。全体を渡す |
| コンテキスト後半用に重要指示を繰り返す | 不要。1Mトークンで一貫性を維持 |
| エージェントの再試行上限を手動で制御 | モデルが自己修正するためシンプルにできる |
| ツール呼び出し失敗時のフォールバック実装 | モデルが代替アプローチを自動で試みる |
| 複雑な推論タスクにChain-of-Thoughtを強制 | Extended Thinkingで適応的に制御 |
| モデルのクセに合わせたプロンプトチューニング | 達成したいことをシンプルに書く |
ケイパビリティカーブが示す次のステップ
AnthropicがCode w/ Claudeイベントで示したメッセージは、単なるベンチマーク更新の発表ではなかった。毎モデルが天井を引き上げていくという軌跡は、開発者がモデルに対する仮定を定期的に見直す必要があることを示している。
6ヶ月前に「このタスクはモデルには無理」と判断したことが、今のモデルでは普通にできるケースがある。過去の制約を前提に書かれたコード、プロンプト、スキャフォールディングを、新しいモデルの能力に合わせて見直す機会が今だ。
今すぐできる3つのアクション:
- 既存のプロンプトを監査する — 「なぜこの指示が存在するのか」を問い、モデルの旧バージョンの弱点対応なら削除する
- エージェントループに自己検証を組み込む — Claudeが自分のアウトプットをInspectしてイテレーションできるフィードバックループを設計する
- コンテキストの渡し方を変える — ファイル単位のチャンキングをやめ、関連するコンテキスト全体を渡すことを試みる
AIエージェントのアーキテクチャと実装パターンの詳細は AIエージェントフレームワーク比較2026 も参照してください。
AIエージェント設計の全体的な観点では、ハーネスエンジニアリング完全解説 でClaudeの実行環境をどう設計するかを具体的なコードレベルで解説している。ケイパビリティカーブの理解と合わせて読むことで、モデルの能力を最大限に引き出す設計ができる。
参照ソース
- Anthropic “The capability curve” — Code w/ Claude Developer Event (2026年5月): https://youtu.be/DNRddIEoH3c
- SWE-bench Verified公式リーダーボード: https://www.swebench.com
- Anthropic Python SDK(Extended Thinking): https://github.com/anthropics/anthropic-sdk-python