「AIエージェントに自律的に動いてほしい」——この願いを持ったエンジニアが今、共通の壁に当たっている。デモでは動く。でも本番では壊れる。原因の多くはモデルの限界ではなく、モデルを動かす環境の設計不足だ。
その環境設計に体系的に取り組む方法論が「ハーネスエンジニアリング」——エージェントのランタイム全体、つまりコンテキスト供給・ツール・メモリ・権限・サンドボックスをまとめて設計する営みだ。この記事ではその全体像を、日本でも広まる5つの流派に整理して読み解く。Claude Code全般は Claude Code完全ガイド2026:インストールから本番運用まで をご覧いただきたい。
この「Agent = Model + Harness」「モデルでないなら、あなたはハーネスだ」というフレーズは、2026年3月にLangChainのVivek Trivedy氏が投稿し大きく拡散した(2,000件超のいいね)。それを引用したOxfordのAI教育者Dominik Lukes氏の投稿が、この分野の合言葉を最も簡潔に言い表している。
この記事でわかること
・ハーネスエンジニアリングの5つの流派と、定義が食い違う理由
・Fowlerの「Guides + Sensors」二軸モデルと、現場での使い分け
・Context Rot(長期タスクで品質が落ちる現象)の正体と対策
・どの流派をどの順で使うか——成熟フェーズ別の判断フロー
30秒でわかるハーネスエンジニアリング
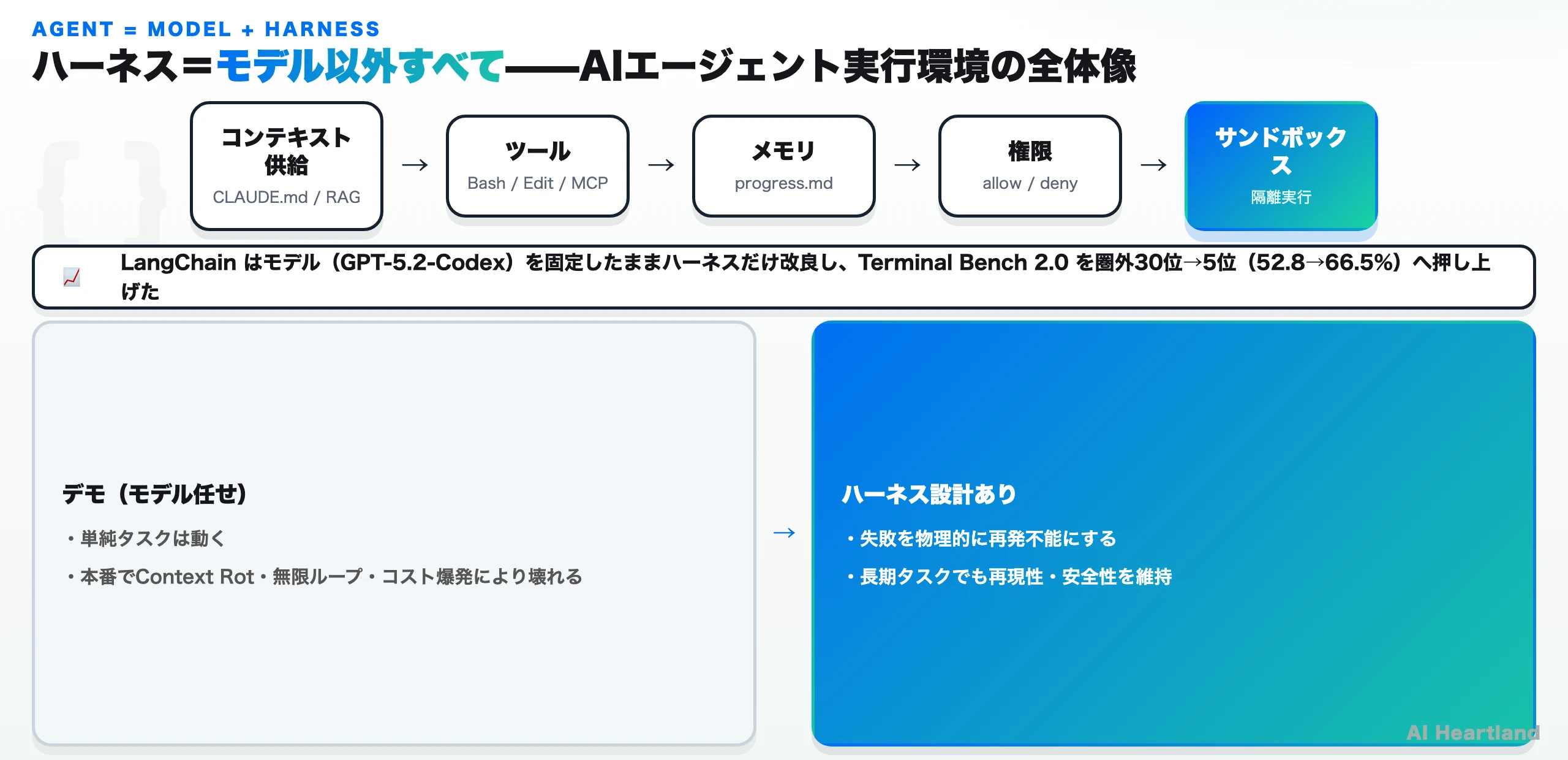
・ハーネス=モデル以外のすべて:コンテキスト供給・ツール・メモリ・権限・サンドボックス・フィードバックループを束ねた「AIエージェントの実行環境」を指す。デモは動くのに本番で壊れる原因の多くは、ここの設計不足にある
・定義は5流派に分かれる:Chase(モデル以外すべて)・Hashimoto(失敗を再発不能にする)・Fowler(Guides+Sensors)・Chawla(三重構造)・Codex(本番故障モード)。同じ言葉でも指す範囲が人によって違う
・「モデルを変えず」に効く:LangChainはモデル(GPT-5.2-Codex)を固定したままハーネスだけ改良し、Terminal Bench 2.0を52.8%→66.5%(+13.7pt)へ、順位を圏外30位から5位へ引き上げた。ハーネス設計が性能の主要変数だという実証だ
・設計の核はGuides×Sensors:事前に正しく誘導する仕組み(Guides)と、事後に出力を検証する仕組み(Sensors)の二軸。Fowlerのこの分け方が、最も実用的な設計判断の軸になる
・長期タスクの敵はContext Rot:履歴が肥大化すると注意機構が劣化し、指示を忘れ重複処理が増える。外部メモリ(AGENTS.md・進捗ファイル)とセッション分割で抑える
・使い方は重ねる:Hashimoto流で始め、Fowler流で整理し、Codex流でスケールに備える。単一の流派に縛られる必要はない
なぜ「ハーネスエンジニアリング」の定義は5流派に割れるのか
ハーネスエンジニアリングという言葉が急速に広まった2025〜2026年、奇妙な現象が起きている。言葉を使う人によって、指している範囲がまるで違うのだ。
「ハーネスって何ですか?」と5人の専門家に聞けば、5通りの答えが返ってくる。これは定義が未整備なのではなく、それぞれが異なる問題意識から同じ言葉に辿り着いたからだ。この言葉の起点をたどると、HashiCorp創業者のMitchell Hashimotoが2026年2月に個人ブログで「エージェントが失敗するたびに、その失敗を二度と起こせない環境を作る」実践を書いたのが最初期とされ、その数日後にOpenAI・Martin Fowler/Birgitta Böckeler(Thoughtworks)らが相次いで同じ結論に到達した。
日本語でのハーネスエンジニアリング論考(speakerdeck.com/kinopeee)が整理した5つの流派は、この状況をよく表している。まずは全体像を1枚で押さえる。

図を樹形図で描き直すと、5流派が「ハーネスエンジニアリング」という一語から枝分かれしている構造が見える。
「モデル以外のすべて」"] H --> B["Hashimoto派
「失敗を再発不能にする環境」"] H --> C["Fowler派
Guides + Sensors"] H --> D["Chawla派
プロンプト⊂コンテキスト⊂ハーネス"] H --> E["Codex派
プロダクションスケール対応"] style H fill:#4A90D9,color:#fff style A fill:#F5A623 style B fill:#7ED321,color:#fff style C fill:#BD10E0,color:#fff style D fill:#E74C3C,color:#fff style E fill:#50E3C2
各流派の中心にある考え方を順に見ていく。ここで押さえたいのは「何が同じで、何が違うか」——5流派は競合ではなく、同じ問題(エージェントを長期・安全・再現性高く動かす)を別の角度から切っている。
Chase派:「モデル以外のすべてがハーネス」
LangChain創業者のHarrison Chaseが体現する考え方だ。
“If you’re not the model, you’re the harness.”
ツール実行、メモリ管理、サブエージェント制御、ガードレール、オーケストレーション——これらすべてがハーネスに含まれる。包括的・総合的なフレームワーク設計の視点から語られるため、LangChain・LangGraphのような大型フレームワークの文脈で使われることが多い。
この定義の利点は「モデルへの入出力以外はすべてエンジニアリング対象」という明快さだ。一方で広すぎて、「ハーネスを改善しよう」という議論が何を指しているのか曖昧になりやすい。
ただしChase派の主張には実証の裏づけがある。LangChainは自社のコーディングエージェント(deepagents-cli)で、モデル(GPT-5.2-Codex)を一切変えずにハーネスだけを反復改良し、Terminal Bench 2.0のスコアを52.8%から66.5%へ、13.7ポイント引き上げた。順位は圏外30位から5位へ跳ね上がった。

「より賢いモデルを待つ」のではなく「手元のモデルを取り巻く環境を設計する」——この一手で圏外から上位へ動く、というのがハーネスエンジニアリングを学ぶ最大の動機だ。
Hashimoto派:「失敗を物理的に再発不能にする環境の累積」
HashiCorp創業者のMitchell Hashimotoが実践し発信している流派で、現場感覚に最も近いとされる。
プロセスはシンプルで、3ステップを回すだけだ。
・①失敗する:エージェントに作業させ、何らかのタスクで失敗が起きる
・②ルール化する:その失敗が「物理的に起きないような」ルールをAGENTS.mdやCLAUDE.mdに1行追記する
・③繰り返す:これを実運用の中で積み重ねる
特別なアーキテクチャ設計から始まるのではなく、実際の失敗から学んでルールファイルを育てていく。後から振り返ると、ルールファイルが「蓄積されたハーネス」になっているという考え方だ。
この流派の強みは「今日から始められる」点だ。何か大掛かりなシステムを構築する前に、エージェントを実際に動かして失敗から学ぶ。その記録がそのままハーネスになる。
Hashimoto流の始め方: エージェントに何か作業させて、失敗したら「なぜ失敗したか」をAGENTS.mdに1行追加する。これを繰り返すだけでハーネスが育ち始める。設計から入るより実行から入る方が、現場では機能する。
Fowler派:「Guides(事前制御)+ Sensors(事後検証)」
ThoughtworksのMartin Fowlerのハーネスエンジニアリング論文が提唱する構造化された二軸モデルだ。定式は Agent = Model + Harness で、HarnessをGuidesとSensorsの二軸に分ける。それぞれさらに「計算的(deterministic)」と「推論的(probabilistic)」に細分される。詳しくは後述の専用セクションで実装まで踏み込む。
Chawla派:「プロンプト⊂コンテキスト⊂ハーネスの三重構造」
教育系ライターのAvi Chawlaが提唱する初学者向けの可視化モデルだ。プロンプトがコンテキストに含まれ、コンテキストがハーネスに含まれるという入れ子構造で、「LLMはCPU、コンテキストはRAM、ツールはデバイスドライバ、ハーネスはOS」というコンピュータアーキテクチャのアナロジーで説明する。
この流派はChase派と逆の包含関係になることがある点が注意だ。Fowler派では「ハーネス⊂コンテキスト設計」となる場合もある。
用語の混乱に注意: ハーネスエンジニアリングを語るとき、相手がどの流派の文脈で話しているかを確認しないと議論がすれ違う。「ハーネスってコンテキストより広い概念ですよね」(Chase派)vs「ハーネスはコンテキスト設計の一部ですよね」(Fowler派)——どちらも正しく、文脈による。
Codex派:「プロダクションスケール特有の故障モードへの対応」
OpenAI CodexチームのRyan Lopopoloが体現するスケール駆動の流派だ。「3人で百万行、95% AI生成」という実績から生まれた考え方で、小規模では現れない問題——Context Rot、コスト爆発、セッション間の記憶損失、再現不能なバグ——に対処するための構造設計を指す。
この流派が重要なのは、デモ環境と本番環境の差を最も直視しているからだ。「88%のエンタープライズAIエージェントプロジェクトが本番到達に失敗する」という数字が各所で引用されるが、これは一部ベンダー調査の値で一次統計としての裏取りは弱い。ただしデモと本番の断絶が大きいという方向性は、現場の実感とも一致する。Codex派はまさにこの断絶を埋めるための流派だ。
5流派の比較と、現場での重ね方
5流派の違いを一覧にすると、それぞれが「どのフェーズ・どの規模で効くか」が見えてくる。
| 流派 | 核心 | 強み | 弱み | 最適なシーン |
|---|---|---|---|---|
| Chase | モデル以外すべて | 包括的・明快 | 広すぎて議論が曖昧に | フレームワーク設計・全体設計 |
| Hashimoto | 失敗から育てる | 即実践可能・現場的 | 体系化しにくい | 個人・小チームの開発 |
| Fowler | Guides + Sensors | 設計判断を明確化 | 複雑・学習コスト高 | チーム設計・大規模システム |
| Chawla | 三重構造 | 初学者に伝わりやすい | 現場応用に限界 | 教育・説明の場面 |
| Codex | 本番故障モード対応 | 実際の問題を直視 | 前提知識が必要 | プロダクション展開 |
実務では単一の流派に縛られる必要はない。Hashimoto流で始めて(失敗から学ぶ)、Fowler流で整理し(Guides/Sensors)、Codex流でスケールに対応する——という重ね使いが現実的だ。この重ね方こそが「何を代替するか」への答えになる。従来は「フレームワークを選ぶ」ことが設計の中心だったが、ハーネスエンジニアリングはフレームワーク選択の前段にある、より本質的な設計レイヤーを代替・補完する。
「言葉の定義は重要ではない。大切なのは期待した結果を得ること」——kinopeee
日本の現場は命名が広まる前から同じ実装を行っていた。名前がついたことで体系化できるようになったが、定義論争より手元の環境をどう改善するかが本質だ。「どのOSSを使うか」を探す段階に来たら、harness設計のOSS・論文を分類した awesome-harness-engineering徹底ガイド が実装手段の地図になる。
Fowlerの「Guides + Sensors」——ハーネス設計の二軸
ここからは実装に踏み込む。5流派のうち、日々の設計判断に最も直接使えるのがFowlerモデルだ。「このチェックはどこで受け止めるべきか」を毎回判断できる座標系を与えてくれる。
Fowler派はHarnessをGuides(事前制御・フィードフォワード)とSensors(事後検証・フィードバック)の二軸に分け、それぞれを「計算的(確定的・高速)」と「推論的(確率的・柔軟)」に細分する。合計4象限で、あらゆるハーネス部品を分類できる。
| 軸 | 制御タイミング | 計算的(確定) | 推論的(確率) |
|---|---|---|---|
| Guides(ガイド) | 事前 | LSP・自動補完・許可リスト | CLAUDE.md・スキル定義・原則 |
| Sensors(センサー) | 事後 | Lint・型チェック・テスト | AIレビュー・E2E・LLM-as-judge |
図にすると、モデルを中心にGuidesが「入口」を、Sensorsが「出口」を固める構造が見える。
LSP・自動補完
ブートストラップスクリプト"] G2["推論的ガイド
AGENTS.md・スキル定義
アーキテクチャ原則"] end subgraph Sensors["Sensors(事後検証)"] S1["計算的センサー
Lint・型チェッカー
構造テスト"] S2["推論的センサー
AIコードレビュー
E2Eテスト"] end M["モデル"] --> Guides M --> Sensors Sensors -->|"自己修正フィードバック"| M
Fowler派の強みは、何をどの層で対処するかを明確に区別できる点だ。「このチェックはLintでやる(計算的センサー)のか、AIレビューエージェントでやる(推論的センサー)のか」を意識的に選択できる。原則は明快で、確定的に検出できるものは必ず計算的な側に置き、推論的なセンサー(高コスト・低信頼)は最後の砦にする。
Guidesの設計——settings.jsonとCLAUDE.md
Guidesは「エージェントが最初から正しく動く」ための入口だ。ここは読者が実際にファイルを書く部分なので、2つの成果物を具体的に示す。
計算的ガイドは、許可・拒否リストのように「モデルがどう推論しても物理的にこの範囲しか動けない」制約だ。Claude Codeなら .claude/settings.json に書く。
{
"permissions": {
"allow": [
"Bash(npm run *)",
"Bash(git diff *)",
"Read",
"Write(src/**)",
"Edit(src/**)"
],
"deny": [
"Bash(rm -rf *)",
"Bash(git push --force *)"
]
}
}
推論的ガイドは、CLAUDE.md(またはAGENTS.md)に書くアーキテクチャ原則だ。「絶対に守られる」保証はないが、大半のケースでモデルは従う。Hashimoto流の「失敗を1行足す」がそのまま積み上がる場所でもある。
# CLAUDE.md — 推論的ガイドの例
## アーキテクチャ原則
- 新規ファイルは必ず src/features/{feature-name}/ 配下に作成する
- 外部APIコールは必ず src/lib/api/ 経由にする(直接fetchは禁止)
- テストファイルは実装ファイルと同ディレクトリに置く
## コミットルール
- 動作確認済みのコードのみコミットする
- マイグレーションファイルは単体でコミットする
CLAUDE.mdの書き方そのものを深掘りしたい場合は CLAUDE.md/AGENTS.md書き方ガイド を参照してほしい。
Sensorsの設計——確定的な網を先に張る
Sensorsは「エージェントの出力を外部から検証し、自己修正を促す」出口だ。ここは新しくコードを増やすより、既存のLint・型チェック・テストをエージェントの動線に接続するのが要点になる。
・計算的センサー:コード変更後に自動で走るLint・型チェック・テスト。Claude CodeならPostToolUseフックで、型エラーの内容をそのままエージェントに返す。「書く→エラー→修正→再確認」のループが自動化され、人間が介入せずに品質が収束する
・推論的センサー:AIレビューエージェントや人間のコードレビュー。計算的センサーが検出できない意味的な問題——過剰設計、ドメインロジックの誤り、セキュリティの論理的欠陥——を補う。コストが高いため、CI後段や週次レビューなど適切なタイミングに置く
設計順序の鉄則: 先に計算的センサー(Lint・型・テスト)で網を張り、それでも漏れる意味的な問題だけを推論的センサー(AIレビュー)に回す。逆にすると、確定的に検出できたはずのバグをLLMに毎回判定させることになり、コストと不確実性が跳ね上がる。
Context Rot——長期タスクで品質が落ちる正体と対策
Codex派が最も重視する問題のひとつがContext Rot(コンテキスト腐敗)だ。「最初はうまくいくのに、長く走らせると壊れる」の正体はここにある。
Context Rotとは何か
ツール実行結果が積み重なるにつれ、コンテキストウィンドウは肥大化する。LLMの注意機構はウィンドウ内の後半部分に弱い——前半の指示が「薄れ」、古いコンテキストを無視した処理が増え始める。
Context Rotが進むと、次のような症状が出始める。これらが何を解決すべき問題かを教えてくれる。
・タスクが完了していないのに「完了した」と誤報告する
・以前に自分が書いたコードと矛盾するコードを書く
・同じ処理を重複して実装する
・指示の細部を無視し始める
Context Rotの対策戦略
対策は3つの戦略の組み合わせだ。それぞれ「症状」に対する具体的な処方箋になっている。
| 戦略 | やること | 効く症状 |
|---|---|---|
| ①記憶の外出し | 作業履歴をprogress.md等に書き出しコンテキストから追い出す |
忘却・矛盾・重複 |
| ②KVキャッシュ安定化 | 静的な文書を先頭に固定、動的要素は後半へ | コスト爆発・レイテンシ |
| ③セッション分割 | タスクをスプリントに割り、境界でリセット | 長時間での品質劣化全般 |
戦略1:外部アーティファクトへの記憶の外出し。コンテキスト内に長大な作業履歴を蓄積しない。代わりにAGENTS.mdやprogress.mdなどのファイルに状態を書き出し、次のセッションで読み込む。Anthropicが推奨する「Initializer + Coding Agent」の二段構成はこの考え方の実装で、Initializerがセッションごとの計画・状態ファイルを生成し、Coding Agentが読み込んで継続する。引き継ぎファイルは次のような素朴なMarkdownで十分だ。
## セッション2 終了時点(2026-04-25)
### 完了
- src/auth/login.ts — JWT認証実装済み、テスト全通過
- src/auth/middleware.ts — 認証ミドルウェア実装済み
### 次のセッションで着手
- [ ] src/users/profile.ts — ユーザープロフィールAPI
- [ ] メール確認フロー(POST /auth/verify-email)
### 既知の問題
- Refreshトークンのローテーションは Sprint 3 以降
- エラーメッセージのi18n未対応
戦略2:KVキャッシュの安定化。Anthropicの解説によれば、プロンプトの先頭部分が安定しているとKVキャッシュが効き、条件次第でトークンコストが大きく下がるケースがある。動的な要素(タイムスタンプ、セッションIDなど)を先頭に置くと毎回キャッシュが無効化されるため、CLAUDE.mdのような静的文書を先頭に固定し、動的な要素は後半に置く構成がコスト面でも有利だ。
戦略3:セッション分割とHandoff。長期タスクを「スプリント」に分割し、スプリント境界でコンテキストをリセットする。前述のprogressファイルがそのままHandoffドキュメントになる。
目安:1スプリントでのコンテキスト消費量は50〜60%以内に収めると品質が安定する。claude --verboseで使用率を観察しながら適切なスプリント粒度を見つける。
何から始めるか——成熟フェーズ別の判断フローと設計バランス
ハーネスを設計するとき、最初に悩むのは「どこから手をつけるか」だ。5流派を丸ごと導入する必要はない。今の問題から逆算して、必要な流派だけを段階的に足していく。
動かして失敗から学ぶ"] Q1 -->|"失敗パターンが溜まってきた"| Q2{"主な問題は?"} Q2 -->|"品質のばらつき"| F["Fowler流でGuides強化
AGENTS.md・スキル定義を整備"] Q2 -->|"バグの見落とし"| S["Fowler流でSensors強化
Lint・テスト・AIレビュー導入"] Q2 -->|"長期タスクで壊れる"| C["Codex流でスプリント設計
Context Rot対策・Handoff設計"] Q1 -->|"チームで使う"| T["Fowler流で全体設計
Guides/Sensors の役割分担を明文化"] H --> IMPROVE["実際の失敗を観察"] IMPROVE --> Q2 style START fill:#4A90D9,color:#fff style H fill:#7ED321,color:#fff style F fill:#BD10E0,color:#fff style S fill:#E74C3C,color:#fff style C fill:#F5A623 style T fill:#50E3C2
判断フローを「症状→アクション」の表に落とすと、日々の運用でそのまま使える。GuidesとSensorsのどちらを先に強化すべきかは、今の症状で決まる。
| 症状 | 推奨アクション |
|---|---|
| エージェントが意図しないファイルを変更する | Guides強化:許可パスをsettings.jsonで明示 |
| コードは動くが品質が低い | Sensors強化:Lint・型チェックをフックに追加 |
| 最初は良いが長時間で劣化する | Context Rot対策:外部アーティファクト設計 |
| チームメンバーによって品質がばらつく | Guides強化:AGENTS.mdのアーキテクチャ原則を充実 |
| デプロイ後にバグが頻発する | Sensors強化:E2EテストをCI後段に追加 |
| 同じ失敗が繰り返される | Hashimoto流:失敗パターンをAGENTS.mdに追記 |
「まず最も単純な解決策から始め、失敗した部分にのみ複雑さを追加する」——これがAnthropicが推奨するハーネス設計の第一原則だ。Guides一枚のCLAUDE.mdから始め、問題が起きた箇所にSensors(フック)を追加する。最初から完璧な設計を目指すと、使われないハーネスができあがる。
この考え方を時間軸に並べると、Claude Code環境でのハーネスの「育て方」になる。Claude Skillsを徹底解説で扱ったスキルシステムも、ここで言うGuides(推論的)の一形態だ。
CLAUDE.md作成
(推論的ガイド初期化)"] --> W2["Week 2
Hooks追加
(計算的センサー)"] W2 --> W3["Week 3
スキル定義
(推論的ガイド充実)"] W3 --> W4["Week 4
ログ・可観測性
(センサーの記録化)"] W4 --> M2["Month 2
スプリント設計
(長期タスク対応)"] M2 --> M3["Month 3
ハーネスレビュー
(不要な複雑さを削る)"] style W1 fill:#d4edda style W2 fill:#d4edda style W3 fill:#fff3cd style W4 fill:#fff3cd style M2 fill:#f8d7da style M3 fill:#f8d7da
Month 3の「ハーネスレビュー」はよく忘れられるが重要なフェーズだ。Fowlerが指摘するように、モデルが賢くなると以前は必要だったHooksやルールが不要になる。定期的に「このSensorがまだ必要か」「このGuideはモデルが自然に守れるようになったか」を見直す。ハーネスは育てながら削るもの、という意識を持つと長期的に維持しやすい。
未解決の課題と、プロンプトエンジニアリングとの違い
ハーネスエンジニアリングは万能ではない。Fowlerが論文で「まだ解けていない問題」として挙げる課題を知っておくと、過度な期待を避けられる。
・ハーネスの一貫性維持:AGENTS.mdのルールが増えると矛盾が混在し始める。ハーネス自体も「リファクタリング」が必要だが、その品質をどう評価するか(コードカバレッジに相当する指標)はまだ確立していない
・行動レベルの信頼性:Lintが通り型エラーが0でも、「仕様どおり動くか」は別問題。行動レベルの検証はLLMベースのセンサー(確率的)に頼らざるを得ず、信頼性が低い
・矛盾する指示への対処:「コードはシンプルに」と「カバレッジ100%」は時に矛盾する。人間は文脈でバランスを取るが、エージェントは字義通り解釈しがち。優先度の明示方法が求められる
・Ashby’s Law問題:制御工学の「必要多様性の法則」によれば、制御者には被制御系と同等の複雑性が要る。エージェントが複雑になるほどハーネスも複雑になる——理論的な限界だ。だからこそ「定期的にシンプル化する」原則が効いてくる
こうした課題を踏まえると、よく混同されるプロンプトエンジニアリングとの違いもはっきりする。
| 比較軸 | プロンプトエンジニアリング | ハーネスエンジニアリング |
|---|---|---|
| 対象 | 単一のリクエスト・応答 | エージェントの実行環境全体 |
| スコープ | リクエスト単位 | セッション〜プロジェクト単位 |
| 永続性 | 都度変更 | 環境として固定・育てる |
| 制御方法 | 自然言語による誘導(確率的) | 外部制約+フィードバックループ |
| 典型的な成果物 | プロンプトテンプレート | AGENTS.md・Hooks・CI設定 |
| 主な解決問題 | 出力品質の向上 | 信頼性・再現性・安全性 |
プロンプトエンジニアリングは「何を言えばいい出力が出るか」を最適化する。ハーネスエンジニアリングは「エージェントが長期にわたって安全・確実に動ける環境を作る」ことを目的とする。両者は対立せず、プロンプトはGuides(推論的)の一部としてハーネスに内包される。二軸のどちらを深掘りすべきか迷ったら プロンプト vs ハーネスエンジニアリング が判断材料になる。
まとめ——どの流派を使うか、より何を解くか
ハーネスエンジニアリングは定義が揺れている分野だが、各流派が解こうとしている問題は共通している:「AIエージェントを長期にわたって、安全に、再現性高く動かすための環境設計」だ。そして「モデルを変えずハーネスだけで圏外30位→5位」というLangChainの実証が示すように、これは抽象論ではなく測定可能な性能変数である。
定義を巡る論争より、手元の問題に最も効く考え方を選んで使う——これがkinopeeeの言う「言葉の定義より結果」の意味だ。
・今日から始めるなら Hashimoto流(失敗から学ぶ)
・品質を体系化するなら Fowler流(Guides/Sensors)
・本番に持っていくなら Codex流(プロダクション故障モード)
それぞれの流派は競合ではなく、成熟フェーズに応じた補完関係にある。ハーネスは設計して終わりではなく、エージェントと共に育て、モデルの進化に合わせて削ぎ落としていくものだ。
実装パターン(Generator-Evaluator、スプリント分解、ラチェット原則)をさらに詳しく知りたい場合は AIエージェントを本番に届けるハーネス設計ガイド を、ハーネスの基礎概念から入り直したい場合は エージェント・ハーネスの基本 を参照してほしい。
参照ソース
・ハーネスエンジニアリングとは(speakerdeck.com/kinopeee) — 5流派の分類と日本語での体系整理
・Harness Engineering for Coding Agent Users — Martin Fowler — Guides + Sensors二軸モデルの原典・未解決課題
・Improving Deep Agents with harness engineering — LangChain Blog — モデル不変でTerminal Bench 2.0を30位→5位(52.8→66.5%)に改善した一次報告
・Harness engineering: leveraging Codex in an agent-first world — OpenAI — Codex派・本番故障モードの一次ソース
・Effective harnesses for long-running agents — Anthropic Engineering Blog — Initializer/Coding Agent設計パターン
・Building effective agents — Anthropic — エージェント設計の基本原則
・Claude Code Best Practices — Anthropic Engineering Blog — Claude Code実践ガイド
・Claude Code公式ドキュメント — Hooks — フックシステムの仕様
・Agent Harness Engineering — The Rise of the AI Control Plane(Medium) — KVキャッシュ最適化・Context Rot対策
・awesome-harness-engineering(GitHub) — パターン・ツール・評価手法のキュレーション