「夜中の3時に呼び出されてダッシュボードを開く——あの時間を、エージェントに渡せたら?」AnthropicのApplied AIチーム、Member of Technical StaffであるIsabella Heは、Code with Claude London 2026で行ったセッション「Ship your first Managed Agent」をこの問いから始めた。
SREのインシデントレスポンスはエージェント化の典型題材として扱われがちだが、これまではエージェントループ・コンパクション・セッション永続化・サンドボックスといった「ハーネス側」のプリミティブを自前で組み立てる必要があり、プロトタイプから本番までに数週間が溶けていた。
Anthropicが2026年4月にリリースしたClaude Managed Agents(CMA)は、この「ハーネス側」をサーバー側へ完全に寄せた設計だ。開発者は エージェント定義・カスタムツール・タスク の3つに集中するだけでよく、コンパクションも・キャッシュも・状態管理も・スケーリングも全てAnthropic側が面倒を見る。
Isabella Heはセッションの中で、わずか6つの関数を書くだけでSREインシデント対応エージェントが実際に動く様子をライブで実演した。本記事は、その実装手順と、なぜこのアーキテクチャがプロダクション向けエージェントの「最速の出荷経路」になるのかを、講演スクリーンショットとともに整理する。
AIエージェントの全体像とフレームワーク選定の俯瞰については AIエージェントフレームワーク完全比較2026:LangChain・LangGraph・AutoGen・CrewAIの選び方 を併せてご覧ください。

0:00 / 動画冒頭
Messages APIからManaged Agentsまで — 3世代のハーネス進化
Isabella Heはまず、Anthropicが提供してきた「Claudeに触るためのインターフェース」3世代の進化を整理した。2023年に最初のClaudeとともにリリースされた Messages API は、トークンインとトークンアウトの生モデルアクセスを提供した。プログラマブルにClaudeを呼べる最初の手段だったが、エージェント化に必要な周辺機能——エージェントループ・コンテキスト管理・コンパクション・ツール実行ランタイム・セッション状態・認証・ホスティング・観測性——は すべて開発者が自前で実装 する必要があった。

4:45 / 「3世代の進化」
モデルが Sonnet 3 → Sonnet 4 → Opus 4.5 と賢くなり、エージェントが扱えるタスクの複雑度が上がるにつれて、必要なプリミティブも複雑化した。次世代として登場した Agent SDK はClaude Codeのハーネスをライブラリとして提供し、エージェントループ・コンテキスト管理・コンパクション・キャッシュ・ツール実行リトライをSDK側が引き受けた。
それでも開発者は「自分のコンテナでSDKを起動し、ホスティングとスケーリングを管理する」責任から逃れられなかった。
- Purpose-built harness: コンパクション・キャッシュ・コンテキスト窓管理
- Tool runtime + sandbox: ツール実行ランタイムとサンドボックス
- Session persistence + checkpointing: セッション永続化とチェックポイント
- Auth (OAuth) + credential vault: 認証とクレデンシャル金庫
- Hosting / scaling / observability: ホスティング・スケーリング・観測性
開発者が書くのは「Task + agent config」と「Custom tool logic(MCP / Skills)」だけ。Anthropicのチーム自身が「Sonnet 4.5のcontext anxiety対策」のような短命のミティゲーションをハーネスに書いては、Opus 4.5の登場で陳腐化させる、という反復を経験した結果として設計された。
CMAが提供する価値は単なる省力化ではない。Isabellaはこう語る。「ハーネスはエージェントと一緒に進化していくべきものです。Sonnet 4.5がcontext anxiety(コンテキスト不安)を見せ始めたとき、私たちはハーネス側でミティゲーションを組みました。しかしOpus 4.5が出るとそのビヘイビアは消え、私たちが書いたコードは無用になりました」。
モデル世代を跨いだ陳腐化を、Anthropic側が吸収する。これが、開発者がエージェント定義に集中できる本質的な理由だ。
3つのプリミティブ — Agent・Environment・Session
CMAの構造は驚くほどシンプルだ。すべての構成要素は3つのリソースに集約される。Agent は「ペルソナと能力」、つまりモデル・システムプロンプト・利用可能なツールを定義する エージェントの脳 だ。Environment は「コンテナと実行環境」、つまりエージェントがツール実行・コード実行を行う エージェントの手 だ。
そして Session は、特定のAgentインスタンスを特定のEnvironment内で起動し、ユーザーとイベントをやり取りする 接続 にあたる。
イベントストリーム / 状態管理"] Agent["Agent
モデル + システムプロンプト + ツール"] Environment["Environment
サンドボックス + ネットワーク許可リスト"] Loop["サーバーサイド
エージェントループ"] Tools["Local Tools / MCP / Skills"] User -->|"events.stream / send"| Session Session -->|"bind"| Agent Session -->|"bind"| Environment Agent --> Loop Loop -->|"tool_call"| Tools Tools -->|"tool_result"| Loop Loop -->|"streaming events"| Session Session -->|"events back"| User
ここで決定的に重要なのは、エージェントループそのものがAnthropicのサーバー側で走る という点だ。クライアントは「イベントを送って、イベントを受け取る」だけの薄いレイヤーになり、ラップトップを閉じても・ハードリロードしても・クライアントが落ちても、エージェントの推論ループはサーバー側で走り続ける。会話状態・ツール呼び出し履歴・コンパクション結果がクラウド側で永続化されるため、開発者はデータベースもキャッシュも自前で組む必要がない。
10:50 / アーキテクチャ説明
ブレインとハンズの分離 — 90%超のTTFT削減を生んだ設計判断
CMAの設計でもう一つ特筆すべきは エージェントループとツール実行を物理的に分離した ことだ。以前のハーネス(Claude Codeを含む)では、エージェントループとツール実行が同じコンテナに同居していた。これは「コンピュータ全体を触れるエージェント」のような強力なツール権限を実現する一方で、すべてのセッションごとに重いコンテナを起動する必要があり、レイテンシとセキュリティの両面で課題があった。
11:50 / アーキテクチャ判断の解説
ブレインとハンズを分離したことで、3つの実装利益が同時に得られた。1つ目は セキュリティ——クレデンシャル管理が分離された金庫(Vault)に外出しされ、エージェント本体は暗号化を通してしかクレデンシャルにアクセスできない構造になった。2つ目は レイテンシ——Anthropicのチーム計測によれば、P95のTime To First Token(TTFT)が 90%以上削減 された。
ツール実行のためにコンテナを毎セッション起動する必要がなくなったためだ。3つ目は 可用性——エージェントループサービスが「数千セッションをまとめて捌く」単一サービスとして動き、ツール実行サンドボックスがオンデマンドで起動するため、コンテナがクラッシュしてもエージェントループは継続する。
セッション当日(Code with Claude London前日)には、Managed AgentsがBring Your Own Container / Bring Your Own Computeをサポートする更新がリリースされた。エージェントの脳(Agent loop)はAnthropic側で動かしたまま、ツール実行サンドボックスを自社インフラ内のコンテナへ向けられる。Anthropic以外のクラウドや、社内ネットワーク内のデータベース・APIにアクセスするエージェントを構築できるようになった意義は大きい。
ハンズオン1: 空のSREエージェントから着手する
ここからが本題のハンズオンだ。Isabella Heはリポジトリ cwc-workshops/ship-your-first-managed-agent をクローンし、streamlit run app.py でStreamlitアプリを起動した。画面の左半分は架空のインシデント「INCIDENT-2277: checkout・P99 latency 10× baseline」を表示するダッシュボード、右半分は実装途中のSREエージェントUIだ。
最初の状態では、エージェントは「agent offline — implement setup_environment() in agent.py」と表示され、未実装の関数を埋めていくことが課題となる。
14:50 / ハンズオン開始時のUI
agent.py には7つの未実装関数のスケルトンが用意されている。隣のタブには完成版の agent_complete.py が並んでおり、ワークショップでは「自分で書く・LLMに書かせる・完成版からコピーする」のどれを選んでも構わない、というスタンスで進行する。Isabella Heはコピーする路線を選び、1関数ずつ完成版から左へ移植して、UIに何が起きるかを観察していく。
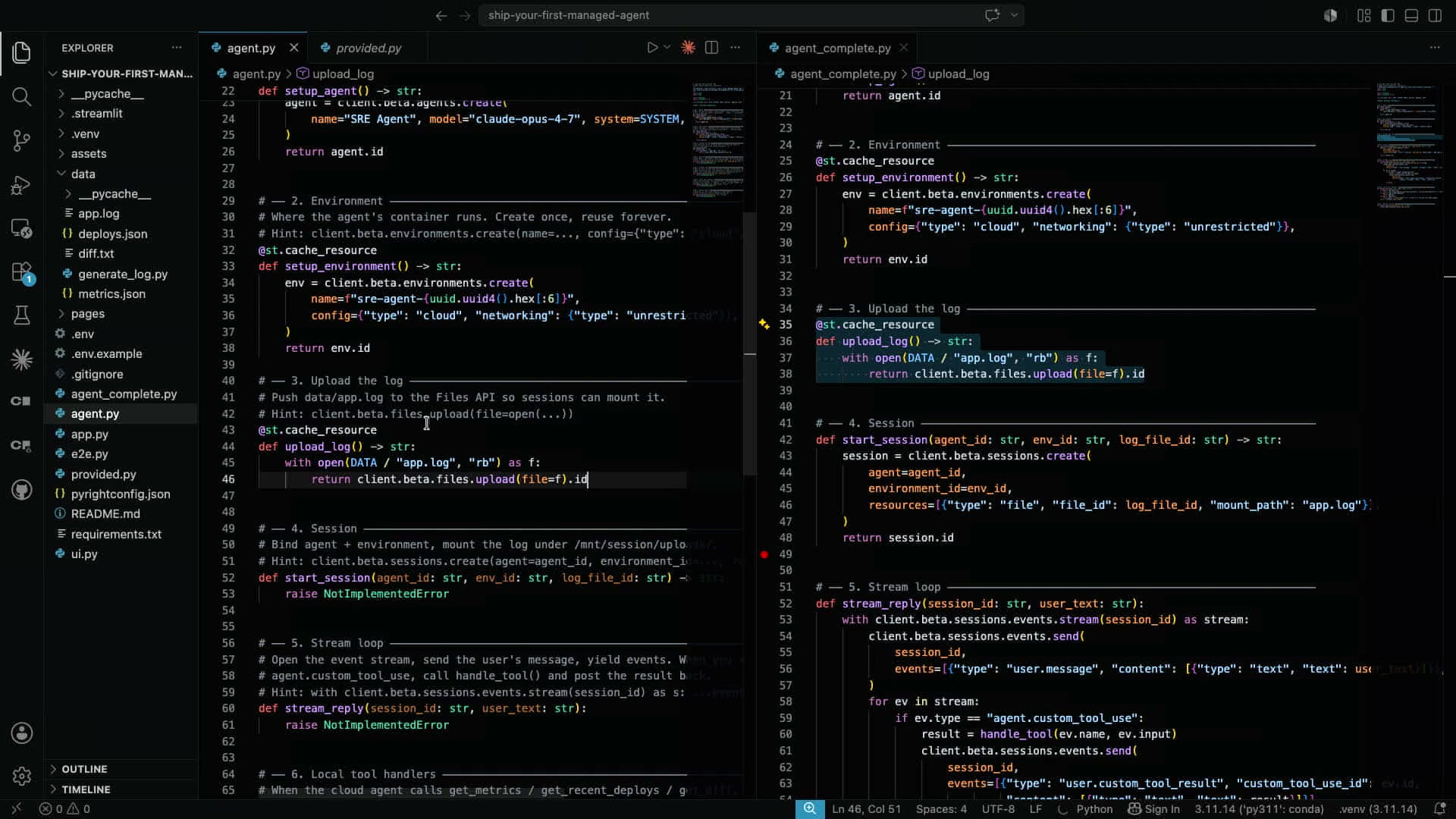
15:30 / コード構造の確認
ハンズオン2: 6関数で完成するエージェント実装
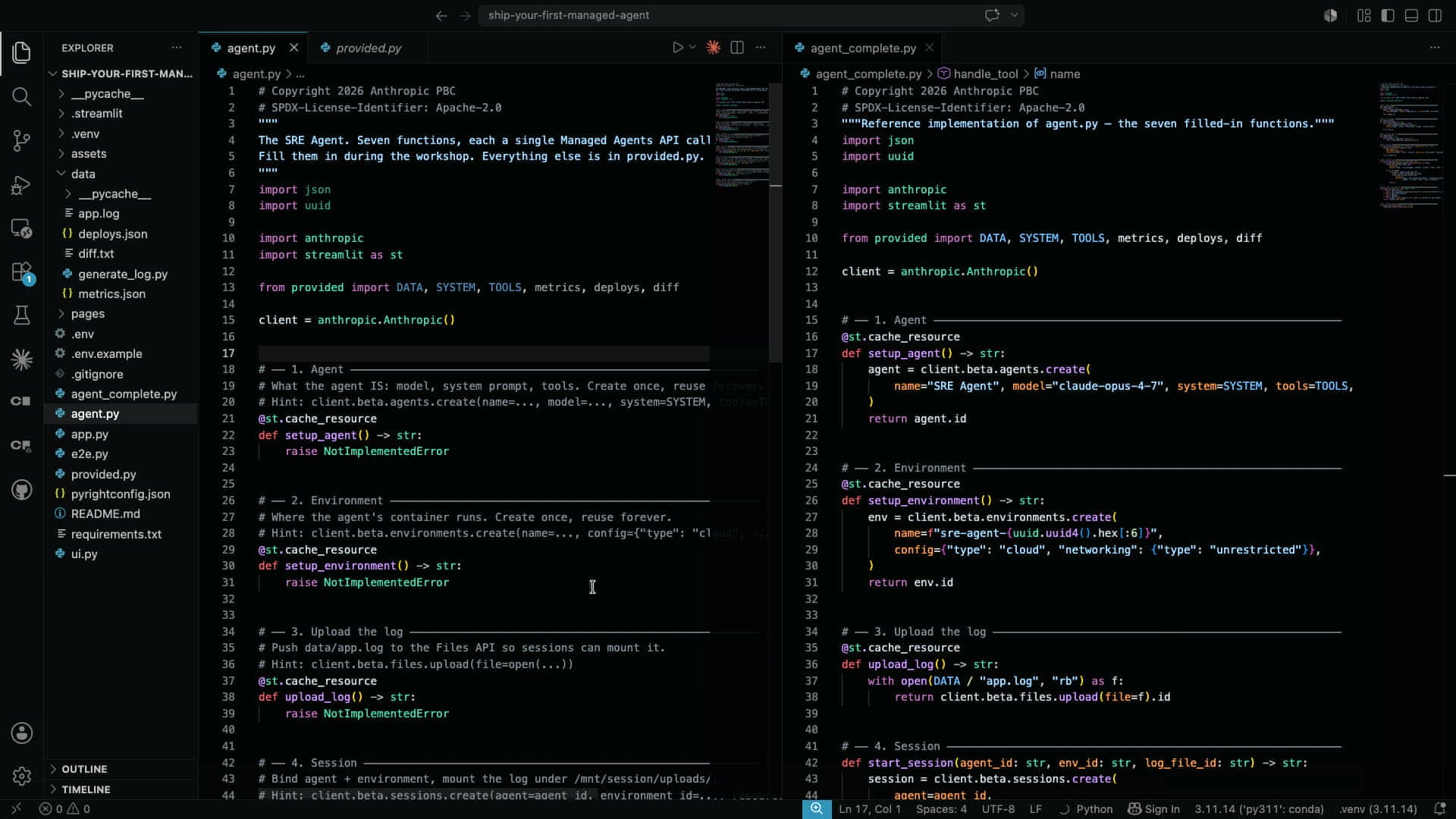
最初の関数は setup_agent() だ。AnthropicクライアントのBeta APIを通じてAgentリソースを作成し、Agent IDを返すだけのシンプルな呼び出しになっている。
import anthropic
import streamlit as st
from provided import DATA, SYSTEM, TOOLS
client = anthropic.Anthropic()
# 1. Agent — モデル・システムプロンプト・ツールを定義する「脳」
@st.cache_resource
def setup_agent() -> str:
agent = client.beta.agents.create(
name="SRE Agent",
model="claude-opus-4-7",
system=SYSTEM,
tools=TOOLS,
)
return agent.id
ここで指定している TOOLS はリポジトリ内の provided.py で事前定義されているJSONスキーマ群で、get_metrics(service, metric) / get_recent_deploys() / get_diff(commit) / bash / sandbox などSREインシデント対応に必要な道具立てが揃っている。
SYSTEM プロンプトも事前定義済みで、極めて簡素な「You are an SRE Agent. Investigate incidents using available tools.」という指示しか書かれていない。Isabella Heは「シンプルなシステムプロンプトでも十分機能します。複雑な制約を追加するのは、エージェントの振る舞いを観察してからで構いません」と強調した。
# 2. Environment — ツールが動くコンテナ
@st.cache_resource
def setup_environment() -> str:
env = client.beta.environments.create(
name=f"sre-agent-{uuid.uuid4().hex[:6]}",
config={
"type": "cloud",
"networking": {"type": "unrestricted"},
},
)
return env.id
Environment は type: "cloud" でAnthropic managed infrastructureを指定。networking はホワイトリスト形式で、unrestricted のほか「特定のホスト名のみ許可」も指定できる。MCPトンネル機能と組み合わせれば、社内ネットワーク内のMCPサーバーへもプライベートに接続できる。
# 3. Upload log — files APIでセッションコンテナに /mnt/session/uploads/app.log を生やす
@st.cache_resource
def upload_log() -> str:
with open(DATA / "app.log", "rb") as f:
return client.beta.files.upload(file=f).id
# 4. Session — Agent + Environment + アップロード済みファイルを束ねる
def start_session(agent_id: str, env_id: str, log_file_id: str) -> str:
session = client.beta.sessions.create(
agent_id=agent_id,
environment_id=env_id,
resources=[
{
"type": "file",
"file_id": log_file_id,
"mount_path": "app.log",
}
],
)
return session.id
ここで興味深いのは、ログファイルが エージェントのコンテナにマウントされる という設計だ。Files APIにアップロードしたファイルは /mnt/session/uploads/app.log のパスでセッションコンテナ内に現れ、エージェントはサンドボックスツールを通じてこのファイルをコードで処理できる。
70,000行の構造化JSONログを直接コンテキストに詰め込むのではなく、エージェント自身が grep / Python / jq などで必要な行を抽出する設計だ。

16:45 / 関数の順次移植
5番目の関数 stream_reply() は、ユーザーのメッセージを送信し、サーバー側で発生するイベントをリアルタイムで受信する核心部分だ。
# 5. Stream loop — ユーザーメッセージを送り、サーバー側イベントを順次受信
def stream_reply(session_id: str, user_text: str):
with client.beta.sessions.events.stream(session_id) as stream:
client.beta.sessions.events.send(
session_id,
events=[{"type": "user.message", "content": [{"type": "text", "text": user_text}]}],
)
for ev in stream:
if ev.type == "agent.custom_tool_use":
result = handle_tool(ev.name, ev.input)
client.beta.sessions.events.send(
session_id,
events=[{"type": "user.custom_tool_result", "custom_tool_use_id": ev.id,
"content": [{"type": "text", "text": result}]}],
)
yield ev
ここでManaged Agentsは 「リクエスト/レスポンス」ではなくイベントストリーム で動く、という設計が顔を出す。agent.custom_tool_use イベントが届いたらクライアント側で対応するローカル関数(handle_tool)を呼び、結果を user.custom_tool_result イベントとしてサーバーへ返す。
サーバー側のエージェントループはこの結果を受けて次の推論サイクルへ進む。クライアントは「ツール呼び出しのハンドラ」だけを担当する。
# 6. Local tool handlers — クラウドのエージェントがツールを呼ぶときの実装側
def handle_tool(name: str, input_dict: dict) -> str:
if name == "get_metrics":
return json.dumps(metrics(input_dict["service"], input_dict["metric"]))
if name == "get_recent_deploys":
return json.dumps(deploys())
if name == "get_diff":
return diff(input_dict["commit"])
return f"unknown tool: {name}"
このローカルツールが今回のワークショップではJSONファイルからデータを返す簡易実装だが、まったく同じワイヤープロトコル で本番ではDatadogクライアント・PagerDuty API・GitHub Issue APIへ差し替えられる。ハンズの実装を本物のインフラへ移植するだけで、エージェント本体は一切変更不要だ。
ハンズオン3: 動作確認 — 「Debug my incident for me」
6関数を埋め終わると、StreamlitのUIに「ask the agent…」入力欄が現れる。Isabella Heは「Debug my incident for me」と打ち込んだ。エージェントは即座にツール呼び出しを開始し、bash でログファイルの行数を確認し、get_recent_deploys() で直近のデプロイ履歴を取得し、get_metrics("checkout", "p99_latency") でメトリクスを引き出していった。
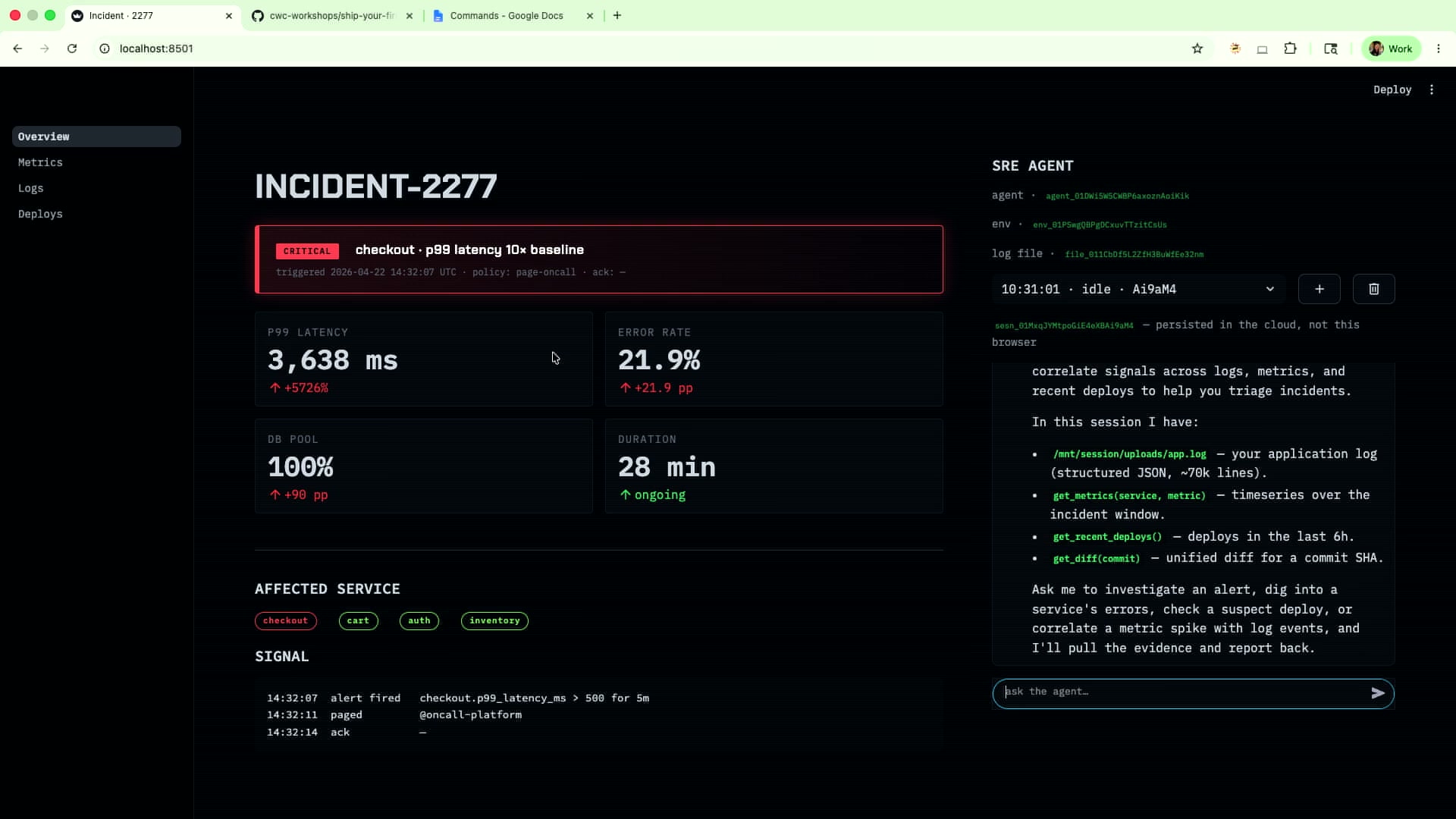
22:30 / エージェント初期化完了
数十秒後、エージェントは推論結果を提示した。「checkoutサービスのP99レイテンシが10倍に膨らんだ原因は、Aliceがコミット a39e21 で投入した build_summary のリファクタです。/api/checkout/summary でクエリがリクエストあたり N回に膨らみ、DB poolが枯渇しています。
Roll back / revertを推奨」。エージェントはさらに、復旧後に確認すべきメトリクス(db_pool warnings、error_rate)と、再発防止のための回帰テスト・アラート閾値も提案した。
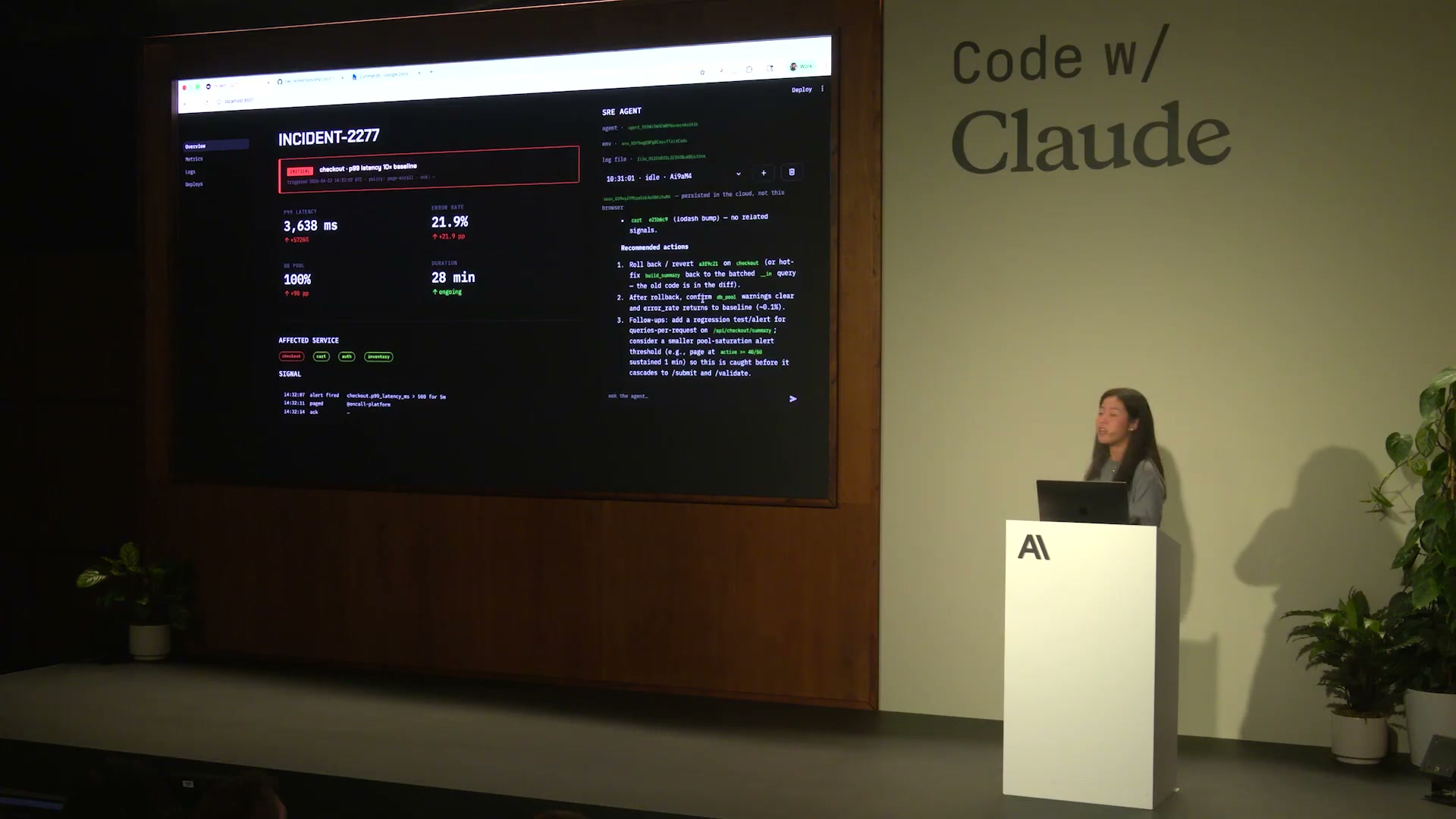
27:20 / エージェントの最終推論結果
ここでIsabella Heが強調したのは 「これは始まりに過ぎない」 という点だ。本番のSREエージェントには、Runbookスキル(チームが過去のインシデントから蓄積したデバッグ手順)、Postmortem RAG(類似事例の検索)、そして Claude Code自身をツールとして呼ぶ「修正実行エージェント」 を組み合わせる設計が想定される。
「人間は監視に回り、コード変更のPR作成までエージェントに任せる」というワークフローを、CMAは1日で構築可能にする。
セッションの4状態と「永続化されたクラウド」
7番目の関数 delete_session() の話に進む前に、Isabella HeはCMAの セッション状態モデル を解説した。セッションは状態機械として設計されており、4つの状態を遷移する。
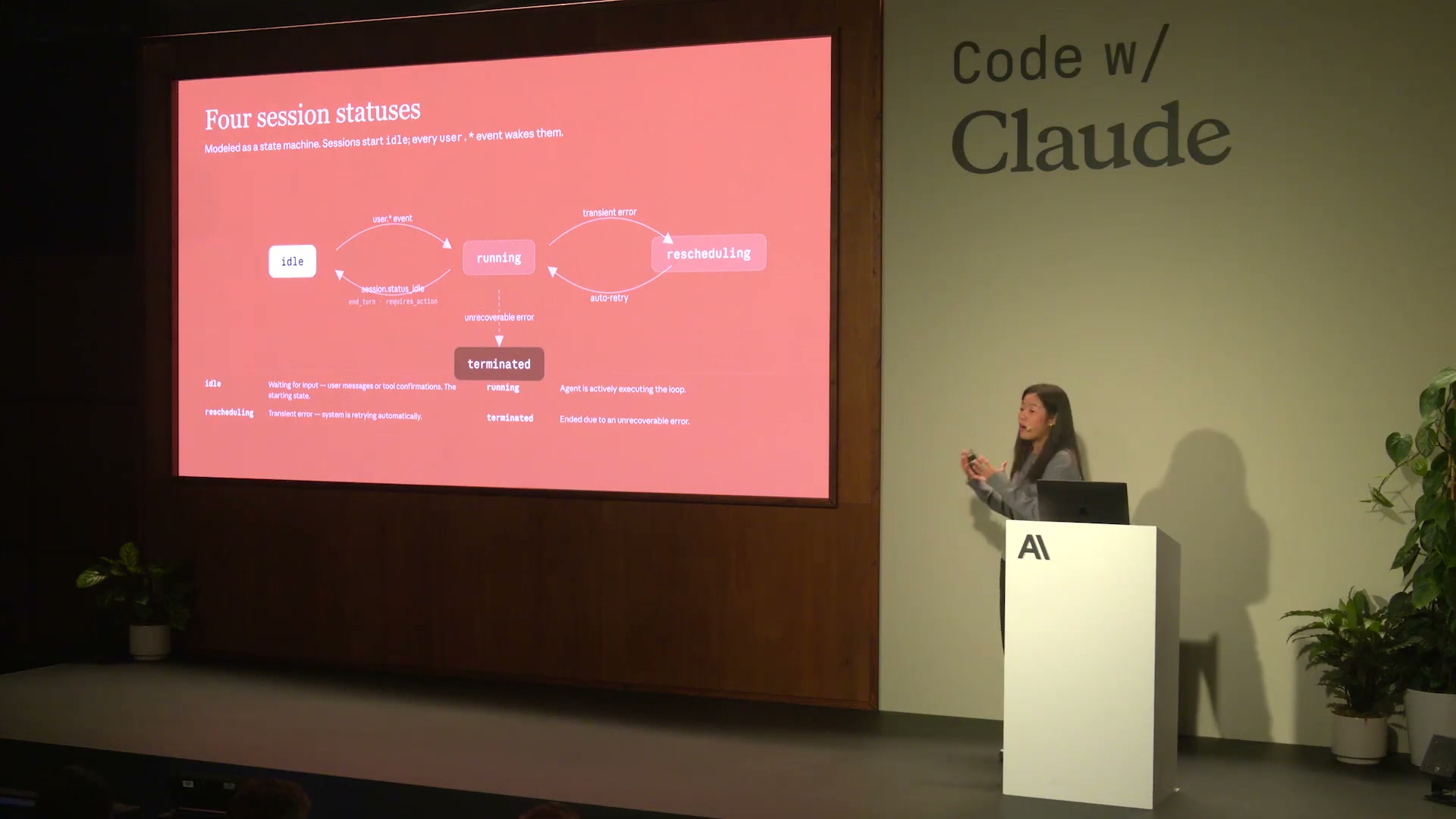
31:40 / 状態機械の解説
| 状態 | 意味 | 遷移トリガー | 主な用途 |
|---|---|---|---|
idle | ユーザー入力またはツール確認待ち。開始時の状態 | `user.message` / `user.custom_tool_result` 送信で `running` へ | セッション初期化直後・ターン完了後 |
running | エージェントループがアクティブに推論実行中 | `end_turn` / `requires_action` で `idle` へ | ツール呼び出し・推論実行中 |
rescheduling | 一時的なエラーが発生し、システムが自動リトライ中 | リトライ成功で `running` へ復帰 | ネットワークエラー・モデル一時障害 |
terminated | 復旧不能なエラーで終了 | 遷移不可 | 致命的エラー・タイムアウト |
この状態モデルは Webhookと組み合わせることで真価を発揮する。Anthropic Consoleで session.status_idle のWebhookを購読しておけば、エージェントがターンを完了するたびに通知を受け取れる。バックグラウンドジョブから「セッションをidle時に再開する」「外部イベントを user.* イベントとしてpush して動作を継続させる」といった非同期パイプラインを組める。CMAは「ブラウザを開いたままにしておく必要のないエージェント」を実現する。
ハードリロードしてもセッション一覧は維持されており、過去のセッションを開けば会話履歴がそのまま復元される。「データベースを用意する必要も、デプロイメントを管理する必要もありません。すべてがクラウド側で永続化されています」とIsabella Heは述べた。delete_session() で明示的に削除した場合は、観測性ログを含め完全に削除される——これはGDPR・SOC2準拠のコンプライアンス要件にも沿った設計だ。
ハンズオン以降 — Beyond the Basics
ワークショップは「最小構成のSREエージェント」で完結したが、Managed Agentsは本番運用に必要な高度機能を多数同梱している。

34:50 / 高度機能の俯瞰
中でも実装に直結する4機能を整理する。
- Subagents: `callable_agents` を通じてオーケストレーターエージェントが子エージェントをspawn。子は独自のコンテキスト窓を持つため、長大なタスクをコンテキスト分解できる。並列化にも有効
- Memory + Dreaming: Persistent agent memoryがコンテナにマウントされる。「Dreaming」サービスがメモリログを定期的に整理し、何を覚えて何を忘れるかをClaude自身が判断(次セッションで詳説)
- Outcomes: エージェントのゴールをルブリック形式で定義。「エージェントが何をしたか」ではなく「何を達成したか」で評価する成果物ベースのインターフェース
- Vaults: per-user / per-sessionでクレデンシャルを `vault_ids` 経由で参照。エージェントは復号化されたクレデンシャルにアクセスできない構造で、SecretsManager不要
Webhooks・Permission policies(always_ask で人間承認を強制)・Interrupt(実行中エージェントを強制idleへ)・Console agent builderといった機能も同時に提供される。Console agent builderは特に注目で、エージェント定義をブラウザUIから直接編集して即座にテストでき、APIへ落とす前の試行錯誤コストを下げる。
エージェントハーネスの基本設計についてさらに踏み込みたい場合は エージェントハーネス入門 や エージェントベストプラクティス:ハーネス設計 が補助線になる。
Code with Claude Londonシリーズの他セッションとしては エージェントの監視をやめる — Sid BidasariaのVerification・並列化・ループ3パターン もエージェント自走化の文脈で重要だ。
まとめ — 「ハーネスは進化する。ハーネスを書く時間は捨てよう」
Isabella Heはセッションをこう締めくくった。「私たちはハーネスを書く側で、コンテキスト・アンキシティのようなビヘイビアごとにミティゲーションを書いては陳腐化させてきました。あなたが同じ消耗をする必要はありません」。Managed Agentsの提供価値は単なる時間短縮ではなく、「モデル世代を跨いだ陳腐化リスクをAnthropic側が吸収する」 という構造的なものだ。
今回のワークショップで実装したSREエージェントは、わずか6関数 + 7番目の delete_session() というシンプルな構成だ。ローカルツールハンドラはJSONファイルから値を返す簡易実装だが、同じワイヤープロトコルでDatadog / PagerDuty / Sentryなど本番システムへ差し替えられる。
Bring Your Own Computeを使えばツール実行サンドボックスを自社インフラへ向けられ、Vaultsを使えばper-userクレデンシャル管理が標準化される。「プロトタイプから本番までを10〜15倍速で抜ける」というAnthropicの主張は、この設計上の積み重ねから生まれている。
夜中の3時に呼ばれたら、人間は監視に回る。エージェントは調査し、原因を特定し、PRを起こし、ロールバックを実行する。Managed Agentsは、その世界線への最短経路として設計されている。
参照ソース
- Ship your first Managed Agent (YouTube) — Isabella He, Code with Claude London 2026, セッション本編
- Anthropic公式: Claude Managed Agents Documentation — APIリファレンス・Beta header
managed-agents-2026-04-01 - Anthropic SDK Python リポジトリ —
client.beta.agents/client.beta.environments/client.beta.sessionsの実装 - Code with Claude London ワークショップ用リポジトリ —
ship-your-first-managed-agentのサンプルコード