本番AIエージェントの最大の課題は、「テキストで答える」から「実際のシステムに手を伸ばす」への移行だ。Anthropic MCP(Model Context Protocol)の公式ガイドは、この移行を体系立てて解説している。
2026年4月、AnthropicはModel Context Protocol(MCP)を使って本番システムに到達するエージェントを構築する方法についての公式ガイドを公開した。3つの統合アプローチの比較から始まり、MCPサーバー設計の4つの原則、OAuth認証の標準化、コンテキスト効率化のパターンまでをカバーする内容だ。
ローカル開発での動作確認はできているが本番環境での展開に苦しんでいるエンジニアに向け、このガイドが示す設計パターンを日本語で体系的に解説する。

- Anthropic公式の本番MCP実装ガイドは「3つの統合アプローチ」と「MCPサーバー設計4原則」が核
- 本番認証はCIMD(Customer-Initiated Managed Data)+ Vaultsでシークレットを安全に取り回す。コンテキスト効率化は2パターンで使い分け
- Skills × MCPの組み合わせ・PRレビュー手順・本番MCPのセキュリティリスクと対策まで、設計原則と実装ロードマップを網羅
MCPサーバーをゼロから構築する実装手順は、MCPサーバーの作り方2026年完全ガイド:TypeScript・Python両対応チュートリアルで解説している。本記事はその応用編として、本番システムに接続するための設計原則を扱う。
3つの統合アプローチ:どこで使い分けるか
本番システムへの接続方法には、大きく3つのアプローチがある。どれが「正解」ではなく、要件によって使い分けることが重要だ。
なぜ「本番システムへの到達」が難しいのか
AIエージェントがトイプロジェクトを超えて本番システムに到達しようとすると、いくつかの壁に当たる。
壁1:認証の複雑さ 本番システムはOAuth、APIキー、SSOなど多様な認証メカニズムを持つ。エージェントが複数のサービスに接続する場合、それぞれの認証を個別に実装・管理しなければならない。トークンの期限切れ、リフレッシュロジック、安全な保存——これらすべてが開発者の負担になる。
壁2:M×N統合問題 エージェントの数が増え、接続するサービスが増えるにつれて、統合の複雑さが乗算的に増加する。M個のエージェントとN個のサービスがある場合、従来の個別実装ではM×N個の統合コードが必要になる。一つのサービスの仕様変更が、すべてのエージェントに影響する。
壁3:クラウドホスト環境での動作 ローカル開発ではデスクトップのCLIツールやローカルファイルシステムが使える。しかし、Webアプリケーション、モバイル、クラウド上で動くエージェントには、コンテナを前提とした設計が通用しない。ローカルstdioプロセスをクラウドエージェントから呼び出すことはできない。
壁4:コンテキストの爆発 ツールが増えるほど、各ツールのスキーマ定義がコンテキストを圧迫する。50個のツールを持つMCPサーバーを接続すると、エージェントの会話のたびにすべてのツール定義が読み込まれ、数千トークンが消費される。
Anthropicの公式ガイドは、これら4つの壁に対する体系的な解答として、次の3アプローチを比較する。
(ローカルで動作確認済み)"] --> B{"本番システムへ
到達しようとすると"} B --> C["壁1: 認証の複雑さ"] B --> D["壁2: M×N統合問題"] B --> E["壁3: クラウドホスト
環境での動作"] B --> F["壁4: コンテキストの爆発"] style B fill:#ff9999,color:#000
アプローチ1:直接API呼び出し
エージェントがHTTPリクエストやSDKを通じてサービスのAPIを直接呼び出す方法だ。
# 直接API呼び出しの例(Python + Anthropic SDK)
import anthropic
import httpx
client = anthropic.Anthropic()
tools = [
{
"name": "get_pull_requests",
"description": "GitHubリポジトリのPull Requestを取得",
"input_schema": {
"type": "object",
"properties": {
"repo": {"type": "string", "description": "owner/repo形式"}
},
"required": ["repo"]
}
}
]
# エージェントがツールを呼んだらAPIを直接叩く
def handle_tool_call(tool_name: str, tool_input: dict) -> str:
if tool_name == "get_pull_requests":
response = httpx.get(
f"https://api.github.com/repos/{tool_input['repo']}/pulls",
headers={"Authorization": f"Bearer {GITHUB_TOKEN}"}
)
return response.text
利点はセットアップが最も簡単な点だ。単一サービス・単一エージェントの組み合わせには十分機能する。しかし、エージェントやサービスが増えるにつれてM×N問題が顕在化し、各ペアに対して独自の認証・エラーハンドリング・ツール定義を実装し直す必要がある。
アプローチ2:コマンドラインインターフェース(CLI)
既存のCLIツールをエージェントがシェルコマンドとして呼び出す方法だ。
# CLIアプローチの例 — エージェントがシェルコマンドを実行
gh pr list --repo owner/repo --json number,title,state
kubectl get pods --namespace production -o json
aws s3 ls s3://my-bucket --recursive
多くのサービスがすでに高品質なCLIを提供しており、ローカル開発環境では最も高速・軽量に動作する。ただし、Anthropicのガイドが指摘するように、「コンテナを公開しないモバイル・Web・クラウドホスト型プラットフォーム」では機能しない。CLIはローカル実行が前提であり、クラウド上のエージェントからのアクセスが困難だ。
アプローチ3:Model Context Protocol(MCP)
MCPは、AIとツールの接続を標準化するプロトコルレイヤーだ。MCPサーバーを1つ実装すれば、Claude、ChatGPT、Cursor、VS Codeなど、MCP対応のすべてのクライアントから利用できる。認証・ツール発見・エラーハンドリングは仕様で標準化されているため、各エージェントへの個別実装が不要になる。
MCPとは何か:AIに手足を与えるプロトコルの仕組みと実践ガイド2026では、MCPのアーキテクチャをゼロから解説している。
| 項目 | 直接API | CLI | MCP |
|---|---|---|---|
| セットアップ | 最小限 | 小 | 中程度(初期投資) |
| クラウド対応 | ✅ | ⚠️ ローカルのみ | ✅ リモートサーバー |
| マルチクライアント | ❌ 個別実装 | ❌ 個別実装 | ✅ 一度で全対応 |
| 認証の標準化 | ❌ 個別実装 | ⚠️ ファイルベース | ✅ OAuth内蔵 |
| ポータビリティ | ❌ | ❌ | ✅ Claude/ChatGPT/Cursor対応 |
| スケーラビリティ | M×N問題 | M×N問題 | M+N実装で済む |
Anthropicのガイドは「初期投資は少し多いが、ポータビリティと長期的なスケーラビリティで優位」とMCPを推奨している。
(1つ実装)"] B2["エージェントB"] --> MC B3["エージェントC"] --> MC MC --> E1["GitHub API"] MC --> E2["Slack API"] end style MC fill:#4A90D9,color:#fff
Anthropic MCPサーバー設計の4原則
Anthropicの公式ガイドの中核は、MCPサーバーを本番品質で設計するための4つの原則だ。それぞれを実装例と共に解説する。
原則1:リモートサーバーを構築する
最初の原則は、stdioトランスポートではなくリモートサーバー(Streamable HTTP)を構築することだ。
ローカルのstdioサーバーはデスクトップのClaude CodeやCursorとの連携には適しているが、クラウドでホストされるエージェントには使えない。Webアプリケーション、モバイルアプリ、あるいはClaude Managed Agentsのようなクラウド実行環境からMCPサーバーを呼び出すには、HTTPエンドポイントが必要だ。
(デスクトップ)"] -->|"ローカルプロセス起動"| S1["MCPサーバー
(同一マシン)"] end subgraph http["Streamable HTTP"] D2["Webアプリ/モバイル/
Claude Managed Agents"] -->|"HTTPリクエスト"| S2["MCPサーバー
(リモートホスト)"] end style S2 fill:#4A90D9,color:#fff
// TypeScript: リモートMCPサーバー(Streamable HTTP)
import { Server } from "@modelcontextprotocol/sdk/server/index.js";
import { StreamableHTTPServerTransport } from "@modelcontextprotocol/sdk/server/streamable-http.js";
import { ListToolsRequestSchema, CallToolRequestSchema } from "@modelcontextprotocol/sdk/types.js";
import express from "express";
const app = express();
app.use(express.json());
const server = new Server(
{ name: "production-mcp-server", version: "1.0.0" },
{ capabilities: { tools: {} } }
);
server.setRequestHandler(ListToolsRequestSchema, async () => ({
tools: [
{
name: "query_database",
description: "本番DBにクエリを実行する",
inputSchema: {
type: "object",
properties: {
sql: { type: "string", description: "実行するSQLクエリ(SELECT のみ)" },
limit: { type: "number", description: "最大取得件数", default: 100 }
},
required: ["sql"]
}
}
]
}));
// Streamable HTTPエンドポイント
app.post("/mcp", async (req, res) => {
const transport = new StreamableHTTPServerTransport({
sessionIdGenerator: () => crypto.randomUUID()
});
await server.connect(transport);
await transport.handleRequest(req, res, req.body);
});
app.listen(3000, () => console.log("MCP Remote Server: http://localhost:3000/mcp"));
ローカル開発・デスクトップClaude Code: stdio(設定が簡単)
Webアプリに組み込む: Streamable HTTP
クラウドエージェント(AWS Lambda等): Streamable HTTP
Claude Managed Agents: Streamable HTTP
モバイルアプリのバックエンド: Streamable HTTP
なお、stdioトランスポートにはセキュリティ上の懸念(後述)があり、本番環境ではStreamable HTTPを強く推奨する。
原則2:インテントベースでツールをグループ化する
第2の原則は、APIエンドポイントをそのままツールに変換するのではなく、ユーザーのインテント(意図)でグループ化することだ。
GitHubのREST APIには数百のエンドポイントがある。それをすべてツールに変換すれば数百のツールができあがる。しかし、そのアプローチには重大な問題がある。LLMが正しいツールを選ぶのが難しくなり、全ツール定義でコンテキストが膨張し、エージェントが「どのエンドポイントを使えばよいか」で迷い誤った選択をしやすくなる。
より良いアプローチは、「ユーザーが達成したいこと」でツールをグループ化することだ。
# ❌ APIエンドポイントをそのままツールにする(アンチパターン)
# GET /repos/{owner}/{repo}/pulls
# GET /repos/{owner}/{repo}/pulls/{pull_number}
# POST /repos/{owner}/{repo}/pulls
# PATCH /repos/{owner}/{repo}/pulls/{pull_number}
# GET /repos/{owner}/{repo}/pulls/{pull_number}/reviews
# POST /repos/{owner}/{repo}/pulls/{pull_number}/reviews
# ... 数十のエンドポイントがそのままツールになる
# ✅ インテントベースでグループ化する(推奨パターン)
INTENT_BASED_TOOLS = [
{
"name": "list_pull_requests",
"description": "オープンなPRを一覧表示(状態・ラベル・作成者でフィルタ可)",
# 内部で GET /pulls を呼び出す
},
{
"name": "review_pull_request",
"description": "PRにレビューを実行(approve/request_changes/commentを選択)",
# 内部で GET /pulls/{n}/files + POST /pulls/{n}/reviews を組み合わせる
},
{
"name": "merge_pull_request",
"description": "PRをマージ(マージ戦略・コミットメッセージを指定可)",
# 内部で PATCH /pulls/{n}/merge を呼び出す
}
]
インテントベースの設計では、1つのMCPツールが複数のAPIエンドポイントを内部で呼び出すことがある。これが本番MCPサーバー設計の核心だ。
この設計の利点は3つある。第一に、LLMが選ぶべきツールが少ないため正確な判断ができる。第二に、ツール定義のトークン数が大幅に減る(後述のツール検索と組み合わせると効果絶大)。第三に、APIの変更があっても、インターフェース(ツール名・パラメータ)を変えずに内部実装だけ更新できる。
原則3:コードオーケストレーション設計
第3の原則は、数百のオペレーションが必要なサービスには、個別ツールではなくコード実行ツールを提供することだ。
たとえば、データベースに対する操作を考えてみよう。SELECT、INSERT、UPDATE、DELETE、各テーブルへのCRUD——完全なデータベースMCPサーバーを作ろうとすると、数十〜数百のツールが必要になる可能性がある。
Anthropicのガイドはこのシナリオに対して、コードオーケストレーションという設計パターンを推奨する。エージェントに個別のCRUDツールを与える代わりに、「コードを書いて実行する」ツールを1つ提供する形だ。
# コードオーケストレーション設計のMCPツール例(Python)
from mcp.server.fastmcp import FastMCP
import json
mcp = FastMCP("database-orchestrator")
@mcp.tool()
async def execute_database_query(
sql: str,
description: str
) -> dict:
"""
安全なサンドボックス内でSQLクエリを実行する。
Args:
sql: 実行するSQLクエリ(SELECT文のみ許可)
description: 操作の説明(監査ログに記録)
Returns:
クエリ結果とメタデータ
"""
# ホワイトリスト検証
normalized = sql.strip().upper()
if not normalized.startswith("SELECT"):
return {"error": "SELECT文のみ実行可能です", "status": "rejected"}
# 監査ログ
audit_log(description, sql, requester="agent")
# 接続と実行
async with get_db_connection() as conn:
rows = await conn.fetch(sql)
return {
"rows": [dict(row) for row in rows],
"count": len(rows),
"status": "success"
}
エージェントはこのツールを使って、複雑なデータ操作を1回の呼び出しで実行できる。個別のCRUDツールを50個実装する代わりに、1つのコード実行ツールで同等の柔軟性を実現できる。
コードオーケストレーション設計が特に有効な場面は以下のとおりだ。
| サービス種別 | 従来アプローチ | コードオーケストレーション |
|---|---|---|
| データベース | SELECT/INSERT/UPDATE/DELETE × テーブル数 | execute_query 1ツール |
| ファイルシステム | read/write/list/delete/copy… | run_file_operation 1ツール |
| CI/CDパイプライン | trigger/status/cancel/log… | pipeline_operation 1ツール |
| クラウドAPI(AWS等) | リソース種別 × 操作 = 数百ツール | cloud_operation 1ツール |
重要注意点: このパターンを採用する場合、コードのサンドボックス実行は必ず適切な分離環境で行う必要がある。WebAssembly、Dockerコンテナ、またはFirecracker VMのような軽量VMで実行を分離することが推奨される。
原則4:リッチなセマンティクスを提供する
第4の原則は、MCP AppsとElicitation機能を使って、エージェントとユーザーのインタラクションを豊かにすることだ。
従来のツール呼び出しは「入力→処理→出力」という単方向のフローだった。しかし本番システムでは、途中でユーザーに確認を求めたり、フォーム入力を要求したりする必要がある。
Elicitationは、MCPサーバーがクライアントを通じてユーザーから構造化されたデータを要求できる機能だ。本番デプロイの承認確認、設定フォームの入力要求、削除操作の最終確認など、重要な操作の前にユーザーの意思を確認できる。
// Elicitation を使った本番デプロイ確認の例
server.setRequestHandler(CallToolRequestSchema, async (request, extra) => {
if (request.params.name === "deploy_to_production") {
const { environment, version } = request.params.arguments as {
environment: string;
version: string;
};
// ユーザーに確認を求める(Elicitation)
const confirmation = await extra.elicit({
message: `本番環境(${environment})にv${version}をデプロイします。よろしいですか?`,
requestedSchema: {
type: "object" as const,
properties: {
confirmed: { type: "boolean" as const, description: "デプロイを承認する" },
reason: { type: "string" as const, description: "デプロイ理由(任意)" }
},
required: ["confirmed"]
}
});
if (confirmation.action === "cancel" || !confirmation.content?.confirmed) {
return { content: [{ type: "text", text: "デプロイをキャンセルしました" }] };
}
// ユーザーが承認した場合のみデプロイ実行
return await performDeployment(environment, version);
}
});
リッチなセマンティクスは、特に本番システムへの書き込み操作(デプロイ、削除、メール送信等)で威力を発揮する。エージェントが自律的に実行するのではなく、重要な操作の前にユーザーへの確認フローを組み込める点が、本番利用における安全性の核心だ。
Anthropic MCPの本番認証実装:CIMDとVaults
本番システムへの接続において、認証は最も複雑な部分の一つだ。Anthropicの最新MCPガイドでは、この問題に対して2つの仕組みが紹介されている。
CIMD:クライアント登録の自動化
最新のMCP仕様で追加されたCIMD(Client ID Metadata Documents)は、MCP対応クライアントのOAuth登録を自動化するための標準だ。
従来、MCPサーバーがOAuth認証を実装するには、Claude Code、Cursor、VS Codeなど各クライアントを個別にOAuthアプリとして登録する作業が必要だった。クライアントごとにclient_idを発行し、リダイレクトURIを設定する——このプロセスが複雑で、新しいMCPクライアントが登場するたびに手動更新が必要だった。
CIMDはこの問題を解決する。MCP対応クライアントはCIMDドキュメントを自分のURIで公開し、MCPサーバーはそのドキュメントを参照して自動的にクライアントを登録できる。
{
"client_name": "Claude",
"client_uri": "https://claude.ai",
"redirect_uris": [
"https://claude.ai/auth/callback"
],
"grant_types": ["authorization_code", "refresh_token"],
"response_types": ["code"],
"token_endpoint_auth_method": "none",
"scope": "openid profile email"
}
MCPサーバー側でCIMDを活用することで、対応クライアントの追加・変更を自動化できる。
// CIMD対応のOAuth動的クライアント登録
async function registerClientViaCIMD(clientUri: string) {
// クライアントのCIMDドキュメントを取得
const metadataUrl = `${clientUri}/.well-known/oauth-client-metadata.json`;
const metadata = await fetch(metadataUrl).then(r => r.json());
// 動的クライアント登録(RFC 7591)
const registration = await oauthServer.registerClient({
client_name: metadata.client_name,
redirect_uris: metadata.redirect_uris,
grant_types: metadata.grant_types ?? ["authorization_code"],
response_types: metadata.response_types ?? ["code"],
});
return registration.client_id; // 自動発行されたclient_id
}
Vaults:OAuthトークン管理の自動化
Claude Managed AgentsのVaultsは、OAuthトークンの保存・リフレッシュを自動管理するAnthropicのサービスだ。
本番エージェントが複数のサービス(GitHub、Slack、Jira、Salesforce等)に接続する場合、各サービスのOAuthトークンを安全に保存し、期限切れ前に自動リフレッシュする仕組みが必要になる。これを自前で実装すると、セキュリティリスクと運用コストが大きい。
Vaultsはこの問題を解決する。開発者はVaultsにサービスを登録するだけで、エージェントが自動的に認証されたAPIアクセスを得られる。
# Claude Managed Agents + Vaults の使用例
from anthropic import Anthropic
client = Anthropic()
# Vaultsに登録済みのサービスを指定してセッションを作成
session = await client.agents.sessions.create(
agent_id="my-production-agent",
vault_connections=[
"github", # Vaultsに登録済みのGitHub OAuth
"slack", # Vaultsに登録済みのSlack OAuth
"jira" # Vaultsに登録済みのJira OAuth
]
)
# エージェントはVaultsから自動的に認証情報を取得して実行
result = await session.run(
"GitHubのPRをレビューして、Slackで通知し、JiraチケットをUpdatedに更新して"
)
VaultsはOAuth 2.0のフローを完全に処理し、アクセストークンの保存(暗号化)、リフレッシュトークンの自動更新、スコープの管理を行う。エージェントの開発者は認証の詳細を実装する必要がなくなる。
(Claude Managed) participant Vault as Vaults
(Anthropic) participant GitHub as GitHub API participant Slack as Slack API User->>Agent: PRをレビューしてSlackに通知 Agent->>Vault: GitHub/Slackのトークンを要求 Vault->>Agent: アクセストークン(自動リフレッシュ済み) Agent->>GitHub: PR情報を取得(Bearer Token) GitHub->>Agent: PRデータ Agent->>Agent: PRをClaudeで分析 Agent->>Slack: レビュー結果を投稿(Bearer Token) Slack->>Agent: 投稿成功 Agent->>User: PRレビュー完了、dev-reviewチャンネルに投稿しました
Claude Managed Agentsの詳細な仕組みと始め方については、別記事で詳しく解説している。
コンテキスト効率化の2パターン
MCPサーバーを本番で運用するとき、コンテキストの効率化はコストと性能の両方に直結する。Anthropicのガイドでは、2つの具体的なパターンが紹介されている。
パターン1:ツール検索でトークンを85%以上削減
ツール検索(Tool Search / Deferred Tool Loading)は、ツール定義を必要なときだけロードする遅延ロード機能だ。
通常のMCPサーバーでは、接続時にすべてのツール定義(名前・説明・パラメータスキーマ)がコンテキストに読み込まれる。50個のツールを持つサーバーなら、会話のたびに全50ツールのスキーマが渡される——これだけで数千トークンを消費する。
ツール検索パターンでは、最初はツールの名前と短い説明のみを渡す。エージェントがツールを使う必要があるとき初めて、そのツールのフルスキーマを取得する。
// ツール検索を実装したMCPサーバー(TypeScript)
import { ListToolsRequestSchema } from "@modelcontextprotocol/sdk/types.js";
// 最初のListToolsリクエスト:名前と短い説明のみ返す
server.setRequestHandler(ListToolsRequestSchema, async (request) => {
const allTools = await getToolRegistry();
return {
tools: allTools.map(tool => ({
name: tool.name,
description: tool.shortDescription, // 1行の説明だけ(スキーマなし)
// inputSchema: tool.schema ← ここを省略することがポイント
}))
};
});
// ツール詳細の取得:必要になったときだけフルスキーマを返す
server.setRequestHandler(GetToolRequestSchema, async (request) => {
const { name } = request.params;
const tool = await getToolByName(name);
return {
tool: {
name: tool.name,
description: tool.fullDescription,
inputSchema: tool.schema // フルスキーマはここで返す
}
};
});
Anthropicのガイドによれば、ツール検索を実装することでツール定義トークンを85%以上削減できる。大規模なMCPサーバー(数十〜数百のツール)ほど、この最適化の効果が大きい。
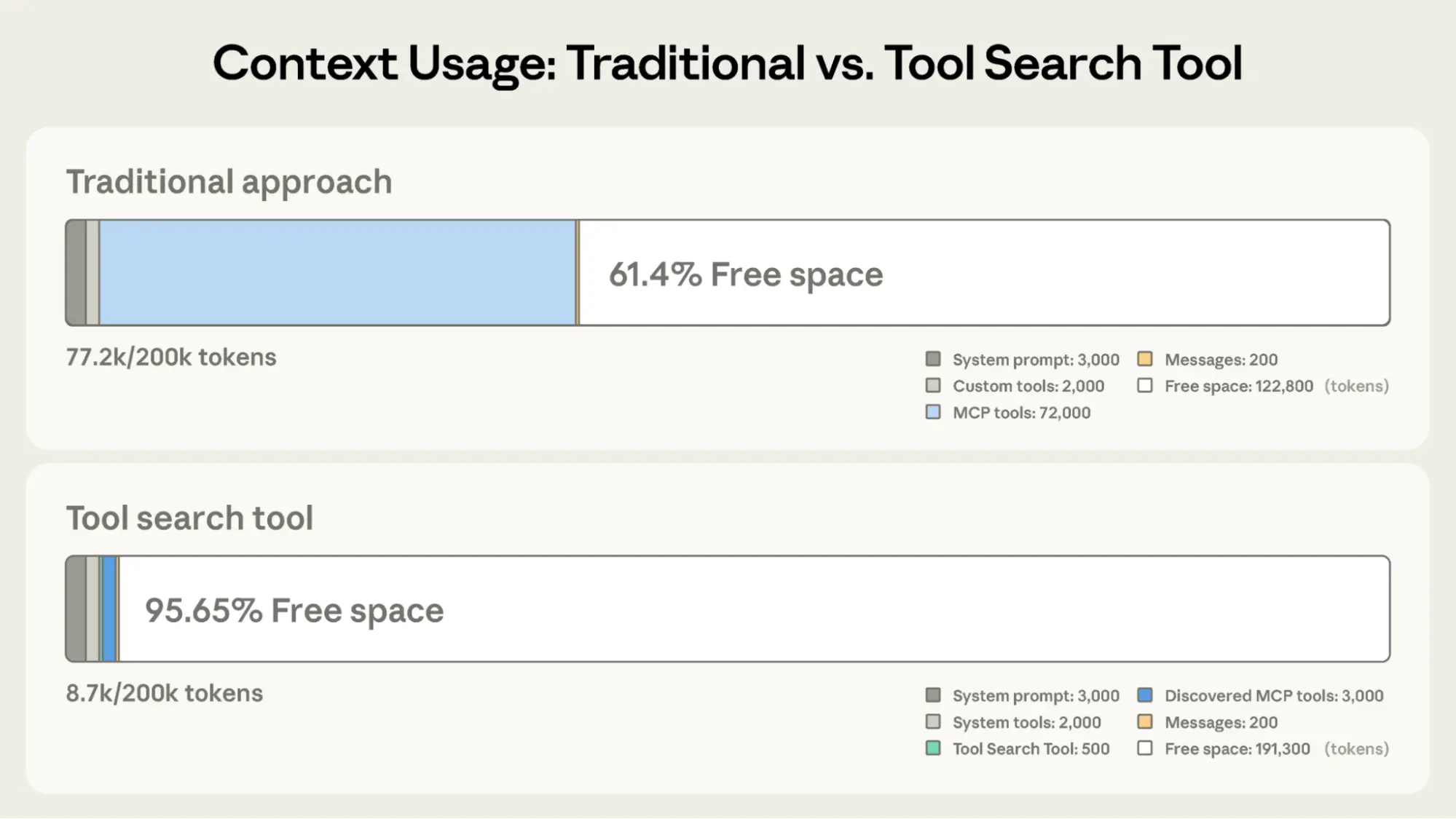
パターン2:プログラマティック呼び出しで37%削減
プログラマティック・ツール呼び出し(Programmatic Tool Calling)は、LLMが逐次的にツールを呼び出す代わりに、コードを生成してバッチ実行するパターンだ。
通常のツール呼び出しフローでは、LLMはツールAを呼び→結果をコンテキストに追加→ツールBを呼び→結果をコンテキストに追加、という形で処理する。各ステップでコンテキスト全体(ツール結果の履歴含む)を処理するため、複雑なワークフローではコンテキストが肥大化する。
プログラマティック呼び出しでは、LLMが「バッチ実行コード」を1回生成し、そのコードがサンドボックスで複数のツールを直接呼び出す。最終結果だけをLLMに返すため、中間結果がコンテキストに蓄積しない。
# プログラマティック呼び出しを受け付けるMCPツール(Python)
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("batch-executor")
@mcp.tool()
async def execute_batch_operations(
operations: list[dict],
return_only_final: bool = True
) -> dict:
"""
複数の操作をバッチで実行し、最終結果のみを返す。
各操作の中間結果はLLMコンテキストに返さないためトークンを節約できる。
Args:
operations: [{tool: str, params: dict, id: str}] の形式で操作を定義
return_only_final: True の場合、最終操作の結果のみ返す
"""
context = {} # 操作間でデータを共有するローカルコンテキスト
for i, op in enumerate(operations):
tool_name = op["tool"]
params = op.get("params", {})
op_id = op.get("id", f"step_{i}")
# 前のステップの結果を参照できる("$step_0.result" 形式)
resolved_params = resolve_references(params, context)
result = await execute_tool(tool_name, resolved_params)
context[op_id] = result
if return_only_final and context:
last_id = list(context.keys())[-1]
return {"final_result": context[last_id], "steps_count": len(operations)}
return {"results": context, "steps_count": len(operations)}
Anthropicのガイドによれば、このパターンにより複雑なワークフローでのトークン消費を約37%削減できる。
MCP・Claude Code周辺のトークン最適化ツール全般については、Claude Codeトークン最適化ツール比較2026|97%削減MCPから619バイトCLAUDE.mdまで5選でも詳しく解説している。
SkillsとMCPを組み合わせる
MCPがツールへの「アクセス」を提供するのに対し、Skillsはエージェントに「手順」を教える。この2つは補完関係にあり、組み合わせることで最も強力なエージェントを実現できる。
| MCP | Skills | |
|---|---|---|
| 何を提供するか | ツールへのアクセス(何ができるか) | 手続き的知識(どうやるか) |
| 具体例 | create_pr, merge_branch, add_comment |
「PRをレビューする6ステップ」 |
| 定義者 | MCPサーバー開発者 | Skills定義ファイル(.md) |
| 実行タイミング | エージェントがツールを呼んだとき | エージェントがタスクを受けたとき |
| ポータビリティ | MCP対応クライアント間で共有 | Skills対応クライアント間で共有 |
.png)
Anthropicのガイドが紹介するSkillsとMCPの組み合わせパターンは2つある。
パターンA:プラグインへのバンドル
GitHubのMCPサーバーとPRレビュースキルを一つの「GitHub Plugin」としてバンドルする。ユーザーがプラグインをインストールすれば、GitHubへのアクセス権限(MCP)とレビューの手順(Skill)を同時に取得できる。
パターンB:MCPサーバーからのSkill配布
MCPサーバーがResources(リソース)としてSkillファイルを提供する。エージェントがサーバーに接続したとき、自動的にそのサービス特有のSkillsが読み込まれる。
# MCPサーバーがResources経由で提供するSkill例
# resource URI: github://skills/pr-review.md
---
description: GitHubのPull Requestを効果的にレビューする手順
---
## PRレビューの手順
1. まず `get_pr_diff` でコード差分を取得する
2. `list_pr_comments` で既存コメントを確認する
3. セキュリティ・パフォーマンス・コードスタイルの順に確認
4. `add_review_comment` で行コメントを追加
5. `submit_review` で approve / request_changes / comment を送信
6. 重大な問題がある場合は `request_changes`、マージ可能なら `approve`
この設計により、MCPサーバーの開発者は「ツールの使い方」まで一緒に配布できる。ユーザーは「どのツールをどの順序で呼び出せばよいか」をエージェントに教える手間が省ける。
セキュリティの考え方:本番MCP実装のリスクと対策
本番システムへのMCP接続を実装する際には、セキュリティを設計の中心に置く必要がある。
プロンプトインジェクションへの対策
MCPサーバーが処理するデータは、攻撃者によって汚染されている可能性がある。メールの本文、GitHubのIssue、Webページのコンテンツ——これらにプロンプトインジェクション攻撃が埋め込まれている可能性がある。
(メール本文/Issue/Webページ)"] -->|"汚染されている
可能性"| B["MCPツールの
戻り値"] B -->|"そのまま渡すと危険"| C["LLMの
コンテキスト"] C -->|"意図しない指示として
実行されるリスク"| D["エージェントの
誤動作"] style B fill:#ff9999,color:#000 style D fill:#ff6666,color:#fff
# ❌ 危険:外部データをそのままツール結果に含める
@mcp.tool()
async def get_github_issue(issue_id: int) -> str:
issue = await github_api.get_issue(issue_id)
return issue["body"] # 攻撃者が body に悪意あるプロンプトを埋め込める
# ✅ 安全:構造化データとして返し、外部コンテンツを明示する
@mcp.tool()
async def get_github_issue(issue_id: int) -> dict:
issue = await github_api.get_issue(issue_id)
return {
"id": issue["number"],
"title": issue["title"],
"body": issue["body"],
"_content_warning": "body フィールドはユーザー生成コンテンツです"
}
最小権限の原則と実装チェックリスト
読み取り専用操作と書き込み操作のツールを分ける(読み取りツールの誤用リスクを下げる)
Elicitationで書き込み操作の前に確認を要求する(本番DB更新、メール送信等)
サービスアカウントを使用し、ユーザーアカウントのフルアクセストークンを渡さない
ツールのパラメータをホワイトリスト検証する(SQLインジェクション・コマンドインジェクション対策)
リクエストレート制限を設ける(ループしたエージェントによる大量API呼び出しを防ぐ)
本番環境ではStreamable HTTPを使い、STDIOは避ける
STDIOトランスポートのリスク
本番環境でMCPを使う場合、STDIOトランスポートには設計上のセキュリティ上の懸念が存在する。OX Securityの調査では、STDIO方式のMCPサーバーは適切に設定されていない場合に任意のOSコマンドが実行できる状態になりえることが報告されている。当サイトのセキュリティ記事群でもSTDIOトランスポートの設計欠陥とRCEのリスクを別途詳しく扱っている。
本番環境ではStreamable HTTPトランスポートを使用し、STDIOは避けることを強く推奨する。
設計原則のまとめと実装ロードマップ
Anthropicの公式ガイドが示す4原則と2つの最適化パターンを段階的に実装することで、本番品質のMCPエージェントが構築できる。
ただし、この7ステップすべてを常に実装すべきというわけではない。冒頭で触れたとおり、単一サービスへの単一エージェント接続であれば直接API呼び出しのままで十分なケースは多く、MCPサーバー化にはリモートサーバーの運用・CIMDやVaultsの学習コスト・認証基盤の保守という追加負担が伴う。接続先サービスが1〜2個、利用クライアントもClaude Code単体にとどまるような小規模プロジェクトでは、MCP移行自体がオーバーエンジニアリングになりうる点は公式ガイドでは強調されていない実務上の留意点だ。M×N問題が現実に発生する規模(複数エージェント×複数サービス、あるいは複数クライアントへの配布が必要な場合)に達してから段階的に導入する方が、投資対効果は見合いやすい。
| ステップ | 実装内容 | 主な効果 |
|---|---|---|
| 1. リモートサーバー | Streamable HTTPトランスポートへの移行 | クラウド・モバイル対応 |
| 2. インテント設計 | ツールをユーザーの意図でグループ化 | LLMの判断精度向上 |
| 3. コードオーケストレーション | 大規模サービスにコード実行ツールを提供 | ツール数削減・柔軟性向上 |
| 4. リッチセマンティクス | ElicitationとMCP Apps実装 | UX改善・安全な実行確認 |
| 5. 認証(CIMD+Vaults) | CIMDで登録自動化、Vaultsでトークン管理 | 開発工数削減・セキュリティ強化 |
| 6. ツール検索 | 遅延ロード実装 | トークン85%以上削減 |
| 7. バッチ実行 | プログラマティック呼び出し | トークン約37%削減 |
サーバー"] --> S2["2.インテント
設計"] --> S3["3.コード
オーケストレーション"] --> S4["4.リッチ
セマンティクス"] --> S5["5.認証
CIMD+Vaults"] --> S6["6.ツール検索"] --> S7["7.バッチ実行"] style S1 fill:#4A90D9,color:#fff style S7 fill:#4A90D9,color:#fff
MCPサーバーをゼロから構築する実装手順は、冒頭で紹介したピラー記事で詳しく解説している。
MCPのアーキテクチャ全体の理解には、Pydantic作者Samuel Colvinによる「MCP is all you need」——Pydantic作者が語るMCPの正しい使い方も参照してほしい。
参照ソース
・Building agents that reach production systems with MCP — Anthropic Official Blog
・MCP Transports — Model Context Protocol Official Documentation
・MCP Authorization Specification — Model Context Protocol
・Claude Managed Agents Overview — Anthropic Platform Docs
・modelcontextprotocol/modelcontextprotocol — GitHub