この記事ではLLMに特化して解説する。LLM全般の仕組みやローカル実行は LLMとは?仕組み・主要モデル比較・ローカル実行・量子化を一気にまとめる2026年版 を参照してほしい。
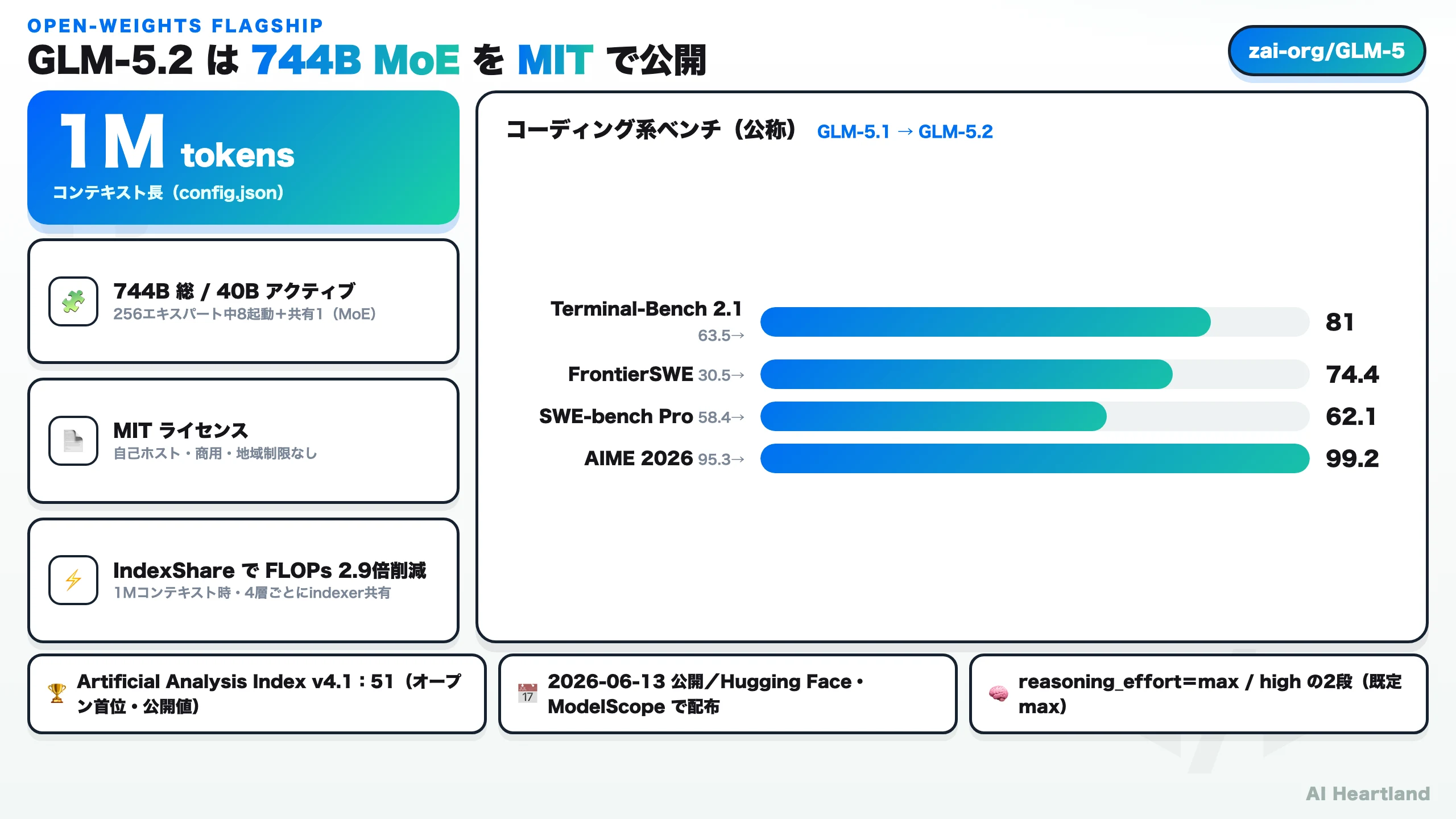
GLM-5.2は、中国のAI企業Z.ai(旧Zhipu AI/智谱AI)が2026年6月13日に重みを公開した、744B MoEのオープンウェイト大規模言語モデルだ。MITライセンスで配布され、1Mトークンのコンテキストと長期タスク(long-horizon)向けのコーディング性能を掲げる。まず「このモデルが何を持っているか」を1枚で示す。
Z.ai(智谱AI)がGLM-5.2をいつ・どの形式で公開したか、一次ソースの所在
744B MoE・1Mコンテキスト・IndexShareというアーキテクチャ上の特徴
公称ベンチマークと、Claude・GPT・DeepSeek・Qwenとの公称比較で読める位置
MITライセンスが許す範囲と、商用利用で確認すべき点
744Bモデルをローカルで動かすときに直面するメモリとコストの現実
・結局なにができる:1Mトークンのコンテキストで、多段のコーディングやエージェント実行を長時間続けさせられる
・なにを解決する:長い作業の途中でモデルが息切れする問題を、long-horizon向けの学習とIndexShareによる効率化で抑える
・なにを代替する:MITで自己ホストできるため、コーディング用途のクローズドAPIを置き換えられる余地がある(ただし重みは実測1,403 GiBで、置き換えの前提は相応の設備)
Hugging Faceの zai-org/GLM-5.2 とModelScopeで配布され、ライセンスはMIT。
本記事は、Hugging Faceのモデルカードと config.json、GitHubの zai-org/GLM-5 README、公式ブログ、arXivの技術レポートという一次ソースだけを根拠に、GLM-5.2の素性を整理する。
噂段階の数値や、出典の取れない性能主張は扱わない。
数値はすべて「公称(モデルカード・README掲載)」または「公開(第三者評価)」と明記する。
We're introducing GLM-5.2, our latest flagship model for long-horizon tasks. It marks a substantial leap in long-horizon task capability over its predecessor GLM-5.1 and, for the first time, delivers that capability on a solid 1M-token context.
(GLM-5.2を発表する。長期タスク向けの最新フラッグシップであり、前身のGLM-5.1から長期タスク能力を大きく引き上げ、それを初めて安定した1Mトークンのコンテキストで実現した。)
— Hugging Face モデルカード zai-org/GLM-5.2

GLM-5.2 とは:Z.ai(智谱AI)の最新オープンモデルで何ができるか
GLM-5.2を出したのはZ.aiという会社だ。
旧称はZhipu AI(智谱AI)で、清華大学発のスタートアップとして知られる。
Hugging Face上の組織名は zai-org であり、GLM-4.5・GLM-5・GLM-5.1といった系譜のモデルを同じ組織アカウントから公開してきた。
まず「このモデルで何ができるのか」に一言で答えると、長いコードベースを丸ごと読ませ、多段のコーディングやツール実行を長時間続けさせる用途に向いたオープンウェイトモデルだ。 モデルカードはGLM-5.2を「our latest flagship model for long-horizon tasks(長期タスク向けの最新フラッグシップ)」と位置づける。 ここで言う long-horizon task とは、数十ステップにわたる自律的なコーディングやエージェント実行のように、長い文脈と多段の判断を要する作業を指す。
公開日は2026年6月13日。 配布チャネルは複数あり、重みそのものを手元に置ける点が要点になる。
・Hugging Faceでの重み配布(zai-org/GLM-5.2、Safetensors形式・BF16)
・ModelScopeでの重み配布(ZhipuAI/GLM-5.2)
・FP8量子化版の公式配布(zai-org/GLM-5.2-FP8)
・Z.ai APIプラットフォーム(https://docs.z.ai/guides/llm/glm-5.2)
・チャットUI https://chat.z.ai
GLM-5.2が掲げる4つの新機能を、README・モデルカードの記述に沿って並べる。
・Solid 1M Context:長期作業を安定して支える1Mトークンのコンテキスト
・Advanced Coding with Flexible Effort:思考量(effort level)を複数段階で切り替え、性能とレイテンシのバランスを取れる強化されたコーディング能力
・Improved Architecture:IndexShareの提案により、1Mコンテキスト時の1トークンあたりFLOPsを2.9倍削減
・Pure Open:MITライセンスによる「地域制限のない」公開
最後の「Pure Open」は、モデルカードが原文で An MIT open-source license — no regional limits, technical access without borders と書いている点だ。
中国発のモデルでは利用地域や用途に制約がつく例もあるなか、GLM-5.2は重み配布とライセンスのうえで地域制限を設けないことを明示している。
ライセンスの解釈は利用者の責任になるため、採用前に必ず最新のLICENSE本文を自分で読むことを勧める。
GLM 系譜の中の位置付け:GLM-4.5 から GLM-5.2 へ何を解決してきたか
GLM-5.2は突然現れたモデルではなく、GLM系統の連続した更新の一段だ。 このセクションでは「GLM-5系が何を解決しようとしてきたか」を系譜で押さえる。 Hugging Faceの公開履歴とREADMEの記述から、近い世代の関係を時系列で示す。
355B / 32B active
オープン世代の確立"] --> B["GLM-5
744B / 40B active
DSA導入・arXiv:2602.15763"] B --> C["GLM-5.1
agentic engineering
長期タスク強化"] C --> D["GLM-5.2
2026-06-13公開
1Mコンテキスト + IndexShare"]
READMEによれば、GLM-4.5からGLM-5への移行で総パラメータは355B(32Bアクティブ)から744B(40Bアクティブ)へスケールし、事前学習データも23Tトークンから28.5Tトークンへ拡大した。 このときにDeepSeek Sparse Attention(DSA)を統合し、長文脈能力を保ったまま推論コストを抑える設計へ切り替えている。 つまりGLM-5世代の狙いは、最初から「複雑なシステム開発と長期エージェントタスク」だった。 GLM-5.2の技術的な土台は、arXivに公開された技術レポート「GLM-5: from Vibe Coding to Agentic Engineering」(arXiv:2602.15763)にある。
GLM-5.1との差分を、公称ベンチマークから読み取れる範囲で整理する。 Artificial Analysisによれば、GLM-5.2はGLM-5.1と同じサイズ(744B総・40Bアクティブ)でありながら、Intelligence Index v4.1で11ポイント上回るとされる。 つまり今回の更新は、パラメータ規模の拡大ではなく、アーキテクチャと学習の改良による性能向上という性格を持つ。
| 項目 | GLM-5.1 | GLM-5.2 |
|---|---|---|
| 公開 | GLM-5.2の前世代 | 2026年6月13日 |
| 規模(公称) | 744B総 / 40Bアクティブ MoE | 744B総 / 40Bアクティブ MoE |
| コンテキスト | 前世代 | 1Mトークン(公式に「solid」と表現) |
| SWE-bench Pro(公称) | 58.4 | 62.1 |
| AIME 2026(公称) | 95.3 | 99.2 |
| Terminal Bench 2.1(公称) | 62.0 | 81.0 |
| Artificial Analysis Index | 約40(公開) | 51(公開・オープン首位) |
数値の伸びは長期タスク系(Terminal Bench、SWE-bench Pro)で大きい。 GLM-5.2が「long-horizon tasks向けフラッグシップ」を名乗る根拠は、この差分に表れている。 言い換えれば、GLM-5.2が解決するのは「エージェントが途中で息切れする」という従来モデルの弱点で、長く走らせるほど成果が積み上がる設計を狙っている。
アーキテクチャと技術特性:744B MoE と IndexShare は何を代替するのか
GLM-5.2の中身は、Hugging Faceに同梱された config.json で確認できる。
モデルカード本文はパラメータ総数を明記していないが、config.json のMoE構成は公式の一次情報として読める。
主要な設定値を抜き出す。
| 設定(config.json) | 値 | 意味 |
|---|---|---|
| model_type | glm_moe_dsa | MoE + DSA(疎なアテンション)構成 |
| num_hidden_layers | 78 | 78層 |
| first_k_dense_replace | 3 | 最初の3層はdense、以降はMoE |
| n_routed_experts | 256 | ルーテッドエキスパート256個 |
| num_experts_per_tok | 8 | 1トークンあたり8エキスパートを起動 |
| n_shared_experts | 1 | 共有エキスパート1個 |
| hidden_size | 6144 | 隠れ層次元 |
| max_position_embeddings | 1048576 | 1Mトークンのコンテキスト |
| kv_lora_rank / q_lora_rank | 512 / 2048 | MLA系の低ランク圧縮アテンション |
| num_nextn_predict_layers | 1 | MTP(投機的デコード用)層 |
公称の総パラメータは744B、1トークンの推論で実際に動くのは約40Bだ(256のルーテッドエキスパートのうち8と、共有1を起動する)。 この比率がMoEの要点になる。 保持すべき重みは744B分だが、1トークンの計算コストは40B級にとどまる。 表現力の上限を大きく取りつつ、推論時の演算量を抑える設計だ。 「何を代替するのか」で言えば、密(dense)な巨大モデルを1台に載せて回すコストを、疎なMoEと圧縮アテンションで置き換える発想になる。
アーキテクチャ上の新しさはIndexShareにある。
モデルカードによれば、IndexShareは「同じindexerを4つの疎アテンション層ごとに再利用する(reuses the same indexer across every four sparse attention layers)」仕組みで、1Mコンテキスト時の1トークンあたりFLOPsを2.9倍削減する。
config.json の index_topk_freq: 4、index_topk: 2048、indexer_types に並ぶ full と shared のパターンが、この4層周期の共有構造に対応している。
詳細はIndexShareの論文(arXiv:2603.12201)が扱う。
もう一つ、MTP層(Multi-Token Prediction)の改良で投機的デコードの受理長を最大20%伸ばしたとされる。 投機的デコードは、小さなドラフトで先読みした複数トークンを本体が一括検証する高速化手法で、受理長が伸びるほど生成が速くなる。
最大1Mコンテキスト"] --> DENSE["先頭3層: dense"] DENSE --> SPARSE["残り75層: MoE層
256エキスパート中8起動 + 共有1"] SPARSE --> ATT["DSA 疎アテンション
IndexShare: indexerを4層ごとに共有"] ATT --> MTP["MTP層で投機的デコード
受理長 最大+20%"] MTP --> OUT["出力
最大131,072トークン"]
公称ベンチマーク:モデルカードとREADME掲載値で何ができるかを測る
ここからの数値は、すべてHugging Faceモデルカードと zai-org/GLM-5 READMEに掲載された公称値だ。
開発元による測定であり、ハーネスや評価条件は項目ごとに異なる。
読者の用途での再現確認を前提に読んでほしい。
まず開発元がREADMEに掲載しているベンチマーク比較画像を示す。
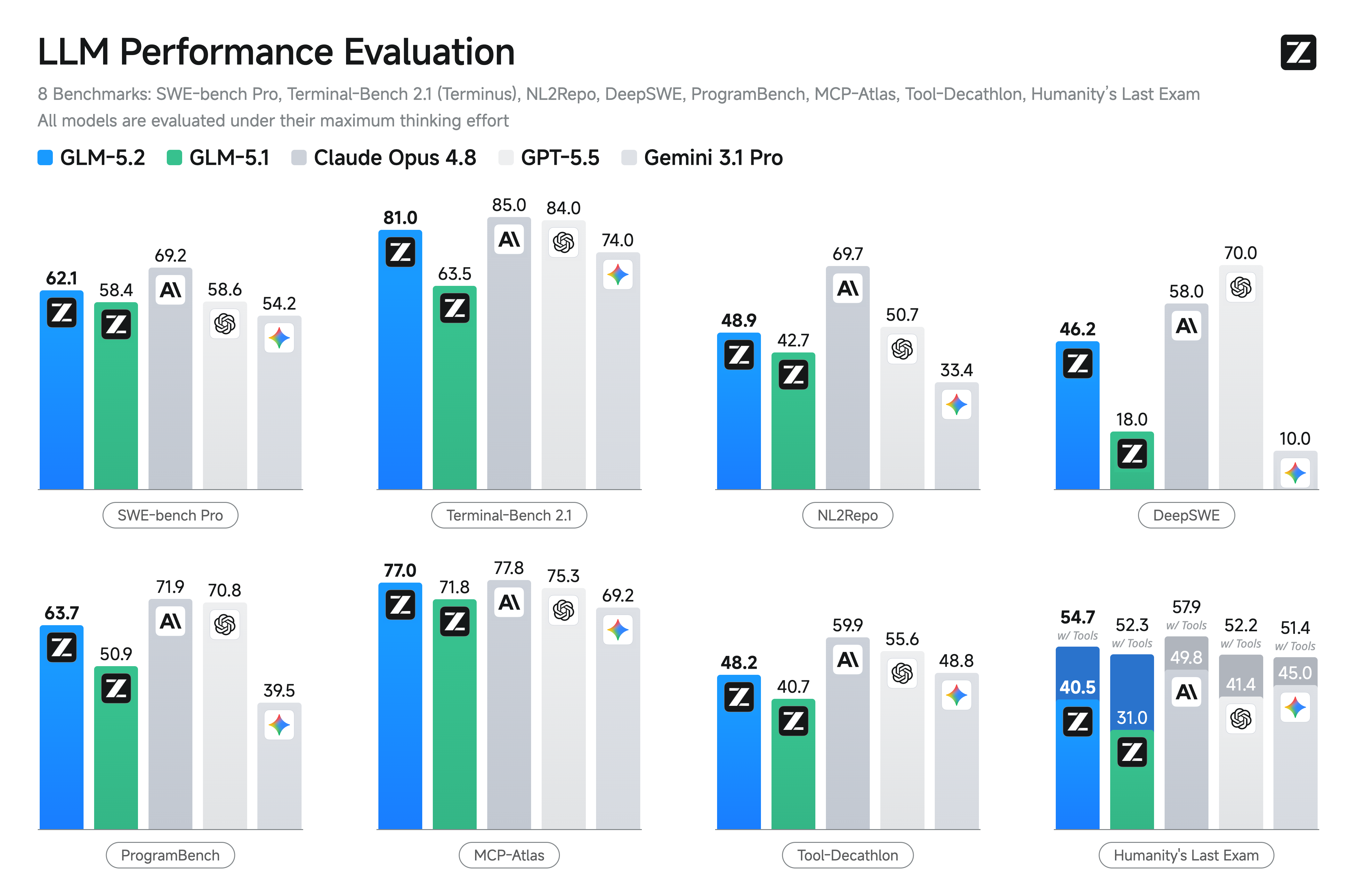
READMEの本文は、標準的なコーディングベンチでGLM-5.2が「the strongest open-source model(最強のオープンソースモデル)」であり、Terminal-Bench 2.1で81.0対62.0、SWE-bench Proで62.1対58.4とGLM-5.1を大きく上回ると述べる。 さらに「Terminal-Bench 2.1(81.0)はClaude Opus 4.8(85.0)の数ポイント差まで迫り、Gemini 3.1 Proを上回る」とも書いている。 モデルカードに掲載された主要ベンチマークを表で押さえる。
| ベンチマーク | 分類 | GLM-5.2(公称) | GLM-5.1(公称) |
|---|---|---|---|
| HLE | 推論 | 40.5 | 31 |
| HLE (w/ Tools) | 推論 | 54.7 | 52.3 |
| AIME 2026 | 数学 | 99.2 | 95.3 |
| HMMT Feb. 2026 | 数学 | 92.5 | 82.6 |
| GPQA-Diamond | 知識 | 91.2 | 86.2 |
| SWE-bench Pro | コーディング | 62.1 | 58.4 |
| NL2Repo | コーディング | 48.9 | 42.7 |
| Terminal Bench 2.1 (Terminus-2) | コーディング | 81.0 | 62.0 |
| FrontierSWE (Dominance) | コーディング | 74.4 | 30.5 |
| SWE-Marathon | コーディング | 13.0 | 1.0 |
| MCP-Atlas (Public Set) | エージェント | 76.8 | 71.8 |
| Tool-Decathlon | エージェント | 48.2 | 40.7 |
伸び幅が際立つのはFrontierSWE(30.5→74.4)とSWE-Marathon(1.0→13.0)、Terminal Bench(62.0→81.0)だ。 いずれも長く続くコーディング作業を測る項目で、GLM-5.2が長期タスク向けを名乗る理由とつながる。 一方、HLE(人類最後の試験)は40.5で、絶対値としてはまだ高くない領域だ。 得意分野と苦手分野が数値にはっきり出ている点は、採用判断のときに見落とさないほうがいい。 「何ができるか」を数値で言えば、GLM-5.2は数学(AIME 99.2)とエージェント的コーディングで強く、純粋な難問知識(HLE)ではまだ余地がある、という読み方になる。
競合モデルとの対比:DeepSeek・Qwen・Claude・GPT・Gemini のどれを代替できるか
モデルカードは同じ表の中で、競合モデルの公称・引用値も並べている。
ここでは代表的な項目だけを取り出して対比する。
他社列の数値はモデルカードに記載された値であり、* 付きは出典元での引用値を意味する(条件が異なる可能性がある)。
| ベンチ(公称/引用) | GLM-5.2 | DeepSeek-V4-Pro | Qwen3.7-Max | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|
| SWE-bench Pro | 62.1 | 55.4 | 60.6 | 69.2 | 58.6 | 54.2 |
| Terminal Bench 2.1 | 81.0 | 64 | 75 | 85 | 84 | 74 |
| FrontierSWE | 74.4 | 29.0 | — | 75.1 | 72.6 | 39.6 |
| GPQA-Diamond | 91.2 | 90.1 | 90 | 93.6 | 93.6 | 94.3 |
| AIME 2026 | 99.2 | 94.6 | 97 | 95.7 | 98.3 | 98.2 |
| MCP-Atlas | 76.8 | 73.6 | 76.4 | 77.8 | 75.3 | 69.2 |
表から読めることを、煽らずに整理する。 コーディング系(SWE-bench Pro、FrontierSWE)でGLM-5.2はGPT-5.5・DeepSeek・Qwenを上回る項目があり、Claude Opus 4.8とは互角からやや下という位置にある。 数学のAIME 2026では99.2でClaude Opus 4.8を上回る。 一方、知識系のGPQA-Diamondでは91.2で、クローズドの上位モデル(93〜94台)にわずかに届かない。 「どのモデルを代替できるか」で言えば、コーディング・エージェント用途でクローズドモデルの費用を抑えたいときの自己ホスト候補として、DeepSeek/Qwen系オープンモデルの上位互換に立つ、という位置づけが読み取れる。
独立評価では、Artificial AnalysisがIntelligence Index v4.1でGLM-5.2(max)に51を付け、オープンウェイトモデルの首位とした。 MiniMax-M3(44)やDeepSeek V4 Pro(max、44)を上回る、というのがArtificial Analysisの公開した位置づけだ。
GLM-5.2 is the new leading open weights model on the Artificial Analysis Intelligence Index.
(GLM-5.2はArtificial Analysis Intelligence Indexで首位のオープンウェイトモデルとなった。)
— Artificial Analysis
VentureBeatは、GLM-5.2が複数の長期コーディングベンチでGPT-5.5を「6分の1のコスト」で上回ると報じた。 コスト効率の主張は配信元の記事に依存するため、自分の課金体系に当てはまるかは個別に検証する必要がある。
GLM-5.2 の使い方:チャットUI・API・自己ホストの3ルートを使い分ける
GLM-5.2を触る入口は3つある。 どれを選ぶかは「重みを手元に置く必要があるか」で決まる。 順に難度と初期コストが上がるので、上から試すのが早い。
| ルート | 入口 | 準備するもの | 向いている場面 |
|---|---|---|---|
| ① チャットUI | chat.z.ai | アカウントのみ | 応答の質・日本語の癖を数分で確かめる |
| ② API | api.z.ai/api/paas/v4 | APIキー | 自分のコードやエージェントに組み込んで試す |
| ③ 自己ホスト | Hugging Face / ModelScope | 数百GB級のメモリとGPU | データを外に出せない・長時間回す |
①と②はREADMEが案内する公式の入口で、重みのダウンロードは要らない。 ③だけが後述のメモリ要件に直面する。 「まずGLM-5.2が自分のタスクで使えるか」を判断する目的なら、①か②で十分に見極められる。
②のAPIはOpenAI互換のチャット補完形式で呼べる(エンドポイントとキーはZ.ai APIプラットフォームで取得する)。
GLM-5系で押さえておきたいのは、思考量を切り替える reasoning_effort パラメータだ。
READMEによれば max と high の2段階を受け付け、既定は max(未設定や high 以外を指定するとMaxで動く)。ベンチマークやリーダーボードの再現は既定のMaxで行い、応答を速くしたいときだけ reasoning_effort="high" を明示する。思考自体は enable_thinking=false で完全に切れる。
ここは初見で間違えやすい。 「effortを指定しなければ軽く動く」のではなく、指定しないと一番重いMaxで動くという向きだ。 READMEの記述を設定値ごとに整理しておく。
| 設定 | 実際に動く思考量 | READMEが想定する用途 |
|---|---|---|
| 未設定(既定) | Max | ベンチマーク・リーダーボードの再現 |
reasoning_effort="high" | High | 応答を速くしたいとき(明示指定が必須) |
reasoning_effort="max" | Max | 既定と同じ(明示しても挙動は変わらない) |
| 上記以外の値 | Max | —(high 以外はMaxに落ちる) |
enable_thinking=false | 思考なし | 思考を完全に切る |
レイテンシや課金トークンが想定より膨らむときは、まずこの既定値を疑うといい。
# OpenAI互換クライアントでGLM-5.2を呼ぶ最小例(キー・URLはZ.ai APIプラットフォームで取得)
from openai import OpenAI
client = OpenAI(api_key="<ZAI_API_KEY>", base_url="https://api.z.ai/api/paas/v4")
resp = client.chat.completions.create(
model="glm-5.2",
messages=[{"role": "user", "content": "このリポジトリの設計方針を要約して"}],
extra_body={"reasoning_effort": "high"}, # 既定はmax。速さ優先ならhigh、思考オフはenable_thinking=false
)
print(resp.choices[0].message.content)
このワンステップで「1Mコンテキストに長文を投げて要約させる」「エージェントのツール呼び出しを回す」といった検証ができる。 自己ホストへの投資判断は、この段階で自分のタスクに対する手応えを掴んでから行うのが堅実だ。
ライセンスと商用利用:MIT が許す範囲で何ができるか
GLM-5.2のライセンスはMITだ。
config.json の隣に置かれたモデルカードのメタデータにも license: mit と記載されている。
MITは、許諾表示を残せば、複製・改変・再配布・商用利用・サブライセンスを広く認める。
重みを社内サーバに置いて自己ホストする、独自データでファインチューニングする、製品に組み込んで販売する、といった使い方が原則として可能だ。
GLM-5.2のMIT採用で実務上効くのは次の点だ。
・自己ホストできるため、APIに機微データを送らずに済む
・ファインチューニング後の派生モデルも自分の裁量で配布・販売できる
・地域制限がないとモデルカードが明記しており、利用地域を理由に止まりにくい
・許諾表示(著作権表示とライセンス文の同梱)の義務は残るため、再配布時の同梱を忘れない
ただし、MITはモデルの出力に対する責任までは引き受けない。 生成物の権利や安全性、各国の規制適合は利用者側の判断になる。 商用採用の前には、LICENSEファイルの原文と、Z.ai側の利用規約(API利用時)を別々に確認しておきたい。 MITという選択は、同じオープンウェイトでも独自ライセンス(例:一定規模以上の商用に別許諾を求める形態)を採る競合と比べ、採用時の法務コストを下げる点で「何を代替できるか」に直結する。
ローカル運用の現実:744B をどう動かすか
オープンウェイトであることと、手元のマシンで気軽に動くことは別の話だ。 GLM-5.2は744Bの重みを持つため、ローカル運用のハードルは高い。 READMEが挙げる対応フレームワークは次の通りだ。
・SGLang(v0.5.13.post1以降、公式cookbookあり)
・vLLM(v0.23.0以降、公式recipesあり)
・Transformers(v0.5.12以降、glm_moe_dsa モデルドキュメントあり)
・KTransformers(v0.5.12以降、CPUオフロード併用のチュートリアルあり)
・Unsloth(v0.1.47-beta以降、量子化・ファインチューニング向けガイドあり)
・Ascend NPU向けにはvLLM-Ascend・xLLM・SGLang
ここは推定で語られがちだが、配布物の実サイズはHugging Face APIで実測できる。 2026-07-29時点で両リポジトリのsafetensorsを合計すると、次の値になった(本記事で実測)。
| 配布形式 | shard数 | safetensors合計(実測) | GiB換算 |
|---|---|---|---|
zai-org/GLM-5.2(BF16) | 282 | 1,506,667,387,408 バイト | 約1,403 GiB(1.51 TB) |
zai-org/GLM-5.2-FP8 | 141 | 755,632,050,320 バイト | 約704 GiB(0.76 TB) |
FP8版はBF16版のちょうど50.2%で、shard数も282→141と半分だ。 READMEやモデルカードが言う「FP8ならおおむね半分」は、配布サイズの実測でも裏付けが取れる。 なお1,506,667,387,408バイトを2バイト/パラメータで割ると約753Bとなり、公称744Bとおおむね整合する(差分は埋め込みやMTP層など、量子化対象外の要素を含むため)。
4ビット量子化まで落とせば単純計算で約350〜380GiBが目安になるが、これは推定であり、量子化方式や実装で増減する。 いずれにせよ単一の消費者向けGPUには載らない。 現実的な選択肢は、複数の高VRAM GPUを束ねる構成か、KTransformersのようにCPUオフロードを併用する構成、あるいは大容量ユニファイドメモリを積んだ環境になる。 加えて、これは重みだけの値だ。 1Mコンテキストを実際に使うならKVキャッシュ分が別途乗るため、上表はあくまで下限として読んでほしい。
代表的な推論フレームワークを早見表にまとめる(対応最小版はREADME記載値)。
| フレームワーク | 対応最小版 | 主な用途 | 補足 |
|---|---|---|---|
| SGLang | v0.5.13.post1〜 | 高スループット推論 | 公式cookbookあり |
| vLLM | v0.23.0〜 | OpenAI互換サーバ | 公式recipesあり |
| Transformers | v0.5.12〜 | 検証・研究 | glm_moe_dsa モデルドキュメント |
| KTransformers | v0.5.12〜 | CPUオフロード併用 | 大容量RAMで744Bを分散 |
| Unsloth | v0.1.47-beta〜 | 量子化・ファインチューニング | 4bit量子化ガイドあり |
FP8版(zai-org/GLM-5.2-FP8)を使う場合の最短手順は、重みを取得してから推論サーバを起動する2ステップだ。
# 1) FP8重みを取得(BF16版よりおよそ半分のディスク・メモリで済む)
huggingface-cli download zai-org/GLM-5.2-FP8 --local-dir ./GLM-5.2-FP8
# 2) vLLMでOpenAI互換サーバとして起動(GPU枚数は環境に合わせる。詳細は公式recipesを参照)
vllm serve ./GLM-5.2-FP8 --served-model-name glm-5.2 --tensor-parallel-size 8
SGLangを使う場合は、同じ重みを次のように起動する(対応版はv0.5.13.post1以降。フラグは公式cookbookで確認する)。
python -m sglang.launch_server --model-path ./GLM-5.2-FP8 --tp 8 --host 0.0.0.0 --port 30000
zai-org/GLM-5.2
BF16 または FP8"] --> DL["ダウンロード
BF16は約1.4〜1.5TB / FP8は約半分"] DL --> Q["量子化
4bit等で約370〜400GB(推定)"] Q --> ENG["推論エンジン
SGLang / vLLM / KTransformers / Unsloth"] ENG --> RUN["マルチGPU or 大容量メモリで実行"]
ローカルLLMを動かす土台づくりについては ローカルLLMツールガイド【2026年版】 で、Ollamaを使った具体的な手順は Ollama 0.24でOpenAI Codex CLIがローカルLLMで動く で扱っている。
GLM-5.2 のサイズ・スペック早見表:数字だけを1か所にまとめる
ここまでで出てきた数値を、確認用に1枚へ集約する。
出典は Hugging Face モデルカード・同梱 config.json・zai-org/GLM-5 README、および本記事のHugging Face API実測だ。
| 項目 | 値 | 出典 |
|---|---|---|
| 総パラメータ | 744B(公称) | README ダウンロード表「744B-A40B」 |
| アクティブパラメータ | 約40B / トークン | 同上(256エキスパート中8+共有1) |
| 層数 | 78層(先頭3層はdense) | config.json |
| 最大コンテキスト | 1,048,576トークン(1M) | config.json max_position_embeddings |
| 最大出力 | 131,072トークン | config.json |
| アーキテクチャ | MoE + DSA(glm_moe_dsa) | config.json model_type |
| BF16 配布サイズ | 約1,403 GiB / 282 shard | Hugging Face API 実測(2026-07-29) |
| FP8 配布サイズ | 約704 GiB / 141 shard | Hugging Face API 実測(2026-07-29) |
| ライセンス | MIT | モデルカード metadata license: mit |
| 公開日 | 2026年6月13日 | 公式ブログ・モデルカード |
サイズを見て自己ホストが現実的でないと判断した場合でも、前掲の①チャットUI・②APIのルートは残る。 「744Bだから手が出ない」と「GLM-5.2を使えない」は別の話だ。
なおZ.aiは同じ組織からモデル以外のOSSも継続して公開している。 GLMファミリー向けのスキル集をまとめた GLM-Skills はその一例で、モデルを採用する際は周辺リポジトリも合わせて見ておくと組み込みの手数が減る。
制限事項・注意点
最後に、GLM-5.2を評価するときに踏まえておきたい点を、事実ベースで挙げる。
公開時点で開発元の公式ベンチマークの一部が出そろっていなかった、という指摘がある。 Artificial Analysisなどの第三者評価が先行し、開発元の詳細値が後追いになった項目があった。 コミュニティの反応は概ね好意的(あるトラッカーでは約91%が肯定)だったが、否定的な声は2点に集まった。 一つは、「オープン」を掲げつつ実利用の入口が有料のCoding Plan経由に見える点への違和感。 もう一つは、大きな仕様更新に対してローンチ時のベンチ提示が手薄に見えた点だ。 これらは観察された評価であり、現在の配布状況はモデルカードと公式ブログで都度確認してほしい。
中国発のモデルである点については、事実だけを記しておく。 GLM-5.2のモデルカードは学習データや内容モデレーションの詳細を網羅的には公開していない。 中国国内のAIサービスには規制由来の出力制約が存在するが、自己ホストするオープンウェイトでその制約がどう作用するかは、モデルや運用設定によって変わる。 特定の話題での挙動が気になる用途なら、自分の環境で実際に試して確認するのが確実だ。 本記事は価値判断を下さず、判断材料の所在だけを示す。
数値はすべて公称・公開値である点も繰り返しておく。 ベンチマークは測定条件で動く。 採用を検討するなら、自分のタスクで小さく走らせて、公称値が再現するかを見るのが一番早い。
まとめ
GLM-5.2は、Z.ai(智谱AI)が2026年6月13日にMITで公開した744B MoEのオープンウェイトモデルだ。 1Mコンテキスト、IndexShareによる疎アテンションの効率化、長期タスク向けの公称ベンチ改善が要点になる。 Artificial Analysisの独立評価ではオープン首位(Index 51)とされ、コーディング系では一部のクローズドモデルに迫る公称値を示した。 一方で744Bの重みはローカル運用のハードルが高く、商用採用にはライセンス本文の確認が要る。 重みが手元に置ける以上、まずはAPIやチャットUIで挙動を確かめ、自分のタスクで公称値が再現するかを小さく検証することから始めるのが現実的だ。
参照ソース
・zai-org/GLM-5.2 — Hugging Face モデルカード(公開日・機能・ベンチマーク・ライセンス・config.json)
・zai-org/GLM-5.2-FP8 — Hugging Face(FP8配布版・shard数と配布サイズの実測元)
・zai-org/GLM-5 — GitHub README(GLM-5.2/5.1/5シリーズ概要・ダウンロード表・対応フレームワーク・reasoning_effort・bench_52.png)
・Z.ai 公式ブログ GLM-5.2(公式発表)
・GLM-5: from Vibe Coding to Agentic Engineering(arXiv:2602.15763)(技術レポート)
・IndexShare(arXiv:2603.12201)(疎アテンションのindexer共有)
・GLM-5.2 — Artificial Analysis(独立評価・Intelligence Index v4.1)





