Claude Code トークン削減のために、コードベースに質問するたびにGlob・Grep・Readが連鎖して1回の質問で数十万トークンを消費する経験は多くの開発者が持っているはずだ。graphify(Graphify-Labs/graphify) は、その問題に対して「コードベースを事前に知識グラフへ圧縮し、AIアシスタントがgrepの代わりにグラフを参照する」というアプローチで挑むOSSスキルだ。PyPI graphifyy 経由で配布される本格的なツールで、READMEには1問あたりトークン消費を71.5倍削減したベンチマーク結果が掲載されている。
なお本記事の初出時は個人アカウント safishamsi のリポジトリだったが、現在は組織アカウント Graphify-Labs へ移管されている(旧URLはリダイレクトで生き続ける)。移管後の実測値は後半の「リポジトリ移管とプロジェクトの現在地」で扱う。
この記事ではgraphifyの仕組み・インストール手順・Claude Code/Codex/Cursorでの常時ON連携・MCP統合・claude トークン節約の本質をまとめる。Claude Code全体の使い方はClaude Code完全ガイド2026:インストールから本番運用までを参照してほしい。同種の knowledge graph claude code 連携を比較検討したい場合は本記事末尾の比較表が役に立つ。
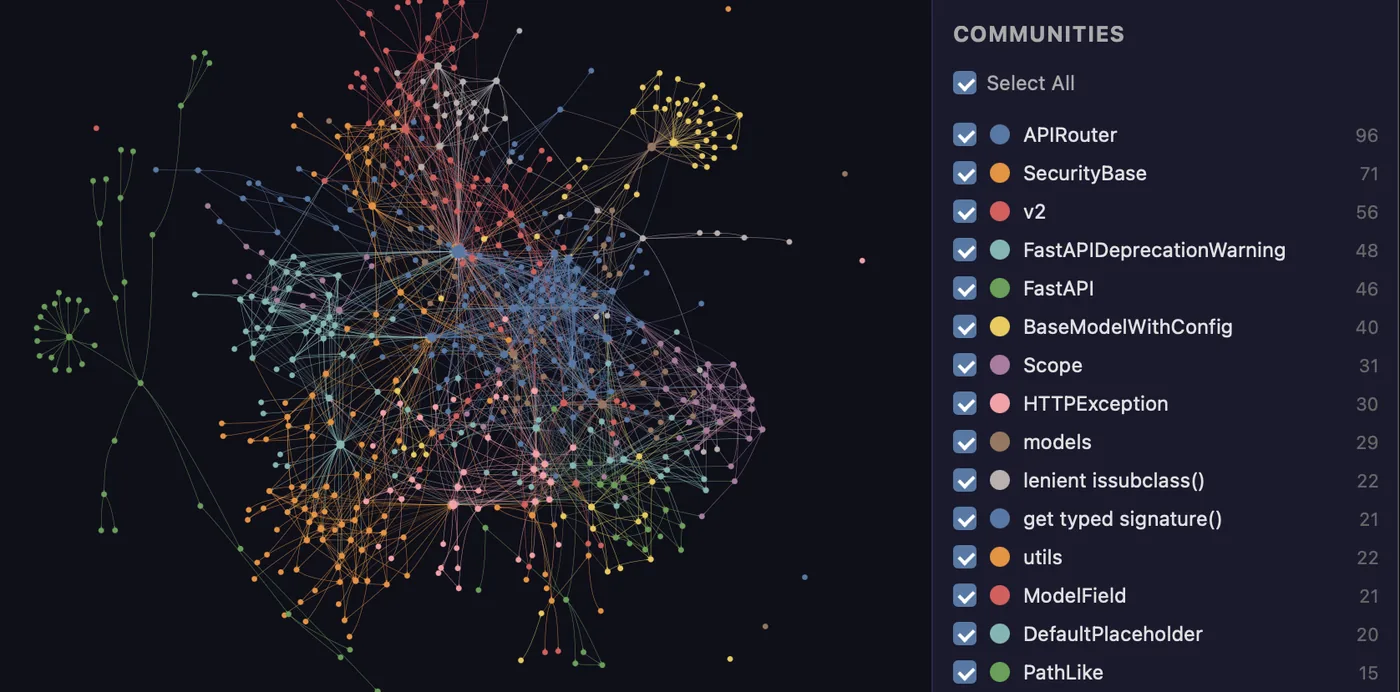
docs/graph-hero.png より)- graphifyはコード・PDF・画像・動画から知識グラフを作り、Claude Codeなどのアシスタントが grepでなくグラフナビゲーション で回答するよう仕向けるスキル。READMEの実測で1問あたり71.5倍のClaude code トークン削減
- tree-sitterでASTを抽出(25言語)→ Whisperで動画を転写 → Claudeサブエージェント並列で意味抽出 → Leidenでコミュニティ検出、という3パスのパイプライン
- PreToolUseフックでGlob/Grep直前に「グラフを先に読め」と差し込む常時ON連携が肝。Codex(hooks.json)・Cursor(rules)・Gemini CLIなど14ツールに対応
graphifyとは何か:Claude Code トークン削減を仕組みで実現するOSSスキル
graphifyは「任意のフォルダを問い合わせ可能な知識グラフに変える」AIコーディングアシスタント用スキルだ。Claude Codeであれば/graphifyスラッシュコマンドで起動し、対象ディレクトリのコード・SQLスキーマ・Rスクリプト・シェル・ドキュメント・論文・画像・動画から概念とリレーションを抽出する。出力は対話型HTML・JSON・人間が読めるGRAPH_REPORT.mdの3点セットで、後段のClaude/Codexはこのレポートを起点にナビゲーションするためトークン消費が劇的に減る。
| 観点 | 従来のClaude Code利用 | graphify導入後 |
|---|---|---|
| 質問への応答経路 | Glob → Grep → Read を連鎖 | GRAPH_REPORT.md → graph.json を参照 |
| 1問あたりのトークン | 数万〜数十万 | 公式実測で71.5倍少ない |
| クロスファイルの関係把握 | ファイルを順次読まないと不明 | グラフ上のedgeで即可視化 |
| 「なぜそう書いたか」 | コード内の散在コメント頼み | rationale_forノードとして集約 |
| 信頼度 | LLMの推測 | EXTRACTED / INFERRED / AMBIGUOUSのタグ付け |
| 永続性 | セッション毎に再grep | graph.jsonを再利用、SHA256キャッシュ |
公式READMEに掲載されている実測例「Karpathy repos + 5 papers + 4 images(52ファイル)」では71.5倍、「graphifyソース + Transformer論文(4ファイル)」では5.4倍のトークン圧縮を達成している。
検証環境: macOS 14.5 / Python 3.12 / Claude Code v2.x / 確認日 2026-05-02。
pip install graphifyyによるインストール可否、graphify claude installが~/.claude/CLAUDE.mdとsettings.jsonに書き込む内容まで確認。実際のトークン削減ベンチはREADME掲載値を参照。
graphifyのアーキテクチャ:3パスパイプラインの設計
graphifyは1回の実行で「決定論的AST抽出」→「動画/音声転写」→「LLMによる意味抽出」の3パスを走らせ、最後にLeidenクラスタリングでコミュニティを検出する。各パスの責務が分離されているため、コードのみ更新時はLLMコールゼロで再ビルドできる。
25言語のクラス・関数・import"] P1B["call-graph 抽出
クロスファイルの呼び出し関係"] P1C["docstring + 設計コメント
rationale_for ノード"] P1D["SQL DDL を解析
tables, views, FK"] end subgraph Pass2[Pass2 動画/音声転写] P2A["faster-whisper でローカル転写"] P2B["god ノード由来のドメインプロンプト"] P2C["transcripts キャッシュ"] end subgraph Pass3[Pass3 LLM 意味抽出] P3A["Claude サブエージェント並列実行"] P3B["概念・関係・design rationale"] P3C["EXTRACTED / INFERRED / AMBIGUOUS タグ"] end Merge["NetworkX グラフへマージ"] Cluster["Leiden コミュニティ検出"] Out["graph.html / graph.json / GRAPH_REPORT.md"] Input --> Pass1 --> Merge Input --> Pass2 --> Merge Input --> Pass3 --> Merge Merge --> Cluster --> Out style Pass1 fill:#d4edda style Pass2 fill:#fff3cd style Pass3 fill:#cce5ff style Out fill:#f8d7da
Pass 1: tree-sitterによるAST抽出
.py .ts .js .go .rs .java .c .cpp .rb .cs .kt .scala .php .swift .lua .zig .ps1 .ex .m .jl .vue .svelte .sql など25言語に対応。LLMコールゼロで実行され、クラス・関数・import・呼び出し関係・docstring・設計コメント(# NOTE:, # IMPORTANT:, # HACK:, # WHY:)を抽出する。SQLは別途pip install graphifyy[sql]で有効化する。
Pass 2: Whisperによる動画/音声転写
.mp4 .mov .mkv .webm .mp3 .wav .m4a 等の動画/音声ファイル、およびYouTube等のURLは音声のみyt-dlpでダウンロードされ、faster-whisperでローカル転写される。「god ノード(最大次数の概念)」から派生したドメイン特化プロンプトを使うため、専門用語に強い。graphify-out/transcripts/にキャッシュされる。
Pass 3: Claudeによる意味抽出
ドキュメント・論文・画像・転写データに対して、Claudeサブエージェントが並列で概念とリレーションを抽出する。各エッジは以下のいずれかでタグ付けされる。
EXTRACTED: ソースに直接書かれていた(confidence 1.0)INFERRED: 妥当な推論(confidence 0.0–1.0付き)AMBIGUOUS: 要レビュー
「LLMが何を見つけたか/何を推測したか」が分離されているため、後段の検証で安全に扱える。
Pass後: Leidenクラスタリング
抽出結果はNetworkXグラフへ統合され、Leiden community detectionでコミュニティに分割される。重要なのは「embeddingベースのクラスタリングを使わない」点で、グラフ構造そのものをsimilarityシグナルとして使うため、Vector DBや埋め込みパイプラインが不要になっている。
インストール手順:3行で常時ON連携
graphifyはPython製。PyPIでの正式パッケージ名は graphifyy(yが2つ) で、pip install graphifyは別物なので注意。
pip install graphifyy
オプション機能はextrasで切り替える。
pip install 'graphifyy[mcp]' # MCPサーバ機能
pip install 'graphifyy[video]' # 動画/音声 (faster-whisper + yt-dlp)
pip install 'graphifyy[sql]' # SQL DDLパース
pip install 'graphifyy[office]' # docx/xlsx
Claude Codeへの常時ON連携
graphify claude install
これだけで以下が自動セットアップされる。
- プロジェクトの
CLAUDE.mdに「グラフがあればgraphify-out/GRAPH_REPORT.mdを先に読む」セクションを追記 .claude/settings.jsonにPreToolUseフックを登録 — Glob/Grep直前に「graphify: Knowledge graph exists. Read GRAPH_REPORT.md for god nodes and community structure before searching raw files.」というメッセージを差し込む- プロジェクト直下で
/graphify .を実行すればgraphify-out/が生成され、Claudeは以後その情報を優先する
設定後は、コードベースに対して質問するたびにClaudeがgrepではなくグラフを参照するようになり、結果としてClaude code トークン削減が常態化する。アンインストールはgraphify claude uninstallで行う。
他のAIコーディングツールとの連携
公式READMEは14のAIコーディングツールへのインストールを1コマンドでサポートする。
| ツール | コマンド | 仕組み |
|---|---|---|
| Claude Code | graphify claude install |
CLAUDE.md + PreToolUseフック |
| Codex | graphify codex install |
AGENTS.md + .codex/hooks.json PreToolUseフック |
| OpenCode | graphify opencode install |
AGENTS.md + .opencode/plugins/graphify.js |
| Cursor | graphify cursor install |
.cursor/rules/graphify.mdc (alwaysApply) |
| Gemini CLI | graphify gemini install |
GEMINI.md + BeforeToolフック |
| GitHub Copilot CLI | graphify copilot install |
~/.copilot/skills/graphify/ |
| VS Code Copilot Chat | graphify vscode install |
.github/copilot-instructions.md |
| Aider | graphify aider install |
AGENTS.md |
| Kiro IDE/CLI | graphify kiro install |
.kiro/steering/graphify.md (always inclusion) |
| Google Antigravity | graphify antigravity install |
.agents/rules + .agents/workflows |
| OpenClaw / Factory Droid / Trae / Trae CN / Hermes | 各 graphify <name> install |
主にAGENTS.md |
ツールごとに「常時ON」を実現する手段が異なる。フック対応のClaude Code・Codex・Gemini CLI・OpenCodeはグラフ参照を強制でき、Cursor・Kiro・AntigravityはruleのalwaysApply / inclusion: alwaysで同等の動きを再現している。
graphifyの基本コマンド:claude トークン節約に直結する操作
公式READMEに記載された主要コマンドを役割別に整理する。
グラフ構築
/graphify . # カレントディレクトリでグラフ構築
/graphify ./raw # 特定フォルダで構築
/graphify ./raw --mode deep # INFERREDエッジを攻めに抽出
/graphify ./raw --update # 変更ファイルのみ再抽出して既存グラフへマージ
/graphify ./raw --directed # 有向グラフ(source→target)
/graphify ./raw --cluster-only # 抽出済みグラフでクラスタリングだけ再実行
/graphify ./raw --no-viz # HTMLをスキップしてレポート+JSONのみ
/graphify ./raw --watch # ファイル変更を検知して自動再ビルド
/graphify ./raw --wiki # コミュニティ単位でWikipedia風MDを生成
/graphify ./raw --svg # graph.svg
/graphify ./raw --graphml # graph.graphml (Gephi/yEd向け)
/graphify ./raw --neo4j # Neo4j向けcypher.txt
/graphify ./raw --neo4j-push bolt://localhost:7687
/graphify ./raw --mcp # MCP stdioサーバ起動
グラフへのコンテンツ追加
論文・X投稿・動画URLを直接コーパスに加えることもできる。
/graphify add https://arxiv.org/abs/1706.03762 # 論文を取得し、グラフ更新
/graphify add https://x.com/karpathy/status/... # ツイート
/graphify add <video-url> --whisper-model medium # 動画→音声→転写→抽出
/graphify add https://... --author "Name" --contributor "Name" # メタ付与
グラフへの問い合わせ
/graphify query "what connects attention to the optimizer?"
/graphify query "show the auth flow" --dfs # 特定パスをDFSで追跡
/graphify query "..." --budget 1500 # トークン上限を指定
/graphify path "DigestAuth" "Response" # 最短パス
/graphify explain "SwinTransformer" # ノードの平易な説明
--budgetを併用すれば「この質問は1500トークン以内で答えて」という制約をグラフ側で強制できる。Claude/Codex経由でなくても、ターミナルから直接グラフに質問できる点も特徴的だ。
Git連携と自動更新
graphify hook install # post-commit + post-checkoutでグラフ自動再ビルド
graphify hook status
graphify hook uninstall
graphify watch ./src # 変更検知→自動再ビルド
graphify check-update ./src # cron-safeなチェック(ペンディング有無)
graphify update ./src # コードのみ再抽出(LLMコール無し)
graphify cluster-only ./my-project # クラスタリングだけ再実行
クロスリポ統合
graphify clone https://github.com/karpathy/nanoGPT
graphify merge-graphs repo1/graphify-out/graph.json repo2/graphify-out/graph.json --out cross-repo.json
クロスリポでgraphをマージできるため、「マイクロサービス全体を1つの知識グラフで横断する」ような使い方が可能になる。
常時ON連携の中核:PreToolUseフックの仕組み
graphifyが他のRAG系ツールと根本的に違うのは、Claude/Codex/Gemini CLIなどの「ツール呼び出し直前」に介入する点だ。Claude Codeの場合、.claude/settings.jsonに登録されるPreToolUseフックが以下のように動く。
1問あたりトークン消費を圧縮
ポイントは「Claudeに指示するのを忘れても自動で介入する」こと。CLAUDE.mdに書いただけでは指示が無視されるケースもあるが、PreToolUseフックはツール呼び出しを物理的に止めて差し込むため、ガードとして機能する。Codexでは同じ思想が.codex/hooks.jsonで実装されており、OpenCodeではtool.execute.beforeプラグインが同等の動きをする。
CursorとKiroはruleのalwaysApply/inclusion: alwaysを使っており、フックは無いがすべての会話に自動でルールが含まれるため挙動は近い。
トークン削減のメカニズム:なぜ71.5倍なのか
「コードを直接読む」に対して「グラフ要約を読む」が情報密度で勝るケースが多いからだ。READMEから読み取れる本質は次の3点。
1. SHA256キャッシュで再抽出を最小化
graphify-out/cache/にSHA256ベースのキャッシュが置かれ、変更ファイルだけが再処理される。コード変更時はAST抽出のみ走り、LLMコールはゼロ。「1度作ったグラフを使い回す」運用で、初回投資以降のトークン消費が激減する。
2. graph.jsonをそのまま読ませない設計
公式READMEは「graph.jsonをプロンプトに丸ごと貼ってはいけない」と明記している。代わりに/graphify queryが必要なサブグラフだけを切り出して渡す。
graphify query "show the auth flow" --graph graphify-out/graph.json
graphify query "what connects DigestAuth to Response?" --graph graphify-out/graph.json
出力にはノードラベル・エッジ種別・confidenceタグ・ソースファイル位置が含まれており、LLMにとってちょうど良いサイズの中間コンテキストになる。
3. MCPサーバとして直接アクセス
pip install 'graphifyy[mcp]' してMCPサーバを立てると、ClaudeやCodexからquery_graph / get_node / get_neighbors / shortest_path といった呼び出しがツールとして使える。プロンプトで毎回コンテキストを渡すよりも更にトークン効率が良い。
python -m graphify.serve graphify-out/graph.json
.mcp.jsonへの登録例:
{
"mcpServers": {
"graphify": {
"type": "stdio",
"command": ".venv/bin/python3",
"args": ["-m", "graphify.serve", "graphify-out/graph.json"]
}
}
}
WSL/Linuxの場合、PEP 668対策で必ずvenvに入れること(公式READMEの注意書きに従う)。
既存のClaude Code トークン削減ツールとの比較
ai-archive-jpでは過去にClaude Codeのトークン最適化系ツールを複数取り上げてきた。代表的な3手法と並べると、graphifyの位置付けが見えてくる。
| ツール / 手法 | アプローチ | 主な削減源 | 適合する質問 | 留意点 |
|---|---|---|---|---|
| graphify(本記事) | 知識グラフ事前生成+PreToolUseフック | grep連鎖の回避 | 構造・関係性・「なぜ」 | 初回構築コストあり |
| Claude Codeのトークン最適化ツール比較 で扱う各種CLI | プロンプト圧縮、ファイル分割 | プロンプト直接圧縮 | 単発質問 | 実行時のオーバーヘッド |
| caveman-claude(トークン圧縮) | ハーネス側でのプロンプト圧縮 | プロンプト本文の圧縮 | 長文プロンプト | 圧縮による情報損失 |
| AIエージェントのトークン最適化2026 で網羅される手法 | 包括的(キャッシュ、ストリーミング、context window管理) | 多面的 | 全般 | 個別実装コスト |
graphifyは「事前にグラフを作って永続化する」点が他と違う。プロンプト圧縮系は1回の質問に対してコストを払う一方、graphifyは1回だけグラフを作っておけばその後すべての質問が高速化する。長期メンテのプロジェクトに圧倒的に向いた設計だ。
出力アーティファクトの中身
/graphify .を実行するとgraphify-out/が作られる。READMEから読み取れる主な中身は以下のとおり。
| ファイル | 中身 | 用途 |
|---|---|---|
graph.html |
対話型グラフ。ブラウザで開いてノードクリック・検索・コミュニティフィルタ | 人間が見る |
GRAPH_REPORT.md |
god ノード・surprising connections・suggested questions | LLMが先に読む |
graph.json |
NetworkX互換の永続グラフ | クエリ・MCP・他ツール連携 |
cache/ |
SHA256キャッシュ | 増分ビルド |
transcripts/ |
Whisper転写結果 | 動画/音声の再利用 |
manifest.json |
mtimeベースのファイル履歴(git cloneで無効) | gitignoreすべき |
cost.json |
ローカルなトークン消費トラッキング | gitignoreすべき |
公式READMEはgraphify-out/をgit commitすることを推奨している。チーム全員が同じグラフを共有でき、誰かが/graphify --updateを走らせるたびに最新状態に保てる。graphify hook installで自動再ビルドも可能だ。
抽出される高次概念
graphifyは単なるコード構造の可視化を超えた要素を抽出する。
- god nodes: 最大次数の概念(最も多くのものが繋がるハブ)
- surprising connections: コード–論文エッジが上位に来るランキング、各結果に英語の理由付き
- suggested questions: そのグラフが特に答えやすい4–5の質問
- rationale_for ノード: docstringや
# NOTE:# WHY:等の「なぜそう書いたか」 - semantic similarity edges: 構造的接続のないクロスファイル概念リンク
- hyperedges: 3+ノードの集団関係(プロトコルを実装する全クラス、認証フローの全関数 等)
.graphifyignoreによるディレクトリ制御
.gitignoreと同じ構文で、グラフ抽出から除外するパスを定義できる。
# .graphifyignore example
vendor/
node_modules/
dist/
*.generated.py
docs/translations/ # 翻訳ファイルなどグラフに含めたくない
AGENTS.md # graphify自身の指示ファイル(再帰防止)
CLAUDE.md
GEMINI.md
!によるネガティブパターン(再包含)も使える。.git等のVCS境界を越えないため、複数プロジェクトを並列で管理しても干渉しない。
graphifyの注意点と限界
公式READMEや実装の挙動から、利用前に押さえておくべき注意点がある。
- 初回の
/graphify .はLLMコールを伴うためトークンを消費する。「初回投資 → その後の節約」の構造を理解した上で使うこと - PyPIパッケージ名は
graphifyy(y2つ)。pip install graphifyは別物 graphify-out/manifest.jsonはmtimeベースなのでgit cloneで無効化される。gitignoreすべきcost.jsonはローカルの個人トラッキング。共有しない方がよい/graphify add <video-url>はyt-dlp経由のため、権利のあるコンテンツのみに使う(ToSと著作権を尊重)- WSL/Linuxは
python3とPEP 668により、必ずvenvで使うこと - Cursor/Kiro/Antigravityはruleベースのため、フック対応ツール(Claude Code/Codex/Gemini CLI/OpenCode)よりは「強制力」が弱い
- EXTRACTED/INFERRED/AMBIGUOUSの区別は重要。INFERREDのconfidenceスコアを見ずに鵜呑みにしないこと
実践フロー:claude トークン節約を恒常化する手順
# 1. インストール
pip install 'graphifyy[mcp,video,sql]'
# 2. Claude Code連携
graphify claude install
# 3. 初回グラフ構築
cd ~/your-project
/graphify .
# 4. Git hookで自動再ビルド
graphify hook install
# 5. 質問
# Claude Code内で普通に質問するだけ。
# PreToolUseフックがグラフ参照を強制してくれる。
# 6. 詳細クエリが必要なとき
graphify query "show the auth flow"
graphify path "User" "JwtService"
graphify explain "OrderRepository"
5ステップで常時OFFのトークン浪費を常時ONの節約モードに切り替えられる。5ステップ目以降のClaudeとの対話で発生するトークン量が最大の節約源だと理解しておきたい。
チームで使う:graphify-outを共有する設計
公式READMEは「graphify-out/をgit commitしてチームで共有する」運用を推奨する。
- 1人が
/graphify .を実行しgraphify-out/をコミット - 残りのチーム員はpullするだけで
GRAPH_REPORT.mdをAIアシスタントが即読み込み graphify hook installでpost-commit/post-checkoutに自動再ビルドを仕込む- ドキュメント変更時のみ
/graphify --updateで意味抽出を再実行
.gitignoreに追加すべき項目:
# 共有を強制したい / 大きすぎるので除外
# graphify-out/cache/ # 抽出速度を共有したい場合はコミットも可
graphify-out/manifest.json # mtimeベース。clone後に無効
graphify-out/cost.json # 個人別のトークン消費トラッキング
FAQ
Q1. Claude Code以外でも本当に効果がある?
ある。Codex / Gemini CLI / OpenCodeはClaude Codeと同じ「PreToolUseフック」相当の機構を持つため、grep直前にグラフ参照を強制できる。Cursor / Kiro / Antigravityはruleベースで「常に含める」ため、フック対応版より少し強制力は弱いがユースケース次第で十分実用になる。
Q2. 無料で使える?トークン代は?
graphify自体はOSS(Apache-2.0)。ただし初回構築時にClaudeサブエージェントを並列で動かすため、LLM API代は発生する。コードのみ更新時はAST抽出のみで再ビルド可能なので、ほとんどのケースでLLMコール無しで済む。コスト管理はSHA256キャッシュとgit hookに任せるのが鉄則。
Q3. embedding/vector DBは要らない?
要らない。READMEは「Clustering is graph-topology-based — no embeddings」と明記している。Claudeが抽出した意味類似エッジ(semantically_similar_to、INFERREDタグ)は既にグラフに入っており、Leidenがそれを使ってコミュニティを切る。Pinecone/Weaviate/Chromaのようなvector DBは不要。
Q4. プライベートコードを送りたくない
graphify自体はローカル実行だが、Pass 3でClaudeサブエージェントを呼ぶためAnthropic APIにコードが送られる。社内秘コードに使うときはAnthropicのData Usage Policyを確認し、必要に応じてエンタープライズ契約で扱う。動画/音声の転写は完全ローカルなので、転写部分だけは外部送信されない。
Q5. Neo4j連携は何ができる?
--neo4jフラグでcypher.txtを生成、--neo4j-push bolt://localhost:7687で起動中Neo4jに直接プッシュできる。Neo4j Browserのvisualizationやcypher検索を使い慣れているチームには嬉しい統合。Gephi/yEd派は--graphmlで対応する。
Q6. graph.jsonをLLMに直接貼っていい?
公式READMEは直接貼るなと書いている。代わりにgraphify queryで必要なサブグラフだけを切り出して渡すか、MCPサーバ経由でツールコール化する。直貼りはgraph.jsonが大きい場合に逆にトークンを浪費する。
Q7. ライセンスは?商用OK?
Apache License 2.0 だ(2026-08-01時点。GitHubのライセンスAPIとリポジトリ直下の LICENSE 本文で確認)。商用利用も可能だが、MITと違ってApache-2.0は特許グラントの明示と、配布時のNOTICE/変更点の告知という条件が付く。自社プロダクトに同梱して再配布する場合は、MIT前提の社内チェックリストのままだと条件を落とす可能性がある点に注意したい。なお関連書籍「The Memory Layer」やGitHub Sponsors、公式サイト graphify.com といった商用展開もあるため、エンタープライズ用途では公式に問い合わせるのがベター。
Q8. 25言語対応とあるが、どの言語が完全にカバーされる?
tree-sitter ASTで構造抽出されるのが25言語、call-graphクロスファイル抽出が全言語、Javaextends/implementsは専用処理あり。SQLはAST抽出(graphifyy[sql])、YAMLは意味抽出のみ。マイナー言語の場合はASTが取れない可能性があるため、READMEの最新表で確認すること。
Q9. SQLスキーマも本当にグラフに入る?
入る。graphify-outのgraph.jsonにはテーブル・ビュー・関数・外部キーがノードとして、FROM/JOIN関係がエッジとして含まれる。LLMコール無しの決定論的抽出なので、スキーマ起点で「このテーブルがどこから参照されているか」を一発で特定できる。データベーススキーマ + アプリコード + インフラ定義を1グラフにまとめられる点はgraphify公式が大きな差別化ポイントとして打ち出している部分。
Q10. 動画・画像・PDFも本当に効くのか?
PDFは引用と概念抽出、画像はClaude visionによる解析(スクリーンショット・図・他言語テキスト含む)、動画・音声はfaster-whisperでローカル転写してClaudeに渡す。社内Wikiの図やWhiteboard写真、設計レビュー動画などをまとめて1グラフ化する用途が想定されている。pip install 'graphifyy[video]'を入れれば動画パイプラインが有効になる。
Q11. graphifyは既存のRAGと何が違う?
一般的なRAGはembedding + vector DBで類似度検索を行うが、graphifyはtopology-basedクラスタリング + 明示的エッジでナビゲーションする。「コードベースを意味で検索する」用途ではvector DBに分があるが、「構造と関係を辿って答える」用途ではグラフが圧倒的に効く。Claude Codeの主用途(リファクタリング・設計理解・影響範囲調査)ではgraphifyのアプローチが向いている。
ベンチマーク71.5倍の内訳を読み解く
公式READMEに掲載された「Karpathy repos + 5 papers + 4 images(52ファイル)」の71.5倍という数字は、単に「grepしなくなる」だけでは出ない。実際には次の3要素が積み重なっている。
- god ノードによる入口最適化 — GRAPH_REPORT.mdは最大10個程度の god ノードに絞ってサマリされており、ここから関連コミュニティに飛ぶことで「全ファイルなめる」が回避される
- rationale_for ノードの集約 —
# WHY:# IMPORTANT:等のコメントから抜き出された設計理由がノードとして1箇所に集まっているため、「なぜ」を聞かれた瞬間にコード本体を読む必要がない - AMBIGUOUS / INFERREDタグによる信頼性カット — confidence < 0.5のエッジを自動で除外できるため、無駄な確認のためのRead呼び出しが減る
逆に「graphifyを使ってもトークンが減らないケース」も明確だ。
| ケース | 削減効果 | 理由 |
|---|---|---|
| 単一ファイル内の細かいバグ調査 | 小さい | グラフより直接読む方が速い |
| 全文grepが本質的に必要な質問(特定文字列の出現箇所) | 小さい | グラフは構造抽出なので生テキスト検索の代替にはならない |
| グラフ構築直後の同セッション質問 | 中程度 | グラフ構築でトークンを消費した直後 |
| 長期メンテのコードベースに対する設計質問 | 大きい | god ノード + rationale_for が刺さる |
graphifyの初回コストの考え方
「初回投資」のトークンコストは以下のように計算できる。
初回構築コスト ≒ コーパス中のファイル数 × 平均トークン × Claudeサブエージェントの抽出効率
≒ 30〜数百ドル相当(中規模コードベースの場合の概算)
これに対して節約効果は「今後の全質問の合計」で計算するため、3〜5回の質問でペイすることが多い。graphify hook installでgit hookを仕込めば、その後はコード変更時に自動で増分再ビルドされ、LLMコール無しでASTのみ更新されるため、追加コストはほぼ発生しない。
# 初回投資
/graphify . # ← LLMコールあり
# 以降の運用(LLMコールほぼ無し)
graphify hook install # コミット毎に自動再ビルド
graphify update ./src # コードのみ再抽出
graphify cluster-only ./src # クラスタリングだけ更新
長期的に見るとClaude Code トークン削減効果はプロジェクトが長く続くほど指数的に増える。逆に短命のスクラッチプロジェクトには向かない。
リポジトリ移管とプロジェクトの現在地
本記事の初出は2026年5月で、当時graphifyは個人アカウント safishamsi の下にあるOSSだった。2026年8月1日時点の実測では、プロジェクトの体制そのものが変わっている。
・リポジトリが組織アカウントへ移管された。https://github.com/safishamsi/graphify へアクセスすると https://github.com/Graphify-Labs/graphify へリダイレクトされる(curl -sIL で最終URLを確認)。旧URLのリンクとcloneは引き続き機能する
・既定ブランチが v6 から v8 に変わっている。READMEをブランチ名込みで直リンクしていた場合、/blob/v6/... は残っているものの最新版を指さない
・GitHub API実測で★99,701・fork 9,661・open issue 732。リポジトリ作成は2026年4月3日、最終コミットは2026年7月30日
・PyPIの graphifyy は 0.9.31(2026-07-30公開)で、公開済みリリースは通算199本。作成から約4か月で199リリースという計算になる
・READMEにはY Combinator S26のバッジと公式サイト graphify.com が並び、個人プロジェクトから「Graphify Labs」という会社のプロダクトへ移行している
①READMEやドキュメントをブランチ名込みで直リンクしている場合は `v8` へ貼り替える(`v6` は消えていないが、記載内容が最新版と一致しない)
②リリース頻度がきわめて高いため、CIやチーム共有の環境ではバージョンを固定しないと、日をまたいだだけで挙動が変わりうる
③ライセンスはApache-2.0であってMITではない。個人OSSからYC企業のプロダクトになった以上、将来のライセンス・課金方針の変更は起こりうると考えて、社内採用の際は固定バージョンとライセンス条文を控えておきたい
git remote を旧URLのままにしていても現状は動くが、移管を明示的に反映しておくほうが後の混乱が少ない。
# 現在のリモートURLを確認する
git remote -v
# 新しい組織アカウントのURLへ更新する
git remote set-url origin https://github.com/Graphify-Labs/graphify.git
# インストール済み graphifyy のバージョンを固定する
pip install "graphifyy==0.9.31"
まとめ:「grepではなくグラフを読ませる」発想の勝利
graphifyは「Claude Code等のAIアシスタントにコード本体を読ませない」という逆転の発想で、結果的に最大71.5倍のClaude code トークン削減を実現するOSSスキルだ。tree-sitter AST + Whisper + Leidenクラスタリングという成熟したコンポーネントを組み合わせ、PreToolUseフックという常時ON連携で「忘れても効く」設計に仕上げている点が秀逸。
Claude Codeを毎日使うエンジニアにとって、pip install graphifyy && graphify claude install && /graphify . の3ステップは導入障壁が低く、初回構築のLLMコスト以降は指数的にトークンが節約される。長期メンテのコードベースほど効果が大きい。
関連記事として、Claude Codeのトークン最適化ツール比較、AIエージェントのトークン最適化2026、caveman-claude(トークン圧縮) も併せて確認してほしい。プロンプト圧縮系・キャッシュ系・グラフ系の3つを使い分ける視点が定着すれば、Claude Code利用コストはチームスケールで顕著に下がる。
最後に、graphifyを「単なるトークン削減ツール」と捉えるのは矮小だ。これはコードベースを事前に理解可能な構造へ整形しておくメタ作業を、AIアシスタントが効率よく扱えるフォーマットで形式化したスキルでもある。Andrej Karpathyが/rawフォルダで論文・X投稿・スクリーンショット・ノートをまとめている話を引き合いに、READMEは「graphifyはあの問題への答え」と位置付けている。今後Claudeのコンテキスト長が増えても、構造化された知識グラフが提供する信号対雑音比の改善は色褪せない。