「NotebookLMは便利だけど、取り込んだ社内資料や研究データがGoogleのクラウドに乗るのが気になる」「モデルはGoogle固定で、APIも無いから自分のワークフローに組み込めない」——AIノートツールをまじめに使い込むほど、この壁にぶつかります。Open Notebook(オープンノートブック)は、まさにこの不満のために生まれた、Google NotebookLMのオープンソース代替です。GitHubの説明はそのものずばり「より柔軟で機能が多いNotebook LMのオープンソース実装」。MITライセンスで、約34,250スター(2026年7月時点)を集めています。
この記事を読むと、①Open Notebookで結局何ができるのか(PDFや動画を取り込んでRAGチャットし、複数話者のポッドキャストまで自動生成する)、②どんな課題を解決するのか(クラウド専用・モデル固定・API無しというNotebookLMの制約)、③何を代替できるのか(プライバシーと拡張性を重視するならNotebookLMそのものの置き換えになりうる)が分かります。そもそもRAG(検索拡張生成)という仕組み自体を先に整理したい方は、RAG実装完全ガイド2026を合わせて読むと、Open Notebookが内部で何をしているのかが立体的に掴めます。
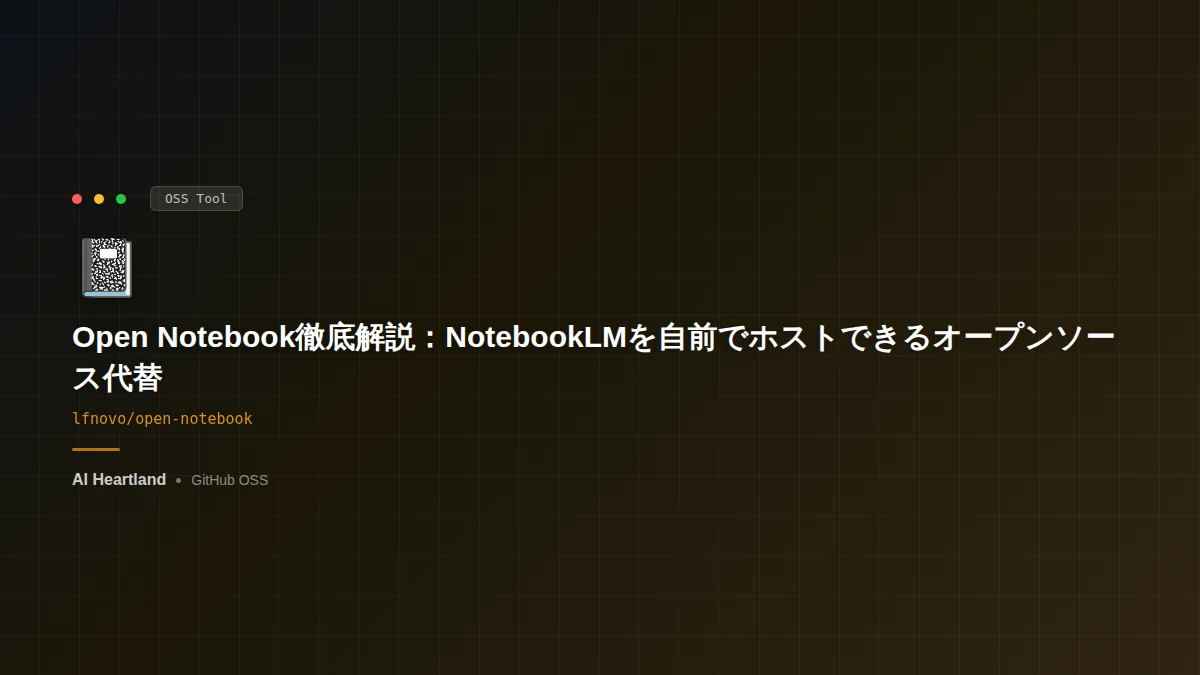
- ・Open NotebookはGoogle NotebookLMをセルフホストで再現するMITライセンスのオープンソース代替。
- ・最大の特徴は「データが手元に残る」ことと、18以上のAIプロバイダを機能ごとに割り当てられる自由度。
- ・PDF・動画・音声・Webページ・Office文書を取り込み、RAGチャットと1〜4話者のポッドキャストを生成できる。
- ・REST APIを備え、取り込みからチャット、ポッドキャスト生成まで外部から自動化できる。
- ・すぐ使える手軽さはNotebookLMに劣る(Docker・設定の知識が前提)。最新版の利用を推奨。
1. Open Notebookとは:NotebookLMをセルフホストで再現するオープンソース代替
Open Notebookは、Google NotebookLMのようなAIノート体験を、自分のサーバーの中で丸ごと動かせるオープンソースソフトウェアです。作者はlfnovo氏、ライセンスはMIT。公式の位置づけは「プライバシーファーストでセルフホスト可能なNotebookLMの代替」であり、GitHubの一文は「より柔軟で機能が多いNotebook LMのオープンソース実装」となっています。
ここで言う「NotebookLM体験」とは、ざっくり資料を取り込む → その資料に根ざしてAIと対話する → 要約や音声番組(ポッドキャスト)を作るという一連の流れのことです。NotebookLMを使ったことがある人なら、あの「自分の資料だけを根拠に答えてくれる安心感」を思い出せば早いでしょう。Open Notebookはその体験を、クラウドではなく自分の管理下で再現します。
Open Notebookが立っている場所を整理すると、次の3つの性質を1つに束ねた点が新しいと言えます。
・プライバシーファースト:セルフホストなので、取り込んだ資料や生成物が手元のインフラから外に出ない
・プロバイダ非依存:特定のAI企業に縛られず、機能ごとに好きなプロバイダを選べる
・自動化可能:REST APIを備え、取り込みやチャット、ポッドキャスト生成をプログラムから呼べる
NotebookLMは非常によくできたツールですが、その裏返しとして「Googleのクラウドで、Googleのモデルで、Googleの決めた範囲で使う」という前提があります。研究データや社内文書、契約書のような外に出したくない資料を扱う場面では、この前提そのものが採用のハードルになります。Open Notebookが新しいのは、同等の体験を保ちながら「どこで動かすか」「どのモデルを使うか」「どう自動化するか」の主導権を利用者に返した点にあります。「便利なクラウドサービスを使う」というより「自分専用のNotebookLMを建てる」感覚に近いと言えます。
- ・NotebookLM=手軽だがクラウド固定の完成品サービス。Open Notebook=自分で建てる、開けたNotebookLM。
- ・「資料を手元に置いたまま、AIと対話し音声番組まで作れる」のがOpen Notebookの核心。
2. なぜ必要か:クラウド専用・モデル固定・API無しというNotebookLMの制約を解決する
Open Notebookが解決するのは、NotebookLMが構造的に持っている3つの制約です。これらはNotebookLMの欠点というより、「クラウドの完成品サービス」であることの必然的な副作用です。
具体的な制約はこうです。
・クラウド専用:資料はGoogleのクラウドに保存される。手元に閉じた環境で完結させられない
・モデル固定:使えるのはGoogleのモデルだけ。用途に応じて別のLLMや音声モデルを選べない
・API無し:外部のワークフローやスクリプトから呼び出せず、既存の業務フローに組み込めない
・カスタマイズ不可:要約の仕方やチャットの挙動を自分好みに細かく変えられない
Open Notebookはこの一つひとつを、設計思想のレベルでひっくり返します。クラウド専用に対してはセルフホストで応え、データを自分のインフラに留めます。モデル固定に対しては18以上のプロバイダから機能ごとに選べるようにし、たとえば「対話はAnthropic、埋め込みはOpenAI、音声合成はElevenLabs」といった組み合わせを可能にします。API無しに対してはフルREST APIを提供し、取り込みからチャット、ポッドキャスト生成までをプログラムから叩けるようにします。
- ・Open Notebookは「NotebookLMの上位互換」ではなく「主導権を取り戻す代替」。手軽さはNotebookLMに軍配が上がる。
- ・セルフホストゆえに、Dockerや設定、プロバイダのAPIキー管理といった運用コストは自分持ちになる。
この制約が効いてくるのは、扱う情報の機微度が上がるほど、あるいは業務への組み込み度が上がるほどです。個人が公開情報を軽く要約するだけなら、NotebookLMの手軽さがそのまま強みになります。しかし社外秘の資料を扱う、特定の高性能モデルや日本語に強いモデルを使いたい、既存のパイプラインに自動で流し込みたい——こうした要件が一つでも入った瞬間に、NotebookLMの3つの制約が壁として立ち上がります。つまり要件が”業務的”になるほど、Open Notebookの自由度の価値が上がるという関係にあります。逆に言えば、そういう要件が無ければ無理にセルフホストする必要はなく、NotebookLMで十分だということでもあります。
Open Notebookのデータの流れと機能の関係を整理すると、次のようになります。ノートブックの中に複数のソースがぶら下がり、それらを根拠にチャット・変換・ノート・ポッドキャストが生まれる構造です。
ノートブック"] --> S["Sources
取り込んだ資料"] N --> Nt["Notes
ノート/メモ"] S --> C["Chat
RAGで根拠付き回答"] S --> T["Transformations
要約/インサイト"] S --> P["Podcast
音声番組を生成"] T --> Nt C --> Nt
この図の中心にあるのがソース(Sources)です。取り込んだ資料が根拠となり、そこから根拠付きのチャット回答、要約やインサイトの変換、そして音声番組が派生していきます。NotebookLMを使ったことがあれば違和感なく理解できるはずで、Open Notebookはこのメンタルモデルをそのまま自分の環境に持ち込めるように作られています。
3. Open Notebookの主な機能:18以上のAIプロバイダ・ソース取り込み・RAGチャット
Open Notebookの機能は多岐にわたりますが、「NotebookLM体験をセルフホストで成立させるための最小十分」に整理できます。主要機能を見ていきましょう。
機能ごとに選べる18以上のAIプロバイダ:Open Notebook最大の差別化です。LLM・埋め込み・音声認識(STT)・音声合成(TTS)という機能ごとに、別々のプロバイダを割り当てられます。「対話は賢いモデル、埋め込みは安いモデル、音声は自然なモデル」といったコスト最適化ができます。
あらゆるソースの取り込み:PDF・動画・音声・Webページ・Office文書など、幅広い形式を取り込めます。NotebookLMと同様に、雑多な資料を1つのノートブックに集約できます。
プロ仕様の複数話者ポッドキャスト生成:ここがOSSとしては際立つ機能です。エピソードプロファイルを定義し、1〜4人の話者を設定できます。話者ごとに声・性格・話す長さを指定でき、イントロ/アウトロまで作り込めます。NotebookLMの「2人の固定話者」に対し、構成の自由度が高いのが特徴です。
全文検索+ベクトル(意味)検索:キーワード一致の全文検索と、意味の近さで探すベクトル検索の両方を備えます。これはDBにSurrealDB v2を採用し、両方を1つの基盤で扱えるからこそ実現しています。
引用付きの文脈認識AIチャット:取り込んだソースに根ざして回答し、どのソースを根拠にしたか引用を返すチャットです。RAGの肝である「根拠が辿れる」性質を備えています。
思考モデル(thinking models)対応:DeepSeek-R1やQwen3といった、推論過程を持つモデルにも対応しているとされます。難しい問いに対して腰を据えて考えさせたい場面で効きます。
カスタム変換(transformations):要約やインサイト抽出を自分好みに定義できます。「この観点で要約する」「この形式で論点を抽出する」といった処理を、テンプレートとして持てます。
フルREST API・任意のパスワード保護・多言語UI:外部から全機能を呼べるREST API、簡易なパスワード保護、そして日本語を含む多言語UIを備えます。
この中でも、日々効いてくるのはプロバイダを機能ごとに割り当てられる設計です。たとえば日本語の資料を扱うなら日本語に強いLLMを対話に、埋め込みは多言語対応の安価なモデルに、音声合成は自然さで評判のプロバイダに——というように、1つの機能のためにすべてを妥協する必要がありません。NotebookLMのようなクラウド完成品では絶対にできない、セルフホストならではの調整幅です。
- ・「機能ごとに最適なプロバイダを選ぶ」ことで、精度・コスト・日本語対応をそれぞれ最適化できる。
- ・引用付きチャットとベクトル検索で、"それっぽい嘘"ではなく"根拠の辿れる回答"に寄せられる。
なお、NotebookLMをPythonのコードから再現するアプローチに興味がある方は、NotebookLMをPythonで再現するnotebooklm.pyも参考になります。Open Notebookが「動かせる完成システム」なのに対し、そちらは「仕組みをコードで理解する」入口として位置づけられます。
4. Open Notebookのインストールと基本操作:Dockerで15分
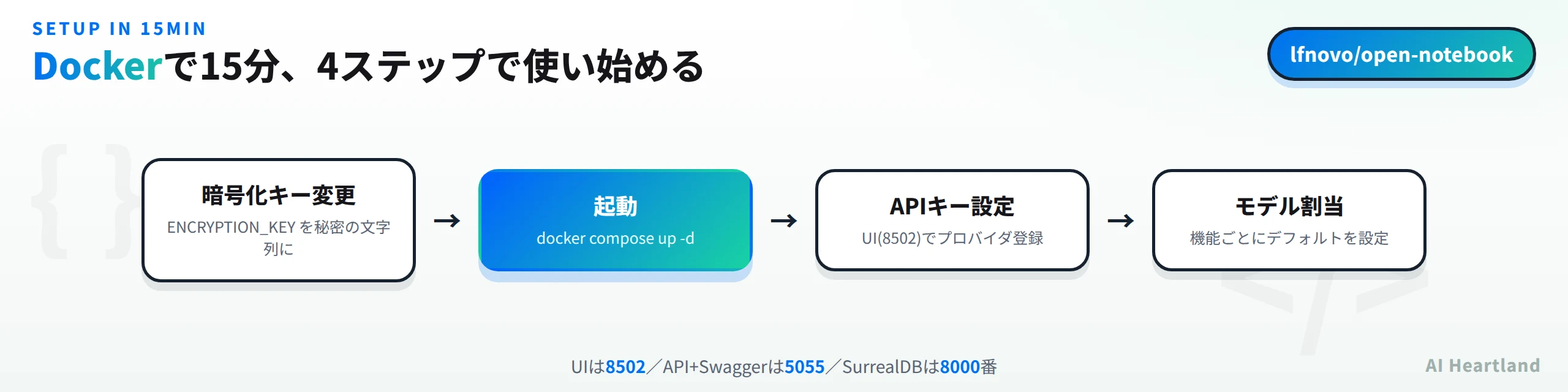
導入はDockerが基本です。公式のdocker-compose.ymlを取得して起動するだけで、最小構成が立ち上がります。まずは取得と起動から。
# 公式の docker-compose.yml を取得
curl -o docker-compose.yml https://raw.githubusercontent.com/lfnovo/open-notebook/main/docker-compose.yml
# バックグラウンドで起動
docker compose up -d
起動後、各サービスには次のポートでアクセスします。UIは8502番、REST API(Swagger付き)は5055番、DBのSurrealDBは8000番です。
・UI(Web画面):http://localhost:8502
・API+Swaggerドキュメント:http://localhost:5055/docs
・SurrealDB:ポート8000
起動前に必ず暗号化キーを変更しておきましょう。docker-compose.ymlの環境変数のうち、OPEN_NOTEBOOK_ENCRYPTION_KEY はプロバイダのAPIキーなどを暗号化するための鍵で、デフォルトのままにしてはいけません。主要な環境変数は次のとおりです。
OPEN_NOTEBOOK_ENCRYPTION_KEY=change-me-to-a-secret-string
SURREAL_URL=ws://surrealdb:8000/rpc
SURREAL_NAMESPACE=open_notebook
SURREAL_DATABASE=open_notebook
compose内のサービス構成もシンプルです。DBには surrealdb/surrealdb:v2 イメージ(ポート8000)、本体には lfnovo/open_notebook:v1-latest イメージ(ポート8502と5055)が使われます。おおまかなセットアップの流れはこうです。
・compose内の暗号化キーを自分の秘密の文字列に変更する
・docker compose up -d で起動する
・15〜20秒ほど待って各サービスが立ち上がるのを待つ
・UI(8502番)を開き、使いたいプロバイダのAPIキーを設定する
・モデルを同期し、各機能のデフォルトを割り当てる
ここまで済めば、あとはUIから資料を取り込んでチャットしたり、ポッドキャストを生成したりできます。「暗号化キーを変える → 起動 → APIキーを入れる → モデルを割り当てる」の4ステップが、Open Notebookを使い始める最短ルートです。
ローカルモデルで完全に閉じたい場合
「クラウドのAPIすら使わず、すべて手元で完結させたい」というニーズにも応えられます。Open NotebookはOllamaに対応しており、公式リポジトリの examples/docker-compose-ollama.yml を使うと、Ollama連携の構成例を参照できます。これを使えば、LLMも埋め込みもローカルのモデルで動かす構成が組めます。ただしローカルLLMはモデルサイズに応じてメモリやGPUを要求するため、マシンスペックには余裕が必要です。
- ・v1.8.3/1.8.4でRCE(リモートコード実行)・パストラバーサル・SurrealDBインジェクションの修正が入った。必ず最新版を使うこと。
- ・`OPEN_NOTEBOOK_ENCRYPTION_KEY` はデフォルトのまま公開しない。外部公開する場合は前段に認証を必ず置く。
セルフホストである以上、セキュリティは自分の責任範囲になります。特に過去に深刻な脆弱性の修正が入っている以上、古いバージョンを使い続けるのは危険です。導入時も運用中も、最新リリースへの追随を習慣にしてください。
5. Open Notebookのアーキテクチャ:FastAPI・Next.js・SurrealDB・Esperanto
Open Notebookの内部は、いくつかの技術を組み合わせて成り立っています。ここを押さえると、「なぜこれだけの機能が1つのセルフホストで成立するのか」が腑に落ちます。
・バックエンド:Python+FastAPI。REST APIやビジネスロジックを担う
・フロントエンド:Next.js+React。旧来のStreamlit(0.x系)から移行し、v1.x系はNext.js/React主体
・データベース:SurrealDB v2。全文検索とベクトル検索を1つのDBで扱える
・プロバイダ抽象化:Esperantoというレイヤーで、18以上のプロバイダを共通インターフェースで扱う
・エージェント/フロー:LangChainとLangGraphを活用
・ポッドキャスト生成:Podcastfy由来の仕組みをベースにしている
言語構成としてはTypeScriptが64.7%、Pythonが33.7%とされ、フロントエンド移行が進んだv1.x系の姿を反映しています。ここで正確に言うと、旧Streamlitからの移行は「100%完了」と断言するより、v1.x系はNext.js/React主体と理解するのが妥当です。
このアーキテクチャの中で、機能の”効きどころ”を握っているのがSurrealDB v2とEsperantoの2つです。SurrealDBは、全文検索(キーワード一致)とベクトル検索(意味の近さ)の両方を1つのDBでこなせるため、Open Notebookは検索基盤を二重に持たずに済みます。Esperantoは、バラバラなAIプロバイダのAPIを共通の入り口にまとめる抽象化レイヤーで、これがあるからこそ「機能ごとにプロバイダを差し替える」という柔軟性が現実的なコストで成立します。
全体の処理の流れを、資料取り込みからポッドキャスト生成まで俯瞰すると次のようになります。ソースが取り込まれてベクトル化され、チャットではRAGで根拠を引き、ポッドキャストではスクリプト生成を経てTTSで音声化される、という多段のパイプラインです。
PDF/動画/音声/Web"] --> Ing["取り込み処理
テキスト抽出/分割"] Ing --> Emb["埋め込み生成
SurrealDBに保存"] Emb --> Q{"何をする?"} Q -->|"質問する"| Rag["RAG検索
関連ソースを抽出"] Rag --> Ans["引用付きで回答
Chat"] Q -->|"番組化する"| Scr["スクリプト生成
話者ごとに配役"] Scr --> Tts["音声合成
TTSプロバイダ"] Tts --> Pod["ポッドキャスト完成"]
この図の左側(取り込み→埋め込み)はすべての機能の共通土台で、右側で「質問するのか、番組化するのか」に応じて処理が分岐します。質問側ではSurrealDBのベクトル検索が関連ソースを引き当て、その根拠に基づいて引用付きの回答が生成されます。番組化側では、ソースを元にスクリプトが作られ、設定した話者ごとに配役されてTTSプロバイダで音声化されます。同じソースから、根拠付きの対話も、耳で聞ける番組も生まれる——このパイプラインの二面性が、Open Notebookの価値の中心です。
6. Open NotebookとGoogle NotebookLMの比較・REST APIによる自動化

では、Open NotebookはNotebookLMとどう違うのか。よく比較される観点を表で整理します。
| 観点 | Open Notebook | Google NotebookLM |
|---|---|---|
| プライバシー | セルフホスト(データが手元に残る) | クラウド(Googleに保存) |
| AIプロバイダ | 18以上から機能ごとに選択 | Googleモデルのみ |
| ポッドキャスト話者数 | 1〜4人(構成を設定可能) | 2人(固定) |
| API | フルREST API | なし |
| デプロイ形態 | Docker/クラウド/ローカル | ホスト型のみ |
| コスト | AI利用分の従量(自分のキー) | サブスクリプション |
| ライセンス | MIT(オープンソース) | プロプライエタリ |
| 手軽さ | 設定・Dockerの知識が必要 | すぐ使える |
要するに、手軽さと完成度はNotebookLM、主導権と拡張性はOpen Notebookという住み分けです。データを外に出したくない、モデルを選びたい、業務フローに組み込みたい——このどれかに当てはまるなら、Open Notebookの価値が立ち上がります。
補足すると、Open NotebookはNotebookLMを”敵”とは見ていません。むしろメンタルモデル(ノートブック→ソース→ノート、そしてチャットとポッドキャスト)はNotebookLMを踏襲しており、NotebookLM利用者がすんなり移行できるよう作られています。「NotebookLMの使い勝手に慣れた人が、そのまま自分のインフラに引っ越せる」ことこそ、Open Notebookが代替として現実的な理由です。
そしてOpen Notebookがユニークなのは、フルREST APIによる自動化を備える点です。UIで手作業する代わりに、外部のスクリプトやワークフローから、ソースの取り込み・チャット・ポッドキャスト生成をプログラムで叩けます。APIとSwaggerドキュメントは5055番ポートに公開されており、まずは http://localhost:5055/docs を開いて、どんなエンドポイントがあるか眺めるのが理解の早道です。
この自動化が効くのは、たとえば次のようなパターンです。①定期取り込み——毎朝、決まったフォルダや社内のドキュメント群を自動でノートブックに取り込み、要約まで生成しておく。②パイプライン組み込み——既存の業務システムから資料をOpen Notebookに流し、生成した要約やインサイトを別のツールへ受け渡す。③一括ポッドキャスト化——複数の資料をまとめて音声番組化し、移動中に耳で消化する。いずれも、UIでポチポチする代わりに「Open Notebookを部品としてワークフローに埋め込む」発想です。NotebookLMにはAPIが無いため、こうした自動化は原理的にできません。ここが業務利用における決定的な差になります。
RAGを本格的な検索・ナレッジ基盤として組みたい場合は、RAGFlowのような専用のRAGエンジンと比較しておくと選択の幅が広がります。Open Notebookは「ノート+対話+音声」の統合体験に寄せた設計で、RAGFlowは検索・取り込み精度に振った設計、という違いを押さえると使い分けやすくなります。
- ・公開情報を手軽に要約したいだけ → NotebookLMで十分。
- ・社外秘資料・モデル選択・業務組み込みのどれかが必要 → Open Notebookが刺さる。
- ・検索・取り込み精度を極めたい → RAGFlowなど専用RAGエンジンも併せて検討。
7. Open Notebookの導入判断:向いている人・注意点(セルフホストの運用コスト)

最後に、導入すべきかの判断材料を整理します。
Open Notebookが向いている人
・研究データや社内文書など、外に出したくない資料をAIで扱いたい
・NotebookLMの体験は好きだが、モデルやプロバイダを自分で選びたい
・取り込みやポッドキャスト生成をAPIで自動化し、業務フローに組み込みたい
・日本語に強いモデルや特定の高性能モデルを対話に使いたい
・Dockerや設定の管理を自分でこなせる(またはこなす体制がある)
慎重に判断すべきケース
・とにかく手軽に使いたい(NotebookLMの即使える手軽さに軍配)
・Docker・サーバー運用の知識や体制が無い
・本格的なマルチユーザー/RBACが必須(現状は任意パスワードのみ)
いくつか具体的な注意点も押さえておきましょう。まずすぐ使える手軽さは無いという点。Open NotebookはDockerや設定の知識を前提とし、プラグアンドプレイではありません。次にローカル音声認識はデフォルトではないこと。音声のテキスト化(STT)はWhisperをプロバイダ経由で使うか、自前のOpenAI互換エンドポイントを立てる形になります。そしてポッドキャストの品質はTTSプロバイダ次第で、2話者ならNotebookLMに近い自然さを狙えるとされる一方、4話者はまだ粗くなりがちです。
- ・マルチユーザー/RBACは無い。任意パスワード1つのみなので、共有運用は前段の認証で補う。
- ・過去に深刻な脆弱性の修正あり。必ず最新リリースを使い、更新を継続する。
- ・MITで商用OKだが、取り込む資料の著作権は別問題。日本の大手メディア記事の取り込みは避ける。
スペックの目安も触れておきます。非公式な目安として、小規模なら4GBメモリ・2vCPU、重い使い方なら8GBメモリ・4vCPU程度とされます。ただしこれはあくまで参考値で、Ollamaでローカルモデルを動かすなら、モデルサイズに応じてさらにリソースが必要です。ライセンスはMITで商用利用も広く許されますが、それはOpen Notebook本体のコードの話であり、取り込んだPDFや記事の著作権はまったくの別問題です。特に当サイトの方針としても、日本の大手メディア記事のような権利が明確な資料を取り込むのは避けるべきです。ライセンスの緩さと、扱う中身の権利は切り分けて考えてください。
なお、最新版はv1.10.0(2026年6月18日リリース)で、チャット内のLaTeXレンダリング、チャット文脈の一括制御、トルコ語UIの追加などが入っています。開発は活発で、機能追加も改善も速いプロジェクトです。裏を返せば、細部の仕様が変わる可能性もあるということなので、バージョンを固定して運用し、更新は変更点を確認してから適用するのが安全です。
まとめ
Open Notebookは、「AIノートツールの主導権を、クラウドから利用者の手元へ取り戻す」という思想で作られた、NotebookLMのオープンソース代替です。NotebookLMのメンタルモデル(ノートブック→ソース→対話・音声番組)を受け継ぎながら、セルフホスト・プロバイダ選択・REST自動化という一点で明確に踏み込みました。
- ・Open NotebookはNotebookLMをセルフホストで再現するMITライセンスのオープンソース代替。
- ・データが手元に残り、18以上のAIプロバイダを機能ごとに選べ、REST APIで自動化できる。
- ・PDFや動画を取り込んでRAGチャットし、1〜4話者のポッドキャストまで生成できる。
- ・手軽さはNotebookLMに劣る(Docker・設定の知識が前提)。過去の脆弱性ゆえ最新版を使う。
- ・MITで商用OKだが、取り込むソースの著作権は別問題。日本の大手メディア記事の取り込みは避ける。
NotebookLMの便利さは認めつつ、「データを外に出したくない」「モデルを選びたい」「自動化したい」のどれかに心当たりがあるなら、まずは docker compose up -d で自分専用のNotebookLMを建ててみてください。仕組みそのものを深掘りしたい方はRAG実装完全ガイド2026を、コードでNotebookLMを再現するアプローチはNotebookLMをPythonで再現するnotebooklm.pyを、検索・取り込みに特化したRAG基盤はRAGFlowを、それぞれ合わせて読むと理解が立体化します。
参照ソース
・lfnovo/open-notebook (GitHub) — 公式リポジトリ。README・機能一覧・Docker構成・リリースノートの一次ソース。
・Open Notebook 公式サイト — 機能紹介・思想・ドキュメントの入口となる公式サイト。
・Open Notebook v1.10.0 リリースノート — 最新版の変更点(LaTeXレンダリング・一括文脈制御・トルコ語UI)の一次ソース。





