「静的スキャナを回すと警告が数百件出るが、そのほとんどが誤検知。かといって手動ペンテストは高コストで、リリースのたびには頼めない」——アプリのセキュリティ検査は、この2つの不満の板挟みでした。Strix(ストリックス)は、この構図を崩すために作られた、自律型AIエージェントによるオープンソースのペネトレーションテストツールです。公式のタグラインはずばり「アプリの脆弱性を発見して修正する、自律型AIハッカー」。GitHubで約28,800スター(2026年7月時点)を集め、AIセキュリティ領域で急速に存在感を増しています。
この記事を読むと、①Strixで何ができるのか(AIエージェントが実際に攻撃してPoCで脆弱性を裏付ける)、②どんな課題を解決するのか(手動ペンテストのコストと、従来スキャナの誤検知の山)、③何を代替できるのか(静的スキャナの補完・置き換えと、定型的なペンテスト工程の自動化)が分かります。なお、サプライチェーンを含む開発セキュリティ全体の考え方は、まずサプライチェーンセキュリティ完全ガイド2026で土台を掴んでおくと、Strixの位置づけが明確になります。

- ・Strixは自律AIエージェントがアプリを実際に攻撃し、動くPoCで脆弱性を裏付けるOSSペンテストツール。
- ・「PoCがなければ発見なし」の設計で、従来スキャナの誤検知を大幅に減らす。
- ・ローカルコード・GitHubリポジトリ・稼働中Webアプリを対象に、CI/CD(PR差分)へも組み込める。
- ・実行にはDockerと外部LLMのAPIキーが必要(スキャン規模に応じたAPI課金あり)。
- ・ライセンスはApache-2.0。ただし「許可した対象のみ」テストする法的責任は利用者にある。
1. Strixとは:脆弱性を自分で突いて実証する「自律型AIペンテスター」

Strixは、人間のペネトレーションテスターがやることを、AIエージェントに自律的に代行させるツールです。作者はusestrixで、実体の91%がPythonで書かれています。従来の「疑わしい箇所を列挙するスキャナ」とは根本的に発想が異なり、Strixのエージェントは実際にエクスプロイトコードを書き、隔離環境で実行し、成功したら動くPoC(概念実証)を添えて報告します。
READMEはこの狙いを明快に述べています。曰く、「手動ペンテストの負担も、従来スキャナの誤検知もなしに」脆弱性を見つけて直す、と。ここで鍵になるのが「PoCがなければ発見なし(No PoC, no finding)」という思想です。脆弱性を報告する前に、実際に悪用できることを自分で確かめる——だからこそ、上がってくる指摘の確度が高くなります。この「実証してから報告する」という順序は、地味に見えて運用を大きく変えます。従来は、スキャナが出した大量の候補を人間が一つずつ精査し、”本物か誤検知か”を判断する必要がありました。Strixはその判断の大部分を、PoCという動かぬ証拠に置き換えます。結果として、セキュリティ担当者の時間は「選別」ではなく「対処」に振り向けられます。
・攻撃を再現する:仮説を立てて終わりではなく、エクスプロイトを実行して裏を取る
・サンドボックスで安全に:攻撃コードは隔離されたDocker内で走らせる
・開発フローに乗る:ローカル・GitHub・本番相当のWebアプリ、いずれも対象にできる
- ・従来スキャナ=「怪しい場所のリスト」を出す。Strix=「実際に突けた脆弱性」を出す。
- ・報告に動くPoCが付くので、開発者は「本当に危ないやつ」から対処できる。
Strixが登場した背景には、AIエージェント技術の急速な成熟があります。コードを読んで理解し、仮説を立て、道具を使い、結果を見て次の手を決める——こうした自律的なループは、まさに攻撃者の思考と相性が良い領域です。実際、Strixは公開後まもなく2万8千を超えるスターを集め、AIセキュリティの新しい定番ツール群の一角として語られるようになりました。攻撃側の自動化が進むいま、防御側も同じ土俵で自動化しなければ間に合わない——Strixはその現実解のひとつです。
「自律型(autonomous)」という言葉も、Strixの文脈では具体的な意味を持ちます。人間が一手ずつ指示するのではなく、目的(脆弱性を見つける)とツール(プロキシやシェル)を与えれば、あとはエージェントが自分で計画し、実行し、結果を評価して次の手を選ぶ——この一連を人手なしで回せることを指します。対象の指定や重点箇所の指示といった”方向づけ”は人間が与えますが、実際の攻め方の細部はエージェントが判断します。
2. Strixが解決する課題:手動ペンテストのコストと従来スキャナの誤検知

Strixが狙うのは、セキュリティ検査における「速さ・正確さ・コスト」のトレードオフです。従来のやり方には、それぞれ明確な弱点がありました。
従来の静的スキャナ(SAST)は速くて安いものの、コードのパターンだけで判断するため誤検知(false positive)が大量に出ます。開発者は「オオカミ少年」化した警告を無視するようになり、本当の脆弱性が埋もれます。
手動ペネトレーションテストは精度が高い反面、時間とコストがかかり、専門家のスケジュールにも縛られます。リリースのたびに実施するのは非現実的で、検査の間隔が空くほどリスクは溜まります。もうひとつ見過ごせないのが”検査のタイミング”の問題です。手動ペンテストは四半期に一度といった頻度になりがちですが、コードは毎日変わります。前回の検査から今日までに入った変更こそが、新しい穴の温床です。Strixのように差分ベースで毎PR検査できる仕組みは、この”検査と変更の時間差”を埋める意味でも効いてきます。
Strixはこの間を埋めます。AIエージェントが自律的に攻めるので手動ほどの人手はかからず、しかも実際にPoCで裏付けるため誤検知が大幅に減ります。「速くて安いが不正確」と「正確だが遅くて高い」の二択を、"実証ベースの自動化"で崩すのがStrixの立ち位置です。
- ・Strixは「PoCで検証するので誤検知が大幅に減る」ツールであり、見逃し(false negative)が起きない保証ではない。
- ・PoC生成に失敗した脆弱性は報告されない可能性がある。最終的な保証には人間のレビューを併用するのが安全。
誤検知が多いことの本当の怖さは、無駄が増えることではなく、警告に慣れた開発者が本物の警告まで無視するようになることです。これは「アラート疲れ(alert fatigue)」と呼ばれ、セキュリティ運用の最大の敵のひとつです。Strixのように「報告される=実際に悪用できた」という前提が守られていれば、開発者は指摘を信頼して即座に動けます。逆に言えば、Strixの価値は”検知件数の多さ”ではなく”指摘の信頼性の高さ“にあります。件数を競う従来スキャナとは評価軸そのものが違う、と理解しておくと使い方を間違えません。
3. Strixの主な機能:偵察から実証まで揃う攻撃的ツールキット

Strixは単なる「LLMにコードを読ませるツール」ではなく、攻撃者が使う一式のツールキットをエージェントに持たせている点が特徴です。READMEが挙げる主な同梱機能は次のとおりです。
・HTTPインターセプトプロキシ(Caido連携)で通信を観察・改ざん
・ブラウザ・エクスプロイト(XSS・CSRF・クリックジャッキング)
・対話的なシェル/コマンド実行
・Python製エクスプロイトを走らせるサンドボックス実行環境
・偵察とOSINT(攻撃面のマッピング)
・静的・動的の両コード解析
・脆弱性ナレッジベース
これらが「本物のツール」であることには意味があります。LLMに知識として脆弱性を語らせるだけなら、それらしい”作文”で終わりがちです。しかしStrixは、実際のプロキシで通信をいじり、実際のブラウザでスクリプトを走らせ、実際のシェルでコマンドを打ちます。つまり推測ではなく実測で判断するため、報告の裏付けが取れるのです。静的解析と動的解析の両方を備えるため、”コード上は問題なさそうでも実行時に破綻する”ケースも拾えます。攻撃者が使う道具立てをそのままエージェントに握らせている——ここがStrixの”攻撃的(offensive)”たるゆえんです。
検出対象も広く、OWASP系の主要カテゴリを網羅します。アクセス制御の不備(IDOR・権限昇格・認証バイパス)、インジェクション(SQL・NoSQL・OSコマンド・SSTI)、サーバーサイド(SSRF・XXE・安全でないデシリアライゼーション・RCE)、クライアントサイド(各種XSS・プロトタイプ汚染・CSRF)、ビジネスロジックの欠陥(レースコンディション・決済操作・ワークフローバイパス)、認証/セッション管理、API固有の問題(mass assignment・レート制限バイパス) などです。これだけ広いカテゴリを一つのツールでカバーできる背景には、”人間の攻撃手順をエージェントに再現させる”という設計思想があります。個別の脆弱性ごとに専用ルールを書くのではなく、汎用的な攻撃能力(通信操作・スクリプト実行・コマンド実行)と推論を組み合わせることで、未知の組み合わせにも対応しようとします。だからこそ、ルールベースでは拾いにくいビジネスロジックの穴にも手が届くわけです。
さらに、複数のエージェントが分担して動くマルチエージェント・オーケストレーションを備えます。1体が攻撃面をマッピングし、別の1体がペイロードを生成し、さらに別の1体が成功したエクスプロイトを文書化する——といった分業で、大きな対象でも精度を保ちながらスケールできます。
見落とされがちですが、Strixが得意とするのは既知パターンだけではありません。ビジネスロジックの欠陥——たとえば「クーポンを並行リクエストで二重適用できる」「本来の手順を飛ばして決済を確定できる」といった、仕様の隙を突く脆弱性は、静的スキャナがもっとも苦手とする領域です。実際に操作を試みるStrixは、こうした”文脈依存の穴”にこそ強みを発揮します。発見して終わりではなく、修正ガイダンスの生成や規制対応を意識したコンプライアンスレポートの出力にも対応し、有償版では修正案をプルリクエストとして自動生成する機能まで用意されています。
- ・言語はPythonが約91%。LLMルーティングにLiteLLM、HTTPプロキシにCaido、テンプレート型スキャンにNuclei、ブラウザ操作にPlaywright、CLIのUIにTextualを採用。
- ・攻撃コードは常にDockerサンドボックス内で実行され、ホストから隔離される。
4. Strixの仕組み:AIが人間のように攻めてPoCで裏付ける
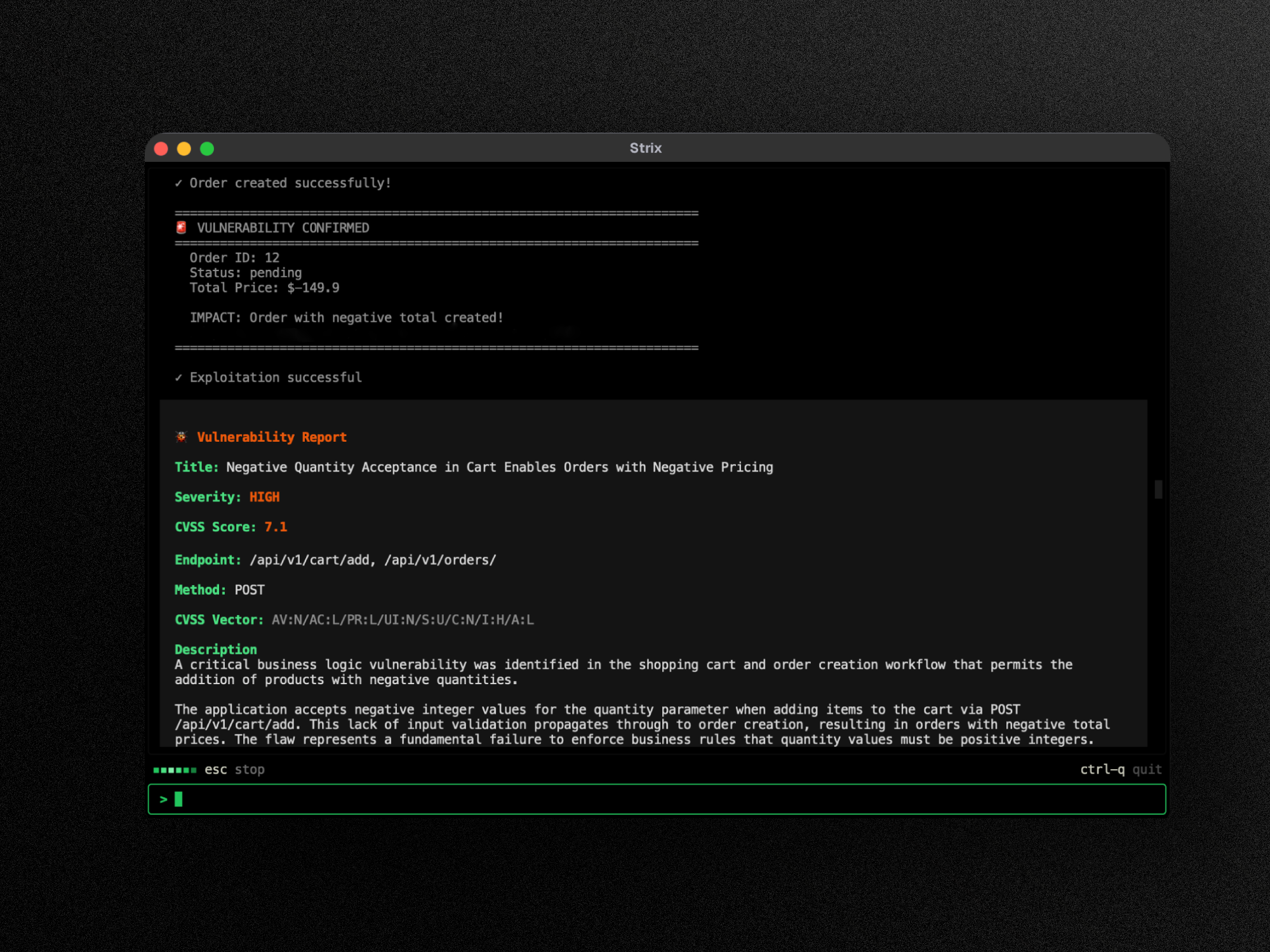
Strixのエージェントは、熟練したペンテスターの思考プロセスを模しています。おおまかには次のように動きます。
コード / リポジトリ / URL"] --> B["偵察
攻撃面をマッピング"] B --> C["仮説
脆弱そうなコードパスを推定"] C --> D["エクスプロイト生成
攻撃コードを自分で記述"] D --> E["サンドボックス実行
隔離Docker内で試行"] E --> F{"悪用できたか"} F -->|"はい"| G["PoC付きで報告
修正ガイダンス生成"] F -->|"いいえ"| C
ポイントは、失敗したら仮説に戻って攻め方を変えるループ構造です。人間のペンテスターが「この入り口がダメなら別の角度で」と試行錯誤するのと同じことを、エージェントが自動で回します。そして悪用に成功したものだけを、動くPoCと修正ガイダンスを添えて報告します。この仕組みは、裏を返せば”時間とAPIコストをかけるほど深く探れる”ことも意味します。クイックスキャンは表層を素早く、標準スキャンはより粘り強く——かける手間と得られる網羅性はトレードオフの関係にあり、重要なシステムほど時間をかけ、日常チェックは軽く、とメリハリをつけるのがコツです。
このループが複数エージェントで並行して走るため、対象が大きくても現実的な時間で回せます。「見つけたと主張する」のではなく「実際に突けたと証明する」——このPoC駆動の検証こそがStrixの核心です。実行はすべてDockerサンドボックス内なので、攻撃コードがホスト環境を汚す心配もありません。
この「失敗したら角度を変える」性質は、ペンテストの本質そのものです。脆弱性の多くは一発で綺麗に決まるものではなく、少しずつ条件を変えながら”通る組み合わせ”を探り当てる作業で見つかります。決め打ちのルールしか持たないスキャナがここで止まるのに対し、Strixのエージェントは仮説と実行を往復し続けられるため、複雑な前提条件が絡む脆弱性にも届きやすくなります。役割を分けた複数エージェントが互いにデータを共有しながら並行で進むため、エンドポイントが数百あるような大規模アプリでも現実的な時間で網羅性を高められます。
5. Strixのインストールと基本的な使い方
導入はワンライナーです。前提として、起動中のDockerと対応LLMのAPIキーを用意しておきます。
# インストール
curl -sSL https://strix.ai/install | bash
次に、使用するLLMとAPIキーを環境変数で設定します。設定は ~/.strix/cli-config.json に永続化されます。
export STRIX_LLM="openai/gpt-5.4"
export LLM_API_KEY="your-api-key"
# 任意設定
export LLM_API_BASE="your-api-base-url"
export PERPLEXITY_API_KEY="your-api-key"
export STRIX_REASONING_EFFORT="high"
あとは対象を指定して実行するだけです。ローカルのディレクトリ、GitHubリポジトリ、稼働中のWebアプリのいずれも指定できます。
# ローカルのコードベース
strix --target ./app-directory
# GitHubリポジトリ
strix --target https://github.com/org/repo
# 稼働中のWebアプリ
strix --target https://your-app.com
認証が必要なアプリや、複数ターゲット、PR差分だけを検査する使い方もできます。
# 認証情報を渡して認証済みテスト
strix --target https://your-app.com --instruction "Perform authenticated testing using credentials: user:pass"
# 複数ターゲットを同時指定
strix -t https://github.com/org/app -t https://your-app.com
# 非対話(-n)・クイックスキャン・main との差分だけ
strix -n --target ./ --scan-mode quick --scope-mode diff --diff-base origin/main
主なフラグは、--target/-t(複数指定可)、--instruction(自然言語で指示)、-n(非対話・ヘッドレス)、--scan-mode(quick/standard)、--scope-mode diff と --diff-base <ref>(差分スコープ)です。
実行の粒度は用途に応じて選べます。--scan-mode quick は素早い一次チェック向き、standard はより丁寧な検査向きです。--instruction に自然言語で「このAPIの認可周りを重点的に」といった指示を与えれば、エージェントの注意をピンポイントに寄せられます。CI用途では -n(非対話)を付け、差分スコープに絞ると実行時間とAPIコストの両方を抑えられます。なお対象を指定すると、Strixはまずサンドボックス用のDockerイメージを取得してから検査を開始します。初回は少し時間がかかりますが、以降はキャッシュされます。まずは小さなスコープで感触を掴み、徐々に対象を広げるのが定石です。また、CIで使う場合はAPIキーを必ずシークレットとして管理し、ログにキーやPoCの生データが残らないよう注意してください。攻撃を実行する性質上、Strix自体の運用も”セキュアに”行う必要があります。
6. CI/CDへの組み込みと対応LLM

Strixが実務で効くのは、プルリクエストのたびに差分だけを自動でペンテストできる点です。GitHub Actionsなら次のように組み込めます。
name: strix-penetration-test
on:
pull_request:
jobs:
security-scan:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
with:
fetch-depth: 0
- name: Install Strix
run: curl -sSL https://strix.ai/install | bash
- name: Run Strix
env:
STRIX_LLM: $
LLM_API_KEY: $
run: strix -n -t ./ --scan-mode quick
このワークフローは、PRが作られるたびに変更差分を非対話でクイックスキャンする最小構成です。ここに --scope-mode diff を足せば、変更のあった部分だけにさらに絞れます。検査結果をアーティファクトとして保存したり、失敗時にPRをブロックしたりといった作り込みも、通常のCIステップと同じ感覚で追加できます。
対応LLMは、LiteLLMを介して幅広く選べます。公式が推奨する構成は次のとおりです。
| 用途 | 推奨モデルID | 提供元 |
|---|---|---|
| 高精度重視 | openai/gpt-5.4 |
OpenAI |
| バランス型 | anthropic/claude-sonnet-4-6 |
Anthropic |
| Google環境 | vertex_ai/gemini-3-pro-preview |
|
| クラウド各種 | Vertex AI / Bedrock / Azure | 各社 |
| ローカル実行 | Ollama / LM Studio | セルフホスト |
モデル選びは精度・速度・コストのバランスで決めます。難度の高い対象や重要システムには高精度モデルを、日常のPRチェックには軽量で安価なモデルを、といった使い分けが現実的です。ローカルモデルを使えばコードを外部に出さずに検査できますが、モデルの推論力に検出精度が引きずられる点は理解しておく必要があります。機密性の高いコードほど、”どこまでを外部LLMに渡すか”の線引きを事前に決めておきましょう。
DevSecOps連携としては、GitHub Actions・GitLab・Bitbucketに加え、Slack・Jira・Linearへの連携がプラットフォーム側で提供されています。「PRを出す → 差分だけ自律ペンテスト → 結果をSlack/Jiraに通知」までを自動化できるのが、開発チームにとっての実用的な価値です。
無償のOSS版に対し、有償のプラットフォーム版(app.strix.ai)は、ワンクリックでの自動修正(PR化)、継続的なペンテスト、SSO(SAML/OIDC)、SOC 2・ISO 27001・PCI DSSを意識したレポート、VPC/セルフホスト、BYOK(自前の鍵の持ち込み)といったエンタープライズ機能で差別化されています。個人や小規模チームはOSS版のCLIで十分ですが、組織的にガバナンスを効かせたい場合はプラットフォーム版が選択肢になります。CIに組み込む際は、”差分スコープ+クイックスキャンを常時、フル検査は夜間やリリース前だけ”のように段階を分けると、精度を保ちつつコストを抑えられます。
7. Strixの導入判断と法的・実務上の注意

最後に、導入前に必ず押さえるべき点を整理します。従来手法との比較は次のとおりです。
| 観点 | Strix | 従来のSASTスキャナ | 手動ペンテスト |
|---|---|---|---|
| 誤検知 | 少ない(PoCで検証) | 多い | 少ない |
| 速度・頻度 | 速い・CIで毎回 | 速い | 遅い・単発 |
| コスト | LLM API従量 | ライセンス費 | 高い(人件費) |
| 悪用の実証 | あり(PoC) | なし | あり |
| 対象 | コード/リポジトリ/Web | 主にコード | 何でも |
補足として、StrixはAIセキュリティ領域で単独の存在ではありません。プロンプトインジェクション検査に強いツールや、AI駆動のセキュリティ調査フレームワークなど、”AIでセキュリティを自動化する”新しいツール群が同時期に台頭しており、Strixはその中で「自律型の攻撃的テスト(ペネトレーション)」を担う一角です。静的解析・依存関係スキャン・プロンプト防御などと組み合わせ、多層で守るのが現実的です。Strix単体で全部を賄うのではなく、”攻めて実証する層”を足す、と捉えると導入判断がしやすくなります。
Strixが向いているケース
・CI/CDに脆弱性検査を組み込み、PRごとに差分を自動チェックしたい
・従来スキャナの誤検知に疲れて、確度の高い指摘だけが欲しい
・専門ペンテスターを毎回は雇えないが、継続的なセキュリティ検査をしたい
逆に、静的解析やSCA(依存関係スキャン)だけで足りる軽微なプロジェクトや、外部LLMにコードを渡せない厳格な環境では、導入のハードルが上がります。その場合はローカルモデル運用を検討するか、対象を絞って部分適用するのが現実的です。
慎重に判断すべき点
まず法的な線引きです。READMEは「自分が所有しているか、許可を得たアプリのみを対象にすること」「倫理的・合法的に使う責任は利用者にある」と明記しています。許可のない対象への攻撃的テストは、日本の不正アクセス禁止法などに抵触するおそれがあります。必ずスコープ合意(書面での許可)を得た範囲でのみ使ってください。
次にコストです。Strixは外部LLMを多用するため、スキャンの規模に応じてAPI利用料が発生します。大規模対象では費用が膨らみ得るので、まずは --scan-mode quick や差分スコープで小さく試すのが安全です。
- ・テスト対象は「所有」または「許可済み」に限定する(不正アクセスは違法)。
- ・LLM API課金が発生する。差分スコープ・クイックスキャンで費用を管理する。
- ・v1.0.x系と若いプロジェクト。重要判断は人間のレビューを併用し、バージョンを固定して運用する。
最後に運用面の助言を。Strixは強力ですが”魔法の箱”ではありません。出てきたPoCと修正案は必ず開発者がレビューし、本番反映前に自分たちのテストで再確認してください。特に自動修正を使う場合は、生成された変更が意図どおりか、副作用がないかを人間が最終判断することが欠かせません。AIに攻めさせ、AIに直させる時代でも、”最後の責任は人間”という原則は変わりません。
まとめ
Strixは、「見つけたと主張するスキャナ」から「実際に突けたと証明するAIペンテスター」へと、脆弱性検査の前提を進めるツールです。PoC駆動の検証で誤検知を減らし、CI/CDに組み込めば継続的なセキュリティ検査が現実になります。セキュリティ検査は「やった/やらない」の二値ではなく、”どれだけ継続的に・確度高く回せるか”の勝負です。Strixはその両方を引き上げる方向の道具ですが、法的な許可とコスト管理、そして人間による最終レビューは省略できません。
- ・Strixは自律AIエージェントが実際に攻撃し、動くPoCで脆弱性を裏付けるOSSペンテストツール。
- ・従来スキャナの誤検知と、手動ペンテストのコストという二律背反を"実証ベースの自動化"で崩す。
- ・ローカル/リポジトリ/WebをCI/CDで継続検査でき、対応LLMも幅広い。
- ・実行にはDockerとLLM APIキーが必要。API課金に注意。
- ・Apache-2.0だが「許可した対象のみテストする」法的責任は利用者にある。
まずは自分が管理するテスト用リポジトリを対象に、strix --target ./ で小さく動かし、出力されるPoCと修正ガイダンスの粒度を自分の目で確かめてみるのがおすすめです。自律ペンテストの標準化という文脈ではOWASP APTs:自律ペンテストの標準化が、AIによる大規模な悪用の実例としてはAIを悪用した大量エクスプロイトと認証情報の収集が、攻守両面の理解を深めてくれます。
参照ソース
・usestrix/strix (GitHub) — 公式リポジトリ。README・機能一覧・CLI仕様・法的注意の一次ソース。
・Strix 公式ドキュメント — インストール・設定・連携の公式ドキュメント。
・How to Use Strix (freeCodeCamp) — 挙動・PoC駆動検証の解説(二次ソース)。





