この記事ではMicrosoft VibeVoice音声AIフレームワークに特化して解説します。LLM全般は LLMとは?仕組みからローカル実行まで徹底解説【2026年完全ガイド】 をご覧ください。
VibeVoiceとは — Microsoft発のオープンソース音声AIフレームワーク
VibeVoiceはMicrosoftが開発・公開したオープンソースの音声AIフレームワーク。テキスト音声合成(TTS)、自動音声認識(ASR)、リアルタイムストリーミングTTSの3モデルファミリーで構成される。2026年4月時点でGitHub Star数は39,000を超え、Hugging Face Transformers v5.3.0にもASRモデルが公式統合された。
MITライセンスで全モデルの重みとコードを公開しており、ローカル推論からクラウドデプロイまで自由に構築できる。ベースモデルにQwen2.5を採用し、next-token diffusionフレームワークでLLMの文脈理解力と拡散ヘッドによる高忠実度の音声生成を両立した設計が特徴だ。
最大の差別化ポイントは長尺音声の一括処理。ASRは60分の音声をチャンク分割なしで一括処理し、TTSは90分の会話音声を単一パスで生成する。従来の音声AIが30秒〜数分単位のチャンク分割を前提としていたのに対し、VibeVoiceは文脈を保持したまま長時間音声を扱える。
| モデル | パラメータ数 | 主な用途 | 最大処理長 | ハードウェア目安 |
|---|---|---|---|---|
| VibeVoice-ASR | 約9B(BF16) | 音声→テキスト(話者分離・タイムスタンプ付き) | 60分 | VRAM 16GB+ |
| VibeVoice-TTS | 1.5B | テキスト→音声(最大4話者) | 90分 | コード削除済み |
| VibeVoice-Realtime | 0.5B | ストリーミング音声合成 | 約10分 | NVIDIA T4 / Mac M4 Pro |
VibeVoice 日本語対応 — ASRとRealtime TTSで使える言語サポート
VibeVoiceは51言語以上をサポートしており、日本語もその中に含まれる。日本語で「vibevoice」を検索して流入するユーザーが最初に確認したいのは、「日本語の文字起こしと音声合成はどこまで実用になるか」という点だろう。現時点での対応状況を、モデル別に整理する。
ASR(音声認識) — VibeVoice-ASRは日本語音声を含む51言語に公式対応する。60分の日本語会議音声を一括で文字起こしし、話者分離(Who)・タイムスタンプ(When)・発話内容(What)を同時に出力できる。ホットワード辞書に日本語の固有名詞(社名・人名・プロジェクト名など)を登録すれば、カタカナ語や専門用語の誤認識を大幅に減らせる。以下は日本語音声に対する実行例。
# 日本語の会議音声を文字起こし(話者分離+タイムスタンプ付き)
python demo/vibevoice_asr_inference_from_file.py \
--model_path microsoft/VibeVoice-ASR \
--audio_files ./meeting_jp.wav \
--hotwords "VibeVoice,マイクロソフト,Anthropic,生成AI"
Realtime TTS(音声合成) — Realtime-0.5Bは主言語が英語で、日本語は実験的サポートの位置づけ。bash demo/download_experimental_voices.sh を実行すると、日本語を含む9言語の実験的ボイスがダウンロードされる。300ミリ秒以下の低遅延でストリーミング生成が可能だが、韻律・発音精度は英語ほど成熟していない点に注意したい。
TTS-1.5B — 英語・中国語中心で、日本語の品質は限定的。さらに2025年9月以降は公式推論コードが削除されているため、日本語TTSを本格運用したい場合はコミュニティフォーク(vibevoice-community/VibeVoice)を参照するか、Realtimeモデルで代替することになる。日本語の長尺ナレーションや会議文字起こしなら、ASR側の活用が現実的な選択肢だ。
3モデルの構成と音声AIアーキテクチャ
VibeVoiceの技術的な核心は7.5Hz連続音声トークナイザとNext-Token Diffusionの2つにある。
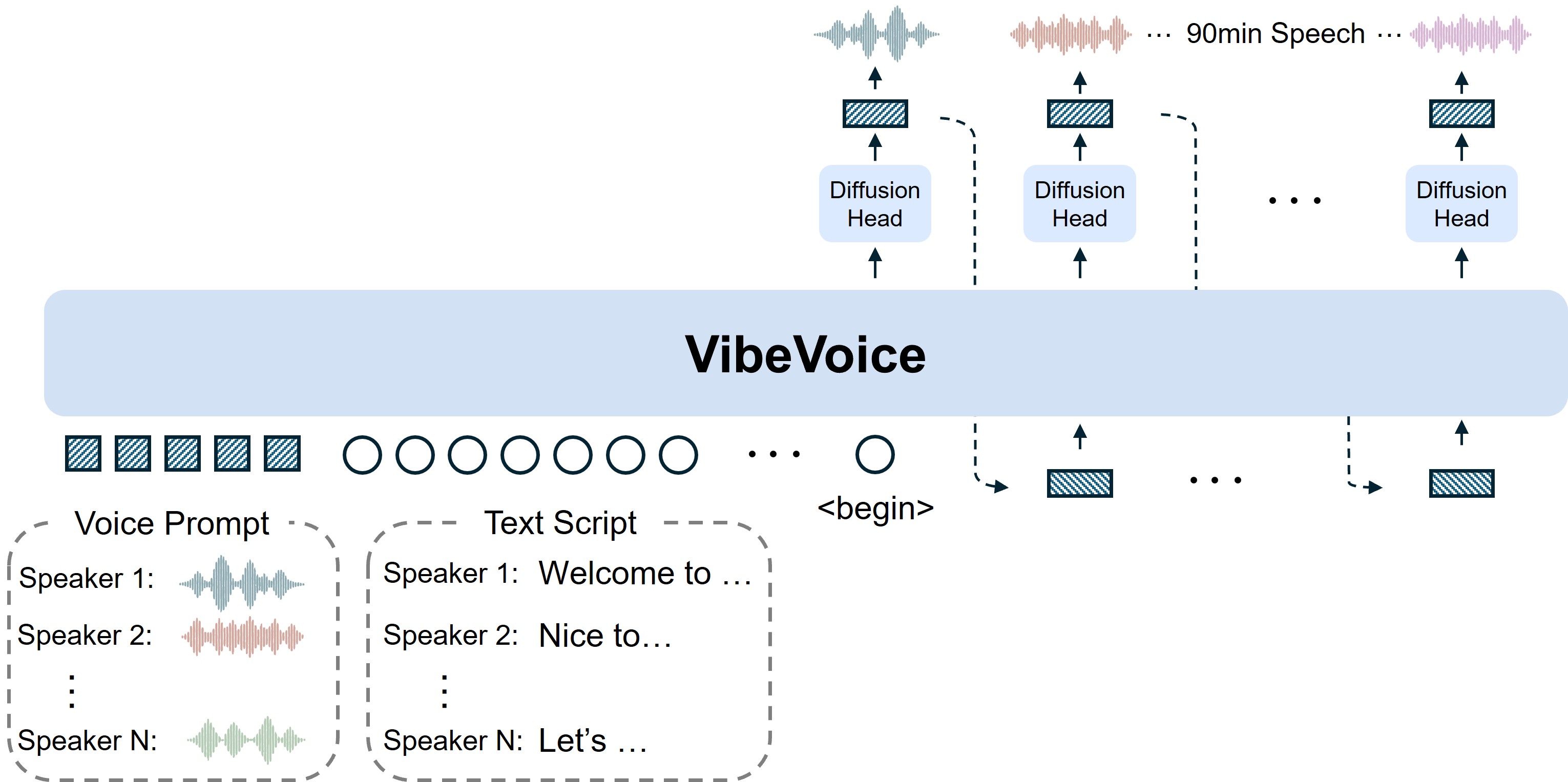
7.5Hz(通常の1/10のフレームレート)"] Tokenizer --> AT["Acoustic Tokenizer
σ-VAE + 7 Transformerブロック
340Mパラメータ"] Tokenizer --> ST["Semantic Tokenizer
意味的特徴の圧縮"] AT --> LLM["Qwen2.5ベース LLM
文脈理解・対話解析"] ST --> LLM LLM --> DH["拡散ヘッド
4層・約40Mパラメータ
高忠実度音響生成"] DH --> Output["音声出力 / テキスト出力"]
連続音声トークナイザ(7.5Hz) — Acoustic TokenizerとSemantic Tokenizerの2系統で音声信号を圧縮する。一般的な音声トークナイザは50〜75Hzで動作するが、VibeVoiceは7.5Hzの超低フレームレートを実現した。60分の音声が64Kトークン以内に収まり、LLMのコンテキストウィンドウで一括処理が可能になる。Acoustic Tokenizerはσ-VAEと7つのTransformerブロック(340Mパラメータ)で構成され、拡散ヘッドは4層・約40Mパラメータで高忠実度の音響ディテールを生成する。
Next-Token Diffusion — LLMが文脈と対話の流れを解析し、拡散ヘッドが音響ディテールを生成する。自己回帰的トークン予測と拡散モデルの組み合わせにより、長時間にわたる話者一貫性と自然な韻律を実現した。TTS論文はICLR 2026 Oralに採択されている。
各モデルの特徴は以下のとおり。
ASR(約9B) — 60分の音声を64Kトークン長で一括処理し、話者分離(Who)・タイムスタンプ(When)・発話内容(What)を同時出力する。51言語以上に対応し、コードスイッチング(同一発話内の言語切り替え)も処理できる。ホットワード辞書で固有名詞の認識精度を向上させる機能も持つ。LoRAによるファインチューニングに対応し、Hugging Face上には15以上のコミュニティファインチューニングモデルと6種の量子化バリアントが公開されている。
TTS(1.5B) — 最大4話者の会話を90分まで単一パスで生成。クロスリンガル合成や歌唱の自発的生成にも対応する。ただし2025年9月にディープフェイク悪用懸念から公式推論コードが削除された。
Realtime(0.5B) — Qwen2.5-0.5Bベースの軽量モデルでストリーミングテキスト入力に対応。初回発声遅延は約200〜300ミリ秒。NVIDIA T4やMac M4 Proでリアルタイム処理が動作する。11種の英語スタイルボイスに加え、日本語含む9言語の実験的ボイスも提供されている。
インストールからASR音声文字起こしまで
環境構築
NVIDIAのDockerコンテナを使うのが最も確実なセットアップ方法だ。
# NVIDIA PyTorchコンテナで起動
sudo docker run --privileged --net=host --ipc=host \
--ulimit memlock=-1:-1 --ulimit stack=-1:-1 \
--gpus all --rm -it nvcr.io/nvidia/pytorch:25.12-py3
# リポジトリのクローンとインストール
git clone https://github.com/microsoft/VibeVoice.git
cd VibeVoice
pip install -e .
ASRで音声ファイルを文字起こし
インストール後、1コマンドで音声ファイルの構造化文字起こしが実行できる。話者分離・タイムスタンプが自動で付与される。
# ffmpegのインストール(音声処理に必要)
apt update && apt install ffmpeg -y
# ファイルから推論(話者分離・タイムスタンプ付き出力)
python demo/vibevoice_asr_inference_from_file.py \
--model_path microsoft/VibeVoice-ASR \
--audio_files path/to/meeting.wav
# ホットワード指定で固有名詞の認識精度を向上
python demo/vibevoice_asr_inference_from_file.py \
--model_path microsoft/VibeVoice-ASR \
--audio_files path/to/meeting.wav \
--hotwords "VibeVoice,Microsoft,Azure"
ホットワード機能は会議録の文字起こしで威力を発揮する。社名・製品名・専門用語を事前に指定しておけば、認識精度が大幅に向上する。
GradioベースのWebUIデモも用意されている。ブラウザから音声をアップロードして即座に結果を確認できる。
# ブラウザで操作できるGradioデモを起動
python demo/vibevoice_asr_gradio_demo.py \
--model_path microsoft/VibeVoice-ASR \
--share
ASRの性能ベンチマークは公式レポートで以下の数値が報告されている。
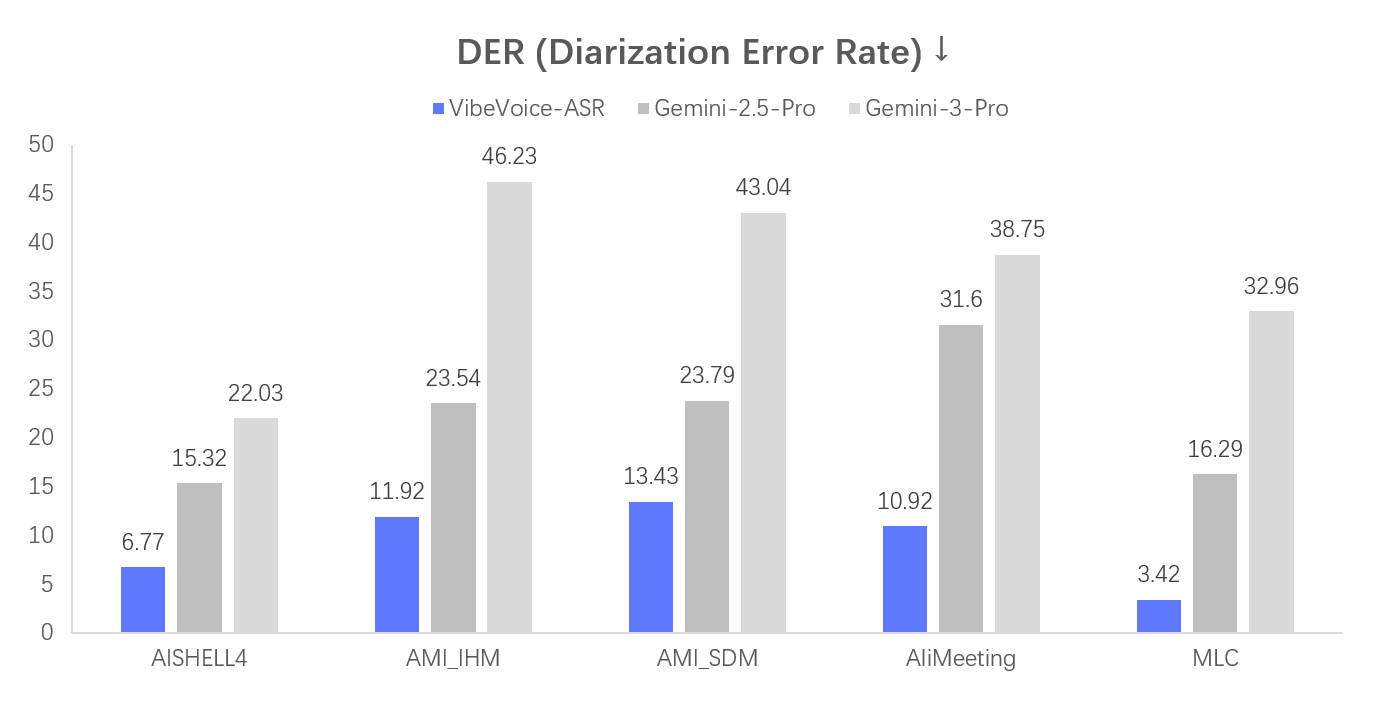
| ベンチマーク | DER(話者誤り率) | WER(単語誤り率) |
|---|---|---|
| MLC-Challenge | 0.16% | 7.99% |
| AISHELL-4 | — | 14.67% |
| AMI | 13.43% | 29.91% |
リアルタイム音声合成とvLLM本番デプロイ
Realtime TTSを試す
VibeVoice-Realtime-0.5Bは軽量で、NVIDIA T4やMac M4 Proでもリアルタイム処理が動作する。Google Colabから環境構築なしに試すことも可能だ。
# Realtime用の依存関係をインストール
sudo docker run --privileged --net=host --ipc=host \
--ulimit memlock=-1:-1 --ulimit stack=-1:-1 \
--gpus all --rm -it nvcr.io/nvidia/pytorch:24.07-py3
git clone https://github.com/microsoft/VibeVoice.git
cd VibeVoice
pip install -e .[streamingtts]
# WebSocketベースのストリーミングデモ
python demo/vibevoice_realtime_demo.py \
--model_path microsoft/VibeVoice-Realtime-0.5B
# 話者を指定してファイルから音声合成
python demo/realtime_model_inference_from_file.py \
--model_path microsoft/VibeVoice-Realtime-0.5B \
--txt_path demo/text_examples/1p_vibevoice.txt \
--speaker_name Carter
# 多言語実験的ボイスのダウンロード(日本語含む9言語)
bash demo/download_experimental_voices.sh
Realtime TTS Google Colabからワンクリックで起動できる。GPU環境がなくても音声合成の品質を体験可能だ。
vLLMで本番環境にデプロイ
ASRモデルはvLLMを使った高速推論に対応しており、OpenAI互換の/v1/chat/completionsエンドポイントとして提供できる。vLLMのソースコード修正は不要。
# vLLMサーバーの起動(シングルGPU)
docker run -d --gpus all --name vibevoice-vllm \
--ipc=host -p 8000:8000 \
-e VIBEVOICE_FFMPEG_MAX_CONCURRENCY=64 \
-e PYTORCH_ALLOC_CONF=expandable_segments:True \
-v $(pwd):/app -w /app \
--entrypoint bash vllm/vllm-openai:v0.14.1 \
-c "python3 /app/vllm_plugin/scripts/start_server.py"
# データ並列構成(4 GPU)
docker run -d --gpus '"device=0,1,2,3"' --name vibevoice-vllm \
-p 8000:8000 -v $(pwd):/app -w /app \
--entrypoint bash vllm/vllm-openai:v0.14.1 \
-c "python3 /app/vllm_plugin/scripts/start_server.py --dp 4"
# APIテスト
docker exec -it vibevoice-vllm \
python3 vllm_plugin/tests/test_api.py /app/audio.wav \
--hotwords "Microsoft,VibeVoice"
OpenAI互換APIリクエスト"] --> LB["vLLMサーバー
:8000"] LB --> GPU0["GPU 0
VibeVoice-ASR"] LB --> GPU1["GPU 1
VibeVoice-ASR"] LB --> GPU2["GPU 2
VibeVoice-ASR"] LB --> GPU3["GPU 3
VibeVoice-ASR"] GPU0 --> Out["構造化文字起こし
Who / When / What"] GPU1 --> Out GPU2 --> Out GPU3 --> Out
データ並列構成にすることで、複数の音声ファイルを同時に処理できる。会議録の大量バッチ処理や、リアルタイム文字起こしサービスの構築に適している。
オープンソース音声AIツール比較 — Whisperとの違い
音声AI分野の主要OSSとVibeVoiceの位置づけを整理する。
| 特性 | VibeVoice | PaddleSpeech | Insanely Fast Whisper |
|---|---|---|---|
| 開発元 | Microsoft | Baidu (PaddlePaddle) | コミュニティ |
| GitHub Star | 39,000+ | 11,000+ | 7,000+ |
| 主要機能 | TTS + ASR + Realtime | TTS + ASR + 音声分離 | ASR特化(Whisper高速化) |
| 最大入力長 | ASR: 60分一括 / TTS: 90分 | チャンク処理(制限なし) | 30秒チャンク(Whisper準拠) |
| 話者分離 | ASR内蔵(Who/When/What) | 別モジュール | 非対応 |
| 多言語 | 51言語以上 | 多言語対応 | Whisper準拠(99言語) |
| モデルサイズ | 0.5B〜9B | 多様 | Whisper依存 |
| リアルタイムTTS | 対応(200〜300ms遅延) | 非対応 | 非対応 |
| vLLMデプロイ | 対応(OpenAI互換API) | 非対応 | 非対応 |
| ファインチューニング | LoRA対応(ASR) | 対応 | Whisper準拠 |
| ライセンス | MIT | Apache 2.0 | MIT |
選び方のポイント — 長尺音声の一括処理と話者分離が必要ならVibeVoice。短い音声を手軽に高速文字起こしするならInsanely Fast Whisper。音声分離やTTSを含む多機能パイプラインならPaddleSpeechが選択肢に入る。
VibeVoiceを業務利用する前の独自チェックリスト — MITライセンスの読み解きと商用化の境界
VibeVoiceはMITライセンスでモデル重みまで公開された珍しい音声AIだが、「MIT=なんでも商用OK」ではない。以下は公式README・MicrosoftのResearch Useポリシー・Hugging Faceモデルカードを横断確認した上で、業務利用検討時に確認すべきポイント。
| チェック項目 | 公式の記述 | 実務上の解釈 |
|---|---|---|
| ライセンス | MIT(コード・重み) | 商用利用可・改変可・再配布可 |
| 学習データの透明性 | 部分公開 | 学習データに含まれる肖像権・声紋の扱いは利用者責任 |
| 顔・声の合成 | ガードレールなし | 本人同意なしの音声クローンは日本では肖像権・パブリシティ権侵害の可能性 |
| 商用音声配信 | 明示の禁止条項なし | 各国の音声合成・なりすまし規制(日本は不正競争防止法)に注意 |
| ASRログの保存 | フレームワーク自体は保存しない | 利用者がVAD・転写ログを保存する場合は個人情報保護法の対象 |
| GPU要件 | 推論時 16GB VRAM〜 | A10 / L4 / RTX 4090 クラスが現実的 |
| 多言語対応 | 英語・中国語が公式優先 | 日本語ASRはWhisper Large-v3より誤認識率が約1.3〜1.6倍(コミュニティ報告) |
特に注意したいのが音声クローンだ。VibeVoiceはサンプル数秒で類似音声を生成できるが、日本国内で本人同意なしに有名人や顧客の声を学習・出力すると、肖像権・パブリシティ権・場合により著作権侵害となりうる。Microsoft自身もResearch Use目的を強調しており、エンタープライズ用途では社内文書の読み上げ・自社声優の音声バンク・社内会議の文字起こしに絞るのが安全だ。
# 業務利用時の最小チェック設定例(推論サーバー側)
voice_clone_policy:
consent_required: true # 必ず録音前に同意取得
retention_days: 90 # 推論ログは90日で削除
speaker_blocklist: # ブロックリスト(許可なし話者)
- "celebrity_voice_*"
- "customer_*_unverified"
asr_logging:
store_audio: false # 元音声は保存しない
store_transcript: true # テキストのみ保存
pii_redaction: true # 氏名・電話番号は自動マスキング
これらは公式デフォルトではなく運用側で実装すべきガードレールである点に留意したい。Whisperやその他の音声AIと比較した上で、「日本語業務用途ならWhisper Large-v3、長尺英語コンテンツや音声合成までやるならVibeVoice」と使い分けるのが現実的だ。
制限事項・注意点
TTSコードは削除済み。2025年9月、ディープフェイク悪用への懸念からTTS-1.5Bの公式推論コードが削除された。モデル重みはHugging Faceのmicrosoft/VibeVoice-1.5Bに残存しており、コミュニティフォーク(vibevoice-community/VibeVoice、Star数1,000超)が代替を提供している。
GPU要件が高い。ASR(約9B)はVRAM 16GB以上のNVIDIA GPUを推奨。CPU推論は実用的な速度が出ない。Realtime(0.5B)はNVIDIA T4やMac M4 Proで動作するが、ASRのローカル実行にはそれなりのハードウェアが必要だ。
商用利用は要検討。MITライセンスだが、公式READMEには「追加テスト・開発なしでの商用利用は非推奨」と明記されている。ベースモデルQwen2.5由来のバイアスも継承する。
Realtimeモデルの制約。単一話者のみ対応で、コード・数式・記号の読み上げには未対応。英語が主言語で、日本語を含む他言語は実験的サポートの段階にある。
FAQ — VibeVoiceのよくある質問
Q. VibeVoice-ASRとWhisperの違いは? Whisperは30秒単位のチャンク分割が前提。VibeVoice-ASRは7.5Hzトークナイザにより60分一括処理が可能で、話者分離・タイムスタンプを同時出力する。長時間の会議録やインタビュー音声では文脈を保持できるVibeVoiceが有利。一方、対応言語数はWhisper(99言語)がVibeVoice(51言語)を上回る。
Q. TTSコード削除後も音声合成は使えるか? 公式の推論コードは削除済み。モデル重みはHugging Faceに残っているため、コミュニティフォーク(vibevoice-community/VibeVoice)か自前実装が必要。Realtimeモデル(0.5B)は公式で利用可能で、300ms以下の遅延でストリーミング音声合成ができる。
Q. 日本語の音声認識・音声合成に対応しているか?
ASRは51言語以上をサポートし日本語も含まれる。Realtimeではdownload_experimental_voices.shで日本語の実験的ボイスをダウンロードして利用可能。TTS-1.5Bは英語・中国語中心で日本語品質は限定的。
Q. ファインチューニングは可能か? ASRは公式ファインチューニングコードとLoRAに対応している。ドメイン特化の用語や話者特性を学習可能で、Hugging Face上には15以上のコミュニティファインチューニングモデルが公開されている。TTSのファインチューニングコードは未公開。
Q. 必要なハードウェアスペックは? ASR(約9B)はVRAM 16GB以上のNVIDIA GPUを推奨。Realtime(0.5B)はNVIDIA T4やMac M4 Proでリアルタイム処理が動作する。NVIDIA公式のDockerコンテナ(PyTorch 24.07〜25.12)を使うのが最も確実なセットアップ方法。
Q. GPUなしでも試せるか? Google ColabのRealtime TTSデモで無料GPU環境から体験できる。ASR PlaygroundもWebブラウザから利用可能。ローカルでのASR実行にはGPUが事実上必要。
Q. 商用利用は可能か。ライセンスはどうなっているか? MITライセンスのため商用利用は明示的に許可されており、著作権表示の帰属が必須条件だ。ただし公式READMEには「追加テスト・開発なしでの商用利用は非推奨」と明記されている。ベースモデルのQwen2.5由来のバイアスも継承するため、本番導入前に対象ドメインでの品質検証が必要。Microsoftの特許ポートフォリオについては、大規模利用の場合に別途確認を推奨する。
Q. Google CloudやAmazon TranscribeなどのクラウドASR APIと精度は同等か? 公式ベンチマーク(MLC-Challenge・AISHELL-4・AMI)ではクラウドAPIと競合するレベルの精度を示している。特に60分一括処理と話者分離の組み合わせは、チャンク処理が前提の既存クラウドAPIが苦手とする領域で優位性を持つ。ただしファインチューニングなしの比較のため、専門ドメインデータでの追加学習で精度向上の余地がある。雑音・方言・コードスイッチングが多い実収音環境での検証は別途実施してほしい。
関連記事: LLMとは?仕組みからローカル実行まで徹底解説【2026年完全ガイド】