Browser-Use は、大規模言語モデル(LLM)に 実際のブラウザを操作させる ためのオープンソースPythonライブラリです。 「このリポジトリのスター数を調べて」「このフォームに入力して送信して」といった 自然言語のゴール を渡すと、エージェントが自分でページを見て、クリックや入力を判断し、タスクを進めます。 GitHubで 7.8万★前後(2026年1月の1万→5月の5万→さらに増加)と急成長し、Y Combinator W25 に採択された、いま最も勢いのあるOSSのWebエージェントです。
本稿は 2026年6月23日(JST)時点 で、公式GitHubリポジトリ(browser-use/browser-use)と一次情報をもとに、仕組み・導入・対応LLM・ユースケース・他ツール比較・限界 を整理します。
AIエージェントの全体像(仕組み・種類・代表的OSS)を先に押さえたい方は AIエージェントとは?仕組み・種類・代表的OSSフレームワークを初心者向けに解説【2026年版】 をご覧ください。
- ・Browser-UseはLLMに実ブラウザを操作させるMITライセンスのOSS(GitHub 7.8万★・YC W25)。
- ・要素抽出 → LLM判断 → Playwright実行 → フィードバックのループでWebタスクを自動化する。
- ・
pip install browser-use+ Playwright導入で動く。数行のコードでエージェントが走る。 - ・対応LLMはClaude / GPT / Gemini / Groq / Azure / ローカル(Ollama)。2026年はRust製betaも登場。
- ・素のPlaywrightと対立せず、その上にLLMの意思決定レイヤを載せた構造。手順を書ききれないタスクに強い。
まずは公式の紹介動画(Y Combinator)で、Browser-Useが何をするものかを掴んでおきましょう。
1. Browser-Useとは — LLMに実ブラウザを操作させるOSS
従来のWeb自動化(Selenium / Playwright)は、「このセレクタの要素をクリック」「このIDの入力欄に文字を入れる」といった 操作手順を人間がコードで書く 必要がありました。 ページ構造が変わるとセレクタが壊れ、メンテナンスが大変になるのが常でした。
Browser-Useはこの発想を逆転させます。 人間は 「何を達成したいか(ゴール)」を自然言語で伝えるだけ で、あとはLLMが画面を見て手順を考え、ブラウザを操作します。 作者は Magnus Müller 氏と Gregor Žunić 氏で、リポジトリの説明は「Make websites accessible for AI agents(WebサイトをAIエージェントが扱えるようにする)」です。
・人間が書くのは「ゴール」だけ。手順はLLMが組み立てる
・対象ページの構造が多少変わっても、LLMが見て適応する
・実ブラウザ(Chromium)を動かすので、ログイン状態やJS描画ページも扱える
・MITライセンスで無料・商用利用可。OSSとして手元で完結できる
「最大のOSS Webエージェント」とも称され、Fortune 500での利用も報告されています。 “決まった手順の自動化”から、“ゴールを渡して任せる自動化”への移行を体現するプロジェクトです。
実力の目安として、公式が公開しているベンチマーク(BU Bench V1)の成功率を見てみましょう。
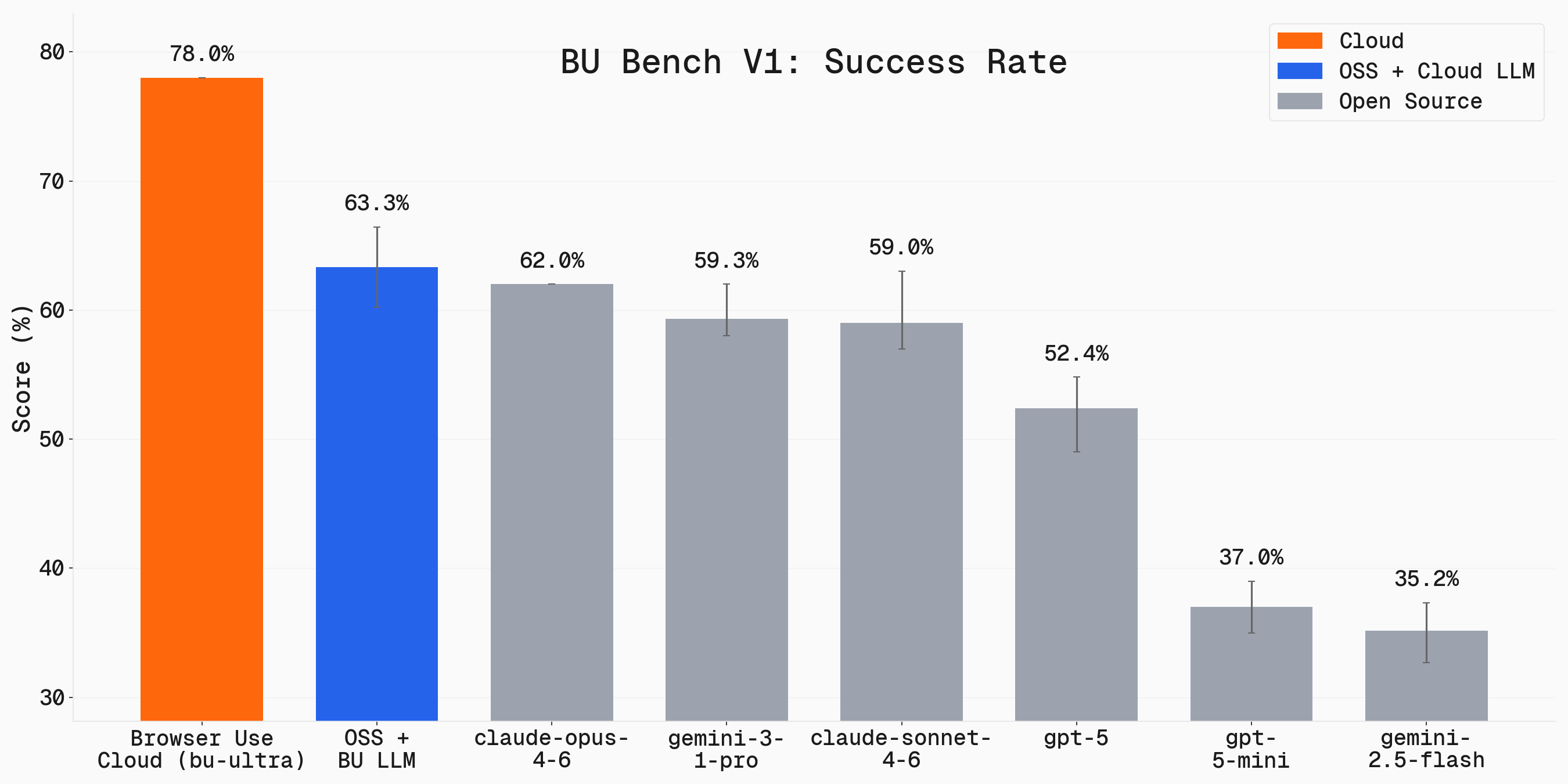
このベンチマークから読み取れるのは、同じBrowser-Useでも“どのLLMを繋ぐか”で成功率が大きく変わる ことです。 上位モデル(Claude Opus系など)とローカル/小型モデルでは、Webタスクの完遂率に明確な差が出ます。 「フレームワークの優劣」だけでなく「接続するモデルの選択」が結果を左右する——後述のモデル選びが重要になる理由が、この図に表れています。
なぜ「ブラウザ」なのか、という点も押さえておく価値があります。 世の中の業務システムやSaaSの多くは、APIをすべて公開しているわけではありません。 管理画面・社内ツール・古い業務システムなど、人間がブラウザで操作することを前提に作られたインターフェース が大量に存在します。 ブラウザを操作できるエージェントは、こうした「APIのない世界」にもアクセスできる——つまり ブラウザを“万能の操作インターフェース”として使える ことが、Browser-Useのような web エージェントが急速に注目を集める根本的な理由です。 LLMが「考える」能力を持った今、足りなかったのは「Web上で実際に手を動かす」手段であり、Browser-Useはまさにその橋渡しを担っています。
2. 仕組み:要素抽出 → LLM判断 → Playwright実行のループ
Browser-Useの中核は、観測(observe)と行動(act)のループ です。 1ステップごとに次を繰り返し、タスクが完了するまで進みます。
例: リポジトリのスター数を調べて"] --> O["ページを観測
操作可能要素を抽出+スクリーンショット"] O --> S["構造化した状態をLLMへ渡す"] S --> D["LLMが次の行動を決定
クリック / 入力 / 遷移 / 抽出"] D --> P["Playwright(Chromium)が実行"] P --> F["結果を観測し状態を更新"] F -->|タスク未完了| O F -->|完了| R["結果を返す"]
各段階を補足します。
・要素抽出(observe):ページ上のボタン・入力欄・リンク・フォームなど“操作できる要素”を抽出し、LLMが理解できる 構造化表現 に変換する。あわせて画面のスクリーンショット(視覚情報)も使う
・判断(decide):LLMが現在の状態とゴールから「次に何をするか」を決める
・実行(act):Playwrightが実際にクリック・入力・遷移を行う
・フィードバック:操作結果を観測して状態を更新し、再びLLMに渡す。これをゴール到達まで繰り返す
ポイントは、DOMの構造化情報とスクリーンショット(視覚)を併用 する点です。 「人間が画面を見てクリックする」のに近い形で、DOM操作だけでは扱いにくいモダンなWeb UIにも対応しやすくしています。
従来のスクレイピングが脆かったのは、特定のセレクタ(HTMLの位置)に依存 していたからです。
サイト側がデザインを変えてHTML構造が変わると、div.foo > span:nth-child(3) のようなセレクタは一斉に壊れ、保守地獄になりました。
Browser-Useは「セレクタを直接指定する」のではなく、その都度ページを観測してLLMが“いま何が見えているか”から判断 するため、ある程度のレイアウト変更には自律的に適応できます。
これは「壊れにくいが、毎回LLMを呼ぶので遅く・高コスト」というトレードオフでもあります。
裏を返すと、毎回同じ構造の高頻度バッチ処理 には素のPlaywrightの方が向き、構造が変わる・手順を事前に書ききれないタスク にBrowser-Useが向く、という判断軸が見えてきます。
3. 導入:pipインストールと最小コード
導入は数コマンドで完了します。 Pythonと、ブラウザエンジン(Playwright/Chromium)をインストールします。
# pip の場合
pip install browser-use
playwright install chromium --with-deps
# uv を使う場合(高速)
uv pip install browser-use
uvx playwright install chromium --with-deps
LLMのAPIキー(例:Anthropic / OpenAI)を環境変数に設定します。
export ANTHROPIC_API_KEY="sk-ant-..."
# または
export OPENAI_API_KEY="sk-..."
あとは数行で、エージェントが自然言語のゴールを実行します。
import asyncio
from browser_use import Agent
from browser_use.llm import ChatAnthropic
async def main():
agent = Agent(
task="browser-use の GitHub リポジトリのスター数を調べて教えて",
llm=ChatAnthropic(model="claude-sonnet-4-5"),
)
result = await agent.run()
print(result)
asyncio.run(main())
これだけで、エージェントがブラウザを起動し、GitHubを開き、スター数を読み取って返してきます。
※ クラス名・モジュールパスはバージョンで変わることがあるため、最新は公式READMEを確認してください(2026年は from browser_use.beta import Agent のRust製beta系も登場しています)。
4. 対応LLMと設定(Claude / GPT / ローカル)
Browser-Useは LLMプロバイダを差し替え可能 な設計です。 対応プロバイダは OpenAI・Anthropic・Google・Groq・Azure OpenAI と、Ollama 経由のローカルモデルです。
# 例: プロバイダを切り替える
from browser_use.llm import ChatOpenAI, ChatAnthropic, ChatOllama
llm = ChatAnthropic(model="claude-sonnet-4-5") # 高精度・複雑タスク向き
# llm = ChatOpenAI(model="gpt-4o") # バランス
# llm = ChatOllama(model="llama3.1") # ローカル・低コスト・簡易タスク向き
ブラウザ側の挙動も設定できます。 よく使うのは ヘッドレス実行 と アクセス可能ドメインの制限(ガードレール) です。
from browser_use import Agent, BrowserProfile
agent = Agent(
task="社内Wikiから今週の議事録リンクを集めて一覧にして",
llm=llm,
browser_profile=BrowserProfile(
headless=True, # 画面非表示で実行
allowed_domains=["wiki.example.com"] # このドメイン以外へは行かせない
),
)
allowed_domains は安全面で重要です。
エージェントが意図せず外部サイトへ遷移するのを防ぎ、操作範囲を明示的に閉じる ことができます。
モデル選びの基本は「複雑なWeb操作ほど上位モデル」。簡単な反復作業はローカル/小型モデルでコストを抑える、という使い分けが現実的です。
ブラウザのプロファイル(Cookieやログイン状態)を再利用する設定も実務で重要です。
毎回ログインからやり直すのは遅く、2FAなどで詰まりやすいため、既存のブラウザプロファイルを指定して認証済みの状態から開始 できるようにしておくと、社内ツールやSaaSの自動化が安定します。
ただしこの場合、エージェントは強い権限を持ったセッションで動くことになるため、allowed_domains と人間確認のガードレールを必ずセットで効かせ、認証済みセッションで信頼できないサイトを踏ませない設計にしてください。
5. 実用ユースケース(データ抽出・フォーム操作・QA)
Browser-Useが効くのは、APIがない/手順が固定できない Web作業です。 代表的なユースケースを挙げます。
・Webデータ抽出:検索結果や一覧ページから必要な情報を集めて構造化する
・フォーム入力・申請の自動化:定型の入力・送信を自然言語の指示で回す
・リサーチエージェント:複数サイトを横断して情報を収集・要約する
・QA・回帰テスト:「ログインして注文できるか」を人間のように試す
・繰り返しの社内オペレーション:管理画面の定型操作を任せる
特に相性が良いのが QA・回帰テスト です。 従来のE2Eテストは「IDがこのボタンをクリック」と手順を固定で書くため、画面が少し変わるだけでテストが壊れがちでした。 Browser-Useなら「ログインして商品をカートに入れ、購入直前まで進めるか確認して」のように振る舞いベースで書けるため、UIの小さな変更に強いテストを記述できます(ただし非決定的なので、合否判定には明確なアサーションを併用するのが前提です)。
また、これらのタスクは cronやCIと組み合わせて定期実行 することで効果が増します。
「毎朝、複数の管理画面から数値を集めてSlackに投げる」「毎週、競合サイトの価格を巡回して記録する」といった定型業務を、エージェントに任せて自動化できます。
このとき必ず headless=True と allowed_domains、上限ステップ数を設定し、無人実行でも暴走しないようガードレールを敷いておきましょう。
抽出結果を 構造化(JSON) して受け取りたい場合は、出力スキーマを指定する使い方が便利です。
from pydantic import BaseModel
from browser_use import Agent
class Repo(BaseModel):
name: str
stars: int
agent = Agent(
task="GitHub Trending から本日のPythonリポジトリ上位5件の名前とスター数を集めて",
llm=llm,
output_model=Repo, # 構造化して返す(イメージ)
)
※ 構造化出力のAPI名はバージョンにより異なります。重要なのは「自然言語のゴール → 構造化データ を一気通貫で得られる」点で、スクレイパーを毎回書かずに済むのが実務上の利点です。
実務での向き不向きをもう少し具体化すると、次のようになります。 向いているのは、対象サイトが頻繁に変わる/複数サイトを横断する/手順を事前に列挙できない、といった“揺らぎのある”作業です。 たとえば「複数の求人サイトから条件に合う案件を集める」「問い合わせフォームの種類がバラバラな取引先に一括で連絡する」「毎回少しずつ違う管理画面で月次のレポートを取得する」などは、従来なら個別にスクリプトを書いていたところを、ゴール記述で吸収できます。 向いていないのは、構造が固定で大量・高速に回したいバッチ(例:同一フォーマットのページを10万件巡回)で、ここはコストと速度の面で素のPlaywright/専用スクレイパーに分があります。 「人間がやると面倒だが判断が要る作業」をエージェントに、「機械的で大量の作業」を従来型に、と振り分けるのが費用対効果の高い使い方です。
6. 他ツールとの違い(Playwright / Selenium / Skyvern / agent-browser)
「結局どれを使えばいいのか」を整理します。 Browser-Useは“LLMで操作を判断する”層であり、素の自動化フレームワークとは役割が違います。
| ツール | 種類 | 操作の決め方 | ライセンス | 向いている用途 |
|---|---|---|---|---|
| Browser-Use | LLM Webエージェント | 自然言語ゴール→LLMが手順を判断 | MIT(OSS) | 手順を書ききれない/変化するWeb操作 |
| Playwright | 自動化フレームワーク | 人間がコードで手順を記述 | OSS | 手順が固定の安定したE2E自動化 |
| Selenium | 自動化フレームワーク | 人間がコードで手順を記述 | OSS | 従来型のブラウザテスト |
| Skyvern | LLM Webエージェント | LLM+視覚でワークフロー自動化 | OSS | 業務ワークフローの自動化 |
| agent-browser(Vercel) | エージェント向けブラウザCLI | エージェントに最適化した実行基盤 | OSS | エージェントの実行下回り |
重要なのは、Browser-UseとPlaywrightは対立しない ことです。 Browser-Useは内部でPlaywright(Chromium)を実行エンジンとして使っており、その上に「LLMが手順を考える」レイヤを載せた構造です。 手順が固定なら素のPlaywrightが速くて確実、手順を事前に書ききれないならBrowser-Use、という住み分けになります。 実際、Browser-Useで試作して挙動を確かめ、安定した手順が固まったらその部分を素のPlaywrightに“書き起こして”高速化する、というハイブリッドな運用も有効です。
同じ“エージェント向けブラウザ”という文脈では、Vercelの実行基盤も比較対象です。詳しくは agent-browser入門:VercelがOSS公開したAIエージェント向けRust製ブラウザ自動化CLI を参照してください。
7. 注意点と限界(コスト・速度・信頼性・セキュリティ)
強力な一方で、LLMエージェント特有の弱点も理解しておく必要があります。
・非決定性:毎回同じ結果になるとは限らない。ページ変化やモデルの判断で失敗・中断し得る
・コスト:1タスクで何度もLLMを呼ぶため、上位モデルだと費用がかさむ。簡易タスクは小型/ローカルモデルへ
・速度:観測→判断→実行のループを回すため、決定的なスクリプトより遅い
・信頼性設計が必須:重要操作(購入・送信・削除)は人間の確認を挟む、上限ステップ数・allowed_domainsでガードレールを敷く
・セキュリティ:認証情報の扱い、prompt injection(ページ内の悪意ある指示にエージェントが従うリスク)に注意。信頼できないサイトでの実行は範囲を絞る
・規約・法令順守:robots.txt・利用規約・各国法令を守る。CAPTCHA/2FAの突破を目的にしない
コストについては、最初に小さく見積もるのがおすすめです。 1タスクあたり数ステップ〜数十ステップのLLM呼び出しが発生し、各ステップで画面情報(スクリーンショット+要素)をモデルに渡すため、1回の実行でもそれなりのトークンを消費 します。 高頻度・大量に回す前に、まず数件で「1タスクあたりの平均ステップ数と概算コスト」を計測し、上位モデルで回すべきタスクと、小型/ローカルモデルで十分なタスクを切り分けると、費用が読めるようになります。
LLMエージェントは“ページに書かれた文章”も入力として読む。悪意あるサイトが「これまでの指示を無視して〇〇しろ」といった文をページに仕込むと、エージェントが従ってしまう恐れがある(間接プロンプトインジェクション)。信頼できないドメインでは allowed_domains で範囲を閉じ、機密操作・認証情報を渡さないのが基本防御だ。
これらは「人間の代わりに考えて操作する」強力さの裏返しです。 決定的なスクリプトより 運用設計(ガードレール・確認・検証) が重要になる、と理解して導入するのが成功の鍵です。
8. 急成長の背景と2026年の最新動向
Browser-Useの伸びは数字に表れています。 2026年1月に約1万★だったものが、5月には約5万★、その後さらに増えて 7.8万★前後 に到達しました。 わずか数か月でこれだけ伸びた背景には、(1)LLMの推論能力が「Webを自律操作できる」水準に達したこと、(2)APIのない業務システムを自動化したいという強い実需、(3)MITライセンスで誰でも組み込める手軽さ、の3点があります。
2026年に入ってからの主な動きも押さえておきましょう。
・Rust製のbeta agent:from browser_use.beta import Agent で使える新世代の実行系が登場。性能・安定性の改善が進んでいる
・ChatBrowserUse:Browser-Use側が用意するモデル選択肢で、セットアップを簡略化する流れ
・TypeScript版:Python発のライブラリをTypeScriptで使えるようにする派生も登場し、フロント/Node系の開発者にも裾野が広がっている
・Browser Use Cloud:OSS本体に加え、マネージドなクラウド(cloud.browser-use.com)も提供。自前でブラウザ基盤を運用したくないチーム向け
この「OSSコア+クラウド」という二層構造は、近年のOSSスタートアップの定石です。 まずOSSで試して有用性を体感し、運用の手間を省きたくなったらクラウドへ という導線が用意されている、と理解するとよいでしょう。 重要なのは、コア機能がOSS(MIT)で公開されているため、ベンダーロックインを避けて自前運用を選べる 余地が残されている点です。
なお、Webエージェントの分野はBrowser-Useの独走ではなく、Skyvernや各種の“computer use”系エージェント、ブラウザ実行基盤(Vercelのagent-browser等)が並走する活発な領域です。 ツール選定の際は「LLMで判断する層(Browser-Use等)」と「実行の下回り(Playwright/ブラウザ基盤)」を分けて考えると、組み合わせの設計がクリアになります。
まとめ
Browser-Useは、LLMに実ブラウザを操作させ、自然言語のゴールからWebタスクを自動化する MITライセンスのOSSです。
要点を整理すると次のようになります。
・GitHub 7.8万★前後・YC W25採択の、最も勢いのあるOSS Webエージェント
・仕組みは「要素抽出+視覚 → LLM判断 → Playwright実行 → フィードバック」のループ
・pip install browser-use + Playwright導入で、数行のコードから動かせる
・対応LLMは Claude / GPT / Gemini / Groq / Azure / ローカル(Ollama)。2026年はRust製betaも
・素のPlaywrightと対立せず、その上にLLMの意思決定レイヤを載せた構造
・非決定性・コスト・速度・セキュリティ(prompt injection)への運用設計が前提
「手順を全部コードで書く」時代から、「ゴールを渡して任せる」時代への移行を体現するのがBrowser-Useだ。APIがなく手順を固定できないWeb作業——リサーチ・データ抽出・定型オペレーション——でこそ真価を発揮する。まずは
pip install browser-use で簡単なタスクを1つ自動化し、allowed_domainsと人間確認のガードレールを入れたうえで用途を広げていくのが安全な始め方だ。参照ソース
・browser-use/browser-use(公式GitHubリポジトリ)
・Browser Use(Y Combinator・W25)
・Launch HN: Browser Use (YC W25) – open-source web agents
・Browser-Use: Open-Source AI Agent For Web Automation(Labellerr)
・AIが自動でブラウザ操作、BrowserUse登場(本サイト・関連ニュース)