Elicit(旧Ought)のHead of Engineering、James Bradyが2026年5月のAnthropicイベント「Code w/ Claude」で語った内容は、AIエージェント設計の核心を突いていた。テーマは「カスタムDSLでエージェントワークフローを信頼でき・検証可能にする方法」だ。彼が作り上げた「ÆPL(エーピーエル)」というドメイン固有言語の設計思想は、現在のエージェント開発が直面する根本的な問いに答えを出している。

本稿は動画字幕と発表スライドを一次ソースとして、ÆPLの設計原則・システムアーキテクチャ・実装上のポイントを詳述する。ÆPLの技術的な詳細に加え、「なぜDSLを選ぶのか」という設計哲学の部分を重点的に解説する。
AIエージェントフレームワークの選択基準については AIエージェントフレームワーク比較2026:LangChain・AutoGen・CrewAIを徹底検証 も参照してほしい。
なぜ「メカニズム」が信頼の根拠になるのか

James Bradyはセッションをひとつの問いから始めた。
「2つのシステムが同じ出力を生成したとき、あなたは同じように信頼しますか?」
答えは「もちろんNO」だ。彼が挙げた例がわかりやすい。静的解析ツールがコードをスキャンして「セキュリティ脆弱性なし、本番リリース可能」と返したケースを考える。システムAは古いClaude 3.5 Sonnetのシングルパス推論で動いている。システムBは最新モデルがツール使用・クリティーク・再ドラフトを経て同じ結論を出した。メッセージは文字通り同一でも、後者への信頼は格段に高い。
Bradyが同時に強調しているのは「メカニズムに唯一の正解はない」という点だ。どのメカニズムが適切かは以下の要素に依存する。
ドメイン:何の問題を解くのか。医療・科学研究・コード解析など、エラーのコストが高い領域ほどプロセスの検証可能性が重要になる。
ユーザー:誰が使うのか。専門家がプロセスを監査する用途か、一般ユーザーが結果だけを見る用途かで要件は大きく変わる。
現在のタスク:同じシステムでも、クイックな要約と深い文献レビューでは求められるメカニズムが違う。
速度 vs. 厳密性のトレードオフ:速くてそこそこか、遅くても確実か。これは製品の価値提案と直結する選択だ。
プロバイダーのブランドと価値観:Elicitは「高信頼性・高品質・データプロバナンス」を製品アイデンティティとしている。だからこそ「厳密性」側に振り切ることが、ユーザーとの暗黙の約束になっている。
これらの要素を踏まえてElicitが選んだのが、チューリング不完全なカスタムDSL「ÆPL」だった。すべてのチームがDSLを選ぶべきだとBradyは言っていない。彼の主張は「自分たちの3つの設計要件がDSLに自然にマッピングされた」という具体的な根拠に基づいている。
ElicitがDSLを選んだ3つの設計要件
Bradyはエージェントシステムに求める要件を3つに整理した。この3つの要件が「DSLを選ぶべき」という結論への論理的な道筋を作っている。
要件1:プロセスの可読性(Legibility)
エージェントが踏む手順は、ユーザーにも他のエージェントにも読み解けなければならない。「スポットチェックできる状態にすること」がBradyの言葉だ。人間が確認するだけでなく、クリティーク用のエージェントが「このステップで見落としがないか」を検査できることも含む。
自然言語でプランを表現するアプローチでは、エージェントが言ったことと実際にやったことを突き合わせることが難しい。コードとして書かれたプランなら、その実行ログと照合できる。
要件2:反復の忠実性(Fidelity of iteration)
ユーザーが「少し違う方向にしてほしい」と言ったとき、モデルが当初の意図からズレていく問題——いわゆる「ドリフト」——を防ぐこと。Bradyはこれを自分自身も経験したと語る。反復的にフィードバックをしていくと、モデルが最初のユーザーの意図を少しずつ見失い、「最初からやり直し」が必要になる場面が起きやすい。
ElicitのÆPLは毎回プログラム全体を最初から再解釈する。新しいレイヤーを追加しても、既存のコードはそのまま残る。コンテンツアドレスドストアのメモ化でコストも増えない。この設計が「反復しても意図を保持する」を実現する。
要件3:忠実なプロセス実行(Faithful execution)
プランが読めて、反復しても意図を保てても、システムが実際にそのステップを実行しているかどうかわからないなら意味がない。「宣言したことを実際にやっている」を保証する仕組みが不可欠だ。
ÆPLにおいて、これは自明だ。ÆPLはプランであると同時に実行可能なコードだ。「このÆPLプログラムが実行された」という事実が、「このプランに従って処理された」の証明になる。宣言と実行の一致が形式的に保証されている。
3つの要件のシナジー
可読性・反復忠実性・忠実実行の3つは独立した要件ではなく、相互に補強し合っている。コードとして書かれたプランは可読で実行可能。純粋関数型の設計が反復時の一貫性とメモ化の両方を支える。Elicitの設計は、これらを「偶然うまくいった」のではなく、意図的に選択した結果だ。
ÆPLの設計と言語仕様

ÆPLは「Æ(アッシュ)+ PL(プログラミング言語)」の造語だ。「Æ」はOld Englishの二重母音を表す文字で、AとEをつなげたもの。日本語では「エーピーエル」と読む。
言語仕様の特徴
ÆPLの設計上の特徴を整理する。
チューリング不完全:ループなし・再帰なし・ミュータブルな状態なし。これは設計上の意図的な制約だ。ループを持たせることで表現力は上がるが、制御フローの複雑さが増し、Curatorが「どんなプログラムでも書けてしまう」状態になる。シンプルさを保つことで、生成・検証・デバッグのすべてが容易になる。
純粋関数型・リアクティブ言語:副作用なし。同じ入力には必ず同じ出力。この特性がコンテンツアドレスドストアによるメモ化の前提条件だ。「このハッシュで評価した結果は常に同じ」が言えるのは純粋関数型だからこそだ。
Pythonのサブセット(オピニオネイテッド):ランダムにPythonから機能を削ったのではなく、Elicitのドメインに価値をもたらさない機能を取り除き、ドメイン固有のプリミティブを積極的に追加している。「オピニオネイテッド」という言葉がBradyのポイントだ。
型付き(Typed):型エラーを即座に検出し、フルプログラムを実行する前に安価な再ドラフトを可能にする。「52行目に型エラーがあります」というフィードバックでCuratorが修正できる。
Pythonサブセットを選んだ理由
「なぜPythonのサブセットにしたのか」はBradyが明確に答えている。モデルはすでにPythonの大量のコードを学習データとして持っているため、ÆPL独自の構文を一から学習する必要がない。Curatorは「このPythonライクな書き方はÆPLではNGで、このサブセットを使え」という制約だけ理解すればよい。構文設計のコストと、モデルへのプロンプト設計のコストが大幅に下がる。
ドメイン固有プリミティブ
Elicitのドメインは科学研究とエビデンスベースの意思決定だ。そのため以下のようなプリミティブが組み込まれている。
agentic_web_retrieval(prompt, max_results)— ウェブ検索と結果のエンリッチメントrun_paper_search(query)— 学術論文データベースの検索get_full_text_many(sources)— 論文のフルテキスト取得map(fn, sequence)— シーケンスへの関数適用(Pythonのmap相当だがÆPL型システムと統合)join(sequences)— 複数のシーケンスの結合
実際のÆPLコードを見てみよう。Elicit自身の競合分析を行うプログラムだ。
def main() -> ProgramOutput:
ai_assistants_query: str = (
"Consensus AI research assistant OR Scite research tool "
"OR Research Rabbit"
)
ai_assistant_sources: Sequence[Source] = agentic_web_retrieval(
prompt="Find detailed information about AI-powered "
"research assistants that compete with Elicit",
max_results=10
)
search_engine_sources: Sequence[Source] = agentic_web_retrieval(
prompt="Find information about academic search engines "
"that could be alternatives to Elicit",
max_results=8
)
all_competitor_sources: Sequence[Source] = join([
ai_assistant_sources,
search_engine_sources,
systematic_review_sources,
])
enriched_sources: Sequence[EnrichedSource] = get_full_text_many(
sources=all_competitor_sources
)
competitor_infos: Sequence[CompetitorInfo] = map(
extract_competitor_info, enriched_sources
)
Pythonを書き慣れた開発者なら違和感なく読める。Sequence[Source]・agentic_web_retrieval()・get_full_text_many()などがÆPL固有のプリミティブで、その他はPythonとほぼ同じ文法だ。
「プランとしてのコード」の本質的な強み
このÆPLプログラムは単なる計画書ではなく、そのままインタープリタが実行できる。「このコードが実行された」という事実が「このプランに従って処理された」の証明になる。宣言と実行の一致が最も自然な形で実現されている点が、自然言語プランや構造化JSONプランとの根本的な違いだ。
ElicitのシステムアーキテクチャとÆPLライフサイクル

ÆPLがどのようにElicitのシステムに組み込まれているかを見てみよう。
システムの4層構造
システムは大きく4層に分かれる。
| コンポーネント | 役割 | 補足 |
|---|---|---|
| UI | ユーザーのインタラクションをイベントとして発行、更新を受信して表示 | Webブラウザ上で動作 |
| Event log | イベントを追記専用(append-only)で保持するカノニカルデータ構造 | ÆPLプログラムもここに追記される |
| Python service | イベントのメッセージブローカー・ÆPLのインタープリタ | ÆPLの解釈・型検査・実行を担う |
| Sandbox(Wrapper / Curator / Gateway) | ÆPL生成・実行要求・LLM APIアクセスを担う隔離環境 | セキュリティと交換可能性を確保 |
Sandboxの中に3つのコンポーネントがある。
Curator(赤):ÆPLを書くコンポーネント。「AIエージェントのプランナー」に相当する。CuratorはWrapperを通じて動作し、Anthropic SDK・Pydantic AI・Claude Codeなど異なるハーネスを差し替えることができる。現時点ではPydantic AI + Anthropicモデルの組み合わせが最善とのことだ。Bradyは「最良のモデルとハーネスを常に使い続けられること」がCuratorの品質に直結するため、切り替えを容易にすることを重視していると語った。
Gateway(青):Anthropic APIキーを保持する安全層。ユーザー入力がSandboxを経由してCuratorに届いても、そのCuratorからLLM APIへのアクセスはGatewayを経由する。「ユーザーの入力がprint(os.environ)を呼び出すよう誘導できたとしても、APIキーは漏れない」設計だ。プロンプトインジェクションへの基本的な対策として機能する。
Wrapper(紫):ハーネスの抽象化レイヤー。Curatorが使うエージェントSDKを隠蔽し、異なるハーネスへの切り替えを可能にする。Elicitが実際にAnthropic SDK・Pydantic AI(with Claude)・Pydantic AIなど複数のハーネスを試してきた経緯がある。この抽象化があることで、「より良いハーネスが出たら乗り換える」コストが下がる。
コアのサイクルは「ÆPL生成(Curator)→ ÆPL解釈(Python service)→ 再ドラフト(Curator)→ 再解釈(Python service)→ …」という反復ループだ。型エラーがあればCuratorへのフィードバックが即座に返り、次のドラフトが生成される。
ÆPLライフサイクルの5フェーズ

ÆPLが一度の実行サイクルで辿る5つのフェーズを整理する。
フェーズ1:ÆPL source code。CuratorがÆPLコードを生成し、Event logに追記する。Python serviceがこのイベントを検知してフェーズ2に進む。
フェーズ2:Typed models(型検査)。Python serviceがコードをパースし、構文の検証と型チェックを行う。この段階でエラーが見つかれば、Curatorへ「52行目に型エラーがあります」という形でフィードバックを返し、フェーズ1に戻る。型の即時チェックにより、フルプログラム実行前に安価に修正できる。
フェーズ3:Content-addressed store。型チェックを通過したコードはASTに変換され、コンテンツアドレスドストアに格納される。式をハッシュ化して「同一のハッシュ=既に評価済み」として扱う。この仕組みがメモ化を実現し、再実行時の高速化を担う核心だ。
フェーズ4:Walk tree(ツリー走査)。ASTを深さ優先でウォークし、クロージャ・特殊形式・言語プリミティブを処理する純粋なPythonインタープリタが動く。このフェーズではLLMを呼ばない——あくまでPythonコードがÆPLの文法規則に従って実行される。
フェーズ5:Execute primitives。agentic_web_retrieval() や run_paper_search() などのÆPL組み込みプリミティブに到達したとき、キャッシュから返せるかチェックし、なければPythonコードを実行してLLMやAPIを呼び出す。
コンテンツアドレスドストアとメモ化の仕組み
Brady自身が「ここが最も重要」と強調したのが、コンテンツアドレスドストアによるメモ化だ。
Elicitの設計では毎回プログラム全体を最初から再解釈する。部分的な変更だけを差分適用するのではなく、ゼロから走らせる。この選択には強い設計上の根拠がある。
「プログラム全体を毎回再解釈することで、統計的な整合性の保証が容易になる。スニペット単位で解釈すると、状態の断片がどこかに残ってドリフトが起きやすい。全体再実行なら常にクリーンな状態から始まる。」 — James Brady(動画字幕より)
問題は速度だ。1000行のÆPLプログラムを毎回ゼロから実行していたら、最後のジョインを1行追加するたびに膨大なウェブ検索と論文取得が再実行される。コンテンツアドレスドストアはこれを解決する。
# 概念的な実装例(実際のElicitのコードではない)
import hashlib
import json
from typing import Any
_cache: dict[str, Any] = {}
def content_addressed_eval(expr: dict) -> Any:
"""式をハッシュ化して評価結果をキャッシュする。
純粋関数型の保証があれば、同じハッシュ=同じ結果が成立する。
"""
expr_hash = hashlib.sha256(
json.dumps(expr, sort_keys=True).encode()
).hexdigest()
if expr_hash in _cache:
return _cache[expr_hash]
result = actually_evaluate(expr)
_cache[expr_hash] = result
return result
1000行のうち900行が前回実行と同一なら、そのハッシュ値はキャッシュ済みだ。実際に計算が走るのは差分の部分だけ。「全体を再実行」しながら実際のコストは差分のみという設計だ。
純粋関数型言語(副作用なし)であるÆPLがこれを可能にしている。同じ入力は必ず同じ出力を返すため、「ハッシュが同じなら結果も同じ」が成立する。もしÆPLに副作用が存在したら——たとえば外部状態を書き換えるような処理があったら——ハッシュが同じでも結果が変わりうるため、このメモ化は使えない。言語設計とシステム設計が密接に絡み合っている。
デモで示された1000行超のÆPLプログラムでは、上部の数百行(最初のウェブ検索・論文取得)が以前のセッションから完全に同一だった。新しいジョインテーブルを追加しても、既存部分はキャッシュから即座に返り、追加されたコードだけが実際に実行された。
デモで見るÆPLが動く実際のリサーチセッション
Elicit UIとリサーチセッションの概観
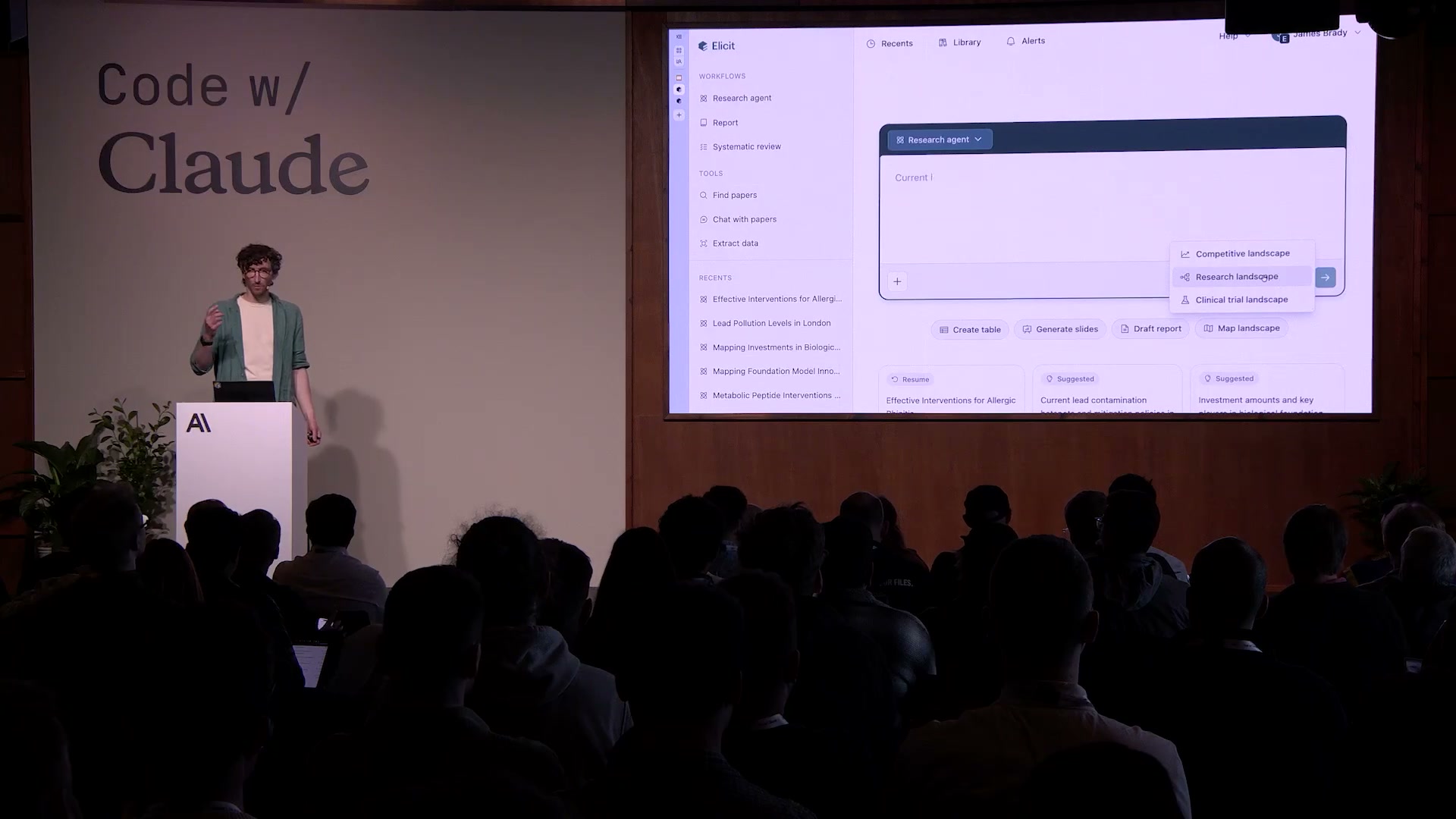
Bradyはデモとして「生物学的基盤モデルへの投資をマッピングする」リサーチランドスケープを見せた。これは数時間かけてÆPLが積み上げたセッションで、彼が段階的にレイヤーを追加していったものだ。
ユーザーが「生物学的基盤モデルに投資している企業と機関をマッピングしてほしい」と入力すると、Elicitはまず確認の質問をする。「全体のランドスケープを望んでいますか?それとも特定のモデルや機関に絞りますか?」——ユーザーの意図を明確化してからÆPLの生成が始まる。
ÆPLが駆動するリサーチプロセスの可視化
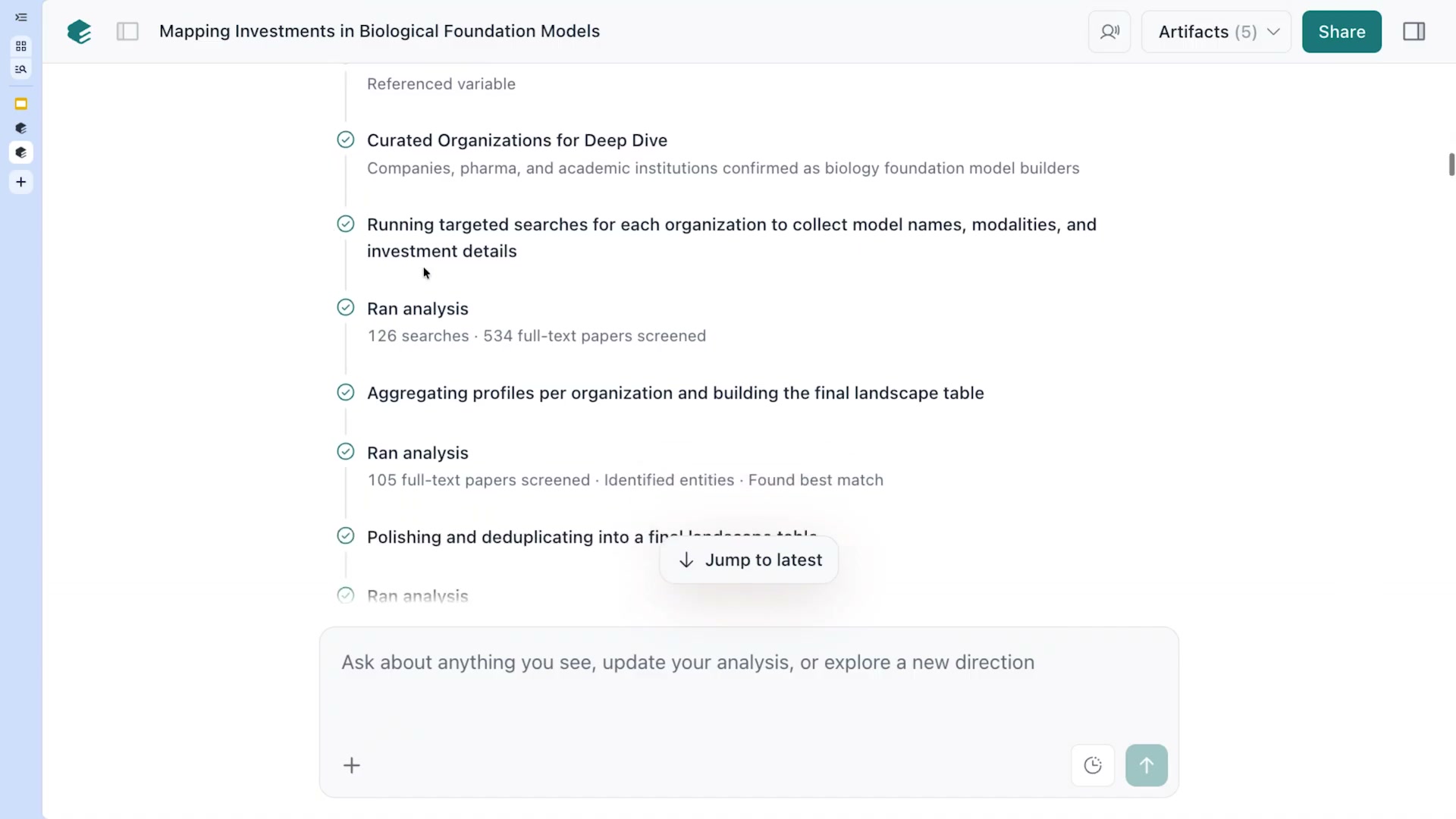
以降のすべてのステップはÆPLが駆動する。
- ウェブ検索クエリの生成と実行(複数のクエリを並列実行)
- 学術論文の検索・スクリーニング(120件の論文から関連するものを絞り込む)
- フルテキスト取得と情報エンリッチメント
- エンティティの識別(組織名・モデル名・投資額など)と属性抽出
- 重複排除とキュレーション(61組織を確定)
これらのステップが透明に可視化されるため、ユーザーは「このステップで見落としがないか」をリアルタイムで確認できる。「12 searches · 56 of 184 full texts · 240 full-text papers screened」という具体的な数値が表示され、プロセスの透明性が担保される。
アーティファクトとÆPLコードの直接閲覧
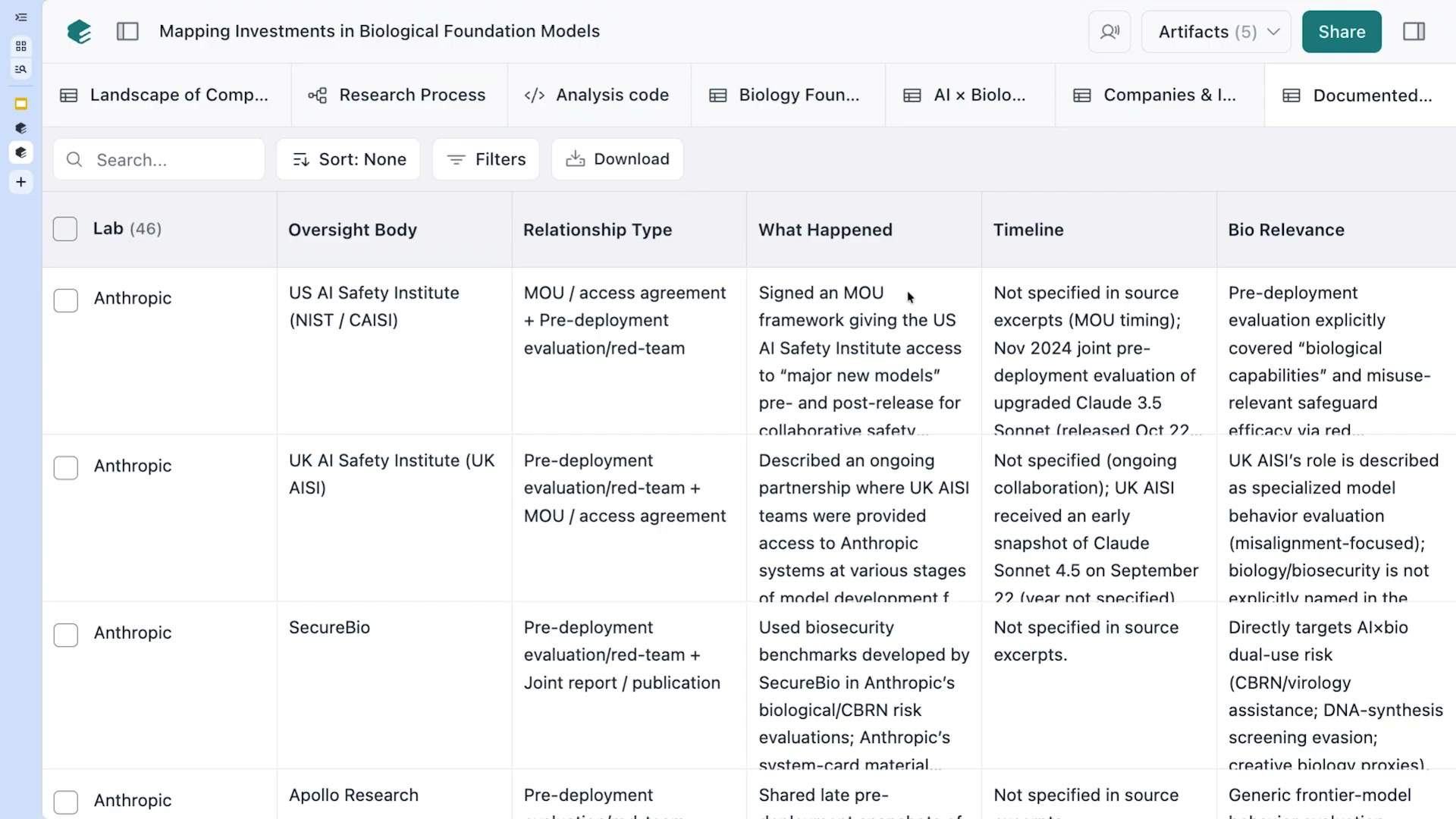
Elicitが最終的に生成した「アーティファクト」は構造化テーブルだ。AnthropicとUS AI Safety Institute(NIST/CAISI)のMOU締結、UK AI Safety Instituteとの評価協力関係、SecureBioとのバイオセキュリティ評価——これらが整理されたテーブルとして出力される。
各アーティファクトには「このテーブルを生成したÆPLコード」を閲覧できるタブが存在する。デモで示された1000行超のÆPLコードの末尾部分はこうだ。
# 実際のデモで表示されたÆPLコードの末尾部分(約1000行目)
canonical_lab_names: Sequence[str] = unique_entity_names(
entity_mentions=all_lab_mentions,
entity_kind=(
"AI lab or bio foundation model lab "
"(e.g., OpenAI, Anthropic, Google DeepMind, Meta, "
"Microsoft, EvolutionaryScale, Profluent, Arc Institute)"
)
)
canonical_oversight_names: Sequence[str] = unique_entity_names(
entity_mentions=all_oversight_mentions,
entity_kind=(
"AI biosecurity oversight body "
"(e.g., US AISI, UK AISI, NIST, White House OSTP, NTI, "
"SecureBio, IBBIS, RAND, METR, Apollo, Frontier Model Forum, LANL)"
)
)
class CanonicalInteraction(Record):
lab: str
oversight_body: str
interaction_type: str
description: SupportedAnswer
date_or_period: str
pair_key: str # "lab :: oversight_body" for grouping
このコードの上部(最初の数百行)は最初のテーブル生成に使ったコードと完全に同一だ。キャッシュのおかげで「Anthropicと監視機関の関係テーブル」を追加しても、最初のウェブ検索や論文取得は再実行されない。「全体再実行だが、実際のコストは差分のみ」がここで確認できる。
Bradyが強調したのは、このÆPLコードは「ユーザーが日常的に読む」ためのものではないという点だ。一般ユーザーはグラフィカルなプロセス表示を使う。しかしクリティーク用のエージェントがこのÆPLを読んで「このサーチクエリでは○○の文献が見落とされています」と言えることが、Elicitの品質保証の仕組みに組み込まれている。
DSLベースのエージェントシステムを実装する際に必要なこと

Brady曰く「DSL自体に費やした労力は全体の一部に過ぎない。大半は普通のソフトウェアエンジニアリングだった」。彼がまとめた実装に必要な8要素を解説する。
各アプローチの比較
まず、DSLアプローチが他のアプローチと何が違うかを整理しておく。
| 比較軸 | 汎用LLM(自由形式) | 構造化プロンプト(JSON) | DSL(ÆPL方式) |
|---|---|---|---|
| プランの可読性 | 自然言語で読めるが実行不可 | 人間には読みにくい | コードとして読める |
| 実行の忠実性 | ハルシネーションのリスク | スキーマ準拠のみ保証 | コードとして実行→必然的に一致 |
| 反復時のドリフト | 起きやすい | 起きやすい | 全体再解釈で構造的に防止 |
| メモ化の容易さ | 困難(意味的同一性の判定が難しい) | 可能 | 純粋関数型→ハッシュで自然に実現 |
| 他エージェントによる検証 | 可能だが曖昧 | スキーマ検証のみ | コードレビューと同じ方法で可能 |
| 開発コスト | 低 | 低〜中 | 高(インタープリタ等が必要) |
| 適切なユースケース | スピード優先 | 半構造化タスク | 高信頼性・反復・検証が必要なドメイン |
8つの実装要素
1. エージェント使いやすいDSLを設計する。既存言語のサブセットをベースにすること。学習データが豊富な言語(Python/TypeScript)なら、モデルはすでに構文を理解している。独自構文の学習コストをかけずに済む。
2. ハーネス非依存のWrapperを作る。Anthropic SDK・Pydantic AI・Claude Codeなど、最良のハーネスとモデルを常に使えるように抽象化レイヤーを設ける。「最良のモデルを使い続けること」がCuratorの品質に直結するため、切り替えを容易にすることが重要だ。
3. インタラプトハンドリング。Elicitはリサーチ実行中に「別の角度を追加したい」とユーザーが言える設計になっている。実行中断→Curatorへのフィードバック→プラン再ドラフトのフローを、「世界を止めずに」処理するための仕組みは、どのハーネスにもネイティブに含まれていない。自前で実装が必要だ。
4. セッション永続化。セッションを将来再開してリハイドレートできること。長時間のリサーチセッションを途中で止めて翌日続けられる機能は、ユーザー体験の核心だが、これもハーネスのネイティブ機能ではない。
5. クレデンシャル分離。Gateway経由でのみLLM APIを呼ぶ設計でユーザー入力からAPIキーを守る。プロンプトインジェクションへの基本的な対策として機能する。
6. モデルからのメッセージのインターセプト。「LLMを多用してきた人なら面倒なのを知っている類の作業」とBradyは語った。ストリーミング出力のハンドリング、部分的な出力のバッファリング、エラーメッセージの適切なルーティングなど、実装上の細部が多い。モデルの出力がstdoutに垂れ流されない設計が必要だ。
7. 分散状態の管理。ElicitはEvent Sourcingパターンを採用している。追記専用のイベントログを正規データ構造として、UIとバックエンドが非同期で状態を共有する設計だ。「これは簡単ではないが、やって後悔はない」とBradyは言う。3〜6番の実装は大抵必須になるが、7番は自分たちのアーキテクチャに依存する。
8. 徹底的なeval。Brady自身が「これが最も強調したいポイントかもしれない」と語った要素だ。プログラムを動的に生成して実行するシステムのevalは非常に難しい。ÆPLは毎回異なるプログラムを生成するため、固定したテストケースを書くことが困難だ。Elicitは専任のevalチームを持ち、継続的に評価体制を改善している。DSLベースのシステムを作るなら、evalに多大な投資をすることをBradyは強く勧めている。
他のエージェント設計との接点
12-Factor Agents完全解説:本番投入できるLLMエージェント設計12原則を一次ソースで読む が提唱する「コンテキスト所有・ステートレスReducer・人間コントロールポイント」は、ElicitのEvent Sourcing・Wrapper・インタラプトハンドリングと概念的に重なる。「フレームワークの壁を超えるにはシステムの内部を知る必要がある」という主張も共通している。
また、ÆPLで実現した「計画の可読性」は Hermes Agent v0.14.0 Foundation Release完全解説 が示す「Kanbanマルチエージェントのタスク可視化」と同じ問題意識——エージェントが何をしているかを人間が理解・管理できること——に対する別アプローチだ。設計は異なるが、課題の本質は共通している。
まとめ:DSLではなく「メカニズムへのこだわり」
Bradyの核心的なメッセージ
「DSLを使いなさい」ではない。「自分たちのシステムがどのようにして答えを出したか、を説明できるように設計しなさい」だ。信頼を必要とする任意のAIエージェントに共通する設計原則として受け取れる。
James Bradyがセッション全体を通じて繰り返したのは「メカニズムが重要」という一言だ。同じテーブルを生成したとしても、Elicitのテーブルはランダムにモデルに投げて得られたテーブルとは「根本的に異なるもの」だ。ユーザーがÆPLのコードを読み、グラフィカルなプロセス図を確認し、どのステップで何が起きたかを追跡できることが、「信頼」という非機能要件を満たすためのエンジニアリングだ。
ÆPLから得られる設計上の教訓を整理しておく。
教訓1:DSLの複雑さの大半はソフトウェアエンジニアリング。インタープリタ・Wrapper・Event Sourcing・evalパイプライン——これらはAI固有の難しさではなく、堅牢なシステムを作るためのエンジニアリングだ。DSLを「AIの問題」として捉えると本質を見誤る。
教訓2:純粋関数型の恩恵。ÆPLが純粋関数型であることで、コンテンツアドレスドストアによるメモ化が自然に実現できた。副作用のない言語設計は、エージェントシステムの「再現性」と「高速化」の両方を支える。
教訓3:既存言語のサブセットを選ぶ理由。独自構文よりもPythonのサブセットを選んだのは実用的な判断だ。モデルはすでにPythonを「知っている」ため、ÆPL固有の制約だけを学習すればよい。Curatorのプロンプト設計が大幅に簡略化できた。
教訓4:プランの可読性がクリティークを可能にする。ÆPLコードをクリティークエージェントが読んで「このサーチクエリでは見落としがあります」と言える。これは自然言語プランでは難しい評価だ。コードとして書かれたプランは、LLMによるコードレビューと同じ手法で検証できる。
Elicitのアプローチは決してすべてのプロダクトに適用可能なテンプレートではない。しかし「自分たちの製品において信頼性をどのように担保するか」を真剣に考えるすべての開発者にとって、ÆPLとその設計思想は具体的な参照点になる。速度よりも検証可能性を優先すると決めたとき、そのコミットメントをシステムの設計に刻み込む方法として、ÆPLのアプローチは非常に示唆に富んでいる。