「AIエージェントを動かすことはできた。でも、なぜ3ヶ月経っても返信品質が最初のまま止まっているのか?」——これはWarpのPetra Donkaが2026年5月、Anthropicの開発者イベント「Code w/ Claude」で語った問いだ。
エージェントに複雑な手順書(ルール)を書き続けても、品質は上がらない。むしろ、リストが膨れ上がり、新しい状況のたびに破綻する。WarpはこのパターンをAIエージェント「Buzz」の運用を通じて学び、「プリンシプルを書け」「学び方を教えよ」「フィードバックループを自動化せよ」という3つの教訓にまとめた。
本記事では、Petra Donkaが28分間の講演で明かしたThe Ralph Loopの全貌——エージェントが毎日GitHubにPRを作り自己改善し続ける仕組み——を一次ソースに基づいて解説する。
AIエージェント全般のフレームワーク比較は AIエージェントフレームワーク比較2026年版 を参照してほしい。
Warpが直面した課題——毎月3,000件のメンションをどう捌くか

Warpはターミナルアプリとして、Twitter・Reddit・Hacker Newsを中心に毎月3,000件以上のメンションを受ける。製品チームがこれをすべて手動でトリアージし、返信を検討し、投稿するのは現実的でない。
Petra Donkaのチームは当初、AIエージェント「Buzz」を構築してこの問題を解決しようとした。Buzzは各メンションを分類し、返信候補を生成してSlackに表示する。チームが確認・投稿するだけで、コミュニティ対応の負荷を大幅に下げることができた——最初のうちは。
問題は時間とともに現れた。Buzzの返信品質が伸び悩む。新しいパターンが出るたびに手動で修正が必要になる。チームが「この返し方は違う」とフィードバックしても、翌週のBuzzは同じ間違いを繰り返す。
The Ralph Loopとは何か——エージェントが自己改善するサイクル
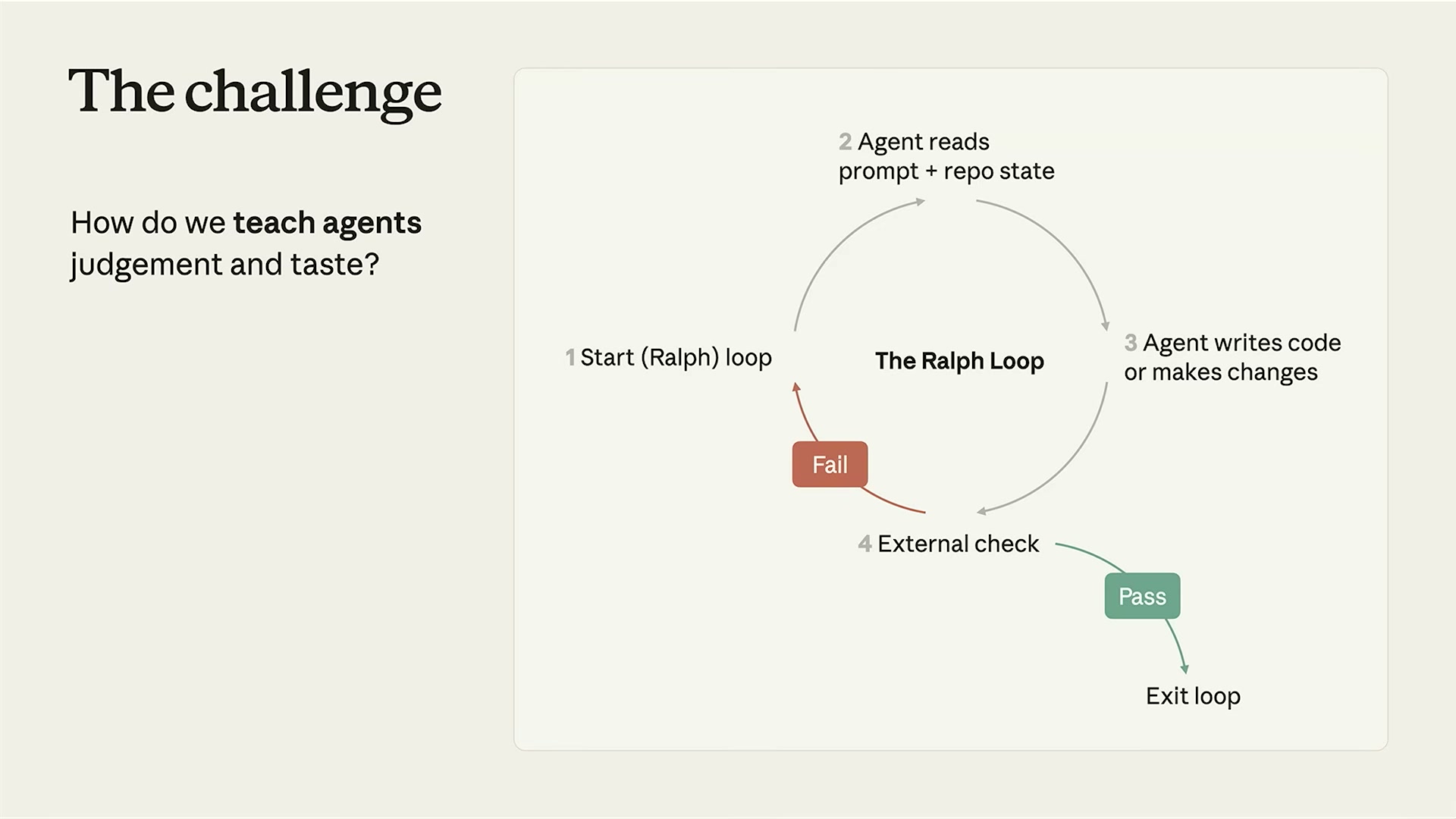
The Ralph Loopは、エージェントが自分自身の命令書を改善し続けるための自律サイクルだ。名前の由来は、Petra Donkaのチームが内部でこの仕組みを指す際に使っていたコードネームから来ている。
ループの構造は4ステップで構成される。
- Start(Ralph)loop — ループを開始する。毎日の定時実行、またはトリガーで起動
- Agent reads prompt + repo state — エージェントが現在のスキルファイル(命令書)とリポジトリの状態を読み込む
- Agent writes code or makes changes — フィードバックを分析し、スキルファイルを更新する
- External check — 自動テストや外部バリデーションでチェック。Passならループ終了、Failなら1に戻る
このサイクルが毎晩自動で回ることで、エージェントは「昨日のフィードバック」を「今日の改善」に変換し続ける。コードがGitHub PRとしてレビュー可能な形で提出されるため、チームは承認するかどうかを判断するだけでよい。
Lesson 1:ルールではなくプリンシプルを書く

Petra Donkaが最初に語った教訓は「ルールではなくプリンシプルを書け」だ。
ルールとプリンシプルの違い
| 観点 | ルール | プリンシプル |
|---|---|---|
| 記述形式 | 「〜せよ」「〜するな」という手順 | 「〜のように考えよ」という思考指針 |
| ファイルサイズ | 増え続ける | コンパクトに保てる |
| 新状況への対応 | 破綻しやすい | 転用しやすい |
| メンテナンス | 逐一追加が必要 | 更新頻度が少ない |
| エージェントの動き | 機械的に従う | 文脈に合わせて判断する |
Warpのケースで具体的に示すとこうなる。
ルール(悪い例):
- ツイートを以下11のアーキタイプに分類すること:
1. バグ報告
2. 機能リクエスト
3. ポジティブな口コミ
...
- 「競合製品への乗り換え」メンションには承認済みの話し言葉ポイントを使うこと
- ユーザーが怒っている場合は返信しないこと
このアプローチの問題は明白だ。ルールが増えるにつれてファイルが肥大化し、ルール同士が矛盾し始め、Anthropicがまとめた「Long list, overly specific, brittle(長く、具体的すぎて、脆い)」という評価がまさに当てはまる。
プリンシプル(良い例):
### Behavior
- Sound like someone who builds the product, not someone who processes feedback.
Speak with ownership and context, not like a support agent reading from a script.
- Don't get defensive — but it's fine to stand up for the product.
If a criticism isn't accurate, address it with facts and confidence.
- Start from what they actually said. Only address what they raised,
not adjacent topics. Don't add unsolicited corrections or context
the user didn't ask for; correcting someone who isn't wrong reads
as condescending and doesn't win anything.
プリンシプルの特徴は思考の指針を与えることだ。「11のアーキタイプに分類せよ」ではなく「製品を作る側の人間として話せ」と伝える。エージェントは新しい状況でも「この原則はここに当てはまるか?」と考えられる。
Anthropicのまとめる評価も対照的だ:「Smaller skill file, transfers well to new situations(ファイルが小さく、新しい状況にも転用できる)」。
Lesson 2:学び方を教える——フィードバックを原則に変換する7ステップ

Petra Donkaが語った2つ目の教訓は「学び方を教えよ」だ。フィードバックを受けたとき、それをどうスキルファイルの改善につなげるかを、エージェント自身がこなせるようにする。
フィードバックをプリンシプルに変換する7ステップ
エージェントの学習エージェント(Buzzの改善担当エージェント)には、以下のプロセスで動くよう指示されている。
Step 1:何が失敗したか(または成功したか)を特定する
抽象的な評価ではなく具体的なフィードバックから出発する。「返信が良くなかった」ではなく「このメンションに対してBuzzは競合の悪口を言ったが、それは不適切だった」という形で始める。
Step 2:なぜ?を問う
失敗は症状であり、根本原因を探る。「なぜBuzzは競合の悪口を言ったのか」→「防衛的な返し方を推奨するルールがあったが、それが過剰に適用された」という具合に掘り下げる。
Step 3:パターンに引き上げる
「この1件だけの問題か、それとも他のケースにも当てはまるか」を問う。特定の状況限定なら注記に留める。広く当てはまるなら原則として昇格させる価値がある。
Step 4:既存のプリンシプルと照合する
スキルファイルにある既存のプリンシプルをレビューし、「鋭くするか」「編集するか」「削除するか」「追加するか」を判断する。新しいプリンシプルが既存のものと重複・矛盾していないか確認する。
Step 5:プリンシプルとして書く
「何をすべきか」ではなく「どう考えるか」を記述する。「競合への言及は避けよ」ではなく「競合が話題に出た場合は、防衛的にならずに自社製品の実際の強みに戻れ」のように。
Step 6:適切なセクションに配置する
スキルファイルのセクション構造は重要だ。Petra Donkaは「セクションがエージェントが原則を適切に適用するうえで大きく影響する」と強調した。「Behavior」「Tone」「Product knowledge」など文脈に合ったセクションに入れることで、エージェントがその原則をいつ参照すべきかを正確に理解できる。
Step 7:編集してコミットする
スキルファイルを更新し、タイトなままに保つ。重複する原則を統合し、古くなった原則を削除する。そしてGitにコミット——プルリクエストを通じてチームのレビューを受ける。
# 日次学習エージェントの設定例(概念図)
learning_agent:
trigger: daily_at_midnight
inputs:
- slack_channel: "#feed-mentions"
lookback_hours: 24
signals:
- reactions: ["✅", "❌", "❤️"]
- thread_replies: true
process:
- analyze_feedback
- identify_patterns
- update_skill_file
output:
- create_github_pr:
branch: "buzz/reply-learning-{date}"
title: "draft-warp-reply: learnings from {date} feedback"
reviewers: ["petra-donka"]
この7ステップを学習エージェントに組み込むことで、人間のチームが「何が悪かったか」をSlackでリアクションするだけで、エージェントが自律的に自分のスキルファイルを改善するPRを作れるようになる。
Lesson 3:日常のフィードバックループ——Small input, Big output

3つ目の教訓は「フィードバックを日常に溶け込ませよ」だ。フィードバックループが機能するためには、チームメンバーがわざわざ「フィードバックを入力する」という意識なしに、自然な行動の中で教師信号を提供できる仕組みが必要だ。
Small input(小さな入力)
WarpのチームはSlackという日常ツールをそのまま使う。新しいインターフェースを学習する必要がない。
- Same tool → Slack — メンション管理も、フィードバック入力も、すべてSlackで完結
- Simple interaction → reactions & threads — エモジリアクション(承認✅・拒否❌・いいね❤️)と返信スレッドがフィードバック信号になる
- Automatic → daily agent run to open PR — 毎晩、学習エージェントが自動起動してGitHub PRを作成
Big output(大きなアウトプット)
チームの小さなアクションが積み重なることで生まれる効果は大きい。
- Lots of time saved on replies — チームが返信を0から考える時間を大幅削減。Buzzが返信案を提示し、確認だけすれば済む
- Close to zero additional time spent from the team — フィードバックをSlackリアクションで入力するのは数秒。チームへの追加負担はほぼゼロ
- Continuously improving agent — 毎日改善されるエージェントが翌日にはより良い返信案を提示する。このサイクルが数週間続くことで、品質は複利的に改善する
デモで見るWarpの実装——Slackチャネルの実際
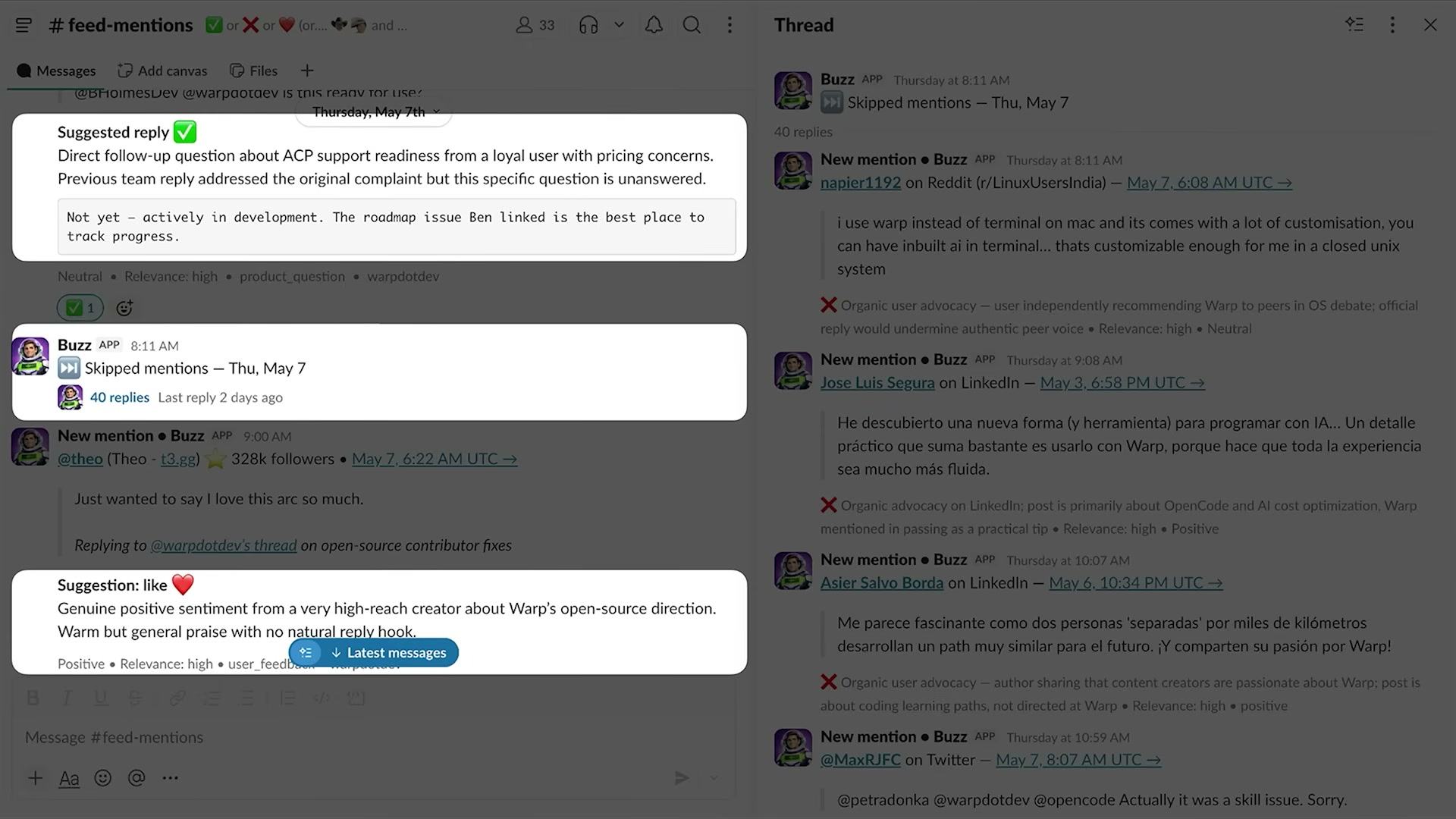
講演ではWarpの実際のSlack画面が公開された。#feed-mentionsチャネルには、Twitter・Reddit・LinkedInなど複数チャネルからのメンションが集約されている。
Buzzエージェントの動作フロー:
- 外部チャネルでWarpへのメンションが発生
- BuzzがメンションをSlackに取り込み、分類・文脈分析を実行
- 返信提案(Suggested reply) を生成し、提案理由・関連性スコア・ラベルとともに表示
- チームメンバーが確認し、✅(承認)・❌(スキップ)・❤️(いいね)のリアクションを付ける
- 承認された提案は元のプラットフォームに投稿。拒否されたものは教師信号として蓄積
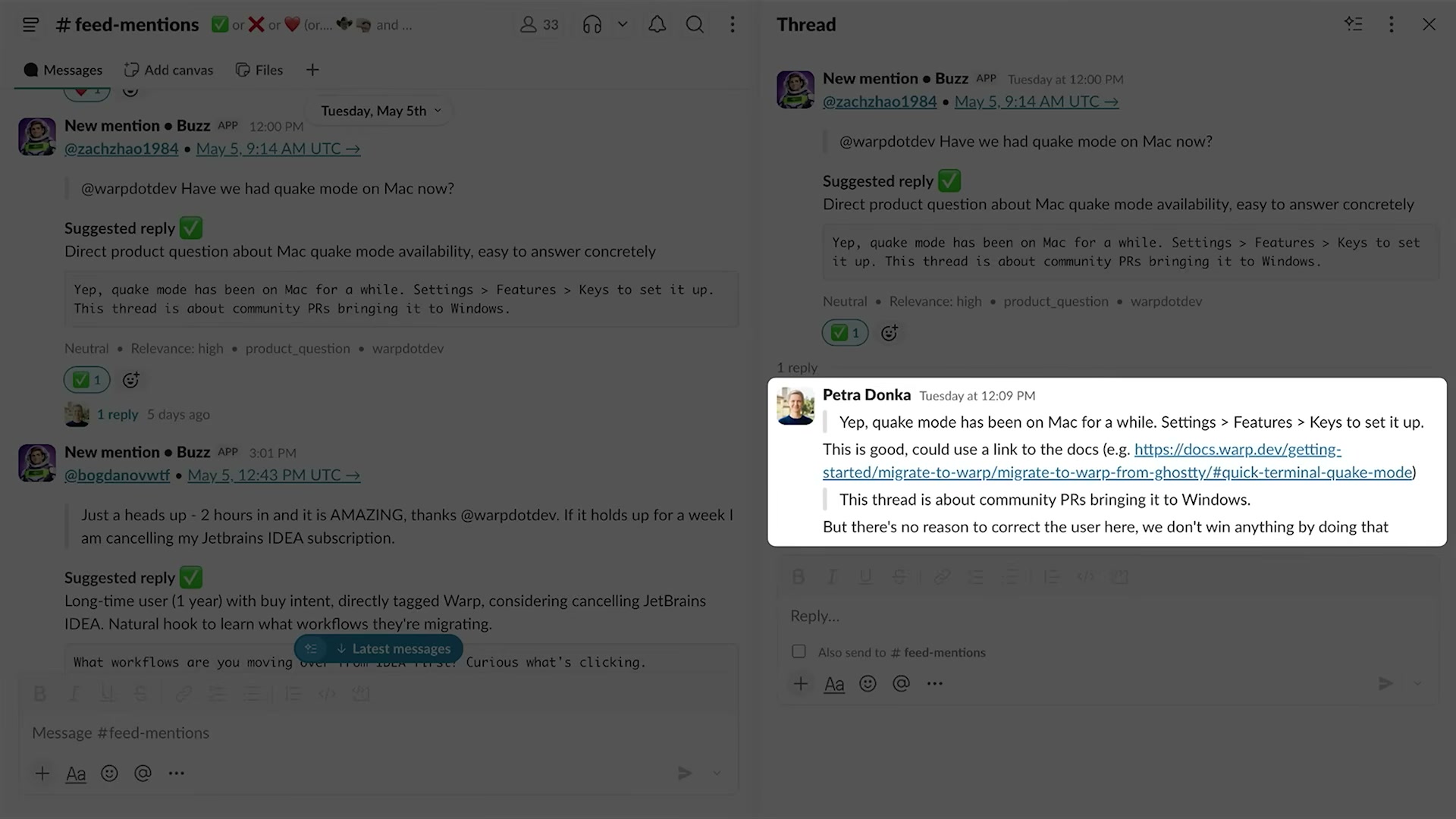
重要なのは、Petra Donka自身がSlackで手動修正した返信内容も教師信号になる点だ。スクリーンショットには、BuzzがMacのquake modeについて回答を提示したのに対し、Petra自身がより詳細な回答(ドキュメントリンク付き)をスレッドに投稿している場面が映っている。この「人間による修正」がそのまま翌日の学習素材になる。
GitHubへのPR自動作成——スキルファイルをコードとして扱う
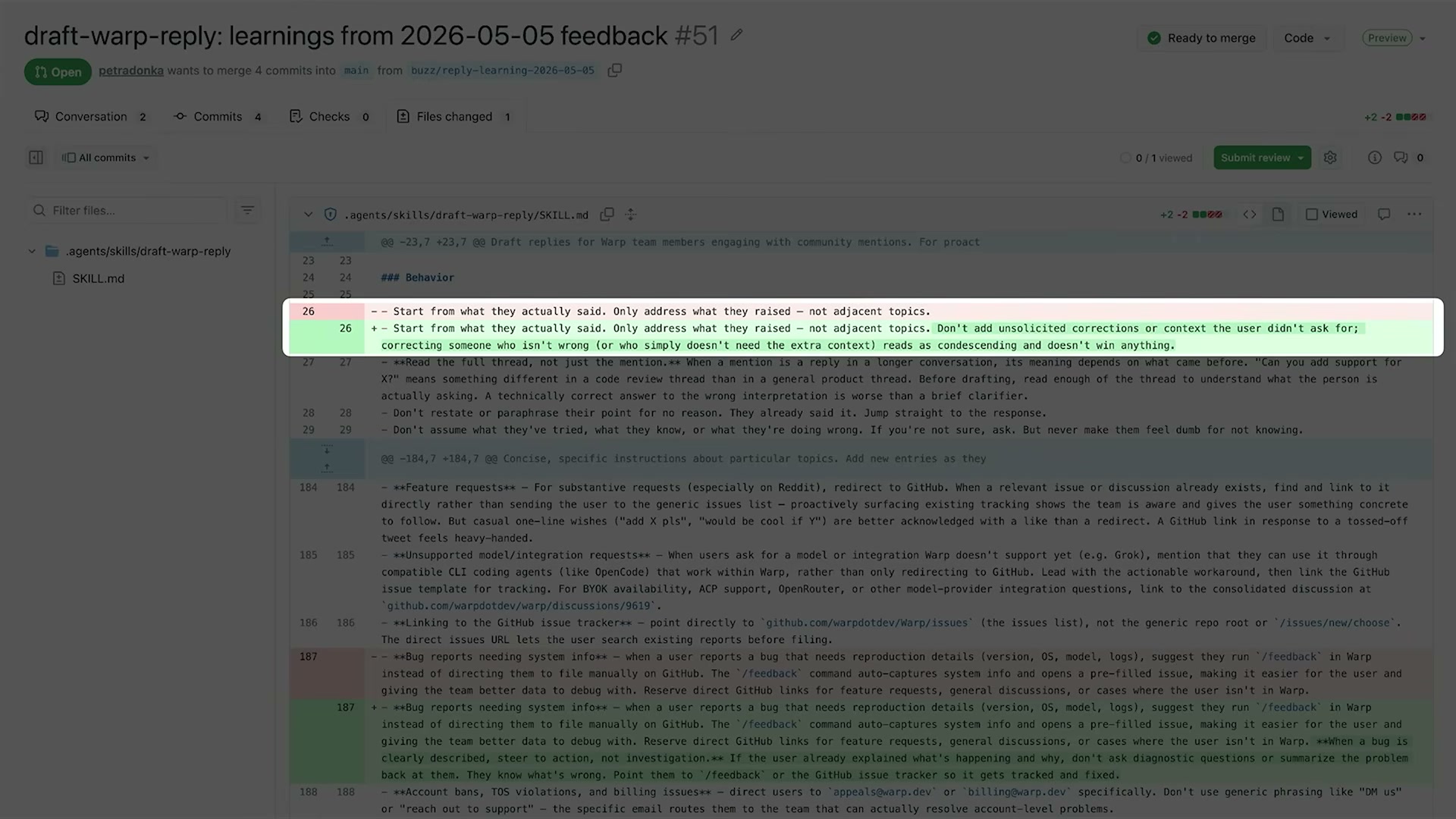
The Ralph Loopの最も特徴的な部分は、学習結果がGitHub Pull Requestとして提出される点だ。スクリーンショットにはdraft-warp-reply: learnings from 2026-05-05 feedback #51というPRが映っており、51日間連続でエージェントが改善PRを作り続けていることがわかる。
PRの内容を見ると、スキルファイル(agents/skills/draft-warp-reply/SKILL.md)に対する差分が示されている。具体的には:
### Behavior
23 23 - Start from what they actually said. Only address what they raised
24 24 — not adjacent topics.
- Don't add unsolicited corrections or context the user didn't ask for;
+ 26 - Don't add unsolicited corrections or context the user didn't ask
+ for; correcting someone who isn't wrong (or who simply doesn't need the
+ extra context) reads as condescending and doesn't win anything.
27 27
28 28 - Don't restate or paraphrase their point for no reason. They already
said it. Jump straight to the response.
このPRにはコメントが付いており、チームメンバーがレビューして「Approve」または修正提案を加える。マージされた変更は、翌日のBuzzの動作にそのまま反映される。
コードのPRレビューと同じプロセスで「エージェントへの指示」を管理できるため、変更履歴が残り、ロールバックも容易だ。Petra Donkaが「命令書をコードとして扱え」と言う理由がここにある。
成果:エージェントが自己改善したとき何が起きるか

Petra Donkaが公開した実績数値は以下の通りだ:
| 指標 | 数値 | 意味 |
|---|---|---|
| 月間メンション処理数 | 3,000件 | Twitter・Reddit・その他チャネルの合計 |
| スキップ率 | 50% | チームの時間不要でスキップ判断できるメンション割合 |
| エージェントスキル数 | 15スキル | トリアージ・返信下書き・学習・分析・レポート生成など |
| 月間クラウド実行数 | 4,000回 | バックグラウンドで自動実行されるエージェントrun数 |
50%スキップというのは特に注目すべき数字だ。メンションの半数は「スパム」「無関係の言及」「返信しても意味がない投稿」として自動判定され、チームは残りの50%にだけ集中できる。この判断精度が毎日改善し続けていることで、本当に重要なメンションへの対応品質が上がっている。
4,000回のクラウドエージェント実行は、チームが「何も考えなくても」バックグラウンドで走り続けている。
まとめ——チームの判断をエージェントに流し込む3原則

Petra Donkaが講演の最後に示した核心メッセージは「エージェントには完璧なプロンプトではなくフィードバックループが必要だ」だ。
3つの原則まとめ
1. Principles, not rules(ルールではなくプリンシプル) エージェントにジャッジメントとテイストを与える。具体的な手順を列挙するのではなく、「どう考えるか」を記述する。スキルファイルは小さく保ち、新しい状況でも転用できる原則を書く。
2. Teach to learn(学び方を教える) 正しいアウトプットを修正するだけでなく、エージェント自身が自分の命令書を育てられるようにする。7ステップのプロセス(特定→Why→パターン化→照合→プリンシプル化→配置→コミット)を学習エージェントに組み込む。
3. Make feedback easy(フィードバックを簡単に) 人間がエージェントを「訓練している」という意識なく、自然に教師信号を提供できる仕組みを作る。Slackリアクションのような最小限のインタラクションでフィードバックが集まり、日次エージェントランがそれを吸収してGitHub PRになる。
このアプローチが適用できる場面
Warpのケースはコミュニティメンション管理だが、同じ設計思想はより広いケースに適用できる。
- カスタマーサポートエージェント — 問い合わせへの返信精度を継続改善
- コードレビューエージェント — レビューコメントのトーン・具体性を日々精緻化
- ドキュメント生成エージェント — フィードバックを受けた文書スタイルを反映
- 営業支援エージェント — 商談フォローアップの文面を改善
共通するのは「チームの暗黙知をエージェントに移転したい」というシナリオだ。ルールリストで形式化できない「プロらしさ」「ブランドボイス」「判断のセンス」——そういったものをThe Ralph Loopは自然に吸収していく。
Petra Donkaの28分間の講演が示したのは、「完璧なプロンプトを書こうとする努力」を「フィードバックループを設計する努力」にシフトすることの価値だ。エージェントは最初から完璧である必要はない——毎日少しずつ賢くなる仕組みがあれば十分だ。
12-Factor Agentsの設計原則との比較も参考にしてほしい。