
Notionやメモアプリに知識をためていくほど、あとで「あの話どこに書いたっけ」が増えていきます。 フォルダ階層とキーワード検索だけでは、内容が近いノート同士を意味でたどるのが難しいからです。 そこを正面から作り替えるのが、markdownノートを意味でつなぐ自己ホスト型ナレッジベースOSS「Atomic」です。
30秒で理解する Atomic
・markdownノートを「アトム」として保存し、自動でチャンク化・埋め込み・タグ付け・意味的リンクを行う自己ホスト型のナレッジベースOSS。コアはRust、フロントエンドはReact、ライセンスはMIT
・セマンティック検索・Wiki合成・空間キャンバス・エージェントチャット・レポートを備え、SQLite+sqlite-vecでベクトル検索を動かす
・デスクトップアプリ(Tauri)/自己ホストサーバー(Docker・fly.io)/iOSアプリの3形態で動き、ClaudeやCursorからMCPで接続できる
・AIプロバイダーはOpenRouter・Ollama・OpenAI互換から選択。Ollamaを使えば外部にデータを出さずローカル完結。2026年6月時点で1,500★超
クラウドに置いたデータをAIで活用する発想に関心があるなら、まずRAGとは?仕組み・構築・ベクトルDB選定までの2026年実装マップで「検索して文脈を渡す」基本を押さえておくと、本記事のAtomicが「自分のノートを自分のRAG基盤にする」仕組みだとすっきり読めます。
理屈より先に動きを見たほうが速いので、公式の代表デモ動画とスクリーンショットを冒頭に置きます。
Atomicとは何か——ノートを「アトム」に変える自己ホスト型ナレッジベース
Atomicは、kenforthewinが開発する「自己ホスト型・意味的につながったパーソナル・ナレッジベース(Self-hosted, semantically-connected personal knowledge base)」です。 公式の説明では「markdownノートを、意味的につながったAI拡張の知識グラフに変える」ツールと位置づけられています。 リポジトリは2025年11月作成、2026年6月時点で1,500★・105フォークを集める、アクティブに更新が続くプロジェクトです。
中心にあるのが「アトム(atom)」という単位です。 アトムはただのmarkdownノートですが、保存すると自動で次の処理がかかります。
・チャンク化:長いノートを検索しやすい単位に分割する
・埋め込み(embedding):各チャンクをベクトル化し、意味を数値で表現する
・タグ付け:LLMが階層的なタグを自動で抽出してカテゴリに整理する
・意味的リンク:埋め込みの近さで、内容が似たアトム同士を自動でつなぐ
つまりユーザーは普通にmarkdownを書くだけで、裏側で「意味でたどれる知識グラフ」が育っていきます。 フォルダにきれいに整理する手間も、タグを手で付ける手間も基本は不要で、書いた内容そのものが構造になります。 「整理しないと探せない」という従来のノート運用の前提を、埋め込みとLLMで肩代わりさせているのがAtomicの核です。
下のスクリーンショットは、1つのアトム(markdownノート)を開いた画面です。 ソースURLやタグ、関連アトムへのリンクが、本文と一緒に扱われているのが分かります。

ギャラリー——Wiki合成・キャンバス・セマンティック検索を見る
Atomicの面白さは、ためたアトムを「別の見え方」で再利用できるところにあります。 公式READMEに載っている代表的な画面を並べ、それぞれが何をしているのかを掴みます。
まずWiki合成です。 タグでまとまったアトム群から、LLMがインラインの引用つきで1本の記事を生成します。 出典は引用元のアトムに紐づくため、「どのノートに基づく記述か」をたどれます。 新しいアトムが増えると記事は再生成され、知識の更新がそのまま反映されます。
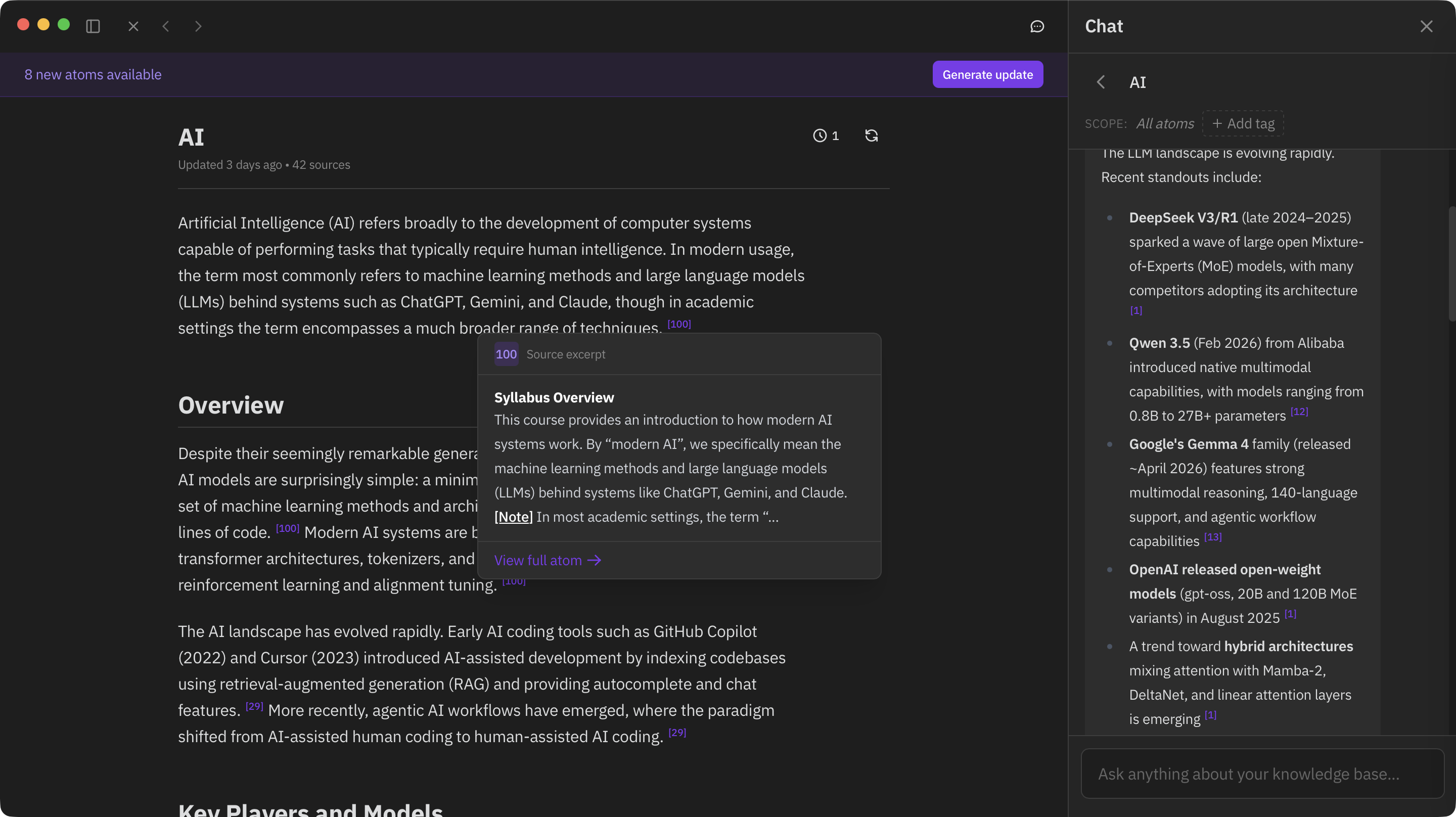
次にキャンバスです。 アトムを力学的レイアウト(force-directed layout)で配置し、意味の近さがそのまま画面上の距離になります。 関連の強いアトムが自然に近くへ集まり、知識の「かたまり」を俯瞰できます。 Sigma.jsとGraphologyで描かれる、インタラクティブなグラフ表示です。
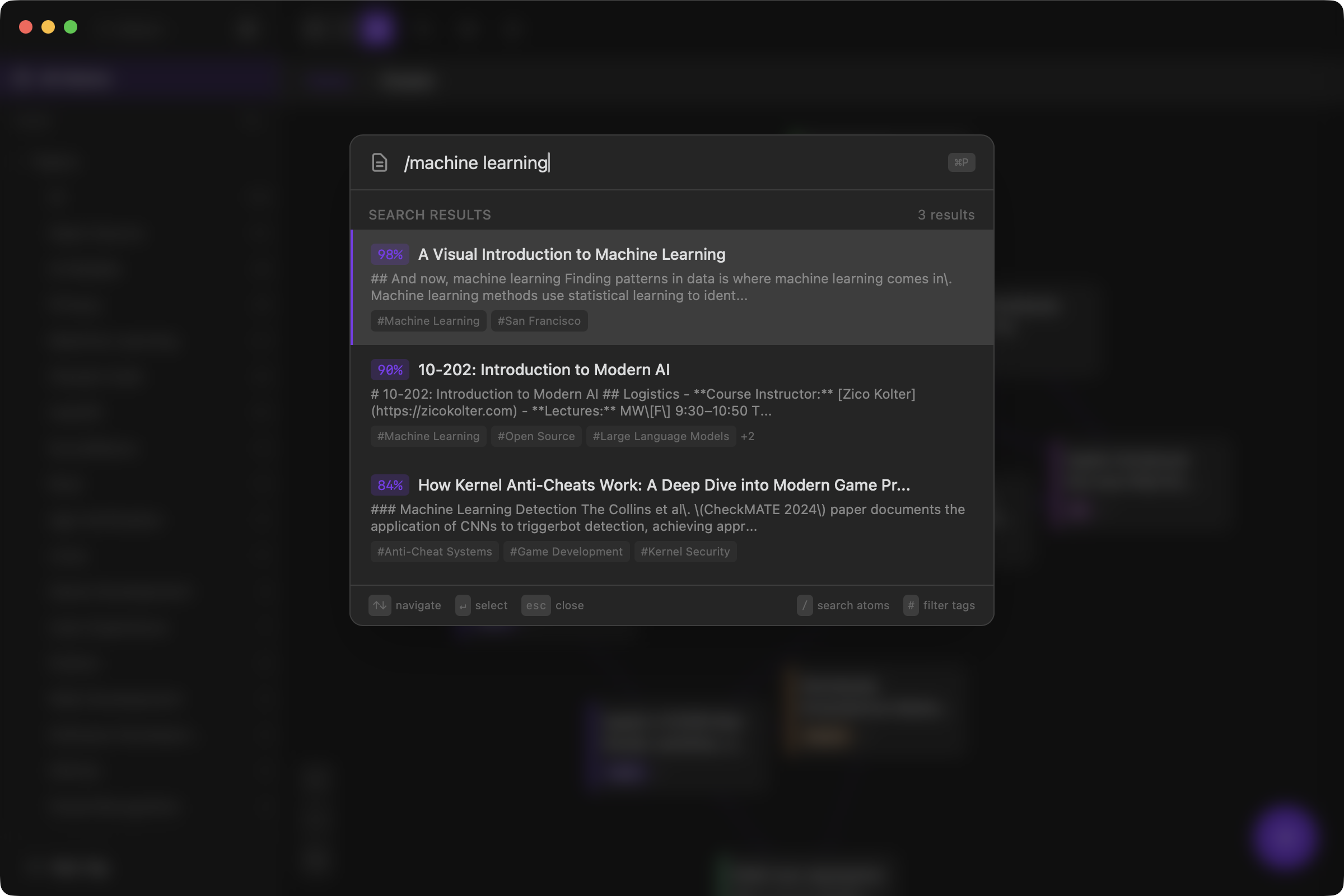
そしてセマンティック検索です。 タイトルや正確なキーワードを思い出せなくても、「意味」でノートを探し出せます。 sqlite-vecによるベクトル検索が裏側で効いており、公式の表現を借りれば「打った言葉ではなく、意図した内容で検索する」体験になります。
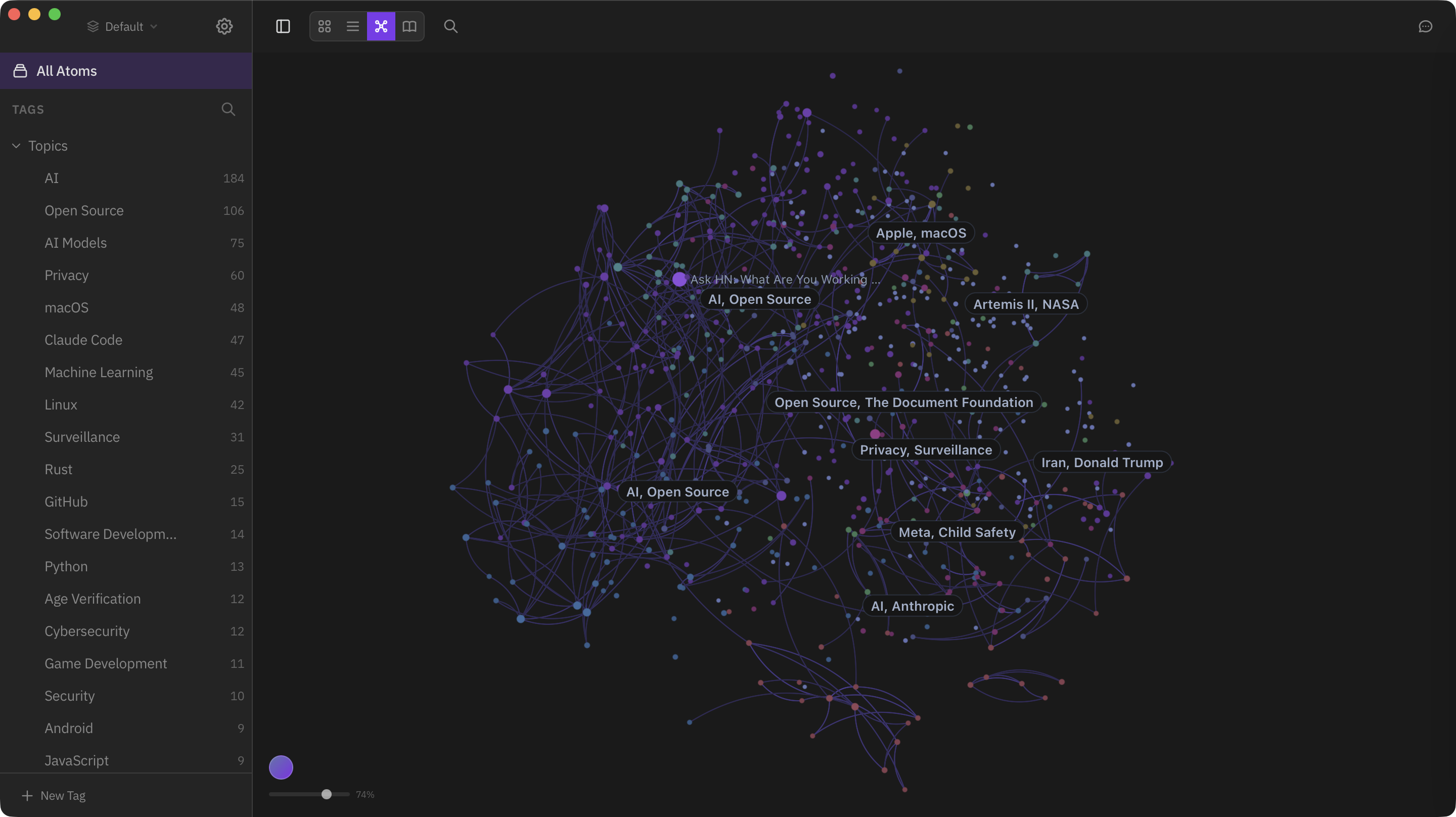
これら3つは別々の機能というより、「同じアトム群を別の角度から見る窓」です。 書いて、検索して、合成して、俯瞰する——という流れが、1つのナレッジベースの上で完結します。
アーキテクチャ・しくみ——atomic-coreを中心に全クライアントがHTTPで接続
Atomicの設計はシンプルで一貫しています。
公式の説明によれば、ビジネスロジックはすべてatomic-coreというフレームワーク非依存のRustクレートに集約されています。
そのコアをatomic-serverがREST API・WebSocketイベント・MCPエンドポイントで包み、すべてのクライアントはatomic-serverにHTTPで接続します。
つまりデスクトップアプリも、ブラウザUIも、iOSアプリも、MCPブリッジも、すべて同じサーバー越しに同じコアを叩く構造です。 ロジックを1か所に閉じ込めているため、クライアントが増えても挙動の一貫性を保ちやすくなっています。
全ビジネスロジック
フレームワーク非依存のRustクレート] SERVER[atomic-server
REST + WebSocket + MCP] CORE --> SERVER SERVER --> TAURI[src-tauri
デスクトップ・サイドカー] SERVER --> WEB[React UI
ブラウザ] SERVER --> IOS[iOSアプリ
SwiftUI] SERVER --> BRIDGE[mcp-bridge
stdio] TAURI --> DESKUI[React UI
デスクトップ] BRIDGE --> MCP[MCPクライアント
Claude・Cursorなど]
データ層も特徴的です。 データベースはSQLiteで、ベクトル検索はsqlite-vec拡張を使います。 専用のベクトルDBを別途立てるのではなく、1つのSQLiteファイルにノートも埋め込みも収める設計のため、自己ホストの運用負荷が小さく済みます。 非同期ランタイムにtokio、HTTPサーバーにactix-webを使う、典型的なモダンRustのサーバー構成です。
フロントエンドはReact 18+TypeScript、ビルドはVite 6、スタイルはTailwind CSS v4、状態管理はZustand 5。 エディタはCodeMirror 6、キャンバスの描画はSigma.jsとGraphologyという布陣です。 デスクトップアプリはTauri v2で包み、サーバーをサイドカーとして起動します。
クレート構成は次のように分かれています。
・crates/atomic-core/ — 全ビジネスロジック
・crates/atomic-server/ — REST+WebSocket+MCPサーバー
・crates/mcp-bridge/ — HTTPとstdioをつなぐMCPブリッジ
・src-tauri/ — Tauriデスクトップアプリ(サーバーをサイドカー起動)
・src/ — Reactフロントエンド
・extension/ — Chromium系ブラウザ拡張
この「コアを1つに、クライアントを多数に」という分け方は、後述するMCPサーバーやiOSアプリといった多様な入口を支える土台になっています。
インストールと起動——デスクトップ・Docker・fly.io・スタンドアロン
Atomicはデスクトップアプリ(Tauri)、ヘッドレスサーバー(Docker/fly.io)、あるいはその両方として動かせます。 用途に応じて入口を選べるのが利点です。
最も手軽なのはデスクトップアプリです。 GitHub ReleasesからmacOS・Linux・Windows向けの最新版を入れ、初回起動時のセットアップウィザードでAIプロバイダーを設定します。
サーバーとして自己ホストするなら、Docker Composeが基本です。
git clone https://github.com/kenforthewin/atomic.git
cd atomic
echo "ATOMIC_SETUP_TOKEN=$(openssl rand -base64 24)" > .env
docker compose up -d
これでAPIサーバー・Webフロントエンド・nginxリバースプロキシの3サービスが立ち上がります。
http://localhost:8080を開き、.envのATOMIC_SETUP_TOKENを使ってセットアップウィザードからインスタンスを「請求(claim)」します。
すでにCaddyやTraefikなど自前のリバースプロキシを持っているなら、同梱のプロキシは省いてserver・webコンテナに直接ルーティングしても構いません。
クラウドに置きたいなら、fly.ioへのデプロイ手順も用意されています。
cp fly.toml.example fly.toml
fly launch --copy-config --no-deploy
fly volumes create atomic_data --region <your-region> --size 1
fly secrets set ATOMIC_SETUP_TOKEN="$(openssl rand -base64 24)"
fly deploy
OAuthやMCPで使う公開URLはFlyのアプリ名から自動検出されます。 Dockerもクラウドも使わず、Rustツールチェーンで直接動かすスタンドアロン構成も選べます。
ATOMIC_SETUP_TOKEN="$(openssl rand -base64 24)" \
cargo run -p atomic-server -- --data-dir ./data serve --port 8080
初回起動時にセットアップトークンをウィザードに入れるか、CLIで直接APIトークンを作成できます。
cargo run -p atomic-server -- --data-dir ./data token create --name default
開発環境を整えるならNode.js 22以上とRustツールチェーン(rustup)が前提で、デスクトップ版はTauri v2のプラットフォーム依存パッケージも要ります。
npm run tauri devでホットリロード付きのデスクトップ開発、cargo testで全テスト、npx tsc --noEmitでフロントエンドの型チェックという具合に、コマンドはモダンな構成です。
AIプロバイダーの設定とローカル完結——OpenRouter・Ollama・OpenAI互換
Atomicは埋め込み・タグ付け・Wiki生成・チャットのためにAIプロバイダーを必要とします。 選択肢は3系統です。
・OpenRouter:openrouter.aiでAPIキーを取得。埋め込み・タグ付け・Wiki・チャットそれぞれに別モデルを割り当てられる
・Ollama:Ollamaをローカルにインストールしてモデルを取得(例:ollama pull nomic-embed-text)。Atomicが利用可能なモデルを自動検出する
・OpenAI互換:OpenAI・Azure OpenAI・Together・GroqなどOpenAI互換APIを持つプロバイダー。ベースURLとAPIキーを設定する
ここで実務上効いてくるのがOllama対応です。 埋め込みもLLM処理もローカルのOllamaに向ければ、ノートの中身を一切外部に送らずに、セマンティック検索やWiki合成を動かせます。 「自己ホストでデータを手元に置く」という思想を、AI処理のレイヤーまで一貫させられるわけです。
ローカルでLLMを動かす環境づくりそのものに関心があるなら、LM Studio 入門|ローカルでLLMを動かすデスクトップアプリも、同じ「手元で完結させる」発想の隣接ツールとして参考になります。 AtomicがOllamaやOpenAI互換エンドポイントを叩く先として、ローカルLLMの選択肢を広げられます。
設定は初回起動時のウィザードか、後からSettingsで変更できます。 用途ごとにモデルを分けられるため、「埋め込みは軽量ローカルモデル、Wiki生成だけクラウドの高性能モデル」といった使い分けも可能です。
基本的な使い方——ブラウザ拡張・RSS・MCPサーバーで知識を入れて出す
Atomicの日常的な使い方は「知識を入れる」「知識を出す」の2方向で考えると整理できます。
知識を入れる側では、まず手書きのmarkdownノート(アトム)が基本です。 それに加えて、Webコンテンツを取り込む2つの経路があります。
1つはブラウザ拡張「Atomic Web Clipper」です。 Chrome Web Storeからインストールし、サーバーURLとAPIトークンをオプションで設定します。 オフライン時のキャプチャはキューに溜まり、サーバーが利用可能になると同期されます。
もう1つはRSSフィードです。 フィードを購読しておくと、新着記事が自動でアトムとして取り込まれます。 気になる情報源を登録しておけば、読んだそばから意味的につながる知識として蓄積されていきます。
知識を出す側で強力なのがMCPサーバーです。 AtomicはMCPエンドポイントを公開し、ClaudeやCursorなどのAIツールから、アトムを検索・読み取り・作成・更新・URL取り込みできます。 公開されるツールは次の5つです。
・semantic_search — 意味でアトムを検索する
・read_atom — アトムを読み取る
・create_atom — アトムを作成する
・ingest_url — URLを取り込んでアトム化する
・update_atom — アトムを更新する
デスクトップ版はatomic-mcp-bridgeというstdio-to-HTTPブリッジを同梱しており、ローカルの認証トークンを自動で読むため、バイナリのパスを指すだけで設定が済みます。
{
"mcpServers": {
"atomic": {
"command": "/Applications/Atomic.app/Contents/MacOS/atomic-mcp-bridge"
}
}
}
リモート/自己ホストのサーバーには、/mcpエンドポイントにBearerトークンで接続します。
{
"mcpServers": {
"atomic": {
"type": "url",
"url": "https://your-server.com/mcp",
"headers": {
"Authorization": "Bearer YOUR_TOKEN"
}
}
}
}
トークンはSettings > Connection > API Tokensか、CLIのatomic-server token create --name "claude"で発行します。
このMCP対応により、Atomicは「自分のノートを、手元のAIエージェントの長期記憶として差し込む」使い方ができます。
MCPそのものの仕組みをもう少し知りたいなら、MCPとは何か?AIに手足を与えるプロトコルの仕組みと実践ガイドを先に読むと、AtomicのMCPサーバーが何を公開しているのかがより明確になります。
ユースケース——調査ログ・RAGの土台・チームの知識基盤
汎用のナレッジベースなので、使いどころは広く考えられます。 公式の機能と設計思想から、現実的なシナリオを整理します。
・個人の調査ログ:ブラウザ拡張とRSSで情報を集め、セマンティック検索とWiki合成で「自分専用の百科事典」を育てる。レポート機能で日次ブリーフィングや矛盾スキャンを自動化する
・AIエージェントの長期記憶:MCPサーバー経由で、ClaudeやCursorから自分のノートを検索・追記させる。会話のたびに過去の知識を文脈として差し込める
・RAGの自己ホスト基盤:sqlite-vecのベクトル検索とアトムのAPIを土台に、外部にデータを出さないRAGパイプラインを組む
・研究・執筆の下調べ:引用つきWiki合成で、出典をたどれる下書きを素早く作る。あとから一次ソースを確認しやすい
・小規模チームの知識基盤:マルチデータベースで複数のナレッジベースを共有レジストリ管理し、サーバーを1つ立てて共同利用する
特にレポート機能は、Atomicを「ためる場所」から「働く場所」に変えます。 公式の説明では、アトムを定期的な調査タスクにかけ、日次ブリーフィング・矛盾スキャン・未解決の問いの追跡といった引用つきの所見を繰り返し生成します。 ためた知識が放置されず、定期的に再解釈されて返ってくる設計です。
クラウドの調査ツールと比べたいなら、NotebookLM使い方ガイド2026|料金・Audio Overview・ChatGPTとの比較が好対照です。 NotebookLMが「クラウドで手軽に出典つき回答」を提供するのに対し、Atomicは「自己ホストで同種の体験を、データを手元に置いたまま」実現する立ち位置だと分かります。
類似OSS・サービスとの比較——自己ホスト×セマンティック×OSS
ナレッジ管理ツールは数多くありますが、「自己ホスト」「セマンティック検索」「OSS」の3点を同時に満たすものは限られます。 代表的なツールと並べて、Atomicの立ち位置を整理します。
| ツール | 形態 | 意味検索/AI | データの所在 | ライセンス |
|---|---|---|---|---|
| Atomic | 自己ホスト(デスクトップ/サーバー/iOS) | sqlite-vec+LLM(埋め込み・Wiki・チャット) | 自分のサーバー/端末。Ollamaでローカル完結可 | MIT |
| NotebookLM | クラウドサービス | Gemini中心の出典つき回答 | Google側(クラウド) | プロプライエタリ |
| Notion | クラウドサービス | Notion AI(追加機能) | Notion側(クラウド) | プロプライエタリ |
| Obsidian | ローカルアプリ | 標準はキーワード。AIはプラグイン依存 | ローカルファイル(markdown) | プロプライエタリ(無料) |
| Logseq | ローカル/自己ホスト | 標準はアウトライン。AIは限定的 | ローカルファイル(markdown) | AGPL-3.0 |
この表から見えるのは、Atomicが「自己ホスト×標準でセマンティック検索/AI内蔵×OSS」という角に立っていることです。 Obsidianやファイルベースのツールはローカル性で近いものの、意味検索やWiki合成は標準では持たず、プラグインや別サービスに頼ります。 NotebookLMやNotionはAIが強力でも、データはクラウドに置かれ、自己ホストはできません。
Atomicは「markdownのローカル性」と「クラウドAIツールの意味的な賢さ」を、自己ホストの枠内で両立しようとしています。 裏返せば、手軽さ・洗練されたUI・大規模なエコシステムでは、成熟したクラウドサービスや老舗ローカルアプリに譲る場面もあります。 「データを手元に置いたまま、意味でつながる知識基盤がほしい」という動機が強いほど、Atomicの設計が刺さります。
ライセンス面でもMITは扱いやすく、出力や自己ホスト構成を社内ツールに組み込む際の法務的な見通しが立てやすいのも実務上の利点です。
制限と注意点——若いプロジェクトと自己ホストの責任
設計の良さとは別に、導入前に押さえておきたい現実的な制約もあります。
・プロジェクトが若い:リポジトリは2025年11月作成と新しく、1,500★とアクティブではあるものの、長期運用での安定性や後方互換性の実績はこれから積み上がる段階。バージョンアップ時の挙動変化には注意したい
・自己ホストの責任:サーバーの構築・更新・バックアップ・セキュリティは自分の責任になる。手軽さではクラウドサービスに譲る
・AIプロバイダーが前提:埋め込み・タグ付け・Wiki生成・チャットはAIプロバイダーがないと機能しない。クラウドを使えばAPIコストが、Ollamaを使えばローカルの計算資源が要る
・品質はモデル依存:Wiki合成や自動タグ付けの質は、選んだLLM・埋め込みモデルに左右される。引用つきとはいえ、生成物は必ず一次ソースで裏取りする前提で使う
・周辺アプリの規約:ブラウザ拡張(Chrome Web Store)やiOSアプリ(App Store)、各AIプロバイダーには本体のMITとは別の規約がある。商用利用時は併せて確認する
逆に言えば、これらは「若い自己ホストOSS」という性格から素直に導かれる制約です。 データ主権とロックイン回避を優先し、運用の手間を引き受けられるなら、十分に実用域にあります。
まとめ——「書くだけで意味でつながる」を自己ホストで
Atomicの本質は、markdownノートを書くという行為を変えずに、その裏で「意味でつながる知識グラフ」を自動的に育てる点にあります。 チャンク化・埋め込み・タグ付け・意味的リンクを自動化し、セマンティック検索・Wiki合成・キャンバス・チャットという複数の窓から、同じアトム群を再利用できます。
・markdownを書くだけで、自動でベクトル化・タグ付け・意味的リンクが付く
・sqlite-vecで意味検索、LLMで引用つきWiki合成・エージェントチャット・定期レポートを生成
・デスクトップ/サーバー/iOSの3形態、MCPでClaudeやCursorからも接続できる
・OpenRouter・Ollama・OpenAI互換から選べ、Ollamaならローカル完結。MIT・1,500★超のアクティブなOSS
誰に向くかを最後に整理します。 NotionやObsidianに知識をためているが「意味でたどれない」もどかしさを感じている人、そしてデータをクラウドに預けたくない人——この2つが当てはまるなら、Atomicの自己ホスト+セマンティックという設計はまっすぐ刺さります。 逆に、設定なしの手軽さや完成されたUI・大規模エコシステムを最優先するなら、クラウドサービスや老舗ローカルアプリのほうが近道です。
まずはデスクトップ版をGitHub Releasesから入れるか、docker compose up -dで1インスタンス立てて、手元のノートを数件アトム化してみるのがおすすめです。
セマンティック検索で「キーワードを思い出せないノート」を意味で引き当てられたとき、Atomicが解こうとしている問題の手触りが一番よく分かります。
自分のノートをAIエージェントの記憶として使う発想に踏み込みたいなら、RAGとは?仕組み・構築・ベクトルDB選定までの2026年実装マップと合わせて読むと、「自己ホストのRAG基盤」としてのAtomicの可能性が立体的に見えてきます。
参照ソース
・kenforthewin/atomic — GitHubリポジトリ(README・アーキテクチャ・ライセンス・スター数)
・Atomic 公式サイト(atomicapp.ai)
・Atomic ブラウザ拡張 — Chrome Web Store








