NotebookLMは優れたAIナレッジツールですが、使い込むほど「ソース数の上限」「ノートブック数の制限」「Geminiへのベンダーロックイン」といった壁にぶつかります。 SurfSenseは、これらの制約を「無制限・自己ホスト・LLM自由」の方向で置き換えることを目的に作られた、プライバシー重視のオープンソースAIナレッジベースです。 ソースもノートブックも無制限、LLMも埋め込みも自由、しかもデータを自分のインフラに置いたままチームで使えます。
30秒で理解する SurfSense
・NotebookLMの代替を掲げるApache-2.0のOSS。ソース・ノートブック・データ容量が無制限で、自分のインフラに自己ホストできる。2026年6月時点で1.4万★超
・100以上のLLM(OpenAI仕様・LiteLLM経由)、6,000以上の埋め込みモデルに対応。vLLM・Ollamaでローカル推論も可能
・27以上の外部コネクタ(Google Drive・Slack・Notion・GitHub・Gmail・Obsidianなど)を1つの検索可能なコーパスに統合。Notion/Slack/Linear/Jira/Driveへ結果を書き戻せる
・引用付きのハイブリッド検索(セマンティック+全文、RRFで再ランク)。レポート・ポッドキャスト・スライド/動画・画像の生成まで1プラットフォームで完結
・Docker一行で自己ホスト。リアルタイムのマルチプレイヤー(RBAC)、デスクトップアプリ、スケジュール/イベント駆動の自動化も備える
まずは全体像を掴むのが早いので、公式READMEのバナーを冒頭に置きます。 SurfSenseは「チーム向けの、データ制限のないNotebookLM代替」を一言のキャッチコピーに掲げています。

公式リポジトリは MODSetter/SurfSense です。 本記事は公式READMEを一次ソースに、SurfSenseが何をして何をしないのかを実務目線で整理します。 PDFやドキュメントを横断的に扱うツールを比較検討している段階なら、先にAI PDF要約ツール8選|OSS vs 商用の比較も眺めておくと、SurfSenseの立ち位置が掴みやすくなります。
SurfSenseとは何か——NotebookLMの「制限」を外したナレッジOSS
SurfSenseの出発点は、NotebookLMへの具体的な不満です。 READMEは冒頭で、NotebookLMの限界を箇条書きで率直に挙げています。
・1つのノートブックに追加できるソース数に上限がある
・持てるノートブックの数にも上限がある
・1ソースあたり50万語・200MBを超えられない
・GoogleのLLM・利用モデルにベンダーロックインされ、構成を選べない
・外部データソースや連携が限られている
・NotebookLMのエージェントは学習・調査用途に最適化され、それ以外の使い方がしにくい
・マルチプレイヤー(複数人の同時利用)に対応していない
SurfSenseは、これらを正面から解こうとしています。 データの流れを自分で管理し(プライバシー)、ソースもノートブックも無制限にし、どんなLLM・画像・TTS・STTモデルでも構成でき、27以上の外部ソースをつなぎ、チームでリアルタイムに共同作業する——これがREADMEの掲げる中心的な価値です。
SurfSenseの本質は「NotebookLMの体験を、制限とベンダーロックインなしで自己ホストできるようにしたもの」です。 推論エンジンも保存先も自分で選べるため、データを外に出せない組織や、Gemini以外のモデルを使いたいチームにとって、NotebookLMの代替候補になります。 ただしREADME自身が「まだproduction-readyではない」と明記している点は、最初に押さえておくべき前提です。
数字の面も押さえます。 リポジトリの構成はPython(約65%)とTypeScript(約32%)が中心で、バックエンドはFastAPI、フロントエンドはNext.jsです。 ライセンスはApache-2.0、本記事執筆時点(2026年6月)で1.4万★を超えており、Trendshiftにも掲載される注目度の高いプロジェクトになっています。
何ができるか——検索・生成・自動化を1つに束ねる
SurfSenseの機能は幅広いですが、大きく「検索・チャット」「成果物の生成(Deliverable Studio)」「コネクタ連携」「自動化」「デスクトップアプリ」の5系統に整理できます。
検索・チャットの中心は、引用付きの回答です。 PDFやドキュメントに対してインライン引用つきで質問でき、ナレッジベース全体を対象にしたハイブリッド検索(セマンティック+キーワード)が走ります。 Perplexityスタイルの「出典が明示される回答」を、自分のデータに対して行えるイメージです。
成果物の生成(Deliverable Studio)は、調べた内容をそのまま使える形に変える機能群です。
・AIレポート生成:引用付きの調査レポートを作り、PDF・DOCX・HTML・LaTeX・EPUB・ODT・プレーンテキストで書き出す
・AIポッドキャスト生成:任意のドキュメントやフォルダを、2人のホストによるAIポッドキャストに20秒未満で変換する
・AIプレゼン/動画メーカー:ソースから編集可能なスライドとナレーション付きの動画概要を作る
・AI画像生成:チャットやドキュメントから高品質な画像を生成する
・AIレジュメビルダー:既存の履歴書を求人票に合わせて書き換え、ATS通過を狙う
これらはすべて、取り込んだ自分のデータに根ざして生成される点が重要です。 ゼロから書かせるのではなく、ナレッジベースを土台に「レポートにする」「音声にする」「スライドにする」という変換を行うため、出力に引用と根拠が伴います。
ギャラリー——ログインからレポート・ポッドキャスト生成まで
ここからは公式READMEのデモGIFから抜き出した代表画面で、実際の操作感を見ていきます。 まず入口は、surfsense.comでのログインです。
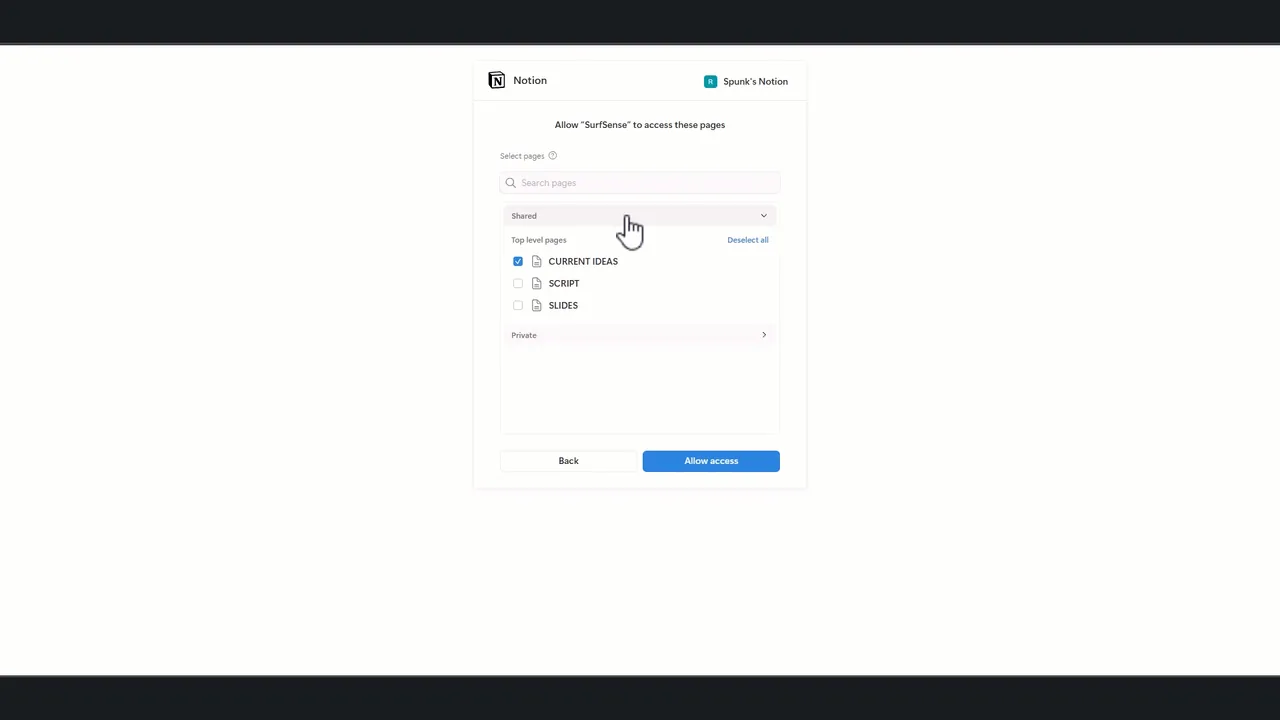
次にコネクタの接続です。 下はNotionを連携する際のOAuth許可画面で、共有ページの中からインデックス対象を選んでいるところです。 こうした外部サービスを接続・同期することで、散らばった情報が1つの検索可能なコーパスにまとまります。
取り込んだデータは、チャットで横断的に問い合わせられます。 回答にはインライン引用が付き、どのソースのどこを根拠にしているかを追えます。
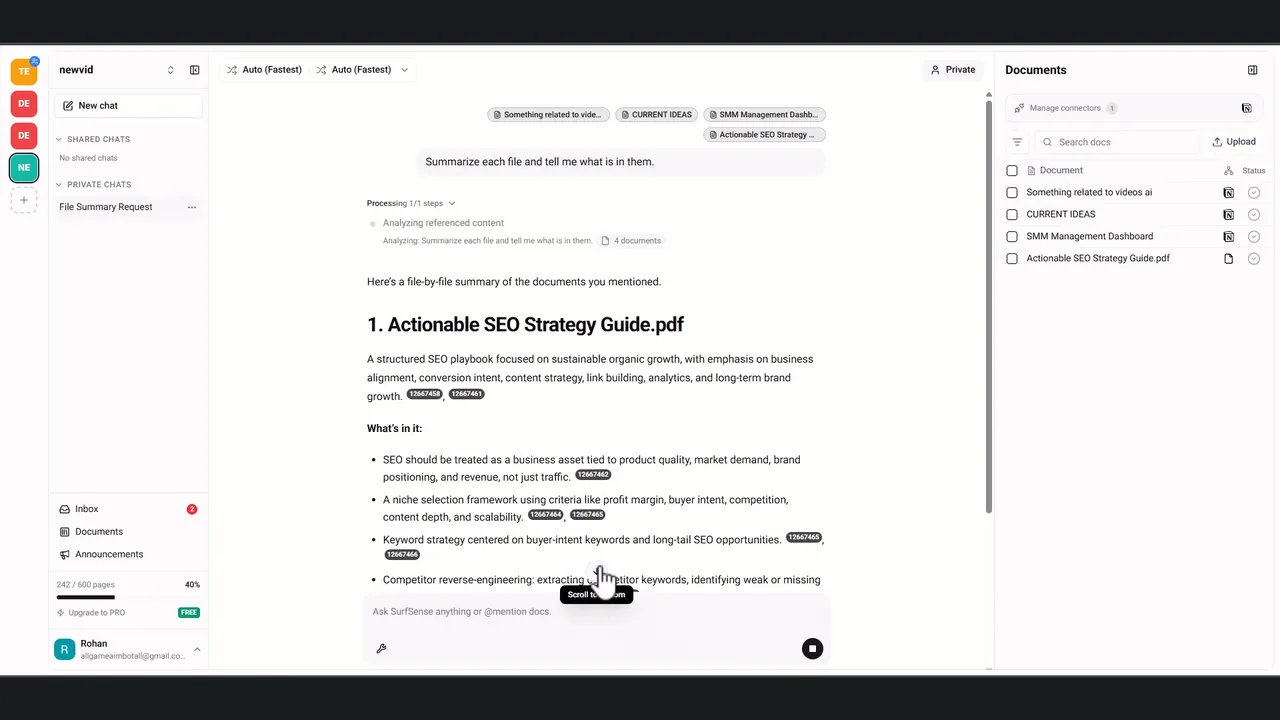
調べた内容は、その場でレポートに変換できます。 下はAIレポート生成の画面で、引用付きの調査レポートを組み立てているところです。
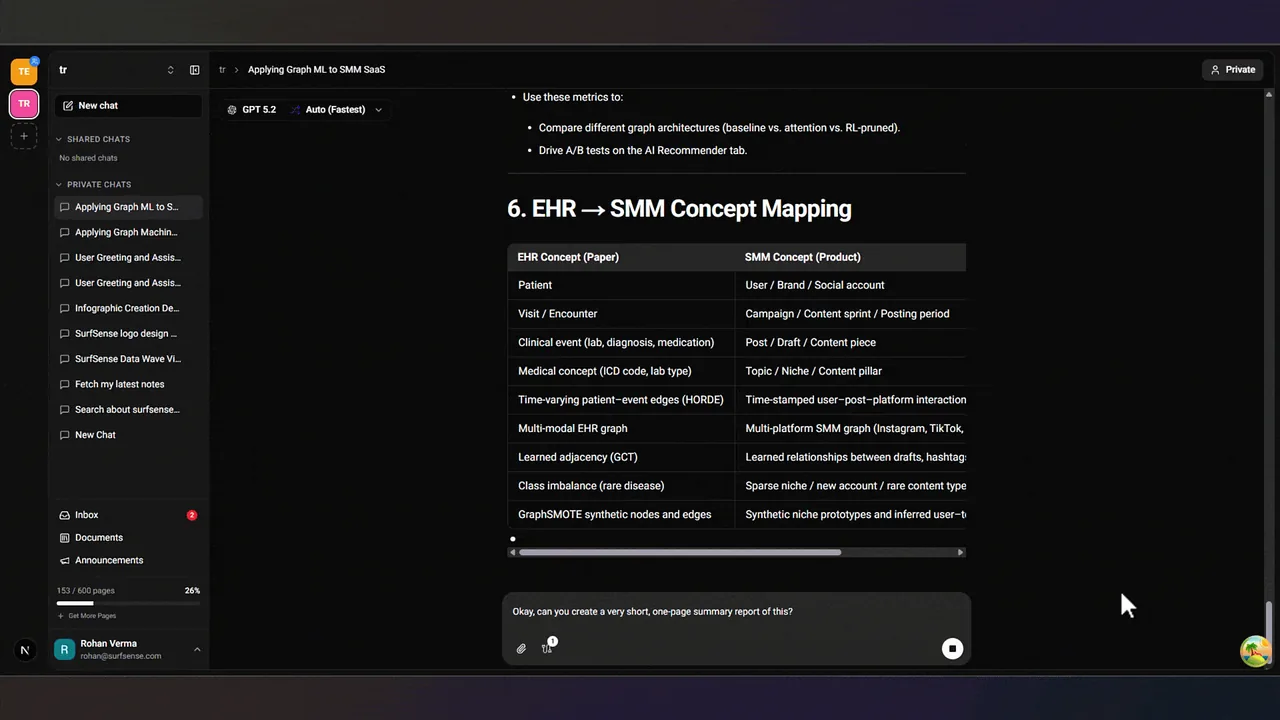
同じソースから、2人のホストによるポッドキャストも作れます。 READMEは「20秒未満で生成」とうたっており、移動中に内容を耳で確認したいときに効きます。
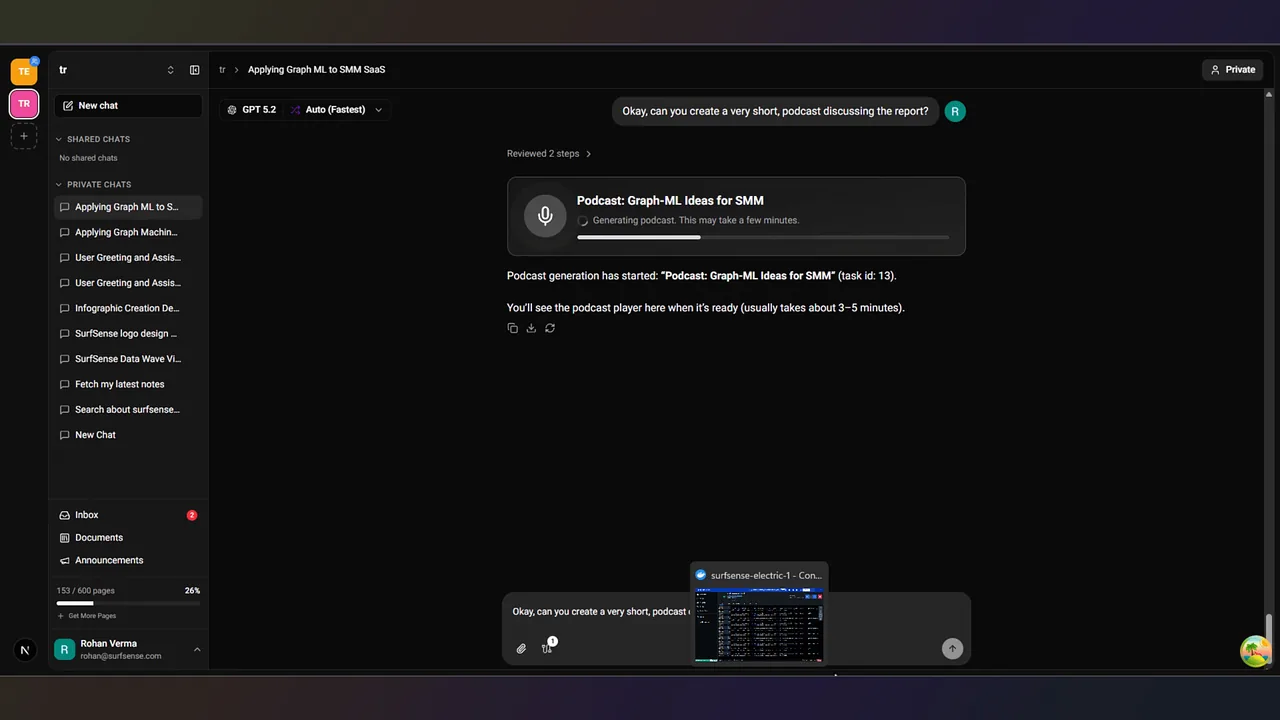
スライドと動画の概要も、ソースから直接生成できます。 下はプレゼン/動画メーカーの画面です。
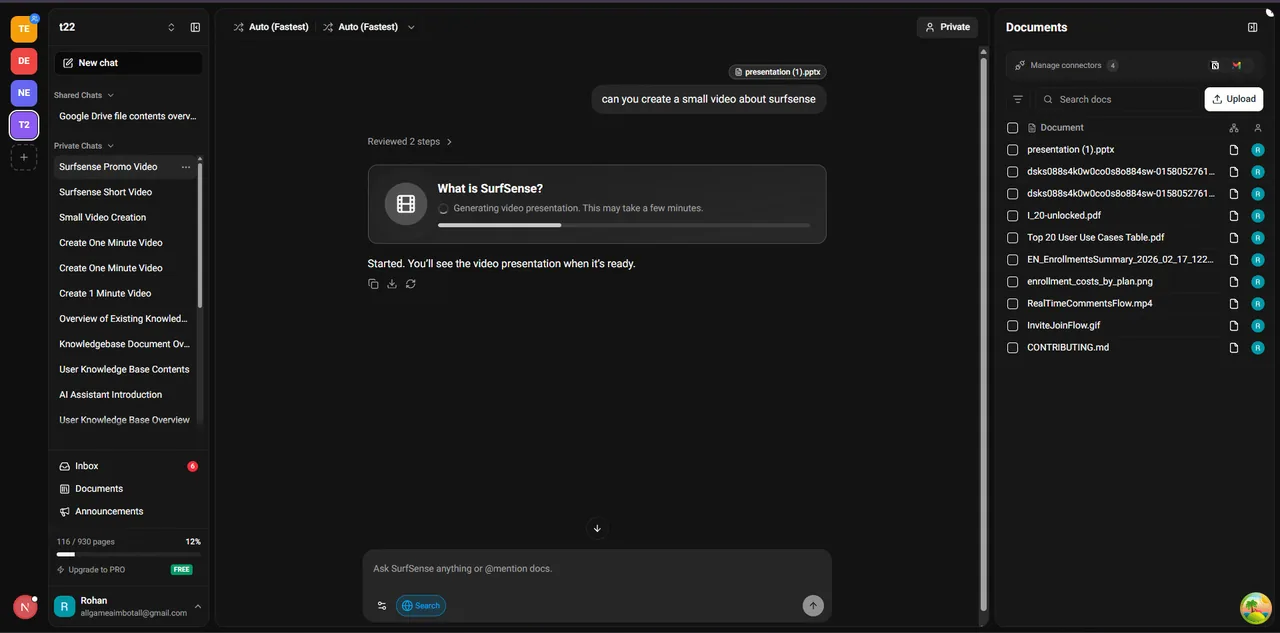
最後にチーム利用です。 リアルタイムのマルチプレイヤー(ベータ)では、共有スペースで同時にAIチャットを進められます。
デスクトップアプリを入れると、これらの体験がどのアプリからでも呼び出せるようになります。 グローバルショートカットで瞬時に起動するGeneral Assistなど、OS全体に染み出す使い方が加わります。
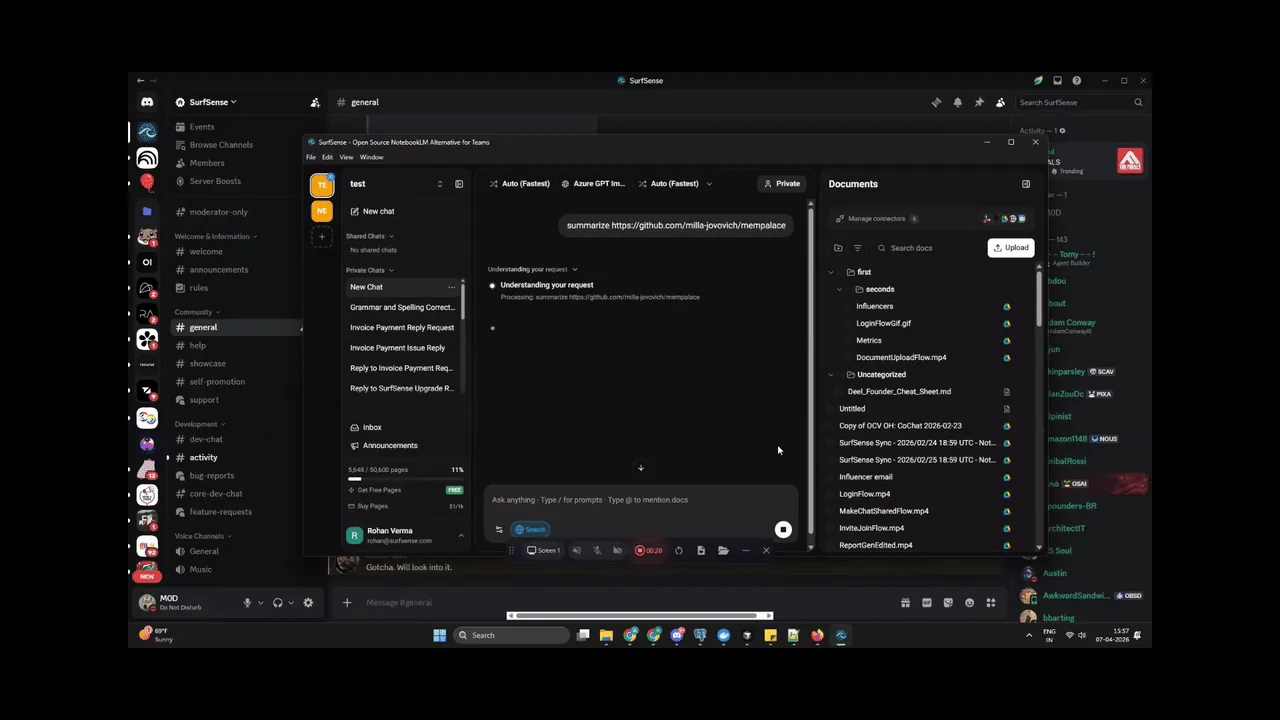
アーキテクチャ・しくみ——コネクタ・ハイブリッド検索・エージェント
SurfSenseの内部は、READMEの記述から「取り込み」「インデックス/検索」「エージェント/生成」の3層に整理できます。 27以上のコネクタとアップロードで集めたデータを、ハイブリッド検索のインデックスに落とし込み、その上でエージェントが検索・生成・書き戻しを行う、という流れです。
Drive / Slack / Notion / GitHub ほか] C2[ファイルアップロード
50以上の形式] C3[ファイル処理
LlamaCloud / Unstructured / Docling] end subgraph IDX[インデックス・検索層] E[埋め込み
6,000以上のモデル] H[ハイブリッド検索
セマンティック + 全文 + RRF再ランク] end subgraph AGENT[エージェント・生成層] A[LangChain Deep Agents
計画・サブエージェント・ファイルシステム] O[Deliverable Studio
レポート / ポッドキャスト / スライド / 画像] WB[ライトバック
Notion / Slack / Linear / Jira / Drive] end C1 --> C3 C2 --> C3 C3 --> E E --> H H --> A A --> O A --> WB
検索の中核は、ハイブリッド検索です。 セマンティック検索と全文検索を組み合わせ、階層インデックスとReciprocal Rank Fusion(RRF)で再ランクします。 意味の近さ(ベクトル)とキーワードの一致を両取りすることで、固有名詞や型番のような「意味ベクトルが苦手な検索」も拾いやすくなります。 埋め込みを使わずに精度を狙うアプローチに興味があれば、Embeddingを捨てるRAG「PageIndex」の解説と読み比べると、RAGの設計選択の幅が見えてきます。
エージェント層は、LangChainの「Deep Agents」で構成されています。 計画(planning)・サブエージェント・ファイルシステムアクセスを持つエージェントが、検索結果をもとにレポートやポッドキャストを生成し、必要に応じてNotionやSlackへ結果を書き戻します。 ファイル処理にローカルで動くDoclingを選べるのも、プライバシー重視の設計を支える要素です。
インストール——クラウドか、Docker一行の自己ホストか
導入は大きく2通りです。 まず試すだけなら、クラウド版が最短です。
・surfsense.com にアクセスしてログインする
・コネクタを接続して同期する(定期同期を有効にすると最新状態を保てる)
・コネクタのインデックスが終わるまでの間に、手元のドキュメントをアップロードする
・インデックスが揃ったら、チャット・検索・レポート生成などで問い合わせる
データを手元に置きたいなら、自己ホストです。 前提としてDocker Desktopがインストールされ、起動している必要があります。 Linux/macOSはワンライナーのインストールスクリプトを実行します。
curl -fsSL https://raw.githubusercontent.com/MODSetter/SurfSense/main/docker/scripts/install.sh | bash
Windowsの場合はPowerShellで次を実行します。
irm https://raw.githubusercontent.com/MODSetter/SurfSense/main/docker/scripts/install.ps1 | iex
インストールスクリプトは、Watchtower を自動でセットアップし、毎日の自動アップデートを行います。
自動更新を避けたい場合は --no-watchtower フラグを付けます。
curl -fsSL https://raw.githubusercontent.com/MODSetter/SurfSense/main/docker/scripts/install.sh | bash -s -- --no-watchtower
本番寄りの自己ホストでは、Watchtowerの自動更新は両刃の剣です。
脆弱性修正をすぐ取り込める一方、production-ready前のプロジェクトでは、破壊的変更が無告知で本番に降ってくるリスクもあります。
重要環境では --no-watchtower で自動更新を切り、バージョンを固定したうえで、更新は手元で検証してから反映するのが安全です。
Docker Compose構成や手動インストールなど、より細かいデプロイ方法は公式ドキュメント(surfsense.com/docs)に記載があります。 デスクトップアプリは、GitHubのlatest releaseからダウンロードできます。
基本的な使い方——コネクタ・チャット・生成・自動化
起動後の流れは、「つなぐ→ためる→聞く→出す」の4段です。
つなぐ段は、コネクタとアップロードです。 Notion・Slack・Google Drive・Gmail・GitHub・Linearなど27以上のソースを1つのコーパスにまとめ、PDF・Officeドキュメント・画像・音声を直接ドロップして即検索可能にします。
聞く段は、検索とチャットです。 ナレッジベース全体に対してハイブリッド検索をかけ、引用付きで回答を得ます。 チームで使う場合は、チャットを共有設定にすればリアルタイムで共同編集でき、AIメッセージにコメントやメンションを付けてやり取りできます。
出す段は、Deliverable Studioとライトバックです。 レポート・ポッドキャスト・スライド/動画・画像を生成し、結果をNotion・Slack・Linear・Jira・Driveへ書き戻せます。 たとえば「この調査サマリをNotionに投稿して」「この議事のアクションをSlackに送って」「このバグ報告からJiraチケットを作って」といった指示が、READMEのプロンプト例として挙げられています。
さらにSurfSenseは、自動化を3種類用意しています。
・スケジュール実行:エージェントを定時で動かす。毎朝のブリーフ、毎週のダイジェスト、定例レポートなど
・イベント駆動:特定フォルダに文書が入った瞬間にエージェントを発火させ、結果をツールへ投稿する
・チャットで作る自動化:作りたい自動化を平易な言葉で説明すると、SurfSenseがノーコードで組み立てる
「研究フォルダにPDFが入ったら引用付きの要約を作る」「請求書がアップされたら取引先・金額・支払期日を表に抽出する」といったトリガーを、コードを書かずに設定できます。 これは、NotebookLMが「調査・学習」に最適化されているのに対し、SurfSenseが「ワークフローの土台」を志向していることの表れです。
ユースケース——どこに効くか
READMEの機能群から、現実的に効く使い方を整理します。
・社内ナレッジの横断検索:Slack・Notion・Drive・GitHubを1つのコーパスに統合し、引用付きで「どこに何が書いてあるか」を即答させる
・データを外に出せない組織の調査基盤:ローカルLLM(vLLM/Ollama)+Doclingで自己ホストし、機微な文書を内側に閉じたままレポート化する
・定例レポートの自動生成:スケジュール実行で、SlackとGmailから週次ステータスを毎週金曜にまとめさせる
・チームの共同調査:共有スペースでリアルタイムにAIチャットを進め、コメントとメンションで議論を残す
・素材の多形態展開:同じソースからレポート・ポッドキャスト・スライドを作り分け、読む人・聞く人・見る人に届ける
ポイントは、これらが「データを手元に置いたまま」成立する点です。 NotebookLMの体験を気に入りつつ、データ所在やLLM固定が引っかかっていたチームほど、自己ホストの価値が効いてきます。 ローカル推論をどこまで現実的に回せるかを見極めたい場合は、Ollamaでローカルにツールを動かす実例も参考になります。
SurfSense と Google NotebookLM の比較
SurfSense自身がREADMEで、NotebookLMとの比較表を提示しています。 ここでは主要な観点を抜き出して整理します。 SurfSenseに有利な項目だけでなく、NotebookLMが優れる項目もREADMEが認めている点に注目してください。
| 観点 | Google NotebookLM | SurfSense |
|---|---|---|
| ノートブックあたりのソース数 | 50(無料)〜600(Ultra, $249.99/月) | 無制限 |
| ノートブック数 | 100(無料)〜500(有料) | 無制限 |
| 1ソースの容量上限 | 50万語 / 200MB | 上限なし |
| 料金 | 無料枠あり、Pro $19.99/月、Ultra $249.99/月 | 無料・OSS、自分のインフラで自己ホスト |
| LLM | Google Geminiのみ | OpenAI仕様・LiteLLM経由で100以上 |
| ローカル/プライベートLLM | 非対応 | 対応(vLLM・Ollama) |
| 自己ホスト | 不可 | 可(Docker一行 / Compose) |
| 外部コネクタ | Drive・YouTube・Webサイト | 27以上(検索エンジン・Drive・Slack・Notion・GitHubほか) |
| 検索 | セマンティック検索 | ハイブリッド検索(セマンティック+全文・RRF) |
| リアルタイム共同編集 | 共有はViewer/Editor(リアルタイムチャットなし) | RBAC+リアルタイムチャット・コメント |
| 動画生成 | Veo 3のシネマティック動画(Ultraのみ)— NotebookLMが優位 | 対応(READMEは「改善中」と明記) |
| ポッドキャスト生成 | カスタマイズ可能な音声概要 — NotebookLMが優位 | 対応(複数TTS、READMEは「改善中」と明記) |
| 自動化・エージェント | なし | スケジュール/イベント/チャット駆動+ライトバック |
表から読み取れるのは、SurfSenseが「制限・データ所在・拡張性」で明確に優位を取り、「仕上がりの良い動画・ポッドキャスト」ではNotebookLMに譲る、というすみ分けです。 READMEがNotebookLM優位の項目を隠さず認めているのは、誠実さの表れであると同時に、SurfSenseの狙いが「派手な生成物」ではなく「制限なく自分のデータを扱える基盤」にあることを示しています。
制限と注意点
便利さの裏側として、採用前に押さえるべき注意があります。 READMEの記述に基づいて挙げます。
第一に、成熟度です。 READMEは「activelyに開発中で、まだproduction-readyではない」と明言しています。 コア機能は揃っていますが、仕様や挙動が短期間で変わる可能性があります。 本番採用ならバージョン固定と検証フローが前提になります。
第二に、生成物の品質差です。 前掲の比較表どおり、動画とポッドキャストの仕上がりはNotebookLMが上だとREADME自身が認めています。 「見栄えのする動画やスライドをそのまま配布したい」用途では、現時点でNotebookLMのほうが向く場面があります。
第三に、運用の自己責任です。 自己ホストの自由は、インフラ・モデル・更新の管理責任を自分で負うことと表裏一体です。 特にWatchtowerの自動更新は、production-ready前のプロジェクトでは破壊的変更を本番に持ち込むリスクになり得ます。
要するにSurfSenseは「制限とベンダーロックインを外す代わりに、運用責任を引き受ける」トレードオフのツールです。 データを外に出せない・LLMを選びたい・無制限に使いたい——この3つのいずれかが強い動機なら有力候補ですが、すぐ使える完成品を求めるなら、まずはクラウド版で感触を掴んでから自己ホストに進むのが堅実です。
まとめ——「制限のないNotebookLM」を自分の手元で
SurfSenseは、NotebookLMの制約(ソース数・ノートブック数・容量・Gemini固定・連携の少なさ・マルチプレイヤー非対応)を、無制限・自己ホスト・LLM自由・27以上のコネクタ・リアルタイム共同編集という形で置き換えるApache-2.0のOSSです。 ハイブリッド検索で引用付きの回答を返し、レポート・ポッドキャスト・スライド・画像の生成、さらにスケジュール/イベント/チャット駆動の自動化までを1つに束ねています。
一方で、まだproduction-readyではなく、動画やポッドキャストの仕上がりはNotebookLMに譲る、という現在地もREADMEは隠していません。 それでも「データを自分のインフラに置いたまま、制限なくチームのナレッジを扱いたい」というニーズに対しては、現時点で数少ない実用的な選択肢です。
まずはクラウド版で体験し、手応えがあればローカルLLM+Docling構成の自己ホストへ——という段階的な進め方が、リスクを抑えつつSurfSenseの強みを引き出す近道になります。 PDFやドキュメントを扱う他のツールと並べて検討したい場合はAI PDF要約ツール8選を、RAGの設計選択を深掘りしたい場合はPageIndexの解説もあわせて参照してください。
参照ソース
・MODSetter/SurfSense — GitHub リポジトリ・README(一次ソース)
・SurfSense 公式サイト・ドキュメント