ドキュメントから知識を抜き出してナレッジグラフやRAGに流し込む——この作業は、やるたびに「抽出ロジックを書き直す」コストがのしかかります。 人物伝記、決算資料、論文、契約書では抜き出したい構造がまるで違い、出力の型もばらばらになりがちです。 そこを「文書を投げると、選んだ型の知識構造が返ってくる」形に作り替えるのが、非構造テキストを8種の知識構造に変えるLLM抽出OSS「Hyper-Extract」です。
30秒で理解する Hyper-Extract
・LLMで非構造テキストを、Model・List・Set・Graph・Hypergraph・Temporal/Spatial/Spatio-Temporal Graphという8種の強く型付けされた「知識抽象」に変換するOSS。タグラインは “Stop reading. Start understanding.”
・GraphRAG・LightRAG・Hyper-RAG・KG-Gen・Cog-RAG・ATOMなど10以上の抽出エンジンと、Finance/Legal/Medical/TCM/Industry/Generalの80以上のドメインテンプレートを-tで切り替えられる
・he parseで抽出、he searchで問い合わせ、he showで可視化、という対話CLIで完結。Python APIも用意される
・OpenAI(gpt-5含む)・Alibaba・ローカルvLLMに対応。Apache-2.0・Python 3.11+・1.1k★。v0.2.0で統一プロバイダーシステムを導入
知識をグラフ化してLLMに渡す発想そのものに関心があるなら、まずRAGとは?仕組み・構築・ベクトルDB選定までの2026年実装マップで「検索して文脈を渡す」基本を押さえておくと、本記事のHyper-Extractが「RAGに食わせる知識構造を作る前段の道具」だとすっきり読めます。
理屈より先に全体像を見たほうが速いので、公式READMEの代表ビジュアルを冒頭に置きます。
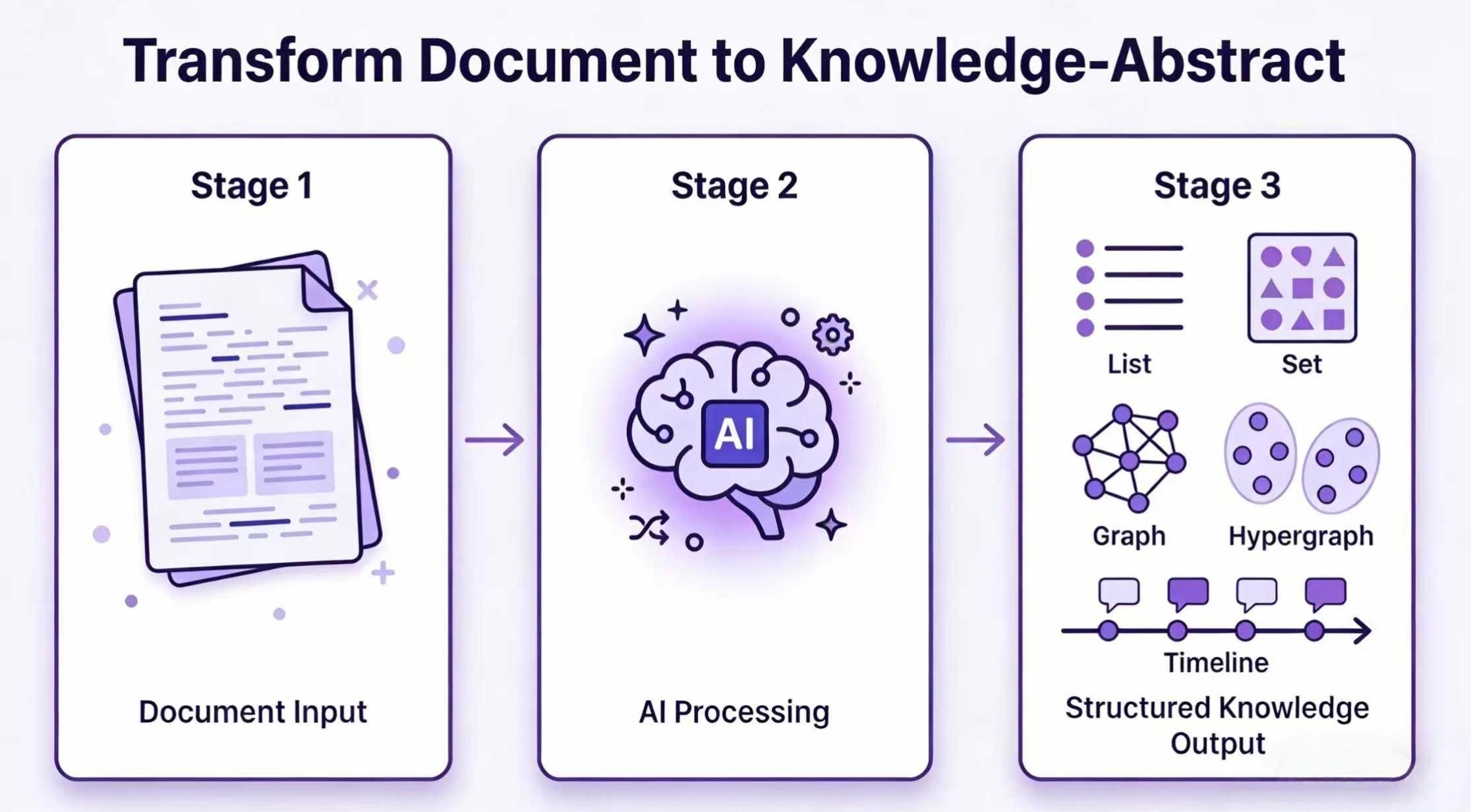
Hyper-Extract とは何か——テキストを「知識抽象」に変える抽出フレームワーク
Hyper-Extractは、yifanfeng97が開発する「インテリジェントでLLM駆動の知識抽出・進化フレームワーク(intelligent, LLM-powered knowledge extraction and evolution framework)」です。 公式の説明では、その役割を「非構造なテキストを、持続的で・予測可能で・強く型付けされた『知識抽象(Knowledge Abstracts)』へ変換する作業を、根本から単純化する」ものと位置づけています。 言い換えれば、ばらばらの文書を「あとから機械的に扱える型のついた知識」に落とし込むための専用ツールです。
ポイントは「知識抽象」という考え方にあります。 ふつう、テキストから情報を抜き出すと、出力はモデルやプロンプトに左右されて毎回ぶれます。 Hyper-Extractは出力を8種類の決まった型(後述のAuto-Types)に固定するため、「同じ文書を同じテンプレートで処理すれば、同じ形の構造が返る」予測可能性を確保しています。 これにより、抽出結果をそのままプログラムやRAGパイプラインに流し込める設計になっています。
リポジトリはPython 100%で書かれ、ライセンスはApache-2.0、Python 3.11以上が必要です。 2026年6月時点で1.1k★・126フォークを集め、3つのリリースが公開されています。 最新はv0.2.0「Unified Provider System」で、2026年5月18日にリリースされました。 ドキュメントは公式サイト(yifanfeng97.github.io/Hyper-Extract/latest/)に整備され、CLIガイド・プロバイダーシステム・テンプレートギャラリー・実例が読めます。
開発者のyifanfeng97はハイパーグラフ関連の研究を背景に持ち、抽出エンジンのひとつに「Hyper-RAG」が含まれるなど、ハイパーグラフを第一級の知識構造として扱う設計思想がプロジェクト全体に通っています。 単なるナレッジグラフ抽出ツールではなく、「グラフの上位概念であるハイパーグラフや時空間グラフまで標準で扱う」点が、この道具の個性です。
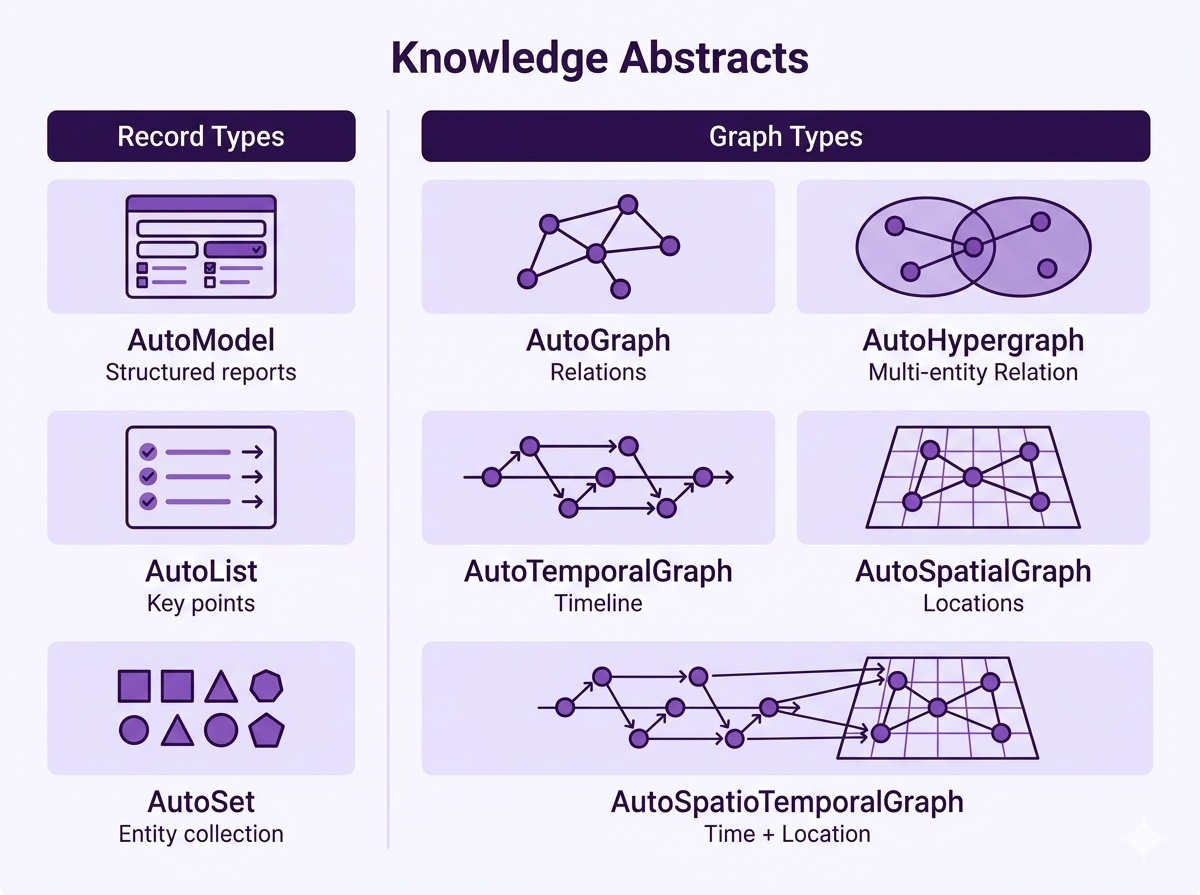
ギャラリー——8つの知識構造と可視化を README 画像で見る
Hyper-Extractの中心は「どんな型で知識を取り出すか」です。 公式READMEに載っている代表的な図を並べ、それぞれが何を表しているのかを掴みます。
まず、8種の知識構造(Auto-Types)を俯瞰するマトリクスです。 単純なModel/List/Setから、Graph・Hypergraph、さらにTemporal Graph・Spatial Graph・Spatio-Temporal Graphまで、扱える「知識の型」が一覧で示されています。
次に、抽出した知識をhe showで可視化した画面です。
he parseでテキストから生成したグラフを、ノードとエッジのインタラクティブな図として確認できます。
「抽出して終わり」ではなく、その場で構造を眺めながら確かめられるのが対話CLIとしての強みです。
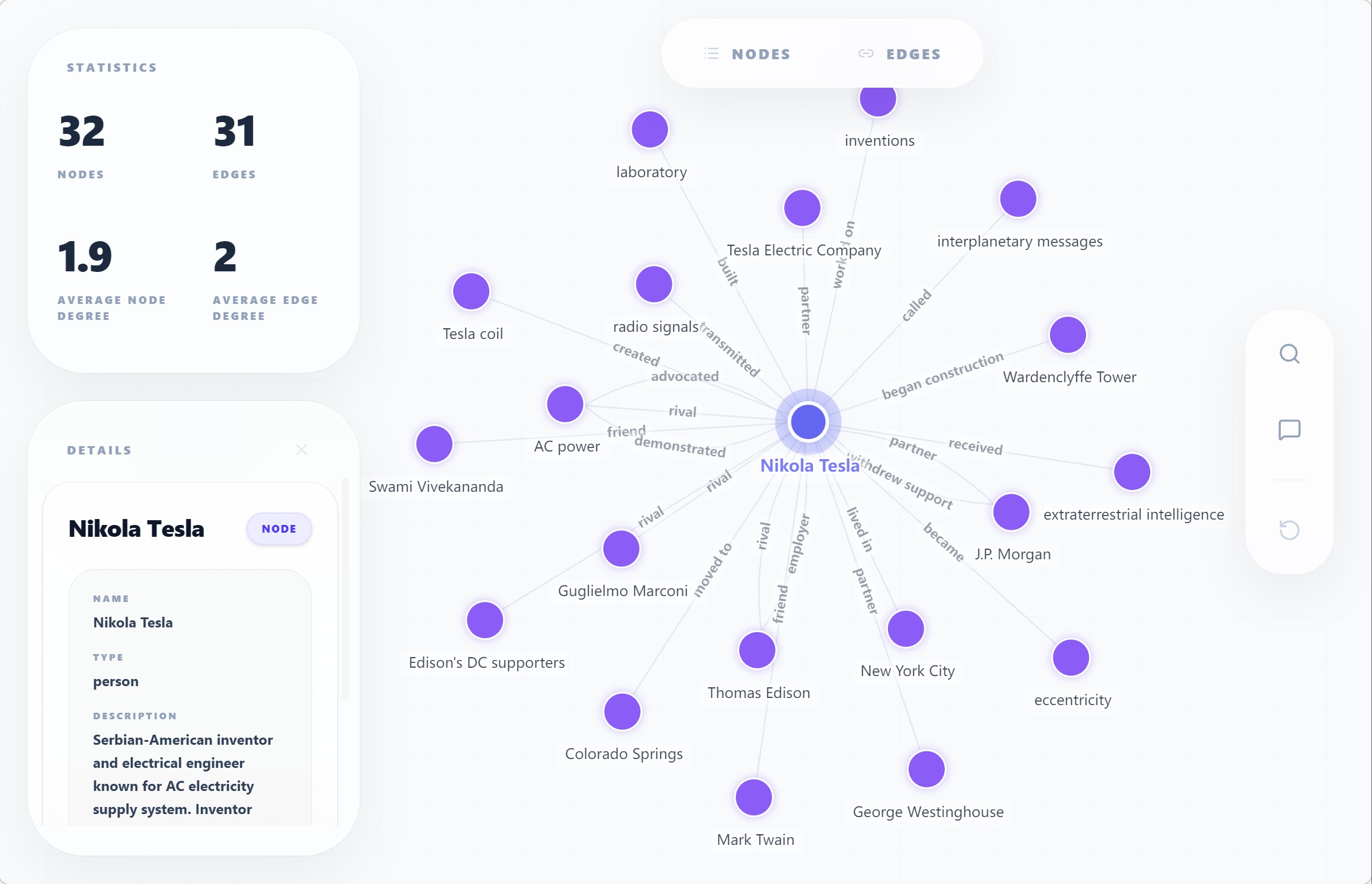
これら2枚は「入力(非構造テキスト)」と「出力(型のついた知識構造)」の両端を表しています。 Hyper-Extractがやっているのは、その間を「テンプレート+抽出エンジン」で橋渡しする一連の処理です。 次の章で、その橋渡しのアーキテクチャを見ていきます。
アーキテクチャ・しくみ——Auto-Types・Methods・Templates の3層構造
Hyper-Extractの設計は、公式の説明によれば3つの層に分かれています。 「型(Auto-Types)」「手法(Methods)」「設定(Templates)」を分離することで、抽出の中身を差し替えやすくしているのが要点です。
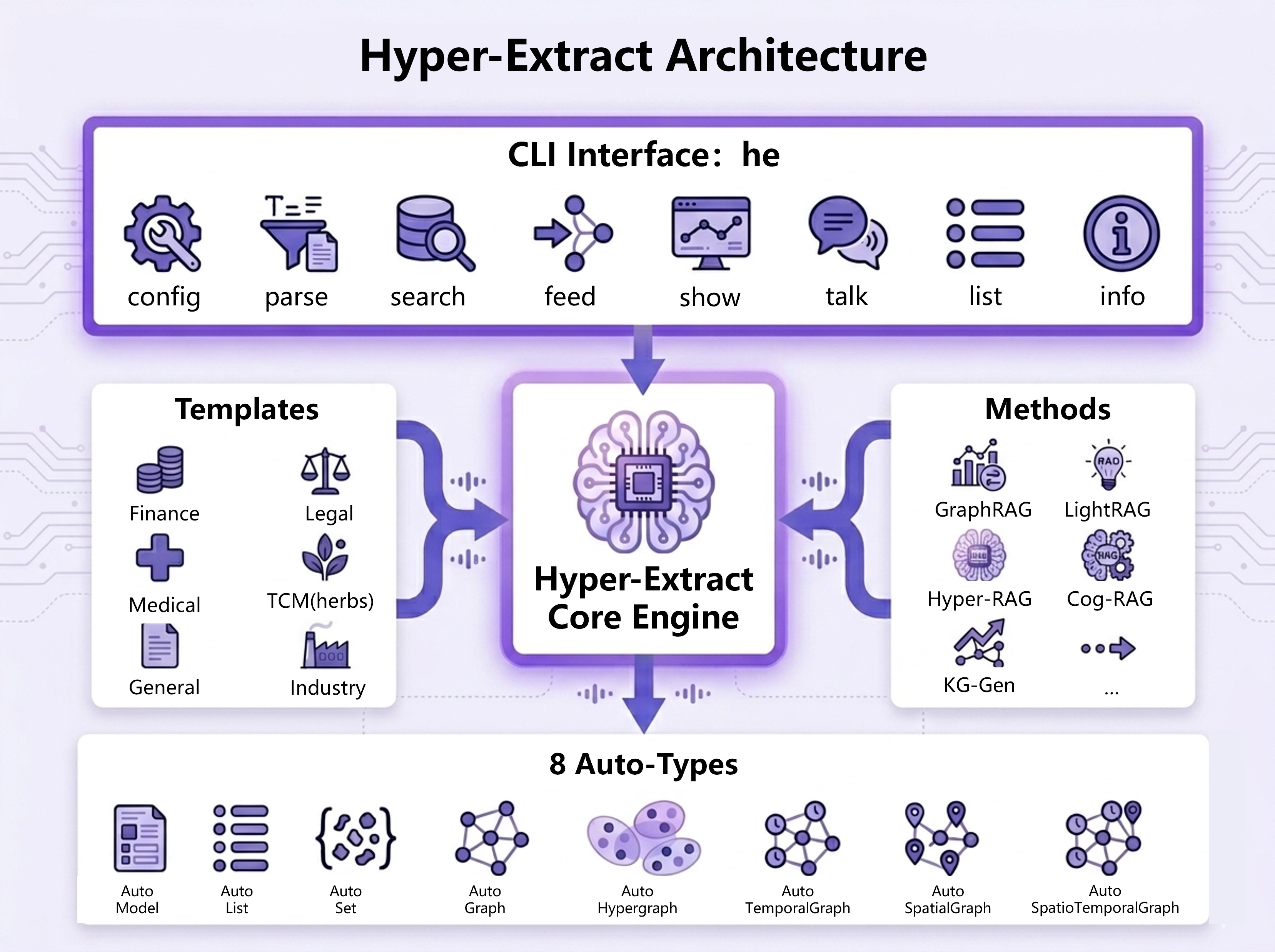
3層をひとことで整理すると、次のようになります。
・Auto-Types:8種の強く型付けされたデータ構造(Model・List・Set・Graph・Hypergraph・Temporal Graph・Spatial Graph・Spatio-Temporal Graph)。出力の「型」を定義する層
・Methods:実際に抽出を行うアルゴリズム群。KG-Gen・GraphRAG・LightRAG・Hyper-RAG・Cog-RAG・ATOMなど10以上のエンジンが含まれる
・Templates:Finance・Legal・Medical・TCM・Industry・Generalなどドメイン別の80以上のYAMLプリセット。どの型をどの手法で抽出するかを宣言的に束ねる層
この分け方が効くのは、「型・手法・ドメイン設定」を独立に組み替えられる点です。
たとえば同じ文書でも、テンプレートをgeneral/biography_graphからfinance/earnings_graphに変えれば、抽出される構造もドメインに合わせて変わります。
抽出手法を差し替えたいときも、Pythonでロジックを書き直すのではなく、テンプレート側の宣言を変えるだけで済みます。
このパイプライン全体を図にすると、入力から知識構造までの流れは次のように整理できます。
PDF・Markdown・論文・決算資料] --> TPL[Template
80+ YAMLプリセット
Finance/Legal/Medical/General] TPL --> METHOD[Method
抽出エンジン
GraphRAG/LightRAG/Hyper-RAG/KG-Gen] METHOD --> TYPE[Auto-Type
8種の知識構造
Graph/Hypergraph/Temporal Graph] TYPE --> KA[Knowledge Abstract
強く型付けされた知識] KA --> SEARCH[he search
問い合わせ] KA --> SHOW[he show
可視化] KA --> EVOLVE[追加文書で
知識を進化・拡張]
図の右端にある「知識の進化(evolution)」も、このツールの名前に含まれる重要な機能です。 公式の説明では「いつでも新しい文書を投入し、知識ベースを拡張・洗練できる(Feed new documents anytime to expand and refine your knowledge base)」とされています。 一度作った知識構造に文書を追加していくと、ナレッジベースが増分的に成長していく——静的な「一発抽出」ではなく、育てられる知識ベースを志向した設計です。
インストールと起動——uv で入れて he config から始める
導入はCLIを入れるところから始めます。
公式のクイックスタートでは、uvを使ったツールインストールが案内されています。
# CLIをインストール(uv tool)
uv tool install hyperextract
# APIキーを設定(OpenAIの例)
he config init -k YOUR_OPENAI_API_KEY
uvはPython製の高速パッケージマネージャで、uv tool installはCLIツールを隔離環境に入れるコマンドです。
これでheコマンドが使えるようになります。
he config initでは、抽出に使うLLMプロバイダーのAPIキーを登録します。
Hyper-ExtractはPython 3.11以上が前提です。 プロバイダーとしてOpenAIのほか、阿里云百炼(Alibaba)やローカルのvLLMにも対応するため、APIキーの代わりにローカルモデルのエンドポイントを設定する運用も可能です。 ローカル完結にしたい場合は、後述のvLLM(Qwen3.5-9B)を立ててそちらを指す構成になります。
設定が済んだら、付属のサンプル文書で動作を確認できます。
公式のクイックスタートは、テスラの伝記サンプル(examples/en/tesla.md)を人物伝記グラフのテンプレートで抽出する例を示しています。
# テスラの伝記を「人物伝記グラフ」テンプレートで抽出し、./output/ に保存
he parse examples/en/tesla.md -t general/biography_graph -o ./output/ -l en
-tでテンプレート、-oで出力先ディレクトリ、-lで言語を指定します。
このコマンド一発で、非構造なmarkdownが「人物・出来事・関係」を持つ知識グラフに変換されます。
基本的な使い方——parse・search・show の3コマンドで完結
Hyper-Extractの操作は、突き詰めると「抽出する・問い合わせる・見る」の3つです。
それぞれCLIのhe parse/he search/he showに対応します。
まずhe parseで文書を知識構造に変えます。
入力はmarkdownだけでなくPDFなども扱え、テンプレートを変えればドメインに応じた抽出ができます。
# 論文PDFを「学術グラフ」テンプレートで抽出
he parse paper.pdf -t general/academic_graph -o ./paper_kb/
# 決算資料を「決算グラフ」テンプレートで抽出
he parse earnings.md -t finance/earnings_graph -o ./finance_kb/
抽出した知識ベースにはhe searchで自然言語の質問を投げられます。
グラフ構造を背景に、出典をたどれる形で回答が返るのが、ただのベクトル検索との違いです。
# テスラの主要な業績を問い合わせる
he search ./output/ "What are Tesla's major achievements?"
# 決算資料から主要なリスク要因を問い合わせる
he search ./finance_kb/ "What are the key risk factors?"
最後にhe showで、抽出した構造を可視化します。
ノードとエッジのインタラクティブな図として表示され、抽出が意図どおりかをその場で確かめられます。
# 抽出済みの知識ベースを可視化
he show ./output/
CLIだけでなく、Pythonからも同じことができます。
プログラムから抽出パイプラインに組み込みたい場合は、Templateクラスを使います。
from hyperextract import Template
# テンプレートからパイプラインを作る
ka = Template.create("general/biography_graph")
# テキストを渡して抽出
with open("examples/en/tesla.md") as f:
result = ka.parse(f.read())
# 結果を可視化
result.show()
Template.create()でテンプレートに対応した抽出器を作り、.parse()にテキストを渡すと知識抽象(Knowledge Abstract)が返ります。
返ってきたオブジェクトは強く型付けされているため、.show()で表示するだけでなく、そのままアプリケーションのデータとして扱えます。
CLIで素早く試し、固まったらPython APIでパイプラインに組み込む——という二段構えが想定された作りです。
対応モデルとプロバイダー——OpenAI・Alibaba・ローカル vLLM
抽出の品質はLLMに左右されるため、どのモデルを使えるかは実用上の要です。 Hyper-Extractは複数のプロバイダーに対応し、v0.2.0で導入された「統一プロバイダーシステム(Unified Provider System)」によって横断的に切り替えやすくなっています。
対応するモデル・埋め込みを整理すると次のとおりです。
・OpenAI:gpt-4o・gpt-4o-mini・gpt-5。クラウドで手軽に高品質な抽出をしたいときの標準的な選択肢
・阿里云百炼(Alibaba):qwen-plus・qwen-turbo・deepseek-r1。中国語ドキュメントや推論重視のdeepseek-r1を使いたいときに
・ローカルvLLM:Qwen3.5-9B(GPTQ-Marlin量子化)。データを外に出さずローカル完結で動かしたいとき
・埋め込みモデル:text-embedding-3-small・bge-m3・text-embedding-v4。検索や意味的な突き合わせに使う
ローカルvLLMに対応している点は、機密文書を扱う現場では大きな意味を持ちます。 契約書や医療記録、社内資料といった「クラウドに出しにくいテキスト」でも、自前のGPUでQwen3.5-9Bを動かせば、抽出処理を組織内に閉じ込められます。 TCM(中医学)やMedical、Legalといったドメインテンプレートが用意されているのも、こうした専門・機密領域での利用を見据えた構成だと読み取れます。
クラウドとローカルを使い分けられるため、「まずOpenAIのgpt-5で精度を確かめ、本番は機密性に応じてローカルvLLMに寄せる」といった段階的な運用も組めます。
ユースケース——論文・決算・専門ドメインの知識ベース化
Hyper-Extractが向くのは、「同じ型の知識を、文書から繰り返し抜き出したい」場面です。 公式の例とテンプレート構成から、現実的な使いどころを整理します。
・学術論文の知識ベース化:general/academic_graphなどで論文群をグラフ化し、he searchで「この手法の前提は?」と横断的に問い合わせる。サーベイや文献整理の下地になる
・金融・決算分析:finance/earnings_graphで決算資料をグラフ化し、リスク要因や業績の関係を構造として取り出す。複数期・複数社を同じ型で比較できる
・専門ドメインの構造化:Legal(法務)・Medical(医療)・TCM(中医学)・Industry(産業)のテンプレートで、専門文書をドメイン特化の知識構造に変える
・時系列・空間を含む知識:Temporal GraphやSpatial Graph、Spatio-Temporal Graphを使えば、「いつ・どこで」の関係を持つ知識を型として保持できる
・RAGの前段としての構造化:抽出した知識グラフ/ハイパーグラフを、GraphRAG的な検索拡張生成の入力に使う
特に「RAGの前段」としての位置づけは押さえておきたいところです。 ベクトル検索だけのRAGは、文書を細切れにして類似度で引くため、要素どうしの関係が落ちがちです。 Hyper-Extractでグラフやハイパーグラフに構造化しておけば、関係を保ったまま検索できる土台が作れます。 RAGの発展形をもう少し体系的に知りたい場合は、RAGの進化|Naive・Advanced・Graph・Agentic RAGの仕組みと選び方2026が、Graph RAGがどの位置づけにあるかを整理するうえで参考になります。
類似OSS比較——GraphRAG・LightRAG との立ち位置
知識抽出・グラフ化のツールは複数ありますが、「扱える知識構造の幅」と「ドメインテンプレート」という軸で見ると、Hyper-Extractの立ち位置がはっきりします。 代表的なツールと並べて整理します。
| ツール | 主な出力構造 | ハイパーグラフ/時空間 | ドメインテンプレート | 位置づけ |
|---|---|---|---|---|
| Hyper-Extract | 8種(Model〜Spatio-Temporal Graph) | 標準対応(Hypergraph・Temporal・Spatial) | 80+(Finance/Legal/Medical/TCM/Industry/General) | 多数の型・エンジンを束ねる抽出フレームワーク |
| GraphRAG | 知識グラフ中心 | 非対応(通常グラフ) | 限定的 | グラフ抽出+検索拡張生成に特化 |
| LightRAG | 知識グラフ中心 | 非対応(通常グラフ) | 限定的 | 軽量なグラフRAG実装 |
| KG-Gen | 知識グラフ | 非対応 | 限定的 | テキストからのKG生成手法 |
| Hyper-RAG | ハイパーグラフ | ハイパーグラフ対応 | 限定的 | ハイパーグラフを使う検索拡張 |
この表で効いてくるのは、Hyper-Extractがこれらの多くを「抽出エンジンのひとつ」として内側に取り込んでいる点です。
GraphRAG・LightRAG・KG-Gen・Hyper-RAGはそれぞれ単体の手法ですが、Hyper-Extractはそれらをテンプレートの-t指定で切り替えながら、共通の8種の型に出力をそろえます。
公式の比較でも、ナレッジグラフ・時間グラフ・空間グラフ・ハイパーグラフ・ドメインテンプレート・対話CLI・多言語対応を同時に満たすことが、GraphRAGやLightRAGに対する差別化点として示されています。
つまり選び方はこうなります。 「とにかく軽くグラフRAGを試したい」ならGraphRAGやLightRAG単体が近道です。 一方で「ハイパーグラフや時空間グラフまで含め、複数の抽出手法を1つの型体系で扱いたい」「ドメイン別テンプレートで抽出を量産したい」なら、Hyper-Extractのフレームワーク的な作りが刺さります。
なお、知識グラフをコードベース理解に応用した近い発想のOSSとしては、CodeGraph完全解説|Claude Codeのツールコール71%削減・コスト35%節約するローカル知識グラフOSSも、「テキスト(コード)を知識グラフに変えてLLMの文脈に効かせる」という点で読み比べる価値があります。
制限と注意点——若いプロジェクトと抽出品質の裏取り
設計の魅力とは別に、導入前に押さえておきたい現実的な制約もあります。
・プロジェクトが若い:3リリース・最新v0.2.0(2026年5月)と新しく、1.1k★とアクティブではあるものの、長期運用での安定性やAPIの後方互換性の実績はこれから。バージョンアップ時の挙動変化には注意したい
・抽出品質はモデル依存:知識構造の正確さは、選んだLLM・埋め込みモデルに左右される。gpt-5とローカルのQwen3.5-9Bでは抽出結果に差が出るため、用途に応じたモデル選定が要る
・LLMコスト・計算資源:クラウドを使えばAPIコストが、ローカルvLLMを使えばGPUなどの計算資源が必要。大量文書を抽出するほど効いてくる
・生成物の裏取りは必須:LLM抽出である以上、関係の取り違えや抜けは起こりうる。出力された知識構造は、引用元の文書と突き合わせて検証する前提で使う
・プロバイダー側の規約:OpenAIやAlibabaなど、利用するLLMプロバイダーの利用規約は本体のApache-2.0とは別。機密文書を扱う場合はデータの送信先を含めて確認する
逆に言えば、これらは「若いLLM抽出フレームワーク」という性格から素直に導かれる制約です。 抽出ロジックを毎回書き直すコストを下げ、複数の知識構造を1つの型体系で扱いたい——という動機が強いほど、現時点でも十分に試す価値があります。
まとめ——「型のついた知識」を量産するための土台
Hyper-Extractの本質は、非構造なテキストから「あとから機械的に扱える、型のついた知識」を繰り返し取り出せるようにする点にあります。 Auto-Types(型)・Methods(手法)・Templates(ドメイン設定)の3層に分けることで、抽出の中身を組み替えやすくし、Model〜Spatio-Temporal Graphまでの8種を共通の出力体系にそろえています。
・LLMで非構造テキストを、8種の強く型付けされた知識構造(List・Graph・Hypergraph・時空間グラフ等)に変換するOSS
・GraphRAG・LightRAG・Hyper-RAGなど10以上の抽出エンジンと、80以上のドメインテンプレートをhe parse -tで切り替えられる
・he parse/he search/he showの対話CLIとPython APIの二段構え。追加文書で知識ベースを進化・拡張できる
・OpenAI(gpt-5含む)・Alibaba・ローカルvLLMに対応。Apache-2.0・Python 3.11+・1.1k★のアクティブなOSS
誰に向くかを最後に整理します。 論文・決算・専門文書から「同じ型の知識」を何度も抜き出したい人、GraphRAGより広い知識構造(ハイパーグラフ・時空間グラフ)を扱いたい人、そして抽出結果をそのままRAGやアプリのデータに流したい人——この条件が当てはまるほど、Hyper-Extractのフレームワーク的な設計はまっすぐ刺さります。 逆に、単機能で軽いグラフRAGを最短で試したいだけなら、GraphRAGやLightRAG単体のほうが近道です。
まずはuv tool install hyperextractでCLIを入れ、付属のテスラ伝記サンプルをgeneral/biography_graphで抽出し、he showで可視化してみるのがおすすめです。
非構造なテキストが「ノードとエッジを持つ知識」に変わる瞬間を見ると、このツールが解こうとしている問題の手触りが一番よく分かります。
抽出した知識構造を実際の検索拡張生成にどう活かすかまで踏み込みたいなら、RAGとは?仕組み・構築・ベクトルDB選定までの2026年実装マップと合わせて読むと、「RAGの前段としての知識抽出」というHyper-Extractの役どころが立体的に見えてきます。
参照ソース
・yifanfeng97/Hyper-Extract — GitHubリポジトリ(README・アーキテクチャ・ライセンス・スター数)
・Hyper-Extract 公式ドキュメント(yifanfeng97.github.io/Hyper-Extract/latest/)
・hyperextract — PyPI(パッケージ配布)