Anthropicが2026年6月9日、Claude Fable 5とClaude Mythos 5をペアで公開した。Fable 5は同社が広く提供する中で最も高性能なモデルで、これまで政府協議のもとで限定提供されてきた未公開モデル「Mythos」と同じ系統、Mythos級(Mythos-class)を、一般ユーザーが初めて触れられるようになった。公式動画でAnthropicは「これまで一般公開した中で最も高性能なモデル」と表現している。
Mythos級はOpus・Sonnet・Haikuの上に位置する能力帯だ。Fable 5とMythos 5は同じ基盤モデルで、違いは安全策の有無にある。Fable 5はサイバー・生物・蒸留の3領域に安全分類器を組み込んだ一般公開版、Mythos 5は一部の安全分類器を解除した最大性能版で、Project Glasswing経由の限定提供だ。後述の公式ベンチマークでも、cyber/bio系の項目ではFable 5がフォールバックによってOpus 4.8寄りのスコアになり、Mythos 5との差が開く。
本記事はAnthropicの公式発表・APIドキュメント・公式ベンチマーク表・公式紹介動画のみを根拠に、Claude Fable 5とMythos 5の位置づけ・性能・価格・既存モデルとの違い・使い分けを整理する。推測値や噂、個人の感想は扱わず、公称されていない数値は「公式未公表」と明記する。
公開直後の6月12日、米政府の輸出規制でFable 5とMythos 5は約2.5週間全ユーザー停止された。6月30日に規制解除、7月1日に再開済みで、現在は通常どおり利用できる。本記事の価格・利用方法セクションは再開後の情報に更新済み。停止の経緯は後述および関連記事で扱う。
モデル選択の考え方そのものを学びたい方は モデル選択の実践科学|Code with Claude LondonでLucasが語るEval・コスト最適化 もあわせてご覧ください。
30秒で理解する Claude Fable 5 / Mythos 5
・何者か:同じ基盤の「Mythos級」ペアモデル。Fable 5=安全分類器入りの一般公開版(claude-fable-5)、Mythos 5=最大性能の限定版(claude-mythos-5)
・性能:SWE-Bench Pro 80.3%、Terminal-Bench 2.1 88.0%、HLE(ツールあり)64.5%などをAnthropicが公称。多くの項目でOpus 4.8・GPT-5.5・Gemini 3.1 Proを上回る
・価格と注意点:入力$10/出力$50(Opus 4.8の2倍)。適応的思考が常時オンで、Fable 5はサイバー・生物の要求をOpus 4.8へフォールバックする
Claude Fable 5とは——Anthropic初の一般公開Mythos級モデル
Claude Fable 5は、Anthropicが「最も高性能な広く提供するモデル(most capable widely released model)」と位置づけるモデルだ。設計思想は明確で、長時間の自律的な作業(long-horizon agentic work)と、最も要求の厳しい推論に向いている。
ここで鍵になるのがMythos級という言葉だ。AnthropicのモデルはこれまでOpus・Sonnet・Haikuの3階層で語られてきたが、Mythos級はそのOpusのさらに上に置かれる能力帯を指す。元になった「Mythos」は、サイバー攻撃・防御に関わる強力な能力ゆえに政府との協議下で限定提供されてきた未公開モデルだった。Claude Fable 5は、その能力を保ったまま安全策を組み込み、一般に開放した最初のモデルにあたる。
Mythosがこれまで一般公開されてこなかったのは、サイバー攻撃・防御に直結する能力が突出していたためだ。公式紹介動画でAnthropicは、前世代の「Claude Mythos Preview」が数千件のサイバーセキュリティ脆弱性を発見していたため広くは公開せず、世界の重要ソフトウェアを守る人々に渡して脆弱性の修正に充てた、と説明している。「欠陥を見つけられるモデルは、それを悪用することもできる」からだ。Claude Fable 5の登場は、その制限を安全分類器という形で技術的に担保しながら、一般提供へ踏み出した転換点にあたる。
公式動画はFable 5の設計思想も語る。「問題に、これまでのどのモデルより長く取り組み続けられる。高度に自律的で、人の介入なしに何日も動ける」とされ、用途もコーディングにとどまらず金融・研究・経済・法務といった「常時の監督が必要だった複雑なタスク」に及ぶという。
同時に、AnthropicはMythos 5(モデルID claude-mythos-5)も発表した。これはFable 5とまったく同じ基盤モデルだが、一部領域で安全分類器を解除した版で、Project Glasswingを通じて承認された顧客にのみ限定提供される。Mythos 5は招待制の「Claude Mythos Preview」の後継にあたり、サイバー防御者やインフラ事業者が主な対象だ。一般ユーザーが使えるMythos級はFable 5のみ、と理解すればよい。
FableとMythosの関係を一言で
・Mythos 5=素のMythos級モデル(セーフガードを一部解除、Project Glasswingで限定提供)
・Fable 5=同じモデルに安全分類器を被せた一般公開版
・両者は同じ能力・同じ価格・同じ1Mコンテキスト。違いは「誰が使えるか」と「どこまで答えるか」だけ
下図はAnthropicの現行モデル系統を俯瞰したものだ。Claude Fable 5とMythos 5が、従来のOpus/Sonnet/Haikuの上位にMythos級として加わった構図がわかる。
モデルファミリー"] --> B["Mythos級
最上位・最高性能"] A --> C["Opus級
高度な推論・コーディング"] A --> D["Sonnet級
速度と知能のバランス"] A --> E["Haiku級
最速・準フロンティア"] B --> B1["Claude Mythos 5
最大性能 / 限定提供 / Project Glasswing"] B --> B2["Claude Fable 5
一般公開 / 安全分類器あり"] B --> B3["Claude Mythos Preview
前世代 / 招待制"] C --> C1["Claude Opus 4.8"] D --> D1["Claude Sonnet 4.6"] E --> E1["Claude Haiku 4.5"]
ベンチマーク——公式15項目でOpus 4.8・GPT-5.5・Geminiを上回る
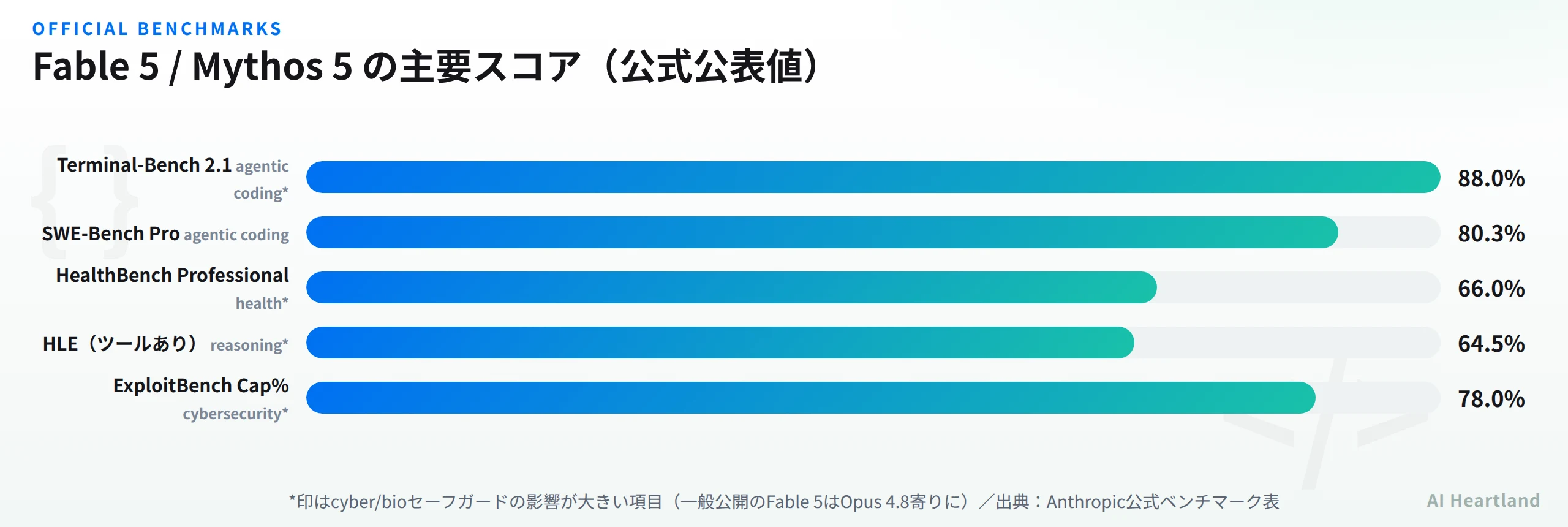
Anthropicは公式インフォグラフィックで、Mythos 5とFable 5のベンチマークを15項目にわたり公開した。下表はその全項目を数値ハードコードで再現したものだ。いずれもAnthropicの内部テストによる公称値であり、第三者による独立検証ではない点に留意してほしい。
まず読み方の前提となる公式メソドロジー注記を訳出しておく。
公式メソドロジー注記(Anthropic公式表より訳出)
・Mythos 5とFable 5のスコアは1〜3パーセントポイント以内の差で、表は2つのうち高い方を採用している
・アスタリスク(*)付きの項目は、サイバー・生物関連のブロッキング・セーフガードの影響で差が大きい。これらの項目ではFable 5はフォールバックによりOpus 4.8寄りのスコアになる
・詳細はシステムカード参照
つまりアスタリスク項目(cyber/bio系)は「Mythos 5の最大性能値」であり、一般公開されるFable 5を実際に使う場合は、その領域でOpus 4.8に近い挙動になると理解すべきだ。
| ベンチマーク(領域) | Mythos 5 / Fable 5 | Mythos Preview | Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|---|
| Agentic coding(SWE-Bench Pro) | 80.3% | 77.8% | 69.2% | 58.6% | 54.2% |
| Agentic coding(FrontierCode Diamond, xhigh) | 29.3% | — | 13.4% | 5.7% | — |
| Knowledge work(GDPval-AA) | 1932 | — | 1890 | 1769 | 1314 |
| Knowledge work vision(GDP.pdf, ツールなし) | 29.8% | — | 22.5% | 24.9% | 16.7% |
| Spatial reasoning(Blueprint-Bench 2) | 38.6% | — | 14.5% | 36.2% | 26.5% |
| Tool use(AutomationBench) | 17.4% | — | 15.5% | 12.9% | 9.6% |
| Computer use(OSWorld-Verified) | 85.0% | 85.4% | 83.4% | 78.7% | 76.2% |
| Legal(Legal Agent Benchmark) | 13.3% | — | 10.4% | 2.1% | 0.0% |
| Multidisciplinary reasoning(HLE, ツールなし)* | 59.0% | 56.8% | 49.8% | 41.4% | 44.4% |
| Multidisciplinary reasoning(HLE, ツールあり)* | 64.5% | 64.7% | 57.9% | 52.2% | 51.4% |
| Biology(BioMysteryBench, hard)* | 46.1% | 29.6% | 40.0% | — | — |
| Biology(BioMysteryBench, human solved)* | 83.9% | 82.6% | 80.4% | — | — |
| Agentic coding(Terminal-Bench 2.1)* | 88.0% | — | 82.7% | 83.4%† | 70.7%‡ |
| Cybersecurity(ExploitBench Cap%)* | 78.0% | 69.0% | 40.0% | 34.0% | — |
| Health(HealthBench Professional)* | 66.0% | 64.7% | 56.9% | 51.8% | — |
表の読み方:「Mythos 5 / Fable 5」列は両モデルの高い方(1〜3pp差)。*印はcyber/bioセーフガードの影響が大きい項目で、一般公開のFable 5は実運用でOpus 4.8寄りになる。GDPval-AAのみスコアでなくレーティング値。FrontierCode/Opus/GPTはxhigh設定。Terminal-Benchの†はGPT-5.5(Codex CLI)、‡はGemini(Gemini CLI)。「—」は公式未公表。
特徴的なのは、コーディング(SWE-Bench Pro、Terminal-Bench 2.1、FrontierCode)と知識労働(GDPval-AA)、法務(Legal Agent Benchmark)で他モデルを明確に引き離している点だ。一方でアスタリスク項目のcyber(ExploitBench 78.0%)やbio(BioMysteryBench)は、まさにFable 5がセーフガードで抑える領域であり、Mythos 5の数値である。Fable 5を一般用途で使う限り、ここまでの能力には届かない設計になっている。
なおMMLU・GPQA Diamond・AIMEといった旧世代の汎用ベンチマークの個別スコアは、この公式15項目表には含まれず公式未公表だ。Anthropicの公式インフォグラフィックはSWE-Bench Pro・GDPval-AA・HLEなど、より新しく飽和していない評価に絞って構成されている。MMLU・GPQA Diamond・AIMEの数値そのものを確認したい場合は、Vals AIやArtificial Analysisといった独立系ベンチマークサイトのFable 5個別ページが選択肢になる。ただしこれらは第三者による独自の測定条件(セーフガードによる拒否をどう扱うかなど)に基づくため、Anthropic公式値と単純比較はできない点に注意してほしい。
価格と利用方法——Opus 4.8の2倍、5つの基盤で提供
Claude Fable 5の価格は入力100万トークンあたり$10、出力100万トークンあたり$50。Opus 4.8(入力$5/出力$25)のちょうど2倍だ。Mythos 5も同額に設定されている。性能は上がるがコストも上がるため、全タスクをFable 5に置き換えるのではなく、難度の高い処理に絞って使う設計が現実的になる。
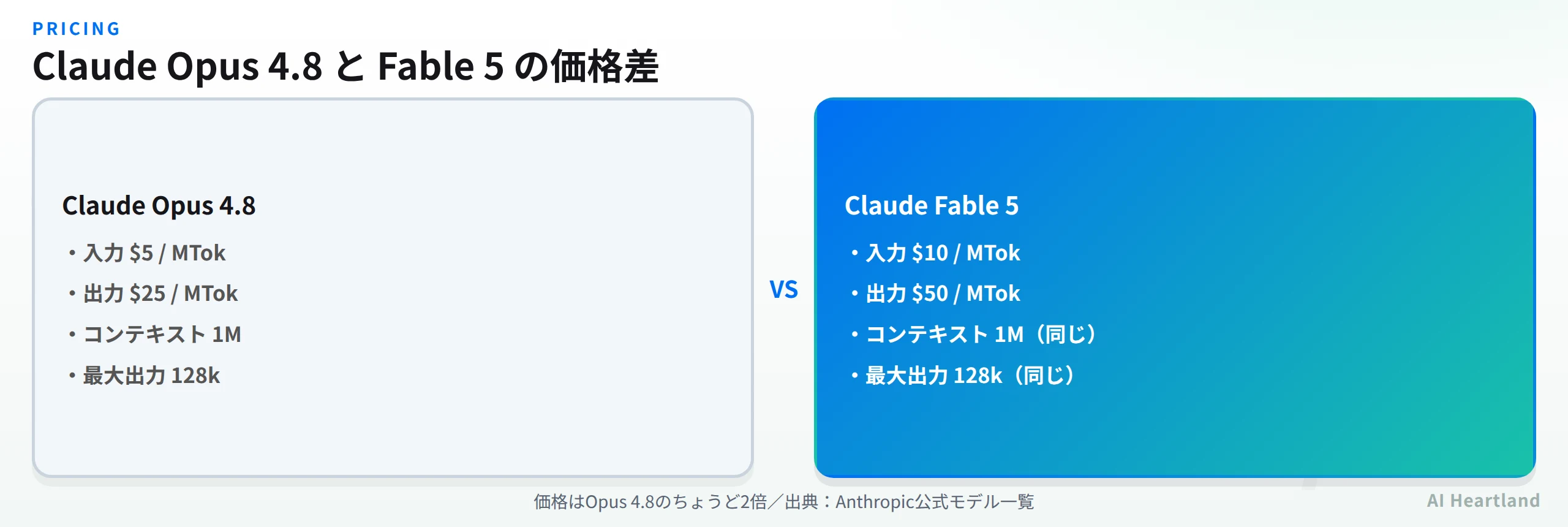
| 項目 | Claude Fable 5 | Claude Opus 4.8 | Claude Sonnet 4.6 |
|---|---|---|---|
| モデルID | claude-fable-5 | claude-opus-4-8 | claude-sonnet-4-6 |
| 入力価格(/MTok) | $10 | $5 | $3 |
| 出力価格(/MTok) | $50 | $25 | $15 |
| コンテキスト | 1Mトークン | 1Mトークン | 1Mトークン |
| 最大出力 | 128k | 128k | 64k |
| 適応的思考 | 常時オン | あり | あり |
利用できるチャネルは幅広い。Claude API・Claude Platform on AWS・Amazon Bedrock・Vertex AI・Microsoft Foundryで一般提供され、同日にGitHub Copilotでも一般提供が始まった。さらにClaude.aiのPro/Max/Team、および一部のプレミアムEnterpriseシートからも利用できる(標準Enterpriseシートは対象外)。
ただし、公開後の提供スケジュールは一度中断を挟んでいる点に注意が要る。6月12日〜6月30日は米政府の輸出規制で全ユーザー停止されていた(詳細は後述)。7月1日の再開後は、Pro/Max/Team・プレミアムEnterpriseシートで7月7日まで週次利用上限の最大50%までFable 5が追加料金なしで含まれ、それ以降はクレジット消費が必要になる。AWS・Google Cloud・Microsoft Foundry経由のアクセスも「可能な限り速やかに」再有効化する、とAnthropicは案内している。
なおFable 5とMythos 5はCovered Modelsに指定されており、30日間のデータ保持が適用される。ゼロデータ保持(ZDR)は利用できないため、データ保持要件が厳しい用途では事前確認が要る。
ローンチ時点で対応している主な機能も押さえておきたい。Anthropicの公式ドキュメントによれば、Fable 5とMythos 5は以下をサポートする。
・Effort:思考の深さとコストを制御するパラメータ(既定は high)
・Task budgets:タスク単位の予算制御(ベータ。task-budgets-2026-03-13 ヘッダーで有効化)
・Memory tool:ファイルベースの永続メモリツール
・Context editing:ツール結果のクリアによる文脈管理(ベータ。context-management-2025-06-27 ヘッダー)
・Compaction:長い会話の自動圧縮
・Vision:画像入力(Anthropicは「新たな最先端」と主張)
長時間の自律作業を主眼に置いたモデルだけに、メモリツール・文脈編集・コンパクションといった「長い文脈を扱い続ける」ための機能が初日から揃っている点が特徴だ。
価格を踏まえたモデル別のコスト試算は、Claude料金まとめ|Claude Code・API・Opus 4.7の価格を計算シミュレーター付きで比較 で具体的に確認できる。
既存モデルとの違い——適応的思考・思考出力・拒否という3つの新挙動
Claude Fable 5は「ほぼドロップインで移行できる」とAnthropicが明言する一方、Messages APIの挙動にはOpus/Sonnet/Haikuと異なる点がいくつかある。Anthropicも「このセクションの挙動はFable 5とMythos 5に固有で、Opus・Sonnet・HaikuのMessages APIは変わらない」と注記している。違いは大きく3つだ。
1. 適応的思考(Adaptive Thinking)が常時オン。Fable 5では適応的思考が唯一の思考モードで、モデルがリクエストごとに「いつ・どれだけ考えるか」を自動で決める。thinking パラメータの設定は不要で、thinking: {"type": "disabled"} を渡すとエラーになる。Opus 4.8では thinking フィールドなしのリクエストは思考なしで走ったが、Fable 5では同じリクエストが適応的思考付きで走る。思考の深さはeffortパラメータで制御する。
2. 生の思考過程は返らない。Fable 5では生のchain-of-thoughtが一切返されない。thinking.display は既定で "omitted"(思考ブロックは空)になり、"summarized" を指定すると要約された思考テキストを受け取れる。マルチターンでは思考ブロックを改変せずそのまま返す必要がある。
3. 安全分類器による拒否。Fable 5はリクエストと生成中の両方で安全分類器を走らせる。分類器が反応すると、エラーではなくHTTP 200の成功応答として stop_reason: "refusal" が返り、stop_details.category にどの分類器が反応したか("cyber"/"bio"/"reasoning_extraction"、または該当なしの null)が示される。出力生成前に拒否されたリクエストは課金されない。生成途中で分類器が反応した場合は、入力とすでに生成済みの出力が課金され、部分出力は破棄する。
下図はこの拒否とフォールバックの流れを示したものだ。
category を返す U->>O: fallbacks で別モデルへ再実行 O-->>U: 通常応答 else 問題なし F-->>U: 通常応答(適応的思考付き) end
再実行を自動化したい場合は、オプトインの fallbacks パラメータを使える(Claude APIとClaude Platform on AWSでベータ。Message Batches APIやAmazon Bedrock・Vertex AI・Microsoft Foundryでは非対応で、クライアント側再実行またはSDKミドルウェアを使う)。Anthropicによれば、拒否してOpus 4.8にフォールバックする必要があるのは平均で5%未満のセッション——裏を返せば少なくとも95%のセッションはFable 5自身の応答で完結する。
この安全分類器の重要性を裏づける実例が、公開直後に起きている。Amazon所属の研究者が、Fable 5に複数のソフトウェア脆弱性を特定させるプロンプト手法を報告し、そのうち1件では実際に脆弱性を悪用する方法を示すコードまで生成させた。Anthropicの検証では、この手法自体はMythos級固有の能力を必要とせず、Haiku 4.5・Sonnet 4.6・Opus 4.6〜4.8・GPT-5.4/5.5・Kimi K2.7を含む他モデルでも同じ実証が可能だったとされる——Anthropic自身、これを「境界線上のケース」であり汎用的な脱獄ではないと位置づけている。それでも米政府はこれを国家安全保障上の懸念とみなし、2026年6月12日にFable 5とMythos 5を全ユーザーで停止させる輸出規制を発動した。Anthropicはこの技術を99%超の確率で検知・遮断する改良版分類器を訓練し、6月30日に規制解除、7月1日に再開している。ここでの説明はAnthropic自身の公式発表に基づくものであり、政府側の判断根拠や規制の妥当性そのものについては独立した検証情報がない点は留意してほしい。なおAnthropicは指令に法的に従いつつも、公式には異議を唱えていた。政府が示したのは口頭の証拠にとどまるとし、この基準を業界全体に適用すれば新モデルの展開そのものが事実上止まりかねない、と反論している——「規制する側」と「規制される側」の見解が一致していない点は、本件を評価するうえで押さえておきたい。この一件は、安全分類器が抽象的な仕組みではなく、実際の報告を受けて更新され続ける生きた防御層であることを示す(経緯の詳細は後述のFAQを参照)。
なお、安全分類器が一般公開を可能にしている背景には、AnthropicのResponsible Scaling Policy(RSP)がある。Mythos級は重大リスク(特にサイバーセキュリティと生物学)の閾値に達したと社内評価されており、その能力を一般提供するための条件がFable 5の分類器だ。effortや思考制御の考え方そのものは Claudeの「思考レバー」完全解説|Effort Level・Adaptive Thinkingの仕組みと選び方 で整理している。
システムプロンプトは公式公開——透明性ポリシーとFable 5の規約
Fable 5の安全設計は、APIの分類器だけではない。意外に知られていないが、AnthropicはClaude.aiとモバイルアプリで使うシステムプロンプトを公式に公開している。場所は公式ドキュメントのrelease-notesページ(platform.claude.com/docs/en/release-notes/system-prompts)で、Claude Fable 5の分も2026年6月9日付で掲載されている。直前のエントリはClaude Opus 4.8(5月28日付)だ。
公式ページは、このプロンプトの役割をこう説明する。
Claude's web interface (claude.ai) and mobile apps use a system prompt to provide up-to-date information, such as the current date, to Claude at the start of every conversation.
ここで重要な但し書きがある。公式は「These system prompt updates do not apply to the Claude API.(これらのシステムプロンプトの更新はClaude APIには適用されない)」と明記している。つまり前述の移行手順で扱ったAPIの挙動と、この公式システムプロンプトは別レイヤーだ。APIでは開発者が自分でシステムプロンプトを設定するため、Claude.ai/アプリ向けの定型プロンプトは付かない。
公式ページの価値は、システムプロンプトの進化を時系列で追える点にもある。2024年のClaude 3系から始まり、世代ごとに規約が精緻化されてきた。近時のエントリは次のとおりだ。
| モデル | 公式掲載日 |
|---|---|
| Claude Fable 5 | 2026-06-09 |
| Claude Opus 4.8 | 2026-05-28 |
| Claude Opus 4.7 | 2026-04-16 |
| Claude Sonnet 4.6 | 2026-02-17 |
| Claude Opus 4.6 | 2026-02-05 |
| …(さかのぼると2024年のClaude 3系まで) | 2024〜 |
公開されたFable 5プロンプトを読むと、本記事で整理したFable 5とMythos 5の関係が、プロンプト自身にも明記されているのが分かる。

能力の高さ・dual-use向けの追加安全策・限定提供のMythos 5との関係が一文に凝縮されている。拒否の方向性も具体的で、たとえば悪性コードについては「教育目的のような一見もっともらしい理由があっても」断ると明記される。
Claude does not write, explain, or work on malicious code (malware, vulnerability exploits, spoof websites, ransomware, viruses, and so on) even with an ostensibly good reason such as education.
一点、誤読を避けるために切り分けておきたい。公式公開されるのはClaude.ai/アプリ向けの「消費者向け」プロンプトで、比較的最小限だ。兵器・CBRN・著作権の細かな数値ルールといった細目は、このページではなく公式のUsage Policyや、前述のAPI安全分類器、さらに第三者が収集した「拡張版」アーカイブ(CL4R1T4S等)に分散している。「公式プロンプトに載っていない=対策がない」ではなく、規約の置き場所が違うだけだ。Fable 5の安全策は、学習(Constitutional AI)・システムプロンプト・分類器・ポリシーの多層で構成されている。
・公式システムプロンプト:ペルソナ・児童安全・悪性コードなど会話で即効く中核規範(claude.ai/アプリ向け・公式公開)
・Usage Policy:兵器・CBRN・サイバー攻撃など高リスク領域の禁止
・安全分類器(API):cyber/bio/蒸留を機械的に遮断(本記事の拒否=この層)
・拡張版アーカイブ:第三者収集。ツールスキーマや著作権の数値細目まで含むが裏取りが必要
システムプロンプトを秘匿せず公式公開していること自体が、Anthropicの「隠蔽に依存しない」設計姿勢を示す。重要な防御を学習・分類器・ポリシーに分散させているため、中核の規約を見せても運用は破綻しない。アクセス制限という別レイヤーの動き(公開直後の一時停止)については Claude Fable 5・Mythos 5が使えないのはなぜ?|モデルの違いとアクセス制限をやさしく解説 で整理している。
何が変わったか——開発者・SaaS・セキュリティの実務観点
仕様の差分を、立場別の「実利」と「気をつけること」に翻訳しておく。

開発者(エージェント/コーディング)にとって。FrontierCodeで2倍以上、SWE-Bench Proで10ポイント超の差をAnthropicが公称しており、長時間の自律コーディングが主戦場なら効果が見込める。Anthropicの開発者向け公式アカウント(@ClaudeDevs)は、Claude Codeチーム自身の働き方が変わったとし、「これまではClaudeが作業を正しく行ったかを検証していた。いまは”正しい作業をしているか”を検証している」と述べている。出力の正しさを逐一確認する段階から、タスクの方向性を監督する段階へ——自律性の向上が役割を一段引き上げた、という主張だ。重要なのはeffortの使い方が変わる点だ。Opus 4.8ではコーディングや高自律タスクに xhigh を明示推奨していたが、Fable 5では大半のタスクで high を既定とし、xhigh は最も能力が要る処理に絞れとAnthropicは案内する。Fable 5は低めのeffortでも従来モデルの xhigh を上回ることが多いためだ。タスクが完了するのに時間がかかりすぎるならeffortを下げる、という調整が効く。
# Before(Claude Opus 4.8)
client.messages.create(
model="claude-opus-4-8",
max_tokens=16000,
thinking={"type": "adaptive"},
output_config={"effort": "high"},
messages=[{"role": "user", "content": "..."}],
)
# After(Claude Fable 5)— thinking指定は不要、effortで深さを制御
client.messages.create(
model="claude-fable-5",
max_tokens=16000,
output_config={"effort": "high"},
messages=[{"role": "user", "content": "..."}],
)
SaaS・プロダクト運用者にとって。価格が2倍になるため、コスト設計の見直しが要る。一方でプロンプトキャッシュの最小長が512トークンに下がった(Opus 4.8は1,024トークン、ただしAmazon Bedrockでは1,024のまま)。Opus 4.8では短すぎてキャッシュできなかったプロンプトが、コード変更なしでキャッシュ対象になる。短いシステムプロンプトを多用するアプリではキャッシュ効率が改善する余地がある。
セキュリティ担当者にとって。安全分類器による拒否は、防御的なセキュリティ業務でも誤発火しうる。拒否は例外ではなくHTTP 200で返るため、stop_reason を見て分岐する実装が必須になる。下のように拒否を検知してフォールバックする処理を入れておくのが安全だ。
resp = client.messages.create(model="claude-fable-5", max_tokens=4096,
messages=[{"role": "user", "content": prompt}])
if resp.stop_reason == "refusal":
category = resp.stop_details.category # "cyber" / "bio" / "reasoning_extraction" / None
# 拒否されたら別モデルで再実行(出力前の拒否は課金されない)
resp = client.messages.create(model="claude-opus-4-8", max_tokens=4096,
messages=[{"role": "user", "content": prompt}])
加えて、Claude CodeやClaude.aiといったクライアントアプリでは、拒否時に裏でOpus 4.8へ自動的にルーティングされる。生のMessages APIを直接叩く場合のみ、構造化された拒否カテゴリが返り既定では自動フォールバックしない——この挙動差を押さえておきたい。
移行・採用判断——既存ユーザーは何をすべきか
Opus 4.8からの移行は、Anthropicの言葉どおりほぼドロップインだ。Messages APIもツール利用も同じ、1Mコンテキストと128k出力も同じ、トークナイザーも同じなのでトークン数もほぼ変わらない。最小手順はモデルIDの差し替えだけで済む。
model = "claude-opus-4-8" # Before
model = "claude-fable-5" # After
そのうえで確認すべき差分は次のとおりだ。
・適応的思考が常時オン:thinking: {"type": "disabled"} はエラー。思考なしで走っていたワークロードは挙動が変わるため max_tokens(思考+応答の合計上限)を見直す
・手動の拡張思考とprefillは非対応:thinking: {"type": "enabled", "budget_tokens": N} とアシスタントメッセージのprefillは400エラー(これはOpus 4.8と同じ)。budget_tokens に直接の代替はなく、effortは別系統の出力レベル制御
・拒否ハンドリング:stop_reason: "refusal" を見て分岐。必要なら fallbacks パラメータかSDKミドルウェアで再実行
・effortは high から:xhigh は能力が要る処理に絞る
・価格は2倍:全面置き換えではなく難度の高い処理に絞る判断が現実的
採用判断のフローを下図にまとめた。Mythos Previewからの移行は別ガイド(公式の移行手順)が用意されている。
最難度の推論・コーディングが主目的?"} B -->|いいえ| C["Opus 4.8 / Sonnet 4.6 を継続
コスト対効果が高い"] B -->|はい| D{"コスト2倍を許容できる?"} D -->|難しい| E["難度の高い処理だけ
Fable 5にルーティング"] D -->|許容できる| F{"安全分類器の拒否を
ハンドリングできる?"} F -->|未対応| G["stop_reason分岐と
フォールバックを実装してから移行"] F -->|対応済み| H["モデルIDを差し替えて移行
effortはhighから調整"]
下図は価格と性能のポジショニングを俯瞰したものだ。Fable 5は「最高性能・最高コスト」の象限に位置し、Opus/Sonnet/Haikuと役割を分担する構図になる。
まとめ
Claude Fable 5とMythos 5は、Anthropicが投入した「Mythos級」のペアモデルだ。同じ基盤を持ちながら、Fable 5はサイバー・生物をセーフガードで抑えた一般公開版、Mythos 5は最大性能の限定版という役割分担になっている。公式ベンチマーク15項目ではSWE-Bench Pro 80.3%・Terminal-Bench 2.1 88.0%などコーディングと知識労働で他モデルを引き離す一方、cyber/bio系のアスタリスク項目では一般公開のFable 5はフォールバックでOpus 4.8寄りになる——この非対称性が両モデルの設計を端的に表している。価格はOpus 4.8の2倍、適応的思考は常時オン、安全分類器による拒否という新しい挙動も加わった。
実務での要点は3つに集約できる。第一に、移行はモデルID差し替えでほぼ済むが、stop_reason: "refusal" のハンドリングは必須。第二に、effortは high を既定にして xhigh は絞る。第三に、コスト2倍を踏まえ、全面置き換えではなく難度の高い処理に絞ってルーティングする設計が現実的だ。第三者ベンチマークの結果が出そろうまでは、公称値を相対的な傾向として捉えつつ、自分のワークロードで小さく試すのが堅実な進め方になる。とりわけ無料で試せるClaude.aiの窓は2026年6月22日までと短い。コーディングや長時間タスクで効果を見極めたいなら、この期間に手元のコードベースで一度回しておくと判断材料が増える。
Mythos級が一般に開かれた意味はそれだけではない。能力の閾値が「重大リスク」に達したモデルを、安全分類器という条件付きで公開する——AnthropicのResponsible Scaling Policyが実運用される最初の事例でもある。この方針転換の経緯は Claude Mythos公開方針転換:6〜12ヶ月以内に一般リリースへ で追える。
参照ソース
・Claude Fable 5 and Claude Mythos 5 — Anthropic(公式発表)
・Introducing Claude Fable 5 and Claude Mythos 5 — Claude API Docs(API仕様・モデルID・対応機能)
・Models overview — Claude API Docs(価格・コンテキスト・出力上限)
・Migration guide — Claude API Docs(Opus 4.8からの移行手順)
・Introducing Claude Fable 5 — Anthropic公式動画(YouTube)(2026-06-09公開。公式の設計思想・セーフガード説明を引用)
・@ClaudeDevs(Anthropic公式)による紹介動画ポスト(X)(2026-06-09。Claude Codeチームの働き方の変化に関する公式発言を引用)
・Statement on the US government directive to suspend access to Fable 5 and Mythos 5 — Anthropic(2026-06-12公式声明。輸出規制の発動経緯)
・Redeploying Claude Fable 5 — Anthropic(2026-06-30公式発表。Amazon研究者の報告内容、新分類器、7月1日再開の詳細)
参考
・Anthropic公式ベンチマークインフォグラフィック「Claude Mythos 5 and Fable 5」(2026-06-09時点・ユーザー提供)——本文のベンチマーク全15項目および公式メソドロジー注記の出典
・本文中の発言引用はAnthropic公式チャンネルの動画「Introducing Claude Fable 5」およびAnthropic公式アカウント@ClaudeDevsのポストより。第三者・個人による感想や推測は採用していない





