「また新モデルが出た。切り替えるべきか?」——AIを使うエンジニアなら誰もが毎月のように直面するこの問いに、科学的に答える方法がある。
Code with Claude London 2026でAnthropicのApplied AIチームのLucasが語ったのは、直感や話題に頼らず、自分のユースケースに特化したデータで意思決定するための反復可能プロセスだ。プライベートEvalの設計から、eval失敗の6パターン、thinkingとeffortのダイヤル操作、そしてプロンプトキャッシングによるコスト-品質フロンティアの移動まで、実演データ付きで公開されている。
LLMのモデル選択・コスト管理の全体像は LLM完全ガイド2026 をご覧ください。
セッション概要:「新モデルが出たら切り替えるべき?」
セッション基本情報
- 登壇者: Lucas(AnthropicのApplied AIチーム)
- イベント: Code with Claude London 2026(2026年5月19日)
- テーマ: モデル選択の反復可能プロセス
- 対象: LLMをプロダクションで運用するエンジニア・MLエンジニア

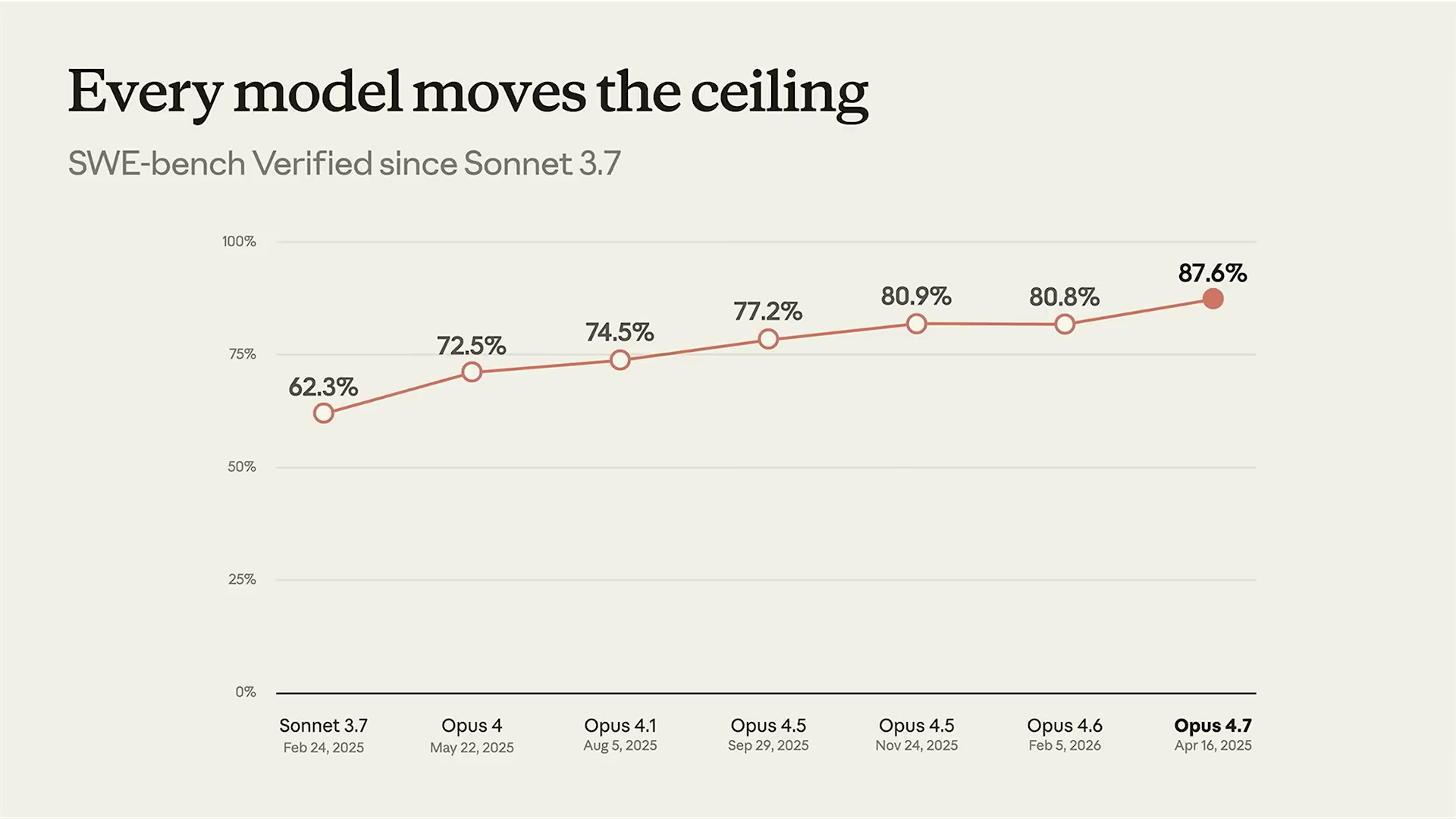
新モデルがリリースされると、必ず以下の「情報」が押し寄せる。ローンチアナウンスの「SWE-bench Verifiedで新SOTA達成」、Xの「アジェンタックタスクで意味のある飛躍」、Hacker Newsの「全パイプラインを切り替えたら精度が30%向上した(Show HN)」、そしてPMからの「来週のリリース前に何か変えるべき?」というSlackメッセージ。
しかしLucasはスライドの右側に小さく、しかし明確に記した。「これらはあなたのユースケースに特化した答えを与えてくれない。反復可能なプロセスが必要だ。」
公開ベンチマーク、著名エンジニアのツイート、HNのSHOW HN——どれもデータとして有用だが、それはあなたが実際に動かしているシステムのデータではない。このセッションはその「反復可能なプロセス」を体系化したものだ。
なぜ公開ベンチマークはあなたのユースケースに役立たないか

LucasはSWE-bench Verified、BrowseComp、GPQA Diamondといった著名なベンチマークについて、「事前確率(priors)として使え、判決(verdicts)として使うな」と述べた。
これらのベンチマークが測定するのは特定の能力の断面であり、あなたが運用する具体的なシステムのパフォーマンスではない。例を挙げると:
- SWE-benchは「GitHubのissueを解決できるか」を測定するが、あなたのコードベース・テストスイート・CI環境でのパフォーマンスは別の話だ
- BrowseCompはウェブブラウジング能力を測定するが、あなたのエージェントが叩くAPIの構造・エラーパターン・認証フローは含まれない
- GPQA Diamondは大学院レベルの科学的推論を測定するが、あなたのカスタマーサービスエージェントが扱う問い合わせの分布とは異なる
これらのベンチマークが高いモデルは「一般的に能力が高い可能性が高い」という事前確率を与えてくれる。しかし「あなたのユースケースで最高のモデルだ」とは言えない。実際、LucasのワークショップデモではOpus 4.7が特定のカスタマーサービスタスクで最高精度を示したが、すべてのタスクでそうではない可能性がある。
ベンチマークの問題をさらに深掘りすると、これらは「過去の特定の時点での特定の能力の断面」を測定しているという点も重要だ。モデルが更新されるたびにベンチマーク数値も更新されるが、その数値の向上があなたのタスクに直接対応するかどうかは別問題だ。
また、ベンチマークには「汚染(contamination)」の問題もある。公開されたベンチマークのデータがモデルの事前学習データに含まれている可能性があり、ベンチマーク上のスコアが実際の汎化能力を過大評価している場合がある。これは公開ベンチマークを事前確率として使う際に常に念頭に置くべき注意点だ。
公開ベンチマークの正しい使い方のまとめ:
- 新モデルを探索するフィルターとして使う — ベンチマーク上で明らかに性能が低いモデルは、自分のevalで試す優先度を下げる
- 回帰テストのシグナルとして使う — 新バージョンで特定のベンチマークが大幅に低下している場合、そのカテゴリのタスクを重点的にevalする
- 競合モデルの比較に使う — 同一の自社evalで全モデルを比較する前に、大まかな優先順位付けに活用する
ただしこれらはあくまで「出発点」だ。最終的な意思決定は常に自分のプライベートevalで行う。
反復可能なプロセス = プライベートEvalの設計
公開ベンチマークを「事前確率」として使いながら、最終的な意思決定は自分のワークロードで計測する——これがLucasが提唱するアプローチの核心だ。
プライベートEvalを構築することで得られるもの:新しいモデルがリリースされるたびに、数時間で自分のシステムへの影響を定量的に評価できる反復可能なプロセスだ。
evalを「一度作って終わり」のものではなく、モデルリリースのたびに実行するインフラとして捉えることが重要だ。このインフラがあれば、「切り替えるべきか?」という問いに対して、ベンチマーク数値やSNSの反応ではなく、自社システムの実測データで答えられる。
プライベートEvalを構築するための最初のステップは、「タスク」の正確な定義だ。
プライベートEvalの構成要素
Lucasが示したプライベートevalの設計フレームワークは、以下の4つの要素から成る。
1. タスクセット(Task Set) 実際のプロダクションワークロードから取得した、代表的なタスクの集合。難しすぎず簡単すぎず、システムが日常的に処理する問題のスペクトルをカバーする。最初は20タスク、成熟したら50〜100タスクが目安だ。
2. 評価メトリクス(Metrics) タスクごとの成功/失敗を定量化する方法。最終出力の評価(LLM-as-judge、ルールベース、人間評価)と中間ステップの評価(ツール呼び出しの正確性、フロー制御の正しさ)の組み合わせが必要だ。
3. 計測インフラ(Harness) 複数のモデル・設定を並列で実行し、結果を集約・可視化するシステム。各タスクを3〜5回実行してノイズを排除し、インフラ障害とモデル失敗を分離して記録する。
4. 意思決定ルール(Decision Rules) 「どの条件が満たされたらモデルを切り替えるか」を事前に定義するルール。例:「精度が現行モデルより2%以上向上、かつコストが増加しない場合に切り替える」。数値を見てから決めるのではなく、先にルールを定義しておくことでバイアスを防ぐ。
この4要素が揃ってはじめて「反復可能なプロセス」になる。タスクセットだけあっても、計測インフラがなければ毎回一から実行する手間がかかる。意思決定ルールがなければ、数字を見た後で都合よく解釈してしまう。
タスクはどこから取得するか
新しくevalを構築する際、最も現実的なタスクの取得源はプロダクションのログだ。
- 成功例のログ: 現在のシステムが正しく処理したリクエストと、その正解の組み合わせ
- 失敗例のログ: ユーザーからのフィードバック、エラーレート、サポートチケットなど問題があった事例
- エッジケース: 担当エンジニアが「これは難しい」と感じた事例を手動で追加
失敗例を意図的に含めることが重要だ。成功例だけのevalセットは「Silentの飽和」(後述)に陥りやすく、モデル間の差異が見えにくい。
タスク設計の原則:数学の答案用紙から学ぶ
Lucasはタスク設計の原則を「数学の試験」になぞらえて説明した。
良い数学の試験には3つの要素がある:
- 問い(Inputs) — 何を解けばよいか
- 答え(Success criteria) — 正解は何か
- 解答過程(Steps) — 正解に至るプロセスが正しいか
LLMのevalも同じ構造を持つべきだ。特にエージェントシステムにおいては、最終的な出力の正確さだけでなく、中間ステップの正しさを評価することが重要だと強調した。
例として挙げたのはカスタマーサービスエージェントだ。このエージェントのevalを設計する場合:
- Inputs: 顧客の問い合わせ文 + 顧客ID + システム設定
- Success criteria(最終): LLM-as-judgeが最終レスポンスを評価(適切か・フレンドリーか・正確か)
- Success criteria(中間): データベースへのクエリは正しいか? 検索を顧客の国にローカライズしたか?
# プライベートEvalのタスク定義例(カスタマーサービスエージェント)
class EvalTask:
def __init__(self):
self.inputs = {
"customer_query": "フライトCA123の遅延補償について教えてください",
"customer_id": "JP_USER_98765",
"customer_country": "JP",
}
self.success_criteria = {
# 最終レスポンスの評価
"final_response": {
"type": "llm_judge",
"rubric": "レスポンスは正確で、フレンドリーで、顧客の問いに直接答えているか",
"threshold": 0.8,
},
# 中間ステップの評価
"intermediate_steps": [
{
"step": "database_query",
"check": "customer_id JP_USER_98765 でDBクエリを実行したか",
"type": "exact_match",
},
{
"step": "search_localization",
"check": "検索を JP(日本)にローカライズしたか",
"type": "boolean",
},
],
}
中間ステップの評価を加えることで、「最終的な答えは正しいが、間違ったプロセスで到達した」という見落としを防ぐ。エージェントがデータベースをクエリせずに一般的な回答をしてしまうケースや、顧客の国を無視してグローバル設定で検索してしまうケースを検出できる。
Eval失敗の6パターン — 驚くべき結果の多くはモデルの問題ではない

LucasはEvalを構築する際に陥りやすい6つの失敗パターンを詳細に解説した。「驚くべきeval結果の多くは、モデルについての事実ではなく、evalのバグだ」という言葉が印象的だった。
1. ノイズをシグナルと誤認(Noise mistaken for signal)
LLMは確率的システムだ。同じタスクを同じモデルに実行させても、毎回同じ結果にはならない。1回だけ実行した結果に基づいてモデルAよりモデルBが良いと結論付けるのは危険だ。
対処法: 各タスクを複数回実行し、平均値と標準偏差を見る。少なくとも3〜5回の繰り返し実行が推奨される。
2. インフラ障害をモデル障害として計上(Conflated infra failures)
エージェントがタイムアウト、ネットワークエラー、外部APIの障害で失敗した場合、それはモデルの問題ではない。しかしevalスクリプトが「失敗」として単純にカウントすると、モデルの精度が下がったように見える。
対処法: エラーログとトランスクリプトを必ず確認する。timeout、connection error、rate limitなどのエラーを別カテゴリとして計上する。
3. グレーダーの偏り(Unfair graders)
LLM-as-judgeを使う場合、評価者のLLM自体にバイアスがある。特に「同じファミリーのモデルは評価を甘くする」というself-bias、「長い回答を好む」「権威的な語調を好む」などの傾向がある。
対処法: 複数の評価モデルを使う。評価ルーブリックを具体的かつ客観的に定義する。「AとBどちらが良いか」ではなく「このルーブリックに基づいて0-10でスコアリングしてください」という形式にする。
4. タスク仕様の曖昧さ(Underspecified tasks)
成功基準が曖昧だと、モデルが「技術的には正しい」が「期待した回答ではない」出力をすることがある。これはモデルの問題ではなく、タスク設計の問題だ。
対処法: success criteriaを書いた後、「この基準で、間違った答えが合格してしまうケースはあるか?」と自問する。エッジケースを想定した基準を追加する。
5. 環境の汚染(Contaminated environment)
エージェントが共有状態(ファイルシステム、データベース、APIキャッシュなど)を使う場合、前のタスクの実行結果が次のタスクに影響する。あるタスクでエージェントが答えを「見つけた」状態で、次のタスクが実行されると精度が高く見える。
対処法: タスク間で環境を完全にリセットする。各タスクは独立した環境で実行する。
6. 無音の飽和(Silent saturation)
タスクセットがモデルの能力に対して簡単すぎると、どのモデルも100%に近いスコアを出してしまう。これではモデル間の差異が見えない。
対処法: 常に難しいタスクを追加し続ける。スコアが90%を超えたら、難易度を上げるタイミングだ。
# eval失敗パターンを防ぐevalハーネスの例
import asyncio
from typing import Optional
class RobustEvalHarness:
def __init__(self, n_runs: int = 3, timeout_seconds: int = 30):
self.n_runs = n_runs
self.timeout_seconds = timeout_seconds
async def run_task_with_retry(self, task, model_client) -> dict:
results = []
infra_failures = 0
for run_idx in range(self.n_runs):
try:
result = await asyncio.wait_for(
model_client.run(task),
timeout=self.timeout_seconds
)
results.append(result)
except asyncio.TimeoutError:
# インフラ障害として別カウント(モデル失敗ではない)
infra_failures += 1
except ConnectionError:
infra_failures += 1
if not results:
return {"status": "infra_failure", "infra_failures": infra_failures}
# 複数実行の集計(ノイズ対策)
scores = [self.grade(r, task.success_criteria) for r in results]
return {
"status": "completed",
"mean_score": sum(scores) / len(scores),
"std_dev": self._std(scores),
"n_completed": len(results),
"infra_failures": infra_failures,
}
def _std(self, values: list[float]) -> float:
mean = sum(values) / len(values)
variance = sum((x - mean) ** 2 for x in values) / len(values)
return variance ** 0.5
3つの判断軸:品質・コスト・レイテンシ
モデルを選ぶ際に最終的に比較するのは「品質(Quality)」「コスト(Cost)」「レイテンシ(Latency)」の3軸だ。しかしLucasは、コストについて重要な誤解を指摘した。
「最安のモデル」は「トークン単価が最も安いモデル」ではない。「成功1件あたりのコストが最も低いモデル」だ。
この違いは特にエージェントシステムで重要になる。エージェントは複数のターンにわたって動作し、1つのタスクを解決するのに多くのAPI呼び出しをする。インテリジェンスの高いモデルは:
- より少ないターン数でタスクを完了する
- ミスによるリトライが少ない
- 不必要な中間ステップを省略できる
結果として、1タスクあたりの合計トークン消費量が少なくなる可能性がある。「成功1件あたりのコスト」で比較することで、初めて正しいコスト比較ができる。
この観点を数式で表すなら:
真のコスト = (トークン単価 × 平均トークン数/タスク) ÷ 成功率
トークン単価が高くても、成功率が高く、1タスクあたりのトークン数が少なければ、真のコストは低くなる。
| 比較軸 | 表面上のコスト | 真のコスト(成功/件) |
|---|---|---|
| Haiku 4.5 + thinking on | 安い(単価) | 高い(多ターン・遅い) |
| Opus 4.7 + low effort | 高い(単価) | 安い(少ターン・速い) |
レイテンシの位置づけ
品質とコストと並んで重要なレイテンシだが、Lucasはこれについても単純な数値比較に警告を発した。
重要なのはユーザー体験に影響するレイテンシだ。バッチ処理のパイプラインでは1タスクに5分かかっても問題ないが、リアルタイムのチャットインターフェースでは1秒の差がユーザー満足度に直結する。
また、エージェントシステムではレイテンシとターン数はトレードオフではなく相関関係にある場合がある。高インテリジェンスモデルが少ないターン数でタスクを完了させると、1ターンあたりのレイテンシは高くても合計処理時間が短くなることがある。
Lucasの内部evalでまさにこれが起きた。Haiku 4.5+thinking-onは1ターンが速いが、多くのターンが必要なため合計処理時間は長い。Opus 4.7+low effortは1ターンあたりのレイテンシが若干高いが、少ないターン数でタスクを完了するため合計処理時間は短い。
このため、Lucasは「エージェントシステムでは1ターンのレイテンシではなくタスク完了までの合計時間を計測すること」を推奨している。
Thinking(思考)とEffortのダイヤルを操る

Lucasはモデルのパフォーマンスをコントロールする2つの独立したダイヤルを説明した。
Thinking(Adaptive Thinking)は、Claude Sonnet 4.6以降で利用可能な推論モードだ。有効にするとClaudeは「System 2思考」——スクラッチパッドを使った段階的な推論——を行うかどうかを自律的に決定する。シンプルな質問は素早く回答し、複雑な問題には深く考える。Lucasは「thinkingをオフにするのは能力を消す操作だ。コストを下げたいならthinkingをオフにするのではなく、effortをlowに下げよ」と述べた。これはClaudeの思考レバー完全解説でも詳しく解説されている。
Effort LevelはClaudeにどれだけの作業量を投入するかを指示するパラメータだ:
low: 最小限の推論。分類・要約など低知性タスク向けmedium: バランスの取れた推論。多くの一般的タスクhigh: 深い推論。複雑な問題解決xhigh: Opus 4.7のみ。非常に難しいタスクmax: 最大限の推論。最も困難なタスクや研究レベルの問題
モデルごとのeffort levelのオプションは:
- Haiku 4.5: effort levelなし(thinkingのみ制御可能)
- Sonnet 4.6: low / medium / high / max(4段階)
- Opus 4.7: low / medium / high / xhigh / max(5段階)
(能力を削除)"] T2["thinking: on
(Adaptive Thinking)
Sonnet 4.6+ のみ"] end subgraph "Effort ダイヤル" E1["effort: low
最小推論"] E2["effort: medium
バランス"] E3["effort: high
深い推論"] E4["effort: xhigh
Opusのみ"] E5["effort: max
最大推論"] end subgraph "モデル選択" M1["Haiku 4.5
低単価
effortなし"] M2["Sonnet 4.6
中単価
4段階 effort"] M3["Opus 4.7
高単価
5段階 effort"] end T2 --> E1 T2 --> E2 T2 --> E3 T2 --> E4 T2 --> E5 M1 --> T1 M2 --> T2 M3 --> T2
このダイヤルの組み合わせが「コスト-品質フロンティア」を決定する。そして次のセクションで見るように、直感に反する結果が待っている。
Thinking と Effort の API実装
実際にAPIでこれらのパラメータを設定する方法を確認しておこう。
import anthropic
client = anthropic.Anthropic()
# Sonnet 4.6 — thinking on、high effort
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=16000,
thinking={
"type": "enabled",
"budget_tokens": 10000, # 思考に使えるトークン数の上限
},
# effort levelはbeta headerまたはモデルパラメータで設定
extra_headers={"anthropic-beta": "interleaved-thinking-2025-05-14"},
messages=[
{"role": "user", "content": "複雑な多段階推論タスク..."}
]
)
# Opus 4.7 — thinking on、low effort(反直感ケースの設定)
response_opus_low = client.messages.create(
model="claude-opus-4-7",
max_tokens=8000,
thinking={
"type": "enabled",
"budget_tokens": 3000, # low effortではbudget_tokensを低く設定
},
messages=[
{"role": "user", "content": "コードフィックスタスク..."}
]
)
budget_tokensの設定がeffort levelに相当する。低い値(1000〜3000)がlowに近い設定、高い値(8000〜20000)がhigh〜maxに近い設定だ。Anthropicの公式ドキュメントでは、effort levelの具体的なトークン数範囲が示されている。
反直感:OpusがHaikuより速く安い理由(内部Evalの事例)

LucasはAnthropicの内部で実際に行ったコードフィックスパイプラインのevalを紹介した。結果は多くのエンジニアの直感を覆すものだった。
散布図の横軸はレイテンシ(速度)、縦軸はコストだ。結果は:
| モデル | thinking | 精度 | コスト | レイテンシ |
|---|---|---|---|---|
| Haiku 4.5 | on(有効) | 100% | 最高(worst) | 最遅(worst) |
| Haiku 4.5 | off(無効) | 92% | 低い | 速い |
| Sonnet 4.6 | off | 100% | 低い | 速い |
| Opus 4.7 | on(low effort) | 100% | 最安(best) | 最速(best) |
Haiku 4.5にthinkingを有効にすると、100%の精度は達成できる。しかしコストもレイテンシも最悪になる。なぜか?
よりインテリジェントなモデルは、タスクをより少ないターン数で完了させる。 Haiku 4.5はコードフィックスのエージェントループで何度も試行錯誤を繰り返す。各試行でthinkingトークンが積み重なる。一方Opus 4.7はlow effortでも問題の本質をすぐに把握し、正しい修正を少ないステップで実行する。
1ターンのAPI呼び出しコストではHaikuの方が安い。しかし「タスク1件を成功させるまでの合計コスト」ではOpusの方が安いのだ。これがLucasが繰り返し強調した「成功1件あたりのコストで比較せよ」という原則の実例だ。
この結果が示す設計上の示唆
この内部evalの結果は、エージェントシステムの設計に関して重要な示唆を与える。
小さいモデルは「安価なルーティング」と「複雑タスクの分解」に使え
Lucasのデモが示すのは、「コードフィックス全体」のようなタスクにはOpus 4.7が適しているが、そのパイプラインの中に「変更が必要なファイルを特定する」「エラーメッセージを分類する」といった部分タスクがある場合、それらにはHaikuを使うことで全体コストを下げられる可能性がある。
重要なのは、「どのモデルをすべてのステップで使うか」ではなく「どのステップにどのモデルが適しているか」という問いだ。プロンプトキャッシングと組み合わせると、小モデルのルーティング判断を高速・安価に行い、高インテリジェンスモデルを実際の問題解決に集中させるというアーキテクチャが実現できる。
エラーからの回復能力がモデル選択に影響する
エージェントシステムでは、ツールの返り値が予期しない形式だったり、外部APIがエラーを返したりすることがある。この「予期しない状況への適応」能力はモデルによって大きく異なり、ベンチマークには現れにくい部分だ。
コードフィックスパイプラインのevalでは、テスト実行が失敗した場合にエージェントがどう対応するか——エラーメッセージを読んで正しく診断し、適切な修正を行えるか——も評価に含まれる。この「回復能力」がHaikuとOpusの差として現れた可能性が高い。
コスト-品質フロンティアを移動させる:プロンプトキャッシングとコンテキスト衛生
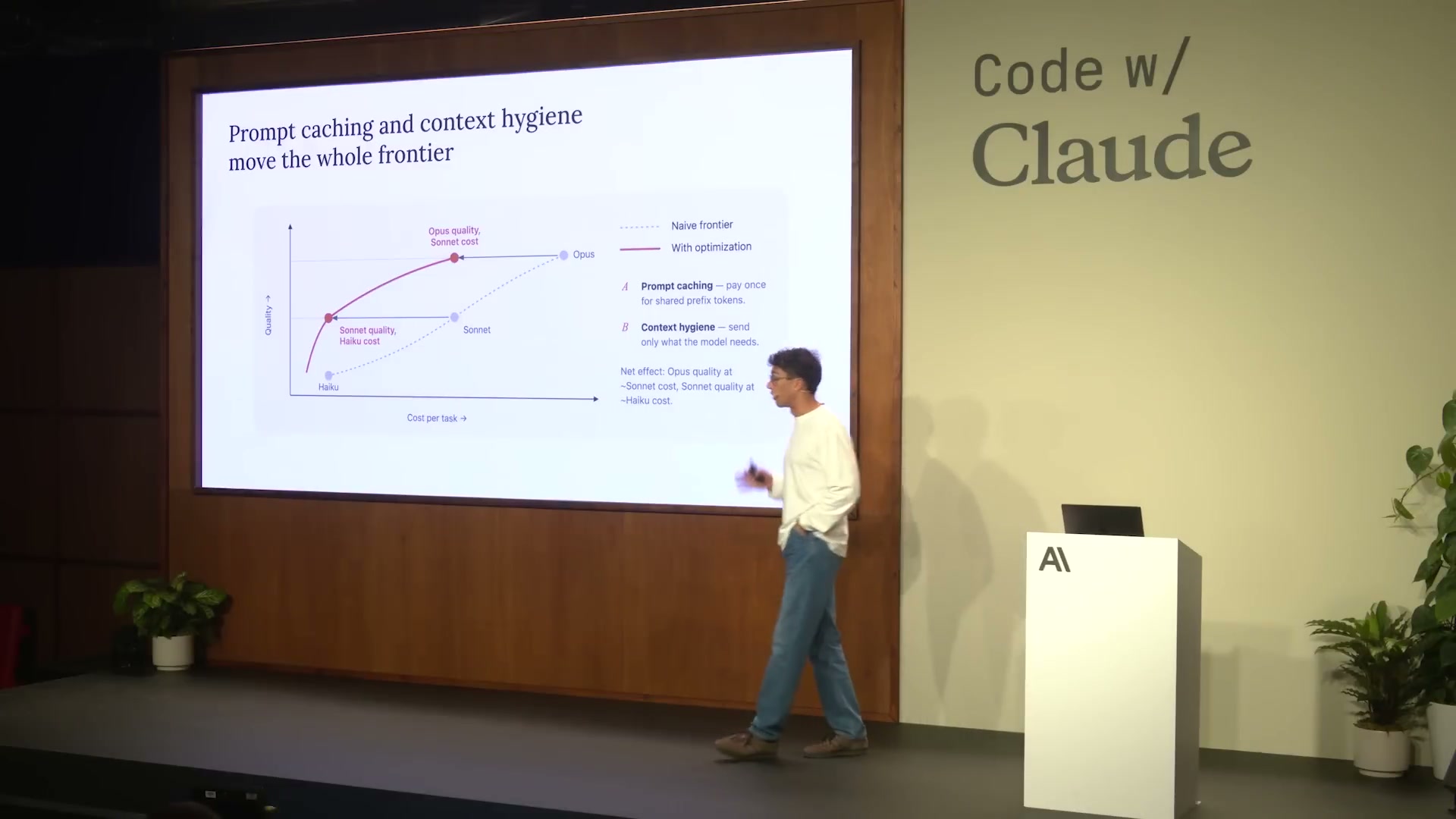
モデル選択だけが最適化の軸ではない。Lucasが強調したのは「プロンプトキャッシングとコンテキスト衛生が、コスト-品質フロンティア全体を移動させる」という点だ。
パレートフロンティアとは「このコストではこれ以上の品質は得られない」という限界線だ。あるモデルを選ぶことはこのフロンティア上の点を選ぶことだ。しかしフロンティアそのものを移動させることができれば、「同じコストでより高い品質」または「同じ品質でより低いコスト」が実現できる。
Lucasが紹介した2つの最適化手法がそれを可能にする:
A: プロンプトキャッシング
- キャッシュされたトークンはリスト価格の1/10で処理される
- 目標キャッシュヒット率:80〜90%
- 「Haikuの単価でSonnetの品質」「Sonnetの単価でOpusの品質」を実現できる
B: コンテキスト衛生(Context Hygiene)
- モデルに必要なものだけを送る
- 不要なコンテキストを削減することでトークン消費を大幅に削減
スライドのパレート図では、ナイーブフロンティア(点線)に対して最適化後のフロンティア(赤実線)が右上方向にシフトしている。各モデルの位置も変わる:
- Haiku: キャッシング後も低コストだが、品質が向上
- Sonnet: 最適化後に「Haiku単価でSonnet品質」の位置に移動
- Opus: 最適化後に「Sonnet単価でOpus品質」の位置に移動
プロンプトキャッシングの仕組みと経済性
プロンプトキャッシングはAnthropicのAPIが提供するトークン削減機能だ。一度処理したプロンプトのプレフィックスをサーバー側にキャッシュし、次のリクエストで同じプレフィックスが来た場合に再処理をスキップする。
キャッシュされたトークンはリスト価格の約1/10(input tokenの10%)で請求される。つまり、1,000,000トークンのシステムプロンプトを100回送信する場合:
- キャッシュなし: 100,000,000トークン分の費用
- キャッシュあり(90%ヒット率): 1,000,000 + 90,000,000×0.1 = 10,000,000トークン分の費用
この場合90%のコスト削減が達成できる。これが「プロンプトキャッシングがフロンティアを移動させる」という意味だ。Opusの品質をSonnetの予算で利用できる状況が生まれる。
Lucasの言葉を借りれば、「キャッシングによって、高いモデルをより安く使えるようになるため、モデル選択の判断軸自体が変わる」。
プロンプトキャッシングの実装
キャッシュヒット率80〜90%を達成するための2つの鉄則:
- messagesの末尾追記のみ — 会話履歴は先頭から変えない。新しいメッセージは常に末尾に追加する
- system promptに動的変数を入れない — 現在時刻、リクエストID、ユーザー固有情報をsystem promptに含めると、毎回キャッシュが無効化される
# プロンプトキャッシングの実装例
import anthropic
client = anthropic.Anthropic()
# NG: system promptに動的変数を含めるとキャッシュが毎回ミス
def bad_implementation(user_query: str, current_time: str, user_id: str):
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=1024,
system=f"""あなたはカスタマーサービスエージェントです。
現在時刻: {current_time} # ← これがキャッシュを破壊する
ユーザーID: {user_id} # ← これもキャッシュを破壊する
[長い会社ポリシードキュメント...]""",
messages=[{"role": "user", "content": user_query}]
)
return response
# OK: system promptは静的。動的情報はmessages内に移動
STATIC_SYSTEM_PROMPT = """あなたはカスタマーサービスエージェントです。
[長い会社ポリシードキュメント...]
[手順マニュアル...]
[FAQ...]""" # これはキャッシュされる(変化しないため)
def good_implementation(user_query: str, current_time: str, user_id: str,
conversation_history: list):
# 動的情報はmessagesの最初のユーザーターンに入れる
context_message = f"現在時刻: {current_time}\nユーザーID: {user_id}"
messages = [
{"role": "user", "content": context_message},
{"role": "assistant", "content": "了解しました。"},
# 既存の会話履歴(末尾追記のみ)
*conversation_history,
# 新しいメッセージは末尾に追加
{"role": "user", "content": user_query}
]
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=1024,
system=STATIC_SYSTEM_PROMPT,
messages=messages
)
return response
コンテキスト衛生の実践(66%削減事例)
Lucasはコンテキスト衛生の具体的な効果を2つの事例で示した。
事例1:JSONからMarkdownへの変換で66.4%トークン削減
ツールレスポンスのデータをJSON形式で返す代わりに、Markdownフォーマットで返すことで66.4%のトークン削減を達成した。タイムスタンプも効率的な形式に変換している。
JSONとMarkdownでは情報量は同じだが、トークン数が大幅に異なる:
# NG: 過剰なJSON形式(トークン消費が多い)
tool_response_json = {
"flight_search_results": {
"query_timestamp": "2026-05-25T09:30:45.123456Z",
"query_parameters": {
"origin": "NRT",
"destination": "LHR",
"departure_date": "2026-06-15"
},
"results": [
{
"flight_id": "BA006",
"airline": "British Airways",
"departure_time": "2026-06-15T11:30:00+09:00",
"arrival_time": "2026-06-15T16:45:00+01:00",
"duration_minutes": 795,
"price_usd": 1245.00,
"available_seats": 12
}
]
}
}
# OK: 効率的なMarkdown形式(66.4%削減)
tool_response_markdown = """
## フライト検索結果
検索日時: 2026-05-25 09:30 UTC | NRT→LHR | 出発: 2026-06-15
| フライト | 出発 | 到着 | 所要時間 | 価格 | 残席 |
|---|---|---|---|---|---|
| BA006 | 11:30+9 | 16:45+1 | 13h15m | $1,245 | 12 |
"""
事例2:ウェブ検索の重複排除で77%トークン削減
ウェブ検索ツールが返す結果には、重複URLや無関係なコンテンツが含まれることが多い。これを適切に処理することで:
- トークン: 77%削減
- コスト: 65%削減
- 精度: 9%向上(余分なノイズが減ったため)
コスト削減と精度向上が同時に達成できるというのは特に注目すべき点だ。通常「コスト削減」と「精度向上」はトレードオフだが、不必要な情報を取り除くことは精度も向上させる。
なぜ不要な情報を削減すると精度が上がるのか。これはLLMの「注意機構」の特性によるものだ。コンテキストウィンドウが長くなるほど、モデルは重要な情報を見つけるのに認知リソースを分散させる。「ロストインザミドル(Lost in the Middle)」と呼ばれる現象で、長いコンテキストの中盤に置かれた重要な情報が見落とされやすいことが研究で示されている。
コンテキスト衛生は単なるコスト最適化ではなく、モデルの実効的な知性を高める作業だ。「モデルが見る情報の質を上げる」という観点から取り組むと、モデル選択と同等かそれ以上の効果が得られることがある。
# コンテキスト衛生の実装例:ウェブ検索結果のクリーンアップ
from urllib.parse import urlparse
def clean_search_results(raw_results: list[dict]) -> str:
"""ウェブ検索結果をクリーンアップして77%トークン削減"""
seen_domains = set()
cleaned = []
for result in raw_results:
url = result.get("url", "")
domain = urlparse(url).netloc
# 重複ドメインをスキップ(同じサイトの複数ページは不要)
if domain in seen_domains:
continue
seen_domains.add(domain)
# 必要な情報のみ抽出(タイトル・URL・スニペットのみ)
cleaned.append(
f"**{result['title']}**\n"
f"{url}\n"
f"{result['snippet'][:200]}" # スニペットは200文字まで
)
# 最大5件に制限(それ以上は通常ノイズ)
if len(cleaned) >= 5:
break
return "\n\n".join(cleaned)
Workshopデモ:TAILbenchでの3モデル×2思考×3努力スイープ
Lucasはワークショップのデモとして、TAILbench(Tailored Airline Benchmark)を使った実際のモデル比較スイープを行った。
TAILbenchはカスタマーサービスのエアラインシナリオに特化したベンチマークで、まさにLucasが話していた「自分のユースケースに特化したeval」の実例だ。
スイープの設定は:
- モデル: Haiku 4.5 / Sonnet 4.6 / Opus 4.7(3種類)
- Thinking: on / off(2種類)
- Effort level: low / medium / high(3種類)
この組み合わせを全て試した結果の主要な発見:
- Opus 4.7 high effort + thinking on が最高精度を達成
- しかも Sonnet 4.6 よりも使用トークン数が少ないという反直感的な結果
- Haiku 4.5 は thinking on にすると精度は上がるが、コストとレイテンシが最悪になる
- Sonnet 4.6 は thinking off の high effort でも競争力のある精度を示す
これはLucasが理論として説明した「インテリジェントなモデルは少ないターンでタスクを完了する」を実データで裏付けるものだ。
このデモの重要な点は、TAILbenchというドメイン特化のevalがあったからこそ、このような詳細な比較ができたということだ。公開ベンチマークであれば、Opus 4.7が最良と分かるかもしれないが、「Sonnetより少ないトークンで済む」という具体的な事実は自分のevalでしか分からない。
また、Code with Claude London 2026の全セッション解説でも紹介しているが、このワークショップは他のセッションと組み合わせることでより深く理解できる。同イベントで発表されたClaudeの能力曲線理論や、エージェントのツール設計パターンと組み合わせることで、モデル選択の判断がより精度の高いものになる。
TAILbenchが示すevalの設計思想
TAILbenchの設計で特に参考になるのは、評価観点の多層化だ。
航空会社のカスタマーサービスエージェントには、単に「正しい答えを返す」以上の要求がある:
- 正確性: フライトの遅延補償額、ルールが正確に反映されているか
- ローカライゼーション: 顧客の国の規制・通貨・日付形式が適切か
- トーン: 謝罪が必要な場面で適切に謝罪しているか
- エスカレーション: 人間のオペレーターへの引き継ぎが必要な状況を正しく判断しているか
- 効率性: 不必要な質問を繰り返していないか
これら5つの観点を別々のメトリクスとして計測することで、モデルAが「正確性は高いがトーンが機械的」、モデルBが「全体的にバランスが良い」といった微細な差異を定量化できる。
あなたのシステムでも同様に、「ひとつの総合スコア」ではなく「複数の観点を個別に計測する」アプローチが、モデル選択の意思決定を精密にする。
Claudeの思考プロセスのトレース
TAILbenchデモでLucasが特に強調したのは、中間ステップのトレーサビリティだ。
エージェントが失敗した場合、「なぜ失敗したか」を素早く特定するためには、エージェントの思考プロセスと各ツール呼び出しのログが不可欠だ。以下のような情報を記録する:
- どのツールをどの順序で呼んだか
- 各ツール呼び出しのパラメータと結果
- thinking blockの内容(thinkingが有効な場合)
- 最終的な意思決定に至る推論の流れ
このトレースデータがあれば、「モデルの知識が足りなかったのか」「ツール設計が悪かったのか」「システムプロンプトが曖昧だったのか」を区別できる。多くの場合、「モデルの問題」に見えた失敗は実はシステム設計の問題だ。
このトレーサビリティの重要性は、Lucasのeval失敗パターンの議論とも直結している。インフラ障害とモデル失敗を区別するためにも、コンテキスト汚染を検出するためにも、詳細なトレースログが必要だ。
3つのまとめ

Lucasはセッションを3つのポイントで締めくくった。
これらの教訓を実践に移すための最小ステップは:
- 今運用しているシステムから20タスクを選んでevalセットを作る
- 複数のモデル×effortの組み合わせをスイープする
- 「成功1件あたりのコスト」で比較する
- プロンプトキャッシングのヒット率を測定し、80%未満なら改善する
このプロセスを一度構築すれば、次のモデルリリース時に数時間で判断できるインフラになる。
Lucasのメッセージの核心
セッション全体を通してLucasが伝えたかったのは、「モデル選択を直感・話題・ベンダーの主張から解放し、データドリブンな意思決定にすること」だ。
これは単なる技術論ではなく、組織論でもある。PMが「来週のリリース前に切り替えるべきか?」と聞いてきたとき、エンジニアが「社内evalによると、このモデルへの切り替えは精度+3%、コスト-8%、レイテンシに変化なし。切り替えを推奨します」と答えられれば、意思決定の質が根本から変わる。
公開ベンチマークはメディアが騒ぎ、PMが気にするが、ビジネスに直結するのは自分のシステムの実測値だ。Lucasのフレームワークはまさにその「自分のシステムの実測値」を取得するための方法論だ。
参照ソース
- Code with Claude London 2026 — YouTube動画「Picking the right model」 — Lucas(Anthropic Applied AI)による本セッションの公式動画
- Anthropic Cookbook — GitHub — プロンプトキャッシング・eval設計のサンプルコード集
- Anthropic Documentation — Extended Thinking — AdaptiveThinkingとeffort levelの公式ドキュメント
- Anthropic Documentation — Prompt Caching — プロンプトキャッシングの実装ガイド