システム設計は、独学がとにかく難しい分野です。負荷分散、キャッシュ、データ分割、CAP定理……用語は聞いたことがあっても、それらがどう組み合わさって「スケールするシステム」になるのかは、断片的な記事をいくら読んでも像を結びません。とりわけ、システム設計面接を控えた人や、スケールで詰まったバックエンドエンジニアにとって、これは切実な壁です。puncsky/system-design-and-architectureは、この壁を越えるための——2015年から世界中のエンジニアに読まれ続けてきた、大規模システム設計の“体系的な学習リポジトリ”です。作者はTian Pan(puncsky)氏、GitHubで3,000スター超(2026年7月時点)を集めています。
この記事を読むと、①このリポジトリで結局何が学べるのか(分散システム・DB・キャッシュ・負荷分散・CAPから実設計・面接対策まで)、②どんな課題を解決するのか(システム設計が断片的にしか学べない問題)、③何を代替できるのか(散在する記事の寄せ集め学習、高価な面接対策教材)が分かります。なお、AIエージェントやLLMアプリを本番規模で動かすときも、この「スケーラブルなシステム設計」の素養は土台として効いてきます(AIエージェントフレームワーク徹底比較2026のような“動かす仕組み”の話とも地続きです)。

- ・system-design-and-architectureは、2015年から続く大規模システム設計の学習リポジトリ(3,000★超)。
- ・分散システム・DB・キャッシュ・負荷分散・CAP定理などを体系的にカバー。
- ・Instagram・Uber・Netflix・Stripeなど、実サービスの設計例を通して学べる。
- ・「実践」「理論」「面接対策」の3本柱で、システム設計面接の準備にも使える。
- ・英語(en/)・中国語(zh-CN/)構成。ライセンスはGPL v3。
1. system-design-and-architectureとは:システム設計を体系的に学べるリポジトリ

system-design-and-architectureは、大規模システムをどう設計するかを、体系立てて学べるようにまとめたオープンな教材リポジトリです。作者のTian Pan(puncsky)氏が2015年から公開・更新し続けており、GitHubの説明は「大規模システムの設計方法を学ぶ。システム設計面接の準備を」。
このリポジトリが長年支持されてきた理由は、「点」の知識を「線」と「面」に編み直してくれることにあります。ネット上には負荷分散やキャッシュの記事が無数にありますが、それらは断片的で、初学者は「結局どう組み合わせるのか」が掴めません。本リポジトリは、これらを理論 → 実践 → 面接対策という一貫した流れで整理し、全体像から個別技術へと降りていけるように構成されています。
内容の柱は、大きく3つに分かれます。
・理論(theories):分散システム、データベース、キャッシュ、負荷分散、CAP定理などの原理
・実践(in practice):Instagram・Uber・Netflixなど実サービスの設計を題材にしたケーススタディ
・面接対策(interview):システム設計面接で問われる考え方と、その臨み方
つまりこのリポジトリは、「システム設計を、記事の寄せ集めでなく“1冊の体系”として学べる」場所です。ある種のオープンな教科書であり、しかもGitHub上で継続的に育てられてきた点に価値があります。
- ・system-design-and-architecture=2015年から続く、システム設計の“オープンな教科書”。
- ・理論・実践・面接対策を一貫した流れで学べ、点の知識を面に編み直せる。
2. なぜ必要か:システム設計が「断片的にしか学べない」を埋める
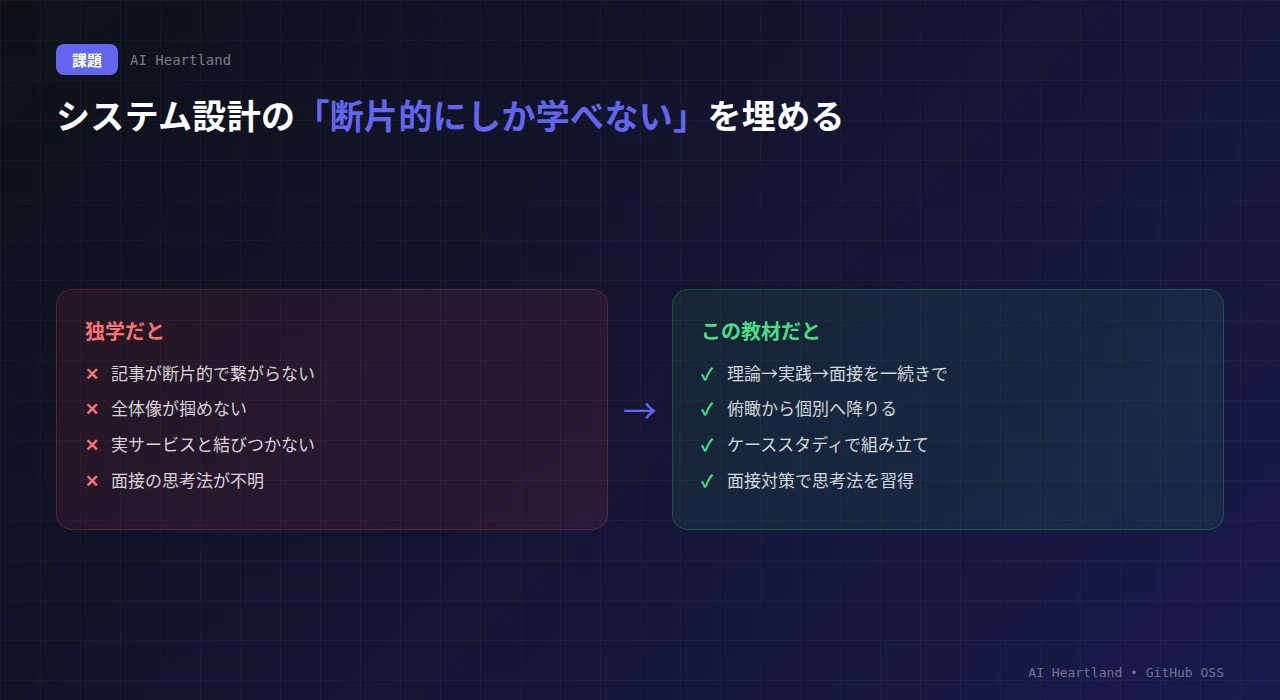
このリポジトリが解決するのは、システム設計という分野が構造的に抱える「体系的に学びにくい」問題です。実務でもキャリアでも重要なのに、独学のハードルが高い——という悩みは、多くのエンジニアに共通します。
具体的な困りごとはこうです。
・記事が断片的:個別技術の記事はあっても、それらの繋がりが見えない
・全体像が掴めない:「スケールするシステム」の全体像を俯瞰する視点を得にくい
・実サービスと結びつかない:理論を学んでも、実際の設計にどう使うか像を結ばない
・面接の思考法が不明:システム設計面接で「何をどう考えるべきか」が分からない
このリポジトリは、これらを「理論・実践・面接を一続きにした体系」で埋めます。断片性には体系的な構成で応え、全体像には俯瞰から個別へ降りる流れで応え、実サービスとの結びつきにはケーススタディで応え、面接の思考法には面接対策セクションで応える——という具合です。
- ・これは「学習教材」であり、そのまま動くソフトウェアやフレームワークではない。
- ・英語(と中国語)中心。日本語版は無いため、本記事のような解説と併読すると理解が早い。
なお、システム設計の学習リソースとしては、本リポジトリのほかにもDonne Martinの「system-design-primer」など著名なものがいくつかあります。その中でpuncsky版が支持されてきたのは、理論・実践・面接対策のバランスの良さと、実サービスのケーススタディの具体性、そして2015年から一貫して更新され続けてきた継続性にあります。どれか1つだけを選ぶ必要はなく、複数を併読して相互補完するのが賢い学び方ですが、「まず1つ、体系立ったものを腰を据えて読みたい」という人にとって、puncsky版は有力な選択肢になります。
この必要性が効いてくるのは、個人開発の延長から、本番規模のシステムへと責任範囲が広がるほどです。小さなアプリなら設計を意識せずとも動きますが、ユーザーが増え、データが膨らみ、可用性が問われる段階になると、途端に「設計を知らないこと」がボトルネックになります。system-design-and-architectureは、その移行期に土台となる設計の語彙と思考法を与えてくれます。
もう一つ、このリポジトリが埋める重要なギャップが「言語化できない暗黙知」です。経験豊富なエンジニアは、なぜか適切な設計をさっと選べますが、それは頭の中に「こういう要件ならこう」という判断のパターンが蓄積されているからです。しかしその暗黙知は、本人ですら言葉にしづらく、後進に伝えにくい。本リポジトリは、そのベテランの頭の中にある判断パターンを、明示的な知識として言語化している点に価値があります。「なぜここでキャッシュを挟むのか」「なぜこのデータは分割すべきなのか」——熟練者なら感覚で分かることを、根拠とともに説明してくれる。これは、独学者にとっては“いきなりベテランの思考を覗ける”近道であり、面接対策としても、単なる暗記を超えた「設計者としての語り」を身につける助けになります。2015年から積み上げられ、世界中のエンジニアの目に晒されて改善され続けてきたという事実が、その内容の信頼性を裏づけています。
3. カバー範囲:分散システム・DB・キャッシュ・負荷分散・CAP

このリポジトリの理論パートは、システム設計に必要な土台を広くカバーします。主なテーマを整理します。
・アーキテクチャ基礎:アーキテクチャ入門、Webサービスのスケーリング、容量見積もり(capacity planning)
・分散システム:データ分割(partitioning)、ルーティング、複製(replication)、一貫性(consistency)、CAP定理
・インフラ:ロードバランサーの種類、フェイルオーバー、並行性モデル
・データ構造:ブルームフィルタ、スキップリスト、B-tree vs B+tree
・データベース:リレーショナルDB、NoSQL(4種類)、キーバリューキャッシュ
・処理基盤:ストリーム処理とバッチ処理、Lambdaアーキテクチャ
・クラウド:クラウドデザインパターン、公開APIの選択
注目すべきは、「抽象的な理論」と「具体的なデータ構造」の両方を扱っている点です。CAP定理のような概念的な話から、ブルームフィルタやB+treeといった実装レベルのデータ構造まで降りていく。この縦の射程の広さが、「なぜこの設計を選ぶのか」を根っこから理解する助けになります。
たとえば「大量のキーの存在チェックを高速にしたい」という要件があったとき、なぜブルームフィルタが選ばれるのか。「範囲検索の多いインデックスをどう持つか」でなぜB+treeなのか。「可用性と一貫性のどちらを優先するか」でCAP定理がどう効いてくるのか——これらは、概念と実装を行き来して初めて腑に落ちる話です。個別技術の記事を単発で読んでいるだけでは、「知ってはいるが、いつ使えばいいか分からない」状態に留まりがちです。本リポジトリは、その断絶を「なぜ・いつ・どう使うか」の文脈で埋めてくれます。とりわけ、容量見積もり(capacity planning)の章は実務でも面接でも重宝します。「1日に何億リクエスト、1リクエスト何KB、ならばストレージと帯域はどれくらい必要か」——この“ざっくり見積もる力”は、設計の初手として欠かせず、しかし独学では身につけにくいスキルです。
主要テーマを層で整理すると次のとおりです。
| 層 | 主なテーマ |
|---|---|
| 全体設計 | アーキテクチャ入門・スケーリング・容量見積もり |
| 分散 | データ分割・複製・一貫性・CAP定理 |
| インフラ | 負荷分散・フェイルオーバー・並行性 |
| データ | RDB・NoSQL(4種)・KVキャッシュ・データ構造 |
| 処理 | ストリーム/バッチ・Lambdaアーキテクチャ |
- ・概念(CAP等)と実装(B+tree・ブルームフィルタ等)を往復でき、「なぜこの設計か」を根から理解できる。
- ・容量見積もりやトレードオフの考え方など、面接でも実務でも問われる“判断力”が身につく。
4. 実践のケーススタディ:Instagram・Uber・Netflix等の設計
理論を学んでも、実際の設計に落とせなければ意味がありません。このリポジトリの実践パートは、誰もが知る実サービスを題材に、設計の進め方を示します。扱われるお題には、次のようなものがあります。
・Instagram:写真ストレージの設計
・Uber:配車・位置情報システムの設計
・Netflix:動画配信・レコメンドの設計
・Stripe:決済システムの設計
・Facebook / LinkedIn:フィード・負荷分散などの設計
これらのケーススタディが優れているのは、「要件 → 見積もり → 設計 → トレードオフ」という思考の順序を追体験できる点です。たとえば「写真共有サービス」を設計するなら、まず規模を見積もり、書き込み/読み出しの特性を考え、データ分割やキャッシュ、CDNをどう配置するかを決めていく——という流れです。典型的なスケーラブルWebサービスの構成を図にすると、次のようなイメージになります(本リポジトリで繰り返し登場する基本形です)。
(KVストア)"] App2 --> Cache App1 --> DB[("DB(分割・複製)")] App2 --> DB App1 --> Q["メッセージキュー"] Q --> W["非同期ワーカー"] DB --> CDN["CDN / オブジェクトストレージ"]
この図の一つひとつの要素——ロードバランサー、キャッシュ、分割・複製されたDB、キュー、CDN——が、理論パートで学んだ概念に対応しています。「理論で部品を知り、ケーススタディで組み立て方を学ぶ」という往復が、システム設計を“使える知識”に変えます。この設計思考は、実はAIアプリの本番運用(推論サーバーの負荷分散、ベクトルDBのスケール、非同期のバッチ処理)にもそのまま応用が効きます。
ケーススタディが優れているもう一つの点は、「一つの正解」を教え込まないことです。システム設計に唯一の正解は無く、要件次第でトレードオフが変わります。たとえば「写真共有サービス」なら、読み出しが圧倒的に多いのか、書き込みも多いのか、遅延をどこまで許容できるのか——前提が変われば、キャッシュ戦略もデータ分割の切り方も変わります。本リポジトリのケーススタディは、この「前提を置き、トレードオフを比較し、選ぶ」という思考のプロセスそのものを追体験させてくれます。暗記ではなく、判断の型が身につくわけです。これはシステム設計面接で面接官が本当に見ている「候補者がどう考えるか」に、そのまま直結します。
具体的にどんな観点でトレードオフを考えるのか、代表的なお題ごとに“設計で悩むポイント”を挙げると、理解が具体的になります。
・Instagram(写真保存):巨大なメディアをどこに置くか(オブジェクトストレージ+CDN)、メタデータのDBをどう分割するか
・Uber(配車):刻々と動く位置情報をどう扱うか、近傍検索をどう高速化するか
・Netflix(動画配信):帯域をどう捌くか(CDN・エンコード)、レコメンドをどう回すか
・Stripe(決済):一貫性と冪等性をどう担保するか、二重課金をどう防ぐか
・LinkedIn / Facebook(フィード):フィード生成をプッシュ型かプル型か、どう負荷分散するか
こうしたお題は、いずれも「どれか一つの技術」では解けません。複数の部品を、要件に応じて組み合わせる必要があり、そこにこそシステム設計の面白さと難しさがあります。本リポジトリは、その組み合わせ方を実サービスの文脈で見せてくれる点で、抽象論に終始しがちな他の教材と一線を画します。
5. 使い方:3つのセクション(実践・理論・面接対策)と学習パス
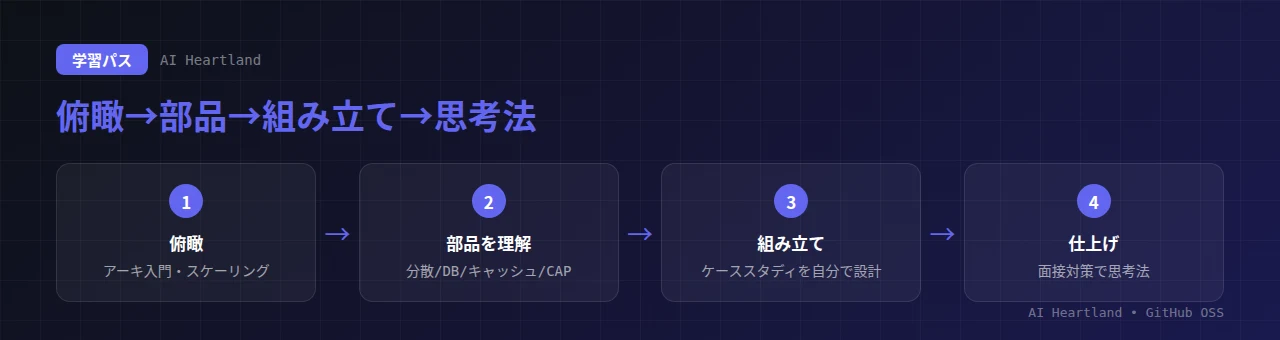
このリポジトリは、「実践」「理論」「面接対策」の3セクションに整理されており、レベル別(初級・中級・シニア)の学習パスが用意されています。読み方の順序に決まりはありませんが、目的別におすすめの進め方があります。
・全体像を掴みたい:まずアーキテクチャ入門とスケーリングの章から俯瞰する
・土台を固めたい:理論セクションで、分散・DB・キャッシュ・CAPの原理を押さえる
・設計力を上げたい:ケーススタディで、実サービスの設計を手を動かして追う
・面接に備えたい:面接対策セクションで、問われる思考法と臨み方を確認する
加えて、リポジトリには関連リンクを集めたawesome-system-design.mdがあり、さらに深掘りしたいテーマの入口として使えます。学習の流れをまとめると、こうなります。
・アーキテクチャ入門で全体像を俯瞰する
・理論で部品(分散・DB・キャッシュ・CAP)を理解する
・ケーススタディで組み立て方を追体験する
・面接対策で思考法を仕上げる
・awesome-system-design.md から関連リソースへ広げる
「俯瞰 → 部品 → 組み立て → 思考法」の順で読むと、断片だった知識が一本の線に繋がる——これがこのリポジトリの正しい使い方です。英語(と中国語)中心なので、本記事のような日本語解説を地図として併読すると、迷わず読み進められます。
学習効果を最大化するコツも添えておきます。受け身で読むだけにしないことです。ケーススタディを読むときは、まず自分で「自分ならどう設計するか」を紙に書き出してから、リポジトリの解説と突き合わせてみる。すると、自分の設計に欠けていた観点(容量見積もりの甘さ、単一障害点の見落とし、一貫性の扱いの雑さなど)が浮き彫りになります。この「自分で設計→答え合わせ」のサイクルこそ、システム設計面接の本番でそのまま使える練習になります。面接では、面接官と対話しながら要件を詰め、ホワイトボードに設計を描いていくからです。もう一つのコツは、一度に完璧を目指さないこと。システム設計は範囲が広く、全部を一気に理解するのは不可能です。まずは頻出テーマ(負荷分散・キャッシュ・DB分割・CAP)から押さえ、必要に応じて深掘りしていく——という段階的な進め方が、挫折せずに続けるコツです。2015年から積み重ねられた膨大な内容だからこそ、「全部読む」より「必要な線から辿る」のが賢い使い方になります。
6. どう活かすか:向いている人・注意点

最後に、活用すべきかの判断材料を整理します。
このリポジトリが向いている人
・システム設計面接を控えており、体系的に対策したい
・スケールで詰まった経験があり、設計の土台を固め直したい
・個人開発から本番規模のシステムへ、責任範囲が広がりつつある
・AIアプリ/エージェントを本番規模で運用する土台として、設計知識を身につけたい
・断片的だった知識を、1つの体系として整理し直したい
留意すべき点
・これは学習教材であり、動くソフトウェアではない(読んで身につけるもの)
・英語(と中国語)中心で、公式の日本語版は無い
・内容は普遍的だが、個別技術の最新動向は別途、一次情報で補う必要がある
いくつか注意点も押さえましょう。まず教材であること。当たり前ですが、読むだけで設計力がつくわけではなく、ケーススタディを自分で手を動かして設計してみることで初めて身につきます。次に言語。英語中心のため、technical英語に不慣れなら、本記事のような日本語解説を併読すると効率的です。そして最新性。システム設計の原理は普遍的ですが、個別のミドルウェアやクラウドサービスの最新機能は移り変わるため、実装時は公式ドキュメントで補ってください。ライセンスはGPL v3なので、内容を引用・改変して再配布する場合は条件の確認が必要です。
- ・学習教材。ケーススタディは“読む”だけでなく“自分で設計してみる”と身につく。
- ・英語中心。日本語解説を地図に併読すると理解が早い。
- ・原理は普遍的だが、個別技術の最新仕様は一次情報で補う。ライセンスはGPL v3。
まとめ
system-design-and-architectureは、「断片化しがちなシステム設計の知識を、1つの体系として学べるようにする」という価値で、2015年から世界中のエンジニアに読まれてきたオープンな学習リポジトリです。理論で部品を知り、ケーススタディで組み立て方を学び、面接対策で思考法を仕上げる——スケーラブルなシステムを設計する力の、確かな土台になります。
- ・system-design-and-architectureは、2015年から続くシステム設計の学習リポジトリ(3,000★超)。
- ・分散システム・DB・キャッシュ・負荷分散・CAPなどを、理論から体系的にカバー。
- ・Instagram・Uber・Netflix等のケーススタディで、設計の進め方を追体験できる。
- ・「実践・理論・面接対策」の3本柱で、システム設計面接の準備にも使える。
- ・学習教材(英語中心・GPL v3)。AIアプリを本番規模で運用する土台としても効く。
最後に、AI時代にこそシステム設計の知識が効く理由を、もう一度強調しておきます。LLMやAIエージェントは強力ですが、それらを「一度動かす」ことと「多数のユーザーに安定して提供する」ことの間には、深い谷があります。推論のレイテンシをどう抑えるか、急増するリクエストをどう捌くか、ベクトルDBをどうスケールさせるか、コストをどう最適化するか——これらはすべて、本リポジトリが教える古典的なシステム設計の応用です。AIの“頭脳”がどれだけ賢くなっても、その周りを固める“システム”の設計は、人間のエンジニアの仕事として残り続けます。むしろAIアプリが当たり前になるほど、それを本番規模で支える設計力の価値は上がっていく。system-design-and-architectureは、その普遍的な土台を、じっくり時間をかけて身につけるに値する教材です。流行の技術は移り変わっても、「大規模なシステムをどう設計するか」という問いと、その答えを導く思考法は、驚くほど変わりません。だからこそ、2015年の内容が今も色褪せずに読まれているのです。一度身につければ長く使える——学習投資として、これほど費用対効果の高い分野もそう多くありません。フレームワークの使い方は数年で陳腐化しますが、設計の思考法はキャリアを通じて資産であり続けます。
「システム設計を、断片でなく体系で学びたい」——そう感じるなら、まずはアーキテクチャ入門の章から俯瞰し、気になるケーススタディを1つ、自分で設計してみてください。AIエージェントやLLMアプリを“動かす仕組み”の観点から捉え直したい方は、AIエージェントフレームワーク徹底比較2026も、システム設計の知識が土台として効く実例として参考になります。
参照ソース
・puncsky/system-design-and-architecture (GitHub) — 公式リポジトリ。理論・ケーススタディ・面接対策・構成の一次ソース。
・awesome-system-design(関連リンク集) — さらに深掘りするための関連リソース集。