サーバーレスでAIを動かそうとして、「デプロイサイズの上限に引っかかって関数に載らない」と詰まった経験はないでしょうか。PyTorchやffmpeg、ヘッドレスブラウザを少し足しただけで、あっという間に上限を超える——これはAI/MLをサーバーレスに乗せるときの、古くて新しい悩みの種でした。
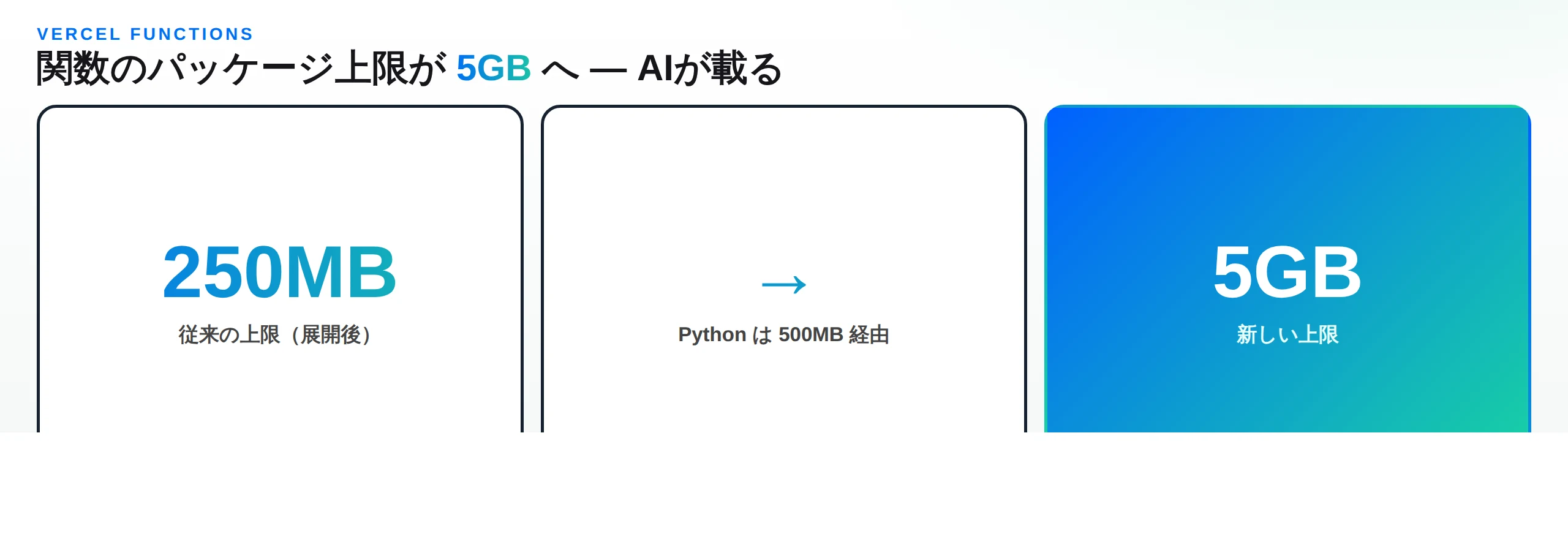
その制約を大きく緩めるアップデートが届きました。本記事で解説するのは、Vercelの公式changelog「Vercel Functions can now be up to 5 GB in package size(Vercel Functionsのパッケージサイズが最大5GBまで可能に)」です。サーバーレス関数の同梱サイズ上限が、従来の 250MB(Pythonランタイムは2026年2月に500MBへ引き上げ)から、一気に 5GB へと拡大されました。
数値だけ見ると地味な「上限緩和」ですが、AIをサーバーレスで動かしたい人にとっては意味が大きい変化です。本サイトはAI関連OSSの解説に特化しているため、本稿では「この変更で結局、何ができるようになる/何の制約が解ける/何の代わりになるのか」というAI開発者目線で読み解きます。なお、Vercel公式サイトは本稿の執筆環境からは直接取得できなかったため、確定情報(5GBという上限・従来値・Fluid computeの概要)と、筆者の解釈・一般的事実とを区別して記述します。具体的な対象ランタイム・プラン・有効化条件は、末尾の公式changelogで必ず確認してください。
- ・Vercel Functionsのパッケージ上限が250MB→最大5GB(Pythonは500MB経由)に拡大。
- ・PyTorch・Transformers・ffmpeg・ヘッドレスChromium・モデル重みを関数に同梱しやすくなる。
- ・「外部から都度ダウンロード」「専用サーバーを立てる」といった回避策が要らなくなるケースが増える。
- ・Fluid compute(AI/I-O向けの新実行モデル)を軸にした上限緩和の流れの一環。
- ・ただし5GBは“同梱サイズ”の上限。メモリ・コールドスタート・課金は別制約で、設計判断は引き続き必要。
1. 何が変わったのか — 250MBから5GBへの拡大
まず事実を正確に押さえます。今回の変更は、Vercel Functions(Vercel上のサーバーレス関数)の 「パッケージサイズ(デプロイ時に同梱できるコード+依存+ファイルの合計サイズ)」の上限 を、最大 5GB まで引き上げる、というものです。

従来、Vercel Functionsの同梱サイズは 展開後(uncompressed)で250MB が基本的な上限でした。これはVercelに限った話ではなく、サーバーレスの世界では長く一般的だった水準です(AWS Lambdaのzipデプロイも展開後250MBが目安)。さらにVercelは2026年2月に、Pythonランタイムの上限を500MB へ引き上げていました。今回の5GBは、その250MB/500MBという基準を、10倍前後の桁 で塗り替える変更です。
なぜ「同梱サイズの上限」がこれほど語られるのか。サーバーレス関数は、リクエストが来たときに コードと依存を一式まとめたパッケージ を取り出して実行します。このパッケージに入れられる量が上限で頭打ちになると、「使いたいライブラリが入らない」「必要なバイナリを同梱できない」という形で、作れるものそのものが制限 されます。つまりパッケージ上限は、単なるストレージの話ではなく、その関数で何を動かせるかの天井 なのです。
開発からデプロイまでの流れの中で、この「上限」がどこに効くのかを図にすると次のようになります。
コード+依存+ファイル"] DEPS["依存ライブラリ
PyTorch / ffmpeg 等"] --> BUNDLE ASSET["モデル重み・
バイナリ"] --> BUNDLE BUNDLE --> GATE{"パッケージ上限?
旧250MB → 新5GB"} GATE -->|"超過"| FAIL["デプロイ失敗
(従来ここで詰まる)"] GATE -->|"以内"| DEPLOY["デプロイ成功"] DEPLOY --> RUN["リクエスト時に展開して実行"]
図の通り、ボトルネックは「バンドルが上限を超えるかどうか」という一点に集約されます。上限が250MBのときは、重い依存を足した瞬間に左の「デプロイ失敗」へ落ちていました。それが5GBになることで、これまで弾かれていた構成が「デプロイ成功」側に回れるようになる——これが変更の本質です。言い換えれば、開発者が「この依存は重すぎるから諦めよう」と自己検閲していた選択肢が、再び机の上に戻ってくる、ということでもあります。
2. なぜAI開発に効くのか — 「250MBの壁」が解ける
ここからが本サイトの読者にとっての核心です。この変更でAI開発に何が起きるのか。結論からいえば、「サーバーレスでAIを動かすときに頻発していた『250MBの壁』が、多くのケースで解ける」ことに尽きます。

AI/MLの処理は、依存とアセットが重くなりやすい という宿命を持ちます。たとえばPythonで機械学習を動かそうとすると、PyTorchやTensorFlow、Transformers、onnxruntimeといったライブラリは、それぞれ単体で数百MB級になることが珍しくありません。さらに、推論に使うモデルの重みファイル自体が数百MB〜GB級になります。動画や画像を扱うならffmpeg、ブラウザ自動化ならヘッドレスChromium——これらネイティブバイナリも数十〜数百MBを消費します。合計すれば、250MBという上限はあっという間に飽和していました。
従来、この壁にぶつかった開発者は、いくつかの回避策を強いられてきました。(1) モデルや重い資産を外部ストレージ(S3等)に置き、関数の起動時に毎回ダウンロードする。(2) 重い処理だけを専用のGPU/CPUサーバーや別の推論サービスに切り出す。(3) そもそもサーバーレスを諦めて、常時起動のコンテナ/VMで動かす。いずれも有効ですが、構成が複雑になり、レイテンシや運用コスト、状態管理の難しさ を抱えます。「関数1つで完結させたいのに、周辺インフラが増えていく」というのは、サーバーレスの手軽さを削ぐ典型的な痛点でした。
パッケージ上限が5GBになると、これらの多くが 「関数の中に同梱して、そのまま実行」 という最もシンプルな形に戻せます。読者が探している「①結局何ができる/②何を解決する/③何を代替する」に当てはめると——① ffmpegやChromium、軽量〜中規模のML依存を含む処理を、サーバーレス関数1つで動かせる。② 外部ダウンロードや専用サーバーといった回避策の複雑さを解消する。③ 「重いから」という理由だけで立てていた常時起動サーバーや、別建ての推論用インフラの一部を代替できる——という整理になります。
ここで誤解を避けたいのは、「5GB載るからLLMがそのまま動く」わけではない、という点です。5GBは 同梱サイズ の上限であり、実行時のメモリ・計算資源・コールドスタート・課金は別の制約です。現実的な恩恵は、巨大LLMの推論 よりも、「重い依存を必要とする中小規模のAI処理」をサーバーレスに乗せやすくなる ことにあります。この線引きを押さえておくと、過剰な期待も過小評価もせずに使えます。
具体的な構成で考えると違いがはっきりします。たとえば「アップロードされた動画から音声を抜き出し、文字起こし用に整える」処理を作るとします。従来は、ffmpegが250MBの壁に収まりきらず、別途ffmpeg入りのコンテナを用意し、関数からそれを呼び出す といった二段構えになりがちでした。関数・コンテナ・両者をつなぐキュー——と部品が増え、デプロイも監視も二重になります。パッケージ上限が5GBになれば、ffmpegを関数に同梱し、1つの関数の中で「受け取る→変換する→返す」を完結 できる見込みが立ちます。部品が減れば、考えることも、壊れる箇所も減ります。サーバーレスの「関数1つで完結する」という本来の手軽さを、AIがらみの重い処理でも取り戻せる——これが体感としての一番の変化です。
3. これまで「載らなかった」もの — 重い依存の正体
「重いから載らなかった」を、もう少し具体的に見ておきましょう。AI/ML開発でパッケージを膨らませる代表的な要素を並べると、250MBがいかに窮屈だったかが分かります。

・PyTorch / TensorFlow:深層学習の中核ライブラリ。CUDA関連を含めると単体で数百MB〜1GB近くに達することもある
・Transformers(Hugging Face):LLM・各種モデルを扱う定番。依存込みで重くなりやすい
・モデル重み(weights):埋め込みモデルや小型分類器でも数百MB、少し大きいモデルならGB級
・ffmpeg:動画・音声処理の必須バイナリ。AIで動画を扱うOSSはほぼ必ず依存する
・ヘッドレスChromium:ブラウザ自動化・スクレイピング・スクショ生成。単体で100MB超
・onnxruntime / ネイティブ拡張:推論高速化やネイティブバインディングで容量を消費する
本サイトで扱ってきたOSSに引き付けると、この変化の意味はさらに具体的になります。たとえば動画をAIで編集するツールはffmpegに依存し、ブラウザを操作するエージェント系OSSはヘッドレスChromiumを必要とします。これらは「Webサービスに組み込んでサーバーレスで動かしたい」と思っても、250MBの壁で同梱できず、別サーバー送りになりがち でした。パッケージ上限が5GBになれば、こうした重いバイナリを含む処理を、Vercel上の関数として アプリと地続きにデプロイ できる現実味が出てきます。
なお、「同梱できる」ことには、サイズ以外の地味だが重要な利点もあります。重いバイナリやモデルを外部ストレージから毎回ダウンロードする構成では、ダウンロードの待ち時間、ネットワーク障害、バージョンずれ(関数のコードと、外部に置いたモデルの世代が食い違う事故)といったリスクが常につきまといます。関数に同梱してしまえば、コードと依存・アセットのバージョンが1つのデプロイ単位に固定 され、「動いていたものが、外部ファイルの差し替えで突然壊れる」類の不具合を避けやすくなります。再現性という観点でも、同梱できることの価値は小さくありません。
もちろん「5GBあるから全部入れよう」は禁物です。同梱物が増えればビルドもデプロイも重くなり、コールドスタートにも響きます。本当に必要な依存だけを選び、不要ファイルを除外する という基本は、上限が緩んでも変わりません。むしろ「入れられてしまう」からこそ、何を入れるかの設計判断がより重要になります。
4. Fluid computeという文脈 — AIワークロード前提の実行モデル
今回の上限拡大は、単発の数値変更というより、Vercelが進める 「AI/I-O中心のワークロードを、サーバーレスで現実的に回す」 という一連の流れの中にあります。その中心にあるのが Fluid compute です。

Fluid computeは、Vercelが提供する関数の 実行モデル です。公式の説明によれば、サーバーレスのスケーラビリティと、サーバーの柔軟性を組み合わせ、API・ストリーミング・AIといった実時間/I-O中心のワークロードを効率よく回すことを狙っています。対応ランタイムは Node.js・Python・Edge・Bun・Rust で、Node.jsとPythonでは最適化された並行実行(in-function concurrency)が使えるとされています。メモリも、Fluid有効時にはPro/Enterpriseで既定2GB(1 vCPU)、最大4GB(2 vCPU)といった水準が案内されています。
なぜパッケージ上限の話とFluid computeがつながるのか。AIワークロードは「重い依存を抱え、I/Oを待ち、ときに長く走る」という特徴を持ちます。これを従来型のサーバーレス(1リクエスト1実行で、サイズもメモリも厳しめ)に押し込むのは無理がありました。そこで、並行性・メモリ・そしてパッケージサイズ といった上限を、AIワークロードが現実に必要とする水準へ引き上げていく——今回の5GB拡大も、その文脈の一手として読むと腑に落ちます。
ただし、注意したいのは 「5GBが具体的にどの条件で使えるか」 です。Fluid computeの有効化が前提なのか、対象ランタイムやプラン(Hobby/Pro/Enterprise)に違いがあるのかは、本稿の執筆環境からは公式ページを直接確認できませんでした。ここは推測で断定せず、末尾の公式changelogと制限ドキュメントで必ず確認 してください。本記事で確定として扱うのは「上限が最大5GBに拡大した」という一点と、Fluid computeの一般的な概要までです。
5. 他プラットフォームとのパッケージサイズ比較
5GBという数字を、他のサーバーレス基盤と並べると、その位置づけが見えてきます。代表的なプラットフォームの「デプロイ時に同梱できるサイズ」の目安を比較します(各社とも仕様は変わるため、導入時は公式の最新値を確認してください)。

| プラットフォーム | 同梱サイズの目安 | 方式・特徴 |
|---|---|---|
| Vercel Functions(新) | 最大5GB | zip的な手軽さのまま大容量を同梱 |
| Vercel Functions(旧) | 250MB(Python 500MB) | 従来のサーバーレス上限 |
| AWS Lambda(zip) | 展開後250MB | 手軽だが大きな依存は不可 |
| AWS Lambda(コンテナイメージ) | 最大10GB | イメージ運用が必要、構成は重め |
| Cloudflare Workers | 圧縮後 数MB〜10MB級 | 超軽量・エッジ特化 |
この並びで見ると、Vercelの5GBは 「zipに近い手軽さのまま、コンテナイメージに迫る容量を積める」中間的なポジション に来たことが分かります。AWS Lambdaで大容量を扱うにはコンテナイメージ方式に切り替える必要があり、ビルドや運用が一段重くなります。一方Cloudflare Workersは数MB級と小さく、超軽量なエッジ処理に振った設計で、そもそも重いAI依存を同梱する用途には向きません。
つまりVercelの今回の変更は、「サーバーレスの手軽さ」と「重い依存を積める容量」のトレードオフを、AI寄りに動かした ものと整理できます。これまで「容量が足りないからコンテナや専用サーバーへ」と判断していたケースの一部が、「関数のまま行ける」へと再分類される——その境界線を押し広げた、というのが比較から見える意義です。プラットフォーム選定の場面でも、「重いAI依存があるからVercelは外す」という従来の前提が崩れる点は見逃せません。Next.jsなどVercel上で動くアプリに、重いAI処理を同じ基盤のまま足せるようになるのは、開発体験としても無視できない差になります。
6. 使いどころと注意点 — コールドスタートとコスト
最後に、実務でどう向き合うかを整理します。上限が緩んだからといって、何でも詰め込めばよいわけではありません。向く使い方 と 注意すべき点 を分けて考えるのが実務的です。

向くケース:ffmpegでの動画・音声処理、ヘッドレスChromiumを使うスクショ生成やブラウザ自動化、埋め込み(embedding)や小型モデルの推論、画像処理ライブラリを使う変換処理——こうした「重いバイナリや中小規模のモデルを必要とするが、リクエスト単位で完結する」処理は、5GBの恩恵を素直に受けられます。これまで別サーバーに切り出していたものを、関数に引き戻せる可能性があります。
注意すべき点:第一に コールドスタート です。パッケージが大きいほど、関数を初めて起動する際の準備(展開・初期化)に時間がかかりやすくなります。レイテンシが重要な経路では、サイズと起動時間のバランスを測る必要があります。第二に コストとメモリ。大きな依存を読み込むほど実行時メモリを消費し、課金にも影響します。第三に 設計の規律。「5GBまで入る」は「5GBまで入れてよい」ではありません。本当に必要な依存だけを選び、不要ファイルを除外し、巨大なモデルは外部ストレージからのロードと同梱とを比較する——という判断は、上限が緩んでも、むしろ緩んだからこそ重要になります。
判断の軸を1つ持つなら、「そのアセットはリクエストのたびに必ず使うか」を問うとよいでしょう。毎回必ず使う重いバイナリ(ffmpeg、Chromiumなど)は、同梱してコールドスタートのコストを一度払う形が合理的です。一方、特定のリクエストでしか使わない巨大なモデルや、頻繁に差し替えたいモデルは、関数に焼き込むより外部ストレージから必要時にロードするほうが、パッケージを軽く保てて取り回しがよいことも多い。つまり5GBという余裕は、「全部同梱する」ためではなく、「同梱と外部ロードを、用途ごとに選べるようになった」と捉えるのが本質です。選択肢が増えたことそのものが価値であり、増えた選択肢をどう使い分けるかが、これからの設計の腕の見せ所になります。
Vercel Functionsのパッケージ上限が250MB(Python 500MB)から最大5GBへ拡大したことで、これまで「重すぎて関数に載らない」と弾かれていたAI/ML依存——PyTorch・Transformers・ffmpeg・ヘッドレスChromium・モデル重み——を、サーバーレス関数に同梱しやすくなりました。外部ダウンロードや専用サーバーといった回避策の一部が不要になり、「重いからコンテナへ」だった判断の境界線がAI寄りに動きます。Fluid computeというAI/I-O向け実行モデルの流れの中にある変更で、他社と比べても「手軽さと容量の中間」を埋める一手です。ただし5GBは同梱サイズの上限にすぎず、コールドスタート・メモリ・課金は別問題。対象プランやランタイム、有効化条件は公式changelogで確認のうえ、『使える上限』ではなく『使うべき設計か』で判断するのが賢い使い方です。
まとめ
本記事では、Vercel公式changelog「Vercel Functions can now be up to 5 GB in package size」を起点に、サーバーレス関数のパッケージ上限が250MB(Python 500MB)から最大5GBへ拡大 したことの意味を、AI開発者の視点で読み解きました。
要点は3つです。第一に、パッケージ上限は「その関数で何を動かせるかの天井」であり、AI/MLでは重い依存とモデルですぐ飽和していた——その天井が10倍前後に上がった。第二に、ffmpeg・Chromium・中小規模モデルといった「重いから別サーバー送り」だった処理を、関数に同梱して動かせる現実味が出た。第三に、これはFluid computeというAI/I-O向け実行モデルの流れの中にある変更で、他社と比べても「手軽さと容量の中間」を埋める位置づけになる。
一方で、5GBは同梱サイズの上限にすぎず、コールドスタート・メモリ・課金という別の制約は残ります。対象ランタイム・プラン・有効化条件は公式情報で確認し、「載るから載せる」ではなく「載せるべき設計か」を考える——その規律さえ持てば、サーバーレスでAIを動かす選択肢は確実に一段広がります。重い依存に阻まれてサーバーレスを諦めていた構成があるなら、いま一度、関数に引き戻せないか見直してみる価値があります。
よくある質問(FAQ)
Q1. 今回の変更を一言でいうと? Vercel Functions(サーバーレス関数)のパッケージサイズ上限が、最大5GBまで拡大されました。従来は展開後250MB(Pythonは2026年2月に500MBへ)が上限で、重いAI/ML依存やモデルを同梱しづらかったのが、5GBで現実的になります。対象条件は公式changelogで確認してください。
Q2. なぜパッケージサイズが重要なのですか? サーバーレス関数は「コード+依存+ファイル」を1パッケージにまとめて実行します。AI/MLはこの依存が重く、PyTorchやffmpeg、Chromium、モデル重みで簡単に250MBを超えていました。上限が天井になると「作れるものそのもの」が制限されるため、5GB化の影響は大きいのです。
Q3. これでサーバーレスでLLMを動かせますか? 「載るサイズが増えた」のは事実ですが、巨大LLMをそのまま動かせる意味ではありません。5GBは同梱サイズの上限で、メモリ・計算資源・コールドスタート・課金は別制約です。恩恵が大きいのは、軽量〜中規模のモデルや、ffmpeg・Chromiumのような重いバイナリを要する処理です。
Q4. Fluid computeとは関係がありますか? Vercelが進めるAI/I-O向けの実行モデルがFluid computeで、Node.js・Python・Edge・Bun・Rustに対応します。並行性・メモリ・パッケージサイズの上限緩和は、AIワークロードを意識した一連の流れの中にあります。今回の5GBがFluid前提かどうか等の詳細は公式で確認してください。
Q5. 他のプラットフォームと比べてどうですか? 目安として、AWS Lambdaはzipで展開後250MB・コンテナイメージで最大10GB、Cloudflare Workersは圧縮後数MB〜10MB級です。Vercelの5GBは「zipの手軽さでイメージ級の容量に迫る」中間ポジションといえます。各社の最新値は公式で確認してください。
Q6. 注意点はありますか? パッケージが大きいほどコールドスタートに影響しやすく、メモリ・課金にも響きます。「5GBまで入る」を「入れてよい」と取り違えず、必要な依存だけを選び、大きなモデルは外部ストレージとも比較する——という設計判断は引き続き重要です。
参照ソース
・Vercel Functions can now be up to 5 GB in package size(公式changelog) — 本記事が解説した一次情報(上限5GBの発表)
・Vercel Functions Limits(公式ドキュメント) — パッケージサイズ・各種上限の確認先
・Fluid compute(公式ドキュメント) — AI/I-O向け実行モデルの概要・対応ランタイム