この記事ではLLMプロンプト圧縮ツール Headroom に特化して解説します。LLMそのものの仕組み・主要モデル比較・ローカル実行から整理したい方は LLMとは?仕組み・主要モデル比較・ローカル実行・量子化を一気にまとめる2026年版 を、トークン最適化の全体像(RTK・Graphify・メモリ階層化など)は AIエージェントのトークン最適化|コスト削減とコンテキスト管理の5アプローチ2026 をご覧ください。
・Headroomはツール出力・ログ・RAGチャンク・会話履歴をLLMに渡す前に60〜95%圧縮するプロンプト圧縮ミドルウェア(Apache 2.0、Python約80%+Rust約15%)
・トークンコスト削減・レイテンシ短縮・RAG精度維持を同時に狙う。ライブラリ/プロキシ/MCPサーバ/wrap一発で既存スタックに後付けできる
・LLMLingua系の汎用枝刈りと違い、コンテンツ種別ごとの専用圧縮器+可逆圧縮(CCR)で構造化データに強い。2026年1月公開から半年で約5.5万★へ急伸

30秒でわかるheadroom(何ができるか)
headroomは、AIエージェントが読むものすべて——ツール出力・ログ・ファイル・RAGチャンク・会話履歴——を、LLMに届く前に圧縮するミドルウェアだ。要点を先に押さえる。
・headroomはLLM入力を「60〜95% fewer tokens, same answers」を掲げて圧縮するOSS(Apache 2.0、作者 chopratejas)
・狙いはトークンコスト削減・レイテンシ短縮・RAG精度維持の三立。入力を削るだけでなく原文をローカル保持して取り戻せる
・ライブラリ(compress())/HTTPプロキシ(コード変更ゼロ)/MCPサーバ/wrap一発の複数形態で導入できる
・JSON・コード・ログ・検索結果・散文を種別判定して別々の圧縮器に振り分けるのが設計の核
・GitHubは約55,800★・約4,000フォーク(2026年7月時点)、構成はPython約80%/Rust約15%/TypeScript約3%

商用API依存のコストとレイテンシに悩むエージェント/RAG運用者に直撃する内容だ。本記事は圧縮の仕組み・精度のトレードオフ・競合との違い・実運用での置き場所を、公式READMEとドキュメントのベンダー記載値を一次ソースとして整理する。数値はすべてベンダー記載であり、本記事の独自実測ではない点を先に断っておく。
なぜ今「LLM入力圧縮」なのか
LLM入力圧縮が2026年に注目を集める理由は3つに集約できる。これが「何を解決するのか」への答えだ。
・トークンコストの爆発:エージェントは1タスクで何十回もLLMを呼び、その都度ツール出力・ログ・ファイルを丸ごと文脈に積む。入力トークンは出力より桁違いに多くなりやすく、月額API料金の主因になる
・長文脈モデルでも残る実用レイテンシ:1Mトークン級の文脈窓があっても、毎リクエストで巨大な入力を処理すれば応答は遅くなり、KVキャッシュも崩れる。窓が広いことと安く速いことは別問題だ
・エージェント時代の入力肥大:MCPツール出力やログは「干し草の山の中の針(needle in haystack)」を生み、無関係トークンが推論精度まで下げる

この文脈で、入力を減らすこと自体がコスト・速度・精度の三方向に効く。トークンを盗まれて課金を破壊される攻撃面まで含めて「入力をどう扱うか」が運用設計の中心になりつつあり、防御の観点は トークン窃取を多層で止める——セッション・AI推論・課金まで含めた防御パターン で整理した。コンテキスト供給の枠組みとしては、Microsoftが Microsoft IQの4層を読み解く——Work/Web/Foundry/FabricとMCP・RAGの関係 で示した「単発RAGを多段・権限対応に進化させる」流れとも地続きだ。headroomはその供給パイプの「入口で削る」側を担う。
headroomの仕組み:コンテンツ種別判定と可逆圧縮(CCR)
headroomの中核は、コンテンツ種別を判定して最適な圧縮器に振り分ける ContentRouter と、その前後に置かれる CacheAligner・CCR だ。公式ドキュメントは、入力を受け取り→キャッシュ整列→種別判定→圧縮→原文記憶→送信という一連のパイプラインとして説明している。
ツール出力 / ログ / RAGチャンク
コード / 会話履歴"] --> B["CacheAligner
プレフィクス安定化
プロバイダKVキャッシュをヒットさせる"] B --> C["ContentRouter
コンテンツ種別を自動判定"] C --> D1["SmartCrusher
JSON / 配列 / ネスト"] C --> D2["CodeCompressor
AST認識 tree-sitter"] C --> D3["Kompress-v2-base
散文 HuggingFace学習済み"] C --> D4["LogCompressor
失敗・エラーを残し成功行を捨てる"] C --> D5["SearchCompressor
クエリ関連度でランキング"] D1 --> E["IntelligentContext
文脈上限超過時に重要度スコアリング"] D2 --> E D3 --> E D4 --> E D5 --> E E --> F["CCR
原文をローカル保持
headroom_retrieve で取り戻し可能"] F --> G["LLMへ送信
圧縮済み入力"]
各コンポーネントの役割を分解する。
・CacheAligner:メッセージのプレフィクスを安定化させ、Anthropic/OpenAI側のKVキャッシュが実際にヒットするようにする。圧縮で文頭が毎回変わるとキャッシュが無効化されるため、その逆を担保する層
・ContentRouter:入力のコンテンツ種別を検出し、最適な圧縮器へ振り分ける司令塔
・SmartCrusher:JSON(配列・ネスト・混在型)を統計的に解析し、エラーや異常値を保持したまま冗長部を畳む
・CodeCompressor:Python・JavaScript/TypeScript・Go・Rust・Java・C/C++・PerlをASTで認識し、構文構造を壊さずに圧縮
・Kompress-v2-base:散文をHuggingFace公開の学習済みモデルで圧縮(エージェント実行トレースで学習と記載)
・LogCompressor:ビルド/テストログから失敗・エラーを残し、成功(passing)出力を落とす
・SearchCompressor:検索結果をユーザクエリへの関連度でランキングして絞る
・IntelligentContext:文脈上限を超える場合にメッセージを重要度でスコアリングして取捨選択
・CCR(Compress-Cache-Retrieve):圧縮した原文をローカルに保存し、LLMには headroom_retrieve ツールを渡す。詳細が必要になればLLM自身がハッシュ指定で原文を取り戻せる「可逆圧縮」
この種別別ルーティングと可逆性が、単一アルゴリズムでプロンプト全体を枝刈りする方式との設計上の分岐点になる。圧縮し過ぎても原文に戻せるため、攻めた圧縮率を許容しやすい。
なぜ「種別ごとに別の圧縮器」なのかは、データ構造の違いを考えると腑に落ちる。JSONは木構造で、冗長なのはキーの繰り返しや配列要素の定型部分だから統計的に畳める。コードは構文木があるので、AST単位で意味を保ったまま空白やボイラープレートを落とせる。ログは時系列で大半が正常行、見たいのは例外だけだから「失敗を残す」フィルタが効く。これらを単一の自然言語圧縮器にかけると、構造を壊すか、構造を守って圧縮率が出ないかのどちらかになる。headroomが種別判定を最上流(ContentRouter)に置くのは、圧縮アルゴリズムの選択そのものが圧縮率と安全性を決めるからだ。
圧縮率と精度のトレードオフ
headroomが掲げる「60〜95%削減・same answers」は、実ワークロード別のベンダー記載値で裏付けられている。以下はすべて公式README/ドキュメント記載の数値で、独自実測ではない点に注意してほしい。
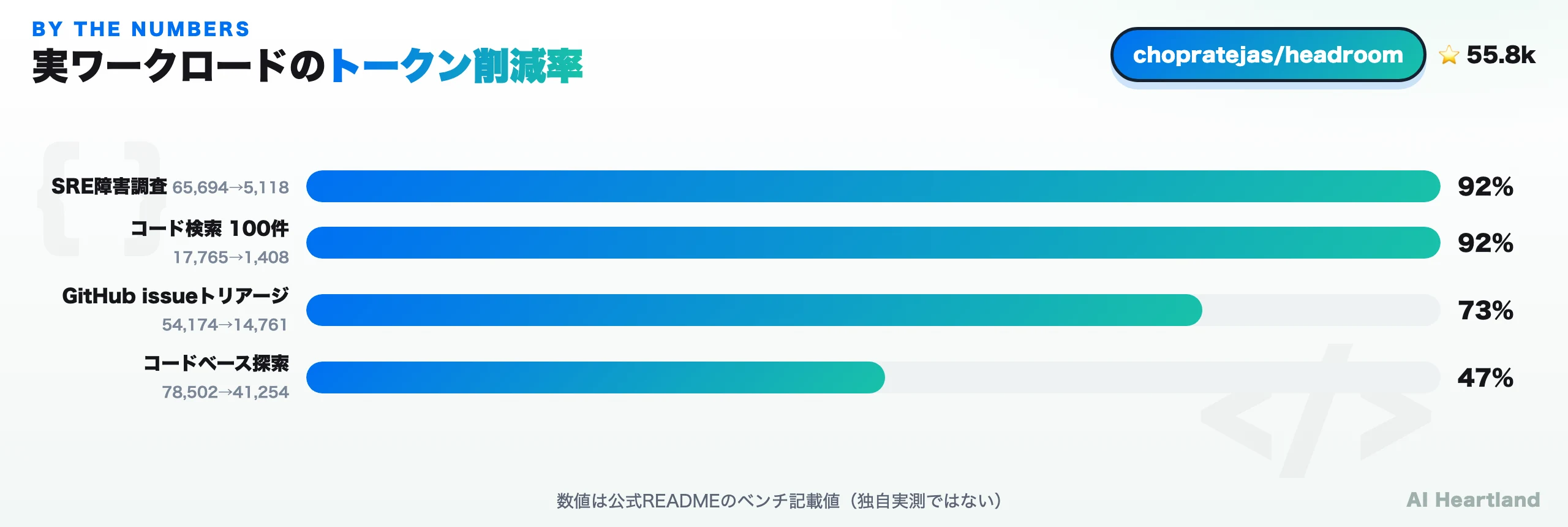
・コード検索(100件):17,765 → 1,408トークン(92%削減)
・SREインシデント調査:65,694 → 5,118トークン(92%削減)
・GitHub issueトリアージ:54,174 → 14,761トークン(73%削減)
・コードベース探索:78,502 → 41,254トークン(47%削減)
・ログ100件(67番目に致命的エラー):10,144 → 1,260トークン(約88%削減)、設問4/4を正答維持(冒頭のデモGIFがこのケース)
精度面では、圧縮を挟んでもベンチスコアが落ちないことを示している。次の表は公式READMEの Accuracy preserved セクションの記載値だ。
| ベンチ | カテゴリ | ベースライン | headroom適用 | 補足 |
|---|---|---|---|---|
| GSM8K | 数学 | 0.870 | 0.870 | ±0.000 |
| TruthfulQA | 事実性 | 0.530 | 0.560 | +0.030 |
| SQuAD v2 | QA | — | 97% | 19%圧縮時 |
| BFCL | ツール呼び出し | — | 97% | 32%圧縮時 |
重要なのは、圧縮率がデータの性質に強く依存する点だ。Hacker NewsのShow HNで作者は、繰り返しの多いサーバログは90%超、行が一意なコード差分(diff)は0%、密度の高い散文では約-0.3%(わずかなオーバーヘッド)と明言している。
公表ベンチの読み方にも注意がいる。GSM8K・TruthfulQA・SQuAD v2はいずれも英語の標準QA/推論タスクで、「圧縮しても正答が落ちない」ことは示せても、「あなたのドメイン固有の長文で重要な一文が消えない」ことまでは保証しない。特にTruthfulQAが0.530→0.560とわずかに上がっているのは、ノイズ除去で精度が上振れる現象(無関係トークンが減って干し草の山問題が緩和される)を示唆するが、これも英語・特定タスクの傾向だ。自社のゴールデンセットで「圧縮あり/なし」を並べて回帰確認するのが、ベンダー数値を鵜呑みにしない唯一の方法になる。
出力トークンまで削る新機能(Output token reduction)
ここまでは「LLMへ送る入力」の圧縮だが、READMEには出力トークン削減が新しく加わった。課金は入力だけでなくモデルが書き戻すトークンにも発生し、Opus級のモデルでは出力単価が入力の約5倍になる。その出力の多くは「では、〜しましょう」という前置き、直前に見せたコードの再掲、ファイルを読むだけの定型手番での過剰な「思考」に費やされる。ここを削るのが出力トークン削減だ。
・verbosity steering:システムプロンプトの末尾に「簡潔に、文脈を再掲しない」という短い指示を追記する。末尾に足すことでプロンプトキャッシュのヒットを崩さない
・effort routing:ツール結果(ファイル読み込みやテスト成功)を受けてモデルが再開するだけの手番では思考努力を下げ、新しい質問やエラー時にはフル努力を保つ
・正直な推定値で報告:出力削減は「本来なら何を書いていたか」が観測できない反実仮想なので、headroomは断定値を作らず信頼区間つきの推定値(例:Reduction 約31.7%、95%CI)で報告する。10%を非適用の対照群に回せば(HEADROOM_OUTPUT_HOLDOUT)実測値も得られる
有効化はプロキシから環境変数 HEADROOM_OUTPUT_SHAPER=1 を立てるだけで(既定はオフ)、コード変更は要らない。headroom learn --verbosity を使えば過去セッションから利用者に合った簡潔さのレベルを自動で学習させることもできる。入力圧縮とは独立に効くので、入力60〜95%削減の上にさらに出力側の削減が乗る構図になる。
LLMLinguaとの違いと競合比較
入力圧縮には複数の系統がある。LLMLingua系(Microsoft Research)はプロンプト文をトークン重要度で枝刈りする汎用手法、headroomはコンテンツ種別ごとの専用圧縮+可逆性に振った実装、という違いがある。これが読者の3問目「何を代替できるのか」への答えだ。アプローチ・対応データ・統合性で整理する。
| ツール | アプローチ | 主な対応データ | 可逆性 | 統合形態 | ライセンス |
|---|---|---|---|---|---|
| headroom | コンテンツ種別判定→専用圧縮器 | JSON・コード・ログ・検索・散文・画像 | あり(CCR) | ライブラリ/プロキシ/MCP/wrap | Apache 2.0 |
| LLMLingua | 小型LMの perplexity でトークン枝刈り | 主に自然言語プロンプト | なし | Pythonライブラリ | MIT |
| LLMLingua-2 | BERT級エンコーダのトークン分類(GPT-4蒸留) | タスク非依存の自然言語 | なし | Pythonライブラリ | MIT |
| SemanticCompression | 意味単位での要約的圧縮 | 自然言語中心 | なし | ライブラリ | 実装依存 |
| Self-Extend 等の文脈拡張 | 圧縮せず窓を広げる(逆方向) | 任意 | 該当なし | モデル側手法 | 実装依存 |
ベンダー記載ベースの傾向として、LLMLinguaは最大20倍(約95%)圧縮を達成する一方で対象は自然言語が主、LLMLingua-2は2〜5倍圧縮だがタスク非依存で3〜6倍高速・GPUメモリも約2.1GBと軽い、という特性がある。headroomの差別化は「JSON/ログ/コードのような構造化・半構造化データへの種別最適化」と「原文をローカルに残してLLMが取り戻せる可逆性」、さらに「出力トークン削減」まで含む点だ。散文の純粋な意味圧縮率だけを比べるならLLMLingua系の方が研究実績は厚い。用途で使い分けるのが現実的で、エージェントのツール出力圧縮ならheadroom、長文プロンプトの一括圧縮ならLLMLingua、という棲み分けになる。
ユースケース別の使い方(RAG・エージェント・ログ)
headroomはどの圧縮器がどのデータに効くかがはっきりしている。代表的なユースケースを「どの圧縮器が担うか」「典型的な削減レンジ」とセットで整理する。
| ユースケース | 主に効く圧縮器 | 典型削減 | 効く理由 |
|---|---|---|---|
| RAGチャンクの中段圧縮 | SearchCompressor | 中〜高 | 上位kの重複・定型句をクエリ関連度で絞る |
| エージェントのツール出力 | SmartCrusher | 高(73〜92%) | 巨大JSON・ls全結果の冗長部を畳む |
| 長文ログの前処理 | LogCompressor | 高(〜92%) | 成功行を捨て失敗・例外だけ残す |
| コードベース探索 | CodeCompressor | 中(47%前後) | ASTで構造を保ちつつ空白・定型を削る |
| 学習データの前処理 | 種別別+learn | データ依存 | 信号対雑音比を上げてから学習セットへ |
RAGパイプラインの中段に置く
検索で取ってきたチャンクは重複や定型句が多く、上位kを丸ごと積むとノイズになる。headroomの SearchCompressor をretrieverとLLMの間に挟み、クエリ関連度でランキング・圧縮してから渡す。RAGの精度を保ちつつ入力を削れるため、kを増やして再現率を上げても文脈予算が破綻しにくい。ツリー型RAGなど検索構造側の工夫とも併用でき、検索の作り込みは PageIndex|ベクトル不要のツリー推論RAG も参考になる。
エージェントのツール出力圧縮
エージェントの最大の水増し源はツール出力だ。lsの全結果、巨大なJSONレスポンス、MCPツールの戻り値が毎ターン文脈に積まれる。プロキシかMCPサーバ形態で挟めば、SmartCrusher がJSONの冗長部を畳み、エラーや異常値だけ残す。コード変更ゼロで効くため、Claude Code・Codex・Cursor・Aider・Copilot CLI といった既存エージェントにそのまま被せられる。
長文ログの要約前処理
ビルドログ・テストログ・SREのインシデントログは、成功行が大半で本当に見たいのは失敗箇所だけ、という構造をしている。LogCompressor は passing 出力を落として failures/errors を残すため、65,694→5,118トークン(92%)のような圧縮を実現する。要約LLMに渡す前段の前処理として置けば、要約自体のコストと取りこぼしを同時に減らせる。
3つの導入形態と headroom wrap
導入はライブラリ/プロキシ/MCPの3形態、加えて既存エージェントに一発で被せる headroom wrap から選ぶ。同じ圧縮エンジンを別の入口で使う形で、改修コストと制御の細かさがトレードオフになる。

・`headroom learn`:失敗したセッションを採掘し、修正内容を `CLAUDE.local.md`(既定・gitignore対象)や `CLAUDE.md` / `AGENTS.md` / `GEMINI.md` に書き戻す。エージェントが同じミスを繰り返さないよう、運用ループの中で指示文脈を更新していく発想
・local-first:これらのストアも含めてデータは利用者のマシン上に置かれる。原文・メモリを外部に出さずに圧縮と学習を完結できる つまりheadroomは「1リクエストの入力圧縮器」であると同時に、「複数エージェント・複数セッションをまたいだ文脈管理レイヤ」としての顔も持つ。トークン最適化を単発の圧縮で終わらせず、メモリ階層化まで含めて設計したいなら、この継続学習・共有メモリの側面が効いてくる。トークン最適化全体の中での位置づけは [AIエージェントのトークン最適化ガイド](/explain/ai-agent-token-optimization-guide-2026/) の分類軸(圧縮/グラフ化/メモリ階層化)に照らすと整理しやすい。 ## コスト試算:圧縮率がそのまま月額削減率 圧縮効果を金額に落とすと効き目が直感的になる。ここでは入力単価を仮に$3.00/百万トークンと置き、エージェントが1日10万リクエスト・平均入力2万トークンを処理する運用を想定する(単価・規模はあくまで試算用の仮定値)。 | 圧縮率 | 1リクエスト入力 | 月間入力トークン | 月額入力コスト($3/1M仮定) | 削減額 | |---|---|---|---|---| | 0%(圧縮なし) | 20,000 | 60,000M | $180,000 | — | | 47%(コードベース探索級) | 10,600 | 31,800M | $95,400 | -$84,600 | | 73%(issueトリアージ級) | 5,400 | 16,200M | $48,600 | -$131,400 | | 92%(ログ/検索級) | 1,600 | 4,800M | $14,400 | -$165,600 | 削減率はモデルや通貨単価に依存しないため、GPT-5.5・Claude・Gemini いずれの料金体系でも「入力トークンを何%削れるか」がそのまま月額削減率になる。出力トークンは従来は圧縮対象外だったが、前述の出力トークン削減(`HEADROOM_OUTPUT_SHAPER`)を有効化すれば出力側にも削減が乗る。実額はベンダー単価と自分のワークロードの圧縮率で再計算してほしい。

・構造化データのスキーマ破壊:SmartCrusherはJSON構造を保つ設計だが、後段で厳密なスキーマ検証をするパイプラインでは、圧縮後の形がバリデーションを通るか確認する。圧縮はLLM入力用と割り切り、機械処理に渡すデータは原文を使う
・ストリーミング応答との相性:入力圧縮は出力ストリームの書き換えではない(出力削減は別機構)。プロキシ経由でSSEが透過するか、自分のスタックで挙動確認する
・LLM側キャッシュの無効化:圧縮で文頭が毎回変わるとプロバイダのプロンプトキャッシュが効かなくなる。headroomは CacheAligner でこれを防ぐ設計だが、自前で前後に文字列を足すとキャッシュ境界がずれる。キャッシュ前提の運用ではヒット率を計測する これらはいずれも「圧縮を入力前処理に限定し、原文を残し、効果を実測する」という原則で回避できる。万能圧縮として無条件に挟むのではなく、効くデータに狙って当てるのが安全だ。 ## headroomを評価すべきチーム
- エージェント/RAGでツール出力・ログ・検索結果が文脈を水増しし、月額API入力コストが膨らんでいるチーム
- コード変更を最小化したい(wrap/プロキシ/MCPで後付けしたい)運用
- 圧縮はしたいが原文の取りこぼしリスクを許容できず、可逆性(CCR)が欲しい場合
- 入力だけでなく出力トークンのコストも削りたいチーム
- ローカル完結で原文を外部に出さずに圧縮したいオンプレ志向
- 入力が密度の高いユニークな散文中心で、圧縮が効きにくい(むしろオーバーヘッド)用途
- 日本語中心で精度要件が厳しく、英語ベンチしか公表がない現状で十分な事前検証ができない場合
- 出力トークン比率が高く、入力削減の総額インパクトが小さいワークロード(出力削減は別途要検討)