この記事ではVoxCPM2というOSSのTTSモデルに特化して解説します。LLM全般の仕組み・主要モデル比較・ローカル実行・量子化は LLMとは?仕組み・主要モデル比較・ローカル実行・量子化を一気にまとめる2026年版 をご覧ください。
- VoxCPM2はOpenBMBが公開したトークナイザレスの多言語TTS。Apache-2.0・約25,576★で、日本語を含む30言語に対応し48kHzのスタジオ品質音声を出力する
- テキスト記述から声を作る音色設計(Voice Design)と、数秒の音声から声を複製するゼロショットボイスクローニングを1モデルで両立。ローカル/オンプレで動かせる
- 本記事では設計(LocEnc→TSLM→RALM→LocDiT)・日本語性能・VRAM要件・実行手順・倫理ガイドラインまで、一次ソースで整理する
30秒で理解するVoxCPM2
まず要点を押さえる。VoxCPM2は「音素やトークナイザに頼らず、テキストから連続的な音響表現を直接生成する」TTSモデルだ。
・VoxCPM2:OpenBMBによるトークナイザレス多言語TTS、Apache-2.0、約25,576★(fork約2,900)
・約2Bパラメータ、200万時間超の多言語音声で学習。日本語含む30言語、48kHz出力
・テキスト記述からの音色設計(Voice Design)とゼロショットボイスクローニングを両立
・ローカル/オンプレ運用可能。VRAM約8GBで動き、pip install voxcpm で導入
・Coqui XTTS / Bark / OpenVoice2 と比べた強みは「商用可ライセンス×30言語×音色設計」の組合せ
商用APIに依存せず、声を「作る」「複製する」両方を自前で回したい開発者には直撃する内容だ。一方でボイスクローニングは法的・倫理的なグレーゾーンを含むため、技術仕様と並べて注意点も最初から押さえておく。
なぜ「トークナイザレス」が話題なのか
従来のTTSは、テキストをまず音素(phoneme)や離散トークンに変換し、それを音響特徴へマッピングする多段パイプラインが主流だった。この設計には構造的な弱点がある。
第一に言語依存だ。音素の体系は言語ごとに大きく異なり、言語が増えるたびに音素辞書と対応モデルを用意する必要がある。VoxCPMの技術文書も「トークナイザベースの手法は言語固有の音素セットを要求し、シームレスなクロスリンガル合成の障壁になる」と指摘している。第二に情報の損失だ。連続的な音響情報を限られた語彙の離散トークンに押し込む量子化の過程で、細かなニュアンスが失われやすい。
トークナイザレス設計は、この2点を回避する。テキストから離散トークンを経由せず連続的な音響表現を直接扱うため、言語固有の変換ステップが要らず、多言語を1モデルで統一的に処理できる。コードスイッチング(言語混在)やクロスリンガルな声の転写も自然になる。日本語のように音素体系が英語と大きく異なる言語ほど、この恩恵は効きやすい。
ローカルでLLMやTTSを動かす環境構築全般は ローカルLLMとは?2026年版ツール比較——Ollama・Lemonade・LM Studio・GPT4Allの選び方 も併せて参照すると、GPU選定や量子化の勘所がつかめる。
多くのTTSは grapheme-to-phoneme(G2P)で文字列を音素列に変換してから合成する。VoxCPM2はこのG2P段も離散トークン段も置かず、テキストから連続音響表現へ直接進む。だから言語ごとのG2P辞書を整備する必要がなく、辞書未整備の言語や固有名詞・新語にも崩れにくい。
VoxCPM2の設計
VoxCPM2は Diffusion自己回帰(diffusion autoregressive)パラダイム を採用し、AudioVAE V2の潜在空間の中で動作する。公式アーキ図に沿うと、処理は LocEnc → Text-Semantic Language Model(TSLM) → Residual Acoustic Language Model(RALM) → LocDiT という流れだ。
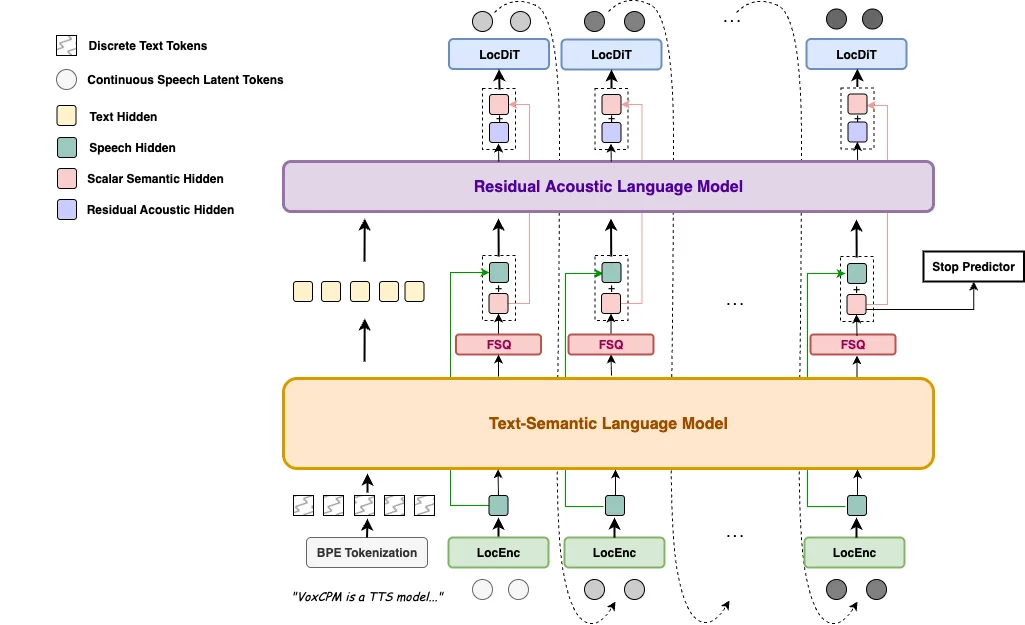
従来TTSの「Text → Tokens → Phonemes → Acoustic」という離散経路に対し、VoxCPM2は「Text → 連続音響表現 → ボコーダ → 波形」を一気通貫で結ぶ。これを図にすると対比が分かりやすい。
言語ごとの音素辞書"] A2 --> A3["離散トークン列"] A3 --> A4["音響モデル"] A4 --> A5["波形"] end subgraph VOX["VoxCPM2:トークナイザレス"] B1["テキスト"] --> B2["LocEnc
局所表現を符号化"] B2 --> B3["TSLM
テキストと意味を統合"] B3 --> B4["RALM + LocDiT
連続音響潜在を直接生成"] B4 --> B5["AudioVAE V2 デコード
48kHz波形"] end
AudioVAE V2は 16kHz入力 → 48kHz出力の非対称エンコード/デコード を担い、入力は軽く扱いつつ出力はスタジオ品質に引き上げる。音響潜在のトークンレートは6.25Hzと低く、長文でも系列が伸びすぎないよう設計されている。Diffusionが高品質な音響モデリングを、自己回帰が長い発話の系列的一貫性を担い、両者を組み合わせることで自然さと長文安定性を両立する狙いだ。
この設計が日本語に効く理由をもう一段掘り下げる。漢字かな交じり文は、同じ文字列でも文脈で読みが変わる(「行った」=いった/おこなった等)。音素辞書ベースのTTSはG2Pの段で読みを確定させてしまうため、辞書が文脈を読み違えると音声も間違う。VoxCPM2はテキストの意味表現をTSLMでそのまま音響側に渡すため、文脈に応じた読み・抑揚を連続表現の中で吸収しやすい。多言語混在(日本語の中に英単語が混じる文)でも、言語ごとに辞書を切り替えずに済むのは大きい。
生成を制御する2つの主要パラメータも押さえておきたい。cfg_value(Classifier-Free Guidance)は記述や参照音声への忠実度を調整するつまみで、値を上げるほど指定に強く従うが上げすぎると不自然になる。公式例の 2.0 が標準的な出発点だ。inference_timesteps はDiffusionの反復回数で、増やすほど品質は上がるが生成は遅くなる。公式例の 10 は品質と速度のバランス点で、リアルタイム寄りなら減らし、収録品質を狙うなら増やす、という調整軸になる。
RALMはResidual Acoustic Language Model(残差音響言語モデル)の略で、参照音声専用モジュールではない。TSLMが出した意味・韻律の土台に対し、RALMが音響的な残差(細部)を予測する役割を担う。アーキ図のFSQ(有限スカラー量子化)とStop Predictorが、潜在の安定化と発話終端の判定を受け持つ。
音色設計(Creative Voice Design)
VoxCPM2の特徴的な機能が、参照音声なしで声を作れる 音色設計だ。性別・年齢・トーン・速度・感情といった声質を、自然言語の括弧記述でテキスト先頭に与えるだけでよい。
・声質パラメータ:性別・年齢・トーン(gentle / cheerful 等)・速度・感情を記述で指定
・参照音声不要:実在の誰かの声を使わずにオリジナルの声を合成・編集できる
・記述を変えるだけで声の方向性を即座に振れる
最小コードは次の通り。(...) の中に声の人物像を書き、続けて読ませたい本文を置く。
from voxcpm import VoxCPM
import soundfile as sf
model = VoxCPM.from_pretrained("openbmb/VoxCPM2", load_denoiser=False)
# 音色設計:参照音声なしで声を作る
wav = model.generate(
text="(A young woman, gentle and sweet voice)こんにちは、VoxCPM2へようこそ。",
cfg_value=2.0,
inference_timesteps=10,
)
sf.write("design.wav", wav, model.tts_model.sample_rate)
CLIからも同等のことができる。
voxcpm design --text "(A calm male narrator)本日のニュースをお伝えします。" --output design.wav
実在の声を使わずに済むため、権利処理の観点では音色設計のほうがボイスクローニングより安全側だ。ナレーションやキャラクターボイスの量産には、まず音色設計から入るのが扱いやすい。
ゼロショットボイスクローニング
参照音声を与えれば、その声質をゼロショットで転写できる。VoxCPM2のクローニングは粒度の異なる2モードを持つ。
・Controllable Voice Cloning:参照音声+スタイル記述で、音色は保ちつつ感情・速度・抑揚を調整
・Ultimate Cloning:参照音声+その書き起こしテキストを与え、音色・リズム・感情・スタイルを忠実に継続
・必要なリファレンス尺は数秒程度。さらに精度を上げたければLoRAで5〜10分の音声から適応
# Controllable Voice Cloning:音色を保ちつつスタイルを制御
wav = model.generate(
text="(slightly faster, cheerful tone)スタイル制御つきでクローンしています。",
reference_wav_path="path/to/voice.wav",
cfg_value=2.0,
)
# Ultimate Cloning:参照音声+書き起こしで最大忠実度
wav = model.generate(
text="ここから続きのテキストを同じ声で読み上げます。",
prompt_wav_path="path/to/voice.wav",
prompt_text="参照音声の書き起こしテキスト。",
reference_wav_path="path/to/voice.wav",
)
OpenBMBの利用規約は、なりすまし・詐欺・偽情報への利用を明確に禁止している(後述「倫理と安全性」)。クローニングは技術的には数秒で成立するからこそ、誰の声を、どの同意のもとで使うかの管理が前提になる。
多言語性能
VoxCPM2は30言語に対応するが、言語ごとに品質差はある。代表的なベンチ数値を出典つきで並べる。いずれも自然性そのものではなく、ASRで読み取った誤り率(WER/CER)と話者類似度(SIM)が中心である点に注意してほしい。
| ベンチ | 指標 | スコア | 出典 |
|---|---|---|---|
| Seed-TTS-eval(英語) | WER / SIM | 1.84% / 75.3% | OpenBMB公式README |
| Seed-TTS-eval(中国語) | CER / SIM | 0.97% / 79.5% | OpenBMB公式README |
| CV3-eval(日本語) | CER | 約5.96% | OpenBMB公式README |
| 内部30言語ASRベンチ | 平均誤り率 | 1.68% | OpenBMB公式README |
英語・中国語は誤り率1%前後と高精度だが、日本語のCERは約5.96% と相対的に高めだ。これは「日本語が苦手」というより、漢字かな交じり・固有名詞・読み分けの難しさが効いている。実用品質には達しているが、ナレーション本番で使うなら、クリーンな日本語音声でLoRA適応して読み精度を底上げするのが現実的な打ち手になる。
30言語平均で誤り率1.68%という内部ベンチの数字は、言語間のばらつきを均した値だ。実務では「自分が使う言語の単体スコア」を見るべきで、平均値に引っ張られて日本語を過大評価しないことが大事になる。CV3-evalは11言語をまたぐ多言語ASR評価で、Seed-TTS-evalが英語・中国語に絞った定番ベンチであるのに対し、より多言語の地力を測る位置づけだ。日本語のCER 5.96%はこのCV3-eval上の値で、英語・中国語の「専用ベンチでの最高値」と直接横並びにはできない点も、数字を読むときの注意点になる。
なお、これらはあくまで「読みの正確さ」の指標であって、声の温かみやイントネーションの自然さといった主観品質は別軸だ。VoxCPM2の音色設計やUltimate Cloningは、この主観品質を参照音声や記述で底上げする仕組みなので、ベンチのCER/WERが多少高くても、良質な参照音声を与えれば体感品質は大きく改善する。最終判断は必ず自分の台本での試聴で行うのが鉄則だ。
ここで挙げた数値はすべてOpenBMB公式READMEに掲載された自己申告値で、第三者の独立再現ではない。WER/CERは「読み間違いの少なさ」を測る指標で、人間が感じる自然性(MOS)とは別物だ。日本語の自然性を最終判断するなら、自分のユースケースの台本で実際に合成して耳で確認するのが確実だ。
ローカル実行手順
導入は軽い。GPU環境さえ整っていれば数分で動く。
・推奨ハード:VRAM約8GBで動作(VoxCPM2 2B)。RTX 4090クラスで快適
・前提:Python ≥ 3.10(<3.13)、PyTorch ≥ 2.5.0、CUDA ≥ 12.0
・レイテンシ:RTX 4090でRTF約0.3(素の推論)、Nano-vLLM併用で約0.13まで短縮
・CPU推論は想定外。リアルタイム会話を狙うならGPU+推論最適化が前提
インストールと最小実行は次の3ステップだ。
# 1. インストール
pip install voxcpm
# 2. 推論(音色設計)
from voxcpm import VoxCPM
import soundfile as sf
model = VoxCPM.from_pretrained("openbmb/VoxCPM2", load_denoiser=False)
wav = model.generate(
text="VoxCPM2をローカルで動かしています。",
cfg_value=2.0,
inference_timesteps=10,
)
sf.write("demo.wav", wav, model.tts_model.sample_rate)
# 3. 低レイテンシ/本番運用(OpenAI互換エンドポイント)
# vLLM-Omni 経由で /v1/audio/speech を立て、API経由で配信
# Nano-vLLM-VoxCPM は RTX 4090 で RTF~0.13・並行リクエスト対応
RTF(Real-Time Factor)は「1秒の音声を作るのに何秒かかるか」の指標で、0.13なら1秒の音声を約0.13秒で生成できる=リアルタイム会話の射程に入る。バッチ生成中心ならRTF 0.3でも実用上の問題は小さい。スループットが要る本番は、vLLM-Omni(PagedAttention+KVキャッシュ、OpenAI互換 /v1/audio/speech)かNano-vLLM-VoxCPMを噛ませて並列化する。
本番デプロイの選び方を整理すると、用途で2つに分かれる。既存のOpenAI TTS APIから乗り換えたいなら、vLLM-Omniが /v1/audio/speech 互換エンドポイントを提供するので、クライアント側のコードをほぼ変えずに差し替えられる。スループットとレイテンシを極限まで詰めたいなら、Nano-vLLM-VoxCPMがRTX 4090でRTF約0.13・並行リクエスト対応と、推論最適化に振った構成になる。このほかComfyUIノード経由でのGUIワークフロー、ONNXエクスポートでのランタイム移植も用意されており、組み込み先に応じて選べる。
導入時の典型的なつまずきは、CUDAバージョンの不一致とVRAM不足だ。CUDA ≥ 12.0・PyTorch ≥ 2.5.0という前提を満たさないと from_pretrained の段で落ちる。VRAMは約8GBが目安だが、長文を一度に流すと一時的にメモリが膨らむため、余裕を見て12GB以上のGPUだと安定する。load_denoiser=False はデノイザを読み込まない軽量設定で、参照音声がクリーンなら有効化不要でメモリを節約できる。
ローカルLLMをコマンドラインで回す運用は Ollama × Codex CLIでローカルLLMをエージェント化する も参考になる。TTSとLLMを同じGPUに同居させる構成を検討するときのVRAM配分の感覚がつかめる。
競合との比較表
主要なオープンソースTTSと並べると、VoxCPM2の立ち位置がはっきりする。クローニング品質・言語数・ライセンスの3点が選定の軸になる。
| モデル | 対応言語 | クローニング | ライセンス | 特徴 |
|---|---|---|---|---|
| VoxCPM2 | 30言語(日本語含む) | ゼロショット+音色設計 | Apache-2.0(商用可) | トークナイザレス・48kHz・音色設計を両立 |
| Coqui XTTS v2 | 17言語 | ゼロショット(6秒参照) | CPML(商用制限) | 枯れた実績だが開発元解散・未メンテ |
| Bark | 多言語(実験的) | プリセット話者中心 | MIT | 笑い声・効果音など非言語音に強い |
| OpenVoice v2 | 主要言語 | ゼロショット・軽量 | MIT | 低レイテンシ・高速プロトタイピング向け |
| Tortoise TTS | 英語中心 | ゼロショット | Apache-2.0 | 高品質だが推論が非常に遅い |
XTTS v2はゼロショットクローンの定番だが、ライセンス(CPML)が商用利用を制限し、開発元Coquiが2024年に解散して以降は実質メンテされていない。Barkは効果音込みの創作音声、OpenVoice v2は軽量・高速、Tortoiseは高品質だが遅い、と各々得意領域が違う。「商用可ライセンス × 30言語 × 音色設計+クローニング」を1モデルで満たす のがVoxCPM2の差別化点だ。
ユースケース
多言語ナレーション
1つのモデルで30言語を扱えるため、製品紹介や研修動画を多言語展開するワークフローに向く。音色設計で統一したブランドボイスを作り、各言語で同じ声色のナレーションを量産できる。
Podcast自動生成
記事や台本を流し込んで音声化するパイプラインに組み込める。話者ごとに参照音声を切り替えれば対談形式も作れる。バッチ処理(voxcpm batch)で大量エピソードをまとめて生成する運用が現実的だ。
アクセシビリティ補助
視覚障害者向けの読み上げや、長文ドキュメントの音声化に使える。48kHz出力で長時間でも聴き疲れしにくい。オンプレで完結するため、社内文書を外部APIに出さずに音声化できるのも利点だ。
教育コンテンツ作成
語学教材で複数言語のネイティブ風音声を用意したり、教材ナレーションを声色を変えて作り分けたりできる。LoRA適応で講師の声に寄せた読み上げを作ることも可能だ。
倫理と安全性
ボイスクローニングは強力ゆえにリスクも大きい。OpenBMBの利用規約と一般的な配慮を整理する。
・ディープフェイク懸念:実在の声を無断複製すれば、なりすまし・詐欺・偽情報に悪用されうる。OpenBMBは「なりすまし・詐欺・偽情報への利用を固く禁じる」と明記している
・同意と検証:他者の声をクローンする場合は本人の明示的同意が前提。商用なら録音時の利用許諾範囲も確認する
・透かし・検知:AI生成音声であることを明示するよう強く推奨されている。配信時はメタデータや音声透かしで「合成音声」と分かる設計にする
Apache-2.0はソフトウェアの利用を許諾するライセンスであって、「他人の声を合成してよい」と保証するものではない。肖像権・パブリシティ権・各国の音声合成規制は別レイヤーで効く。声の権利処理はライセンスとは独立に必要だと理解しておく。
よくある落とし穴
実運用で詰まりやすいポイントを先回りで挙げる。
・「日本語ネイティブ」品質の期待値:日本語CERは約5.96%で英語・中国語より高め。固有名詞や読み分けはミスが出る前提で、本番台本は事前合成して耳でチェックする
・ボイスクローニングの法的グレーゾーン:技術的に数秒で複製できても、無断クローンは権利侵害になりうる。同意取得を運用フローに組み込む
・リアルタイムストリームのレイテンシ:素のRTFは約0.3。会話用途で本当にリアルタイムが要るなら、Nano-vLLMやvLLM-Omniでの最適化が必須
・GPU/CPU推論のスピード差:CPU推論は想定されていない。VRAM約8GBのGPUを前提に環境を組む
権利・倫理のリスクを避けたいなら、最初はクローニングではなく音色設計で必要な声を作るのが安全だ。オリジナルの声で要件を満たせるなら、実在話者の同意取得や権利処理を回避できる。クローンは「どうしてもその人の声が必要」な場合に限定するのが、運用上もトラブルが少ない。
まとめ
VoxCPM2は、トークナイザレス設計で多言語の壁を越え、音色設計とゼロショットクローニングを1モデルで両立したオープンウェイトTTSだ。Apache-2.0で商用可、VRAM約8GBでローカル運用でき、30言語に対応する。日本語は英語・中国語より誤り率が高めだが、LoRA適応と参照音声の質で実用域に持ち込める。声を「作る」「複製する」両方を自前で回したい開発者にとって、現時点で有力な選択肢の一つだ。クローニングの法的・倫理的配慮を運用に組み込めるかが、本番投入の分かれ目になる。
参照ソース
・OpenBMB/VoxCPM 公式リポジトリ(README・アーキ図・コード例・ベンチ数値・利用規約)— https://github.com/OpenBMB/VoxCPM
・openbmb/VoxCPM2 Hugging Faceモデルカード(対応言語・学習データ・ライセンス)— https://huggingface.co/openbmb/VoxCPM2
・VoxCPM技術論文 “Tokenizer-Free TTS for Context-Aware Speech Generation and True-to-Life Voice Cloning”(arXiv:2509.24650、トークナイザレス設計の動機)— https://arxiv.org/abs/2509.24650