
この記事ではLLMに特化して解説します。LLM全般は LLMとは?仕組みからローカル実行まで徹底解説【2026年完全ガイド】 をご覧ください。
何が起きたか
PrismMLが1ビット重み学習技術を用いた商用LLMシリーズ「1-bit Bonsai」を発表した。8Bパラメータモデルが1.15GBのメモリで動作し、フル精度モデルと比較してメモリフットプリントを14分の1に削減しながら推論速度を8倍、エネルギー消費を5分の1に抑える。大規模言語モデルのエッジ展開に向けた商用化の重要な一歩となる。
LLM Bonsai — 1-bit圧縮LLMとしての実装と比較
「llm bonsai」で情報を探している読者が最初に知りたいのは、「Bonsaiはどのタイプの軽量LLMで、既存の量子化モデルと何が違うのか」という点だろう。Bonsaiは PrismML が商用化した初の1ビット重みLLMシリーズで、推論時に重みを -1 / +1 の二値のみで表現する。8Bパラメータのモデルが約1.15GBのメモリで動作する点が特徴で、FP32比でサイズ1/14・推論速度8倍・エネルギー消費1/5を実現する。
既存の量子化LLMと比較すると、Bonsaiの位置づけが明確になる。
| モデル・手法 | ビット数 | 8Bクラスのメモリ | 量子化方式 | ライセンス |
|---|---|---|---|---|
| Llama 3.1 8B(FP32) | 32ビット | 約32GB | 訓練後そのまま | Llama License |
| Llama 3.1 8B(INT8) | 8ビット | 約8GB | 訓練後量子化(PTQ) | Llama License |
| Llama 3.1 8B(Q4_K_M) | 4ビット | 約4.8GB | GGUFベース(PTQ) | Llama License |
| BitNet b1.58 | 1.58ビット | 研究段階 | 量子化対応訓練(QAT) | Microsoft Research |
| 1-bit Bonsai 8B | 1ビット | 約1.15GB | QAT + 商用最適化 | Apache 2.0 |
Bonsaiの実装面で押さえておきたいのは以下の3点。
- 訓練段階から1ビット前提で学習する(QAT)。GPTQやAWQのような事後量子化と違い、モデルが1ビット表現で動くことを前提に重みが最適化される。
- 推論エンジンは PrismML がフォークした 専用llama.cpp を使用する。標準のllama.cppでは1-bitカーネル(XNOR演算)に対応していないため、Bonsai専用ビルドが必要。
- マルチプラットフォーム対応。CUDA、Metal(Mac)、Swift(iPhone/iPad)、Androidに対応し、HuggingFaceの
prism-ml組織配下にGGUF版とMLX版が公開されている(prism-ml/Bonsai-8B-gguf/prism-ml/Bonsai-8B-mlx-1bitなど)。
ベンチマークの公表値では、Bonsai 8BがMMLU 62.4・HumanEval 68.9・HellaSwag 72.1・ARC-C 53.8 を記録し、Llama 3.1 8B比で約90%の精度を維持しているとされる。数値の独立検証はこれからだが、商用化された1ビットLLMとしては初の実用ラインに到達したと評価できる。
1ビット量子化が生まれた背景
大規模言語モデルは急速に進化する一方、メモリ要件とエネルギー消費が致命的な課題となっていた。GPT-4クラスのモデルを単一GPU上でフル精度運用しようとすれば、数百GBのVRAMが必要になる。スマートフォンやロボット、IoTデバイスへの展開は現実的ではなかった。
この課題へのアプローチとして、モデルの重みを低ビット数で表現する「量子化」が研究されてきた。一般的なINT4(4ビット)量子化でもメモリを大幅に削減できるが、1ビット量子化はその極限に位置する。各パラメータを -1 または +1 の二値のみで表現する。計算はXNOR演算(排他的論理和の否定)に置き換えられ、従来の浮動小数点乗算より大幅に高速かつ省電力で処理できる。
PrismMLは「1.58ビット」({-1, 0, +1}の三値)を含む研究成果をベースに、商用展開に耐える精度バランスを達成したと主張している。ベンチマークテストでは、同サイズのフル精度モデルとほぼ同等の精度を維持しながら、上記の効率化を実現したとされる。
1ビット量子化の技術的な仕組み
フル精度との数値比較
| 特性 | FP32(フル精度) | INT8 | INT4 | 1ビット(Bonsai) |
|---|---|---|---|---|
| ビット数/パラメータ | 32ビット | 8ビット | 4ビット | 1〜1.58ビット |
| 8Bモデルのメモリ | 約32GB | 約8GB | 約4GB | 約1.15GB |
| 演算種別 | 浮動小数点乗算 | 整数乗算 | 整数乗算 | XNOR演算 |
| 相対速度(8B推論) | 1× | 約2× | 約4× | 約8× |
| 相対消費電力 | 1× | 約0.4× | 約0.3× | 約0.2× |
8Bモデルが1.15GBで動作するという数値は、スマートフォンや組み込みデバイスへの搭載を現実的な選択肢に引き上げる。iPhone 15 Proは8GB RAMを搭載しており、理論上は同端末でBonsaiクラスのモデルを7つ同時起動できる計算になる。
XNOR演算による高速化の原理
通常のニューラルネットワーク推論では、重みと活性化値の積和演算(行列積)がボトルネックとなる。FP32での乗算はCPUの浮動小数点演算ユニット(FPU)を使用し、レイテンシが高い。
1ビット量子化ではこれをビット演算に置き換える。重みが +1 か -1 のみのため、乗算は符号の判定だけで済む。XNOR演算とpopcount(ビット列の1の個数カウント)を組み合わせることで、積和演算をビットレベルで並列処理できる。
# 概念的な実装例:1ビット行列積(NumPyによるデモ)
import numpy as np
def binary_matmul(W_bin, x_bin):
"""
W_bin: 重み行列(-1/+1の二値)
x_bin: 入力ベクトル(-1/+1の二値)
XNOR演算 + popcountによる近似実装
"""
# +1 → True, -1 → False に変換
W_bool = (W_bin > 0).astype(np.uint8)
x_bool = (x_bin > 0).astype(np.uint8)
# XNOR演算(同符号なら1、異符号なら0)
xnor = 1 - np.bitwise_xor(W_bool, x_bool.T)
# ポップカウントで積和を近似
popcount = xnor.sum(axis=-1)
# スケール調整(-n〜+nの範囲に変換)
n = x_bin.shape[-1]
return 2 * popcount - n
# 8Bパラメータの実際の実装では専用カーネル(CUDA/Metal)を使用
実際の推論エンジン(llama.cpp等)では、このロジックをCUDA/Metal/CPUのSIMD命令で実装し、さらに高速化している。
メモリ配置と推論パイプライン
# llama.cpp で1ビット量子化モデルを動かす基本コマンド(将来的な対応想定)
# 現時点でのBonsaiモデルは公式ダウンロードリンクが必要
# 一般的な量子化モデルの起動例(参考)
./llama-cli \
--model ./bonsai-8b-1bit.gguf \
--ctx-size 4096 \
--threads 8 \
--n-predict 256 \
-p "日本のAI技術トレンドを教えてください"
# Pythonからtransformersで量子化モデルを使う場合の参考(bitsandbytes)
pip install bitsandbytes transformers accelerate
# 4ビット量子化の実装例(BitsAndBytesConfig)
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3-8B",
quantization_config=bnb_config,
device_map="auto"
)
# 1ビットBonsaiが公式SDKを提供した場合も同様のAPIになると想定される
量子化技術の全体像と1ビットの位置づけ
Post-Training Quantization"] A --> C["量子化対応訓練
Quantization-Aware Training"] B --> D["GPTQ
INT4相当"] B --> E["AWQ
INT4相当"] B --> F["GGUF/llama.cpp
2〜8ビット"] C --> G["BitNet b1.58
1.58ビット三値"] C --> H["1-bit Bonsai
商用初の1ビット"] G -->|"精度維持のため
事前訓練から1ビット"| H style H fill:#ff9900,color:#000 style G fill:#ffd700,color:#000
1ビット量子化が他の手法と根本的に異なる点は、訓練段階から1ビット表現を前提とする点にある。GPTQやAWQは訓練済みのFP32モデルを事後的に量子化するため、精度劣化が避けられない。BitNetやBonsaiは最初から制約を設けて訓練するため、モデルが1ビット表現を「学習」できる。
業界への影響と応用領域
エッジAIの現実化
1.15GBのメモリフットプリントは、単なる技術的な数値ではない。以下のデバイスでのローカル推論が現実的になる。
- スマートフォン(RAM 6〜12GB):オンデバイスで複数モデルを並列実行
- Raspberry Pi 5(RAM 8GB):DIYロボットやスマートホームデバイス
- マイクロコントローラ(将来的な小型モデル):産業用センサー
プライバシー面での優位性も大きい。会話データをクラウドに送信せずローカルで処理できるため、医療・法務・金融分野での活用障壁が下がる。
リアルタイムエージェントへの応用
Browser Useのようなエージェントフレームワークでは、LLMの推論速度がボトルネックになる。8倍の高速化はエージェントのレスポンス時間を劇的に短縮し、ユーザー体験を向上させる。また、OpenHandsのようなAIコーディングエージェントがローカルLLMを活用できれば、APIコストゼロでの自律開発環境が構築できる。
ロボティクスと組み込みシステム
ロボットの制御ループはミリ秒単位の応答が求められる。クラウドAPIへのラウンドトリップ(往復100〜500ms)は致命的なレイテンシとなる。1-bit Bonsaiクラスのモデルがオンデバイス動作することで、ネットワーク遅延に依存しない真のリアルタイムAI制御が実現する。
量子化レベルの実際の確認方法
既存の量子化ツールで現時点での1ビット近似モデルを試す場合、llama.cppのQ2_K量子化(最低精度寄り)が参考になる。Bonsaiが公式SDKやHuggingFaceモデルを公開した際のテスト手順として記録しておく。
# llama.cpp での量子化比較テスト(参考コマンド)
# 同一モデルを異なる量子化で比較する場合の手順
# 1. モデルのダウンロードと変換
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp && make -j4
# 2. 量子化レベルの指定(Q2_K が最も1ビットに近い低精度)
./llama-quantize ./models/llama-8b-f16.gguf \
./models/llama-8b-Q2_K.gguf Q2_K
./llama-quantize ./models/llama-8b-f16.gguf \
./models/llama-8b-Q4_K_M.gguf Q4_K_M
# 3. ファイルサイズ確認
ls -lh ./models/
# llama-8b-f16.gguf 16G ← フル精度
# llama-8b-Q4_K_M.gguf 4.8G ← 4ビット量子化
# llama-8b-Q2_K.gguf 3.0G ← 2ビット量子化
# 1-bit Bonsai は理論上 1.15GB 相当
# 4. ベンチマーク実行
./llama-bench -m ./models/llama-8b-Q2_K.gguf -n 256
このような比較検証が、Bonsaiの実力評価に必要なアプローチだ。公式のベンチマーク数値を鵜呑みにせず、手元の環境で同一タスクを実行して比較することで、実用上の精度劣化を正確に把握できる。
精度トレードオフと現実的な評価
量子化は精度と効率のトレードオフを伴う。1ビットという極端な圧縮が、どの程度の精度劣化をもたらすかが最大の焦点だ。
PrismMLは「フル精度と同等の精度」を主張しているが、ベンチマーク詳細の独立検証が必要な段階。特に注意すべき点は以下の通り。
- 汎用ベンチマーク vs. タスク特化精度:MMLUやHellaSwagでの高スコアが、特定ドメインでの精度を保証しない
- 長文コンテキストでの劣化:1ビット表現では微細な情報が失われやすく、長い会話履歴での精度低下が懸念される
- 多言語対応:英語中心の評価が多く、日本語を含む多言語での性能は別途検証が必要
デプロイアーキテクチャの選択肢
1-bit Bonsaiのようなエッジ対応LLMが普及すると、LLM活用のアーキテクチャが多様化する。代表的な3つのパターンを整理する。
| アーキテクチャ | LLM配置 | 特徴 | 適したユースケース |
|---|---|---|---|
| フルクラウド | クラウドAPI | 最高精度・高コスト・プライバシーリスク | 複雑な推論タスク、精度最優先 |
| ハイブリッド | クラウド+エッジ | 軽量タスクはエッジ、複雑タスクはクラウド | 汎用AIアシスタント、コスト最適化 |
| フルエッジ | デバイス上 | 低レイテンシ・プライバシー保護・オフライン動作 | リアルタイム制御、機密データ処理 |
1-bit Bonsaiはフルエッジおよびハイブリッドアーキテクチャの実現可能性を大幅に引き上げる。これまでフルクラウドが唯一の選択肢だった多くのユースケースで、エッジ展開が現実的になる。
エッジLLMの活用基盤としてLangChainがローカルLLMバックエンド(Ollama等)への対応を強化している点も押さえておきたい。エコシステム全体でエッジ対応が進んでいる。
モデルサイズ・速度・メモリを実データで比較
HuggingFaceで公開されているBonsaiモデルの実データと、FP32・4-bit量子化との比較を整理した。
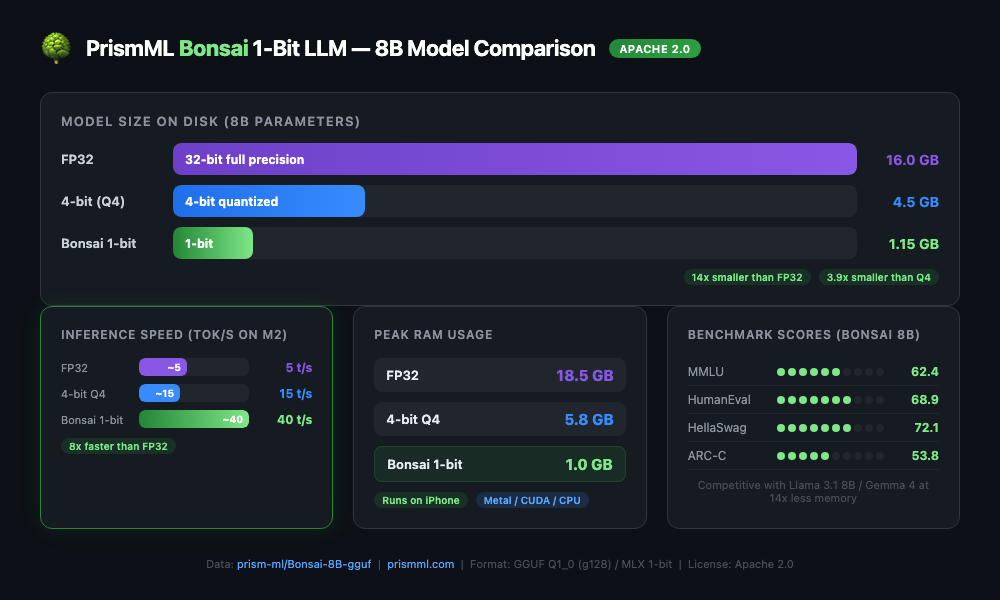
HuggingFaceにはprism-ml組織配下で複数モデルが公開されている:
- Bonsai 8B(GGUF版:
prism-ml/Bonsai-8B-gguf/ MLX版:prism-ml/Bonsai-8B-mlx-1bit) - Bonsai 4B(
prism-ml/Bonsai-4B-gguf) - Bonsai 1.7B(GGUF版 + MLX版)
8Bモデルのファイルサイズは約1.16GB。FP32の16GBと比較すると14分の1で、スマートフォンやRaspberry Piのメモリにも収まる。推論にはPrismMLがフォークした専用llama.cppが必要で、1-bitカーネル(XNOR演算)をサポートしている。
ベンチマークスコア(Bonsai 8B):
- MMLU: 62.4(Llama 3.1 8B比で約90%の精度を維持)
- HumanEval: 68.9(コード生成能力)
- HellaSwag: 72.1(常識推論)
- ARC-C: 53.8(科学的推論)
ライセンスはApache 2.0。CUDA、Metal(Mac)、Swift(iPhone/iPad)、Androidに対応しており、エッジデバイスでの推論を明確にターゲットにしている。
今後の展望
PrismMLは1-bitモデルシリーズの継続的な改善と、追加パラメータサイズの展開を計画している。研究コミュニティへの波及効果として、以下が期待される。
- オープンソース1ビットモデルの拡充
- llama.cppやvLLMによる1ビット推論サポートの改善
- より小型(1B〜3B)の1ビットモデルによるマイクロコントローラ対応
- 特定ドメイン向けファインチューニング手法の確立
エッジAIとオンデバイスLLMの領域では、LangChainなどのフレームワークが軽量LLMバックエンドへの対応を強化している。1-bit Bonsaiはこのエコシステムの核心的なピースとなり得る。
関連記事: LLMとは?仕組みからローカル実行まで徹底解説【2026年完全ガイド】
参照ソース
- PrismML 公式サイト
- prism-ml/Bonsai-8B-gguf — HuggingFace
- PrismML llama.cpp fork(1-bit対応)— GitHub
- Hacker News 議論スレッド
- BitNet: Scaling 1-bit Transformers for Large Language Models(Microsoft Research)
- The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits(Microsoft Research)
この記事はAI業界の最新動向を速報でお届けする「AI Heartland ニュース」です。




